

Comprendre les fichiers physiques MySQL

La colonne
tutoriel mysql présente les fichiers physiques MySQL.

1. Fichier de stockage de données de base de données
La base de données MySQL créera un dossier nommé base de données sous le répertoire de données pour stocker les données dans les données du fichier de table de base de données. Différents moteurs de base de données ont des extensions différentes pour chaque table. Par exemple : MyISAM utilise ".MYD" comme extension, Innodb utilise ".ibd", Archive utilise ".arc" et CSV utilise ".csv".
1. Fichier ".FRM"
Avant la version 8.0, quel que soit le moteur de stockage, après avoir créé la table, un fichier '.frm' nommé d'après la table sera généré. Le fichier frm stocke principalement les informations de données liées à la table, y compris les informations de définition de la structure de la table. Lorsque la base de données tombe en panne, les utilisateurs peuvent restaurer la structure de la table de données via le fichier frm.
2. Fichier ".MYD"
Le fichier ".MYD" est dédié au moteur de stockage MyISAM et stocke les données de la table MyISAM. Chaque table MyISAM aura un fichier ".MYD" correspondant, qui est également stocké dans le dossier de la base de données correspondante, avec le fichier ".frm".
3. Fichier ".MYI"
Le fichier ".MYI" est également exclusif au moteur de stockage MyISAM et stocke principalement les informations liées à l'index de la table MyISAM. Pour le stockage MyISAM, le contenu pouvant être mis en cache provient principalement du fichier « .MYI ». Chaque table MyISAM correspond à un fichier ".MYI", qui est stocké au même emplacement que ".frm" et ".MYD".
4. Fichier ".ibd" et fichier ".ibdata"
Ces deux fichiers sont des fichiers qui stockent les données Innodb La raison pour laquelle il existe deux types de fichiers pour stocker les données Innodb (y compris. Index) car la méthode de stockage de données d'Innodb peut être configurée pour déterminer s'il faut utiliser un espace table partagé pour stocker des données ou un espace table exclusif pour stocker des données. La méthode de stockage exclusive de l'espace table utilise des fichiers ".ibd" pour stocker les données, et chaque table possède un fichier ".ibd". Les fichiers sont stockés au même emplacement que les données MyISAM. Si vous choisissez d'utiliser un espace table de stockage partagé pour stocker des données, un fichier ibdata sera utilisé pour les stocker. Toutes les tables utilisent un (ou plusieurs fichiers ibdata configurables).
Les fichiers ibdata peuvent être configurés via deux paramètres : innodb_data_home_dir (répertoire de stockage de données) et innodb_data_file_path (configurer le nom de chaque fichier) Plusieurs fichiers ibdata peuvent être configurés en même temps dans innodb_data_file_path <.> configuration L'espace table partagé et l'espace table exclusif sont tous basés sur la méthode de stockage des données. #innodb_data_file_path = ibdata1:2000M;ibdata2:10M:autoextend
Espace table partagé :
Avantages : L'espace table peut être divisé en plusieurs fichiers et stocké sur chaque disque. Les données et les fichiers sont regroupés pour une gestion facile. Inconvénients : toutes les données et tous les index sont stockés dans un seul fichier, et plusieurs tables et index sont mélangés et stockés dans l'espace table, de cette manière, après qu'un grand nombre d'opérations de suppression soient effectuées sur une table, il y en a. Il y aura un grand nombre de lacunes dans l'espace table, en particulier pour l'analyse statistique et les applications telles que les systèmes de journaux, qui sont les plus inadaptées aux espaces table partagés.Espace table indépendant :
Avantages :- Chaque table possède son propre espace table indépendant.
- Les données et index de chaque table seront stockés dans son propre espace table.
- Une seule table peut être déplacée entre différentes bases de données.
- L'espace peut être récupéréa) L'opération
récupère automatiquement l'espace du tableau Pour l'analyse statistique ou les tableaux de valeurs quotidiennes, après la suppression d'une grande quantité de données, vous pouvez passer :
b) Pour les tables utilisant des espaces table indépendants, quelle que soit la manière dont elles sont supprimées, la fragmentation de l'espace table n'affectera pas sérieusement les performances, et il est toujours possible d'y remédier. Inconvénients : La table unique est trop grande, par exemple plus de 100 G. En comparaison, l'efficacité et les performances de l'utilisation d'espaces table exclusifs seront plus élevées. Conversion entre espaces table partagés et espaces table indépendants.Drop table;Recyclez l'espace inutilisé.alter table TableName engine=innodb
show variables like "innodb_file_per_table"; ON代表独立表空间管理,OFF代表共享表空间管理; 修改数据库的表空间管理方式 修改innodb_file_per_table的参数值即可,但是修改不能影响之前已经 使用过的共享表空间和独立表空间; innodb_file_per_table=1 为使用独占表空间 innodb_file_per_table=0 为使用共享表空间复制代码
Fichiers journaux : journal des requêtes, journal des requêtes lentes, journal des erreurs, journal des transactions, journal binlog, journal des erreurs, journal des relais
2.1 查询日志
查询日志在mysql中被称之为 general log(通用日志),不要被"查询日志"的名字误导,错误的以为查询日志只会记录select语句,其实不然,查询日志记录了数据库执行的命令,不管这些语句是否正确,都会被记录,我想这也是 general log 之所以"通用"的原因吧,由于数据库操作命令有可能非常多而且执行比较频繁,所以当开启了查询日志以后,数据库可能需要不停的写入查询日志,这样会增大服务器的IO压力,增加很多系统开销,所以默认情况下,mysql的查询日志是没有开启的,但是开启查询日志也有助于我们分析哪些语句执行密集,执行密集的select语句对应的数据是否能够被缓存,查询日志也可以帮助我们分析问题,所以,我们可以根据实际情况决定是否开启查询日志,如果需要可以手动开启。如果开启了查询日志,那么我们可以通过如下3种方式存储查询日志。
方式1:将查询日志存放于指定的日志文件中。
方式2:将查询日志存放于
mysql.general_log表中。方式3:将查询日志同时存放于指定的日志文件与mysql库的general_log表中。
查看查询日志是否开启
show VARIABLES LIKE 'general_log';复制代码

show variables where variable_name like "%general_log%" or variable_name="log_output";复制代码

general_log:表示查询日志是否开启,ON表示开启,OFF表示未开启,默认为OFF
log_output:表示当查询日志开启以后,以哪种方式存放,log_output可以设置为4种值,"FILE"、"TABLE"、"FILE,TABLE"、"NONE"。
# 设置查询日志的输出方式 set global log_output=[none|file|table|file,table]; # 设置general log的日志文件路径 set global general_log_file='/tmp/general.log'; # 开启general log set global general_log=on; # 关闭general log set global general_log=off;复制代码
2.2 慢日志
所谓的慢查询就是通过设置来记录超过一定时间的SQL语句!
开启MySQL的慢查询日志功能
# 查看是否开启 未使用索引的SQL记录日志查询 show variables like 'log_queries_not_using_indexes'; # 开启 未使用索引的SQL记录日志查询 set global log_queries_not_using_indexs=on/off; # 查看超过多长时间的查询记入慢查询日志中 show variables like 'long_query_time'; # 设置记录时长,0为全部记录,设置之后需重新启动 set global long_query_time=10 # 查看是否开启 mysql慢查询日志功能 show variables like 'slow_qurey_log' # 开启、关闭慢日志 set global slow_qurey_log=on/off; # 查看日志记录位置 show variables like 'slow_query_log_file'; #日志存储方式 show variables like "log_output";复制代码
- flie方式
select sleep(10) 执行完成查看日志
# Time: 2020-10-26T05:12:09.564006Z # User@Host: root[root] @ localhost [] Id: 12 # Query_time: 10.000272 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 1 SET timestamp=1603689119; select sleep(10);复制代码
-
table方式

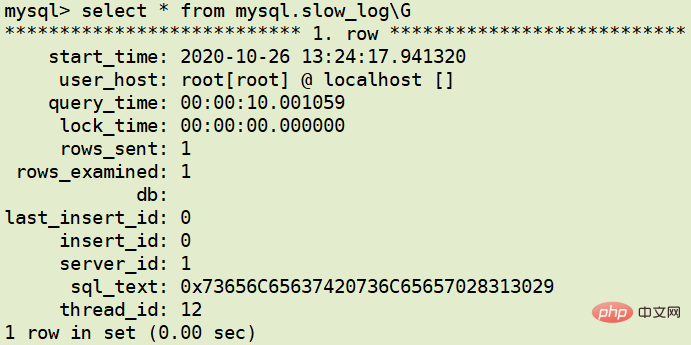
日志分析工具 mysqldumpslow
查看 mysqldumpslow 的帮助信息:
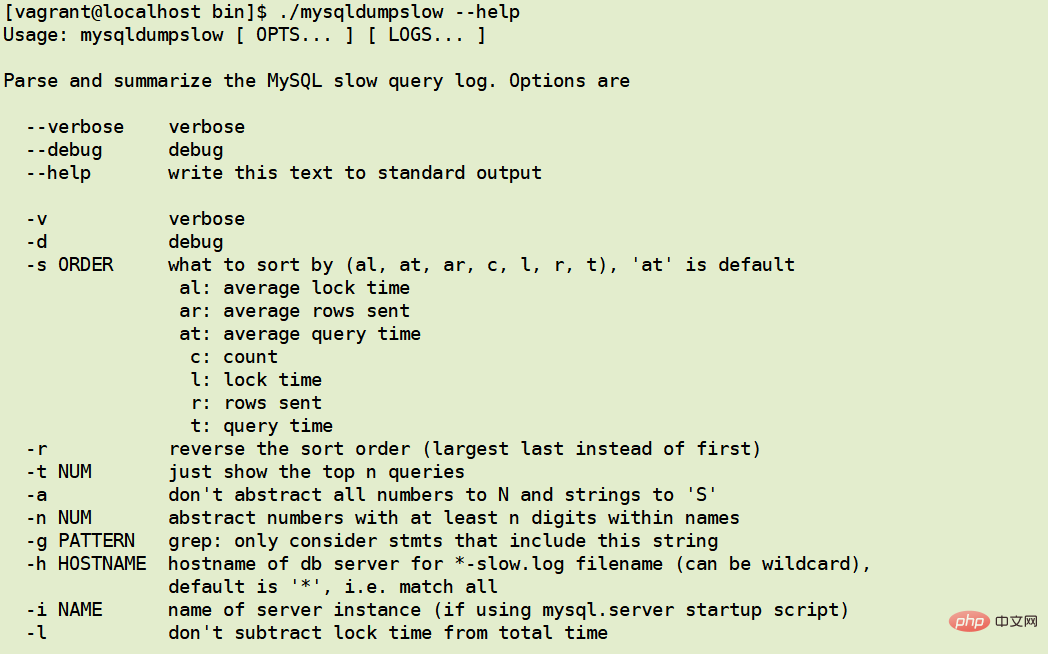
-s ORDER ORDER排序依据(al,at,ar,c,l,r,t),“at”是默认值 al: 平均锁定时间 ar: 平均发送行数 at: 平均查询时间 c: 计数 l: 锁定时间 r: 已发送行 t: 查询时间 -r 反转排序顺序(最大的最后一个而不是第一个) -t NUM 只显示前n个查询 -a 不要将所有数字抽象为N,将字符串抽象为“S” -n NUM 名字中至少有n个数字的抽象数字 -g PATTERN grep: 只考虑包含此字符串的记录 -h HOSTNAME hostname of db server for *-slow.log filename (can be wildcard), default is '*', i.e. match all -i NAME name of server instance (if using mysql.server startup script) -l don't subtract lock time from total time复制代码
2.3 错误日志
错误日志(Error Log)是 MySQL 中最常用的一种日志,主要记录 MySQL 服务器启动和停止过程中的信 息、服务器在运行过程中发生的故障和异常情况等。
# 查看错误日志记录位置
show variables like "log_error";
# 在 MySQL 中,可以使用 mysqladmin 命令来开启新的错误日志,以保证 MySQL 服务器上的硬盘空间。
# mysqladmin 命令的语法如下:
mysqladmin -uroot -p flush-logs
# 执行该命令后,MySQL 服务器首先会自动创建一个新的错误日志,然后将旧的错误日志更名为 filename.err-old 。可以手动直接删除。
#配置文件中配置
[mysqld]
log-error=dir/{filename}复制代码2.4 二进制日志
二进制日志(Binary Log)也可叫作变更日志(Update Log),是 MySQL 中非常重要的日志。主要用于记录数据库的变化情况,即 SQL 语句的 DDL 和 DML 语句,不包含数据记录查询操作。
# 查看 binary log 日志是否开启,binary log日志默认关闭
show variables like "log_bin";
# 在MySQL中可以再配置文件中开启二进制文件日志
[mysqld]
log-bin=dir/{filename}复制代码其中,dir 参数指定二进制文件的存储路径;filename 参数指定二进制文件的文件名,其形式为 filename.number,number 的形式为 000001、000002 等,每次重启 MySQL 服务后,都会生成一个新的二进制日志文件,这些日志文件的文件名中 filename 部分不会改变,number 会不断递增。
二进制日志的格式有三种:STATEMENT,ROW,MIXED。
① STATEMENT模式(SBR)
每一条会修改数据的 sql 语句会记录到 binlog 中。优点是并不需要记录每一条 sql 语句和每一行的数据变化, 减少了 binlog 日志量,节约 IO ,提高性能。缺点是在某些情况下会导致 master-slave 中的数据不一致(如 sleep() 函数, last_insert_id() ,以及 user-defined functions(udf) 等会出现问题)复制代码
② ROW模式(RBR)
不记录每条 sql 语句的上下文信息,仅需记录哪条数据被修改了,修改成什么样了。而且不会出现某些特定情况下 的存储过程、或 function 、或 trigger 的调用和触发无法被正确复制的问题。缺点是会产生大量的日志,尤其是 alter table的时候会让日志暴涨。复制代码
③ MIXED模式(MBR)
以上两种模式的混合使用,一般的复制使用 STATEMENT 模式保存 binlog ,对于 STATEMENT 模式无法复制的操作使用 ROW 模式保存 binlog , MySQL 会根据执行的 SQL 语句选择日志保存方式。复制代码
binlog复制配置
在mysql的配置文件 my.cnf 或中,可以通过一下选项配置 binary log
binlog_format = MIXED //binlog日志格式,mysql默认采用statement,建议使用mixed log-bin = mysql-bin //binlog日志文件 expire_logs_days = 7 //binlog过期清理时间 max_binlog_size = 100m //binlog每个日志文件大小 binlog_cache_size = 4m //binlog缓存大小 max_binlog_cache_size = 512m //最大binlog缓存大小 server-id = 1复制代码
2.5二进制文件基本操作
可以使用如下命令查看 MySQL 中有哪些二进制日志文件:
show binary logsshow master status命令用来查看当前的二进制日志;二进制日志使用二进制格式存储,不能直接打开查看。如果需要查看二进制日志,使用
show binlog events in 'mysql-bin.000001';命令。-
删除二进制文件
- 使用
RESET MASTER语句可以删除的所有二进制日志 - 每个二进制日志文件后面有一个 6 位数的编号,如 000001。使用
PURGE MASTER LOGS TO 'filename.number'语句,可以删除指定二进制日志的编号之前的日志 - 使用
PURGE MASTER LOGS TO 'yyyy-mm-dd hh:MM:ss'语句,可以删除指定时间之前创建的二进制日志
- 使用
-
使用二进制文件恢复数据
-
创建数据库
CREATE TABLE `33hao_activity` ( `activity_id` mediumint(9) NOT NULL AUTO_INCREMENT COMMENT 'id', `activity_title` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '标题', `activity_type` enum('1','2') CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '活动类型 1:商品 2:团购', `activity_banner` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '活动横幅大图片', `activity_style` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '活动页面模板样式标识码', `activity_desc` varchar(1000) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '描述', `activity_start_date` int(10) UNSIGNED NOT NULL DEFAULT 0 COMMENT '开始时间', `activity_end_date` int(10) UNSIGNED NOT NULL DEFAULT 0 COMMENT '结束时间', `activity_sort` tinyint(1) UNSIGNED NOT NULL DEFAULT 255 COMMENT '排序', `activity_state` tinyint(1) UNSIGNED NOT NULL DEFAULT 1 COMMENT '活动状态 0为关闭 1为开启', PRIMARY KEY (`activity_id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '活动表' ROW_FORMAT = Compact;复制代码Copier après la connexion -
新增 2 条数据
INSERT INTO `33hao_activity` VALUES (1, '2017年跨年满即送活动', '1', '05364373801675235.jpg', 'default_style', '', 1483113600, 1483286400, 0, 0); INSERT INTO `33hao_activity` VALUES (2, '转盘抽奖弹窗', '1', '06480453986921327.jpg', '', '转盘抽奖弹窗', 1594656000, 1594915200, 0, 0);复制代码
Copier après la connexion -
删除数据
drop table `33hao_activity`;复制代码
Copier après la connexion -
恢复数据
-
根据节点需要我们查看日志文件提供给我们的数据库创建,表创建,数据新增等时创建的语句节点,从而恢复数据。
mysqlbinlog --start-position=154 --stop-position=2062 D:/phpstudy_pro/Extensions/MySQL5.7.26/data/mysql-bin.000001 | mysql -uroot -p复制代码
Copier après la connexion -
根据时间恢复数据
mysqlbinlog --start-datetime='2020-09-27 22:22:22' --stop-datetime='2020-09-27 22:30:00' /www/server/data/mysql-bin.000036 | mysql -uroot -p复制代码
Copier après la connexion -
直接执行binlog日志
mysqlbinlog /www/server/data/mysql-bin.000036 | mysql -uroot -p复制代码
Copier après la connexion
-
-
更多相关免费学习推荐:mysql教程(视频)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 La relation entre l'utilisateur de MySQL et la base de données
Apr 08, 2025 pm 07:15 PM
La relation entre l'utilisateur de MySQL et la base de données
Apr 08, 2025 pm 07:15 PM
Dans la base de données MySQL, la relation entre l'utilisateur et la base de données est définie par les autorisations et les tables. L'utilisateur a un nom d'utilisateur et un mot de passe pour accéder à la base de données. Les autorisations sont accordées par la commande Grant, tandis que le tableau est créé par la commande Create Table. Pour établir une relation entre un utilisateur et une base de données, vous devez créer une base de données, créer un utilisateur, puis accorder des autorisations.
 MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL a une version communautaire gratuite et une version d'entreprise payante. La version communautaire peut être utilisée et modifiée gratuitement, mais le support est limité et convient aux applications avec des exigences de stabilité faibles et des capacités techniques solides. L'Enterprise Edition fournit une prise en charge commerciale complète pour les applications qui nécessitent une base de données stable, fiable et haute performance et disposées à payer pour le soutien. Les facteurs pris en compte lors du choix d'une version comprennent la criticité des applications, la budgétisation et les compétences techniques. Il n'y a pas d'option parfaite, seulement l'option la plus appropriée, et vous devez choisir soigneusement en fonction de la situation spécifique.
 Intégration RDS MySQL avec Redshift Zero ETL
Apr 08, 2025 pm 07:06 PM
Intégration RDS MySQL avec Redshift Zero ETL
Apr 08, 2025 pm 07:06 PM
Simplification de l'intégration des données: AmazonrDSMysQL et l'intégration Zero ETL de Redshift, l'intégration des données est au cœur d'une organisation basée sur les données. Les processus traditionnels ETL (extrait, converti, charge) sont complexes et prennent du temps, en particulier lors de l'intégration de bases de données (telles que AmazonrDSMysQL) avec des entrepôts de données (tels que Redshift). Cependant, AWS fournit des solutions d'intégration ETL Zero qui ont complètement changé cette situation, fournissant une solution simplifiée et à temps proche pour la migration des données de RDSMySQL à Redshift. Cet article plongera dans l'intégration RDSMYSQL ZERO ETL avec Redshift, expliquant comment il fonctionne et les avantages qu'il apporte aux ingénieurs de données et aux développeurs.
 Comment remplir le nom d'utilisateur MySQL et le mot de passe
Apr 08, 2025 pm 07:09 PM
Comment remplir le nom d'utilisateur MySQL et le mot de passe
Apr 08, 2025 pm 07:09 PM
Pour remplir le nom d'utilisateur et le mot de passe MySQL: 1. Déterminez le nom d'utilisateur et le mot de passe; 2. Connectez-vous à la base de données; 3. Utilisez le nom d'utilisateur et le mot de passe pour exécuter des requêtes et des commandes.
 L'optimisation des requêtes dans MySQL est essentielle pour améliorer les performances de la base de données, en particulier lorsqu'elle traite avec de grands ensembles de données
Apr 08, 2025 pm 07:12 PM
L'optimisation des requêtes dans MySQL est essentielle pour améliorer les performances de la base de données, en particulier lorsqu'elle traite avec de grands ensembles de données
Apr 08, 2025 pm 07:12 PM
1. Utilisez l'index correct pour accélérer la récupération des données en réduisant la quantité de données numérisées SELECT * FROMMLOYEESEESHWHERELAST_NAME = 'SMITH'; Si vous recherchez plusieurs fois une colonne d'une table, créez un index pour cette colonne. If you or your app needs data from multiple columns according to the criteria, create a composite index 2. Avoid select * only those required columns, if you select all unwanted columns, this will only consume more server memory and cause the server to slow down at high load or frequency times For example, your table contains columns such as created_at and updated_at and timestamps, and then avoid selecting * because they do not require inefficient query se
 Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.
 Comment copier et coller Mysql
Apr 08, 2025 pm 07:18 PM
Comment copier et coller Mysql
Apr 08, 2025 pm 07:18 PM
Copier et coller dans MySQL incluent les étapes suivantes: Sélectionnez les données, copiez avec Ctrl C (Windows) ou CMD C (Mac); Cliquez avec le bouton droit à l'emplacement cible, sélectionnez Coller ou utilisez Ctrl V (Windows) ou CMD V (Mac); Les données copiées sont insérées dans l'emplacement cible ou remplacer les données existantes (selon que les données existent déjà à l'emplacement cible).
 Comment voir Mysql
Apr 08, 2025 pm 07:21 PM
Comment voir Mysql
Apr 08, 2025 pm 07:21 PM
Affichez la base de données MySQL avec la commande suivante: Connectez-vous au serveur: MySQL -U Username -P mot de passe Exécuter les bases de données Afficher les bases de données; Commande pour obtenir toutes les bases de données existantes Sélectionnez la base de données: utilisez le nom de la base de données; Tableau de vue: afficher des tables; Afficher la structure de la table: décrire le nom du tableau; Afficher les données: sélectionnez * dans le nom du tableau;
