
 Opération et maintenance
CentOS
Explication détaillée de la façon d'installer HBase1.4 sur Centos7
Opération et maintenance
CentOS
Explication détaillée de la façon d'installer HBase1.4 sur Centos7
Explication détaillée de la façon d'installer HBase1.4 sur Centos7

La colonne suivante vous présentera l'installation HBase1.4 de Centos7 à partir de la colonne tutoriel d'introduction à Centos J'espère qu'elle sera utile aux amis qui en ont besoin !
Préparation
1. Le cluster hadoop a été installé Ici, nous allons installer hbase1.4 sur la base de Hadoop2.7 installé sur Centos7, ce sont donc les trois mêmes machines. est la suivante :
| hostname | IP地址 | 部署规划 |
| node1 | 172.20.0.4 | Master、RegionServer |
| node2 | 172.20.0.5 | Backup-Master、RegionServer |
| node3 | 172.20.0.6 | RegionServer |
2. Téléchargez le package d'installation depuis le site officiel : hbase-1.4.12-bin.tar.gz (il est recommandé d'aller sur le site miroir open source de l'Université Tsinghua. ou l'Université des sciences et technologies de Chine).
3. hbase sera déployé dans le chemin/mydata qui existe déjà sur les trois machines :
export HBASE_HOME=/mydata/hbase-1.4.12export PATH=${HBASE_HOME}/bin:$PATHConfiguration
Modifiez d'abord la configuration hbase sur. node1 et complétez-le, puis copiez-le uniformément sur d'autres nœuds pour garantir la cohérence du contenu de la configuration.
Décompressez hbase-1.4.12-bin.tar.gz dans /mydata/, saisissez /mydata/hbase-1.4.12/conf et configurez :
<!-- 文件名 hbase-site.xml --><configuration> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.rootdir</name> <value>hdfs://node1:9000/hbase</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>node1,node2,node3</value> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/mydata/data/zookeeper</value> </property> </configuration>
# 文件名 regionserversnode1 node2 node3
# 文件名 backup-masters 该文件需要新建node2
| 配置项 | 含义 |
hbase.cluster.distributed Copier après la connexion |
分布式模式 |
hbase.rootdir Copier après la connexion |
hbase的数据存储位置,这里为hdfs的/hbase,host:port对应hadoop配置中的fs.defaultFS |
hbase.zookeeper.quorum Copier après la connexion |
所有要部署zookeeper的host,通常三台以上吧,最多当然可以每一台都部署 |
hbase.zookeeper.property.dataDir Copier après la connexion |
zookeeper运行时的数据存储位置 |
regionservers Copier après la connexion |
所有RegionServer,通常部署到每一台DataNode上 |
backup-masters Copier après la connexion |
作为备份的Master |
Remarque : Le gardien de zoo utilise ici celui fourni avec hbase. Bien sûr, vous pouvez également utiliser celui externe existant, que je ne mentionnerai pas ici.
Le répertoire des journaux par défaut est dans $HBASE_HOME/logs, et le fichier pid est dans /tmp, qui peut être modifié :
# 文件名 hbase-env.shexport HBASE_LOG_DIR=/mydata/logs/hbase export HBASE_PID_DIR=/mydata/data/pid
Une fois la configuration terminée, copiez le fichier du programme hbase dans les deux autres :
node1> scp -r /mydata/hbase-1.4.12/ root@node2:/mydata/node1> scp -r /mydata/hbase-1.4.12/ root@node3:/mydata/
Start
node1> start-hbase.sh
| node1上用jps命令验证进程 | HMaster、HRegionServer、HQuorumPeer |
| node2上用jps命令验证进程 | HMaster、HRegionServer、HQuorumPeer |
| node3上用jps命令验证进程 | HRegionServer、HQuorumPeer |
Remarque : HQuorumPeer est un processus zookeeper. Les nœuds qui ne déploient pas zookeeper ne l'ont pas si un zookeeper externe est utilisé, le processus. le nom devient QuorumPeerMain.
Test
L'adresse suivante est accessible via le navigateur :
| Backend du Master | http://node1:16010 | ||||
|
http://node1 : 16030 http://node2:16030
|
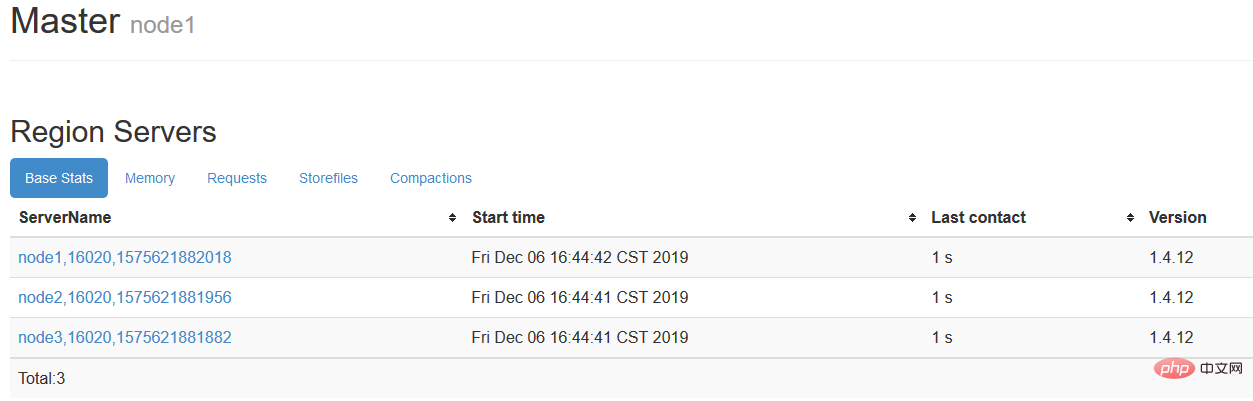 http://node3:16030
http://node3:16030Visitez le premier pour voir :
Exécutez un exemple officiel ci-dessous (la commande suivante peut être exécutée sur n'importe quelle machine sur laquelle hbase est déployé) :node> hbase shell hbase> create 'test', 'cf' hbase> list 'test' hbase> describe 'test' hbase> put 'test', 'row1', 'cf:a', 'value1' hbase> put 'test', 'row2', 'cf:b', 'value2' hbase> put 'test', 'row3', 'cf:c', 'value3' hbase> scan 'test' hbase> get 'test', 'row1'
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1358
1358
 52
52

 Adresses de téléchargement d'images de différentes versions de CentOS7 et descriptions de versions (y compris la version Everything)
Feb 29, 2024 am 09:20 AM
Adresses de téléchargement d'images de différentes versions de CentOS7 et descriptions de versions (y compris la version Everything)
Feb 29, 2024 am 09:20 AM
Lors du chargement de CentOS-7.0-1406, il existe de nombreuses versions facultatives. Pour les utilisateurs ordinaires, ils ne savent pas laquelle choisir : (1) CentOS-xxxx-LiveCD.ios et CentOS-xxxx- Quoi. est la différence entre bin-DVD.iso ? Le premier n’a que 700 Mo et le second 3,8 Go. La différence ne réside pas seulement dans la taille, mais la différence la plus essentielle est que CentOS-xxxx-LiveCD.ios ne peut être chargé que dans la mémoire et exécuté, et ne peut pas être installé. Seul CentOS-xxx-bin-DVD1.iso peut être installé sur le disque dur. (2) CentOS-xxx-bin-DVD1.iso, Ce
 Étapes pour accéder au mode de réparation d'urgence de CentOS 7
Jan 13, 2024 am 09:36 AM
Étapes pour accéder au mode de réparation d'urgence de CentOS 7
Jan 13, 2024 am 09:36 AM
Ouvrez la page centos7 et apparaissez : bienvenue en mode urgence ! après vous être connecté, tapez « journalctl -xb » pour afficher les journaux système, « systemctlreboot » pour redémarrer, « systemctldefault » pour réessayer de démarrer en mode par défaut. giverootpasswordformaintenance(??Control-D???) : Solution : exécuter r
 Comment accéder et nettoyer les fichiers indésirables dans le répertoire /tmp dans CentOS 7 ?
Dec 27, 2023 pm 09:10 PM
Comment accéder et nettoyer les fichiers indésirables dans le répertoire /tmp dans CentOS 7 ?
Dec 27, 2023 pm 09:10 PM
Il y a beaucoup de déchets dans le répertoire tmp du système centos7. Si vous souhaitez nettoyer les déchets, comment devez-vous procéder ? Jetons un coup d'œil au didacticiel détaillé ci-dessous. Pour afficher la liste des fichiers dans le répertoire de fichiers tmp, exécutez la commande cdtmp/ pour basculer vers le répertoire de fichiers actuel de tmp, et exécutez la commande ll pour afficher la liste des fichiers dans le répertoire actuel. Comme indiqué ci-dessous. Utilisez la commande rm pour supprimer des fichiers. Il convient de noter que la commande rm supprime définitivement les fichiers du système. Par conséquent, il est recommandé que lors de l'utilisation de la commande rm, il soit préférable de donner une invite avant de supprimer le fichier. Utilisez la commande rm-i file name, attendez que l'utilisateur confirme la suppression (y) ou ignore la suppression (n), et le système effectuera les opérations correspondantes. Comme indiqué ci-dessous.
 Comment installer l'extension mbstring sous CENTOS7 ?
Jan 06, 2024 pm 09:59 PM
Comment installer l'extension mbstring sous CENTOS7 ?
Jan 06, 2024 pm 09:59 PM
1.UncaughtError:Calltoundefinedfunctionmb_strlen(); Lorsque l'erreur ci-dessus se produit, cela signifie que nous n'avons pas installé l'extension mbstring ; 2. Entrez dans le répertoire d'installation de PHP cd/temp001/php-7.1.0/ext/mbstring ; /usr/local/bin /phpize ou /usr/local/php7-abel001/bin/phpize) pour installer l'extension php 4../configure--with-php-config=/usr/local/php7-abel
 Comment définir des règles de mot de passe dans centos7 ?
Jan 07, 2024 pm 01:17 PM
Comment définir des règles de mot de passe dans centos7 ?
Jan 07, 2024 pm 01:17 PM
Définir des règles de mot de passe pour des raisons de sécurité. Définissez le nombre de jours d'expiration du mot de passe. L'utilisateur doit changer le mot de passe dans les jours. Ce paramètre affecte uniquement les utilisateurs créés, pas les utilisateurs existants. Si vous définissez un utilisateur existant, exécutez la commande "chage -M (jours) (utilisateur)". PASS_MAX_DAYS60#Délai d'expiration du mot de passe PASS_MIN_DAYS3#Délai de changement de mot de passe initial PASS_MIN_LEN8#Longueur minimale du mot de passe PASS_WARN_AGE7#Délai d'invite d'expiration du mot de passe Répétez l'utilisation de la restriction du mot de passe [root@linuxprobe~]#vi/etc/pam.d/system-auth#nearline15 :
 Comment installer Mysql dans CentOS7 et le configurer pour qu'il démarre automatiquement au démarrage
Jun 02, 2023 pm 08:36 PM
Comment installer Mysql dans CentOS7 et le configurer pour qu'il démarre automatiquement au démarrage
Jun 02, 2023 pm 08:36 PM
Centos7 n'a pas de base de données MySQL. La base de données par défaut est Mariadb (une branche de MySQL). Vous pouvez installer la base de données MySQL manuellement en suivant les étapes ci-dessous. 1. Téléchargez le fichier d'installation rpm wgethttp://repo.mysql.com/mysql-community-release-el7.rpm 2. Exécutez rpm pour installer rpm-ivhmysql-community-release-el7.rpm Une fois la résolution des dépendances terminée. , les options suivantes apparaissent : dependenciesresolved ==================================
 Comment modifier et définir les touches de raccourci par défaut de CentOS7 ?
Jan 09, 2024 pm 06:14 PM
Comment modifier et définir les touches de raccourci par défaut de CentOS7 ?
Jan 09, 2024 pm 06:14 PM
Lorsque les touches de raccourci par défaut entrent en conflit avec les touches du logiciel que vous utilisez ou que vous devez utiliser les touches de raccourci selon vos propres habitudes, vous devez modifier et définir les touches de raccourci par défaut. Comment modifier les touches de raccourci par défaut de CentOS7 ? Jetons un coup d'œil au didacticiel détaillé ci-dessous. 1. Démarrez le système Centos7 dans la machine virtuelle et accédez au bureau. 2. Cliquez sur Applications->Outils système->Paramètres dans le coin supérieur gauche. 3. Entrez dans l'interface de configuration et cliquez sur le périphérique. 4. Sélectionnez Clavier et cliquez sur n'importe lequel. à droite. Et appuyez sur la touche de raccourci à définir sur le clavier pour modifier sa touche de raccourci (notez que certaines ne peuvent pas être modifiées !) 5. Après le changement, comme indiqué ci-dessous, cliquez enfin sur Paramètres, pour que le paramètre de la touche de raccourci soit défini. la modification est terminée.
 Désactivez IPv6 pour CentOS 7, utilisez uniquement IPv4
Jan 15, 2024 pm 10:39 PM
Désactivez IPv6 pour CentOS 7, utilisez uniquement IPv4
Jan 15, 2024 pm 10:39 PM
centos7 utilise le protocole ipv6. Si un problème survient, il sera difficile à résoudre. Donc, si vous souhaitez désactiver ipv6, comment devez-vous le désactiver ? Jetons un coup d'œil au didacticiel détaillé ci-dessous. 1. Utilisez la commande ifconfig pour vérifier les informations de la carte réseau. Si inet6fe80::20c:29ff:fed0:3514 apparaît, cela signifie que ipv62 est activé sur la machine. Modifiez la configuration /etc/sysctl.conf et ajoutez net.ipv6. conf.all.disable_ipv6=13. Modifiez la configuration de /etc/sysconfig/network, ajoutez NETWORKING_IPV6=no, enregistrez et quittez 4. Modifiez /etc/s
