

La colonne

En fait, un autre sujet très important du multi-threading Python s'appelle, GIL (Global Interpreter Lock, c'est-à-dire, l'interpréteur global Lock).
En Python, le multitâche peut être réalisé grâce à plusieurs processus, multi-threads et multi-coroutines. Le multi-threading est-il nécessairement plus rapide que le mono-threading ?
Ci-dessous, j'utilise un morceau de code pour prouver mon point de vue.
'''
@Author: Runsen
@微信公众号: Python之王
@博客: https://blog.csdn.net/weixin_44510615
@Date: 2020/6/4
'''import threading, timedef my_counter():
i = 0
for _ in range(100000000):
i = i+1
return Truedef main1():
start_time = time.time() for tid in range(2):
t = threading.Thread(target=my_counter)
t.start()
t.join() # 第一次循环的时候join方法引起主线程阻塞,但第二个线程并没有启动,所以两个线程是顺序执行的
print("单线程顺序执行total_time: {}".format(time.time() - start_time))def main2():
thread_ary = {}
start_time = time.time() for tid in range(2):
t = threading.Thread(target=my_counter)
t.start()
thread_ary[tid] = t for i in range(2):
thread_ary[i].join() # 两个线程均已启动,所以两个线程是并发的
print("多线程执行total_time: {}".format(time.time() - start_time))if __name__ == "__main__":
main1()
main2()复制代码Exécuter les résultats
单线程顺序执行total_time: 17.754502773284912多线程执行total_time: 20.01178550720215复制代码
J'ai peur que vous disiez que j'ai obtenu des résultats aléatoires, donc je ferais mieux de prendre une capture d'écran pour voir clairement

À ce moment-là, je me demandais : y a-t-il un problème avec ma machine ? En fait, ce n'est pas le cas, les threads de Python ont échoué et ne jouent aucun rôle dans le calcul parallèle.
Le thread de Python encapsule le thread du système d'exploitation sous-jacent. Dans le système Linux, il s'agit de Pthread (nom complet : POSIX Thread), et dans le système Windows, il s'agit de Windows Thread. De plus, les threads de Python sont entièrement gérés par le système d'exploitation, comme la coordination du moment d'exécution, la gestion des ressources mémoire, la gestion des interruptions, etc.
Le concept de GIL peut être expliqué dans une phrase simple, c'est-à-direA tout moment, quel que soit le nombre de threads, un seul L'interpréteur CPython ne peut exécuter qu'un seul octet de code . Points à noter sur cette définition :
La première chose à préciser est que GIL n'est pas une fonctionnalité de Python , c'est un concept introduit lors de l'implémentation de l'analyseur Python (CPython ).
C++ est un ensemble de normes de langage (grammaire), mais il peut être compilé en code exécutable à l'aide de différents compilateurs. Compilateurs célèbres tels que GCC, INTEL C++, Visual C++, etc.
Il en va de même pour Python. Le même morceau de code peut être exécuté via différents environnements d'exécution Python tels que CPython, PyPy et Psyco.
Les autres interpréteurs Python peuvent ne pas avoir de GIL. Par exemple, Jython (JVM) et IronPython (CLR) n'ont pas de GIL, tandis que CPython et PyPy ont GIL
Parce que CPython est l'environnement d'exécution Python par défaut dans la plupart des environnements. Par conséquent, pour beaucoup de gens, CPython est Python, et ils tiennent pour acquis que GIL est un défaut du langage Python. Alors soyons clairs ici : GIL n'est pas une fonctionnalité de Python. Python n'a pas du tout besoin de s'appuyer sur GIL
L'essence de GIL est qu'un verrou mutex étant un verrou mutex, l'essence de tous les verrous mutex est la même. Ils transforment les opérations simultanées en opérations en série, contrôlant ainsi que les données partagées ne peuvent être modifiées que par une seule tâche à la fois. garantissant ainsi la sécurité des données.
Une chose est sûre : pour protéger la sécurité des différentes données, différents verrous doivent être ajoutés.
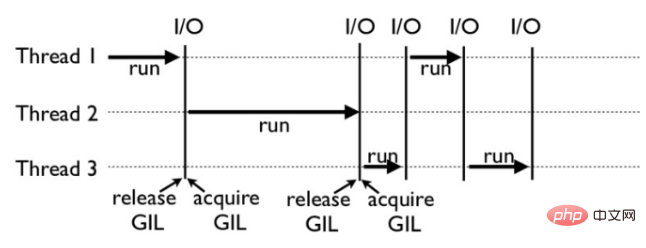
Comment fonctionne GIL : Par exemple, l'image ci-dessous est un exemple du fonctionnement de GIL dans un programme Python. Parmi eux, les threads 1, 2 et 3 sont exécutés à tour de rôle. Lorsque chaque thread démarre l'exécution, il verrouille le GIL pour empêcher les autres threads de s'exécuter de la même manière, une fois que chaque thread a terminé son exécution pendant un certain temps, il libère le GIL ; permettre à d'autres threads de s'exécuter. Le thread commence à utiliser des ressources.
Les tâches gourmandes en informatique se caractérisent par la nécessité d'une grande quantité de calculs et la consommation de ressources CPU.
Regardons d'abord un exemple simple nécessitant beaucoup de calculs :
'''
@Author: Runsen
@微信公众号: Python之王
@博客: https://blog.csdn.net/weixin_44510615
@Date: 2020/6/4
'''import time
COUNT = 50_000_000def count_down():
global COUNT while COUNT > 0:
COUNT -= 1s = time.perf_counter()
count_down()
c = time.perf_counter() - s
print('time taken in seconds - >:', c)
time taken in seconds - >: 9.2957003复制代码Il s'agit d'un seul thread, et le temps est de 9 s. Utilisons deux threads pour voir quel est le résultat :
'''
@Author: Runsen
@微信公众号: Python之王
@博客: https://blog.csdn.net/weixin_44510615
@Date: 2020/6/4
'''import timefrom threading import Thread
COUNT = 50_000_000def count_down():
global COUNT while COUNT > 0:
COUNT -= 1s = time.perf_counter()
t1 = Thread(target=count_down)
t2 = Thread(target=count_down)
t1.start()
t2.start()
t1.join()
t2.join()
c = time.perf_counter() - s
print('time taken in seconds - >:', c)
time taken in seconds - >: 17.110625复制代码L'opération principale de notre programme est le calcul.Le CPU n'attend pas.Après le passage au multi-thread, après l'ajout de threads, les commutations fréquentes entre les threads augmentent bien sûr le temps.
Il existe un autre type qui est gourmand en E/S. Les tâches impliquant des E/S réseau et disque sont toutes des tâches gourmandes en E/S. La caractéristique de ce type de tâche est que la consommation du processeur est très faible et la plupart des tâches. le temps attend les IO. L'opération est terminée (car la vitesse des IO est bien inférieure à la vitesse du CPU et de la mémoire). Pour les tâches gourmandes en E/S, plus il y a de tâches, plus l'efficacité du processeur est élevée, mais il y a une limite. Les tâches les plus courantes sont les tâches gourmandes en E/S, telles que les applications Web.
Résumé : Pour les travaux intensifs en io (crawler Python), le multithreading peut grandement améliorer l'efficacité du code. Pour le calcul gourmand en CPU (analyse de données Python, apprentissage automatique, apprentissage profond), le multithreading peut être légèrement moins efficace que le monothreading. Par conséquent, le multithreading n'existe pas pour améliorer l'efficacité dans le domaine des données. La seule façon d'améliorer la puissance de calcul est de mettre à niveau le CPU vers le GPU et le TPU.
Recommandations d'apprentissage gratuites associées : Tutoriel vidéo Python
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Quelle langue est le langage C ?
Quelle langue est le langage C ?
 Il n'y a pas d'option WLAN dans Win11
Il n'y a pas d'option WLAN dans Win11
 utilisation de la commande telnet
utilisation de la commande telnet
 Quelles sont les différences entre le pool de threads Spring et le pool de threads JDK ?
Quelles sont les différences entre le pool de threads Spring et le pool de threads JDK ?
 Balises HTML courantes
Balises HTML courantes
 Site officiel d'Okex
Site officiel d'Okex
 Plateforme nationale de monnaie numérique
Plateforme nationale de monnaie numérique
 Quelle est la fonction du diviseur de fréquence
Quelle est la fonction du diviseur de fréquence










![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



