

La fonction de jointure de MySQL est-elle trop faible ?

La colonne tutoriel mysql d'aujourd'hui présente la fonction de jointure.

Concernant la jointure MySQL, vous devez connaître beaucoup d'"anecdotes" à ce sujet. Par exemple, la jointure à deux tables nécessite une petite table pour piloter une grande table Alibaba. les spécifications du développeur en interdisent trois. Pour les opérations de jointure de plus d'une table, la fonction de jointure de MySQL est extrêmement faible, etc. Ces normes ou remarques peuvent être vraies ou fausses, parfois vraies ou parfois fausses. Vous devez avoir une compréhension approfondie de la jointure pour comprendre clairement.
Maintenant, jetons un coup d'œil complet à l'opération de jointure de MySQL.
Texte
Dans les requêtes quotidiennes de base de données, nous devons souvent effectuer des opérations de jointure sur plusieurs tables pour obtenir les données fusionnées de plusieurs tables à la fois. Cela nécessite l'utilisation de la grammaire de jointure de base de données. La jointure est une opération très courante dans le domaine des données pour fusionner deux ensembles de données. Si vous en savez plus, vous constaterez que MySQL, Oracle, PostgreSQL et Spark prennent tous en charge cette opération. Le protagoniste de cet article est MySQL S'il n'y a pas d'explication particulière ci-dessous, la jointure de MySQL sera utilisée comme sujet principal. Oracle, PostgreSQL et Spark peuvent être considérés comme les grands patrons qui les ont battus. Leur optimisation d'algorithme et leur implémentation de jointure sont meilleures que MySQL.
La jointure MySQL a de nombreuses règles. Si vous ne faites pas attention, une mauvaise instruction de jointure peut non seulement conduire à une requête complète d'une certaine table, mais aussi peut affecter le cache du. la base de données entraîne le remplacement de la plupart des données chaudes, ce qui réduit les performances de la base de données entière.
Par conséquent, l'industrie a résumé de nombreuses normes ou principes pour les jointures MySQL, telles que les petites tables pilotant de grandes tables et interdisant les opérations de jointure de plus de trois tables. Ci-dessous, nous présenterons tour à tour l'algorithme de jointure MySQL, le comparerons avec l'implémentation de jointure d'Oracle et Spark, et entrecouperons les réponses aux raisons pour lesquelles les spécifications ou principes ci-dessus sont formés.
Pour la mise en œuvre des opérations de jointure, il existe probablement trois algorithmes plus courants : Nested Loop Join (jointure imbriquée en boucle), Hash Join (jointure par hachage) et Sort Merge Join (jointure par fusion de tri), ils ont chacun leurs propres avantages, inconvénients et conditions applicables, nous les présenterons tour à tour ensuite.
Implémentation de Nested Loop Join dans MySQL
Nested Loop Join analyse la table pilote Chaque fois qu'un enregistrement est lu, les données correspondantes sont interrogées dans la table pilotée en fonction de l'index sur l'associé. champ de la jointure. Il convient aux scénarios dans lesquels le sous-ensemble de données à connecter est petit. C'est également le seul algorithme de jointure MySQL. Nous expliquerons ses détails en détail ci-dessous.
Il existe deux variantes de l'algorithme Nested Loop Join dans MySQL, à savoir Index Nested-Loop Join et Block Nested-Loop Join.
Algorithme de jointure en boucle imbriquée d'index
Ensuite, initialisons la structure et les données de la table associée
CREATE TABLE `t1` ( `id` int(11) NOT NULL, `a` int(11) DEFAULT NULL, `b` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `a` (`a`) ) ENGINE=InnoDB; delimiter ;; # 定义存储过程来初始化t1 create procedure init_data() begin declare i int; set i=1; while(i<p>Comme le montre la commande ci-dessus, les deux tables ont un Le principal ID d'index clé et un index a, il n'y a pas d'index sur le champ b. La procédure stockée init_data insère 10 000 lignes de données dans la table t1 et 500 lignes de données dans la table t2. </p><p>Afin d'empêcher l'optimiseur MySQL de sélectionner la table comme table pilote et d'affecter le processus d'exécution de l'analyse des instructions SQL, nous utilisons directement Straight_join pour permettre à MySQL d'utiliser un ordre de table de connexion fixe pour les requêtes dans ce qui suit. instruction, t1 est la table pilote, t2 est la table pilotée. </p><pre class="brush:php;toolbar:false">select * from t2 straight_join t1 on (t2.a=t1.a);复制代码
Utilisez la commande expliquer présentée dans notre article précédent pour afficher le plan d'exécution de cette instruction.
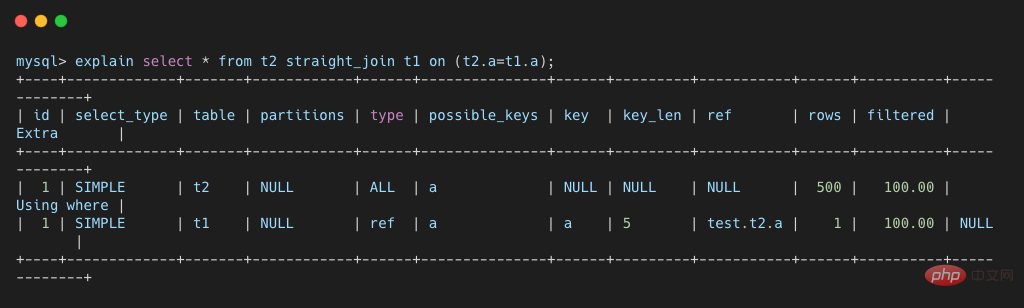
Comme vous pouvez le voir sur la figure ci-dessus, le champ a de la table t1 est indexé et l'index est utilisé dans le processus de jointure, donc le flux d'exécution du L'instruction SQL est la suivante :
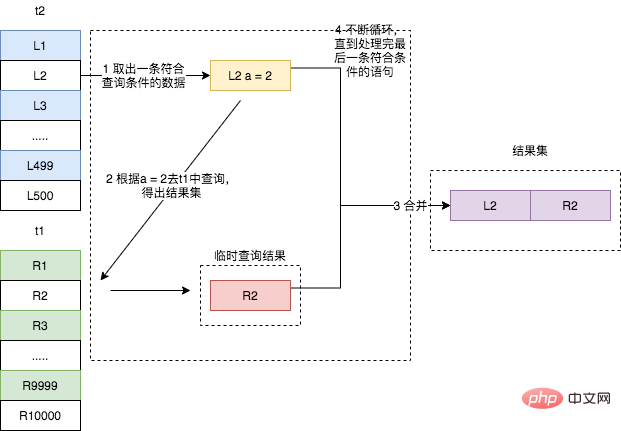
- Lire une ligne de données L1 de la table t2 ;
- Utiliser le champ a de L1 pour interroger la table t1 comme condition ; Récupérez les données qui satisfont à la condition dans t1. Les lignes conditionnelles forment les lignes correspondantes avec L1 et font partie de l'ensemble de résultats
- est exécuté à plusieurs reprises jusqu'à ce que la table t2 soit analysée.
2log2M. Évidemment, N a un plus grand impact sur le nombre de lignes analysées, donc dans ce cas, une petite table doit être utilisée comme table de pilotage.
Bien sûr, la prémisse de tout cela est que le champ de jointure associé est a, et qu'il y a un index sur le champ a de la table t1.如果没有索引时,再用上图的执行流程时,每次到 t1 去匹配的时候,就要做一次全表扫描。这也导致整个过程的时间复杂度编程了 N * M,这是不可接受的。所以,当没有索引时,MySQL 使用 Block Nested-Loop Join 算法。
Block Nested-Loop Join
Block Nested-Loop Join的算法,简称 La fonction de jointure de MySQL est-elle trop faible ?,它是 MySQL 在被驱动表上无可用索引时使用的 join 算法,其具体流程如下所示:
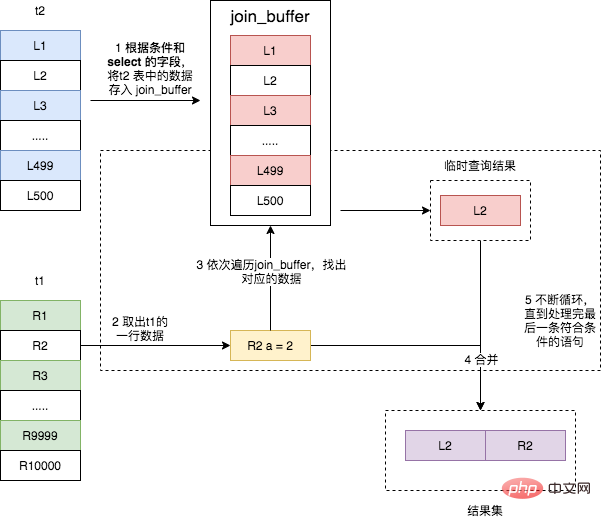
- 把表 t2 的数据读取当前线程的 join_buffer 中,在本篇文章的示例 SQL 没有在 t2 上做任何条件过滤,所以就是讲 t2 整张表 放入内存中;
- 扫描表 t1,每取出一行数据,就跟 join_buffer 中的数据进行对比,满足 join 条件的,则放入结果集。
比如下面这条 SQL
select * from t2 straight_join t1 on (t2.b=t1.b);复制代码
这条语句的 explain 结果如下所示。可以看出
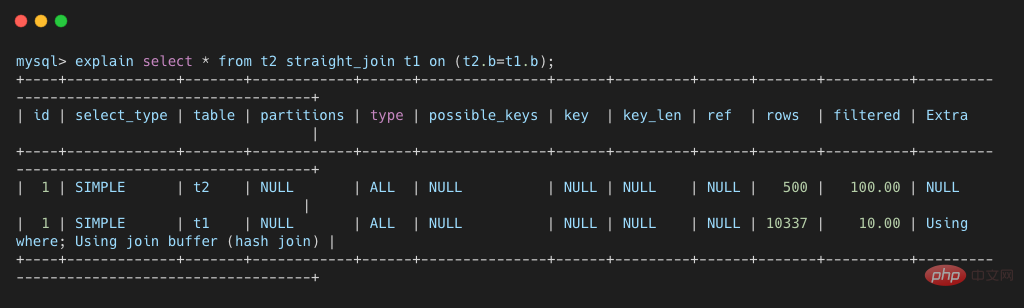
可以看出,这次 join 过程对 t1 和 t2 都做了一次全表扫描,并且将表 t2 中的 500 条数据全部放入内存 join_buffer 中,并且对于表 t1 中的每一行数据,都要去 join_buffer 中遍历一遍,都要做 500 次对比,所以一共要进行 500 * 10000 次内存对比操作,具体流程如下图所示。
主要注意的是,第一步中,并不是将表 t2 中的所有数据都放入 join_buffer,而是根据具体的 SQL 语句,而放入不同行的数据和不同的字段。比如下面这条 join 语句则只会将表 t2 中符合 b >= 100 的数据的 b 字段存入 join_buffer。
select t2.b,t1.b from t2 straight_join t1 on (t2.b=t1.b) where t2.b >= 100;复制代码
join_buffer 并不是无限大的,由 join_buffer_size 控制,默认值为 256K。当要存入的数据过大时,就只有分段存储了,整个执行过程就变成了:
- 扫描表 t2,将符合条件的数据行存入 join_buffer,因为其大小有限,存到100行时满了,则执行第二步;
- 扫描表 t1,每取出一行数据,就跟 join_buffer 中的数据进行对比,满足 join 条件的,则放入结果集;
- 清空 join_buffer;
- 再次执行第一步,直到全部数据被扫描完,由于 t2 表中有 500行数据,所以一共重复了 5次
这个流程体现了该算法名称中 Block 的由来,分块去执行 join 操作。因为表 t2 的数据被分成了 5 次存入 join_buffer,导致表 t1 要被全表扫描 5次。
| 全部存入 | 分5次存入 | |
|---|---|---|
| 内存操作 | 10000 * 500 | 10000 * (100 + 100 + 100 + 100 + 100) |
| 扫描行数 | 10000 + 500 | 10000 * 5 + 500 |
Comme indiqué ci-dessus, par rapport aux données de table qui peuvent toutes être stockées dans join_buffer, le nombre de jugements de mémoire n'a pas changé. Il s'agit du produit du nombre de lignes dans les deux tables, qui est de 10 000 * 500. Cependant, la table pilotée sera analysée plusieurs fois, chaque fois qu'elle est enregistrée, la table pilotée sera à nouveau analysée, ce qui affecte l'efficacité de l'exécution finale.
Sur la base des deux algorithmes ci-dessus, nous pouvons tirer la conclusion suivante, qui est également la norme pour la plupart des instructions de jointure MySQL sur Internet.
Il y a un index sur la table pilotée, c'est-à-dire que lorsque l'algorithme Index Nested-Loop Join peut être utilisé, l'opération de jointure peut être utilisée.
Qu'il s'agisse de l'algorithme Index Nested-Loop Join ou de Block Nested-Loop Join, une petite table doit être utilisée comme table de pilotage.
Parce que la complexité temporelle des deux algorithmes de jointure ci-dessus est au moins dans une relation de premier ordre avec le nombre de lignes de la table impliquée, et cela prend beaucoup d'espace mémoire, il est donc compréhensible que les spécifications du développeur Alibaba interdisent strictement les opérations de jointure de plus de trois tables.
Mais les deux algorithmes ci-dessus ne sont qu'un des algorithmes de jointure. Il existe également des algorithmes de jointure plus efficaces, tels que Hash Join et Sorted Merged Join. Malheureusement, ces deux algorithmes ne sont actuellement pas disponibles dans la version grand public de MySQL, mais Oracle, PostgreSQL et Spark les prennent tous en charge. C'est aussi la raison pour laquelle les plaintes en ligne concernant MySQL sont si faibles (MySQL version 8.0 prend en charge la jointure par hachage, mais 8.0 prend actuellement en charge la jointure par hachage (pas encore une version grand public).
En fait, les spécifications du développeur Alibaba stipulaient également que lors de la migration d'Oracle vers MySQL, les performances des opérations de jointure de MySQL étaient trop mauvaises pour interdire l'opération de jointure de plus de trois tables.
Algorithme de jointure par hachage
La jointure par hachage consiste à analyser la table du pilote, à utiliser les champs associés de la jointure pour créer une table de hachage dans la mémoire, puis à analyser la table pilotée et à la lire. chaque ligne de données de la table de hachage Recherchez les données correspondantes. Il s'agit d'une méthode courante pour les opérations de connexion de grands ensembles de données. Elle convient aux scénarios dans lesquels la quantité de données dans la table pilote est faible et peut être utilisée pour grandes tables sans index. et pour les requêtes parallèles. Malheureusement, cela ne s'applique qu'aux scénarios d'équi-jointure, comme sur a.id = où b.a_id.
est toujours l'instruction de jointure des deux tables ci-dessus. Le processus d'exécution est le suivant :
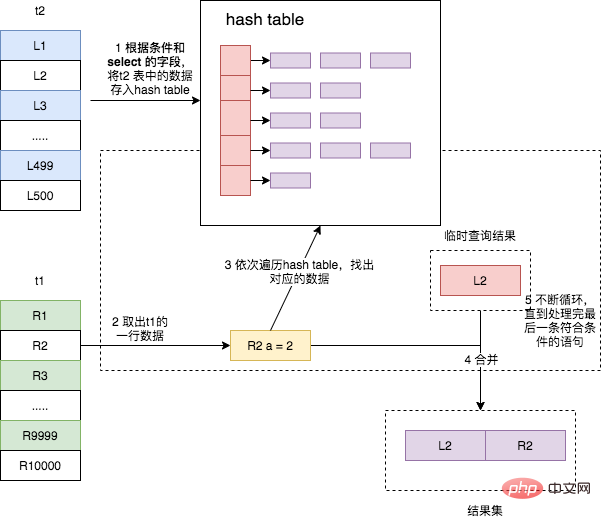
- Retirez les données qualifiées du pilote. table t2, et La valeur du champ de jointure de chaque ligne est hachée, puis stockée dans la table de hachage en mémoire
- parcourt la table pilotée t1, et chaque ligne de données qui remplit les conditions est supprimée, et la valeur du champ de jointure est également hachée. Obtenez le résultat dans la table de hachage en mémoire pour trouver une correspondance. Si elle est trouvée, elle fait partie du jeu de résultats.
On peut voir que cet algorithme est similaire à Block Nested-Loop Join, sauf que le tampon de jointure non ordonné est remplacé par une table de hachage, de sorte que les données ne correspondent pas Il n'est plus nécessaire de parcourir toutes les données dans le tampon de jointure, mais d'utiliser directement le hachage pour obtenir la ligne correspondante avec une complexité temporelle proche de O(1), ce qui améliore grandement la vitesse de jointure des deux tables.
Cependant, en raison des caractéristiques du hachage, cet algorithme ne peut être appliqué qu'au scénario de connexion équivalent, et cet algorithme ne peut pas être utilisé dans d'autres scénarios de connexion.
Algorithme de jointure de fusion triée
La jointure de fusion de tri trie d'abord les deux tables en fonction des champs associés de la jointure (si elle a déjà été triée, par exemple s'il y a un index sur le champ , il n'est pas nécessaire de trier à nouveau), puis effectuez une opération de fusion sur les deux tables. Si les deux tables ont été triées, il n'est pas nécessaire de les trier à nouveau lors d'une jointure par fusion de tri. Dans ce cas, les performances de Merge Join seront meilleures que celles de Hash Join. La jointure de fusion peut être adaptée aux jointures non équivalentes (>, =, ).
Il est à noter que si le champ connecté possède déjà un index, c'est-à-dire s'il a été trié, l'opération de fusion peut être effectuée directement. Par contre, si le champ connecté ne possède pas d'index. , son processus d'exécution est le suivant.
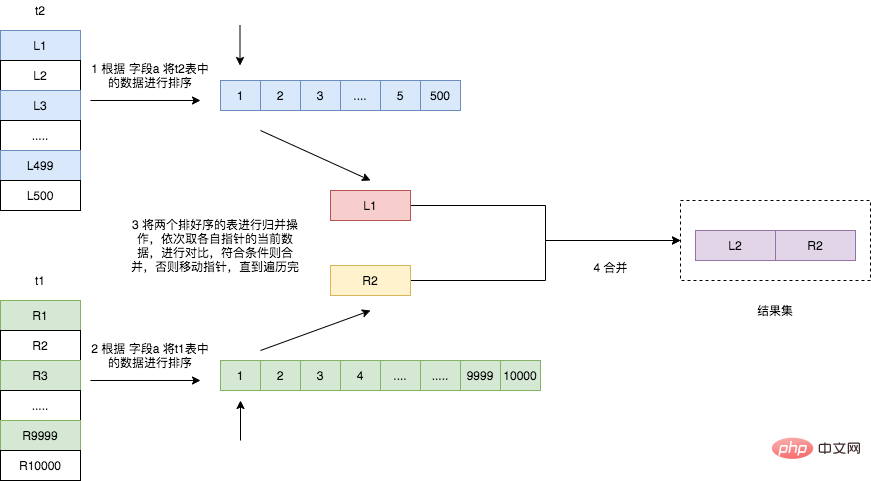
- Table de parcours t2, lisez les données qui remplissent les conditions, et triez-les en fonction de la valeur du champ de connexion a
- Parcours tableau t1, Lire les données qui remplissent les conditions et les trier en fonction de la valeur du champ de connexion a
- Fusionner les deux données triées pour obtenir l'ensemble de résultats.
La principale consommation de temps de l'algorithme Sorted Merge Join est l'opération de tri des deux tables, donc si les deux tables ont été triées en fonction du champ de connexion, l'algorithme est encore plus rapide que le Hash Rejoindre l'algorithme. Dans un cas, cet algorithme est plus rapide que l’algorithme Nested Loop Join.
Maintenant, résumons les différences, les avantages et les inconvénients des trois algorithmes ci-dessus.
| Nested Loop Join | Hash Join | Sorted Merge Join | |
|---|---|---|---|
| 连接条件 | 适用于任何条件 | 只适用于等值连接(=) | 等值或非等值连接(>,=,’除外 |
| 主要消耗资源 | CPU、磁盘I/O | 内存、临时空间 | 内存、临时空间 |
| 特点 | 当有高选择性索引或进行限制性搜索时效率比较高,能够快速返回第一次的搜索结果 | 当缺乏索引或者索引条件模糊时,Hash Join 比 Nested Loop 有效。通常比 Merge Join 快。在数据仓库环境下,如果表的纪录数多,效率高 | 当缺乏索引或者索引条件模糊时,Sort Merge Join 比 Nested Loop 有效。当连接字段有索引或者提前排好序时,比 hash join 快,并且支持更多的连接条件 |
| 缺点 | 无索引或者表记录多时效率低 | 建立哈希表需要大量内存,第一次的结果返回较慢 | 所有的表都需要排序。它为最优化的吞吐量而设计,并且在结果没有全部找到前不返回数据 |
| 需要索引 | 是(没有索引效率太差) | 否 | 否 |
Compréhension de l'opération Join
Après avoir parlé des algorithmes liés à Join, parlons également de la compréhension commerciale de l'opération Join.
Lorsque le métier n'est pas complexe, la plupart des jointures ne sont pas irremplaçables. Par exemple, l'enregistrement de commande ne contient généralement que le user_id de l'utilisateur de la commande. Lors du renvoi des informations, le nom de l'utilisateur doit être obtenu. Les solutions d'implémentation possibles sont les suivantes :
- Une opération de base de données, en utilisant. l'opération de jointure, la table de commande et la table utilisateur Effectuer une jointure et un retour avec le nom d'utilisateur
- Deux opérations de base de données, deux requêtes, la première fois pour obtenir les informations de commande et l'identifiant de l'utilisateur, la deuxième fois pour obtenir le nom basé sur l'id_utilisateur et utilisez le programme de code pour fusionner les informations ;
- Utilisez des noms d'utilisateur redondants ou lisez à partir de bases de données non relationnelles telles que ES.
Les solutions ci-dessus peuvent toutes résoudre le problème de l'agrégation des données et sont traitées en fonction du code du programme, qui est plus facile à déboguer et à optimiser que la jointure à la base de données. Par exemple, le nom d'utilisateur n'est pas récupéré. la base de données, mais d'abord récupéré du cache Rechercher dans .
Bien sûr, l'opération de jointure n'est pas inutile, la technologie a donc ses scénarios d'utilisation. Les solutions ou règles ci-dessus sont résumées par l'équipe de développement Internet et conviennent à une concurrence élevée, une écriture légère et une lecture lourde, une distribution. , et logique métier Dans les cas simples, ces scénarios n'ont généralement pas d'exigences élevées en matière de cohérence des données, et même les lectures incorrectes sont autorisées.
Cependant, dans les scénarios d'applications d'entreprise tels que la banque financière ou la finance, l'opération de jointure est indispensable. Ces applications sont généralement à faible concurrence, écrivent fréquemment des données complexes, sont gourmandes en CPU plutôt qu'en E/S et leur activité principale. La logique est traitée via la base de données et même par des systèmes contenant un grand nombre de procédures stockées et ayant des exigences élevées en matière de cohérence et d'intégrité.
Plus de recommandations d'apprentissage gratuites connexes : tutoriel MySQL(vidéo)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Moniteur Disd Droplet avec service d'exportateur Redis
Apr 10, 2025 pm 01:36 PM
Moniteur Disd Droplet avec service d'exportateur Redis
Apr 10, 2025 pm 01:36 PM
La surveillance efficace des bases de données Redis est essentielle pour maintenir des performances optimales, identifier les goulots d'étranglement potentiels et assurer la fiabilité globale du système. Le service Redis Exporter est un utilitaire puissant conçu pour surveiller les bases de données Redis à l'aide de Prometheus. Ce didacticiel vous guidera à travers la configuration et la configuration complètes du service Redis Exportateur, en vous garantissant de créer des solutions de surveillance de manière transparente. En étudiant ce tutoriel, vous réaliserez les paramètres de surveillance entièrement opérationnels
 Comment afficher l'erreur de base de données SQL
Apr 10, 2025 pm 12:09 PM
Comment afficher l'erreur de base de données SQL
Apr 10, 2025 pm 12:09 PM
Les méthodes de visualisation des erreurs de base de données SQL sont: 1. Afficher directement les messages d'erreur; 2. Utilisez des erreurs d'affichage et des commandes d'avertissement Show; 3. Accédez au journal d'erreur; 4. Utiliser les codes d'erreur pour trouver la cause de l'erreur; 5. Vérifiez la connexion de la base de données et la syntaxe de requête; 6. Utilisez des outils de débogage.
 Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Apache se connecte à une base de données nécessite les étapes suivantes: Installez le pilote de base de données. Configurez le fichier web.xml pour créer un pool de connexion. Créez une source de données JDBC et spécifiez les paramètres de connexion. Utilisez l'API JDBC pour accéder à la base de données à partir du code Java, y compris l'obtention de connexions, la création d'instructions, les paramètres de liaison, l'exécution de requêtes ou de mises à jour et de traitement des résultats.
