
 base de données
tutoriel mysql
Explication du plan d'exécution MySQL et déduction de la structure des données d'indexation
base de données
tutoriel mysql
Explication du plan d'exécution MySQL et déduction de la structure des données d'indexation
Explication du plan d'exécution MySQL et déduction de la structure des données d'indexation

Tutoriel MySQLLa colonne présente le plan d'exécution, explique et indexe la structure des données

Préparation work
Construisez d'abord la table de base de données, la table MySQL pour la démonstration, l'instruction de création de table :
CREATE TABLE `emp` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `empno` int(11) DEFAULT NULL COMMENT '雇员工号', `ename` varchar(255) DEFAULT NULL COMMENT '雇员姓名', `job` varchar(255) DEFAULT NULL COMMENT '工作', `mgr` varchar(255) DEFAULT NULL COMMENT '经理的工号', `hiredate` date DEFAULT NULL COMMENT '雇用日期', `sal` double DEFAULT NULL COMMENT '工资', `comm` double DEFAULT NULL COMMENT '津贴', `deptno` int(11) DEFAULT NULL COMMENT '所属部门号', PRIMARY KEY (`id`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='雇员表';CREATE TABLE `dept` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `deptno` int(11) DEFAULT NULL COMMENT '部门号', `dname` varchar(255) DEFAULT NULL COMMENT '部门名称', `loc` varchar(255) DEFAULT NULL COMMENT '地址', PRIMARY KEY (`id`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='部门表';CREATE TABLE `salgrade` ( `id` int(11) NOT NULL COMMENT '主键', `grade` varchar(255) DEFAULT NULL COMMENT '等级', `lowsal` varchar(255) DEFAULT NULL COMMENT '最低工资', `hisal` varchar(255) DEFAULT NULL COMMENT '最高工资', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='工资等级表';CREATE TABLE `bonus` ( `id` int(11) NOT NULL COMMENT '主键', `ename` varchar(255) DEFAULT NULL COMMENT '雇员姓名', `job` varchar(255) DEFAULT NULL COMMENT '工作', `sal` double DEFAULT NULL COMMENT '工资', `comm` double DEFAULT NULL COMMENT '津贴', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='奖金表';复制代码
Plan d'exécution de suivi, optimisation des requêtes, optimisation de l'index et autres exercices de connaissances, basés sur le tableau ci-dessus pour fonctionner.
Plan d'exécution MySQL
Pour effectuer le réglage SQL, vous devez savoir comment l'instruction SQL à régler est exécutée et vérifier le processus d'exécution spécifique de l'instruction SQL pour accélérer l'efficacité de l'exécution de l'instruction SQL.
Vous pouvez utiliser l'instruction explain + SQL pour simuler l'optimiseur exécutant des instructions de requête SQL, afin de savoir comment MySQL traite les instructions SQL.
Pour plus d'informations sur explain, vous pouvez consulter l'introduction du site officiel.
expliquer le format de sortie
mysql> explain select * from emp; +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+| 1 | SIMPLE | emp | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+复制代码
champ id, select_type et explication des autres champs :
| Column | Meaning |
|---|---|
| id | The SELECT identifier(该SELECT标识符) |
| select_type | The SELECT type( 该SELECT类型) |
| table | The table for the output row(输出该行的表名) |
| partitions | The matching partitions(匹配的分区) |
| type | The join type(连接类型) |
| possible_keys | The possible indexes to choose(可能的索引选择) |
| key | The index actually chosen(实际选择的索引) |
| key_len | The length of the chosen key(所选键的长度) |
| ref | The columns compared to the index(与索引比较的列) |
| rows | Estimate of rows to be examined(检查的预估行数) |
| filtered | Percentage of rows filtered by table condition(按表条件过滤的行百分比) |
| extra | Additional information(附加信息) |
id
select查询的序列号,包含一组数字,表示查询中执行select子句或者操作表的顺序。
id号分为三类:
- 如果id相同,那么执行顺序从上到下
mysql> explain select * from emp e join dept d on e.deptno = d.deptno join salgrade sg on e.sal between sg.lowsal and sg.hisal; +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+ | 1 | SIMPLE | e | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL | | 1 | SIMPLE | d | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | Using where; Using join buffer (Block Nested Loop) | | 1 | SIMPLE | sg | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | Using where; Using join buffer (Block Nested Loop) | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+复制代码
这个查询,用explain执行一下,
id序号都是1,那么MySQL的执行顺序就是从上到下执行的。
- 如果id不同,如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
mysql> explain select * from emp e where e.deptno in (select d.deptno from dept d where d.dname = 'SALEDept'); +----+--------------+-------------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+--------------+-------------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+| 1 | SIMPLE | <subquery2> | NULL | ALL | NULL | NULL | NULL | NULL | NULL | 100.00 | NULL | | 1 | SIMPLE | e | NULL | ALL | NULL | NULL | NULL | NULL | 2 | 50.00 | Using where; Using join buffer (Block Nested Loop) | | 2 | MATERIALIZED | d | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | Using where | +----+--------------+-------------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+复制代码</subquery2>
这个例子的执行顺序是先执行
id为2的,然后执行id为1的。
- id相同和不同的,同时存在:相同的可以认为是一组,从上往下顺序执行,在所有组中,id值越大,优先级越高,越先执行
还是上面那个例子,先执行
id为2的,然后按顺序从上往下执行id为1的。
select_type
主要用来分辨查询的类型,是普通查询还是联合查询还是子查询。
select_type Value |
JSON Name | Meaning |
|---|---|---|
| SIMPLE | None | Simple SELECT (not using UNION or subqueries) |
| PRIMARY | None | Outermost SELECT |
| UNION | None | Second or later SELECT statement in a UNION |
| DEPENDENT UNION | dependent (true) | Second or later SELECT statement in a UNION, dependent on outer query |
| UNION RESULT | union_result | Result of a UNION. |
| SUBQUERY | None | First SELECT in subquery |
| DEPENDENT SUBQUERY | dependent (true) | First SELECT in subquery, dependent on outer query |
| DERIVED | None | Derived table |
| MATERIALIZED | materialized_from_subquery | Materialized subquery |
| UNCACHEABLE SUBQUERY | cacheable (false) | A subquery for which the result cannot be cached and must be re-evaluated for each row of the outer query |
| UNCACHEABLE UNION | cacheable (false) | The second or later select in a UNION that belongs to an uncacheable subquery (see UNCACHEABLE SUBQUERY) |
-
SIMPLE简单的查询,不包含子查询和union
mysql> explain select * from emp; +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+| 1 | SIMPLE | emp | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 100.00 | NULL | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+复制代码
-
primary查询中若包含任何复杂的子查询,最外层查询则被标记为Primary -
union若第二个select出现在union之后,则被标记为union
mysql> explain select * from emp where deptno = 1001 union select * from emp where sal | NULL | ALL | NULL | NULL | NULL | NULL | NULL | NULL | Using temporary | +----+--------------+------------+------------+------+---------------+------+---------+------+------+----------+-----------------+复制代码
这条语句的select_type包含了primary和union
-
dependent union跟union类似,此处的depentent表示union或union all联合而成的结果会受外部表影响 -
union result从union表获取结果的select -
dependent subquerysubquery的子查询要受到外部表查询的影响
mysql> explain select * from emp e where e.empno in ( select empno from emp where deptno = 1001 union select empno from emp where sal | NULL | ALL | NULL | NULL | NULL | NULL | NULL | NULL | Using temporary | +----+--------------------+------------+------------+------+---------------+------+---------+------+------+----------+-----------------+复制代码
这条SQL执行包含了PRIMARY、DEPENDENT SUBQUERY、DEPENDENT UNION和UNION RESULT
-
subquery在select或者where列表中包含子查询
举例:
mysql> explain select * from emp where sal > (select avg(sal) from emp) ; +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+| 1 | PRIMARY | emp | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 33.33 | Using where | | 2 | SUBQUERY | emp | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 100.00 | NULL | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+复制代码
-
DERIVEDfrom子句中出现的子查询,也叫做派生表 -
MATERIALIZEDMaterialized subquery? -
UNCACHEABLE SUBQUERY表示使用子查询的结果不能被缓存
例如:
mysql> explain select * from emp where empno = (select empno from emp where deptno=@@sort_buffer_size); +----+----------------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+----------------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+| 1 | PRIMARY | emp | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 100.00 | Using where | | 2 | UNCACHEABLE SUBQUERY | emp | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 25.00 | Using where | +----+----------------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+复制代码
-
uncacheable union表示union的查询结果不能被缓存
table
对应行正在访问哪一个表,表名或者别名,可能是临时表或者union合并结果集。
- 如果是具体的表名,则表明从实际的物理表中获取数据,当然也可以是表的别名
- 表名是derivedN的形式,表示使用了id为N的查询产生的衍生表
- 当有union result的时候,表名是union n1,n2等的形式,n1,n2表示参与union的id
type
type显示的是访问类型,访问类型表示我是以何种方式去访问我们的数据,最容易想到的是全表扫描,直接暴力的遍历一张表去寻找需要的数据,效率非常低下。
访问的类型有很多,效率从最好到最坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
一般情况下,得保证查询至少达到range级别,最好能达到ref
-
all全表扫描,一般情况下出现这样的sql语句而且数据量比较大的话那么就需要进行优化
通常,可以通过添加索引来避免ALL
-
index全索引扫描这个比all的效率要好,主要有两种情况:- 一种是当前的查询时覆盖索引,即我们需要的数据在索引中就可以索取
- 一是使用了索引进行排序,这样就避免数据的重排序
-
range表示利用索引查询的时候限制了范围,在指定范围内进行查询,这样避免了index的全索引扫描,适用的操作符: =, , >, >=,
官网上举例如下:
SELECT * FROM tbl_name WHERE key_column = 10;
SELECT * FROM tbl_name WHERE key_column BETWEEN 10 and 20;
SELECT * FROM tbl_name WHERE key_column IN (10,20,30);
SELECT * FROM tbl_name WHERE key_part1 = 10 AND key_part2 IN (10,20,30);
-
index_subquery利用索引来关联子查询,不再扫描全表
value IN (SELECT key_column FROM single_table WHERE some_expr)
-
unique_subquery该连接类型类似与index_subquery,使用的是唯一索引
value IN (SELECT primary_key FROM single_table WHERE some_expr)
-
index_merge在查询过程中需要多个索引组合使用 -
ref_or_null对于某个字段既需要关联条件,也需要null值的情况下,查询优化器会选择这种访问方式
SELECT * FROM ref_table
WHERE key_column=expr OR key_column IS NULL;
-
fulltext使用FULLTEXT索引执行join -
ref使用了非唯一性索引进行数据的查找
SELECT * FROM ref_table WHERE key_column=expr;
SELECT * FROM ref_table,other_table WHERE ref_table.key_column=other_table.column;
SELECT * FROM ref_table,other_table WHERE ref_table.key_column_part1=other_table.column AND ref_table.key_column_part2=1;
-
eq_ref使用唯一性索引进行数据查找
SELECT * FROM ref_table,other_table WHERE ref_table.key_column=other_table.column;
SELECT * FROM ref_table,other_table WHERE ref_table.key_column_part1=other_table.column AND ref_table.key_column_part2=1;
-
const这个表至多有一个匹配行
SELECT * FROM tbl_name WHERE primary_key=1;
SELECT * FROM tbl_name WHERE primary_key_part1=1 AND primary_key_part2=2;
例如:
mysql> explain select * from emp where id = 1; +----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+| 1 | SIMPLE | emp | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL | +----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+复制代码
-
system表只有一行记录(等于系统表),这是const类型的特例,平时不会出现
possible_keys
显示可能应用在这张表中的索引,一个或多个,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询实际使用

key
实际使用的索引,如果为null,则没有使用索引,查询中若使用了覆盖索引,则该索引和查询的select字段重叠

key_len
表示索引中使用的字节数,可以通过key_len计算查询中使用的索引长度,在不损失精度的情况下长度越短越好
ref
显示索引的哪一列被使用了,如果可能的话,是一个常数
rows
根据表的统计信息及索引使用情况,大致估算出找出所需记录需要读取的行数,此参数很重要,直接反应的sql找了多少数据,在完成目的的情况下越少越好

extra
包含额外的信息
-
using filesort说明mysql无法利用索引进行排序,只能利用排序算法进行排序,会消耗额外的位置 -
using temporary建立临时表来保存中间结果,查询完成之后把临时表删除 -
using index这个表示当前的查询是覆盖索引的,直接从索引中读取数据,而不用访问数据表。如果同时出现using where 表明索引被用来执行索引键值的查找,如果没有,表示索引被用来读取数据,而不是真的查找 -
using where使用where进行条件过滤 -
using join buffer使用连接缓存 -
impossible wherewhere语句的结果总是false
MySQL索引基本知识
想要了解索引的优化方式,必须要对索引的底层原理有所了解。
索引的优点
- 大大减少了服务器需要扫描的数据量
- 帮助服务器避免排序和临时表
- 将随机io变成顺序io(提升效率)
索引的用处
- 快速查找匹配WHERE子句的行
- 从consideration中消除行,如果可以在多个索引之间进行选择,mysql通常会使用找到最少行的索引
- 如果表具有多列索引,则优化器可以使用索引的任何最左前缀来查找行
- 当有表连接的时候,从其他表检索行数据
- 查找特定索引列的min或max值
- 如果排序或分组时在可用索引的最左前缀上完成的,则对表进行排序和分组
- 在某些情况下,可以优化查询以检索值而无需查询数据行
Explication du plan dexécution MySQL et déduction de la structure des données dindexation
MySQL索引数据结构推演
索引用于快速查找具有特定列值的行。
如果没有索引,MySQL必须从第一行开始,然后通读整个表以找到相关的行。
表越大花费的时间越多,如果表中有相关列的索引,MySQL可以快速确定要在数据文件中间查找的位置,而不必查看所有数据。这比顺序读取每一行要快得多。
既然MySQL索引能帮助我们快速查询到数据,那么它的底层是怎么存储数据的呢?
几种可能的存储结构
hash
hash表的索引格式

Inconvénients du stockage de données dans des tables de hachage :
- Si vous utilisez le stockage de hachage, vous devez ajouter tous les fichiers de données à la mémoire, ce qui consomme plus de mémoire espace
- Si toutes les requêtes sont des requêtes équivalentes, alors le hachage est très rapide, mais dans l'environnement de travail réel, les données de recherche de plage sont plus nombreuses que les requêtes équivalentes, dans ce cas, le hachage ne convient pas
En fait, lorsque le moteur de stockage MySQL est memory, la structure des données d'index utilise une table de hachage.
Arbre binaire
La structure d'un arbre binaire est comme ceci :
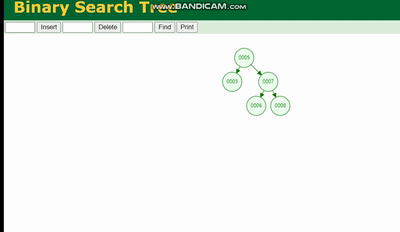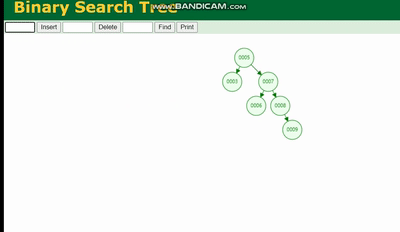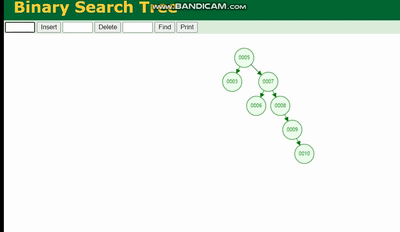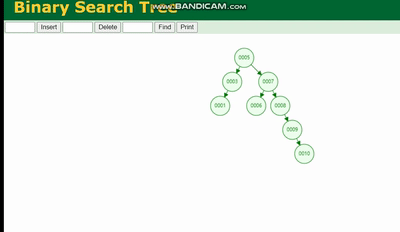
Un arbre binaire provoquera perte de données en raison de la profondeur de l'arborescence, si la profondeur de l'arborescence est trop profonde, cela entraînera plus de temps d'E/S et affectera l'efficacité de la lecture des données.
L'arbre AVL doit être tourné, voir la légende :
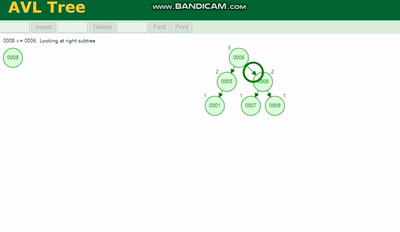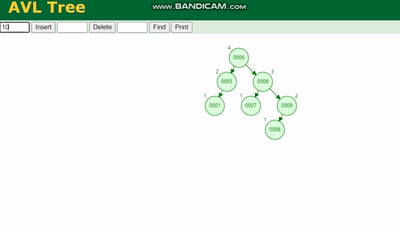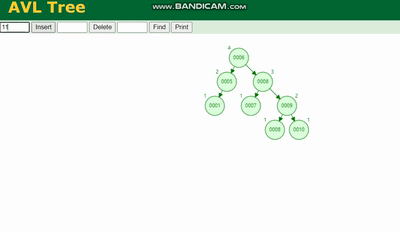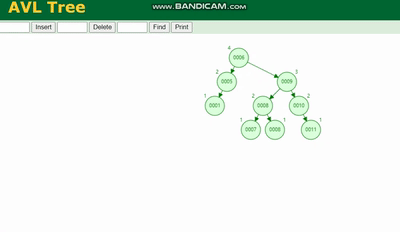
Arbre rouge-noir Il y a plus d'opérations en plus de la rotation Une fonction 变色 (afin de réduire la rotation), bien que la vitesse d'insertion soit rapide, l'efficacité des requêtes est perdue.
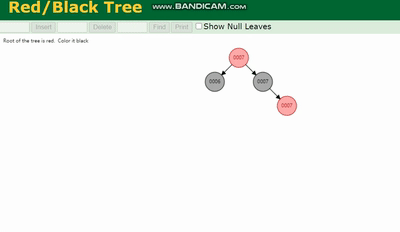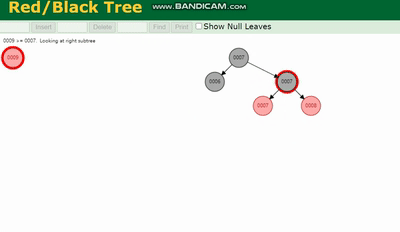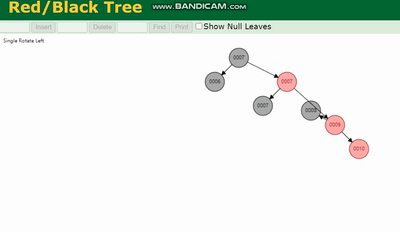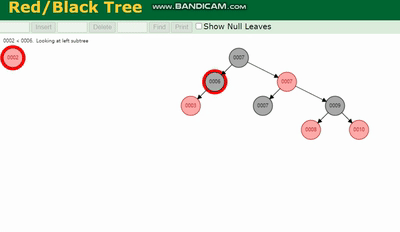
Arbre binaire, Arbre AVL, Arbre rouge-noir seront tous causés par la profondeur de l'arborescence étant trop profonde. Le nombre de fois d'E/S augmente, ce qui affecte l'efficacité de la lecture des données.
Jetons un coup d'œil aux B-tree
Caractéristiques du B-tree :
- Toutes les valeurs clés sont distribuées dans tout le arbre
- La recherche peut se terminer à un nœud non-feuille, et une recherche est effectuée dans l'ensemble complet de mots-clés. Les performances sont proches de la recherche binaire
- Chaque nœud a au plus m sous-arbres.
- Le nœud racine a au moins 2 sous-arbres Arbre
- Le nœud de branche a au moins m/2 sous-arbres (tous les nœuds de branche sauf le nœud racine et les nœuds feuilles)
- Tous les nœuds feuilles sont au même niveau, et chaque nœud peut avoir au plus une clé m -1 et disposés par ordre croissant
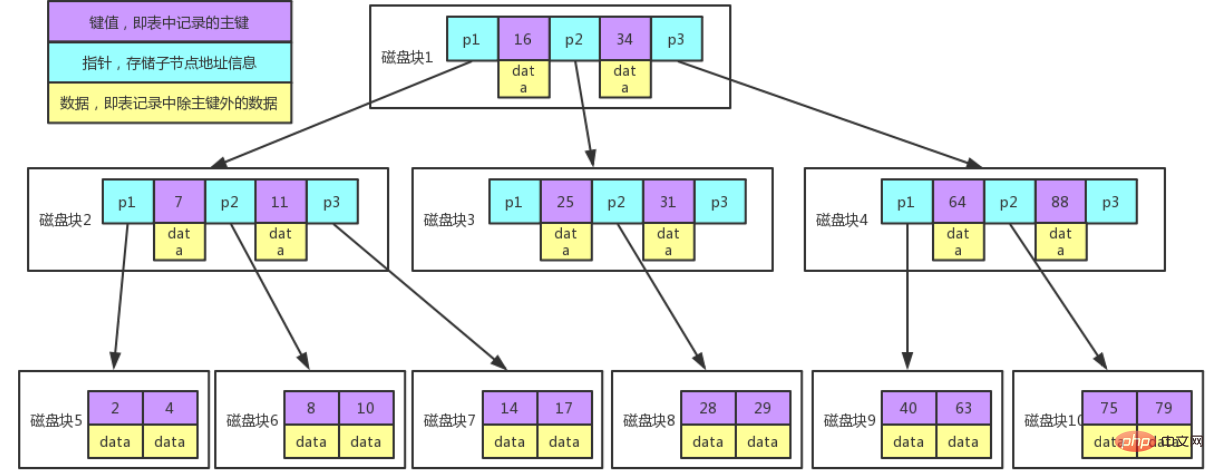
Description de la légende:
Chaque nœud occupe un bloc de disque. Il y a deux clés d'ordre croissant sur un nœud et trois pointeurs vers le nœud racine du sous-arbre. Les pointeurs stockent l'adresse du bloc de disque où se trouve le nœud enfant. situé.
Les trois champs range divisés par les deux mots-clés correspondent aux champs range des données du sous-arbre pointé par les trois pointeurs.
Prenons l'exemple du nœud racine, les mots-clés sont 16 et 34, la plage de données du sous-arbre pointé par le pointeur P1 est inférieure à 16, la plage de données du sous-arbre pointé par le pointeur P2 est 16 ~ 34 et la plage de données pointée par le pointeur P3. La plage de données du sous-arbre est supérieure à 34.
Processus de recherche par mot clé :
1. Recherchez le bloc de disque 1 en fonction du nœud racine et lisez-le en mémoire. [Opération d'E/S disque 1ère fois]
2. Comparez le mot-clé 28 dans l'intervalle (16,34), trouvez le pointeur P2 du bloc disque 1.
3. Recherchez le bloc de disque 3 en fonction du pointeur P2 et lisez-le dans la mémoire. [Opération d'E/S disque 2ème fois]
4. Comparez le mot-clé 28 dans l'intervalle (25,31), recherchez le pointeur P2 du bloc disque 3.
5. Recherchez le bloc de disque 8 en fonction du pointeur P2 et lisez-le dans la mémoire. [Opération d'E/S disque 3ème fois]
6. Recherchez le mot-clé 28 dans la liste de mots-clés du bloc de disque 8.
De là, nous pouvons connaître les lacunes du stockage B-tree :
- Chaque nœud a une clé et contient également des données, et l'espace de stockage de chaque page est limité si. les données sont relativement volumineuses, cela entraînera une diminution du nombre de clés stockées dans chaque nœud
- Lorsque la quantité de données stockées est importante, cela entraînera une plus grande profondeur et augmentera le nombre de fois d'E/S disque pendant la requête, et ainsi affecter les performances de la requête
Alors, quelle est la structure des données de l'index MySQL ?
Site Web officiel : La plupart des index MySQL (PRIMARY KEY, UNIQUE, INDEX et FULLTEXT) sont stockés dans des B-trees
Ne vous méprenez pas, en fait, la structure de stockage de l'index MySQL est B+树 Après notre analyse ci-dessus, nous savons que B树 est. inapproprié.
Structure de données d'index mysql---B+Tree
B+Tree est une optimisation basée sur BTree, avec les changements suivants :
1 . Chaque nœud de B+Tree peut contenir plus de nœuds. Il y a deux raisons à cela. La première raison est de réduire la hauteur de l'arborescence, et la deuxième raison est de modifier la plage de données en plusieurs intervalles. la récupération des données est plus rapide.
2. Les nœuds non-feuilles stockent les clés et les nœuds feuilles stockent les clés et les données.
3. Deux pointeurs de nœuds feuilles sont connectés l'un à l'autre (conformément aux caractéristiques de lecture anticipée du disque), et les performances des requêtes séquentielles sont plus élevées.
Schéma de stockage et de recherche de l'arbre B+ :
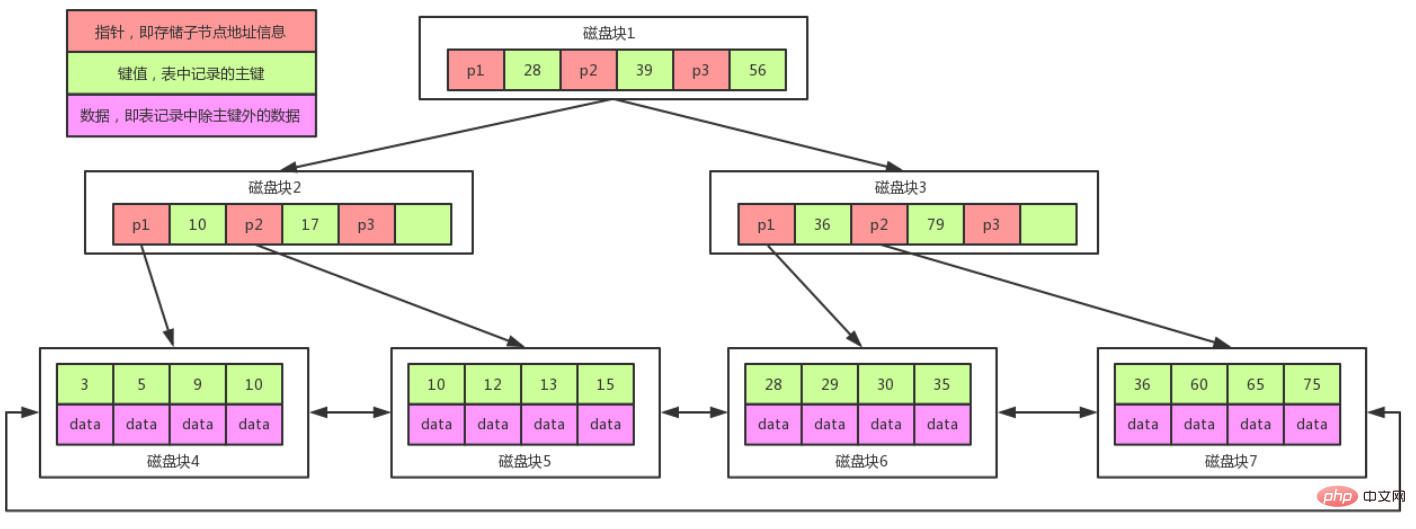
注意:
在B+Tree上有两个头指针,一个指向根节点,另一个指向关键字最小的叶子节点,而且所有叶子节点(即数据节点)之间是一种链式环结构。
因此可以对 B+Tree 进行两种查找运算:一种是对于主键的范围查找和分页查找,另一种是从根节点开始,进行随机查找。
由于B+树叶子结点只存放data,根节点只存放key,那么我们计算一下,即使只有3层B+树,也能制成千万级别的数据。
你得知道的技(zhuang)术(b)名词
假设有这样一个表如下,其中id是主键:
mysql> select * from stu; +------+---------+------+| id | name | age | +------+---------+------+| 1 | Jack Ma | 18 | | 2 | Pony | 19 | +------+---------+------+复制代码
回表
我们对普通列建普通索引,这时候我们来查:
select * from stu where name='Pony';复制代码
由于name建了索引,查询时先找name的B+树,找到主键id后,再找主键id的B+树,从而找到整行记录。
这个最终会回到主键上来查找B+树,这个就是回表。
覆盖索引
如果是这个查询:
mysql> select id from stu where name='Pony';复制代码
就没有回表了,因为直接找到主键id,返回就完了,不需要再找其他的了。
没有回表就叫覆盖索引。
最左匹配
再来以name和age两个字段建组合索引(name, age),然后有这样一个查询:
select * from stu where name=? and age=?复制代码
这时按照组合索引(name, age)查询,先匹配name,再匹配age,如果查询变成这样:
select * from stu where age=?复制代码
直接不按name查了,此时索引不会生效,也就是不会按照索引查询---这就是最左匹配原则。
加入我就要按age查,还要有索引来优化呢?可以这样做:
- (推荐)把组合索引(name, age)换个顺序,建(age, name)索引
- 或者直接把
age字段单独建个索引
索引下推
可能也叫
谓词下推。。。
select t1.name,t2.name from t1 join t2 on t1.id=t2.id复制代码
t1有10条记录,t2有20条记录。
我们猜想一下,这个要么按这个方式执行:
先t1,t2按id合并(合并后20条),然后再查t1.name,t2.name
或者:
先把t1.name,t2.name找出来,再按照id关联
如果不使用索引条件下推优化的话,MySQL只能根据索引查询出t1,t2合并后的所有行,然后再依次比较是否符合全部条件。
当使用了索引条件下推优化技术后,可以通过索引中存储的数据判断当前索引对应的数据是否符合条件,只有符合条件的数据才将整行数据查询出来。
小结
-
Explain为了知道优化SQL语句的执行,需要查看SQL语句的具体执行过程,以加快SQL语句的执行效率。 - 索引优点及用处。
- 索引采用的数据结构是B+树。
- 回表,覆盖索引,最左匹配和索引下推。
更多相关免费学习推荐:mysql教程(视频)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1393
1393
 52
1205
24
52
1205
24

 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Apache se connecte à une base de données nécessite les étapes suivantes: Installez le pilote de base de données. Configurez le fichier web.xml pour créer un pool de connexion. Créez une source de données JDBC et spécifiez les paramètres de connexion. Utilisez l'API JDBC pour accéder à la base de données à partir du code Java, y compris l'obtention de connexions, la création d'instructions, les paramètres de liaison, l'exécution de requêtes ou de mises à jour et de traitement des résultats.
 Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Le processus de démarrage de MySQL dans Docker se compose des étapes suivantes: Tirez l'image MySQL pour créer et démarrer le conteneur, définir le mot de passe de l'utilisateur racine et mapper la connexion de vérification du port Créez la base de données et l'utilisateur accorde toutes les autorisations sur la base de données
 CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
L'installation de MySQL sur CENTOS implique les étapes suivantes: Ajout de la source MySQL YUM appropriée. Exécutez la commande YUM Install MySQL-Server pour installer le serveur MySQL. Utilisez la commande mysql_secure_installation pour créer des paramètres de sécurité, tels que la définition du mot de passe de l'utilisateur racine. Personnalisez le fichier de configuration MySQL selon les besoins. Écoutez les paramètres MySQL et optimisez les bases de données pour les performances.
