


Les étudiants qui ont utilisé webpack doivent savoir que Présentation de la pratique de lanalyse des dépendances des mini-programmes peut être utilisé pour analyser les dépendances des fichiers js du projet en cours.
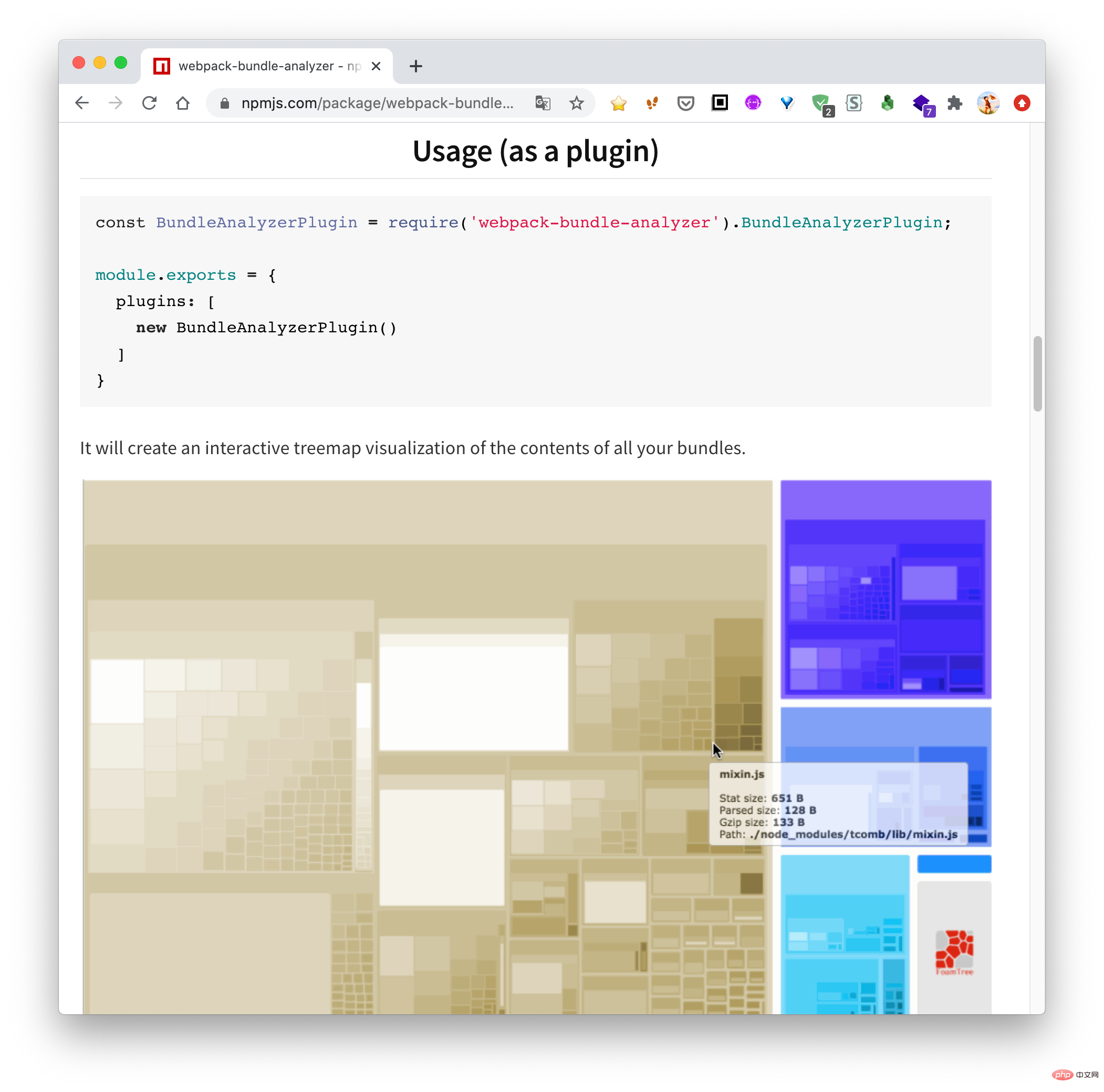
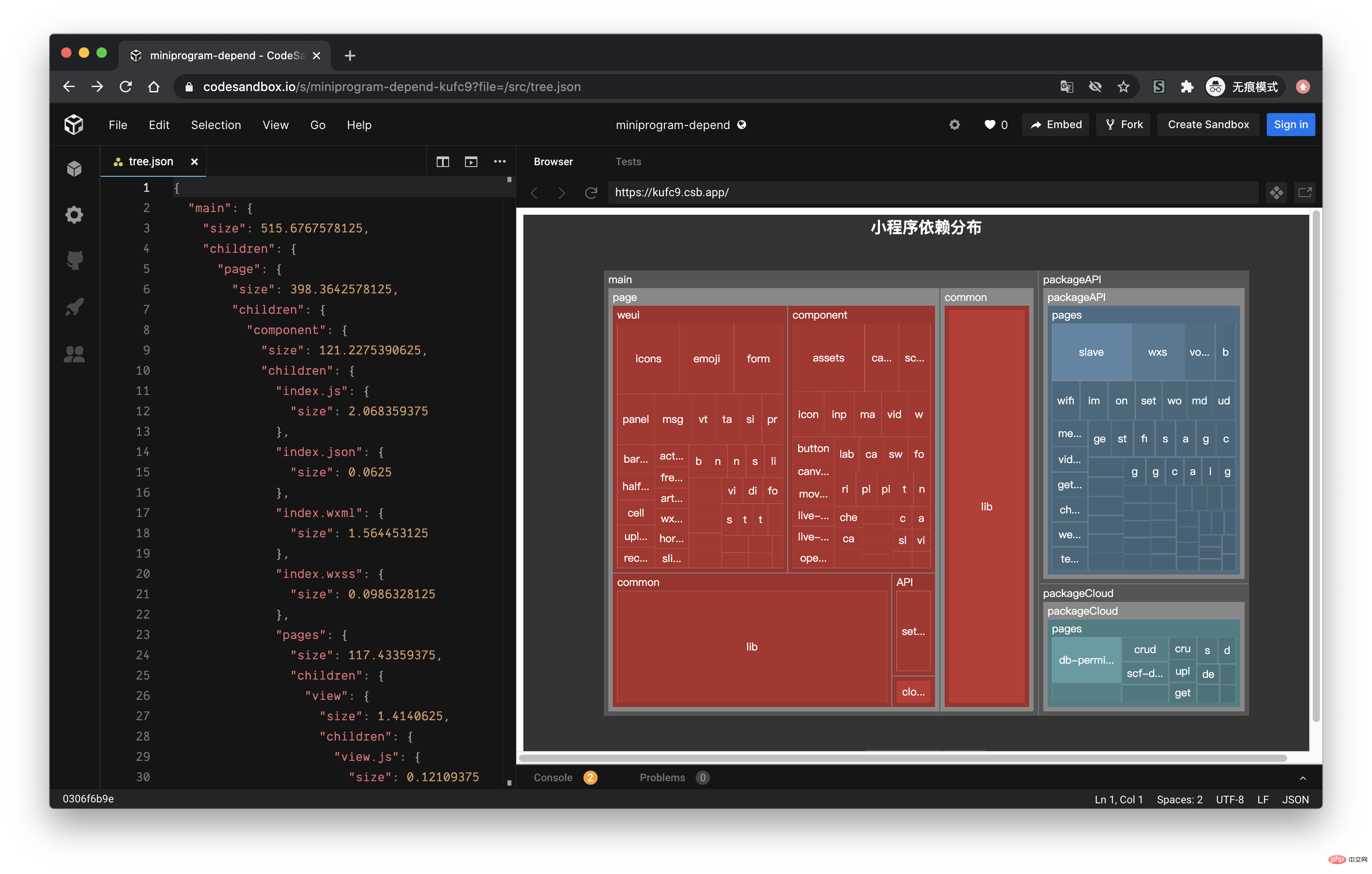
Parce que je me suis récemment occupé de mini-programmes et que les mini-programmes sont particulièrement sensibles à la taille du paquet, je pensais créer un outil similaire pour afficher les dépendances actuelles entre les principaux packages et sous-contrats du mini programme. Après plusieurs jours de lancer, j'ai enfin réussi, et l'effet est le suivant :
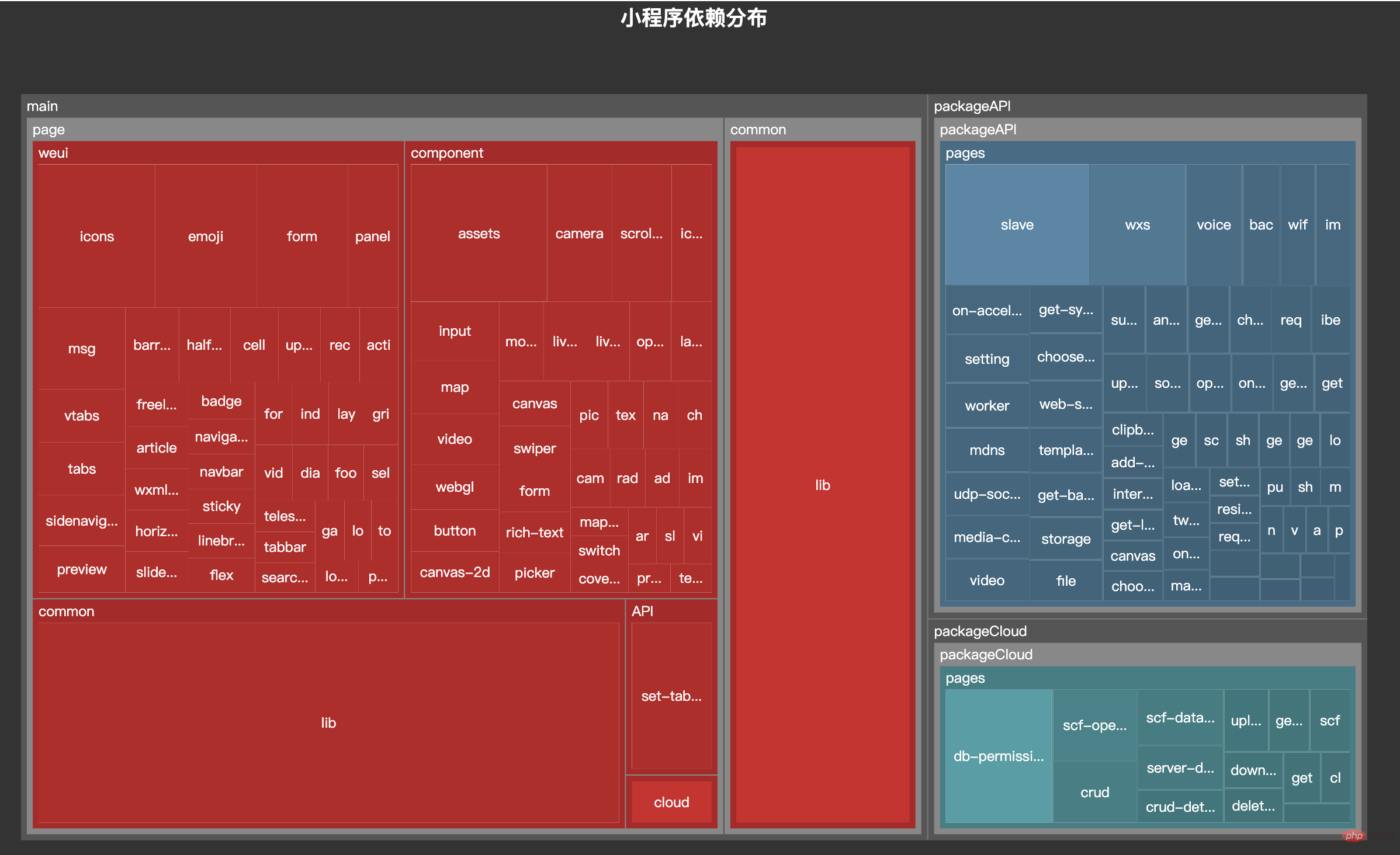
L'article d'aujourd'hui vous amènera à mettre en œuvre cet outil.
La page du mini programme est définie par le paramètre app.json de pages, qui permet de préciser à quelles pages se compose le mini programme auquel correspond chaque élément. au chemin d'une page (informations (y compris le nom du fichier). Pour chaque page de pages, l'applet recherchera les quatre fichiers correspondants json, js, wxml, wxss pour traitement.
Si le répertoire de développement est :
├── app.js ├── app.json ├── app.wxss ├── pages │ │── index │ │ ├── index.wxml │ │ ├── index.js │ │ ├── index.json │ │ └── index.wxss │ └── logs │ ├── logs.wxml │ └── logs.js └── utils复制代码
, vous devez écrire dans app.json :
{ "pages": ["pages/index/index", "pages/logs/logs"]
}复制代码Pour faciliter la démonstration, nous forkons d'abord une démo officielle du mini programme, puis Créer un nouveau fichier depend.js, et le travail lié à l'analyse des dépendances est implémenté dans ce fichier.
$ git clone git@github.com:wechat-miniprogram/miniprogram-demo.git $ cd miniprogram-demo $ touch depend.js复制代码
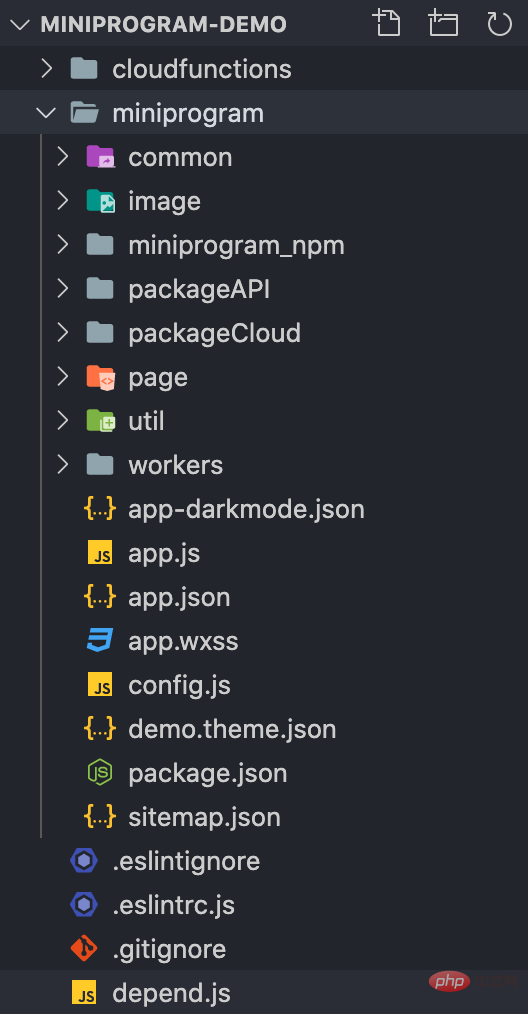
La structure générale du répertoire est la suivante :
Avec app.json comme entrée, nous pouvons obtenir toutes les pages du package principal.
const fs = require('fs-extra')const path = require('path')const root = process.cwd()class Depend { constructor() { this.context = path.join(root, 'miniprogram')
} // 获取绝对地址
getAbsolute(file) { return path.join(this.context, file)
} run() { const appPath = this.getAbsolute('app.json') const appJson = fs.readJsonSync(appPath) const { pages } = appJson // 主包的所有页面
}
}复制代码Chaque page correspondra à json, js, wxml, wxss quatre fichiers :
const Extends = ['.js', '.json', '.wxml', '.wxss']class Depend { constructor() { // 存储文件
this.files = new Set() this.context = path.join(root, 'miniprogram')
} // 修改文件后缀
replaceExt(filePath, ext = '') { const dirName = path.dirname(filePath) const extName = path.extname(filePath) const fileName = path.basename(filePath, extName) return path.join(dirName, fileName + ext)
} run() { // 省略获取 pages 过程
pages.forEach(page => { // 获取绝对地址
const absPath = this.getAbsolute(page)
Extends.forEach(ext => { // 每个页面都需要判断 js、json、wxml、wxss 是否存在
const filePath = this.replaceExt(absPath, ext) if (fs.existsSync(filePath)) { this.files.add(filePath)
}
})
})
}
}复制代码Maintenant, les fichiers liés aux pages dans les pages sont placés dans le champ de fichiers Enregistré.
Après avoir obtenu les fichiers, nous devons construire une arborescence de fichiers arborescente basée sur chaque fichier pour un affichage ultérieur des dépendances.
Supposons que nous ayons un répertoire pages et qu'il y ait deux pages dans le répertoire pages : detail, index Il y a quatre fichiers correspondants sous ces deux dossiers de pages.
pages ├── detail │ ├── detail.js │ ├── detail.json │ ├── detail.wxml │ └── detail.wxss └── index ├── index.js ├── index.json ├── index.wxml └── index.wxss复制代码
Sur la base de la structure de répertoires ci-dessus, nous construisons une arborescence de fichiers comme suit, size est utilisé pour indiquer la taille du fichier ou du dossier actuel, children stocke les fichiers sous le dossier, si c'est un fichier. Il n'y a pas d'attribut children.
pages = { "size": 8, "children": { "detail": { "size": 4, "children": { "detail.js": { "size": 1 }, "detail.json": { "size": 1 }, "detail.wxml": { "size": 1 }, "detail.wxss": { "size": 1 }
}
}, "index": { "size": 4, "children": { "index.js": { "size": 1 }, "index.json": { "size": 1 }, "index.wxml": { "size": 1 }, "index.wxss": { "size": 1 }
}
}
}
}复制代码Nous construisons d'abord un champ tree dans le constructeur pour stocker les données de l'arborescence de fichiers, puis nous passons chaque fichier dans la méthode addToTree pour ajouter le fichier à l'arborescence.
class Depend { constructor() { this.tree = { size: 0, children: {}
} this.files = new Set() this.context = path.join(root, 'miniprogram')
}
run() { // 省略获取 pages 过程
pages.forEach(page => { const absPath = this.getAbsolute(page)
Extends.forEach(ext => { const filePath = this.replaceExt(absPath, ext) if (fs.existsSync(filePath)) { // 调用 addToTree
this.addToTree(filePath)
}
})
})
}
}复制代码 Implémentez ensuite la méthode addToTree :
class Depend { // 省略之前的部分代码
// 获取相对地址
getRelative(file) { return path.relative(this.context, file)
} // 获取文件大小,单位 KB
getSize(file) { const stats = fs.statSync(file) return stats.size / 1024
} // 将文件添加到树中
addToTree(filePath) { if (this.files.has(filePath)) { // 如果该文件已经添加过,则不再添加到文件树中
return
} const size = this.getSize(filePath) const relPath = this.getRelative(filePath) // 将文件路径转化成数组
// 'pages/index/index.js' =>
// ['pages', 'index', 'index.js']
const names = relPath.split(path.sep) const lastIdx = names.length - 1
this.tree.size += size let point = this.tree.children
names.forEach((name, idx) => { if (idx === lastIdx) {
point[name] = { size } return
} if (!point[name]) {
point[name] = {
size, children: {}
}
} else {
point[name].size += size
}
point = point[name].children
}) // 将文件添加的 files
this.files.add(filePath)
}
}复制代码 Nous pouvons sortir le fichier vers Présentation de la pratique de lanalyse des dépendances des mini-programmes après l'avoir exécuté pour y jeter un œil.
run() { // ...
pages.forEach(page => { //...
})
fs.writeJSONSync('Présentation de la pratique de lanalyse des dépendances des mini-programmes', this.tree, { spaces: 2 })
}复制代码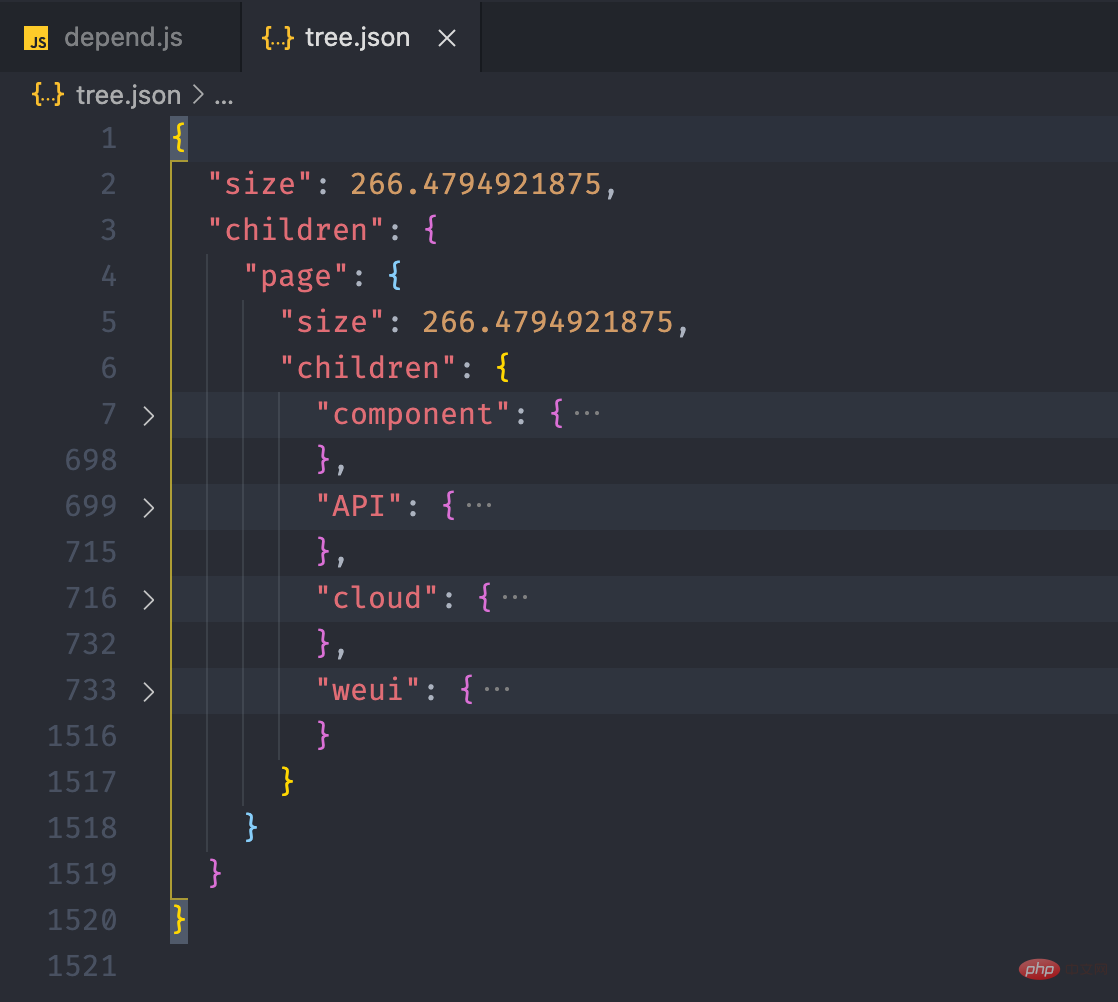
Les étapes ci-dessus semblent correctes, mais il nous manque un lien important, c'est-à-dire qu'avant de construire l'arborescence des fichiers, vous également besoin d'obtenir les dépendances de chaque fichier, afin que la sortie soit l'arborescence de fichiers complète du mini-programme. Les dépendances des fichiers doivent être divisées en quatre parties, à savoir js, json, wxml, wxss Ces quatre types de fichiers obtiennent des dépendances.
L'applet prend en charge CommonJS pour la modularisation Si es6 est activé, elle peut également prendre en charge ESM pour la modularisation. Si l'on veut obtenir les dépendances d'un fichier js, il faut d'abord clarifier les trois manières d'écrire des fichiers js pour importer des modules. Pour les trois syntaxes suivantes, on peut introduire Babel pour obtenir des dépendances.
import a from './a.js'export b from './b.js'const c = require('./c.js')复制代码Convertissez le code en AST via @babel/parser, puis parcourez les nœuds AST via @babel/traverse pour obtenir les valeurs des trois méthodes d'importation ci-dessus et les placer dans le tableau.
const { parse } = require('@babel/parser')const { default: traverse } = require('@babel/traverse')class Depend { // ...
jsDeps(file) { const deps = [] const dirName = path.dirname(file) // 读取 js 文件内容
const content = fs.readFileSync(file, 'utf-8') // 将代码转化为 AST
const ast = parse(content, { sourceType: 'module', plugins: ['exportDefaultFrom']
}) // 遍历 AST
traverse(ast, { ImportDeclaration: ({ node }) => { // 获取 import from 地址
const { value } = node.source const jsFile = this.transformScript(dirName, value) if (jsFile) {
deps.push(jsFile)
}
}, ExportNamedDeclaration: ({ node }) => { // 获取 export from 地址
const { value } = node.source const jsFile = this.transformScript(dirName, value) if (jsFile) {
deps.push(jsFile)
}
}, CallExpression: ({ node }) => { if (
(node.callee.name && node.callee.name === 'require') &&
node.arguments.length >= 1
) { // 获取 require 地址
const [{ value }] = node.arguments const jsFile = this.transformScript(dirName, value) if (jsFile) {
deps.push(jsFile)
}
}
}
}) return deps
}
}复制代码Après avoir obtenu le chemin du module dépendant, vous ne pouvez pas ajouter immédiatement le chemin au tableau de dépendances, car selon la syntaxe du module js le suffixe peut être omis, et lorsque le chemin requis est un dossier , Par défaut, index.js sous ce dossier sera importé.
class Depend { // 获取某个路径的脚本文件
transformScript(url) { const ext = path.extname(url) // 如果存在后缀,表示当前已经是一个文件
if (ext === '.js' && fs.existsSync(url)) { return url
} // a/b/c => a/b/c.js
const jsFile = url + '.js'
if (fs.existsSync(jsFile)) { return jsFile
} // a/b/c => a/b/c/index.js
const jsIndexFile = path.join(url, 'index.js') if (fs.existsSync(jsIndexFile)) { return jsIndexFile
} return null
} jsDeps(file) {...}
}复制代码Nous pouvons créer un js et voir si le résultat deps est correct :
// 文件路径:/Users/shenfq/Code/fork/miniprogram-demo/import a from './a.js'export b from '../b.js'const c = require('../../c.js')复制代码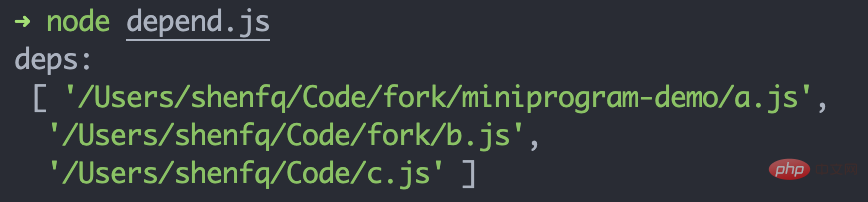
json 文件本身是不支持模块化的,但是小程序可以通过 json 文件导入自定义组件,只需要在页面的 json 文件通过 usingComponents 进行引用声明。usingComponents 为一个对象,键为自定义组件的标签名,值为自定义组件文件路径:
{ "usingComponents": { "component-tag-name": "path/to/the/custom/component"
}
}复制代码自定义组件与小程序页面一样,也会对应四个文件,所以我们需要获取 json 中 usingComponents 内的所有依赖项,并判断每个组件对应的那四个文件是否存在,然后添加到依赖项内。
class Depend { // ...
jsonDeps(file) { const deps = [] const dirName = path.dirname(file) const { usingComponents } = fs.readJsonSync(file) if (usingComponents && typeof usingComponents === 'object') { Object.values(usingComponents).forEach((component) => {
component = path.resolve(dirName, component) // 每个组件都需要判断 js/json/wxml/wxss 文件是否存在
Extends.forEach((ext) => { const file = this.replaceExt(component, ext) if (fs.existsSync(file)) {
deps.push(file)
}
})
})
} return deps
}
}复制代码wxml 提供两种文件引用方式 import 和 include。
<import></import><include></include>复制代码
wxml 文件本质上还是一个 html 文件,所以可以通过 html parser 对 wxml 文件进行解析,关于 html parser 相关的原理可以看我之前写过的文章 《Vue 模板编译原理》。
const htmlparser2 = require('htmlparser2')class Depend { // ...
wxmlDeps(file) { const deps = [] const dirName = path.dirname(file) const content = fs.readFileSync(file, 'utf-8') const htmlParser = new htmlparser2.Parser({ onopentag(name, attribs = {}) { if (name !== 'import' && name !== 'require') { return
} const { src } = attribs if (src) { return
} const wxmlFile = path.resolve(dirName, src) if (fs.existsSync(wxmlFile)) {
deps.push(wxmlFile)
}
}
})
htmlParser.write(content)
htmlParser.end() return deps
}
}复制代码最后 wxss 文件导入样式和 css 语法一致,使用 @import 语句可以导入外联样式表。
@import "common.wxss";复制代码
可以通过 postcss 解析 wxss 文件,然后获取导入文件的地址,但是这里我们偷个懒,直接通过简单的正则匹配来做。
class Depend { // ...
wxssDeps(file) { const deps = [] const dirName = path.dirname(file) const content = fs.readFileSync(file, 'utf-8') const importRegExp = /@import\\s*['"](.+)['"];*/g
let matched while ((matched = importRegExp.exec(content)) !== null) { if (!matched[1]) { continue
} const wxssFile = path.resolve(dirName, matched[1]) if (fs.existsSync(wxmlFile)) {
deps.push(wxssFile)
}
} return deps
}
}复制代码现在我们需要修改 addToTree 方法。
class Depend { addToTree(filePath) { // 如果该文件已经添加过,则不再添加到文件树中
if (this.files.has(filePath)) { return
} const relPath = this.getRelative(filePath) const names = relPath.split(path.sep)
names.forEach((name, idx) => { // ... 添加到树中
}) this.files.add(filePath) // ===== 获取文件依赖,并添加到树中 =====
const deps = this.getDeps(filePath)
deps.forEach(dep => { this.addToTree(dep)
})
}
}复制代码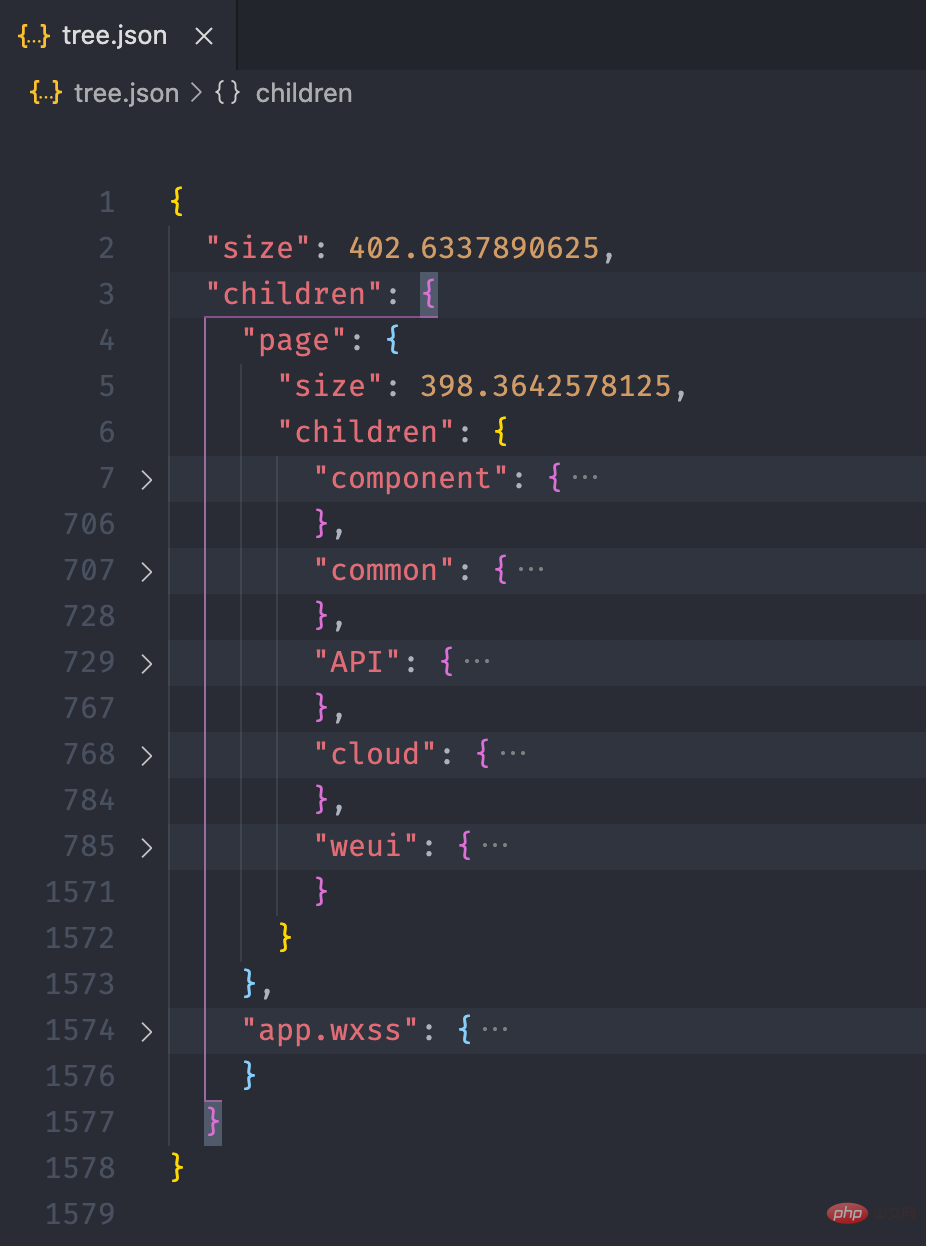
熟悉小程序的同学肯定知道,小程序提供了分包机制。使用分包后,分包内的文件会被打包成一个单独的包,在用到的时候才会加载,而其他的文件则会放在主包,小程序打开的时候就会加载。subpackages 中,每个分包的配置有以下几项:
| 字段 | 类型 | 说明 |
|---|---|---|
| root | String | 分包根目录 |
| name | String | 分包别名,分包预下载时可以使用 |
| pages | StringArray | 分包页面路径,相对与分包根目录 |
| independent | Boolean | 分包是否是独立分包 |
所以我们在运行的时候,除了要拿到 pages 下的所有页面,还需拿到 subpackages 中所有的页面。由于之前只关心主包的内容,this.tree 下面只有一颗文件树,现在我们需要在 this.tree 下挂载多颗文件树,我们需要先为主包创建一个单独的文件树,然后为每个分包创建一个文件树。
class Depend { constructor() { this.tree = {} this.files = new Set() this.context = path.join(root, 'miniprogram')
} createTree(pkg) { this.tree[pkg] = { size: 0, children: {}
}
} addPage(page, pkg) { const absPath = this.getAbsolute(page)
Extends.forEach(ext => { const filePath = this.replaceExt(absPath, ext) if (fs.existsSync(filePath)) { this.addToTree(filePath, pkg)
}
})
} run() { const appPath = this.getAbsolute('app.json') const appJson = fs.readJsonSync(appPath) const { pages, subPackages, subpackages } = appJson
this.createTree('main') // 为主包创建文件树
pages.forEach(page => { this.addPage(page, 'main')
}) // 由于 app.json 中 subPackages、subpackages 都能生效
// 所以我们两个属性都获取,哪个存在就用哪个
const subPkgs = subPackages || subpackages // 分包存在的时候才进行遍历
subPkgs && subPkgs.forEach(({ root, pages }) => {
root = root.split('/').join(path.sep) this.createTree(root) // 为分包创建文件树
pages.forEach(page => { this.addPage(`${root}${path.sep}${page}`, pkg)
})
}) // 输出文件树
fs.writeJSONSync('Présentation de la pratique de lanalyse des dépendances des mini-programmes', this.tree, { spaces: 2 })
}
}复制代码addToTree 方法也需要进行修改,根据传入的 pkg 来判断将当前文件添加到哪个树。
class Depend { addToTree(filePath, pkg = 'main') { if (this.files.has(filePath)) { // 如果该文件已经添加过,则不再添加到文件树中
return
} let relPath = this.getRelative(filePath) if (pkg !== 'main' && relPath.indexOf(pkg) !== 0) { // 如果该文件不是以分包名开头,证明该文件不在分包内,
// 需要将文件添加到主包的文件树内
pkg = 'main'
} const tree = this.tree[pkg] // 依据 pkg 取到对应的树
const size = this.getSize(filePath) const names = relPath.split(path.sep) const lastIdx = names.length - 1
tree.size += size let point = tree.children
names.forEach((name, idx) => { // ... 添加到树中
}) this.files.add(filePath) // ===== 获取文件依赖,并添加到树中 =====
const deps = this.getDeps(filePath)
deps.forEach(dep => { this.addToTree(dep)
})
}
}复制代码这里有一点需要注意,如果 package/a 分包下的文件依赖的文件不在 package/a 文件夹下,则该文件需要放入主包的文件树内。
经过上面的流程后,最终我们可以得到如下的一个 json 文件:
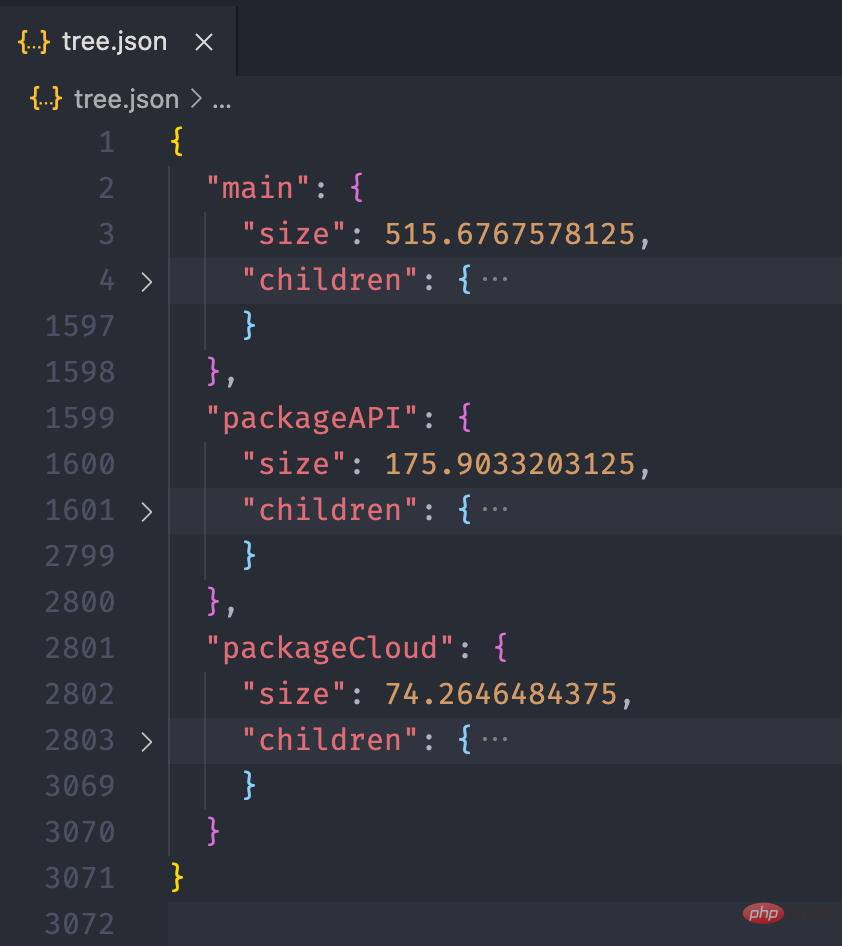
接下来,我们利用 Présentation de la pratique de lanalyse des dépendances des mini-programmes 的画图能力,将这个 json 数据以图表的形式展现出来。我们可以在 Présentation de la pratique de lanalyse des dépendances des mini-programmes 提供的实例中看到一个 Disk Usage 的案例,很符合我们的预期。
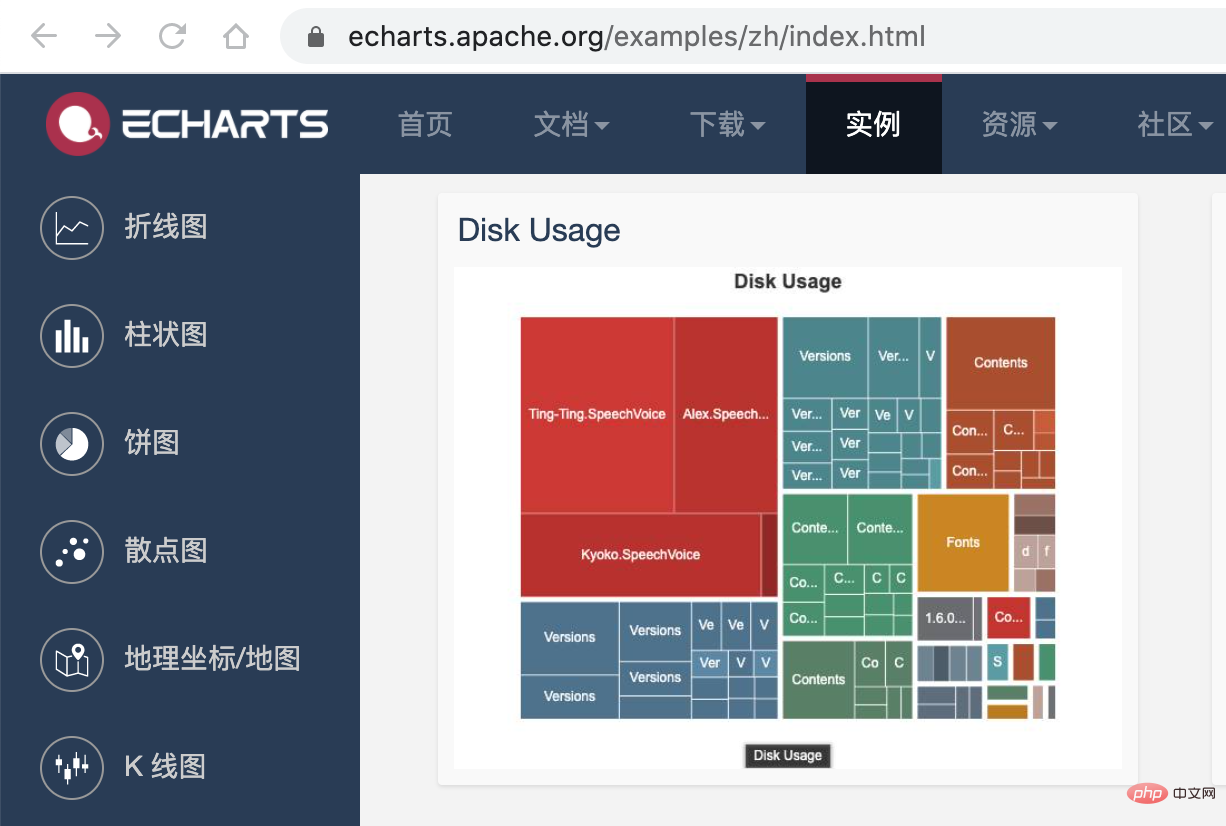
Présentation de la pratique de lanalyse des dépendances des mini-programmes 的配置这里就不再赘述,按照官网的 demo 即可,我们需要把 tree. json 的数据转化为 Présentation de la pratique de lanalyse des dépendances des mini-programmes 需要的格式就行了,完整的代码放到 codesandbod 了,去下面的线上地址就能看到效果了。
线上地址:https://codesandbox.io/s/cold-dawn-kufc9
这篇文章比较偏实践,所以贴了很多的代码,另外本文对各个文件的依赖获取提供了一个思路,虽然这里只是用文件树构造了一个这样的依赖图。
在业务开发中,小程序 IDE 每次启动都需要进行全量的编译,开发版预览的时候会等待较长的时间,我们现在有文件依赖关系后,就可以只选取目前正在开发的页面进行打包,这样就能大大提高我们的开发效率。如果有对这部分内容感兴趣的,可以另外写一篇文章介绍下如何实现。
相关免费学习推荐:微信小程序开发教程
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Acquisition de chemin de mini-programme
Acquisition de chemin de mini-programme
 Quels sont les outils de développement asp ?
Quels sont les outils de développement asp ?
 Quel logiciel est Xiaohongshu ?
Quel logiciel est Xiaohongshu ?
 Supprimer l'historique de recherche
Supprimer l'historique de recherche
 Comment annuler l'erreur de commit git
Comment annuler l'erreur de commit git
 utilisation de l'instruction d'insertion
utilisation de l'instruction d'insertion
 CSS définir la couleur du texte
CSS définir la couleur du texte
 Comment utiliser la jointure gauche
Comment utiliser la jointure gauche
 Comment désactiver les mises à jour automatiques dans Win10
Comment désactiver les mises à jour automatiques dans Win10










![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



