


Recommandations d'apprentissage gratuites associées : Tutoriel vidéo MySQL
Dans les bases de données relationnelles, un index est une structure de stockage physique distincte qui trie les valeurs d'une ou plusieurs colonnes dans une table de base de données. . Collection et liste correspondante de pointeurs logiques vers les pages de données du tableau qui identifient physiquement ces valeurs. L'index est équivalent à la table des matières d'un livre. Vous pouvez trouver rapidement le contenu souhaité en fonction des numéros de page dans la table des matières.
Lorsqu'il y a un grand nombre d'enregistrements dans la table, si vous souhaitez interroger la table, la première façon de rechercher des informations est de rechercher dans toute la table, c'est-à-dire de supprimer tous les enregistrements un par un, comparez-les un par un avec les conditions de requête, puis renvoyez les enregistrements qui remplissent les conditions, cela consommera beaucoup de temps système de base de données et entraînera de nombreuses opérations d'E/S disque ; table, puis recherchez la valeur d'index qui répond aux conditions de requête dans l'index, et enfin enregistrez-la dans l'index. Le ROWID (équivalent au numéro de page) dans la table peut trouver rapidement l'enregistrement correspondant dans la table.
La structure de données d'index utilisée par le moteur de stockage InnoDB après MySQL 5.5 utilise principalement : B+Tree ; cet article vous amènera à parler de la vie passée et présente de B+Tree ;
**Mark**:B+Tree peut être utilisé pour , > ;=, BETWEEN, IN et LIKE qui ne commencent pas par un caractère générique utilisent des index. (Après MySQL 5.5)
Ces faits peuvent bouleverser certaines de vos perceptions, comme dans d'autres articles ou livres que vous avez lus. Toutes les requêtes ci-dessus sont des « requêtes de plage » et ne sont pas indexées !
C'est vrai, avant la version 5.5, l'optimiseur ne choisissait pas de rechercher dans l'index. L'optimiseur pensait que les lignes récupérées de cette manière étaient plus nombreuses que celles de l'analyse complète de la table, car il faudrait revenir en arrière. à la table pour vérifier, ce qui peut impliquer Le nombre de lignes d'E/S est plus grand et est abandonné par l'optimiseur.
Après optimisation de l'algorithme (B+Tree), il prend en charge l'analyse de certains types de plages (en profitant de l'ordre de la structure de données B+Tree). Cette approche viole également le principe du préfixe le plus à gauche, ce qui fait que la condition après la requête de plage ne peut pas utiliser l'index conjoint, ce que nous expliquerons en détail plus tard.
2. Avantages et inconvénients de l'index
L'une des significations de l'existence de la base de données est de résoudre le stockage des données et la recherche rapide. Alors, où se trouvent les données de la base de données ? C'est vrai, c'est un disque. Quels sont les avantages d'un disque ? Bon marché! Et les inconvénients ? Plus lent que l'accès à la mémoire.
Alors, connaissez-vous la structure de données principalement utilisée par les index MySQL ?
Arbre B+ ! lâchez-vous.
Quel type de structure de données est l'arbre B+ ? Pourquoi MySQL a-t-il choisi l'arbre B+ pour l'index ?
En fait, le choix final de l'arbre B+ a connu une longue évolution :
Arbre de tri binaire→ Arbre binaire équilibré → B-Tree (arbre B) → B+Tree (arbre B+)
Un ami m'a demandé "Quelle est la différence entre B-tree et Arbre B" " ? Pour généraliser ici, les structures de données MySQL n'ont que B-Tree (arbre B) et B+Tree (arbre B+). La plupart d'entre elles sont simplement des prononciations différentes. "B-Tree" est généralement appelé B-tree. B-tree. ~~
Et l'arbre rouge-noir mentionné par des amis est une structure de stockage dans un langage de programmation, pas MySQL, par exemple, HashMap de Java utilise une liste chaînée plus un arbre rouge-noir.
D'accord, aujourd'hui, je vais vous guider à travers le processus d'évolution vers un arbre B+.
Avant de comprendre l'arbre B+, parlons brièvement de l'arbre de tri binaire. left La valeur du nœud enfant du sous-arbre doit être plus petite que lui-même, et la valeur du nœud enfant de son sous-arbre droit doit être supérieure à lui-même. Si tous les nœuds remplissent cette condition, alors il s'agit d'un arbre trié binaire. (Ici, vous pouvez regrouper les points de connaissance de la recherche binaire) 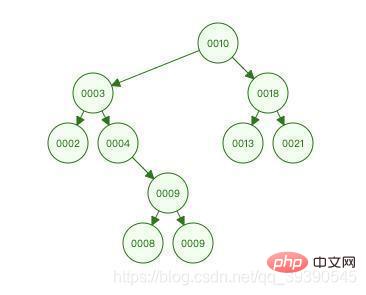
L'image ci-dessus est un arbre de tri binaire. Vous pouvez essayer d'utiliser ses caractéristiques pour expérimenter le processus de recherche de 9 : <.>
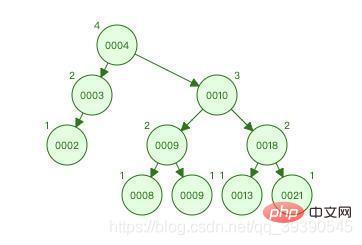
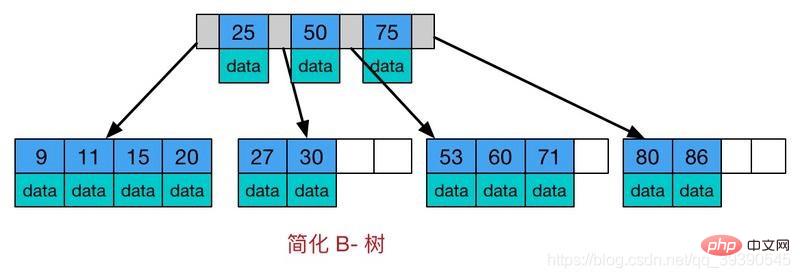
Les caractéristiques du B-tree :
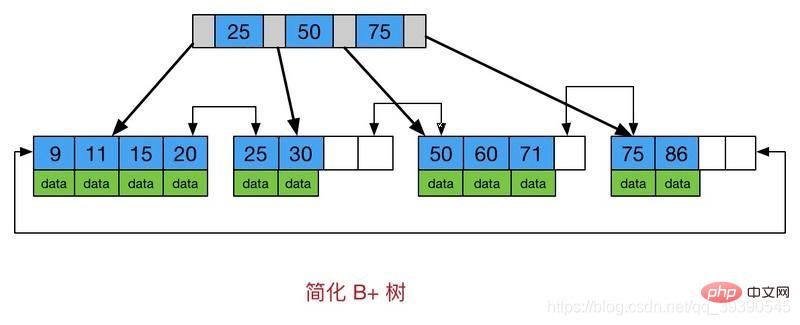
Ce que vous devez savoir, c'est qu'à chaque fois vous créez une table, le système créera automatiquement un index clusterisé basé sur l'ID (l'arborescence B+ ci-dessus) pour que vous puissiez stocker toutes les données ; chaque fois que vous ajoutez un index, la base de données créera un index supplémentaire pour vous (l'arborescence B+ ci-dessus) ), et le nombre de champs sélectionnés par l'index est chacun Le nombre d'index de données de stockage de nœuds. Notez que cet index ne stocke pas toutes les données.
Par exemple, si vous créez un nom, un index d'âge name_age_index, interrogez des données. Lors de l'utilisation de
select * from table where name ='陈哈哈' and age = 26; 1复制代码
Comme il n'y a que le nom et l'âge dans l'index supplémentaire, après avoir atteint l'index, la base de données doit revenir à l'index clusterisé pour trouver d'autres données. Il s'agit d'un retour de table, et c'est ce que vous faites. mémoriser : utiliser moins La raison de la sélection *.
sera mieux comprise lorsqu'elle sera combinée avec les retours de table. Par exemple, dans l'index name_age_index ci-dessus, il y a une requête
select name, age from table where name ='陈哈哈' and age = 26; 1复制代码
À ce moment, le nom du champ sélectionné, l'âge est dans l'index name_age_index peut être obtenu, il n'est donc pas nécessaire de revenir à la table, la couverture de l'index est satisfaite et les données de l'index sont renvoyées directement, ce qui est très efficace. Il s’agit de la méthode d’optimisation préférée des étudiants DBA lors de l’optimisation.
L'ordre d'index de stockage des nœuds de l'arbre B+ est stocké de gauche à droite lors de la correspondance, il est naturel de satisfaire la correspondance de gauche à droite ; Habituellement, lorsque nous construisons une indexation conjointe, c'est-à-dire l'indexation de plusieurs champs, je pense que les étudiants qui ont établi des index constateront qu'Oracle et MySQL nous permettent de choisir l'ordre de l'index. Par exemple, nous voulons indexer les trois champs a. , b et c. Pour créer un index commun, nous pouvons choisir la priorité que nous voulons, a, b, c ou b, a, c ou c, a, b, etc. Pourquoi la base de données nous laisse-t-elle choisir l'ordre des champs ? Ne sont-ils pas tous des index conjoints de trois champs ? Cela nous amène au principe du préfixe le plus à gauche des index de bases de données.
Dans notre développement, nous rencontrons souvent le problème qu'un index conjoint est construit pour ce champ, mais l'index n'est pas utilisé lorsque SQL interroge ce champ. Par exemple, l'index abc_index : (a, b, c) est un index conjoint des trois champs a, b, c. Lorsque le sql suivant est exécuté, l'index abc_index ne peut pas être atteint ; Les trois situations suivantes utiliseront l'index :
select * from table where c = '1'; select * from table where b ='1' and c ='2'; 123复制代码
Avez-vous des indices à partir des deux exemples ci-dessus ?
Oui, l'index abc_index : (a,b,c) ne sera utilisé que dans trois types de requêtes : (a), (a,b) et (a,b,c). En fait, il y a un peu d'ambiguïté ici. En fait, (a,c) sera également utilisé, mais seul l'index du champ a sera utilisé, et le champ c ne sera pas utilisé.
De plus, il existe un cas particulier Dans le type suivant, seuls a et b seront indexés, et c ne sera pas indexé.
select * from table where a = '1'; select * from table where a = '1' and b = '2'; select * from table where a = '1' and b = '2' and c='3'; 12345复制代码
Pour les instructions SQL du type ci-dessus, une fois a et b indexés, c est déjà dans le désordre, donc c ne peut pas être indexé, et l'optimiseur pensera que ce n'est pas aussi bon que l'index complet du champ c d'analyse de table arrive rapidement.
**Préfixe le plus à gauche : comme son nom l'indique, cela signifie la priorité la plus à gauche. Dans l'exemple ci-dessus, nous avons créé un index multi-colonnes a_b_c, ce qui équivaut à créer (a) un index à colonne unique et (). a,b) indice combiné. Et (a,b,c) indice combiné. **
Par conséquent, lors de la création d'un index multi-colonnes, en fonction des besoins de l'entreprise, la colonne la plus fréquemment utilisée dans la clause Where est placée à l'extrême gauche.
4. Optimisation du pushdown d'index
select * from table where a = '1' and b > '2' and c='3'; 1复制代码
Cette instruction a deux possibilités d'exécution :
hit L'index conjoint name_age_index interroge toutes les données qui satisfont au nom commençant par « 陈 », puis retourne à la table pour interroger toutes les lignes satisfaisantes.6. Précautions lors de l'utilisation des index
对串列进行索引,如果可能应该指定一个前缀长度。例如,如果有一个char(255)的列,如果在前10个或20个字符内,多数值是惟一的,那么就不要对整个列进行索引。短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作。
查询只使用一个索引,因此如果where子句中已经使用了索引的话,那么order by中的列是不会使用索引的。因此数据库默认排序可以符合要求的情况下不要使用排序操作;尽量不要包含多个列的排序,如果需要最好给这些列创建复合索引。
一般情况下不推荐使用like操作,如果非使用不可,如何使用也是一个问题。like “%陈%” 不会使用索引而like “陈%”可以使用索引。
这将导致索引失效而进行全表扫描,例如
SELECT * FROM table_name WHERE YEAR(column_name)<h2 data-id="heading-21">6、不使用not in和操作</h2><p>这不属于支持的范围查询条件,不会使用索引。</p><h1 data-id="heading-22">我的体会</h1><p> 曾经,我一度以为我很懂MySQL。</p><p> 刚入职那年,我还是个孩子,记得第一个需求是做个统计接口,查询近两小时每隔5分钟为一时间段的网站访问量,JSONArray中一共返回24个值,当时菜啊,写了个接口循环二十四遍,发送24条SQL去查(捂脸),由于那个接口,被技术经理嘲讽~~表示他写的SQL比我吃的米都多。虽然我们山东人基本不吃米饭,但我还是羞愧不已。。<br>然后经理通过调用一个dateTime函数分组查询处理一下,就ok了,效率是我的几十倍吧。从那时起,我就定下目标,深入MySQL学习,万一日后有机会嘲讽回去?</p><p> 筒子们,MySQL路漫漫,其修远兮。永远不要眼高手低,一起加油,希望本文能对你有所帮助。</p>
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Index MySQL
Index MySQL
 Comment télécharger Binance
Comment télécharger Binance
 Comment faire des captures d'écran sur Huawei mate60pro
Comment faire des captures d'écran sur Huawei mate60pro
 Que faire si le post-scriptum ne peut pas être analysé
Que faire si le post-scriptum ne peut pas être analysé
 Que diriez-vous de l'échange MEX
Que diriez-vous de l'échange MEX
 saut de ligne forcé de mot
saut de ligne forcé de mot
 Codes hexadécimaux de couleur courants
Codes hexadécimaux de couleur courants
 Système OA définitivement gratuit
Système OA définitivement gratuit
 Comment résoudre dns_probe_possible
Comment résoudre dns_probe_possible










![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



