

Comment créer un modèle d'IA de base avec TensorFlow.js ?


Dans cet article, nous voyons comment utiliser TensorFlow.js pour créer des modèles d'IA de base et utiliser des modèles plus complexes pour implémenter des fonctions intéressantes. Je viens de commencer à entrer en contact avec l'intelligence artificielle. Même si une connaissance approfondie de l'intelligence artificielle n'est pas requise, j'ai encore besoin de comprendre certains concepts.
Qu'est-ce qu'un modèle ?
Le monde réel est très complexe, et nous devons le simplifier pour le comprendre. Nous pouvons le simplifier grâce à des modèles. Il existe de nombreux types de modèles : comme des cartes du monde, ou des graphiques, etc.

Par exemple, si vous souhaitez construire un modèle pour exprimer la relation entre le prix de location d'une maison et la superficie de la maison : Tout d'abord, vous devez collecter quelques données :
| 房间数量 | 价格 |
|---|---|
| 3 | 131000 |
| 3 | 125000 |
| 4 | 235000 |
| 4 | 265000 |
| 5 | 535000 |
Ensuite, affichez ces données sur un graphique bidimensionnel, et traitez chaque paramètre (prix, nombre de chambres) comme 1 dimension :
Ensuite, nous pouvons dessiner un ligne et prédire le prix de location d’une maison avec plus de pièces. Ce modèle est appelé régression linéaire et constitue l’un des modèles les plus simples de l’apprentissage automatique. Mais ce modèle n'est pas assez bon :
- Il n'y a que 5 données, donc il n'est pas assez fiable.
- Il n'y a que 2 paramètres (prix, chambre), mais il y a d'autres facteurs qui peuvent affecter le prix : comme la superficie, la décoration, etc.
Le premier problème peut être résolu en ajoutant plus de données, disons un million. Pour la deuxième question, davantage de dimensions peuvent être ajoutées. Dans un graphique 2D il est facile de comprendre les données et de tracer une ligne, dans un graphique 3D vous pouvez utiliser un plan :

Mais qu'en est-il lorsque les dimensions des données sont 3D, 4D ou même 1 000 000. Lorsque la dimension dépasse trois dimensions, le cerveau n'a aucun moyen de la visualiser sur un graphique, mais l'hyperplan peut être calculé mathématiquement lorsque la dimension dépasse trois dimensions, et les réseaux de neurones sont nés pour résoudre ce problème.
Qu'est-ce qu'un réseau de neurones ?
Pour comprendre ce qu'est un réseau de neurones, il faut savoir ce qu'est un neurone. Un vrai neurone ressemble à ceci :

Un neurone est composé des parties suivantes :
- Dendrites : C'est l’extrémité d’entrée des données.
- Axon : C'est l'extrémité de sortie.
- Synapse (non représentée sur le schéma) : Cette structure permet la communication entre un neurone et un autre. Il est responsable de la transmission des signaux électriques entre les terminaisons nerveuses des axones et les dendrites des neurones voisins. Ces synapses sont essentielles à l’apprentissage car elles augmentent ou diminuent l’activité électrique en fonction de leur utilisation.
Neurones en machine learning (simplifié) :

- Inputs (input) : paramètre d'entrée.
- Poids : Comme les synapses, utilisés pour mieux établir une régression linéaire en régulant les neurones.
- Fonction linéaire (fonction linéaire) : Chaque neurone est comme une fonction de régression linéaire. Pour un modèle de régression linéaire, un seul neurone suffit.
- Fonction d'activation : Certaines fonctions d'activation peuvent être utilisées pour changer la sortie d'une fonction scalaire à une autre fonction non linéaire. Les plus courants sont sigmoïde, RELU et tanh.
- Sortie : La sortie calculée après application de la fonction d'activation.
Les fonctions d'activation sont très utiles, et on leur attribue principalement la puissance des réseaux de neurones. Sans aucune fonction d’activation, il est impossible d’obtenir un réseau de neurones intelligent. Parce que même si vous avez plusieurs neurones dans votre réseau neuronal, le résultat de votre réseau neuronal sera toujours une régression linéaire. Par conséquent, un mécanisme est nécessaire pour transformer chaque régression linéaire en non linéaire afin de résoudre des problèmes non linéaires. Ces fonctions linéaires peuvent être converties en fonctions non linéaires grâce à des fonctions d'activation :

Entraînement du modèle
Comme décrit dans l'exemple de régression linéaire 2D, tracez simplement une ligne dans le graphique pour prédire de nouvelles données. Pourtant, l’idée du « deep learning » est de faire en sorte que notre réseau neuronal apprenne à tracer cette ligne. Pour une ligne simple, vous pouvez utiliser un réseau neuronal très simple avec un seul neurone, mais pour un modèle qui souhaite faire des choses plus complexes, comme classer deux ensembles de données, le réseau doit être « entraîné ». ce qui suit :

Le processus n'est pas compliqué puisqu'il est en 2D. Chaque modèle est utilisé pour décrire un monde, mais le concept de « formation » est très similaire dans tous les modèles. La première étape consiste à tracer une ligne aléatoire et à l’améliorer de manière itérative dans l’algorithme, en corrigeant les erreurs du processus à chaque itération. Cet algorithme d'optimisation est appelé Gradient Descent (les algorithmes avec le même concept sont aussi plus complexes SGD ou ADAM, etc.). Chaque algorithme (régression linéaire, régression logarithmique, etc.) a une fonction de coût différente pour mesurer l'erreur, et la fonction de coût convergera toujours vers un certain point. Il peut être convexe ou concave, mais il finira par converger vers un point avec une erreur de 0 %. Notre objectif est d’y parvenir.

Lorsque vous utilisez l'algorithme de descente de gradient, vous partez d'un point aléatoire dans sa fonction de coût, mais nous ne savons pas exactement où il se trouve ! C'est comme avoir les yeux bandés et être jeté sur une montagne. Si vous voulez descendre la montagne, vous devez vous rendre pas à pas jusqu'au point le plus bas. Si le terrain est irrégulier (comme une fonction concave), la descente sera plus compliquée.
L'algorithme "Gradient Descent" ne sera pas expliqué en profondeur ici. Il suffit de rappeler qu'il s'agit d'un algorithme d'optimisation permettant de minimiser les erreurs de prédiction lors de l'entraînement des modèles d'IA. Cet algorithme nécessite beaucoup de temps et de GPU pour la multiplication matricielle. Il est généralement difficile d'atteindre ce point de convergence dès la première exécution, donc certains hyperparamètres doivent être modifiés, comme le taux d'apprentissage ou l'ajout de régularisation. Après les itérations de descente de gradient, le point de convergence est approché lorsque l'erreur s'approche de 0 %. Cela crée un modèle qui peut ensuite être utilisé pour faire des prédictions.

Entraîner des modèles avec TensorFlow.js
TensorFlow.js fournit un moyen simple de créer des réseaux de neurones. Créez d’abord une classe trainModel avec la méthode LinearModel. Nous utiliserons un modèle séquentiel. Un modèle séquentiel est un modèle dans lequel la sortie d'une couche est l'entrée de la couche suivante, c'est-à-dire lorsque la topologie du modèle est une hiérarchie simple sans branches ni sauts. Définissez les couches à l'intérieur de la méthode trainModel (nous n'utilisons qu'une seule couche car elle suffit pour résoudre le problème de régression linéaire) :
import * as tf from '@tensorflow/tfjs';
/**
* 线性模型类
*/
export default class LinearModel {
/**
* 训练模型
*/
async trainModel(xs, ys){
const layers = tf.layers.dense({
units: 1, // 输出空间的纬度
inputShape: [1], // 只有一个参数
});
const lossAndOptimizer = {
loss: 'meanSquaredError',
optimizer: 'sgd', // 随机梯度下降
};
this.linearModel = tf.sequential();
this.linearModel.add(layers); // 添加一层
this.linearModel.compile(lossAndOptimizer);
// 开始模型训练
await this.linearModel.fit(
tf.tensor1d(xs),
tf.tensor1d(ys),
);
}
//...
}Utiliser cette classe pour l'entraînement :
const model = new LinearModel() // xs 与 ys 是 数组成员(x-axis 与 y-axis) await model.trainModel(xs, ys)
Une fois l'entraînement est terminé, vous pouvez démarrer Predicted.
Prédiction avec TensorFlow.js
Bien que vous deviez définir certains hyperparamètres au préalable lors de l'entraînement du modèle, faire des prédictions générales reste facile. Il suffit de passer le code suivant :
import * as tf from '@tensorflow/tfjs';
export default class LinearModel {
... //前面训练模型的代码
predict(value){
return Array.from(
this.linearModel
.predict(tf.tensor2d([value], [1, 1]))
.dataSync()
)
}
}Vous pouvez désormais prédire :
const prediction = model.predict(500) // 预测数字 500 console.log(prediction) // => 420.423
Utilisez le modèle pré-entraîné dans TensorFlow.js
La formation du modèle est la partie la plus difficile. Premièrement, les données sont standardisées pour la formation et tous les hyperparamètres doivent être définis correctement, etc. Pour nous, débutants, nous pouvons directement utiliser ces modèles pré-entraînés. TensorFlow.js peut utiliser de nombreux modèles pré-entraînés et peut également importer des modèles externes créés avec TensorFlow ou Keras. Par exemple, vous pouvez directement utiliser le modèle posenet (évaluation de la posture humaine en temps réel) pour réaliser des projets intéressants :
Le code de cette Démo : https://github .com/aralroca/posenet- d3
C'est facile à utiliser :
import * as posenet from '@tensorflow-models/posenet' // 设置一些常数 const imageScaleFactor = 0.5 const outputStride = 16 const flipHorizontal = true const weight = 0.5 // 加载模型 const net = await posenet.load(weight) // 进行预测 const poses = await net.estimateSinglePose( imageElement, imageScaleFactor, flipHorizontal, outputStride )
Ce JSON est une pose variable :
{
"score": 0.32371445304906,
"keypoints": [
{
"position": {
"y": 76.291801452637,
"x": 253.36747741699
},
"part": "nose",
"score": 0.99539834260941
},
{
"position": {
"y": 71.10383605957,
"x": 253.54365539551
},
"part": "leftEye",
"score": 0.98781454563141
}
// 后面还有: rightEye, leftEar, rightEar, leftShoulder, rightShoulder
// leftElbow, rightElbow, leftWrist, rightWrist, leftHip, rightHip,
// leftKnee, rightKnee, leftAnkle, rightAnkle...
]
}Vous pouvez le voir à partir de la démo officielle, en utilisant ce modèle Il existe de nombreux projets intéressants qui peuvent être développés.
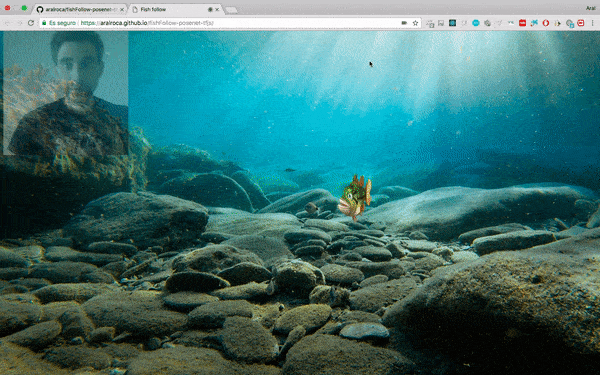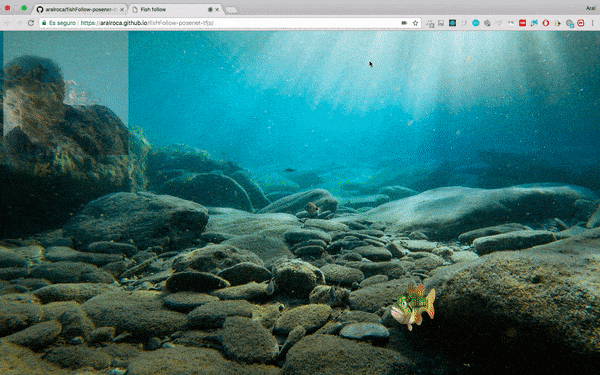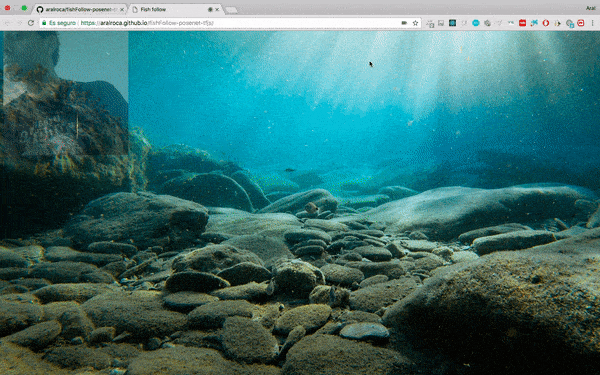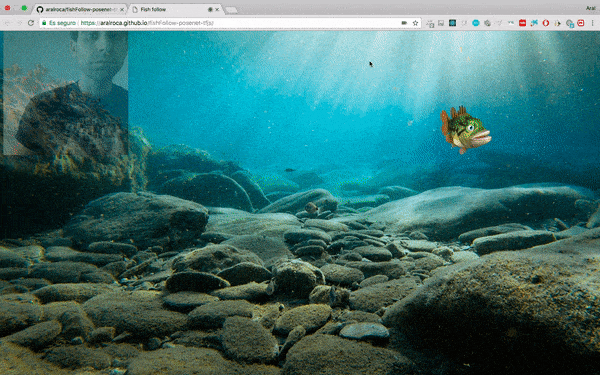
Code source de ce projet : https://github.com/aralroca/fishFollow-posenet-tfjs
Importer le modèle Keras
Les modèles externes peuvent être importés dans TensorFlow.js. Vous trouverez ci-dessous un programme de reconnaissance de nombres utilisant le modèle Keras (format h5). Tout d'abord, utilisez tfjs_converter pour convertir le format du modèle.
pip install tensorflowjs
Utilisez le convertisseur :
tensorflowjs_converter --input_format keras keras/cnn.h5 src/assets
Enfin, importez le modèle dans le code JS :
// 载入模型
const model = await tf.loadModel('./assets/model.json')
// 准备图片
let img = tf.fromPixels(imageData, 1)
img = img.reshape([1, 28, 28, 1])
img = tf.cast(img, 'float32')
// 进行预测
const output = model.predict(img)Cela ne prend que quelques lignes de code pour le compléter. Bien sûr, vous pouvez ajouter plus de logique au code pour obtenir plus de fonctions. Par exemple, vous pouvez écrire des nombres sur un canevas, puis obtenir leurs images à des fins de prédiction.

Code source de ce projet : https://github.com/aralroca/MNIST_React_TensorFlowJS
Pourquoi devrait-il être utilisé dans le navigateur ?
En raison des différents appareils, l'efficacité peut être très faible lors de l'entraînement du modèle dans le navigateur. L'utilisation de TensorFlow.js pour utiliser WebGL afin d'entraîner le modèle en arrière-plan est 1,5 à 2 fois plus lente que l'utilisation de la version Python de TensorFlow.
Mais avant l'émergence de TensorFlow.js, il n'existait pas d'API permettant d'utiliser les modèles d'apprentissage automatique directement dans le navigateur. Désormais, les modèles peuvent être entraînés et utilisés hors ligne dans les applications du navigateur. Et les prédictions sont plus rapides car il n’y a aucune requête adressée au serveur. Un autre avantage est le faible coût puisque tous ces calculs sont effectués côté client.
Résumé
- Un modèle est une manière simplifiée de représenter le monde réel et peut être utilisé pour faire des prédictions.
- Des modèles peuvent être créés à l'aide de réseaux de neurones.
- TensorFlow.js est un outil simple pour créer des réseaux de neurones.
Adresse originale en anglais : https://aralroca.com/blog/first-steps-with-tensorflowjs
Auteur : Aral Roca
Pour plus de connaissances liées à la programmation, veuillez visiter : Cours de programmation ! !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 WebSocket et JavaScript : technologies clés pour mettre en œuvre des systèmes de surveillance en temps réel
Dec 17, 2023 pm 05:30 PM
WebSocket et JavaScript : technologies clés pour mettre en œuvre des systèmes de surveillance en temps réel
Dec 17, 2023 pm 05:30 PM
WebSocket et JavaScript : technologies clés pour réaliser des systèmes de surveillance en temps réel Introduction : Avec le développement rapide de la technologie Internet, les systèmes de surveillance en temps réel ont été largement utilisés dans divers domaines. L'une des technologies clés pour réaliser une surveillance en temps réel est la combinaison de WebSocket et de JavaScript. Cet article présentera l'application de WebSocket et JavaScript dans les systèmes de surveillance en temps réel, donnera des exemples de code et expliquera leurs principes de mise en œuvre en détail. 1. Technologie WebSocket
 PHP et Vue : une combinaison parfaite d'outils de développement front-end
Mar 16, 2024 pm 12:09 PM
PHP et Vue : une combinaison parfaite d'outils de développement front-end
Mar 16, 2024 pm 12:09 PM
PHP et Vue : une combinaison parfaite d'outils de développement front-end À l'ère actuelle de développement rapide d'Internet, le développement front-end est devenu de plus en plus important. Alors que les utilisateurs ont des exigences de plus en plus élevées en matière d’expérience des sites Web et des applications, les développeurs front-end doivent utiliser des outils plus efficaces et plus flexibles pour créer des interfaces réactives et interactives. En tant que deux technologies importantes dans le domaine du développement front-end, PHP et Vue.js peuvent être considérés comme une arme parfaite lorsqu'ils sont associés. Cet article explorera la combinaison de PHP et Vue, ainsi que des exemples de code détaillés pour aider les lecteurs à mieux comprendre et appliquer ces deux éléments.
 Questions fréquemment posées par les enquêteurs front-end
Mar 19, 2024 pm 02:24 PM
Questions fréquemment posées par les enquêteurs front-end
Mar 19, 2024 pm 02:24 PM
Lors des entretiens de développement front-end, les questions courantes couvrent un large éventail de sujets, notamment les bases HTML/CSS, les bases JavaScript, les frameworks et les bibliothèques, l'expérience du projet, les algorithmes et les structures de données, l'optimisation des performances, les requêtes inter-domaines, l'ingénierie front-end, les modèles de conception et les nouvelles technologies et tendances. Les questions de l'intervieweur sont conçues pour évaluer les compétences techniques du candidat, son expérience en matière de projet et sa compréhension des tendances du secteur. Par conséquent, les candidats doivent être parfaitement préparés dans ces domaines pour démontrer leurs capacités et leur expertise.
 JavaScript et WebSocket : créer un système efficace de prévisions météorologiques en temps réel
Dec 17, 2023 pm 05:13 PM
JavaScript et WebSocket : créer un système efficace de prévisions météorologiques en temps réel
Dec 17, 2023 pm 05:13 PM
JavaScript et WebSocket : Construire un système efficace de prévisions météorologiques en temps réel Introduction : Aujourd'hui, la précision des prévisions météorologiques revêt une grande importance pour la vie quotidienne et la prise de décision. À mesure que la technologie évolue, nous pouvons fournir des prévisions météorologiques plus précises et plus fiables en obtenant des données météorologiques en temps réel. Dans cet article, nous apprendrons comment utiliser la technologie JavaScript et WebSocket pour créer un système efficace de prévisions météorologiques en temps réel. Cet article démontrera le processus de mise en œuvre à travers des exemples de code spécifiques. Nous
 Tutoriel JavaScript simple : Comment obtenir le code d'état HTTP
Jan 05, 2024 pm 06:08 PM
Tutoriel JavaScript simple : Comment obtenir le code d'état HTTP
Jan 05, 2024 pm 06:08 PM
Tutoriel JavaScript : Comment obtenir le code d'état HTTP, des exemples de code spécifiques sont requis Préface : Dans le développement Web, l'interaction des données avec le serveur est souvent impliquée. Lors de la communication avec le serveur, nous devons souvent obtenir le code d'état HTTP renvoyé pour déterminer si l'opération a réussi et effectuer le traitement correspondant en fonction de différents codes d'état. Cet article vous apprendra comment utiliser JavaScript pour obtenir des codes d'état HTTP et fournira quelques exemples de codes pratiques. Utilisation de XMLHttpRequest
 Django est-il front-end ou back-end ? Vérifiez-le!
Jan 19, 2024 am 08:37 AM
Django est-il front-end ou back-end ? Vérifiez-le!
Jan 19, 2024 am 08:37 AM
Django est un framework d'application Web écrit en Python qui met l'accent sur un développement rapide et des méthodes propres. Bien que Django soit un framework Web, pour répondre à la question de savoir si Django est un front-end ou un back-end, vous devez avoir une compréhension approfondie des concepts de front-end et de back-end. Le front-end fait référence à l'interface avec laquelle les utilisateurs interagissent directement, et le back-end fait référence aux programmes côté serveur. Ils interagissent avec les données via le protocole HTTP. Lorsque le front-end et le back-end sont séparés, les programmes front-end et back-end peuvent être développés indépendamment pour mettre en œuvre respectivement la logique métier et les effets interactifs, ainsi que l'échange de données.
 Explorer la technologie front-end du langage Go : une nouvelle vision du développement front-end
Mar 28, 2024 pm 01:06 PM
Explorer la technologie front-end du langage Go : une nouvelle vision du développement front-end
Mar 28, 2024 pm 01:06 PM
En tant que langage de programmation rapide et efficace, le langage Go est très populaire dans le domaine du développement back-end. Cependant, peu de gens associent le langage Go au développement front-end. En fait, l’utilisation du langage Go pour le développement front-end peut non seulement améliorer l’efficacité, mais également ouvrir de nouveaux horizons aux développeurs. Cet article explorera la possibilité d'utiliser le langage Go pour le développement front-end et fournira des exemples de code spécifiques pour aider les lecteurs à mieux comprendre ce domaine. Dans le développement front-end traditionnel, JavaScript, HTML et CSS sont souvent utilisés pour créer des interfaces utilisateur.
 Django : Un framework magique capable de gérer à la fois le développement front-end et back-end !
Jan 19, 2024 am 08:52 AM
Django : Un framework magique capable de gérer à la fois le développement front-end et back-end !
Jan 19, 2024 am 08:52 AM
Django : Un framework magique capable de gérer à la fois le développement front-end et back-end ! Django est un framework d'application Web efficace et évolutif. Il est capable de prendre en charge plusieurs modèles de développement Web, notamment MVC et MTV, et peut facilement développer des applications Web de haute qualité. Django prend non seulement en charge le développement back-end, mais peut également créer rapidement des interfaces frontales et obtenir un affichage de vue flexible via un langage de modèle. Django combine le développement front-end et le développement back-end dans une intégration transparente, afin que les développeurs n'aient pas à se spécialiser dans l'apprentissage.
