

Une brève analyse de Buffer dans NodeJS


Recommandations associées : "tutoriel node js"
À l'époque, j'ai lu Nine Lights et One Deep NodeJS de Pu Ling pour obtenir a commencé avec Node. , le livre de Park Dada parle très peu de pratique et consacre plus d'espace à l'explication des principes. Après avoir écouté tant de principes, il a ensuite commencé à utiliser NodeJS dans le domaine de l'ingénierie front-end mais a été gêné partout. , il a découvert que la partie difficile de NodeJS n'est rien d'autre que les fichiers et les fichiers. La mise en réseau, les opérations sur les fichiers et la mise en réseau reposent toutes sur un objet très important - Stream, ce que Park n'a pas mentionné dans son livre.
Buffer Park Dada l'a mentionné dans le livre, mais comme le flux traite réellement le Buffer, il doit encore être brièvement résumé.
Qu'est-ce que Buffer
Comme introduit dans l'API officielle, avant que ES6 n'introduise TypedArray, JavaScript n'avait aucun mécanisme pour lire ou exploiter les flux de données binaires. La classe Buffer a été introduite dans le cadre de l'API NodeJS pour pouvoir interagir avec les flux réseau tels que TCP et les flux de fichiers.
Maintenant que TypedArray a été ajouté à ES6, la classe Buffer implémente l'API Unit8Array d'une manière plus optimisée et adaptée aux opérations NodeJS.
En bref, la classe Buffer est utilisée pour traiter des données binaires. Parce qu'elle est si couramment utilisée, elle est placée directement dans une variable globale. Il n'est pas nécessaire de l'utiliser.
Les instances de la classe Buffer sont similaires aux tableaux d'entiers, mais la taille du tampon est déterminée lors de sa création et ne peut pas être ajustée. La différence avec l'objet Buffer est qu'il ne passe pas par le mécanisme d'allocation de mémoire de V8. Buffer est un module qui combine JavaScript et C++. La mémoire est demandée par C++ et allouée par JavaScript.
Nous ne discuterons pas des connaissances connexes sur l'allocation de mémoire tampon. Les étudiants intéressés peuvent lire le livre de Park Laoshi.
Instantiate Buffer
Avant NodeJS v6, Buffer était instancié en appelant le constructeur, renvoyant des résultats différents selon les paramètres. Pour des raisons de sécurité, cette méthode a été supprimée dans les versions postérieures à la v6, fournissant
- Buffer.from()
- Buffer.alloc()
- Buffer.allocUnsafe( )
Trois fonctions distinctes avec des responsabilités claires gèrent le travail d'instanciation de Buffer.
- Buffer.from(array) : renvoie un tampon contenant une copie des octets fournis. Chaque élément du tableau est un nombre représentant un octet, la valeur doit donc être comprise entre 0 et 255. sinon ce sera modulo
- Buffer.from(arrayBuffer) : renvoie un nouveau Buffer qui partage la mémoire avec l'ArrayBuffer donné
- Buffer.from(buffer) : renvoie le Buffer donné Une copie de Buffer
- Buffer.from(string [, encoding]) : renvoie un Buffer
- Buffer.alloc(size [, fill [, encoding]]) contenant la chaîne donnée : Renvoie un Buffer du taille spécifiée et "rempli"
- Buffer.allocUnsafe(size) : renvoie un Buffer de la taille spécifiée, le contenu doit être rempli avec des méthodes telles que buf.fill(0)
// 0x 表示 16 进制
Buffer.from([1, 2, 3]) // [0x1, 0x2, 0x3]
Buffer.from('test', 'utf-8') // [0x74, 0x65, 0x73, 0x74]
Buffer.alloc(5, 1) // [0x1, 0x1, 0x1, 0x1, 0x1]
Buffer.allocUnsafe(5); // 值不确定,后面详谈Buffer.allocUnsafe() s'exécutera plus rapidement que Buffer.alloc() Il n'est pas sûr de lire le nom, ce n'est en effet pas sûr.
Le segment de mémoire alloué lors de l'appel de Buffer.allocUnsafe() n'a pas été initialisé (pas réinitialisé à zéro), donc la vitesse d'allocation de mémoire est très lente, mais le segment de mémoire alloué peut contenir d'anciennes données. Si vous n'écrasez pas ces anciennes données lors de son utilisation, cela peut provoquer des fuites de mémoire. Bien que ce soit rapide, essayez d'éviter de l'utiliser.
Encodage
Buffer prend en charge les formats d'encodage suivants
- ascii
- utf8
- utf16le
- base64
- binaire
- hex
La conversion de tampon et de chaîne
String to Buffer est relativement simple
Buffer.from(string [, encoding])
En même temps, l'instance Buffer dispose également d'une méthode toString pour convertir le Buffer en chaîne
buf.toString([encoding[, start[, end]]])
Épissage du tampon
Utiliser la méthode concat pour parler de plusieurs instances Buffer sont fusionnées en une seule instance Buffer
Buffer.concat(list[, totalLength])
StringDecoder
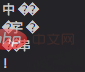
Dans NodeJS, un caractère chinois est représenté par trois octets If. nous utilisons autre chose que 3 lors du traitement des caractères chinois. Des multiples du nombre d'octets provoqueront des problèmes d'épissage de caractères tronqués.
const buf = Buffer.from('中文字符串!');
for(let i = 0; i < buf.length; i+=5){
var b = Buffer.allocUnsafe(5);
buf.copy(b, 0, i);
console.log(b.toString());
}Vous pouvez voir qu'il y a des caractères tronqués dans les résultats
Mais si vous utilisez le module string_decoder, vous pouvez résoudre ce problème
const StringDecoder = require('string_decoder').StringDecoder;
const decoder = new StringDecoder('utf8');
const buf = Buffer.from('中文字符串!');
for(let i = 0; i < buf.length; i+=5){
var b = Buffer.allocUnsafe(5);
buf.copy(b, 0, i);
console.log(decoder.write(b));
}StringDecoder in Après avoir obtenu l'encodage, nous savons que les octets larges occupent 3 octets sous UTF-8, donc lors du traitement des octets incomplets à la fin, ils seront conservés jusqu'à la deuxième écriture(). Actuellement, seuls UTF-8, Base64 et UCS-2/UTF-16LE peuvent être traités.
Autres API Buffer couramment utilisées
Il existe également des API Buffer couramment utilisées
- Buffer.isBuffer : Détermine si l'objet est un Buffer
- Buffer.isEncoding : Détermine l'encodage de l'objet Buffer
- buf.length : Renvoie les octets de mémoire demandés pour cette instance Buffer Le nombre n'est pas le nombre d'octets du contenu de l'instance Buffer
- buf.indexOf : similaire à l'indexOf du tableau, renvoie la position d'une chaîne, d'un code acsii ou d'un buf dans le buf modifié
- buf. copy : copiez (une partie de) le contenu d'un buf vers un autre buf
Pour plus de connaissances sur la programmation, veuillez visiter : Vidéo de programmation ! !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1358
1358
 52
52

 La différence entre nodejs et tomcat
Apr 21, 2024 am 04:16 AM
La différence entre nodejs et tomcat
Apr 21, 2024 am 04:16 AM
Les principales différences entre Node.js et Tomcat sont : Runtime : Node.js est basé sur le runtime JavaScript, tandis que Tomcat est un conteneur de servlet Java. Modèle d'E/S : Node.js utilise un modèle asynchrone non bloquant, tandis que Tomcat est un modèle de blocage synchrone. Gestion de la concurrence : Node.js gère la concurrence via une boucle d'événements, tandis que Tomcat utilise un pool de threads. Scénarios d'application : Node.js convient aux applications en temps réel, gourmandes en données et à forte concurrence, et Tomcat convient aux applications Web Java traditionnelles.
 La différence entre nodejs et vuejs
Apr 21, 2024 am 04:17 AM
La différence entre nodejs et vuejs
Apr 21, 2024 am 04:17 AM
Node.js est un environnement d'exécution JavaScript côté serveur, tandis que Vue.js est un framework JavaScript côté client permettant de créer des interfaces utilisateur interactives. Node.js est utilisé pour le développement côté serveur, comme le développement d'API de service back-end et le traitement des données, tandis que Vue.js est utilisé pour le développement côté client, comme les applications monopage et les interfaces utilisateur réactives.
 Nodejs est-il un framework backend ?
Apr 21, 2024 am 05:09 AM
Nodejs est-il un framework backend ?
Apr 21, 2024 am 05:09 AM
Node.js peut être utilisé comme framework backend car il offre des fonctionnalités telles que des performances élevées, l'évolutivité, la prise en charge multiplateforme, un écosystème riche et une facilité de développement.
 Comment connecter Nodejs à la base de données MySQL
Apr 21, 2024 am 06:13 AM
Comment connecter Nodejs à la base de données MySQL
Apr 21, 2024 am 06:13 AM
Pour vous connecter à une base de données MySQL, vous devez suivre ces étapes : Installez le pilote mysql2. Utilisez mysql2.createConnection() pour créer un objet de connexion contenant l'adresse de l'hôte, le port, le nom d'utilisateur, le mot de passe et le nom de la base de données. Utilisez connection.query() pour effectuer des requêtes. Enfin, utilisez connection.end() pour mettre fin à la connexion.
 Quelle est la différence entre les fichiers npm et npm.cmd dans le répertoire d'installation de nodejs ?
Apr 21, 2024 am 05:18 AM
Quelle est la différence entre les fichiers npm et npm.cmd dans le répertoire d'installation de nodejs ?
Apr 21, 2024 am 05:18 AM
Il existe deux fichiers liés à npm dans le répertoire d'installation de Node.js : npm et npm.cmd. Les différences sont les suivantes : différentes extensions : npm est un fichier exécutable et npm.cmd est un raccourci de fenêtre de commande. Utilisateurs Windows : npm.cmd peut être utilisé à partir de l'invite de commande, npm ne peut être exécuté qu'à partir de la ligne de commande. Compatibilité : npm.cmd est spécifique aux systèmes Windows, npm est disponible multiplateforme. Recommandations d'utilisation : les utilisateurs Windows utilisent npm.cmd, les autres systèmes d'exploitation utilisent npm.
 Nodejs est-il un langage de développement back-end ?
Apr 21, 2024 am 05:09 AM
Nodejs est-il un langage de développement back-end ?
Apr 21, 2024 am 05:09 AM
Oui, Node.js est un langage de développement backend. Il est utilisé pour le développement back-end, notamment la gestion de la logique métier côté serveur, la gestion des connexions à la base de données et la fourniture d'API.
 Quelles sont les variables globales dans nodejs
Apr 21, 2024 am 04:54 AM
Quelles sont les variables globales dans nodejs
Apr 21, 2024 am 04:54 AM
Les variables globales suivantes existent dans Node.js : Objet global : global Module principal : processus, console, nécessiter Variables d'environnement d'exécution : __dirname, __filename, __line, __column Constantes : undefined, null, NaN, Infinity, -Infinity
 Y a-t-il une grande différence entre nodejs et java ?
Apr 21, 2024 am 06:12 AM
Y a-t-il une grande différence entre nodejs et java ?
Apr 21, 2024 am 06:12 AM
Les principales différences entre Node.js et Java résident dans la conception et les fonctionnalités : Piloté par les événements ou piloté par les threads : Node.js est piloté par les événements et Java est piloté par les threads. Monothread ou multithread : Node.js utilise une boucle d'événements monothread et Java utilise une architecture multithread. Environnement d'exécution : Node.js s'exécute sur le moteur JavaScript V8, tandis que Java s'exécute sur la JVM. Syntaxe : Node.js utilise la syntaxe JavaScript, tandis que Java utilise la syntaxe Java. Objectif : Node.js convient aux tâches gourmandes en E/S, tandis que Java convient aux applications de grande entreprise.
