


Recommandation gratuite : Tutoriel vidéo Python
Cela fait longtemps que je n'ai pas écrit d'article sur les robots. J'ai écrit un code Python de 20 lignes pour explorer les skins de tous les héros dans Honor of Kings
, et la réponse a été forte. De nombreux étudiants voulaient que j'écrive un autre article sur l'exploration des skins pour le site officiel de League of Legends, mais c'est dû. aux nombreuses choses à faire, j'ai continué à le reporter, a été retardé jusqu'à présent, donc dans cet article, nous allons apprendre comment explorer tous les skins de héros dans League of Legends.
Explorer le code est très simple. Vous n'aurez peut-être besoin que d'écrire environ 30 lignes de haut en bas pour terminer, mais l'important est le processus d'analyse. Avant cela, comprenons d'abord ce qui est nécessaire pour cet article. .
Le premier est le module de requêtes, qui est un module qui simule les requêtes du navigateur Nous pouvons l'utiliser pour obtenir des informations sur la page Web, comme Baidu :
import requests url = 'http://www.baidu.com'response = requests.get(url)print(response.text)
Résultats de fonctionnement : 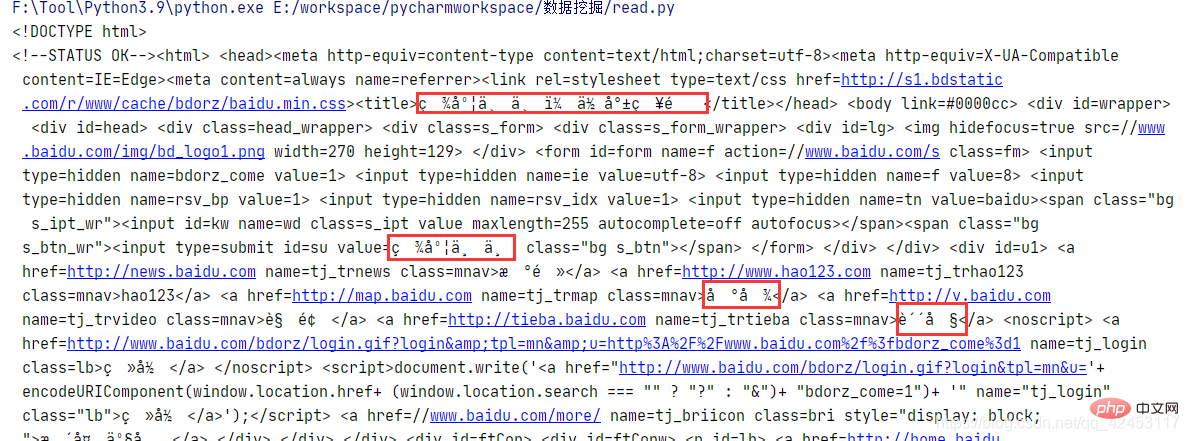
Grâce à la fonction get, vous pouvez envoyer une requête à l'URL avec les paramètres spécifiés. L'objet de réponse obtenu encapsule de nombreuses informations de réponse, et text est le contenu de la réponse. Notez qu'il y a des caractères tronqués dans le contenu acquis, ce qui est dû à une incohérence dans l'encodage et le décodage. Obtenez simplement les données binaires d'abord, puis décodez-les à nouveau :
import requests url = 'http://www.baidu.com'response = requests.get(url)print(response.content.decode())
Résultats en cours d'exécution. : 
le module json peut convertir les chaînes json et les types de données Python les uns vers les autres, comme la conversion de json en objets Python :
import json
json_str = '{"name":"zhangsan","age":"20"}'rs = json.loads(json_str)print(type(rs))print(rs)Utilisez la fonction loads pour convertir les caractères json La chaîne est convertie en type de dictionnaire, et le résultat en cours d'exécution est :
<class>
{'name': 'zhangsan', 'age': '20'}</class>Et si vous souhaitez convertir des données Python en chaîne json, c'est également très simple :
import json
str_dict = {'name': 'zhangsan', 'age': '20'}json_str = json.dumps(str_dict)print(type(json_str))print(json_str)Vous pouvez convertir les données Python via la dumps fonction est une chaîne json, le résultat en cours d'exécution est :
<class>
{"name": "zhangsan", "age": "20"}</class>Les deux modules introduits plus tôt, grâce à ces deux modules, nous pouvons compléter ce programme.
Avant de commencer officiellement à écrire du code, nous devons d'abord analyser la source de données, aller sur le site officiel : https://lol.qq.com/main.shtml, faites défiler vers le bas pour trouver la liste des héros :
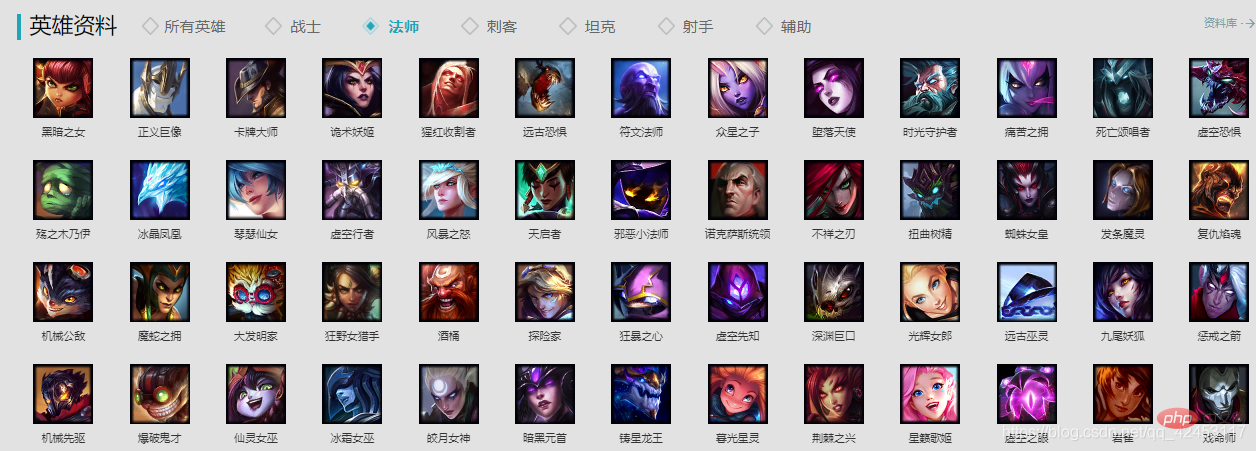
On clique sur un héros au hasard pour vérifier : 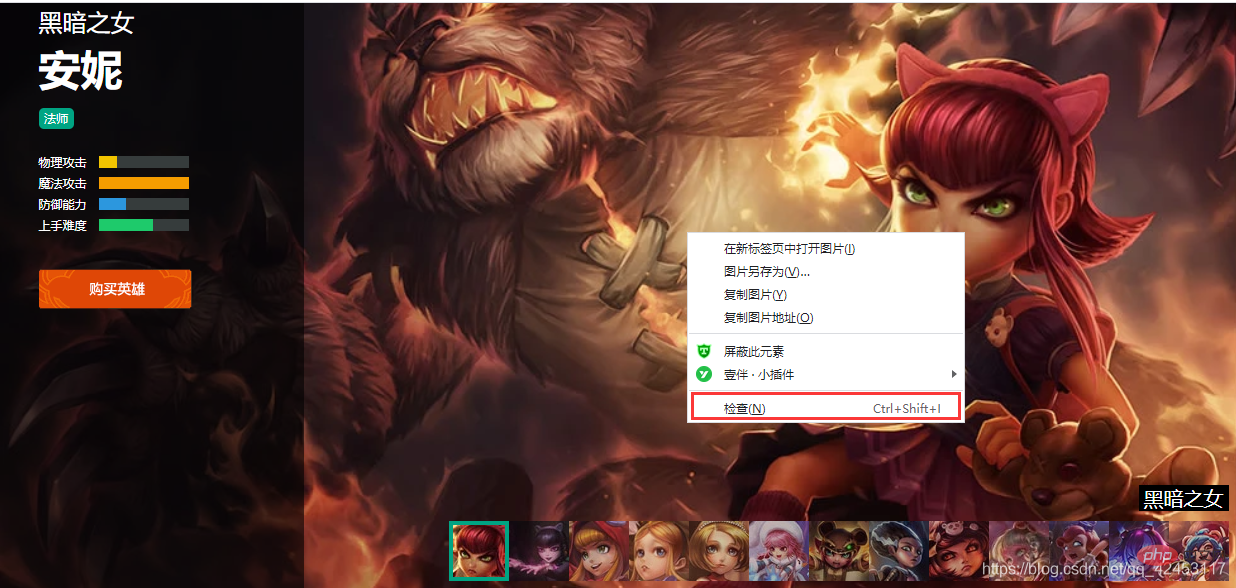
On fait un clic droit sur l'image du skin pour vérifier : 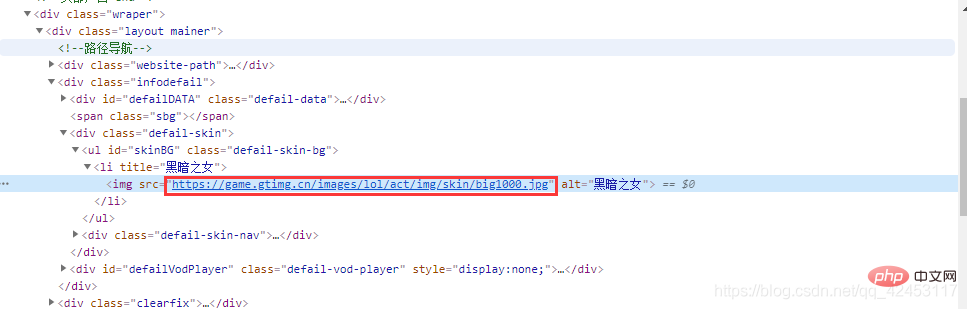
De cette façon, on retrouve l'url de ce skin, on sélectionne ensuite la seconde peau et on regarde son URL : 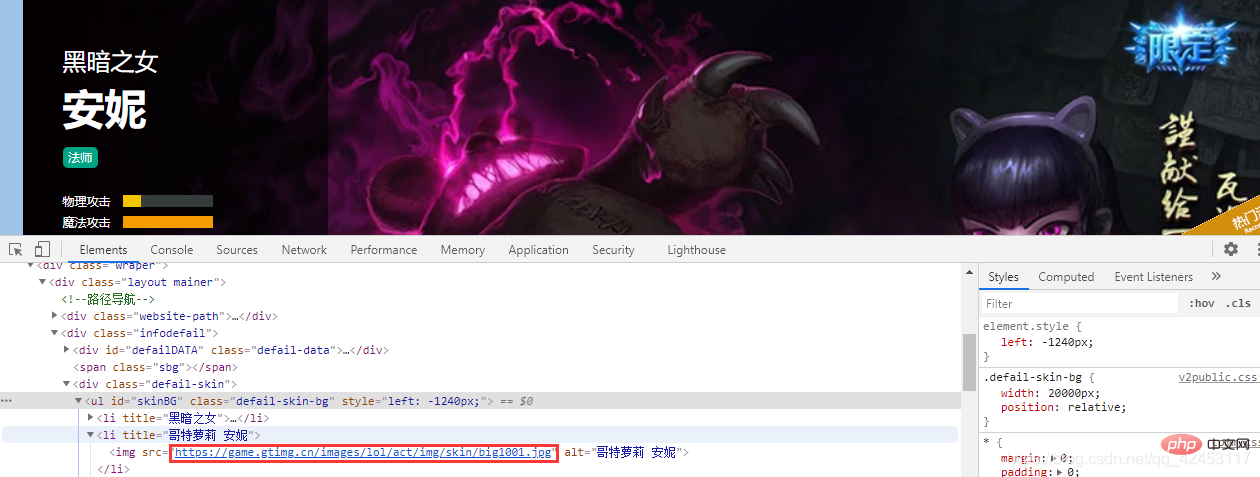
Jetons un oeil à toutes les URL des skins d'Annie :
https://game.gtimg.cn/images/lol/act/img/skin/big1000.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1001.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1002.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1003.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1004.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1005.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1006.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1007.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1008.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1009.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1010.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1011.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1012.jpg
De quels motifs peut-on trouver ces URL ? En fait, le modèle est très évident. Le contenu devant l'URL est le même. La seule différence est big1000.jpg, et chaque image de skin ajoute 1 à l'URL.
Alors la question est : comment distingue-t-on le héros auquel appartient cette image ? Nous observons l'adresse en haut du navigateur : 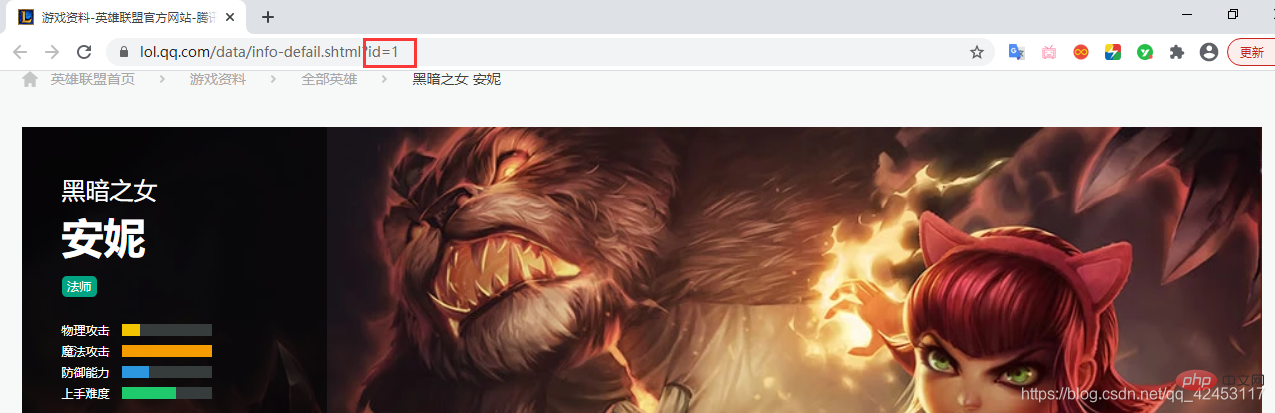
Il y a une valeur d'attribut id sur l'adresse, nous pouvons donc deviner si le big1000.jpg dans l'URL de l'image du skin est le même que celui du héros. id et le skin id. De quoi est-il composé ?
Pour prouver notre conjecture, nous devons voir si d'autres skins de héros remplissent également cette condition : 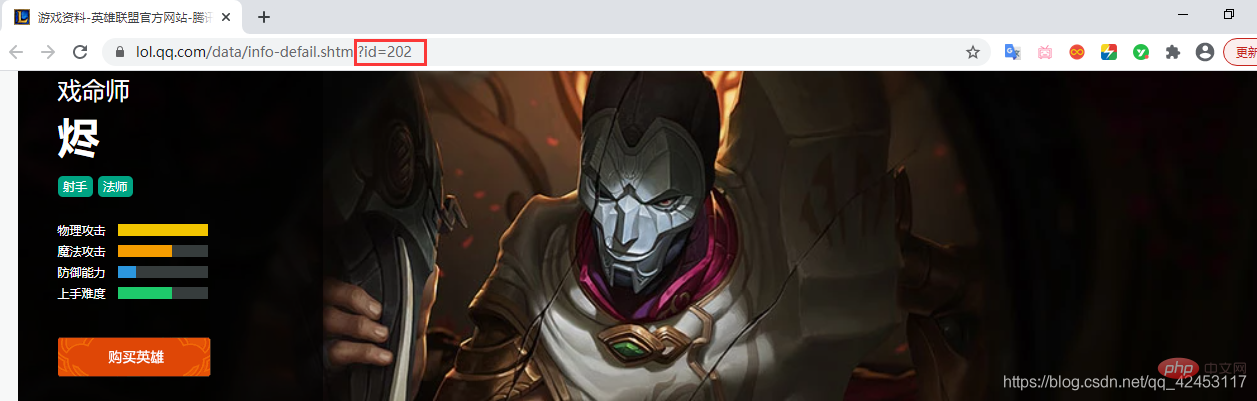
Ouvrez la page de détails de Jhin, son identifiant est 202, donc la dernière partie du skin de Jhin L'URL de l'image doit être : big ' + 202 + ' 皮肤编号.jpg, donc son URL doit être :
https://game.gtimg.cn/images/lol/act/img/skin/big202000.jpg https://game.gtimg.cn/images/lol/act/img/skin/big202001.jpg https://game.gtimg.cn/images/lol/act/img/skin/big202002.jpg https://game.gtimg.cn/images/lol/act/img/skin/big202003.jpg https://game.gtimg.cn/images/lol/act/img/skin/big202004.jpg https://game.gtimg.cn/images/lol/act/img/skin/big202005.jpg
事实是不是如此呢?检查一下便知: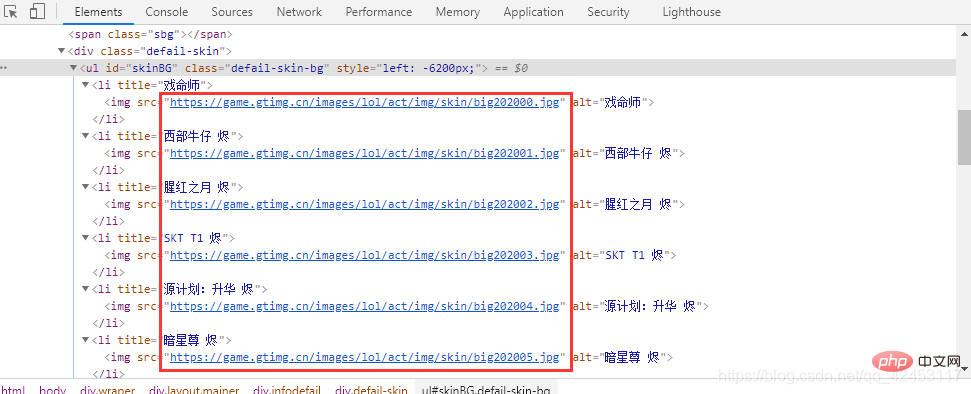
规律已经找到,但是我们还面临着诸多问题,比如每个英雄对应的id是多少呢?每个英雄又分别有多少个皮肤呢?
先来解决第一个问题,每个英雄对应的id是多少?我们只能从官网首页中找找线索,在首页位置打开网络调试台:
点击Network,并选中XHR,XHR是浏览器与服务器请求数据所依赖的对象,所以通过它便能筛选出一些服务器的响应数据。
此时我们刷新页面,在筛选出的内容发现了这么一个东西: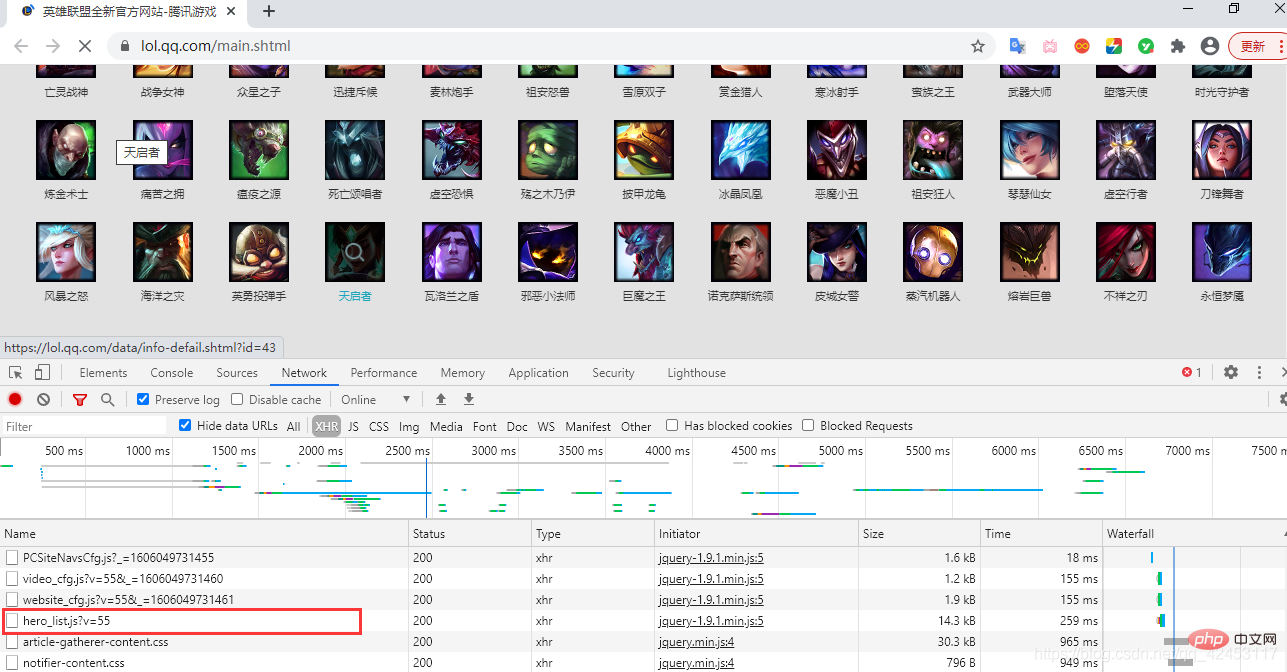
hero_list,英雄列表?这里面会不会存储着所有英雄的信息呢?
点击右侧的Response,得到了一串json字符串,我们将其解析一下: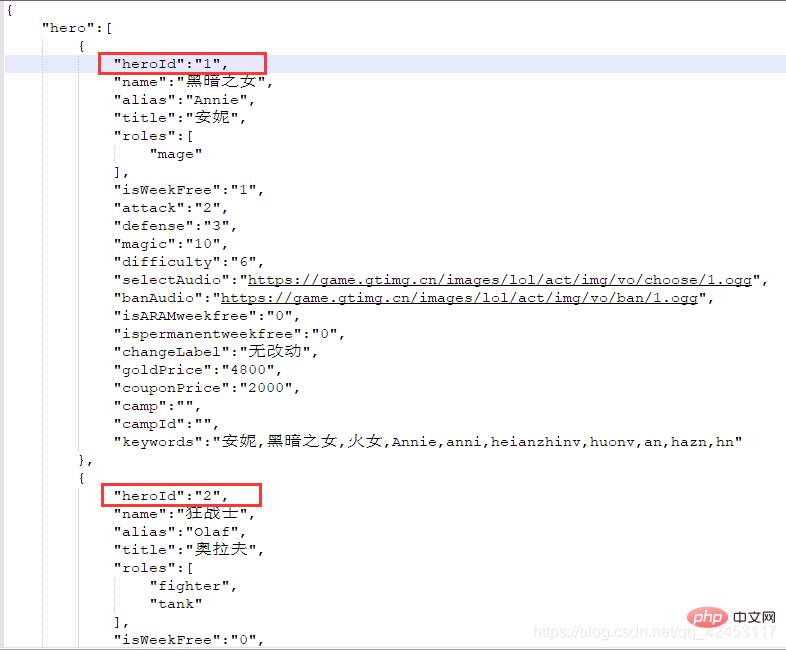
这些数据里果然存储的是英雄的信息,包括名字、id、介绍等等,那么接下来我们的任务就是将英雄名字和id单独提取出来,过滤掉其它信息。
忘了告诉你们了,这个文件的url在这里可以找到: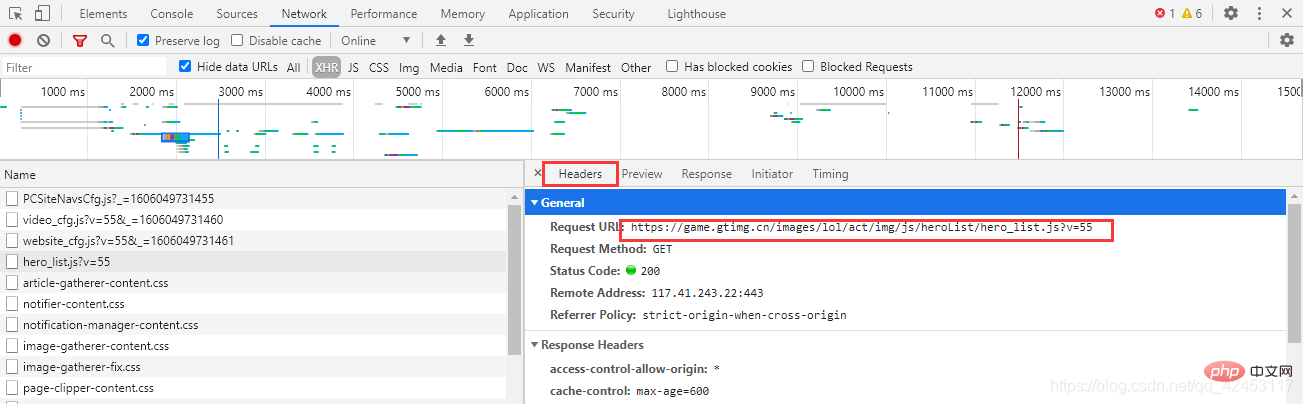
接下来开始写代码:
import jsonimport requests# 定义一个列表,用于存放英雄名称和对应的idhero_id = []url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js?v=20'response = requests.get(url)text = response.text# 将json字符串转为列表hero_list = json.loads(text)['hero']# 遍历列表for hero in hero_list:
# 定义一个字典
hero_dict = {'name': hero['name'], 'id': hero['heroId']}
# 将列表加入字典
hero_id.append(hero_dict)print(hero_id)首先通过requests模块请求该url,就能够获取到一个json字符串,然后使用json模块将该字符串转为Python中的列表,最后循环取出每个英雄的name和heroid属性,放入新定义的列表中,这个程序就完成了英雄id的提取。
接下来解决第二个问题,如何知晓某个英雄究竟有多少个皮肤,按照刚才的思路,我们可以猜测一下,对于皮肤也应该会有一个文件存储着皮肤信息,在某个英雄的皮肤页面打开网络调试台,并选中XHR,刷新页面,找找线索: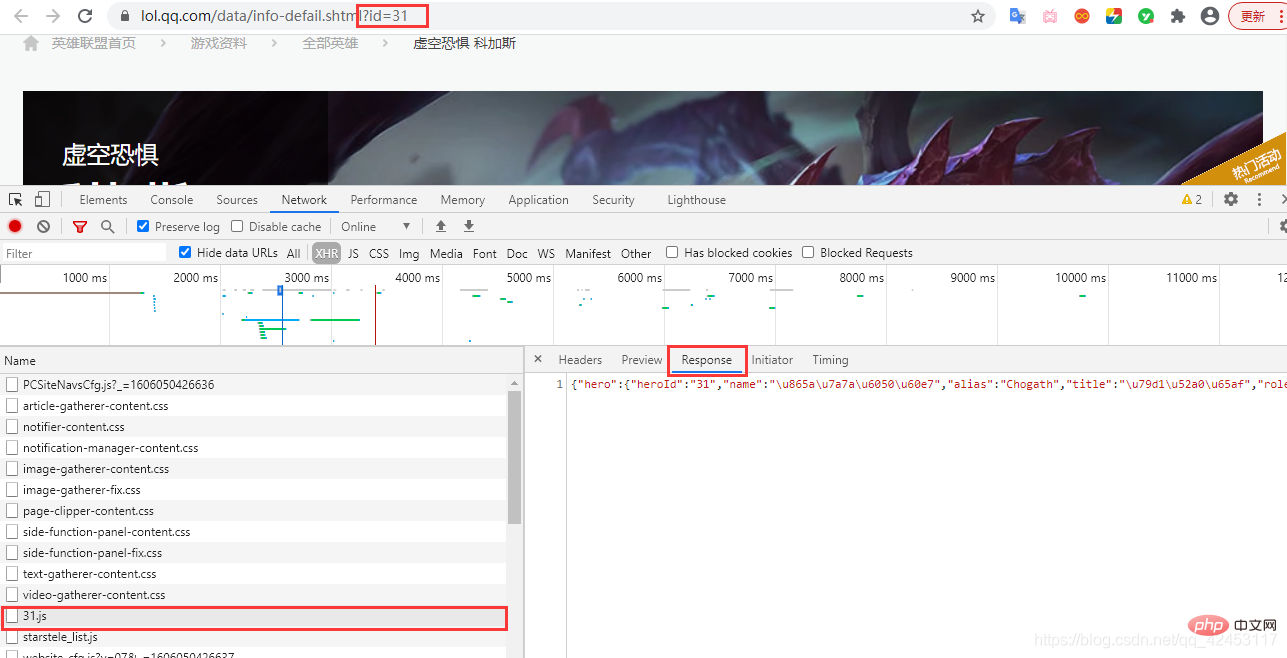
找来找去确实找不到有哪个文件是跟皮肤有关系的,但是这里发现了一个31.js文件,而当前英雄的id也为31,这真的是巧合吗?我们将右边的json字符串解析一下: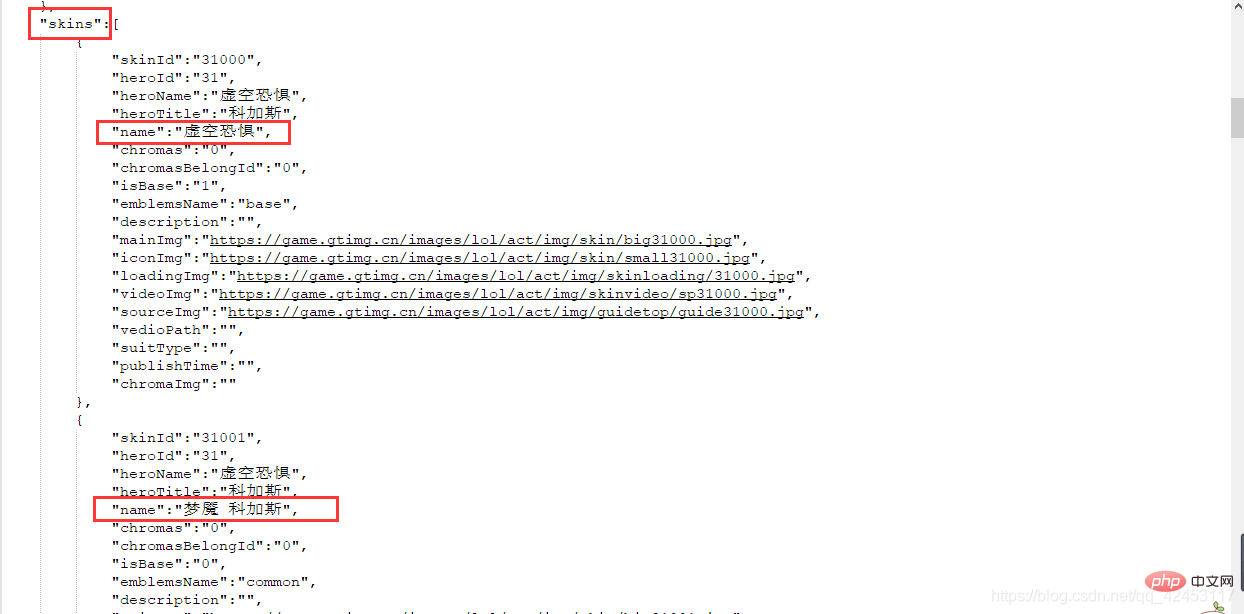
该json数据中有一个skins属性,该属性值即为当前英雄的皮肤信息,既然找到了数据,那接下来就好办了,开始写代码:
import jsonimport requests url = 'https://game.gtimg.cn/images/lol/act/img/js/hero/31.js'response = requests.get(url)text = response.text# 将json字符串转为列表skins_list = json.loads(text)['skins']skin_num = len(skins_list)
准备工作已经完成了我们所有的前置任务,接下来就是在此基础上编写代码了:
import requestsimport jsonimport osimport tracebackfrom tqdm import tqdmdef spider_lol():
# 定义一个列表,用于存放英雄名称和对应的id
hero_id = []
skins = []
url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js?v=20'
response = requests.get(url)
text = response.text # 将json字符串转为列表
hero_list = json.loads(text)['hero']
# 遍历列表
for hero in hero_list:
# 定义一个字典
hero_dict = {'name': hero['name'], 'id': hero['heroId']}
# 将列表加入字典
hero_id.append(hero_dict)
# 得到每个英雄对应的id后,即可获得英雄对应皮肤的url
# 英雄id + 001
# 遍历列表
for hero in hero_id:
# 得到英雄名字
hero_name = hero['name']
# 得到英雄id
hero_id = hero['id']
# 创建文件夹
os.mkdir('C:/Users/Administrator/Desktop/lol/' + hero_name)
# 进入文件夹
os.chdir('C:/Users/Administrator/Desktop/lol/' + hero_name)
# 得到id后即可拼接存储该英雄信息的url
hero_info_url = 'https://game.gtimg.cn/images/lol/act/img/js/hero/' + hero_id + '.js'
# 通过访问该url获取英雄的皮肤数量
text = requests.get(hero_info_url).text
info_list = json.loads(text)
# 得到皮肤名称
skin_info_list = info_list['skins']
skins.clear()
for skin in skin_info_list:
skins.append(skin['name'])
# 获得皮肤数量
skins_num = len(skin_info_list)
# 获得皮肤数量后,即可拼接皮肤的url,如:安妮的皮肤url为:
# https://game.gtimg.cn/images/lol/act/img/skin/big1000.jpg ~ https://game.gtimg.cn/images/lol/act/img/skin/big1012
s = ''
for i in tqdm(range(skins_num), '正在爬取' + hero_name + '的皮肤'):
if len(str(i)) == 1:
s = '00' + str(i)
elif len(str(i)) == 2:
s = '0' + str(i)
elif len(str(i)) == 3:
pass
try:
# 拼接皮肤url
skin_url = 'https://game.gtimg.cn/images/lol/act/img/skin/big' + hero_id + '' + s + '.jpg'
# 访问当前皮肤url
im = requests.get(skin_url)
except:
# 某些英雄的炫彩皮肤没有url,所以直接终止当前url的爬取,进入下一个
continue
# 保存图片
if im.status_code == 200:
# 判断图片名称中是否带有'/'、'\'
if '/' in skins[i] or '\\' in skins[i]:
skins[i] = skins[i].replace('/', '')
skins[i] = skins[i].replace('\\', '')
with open(skins[i] + '.jpg', 'wb') as f:
f.write(im.content)def main():
try:
spider_lol()
except Exception as e:
# 打印异常信息
print(e)if __name__ == '__main__':
main()运行效果: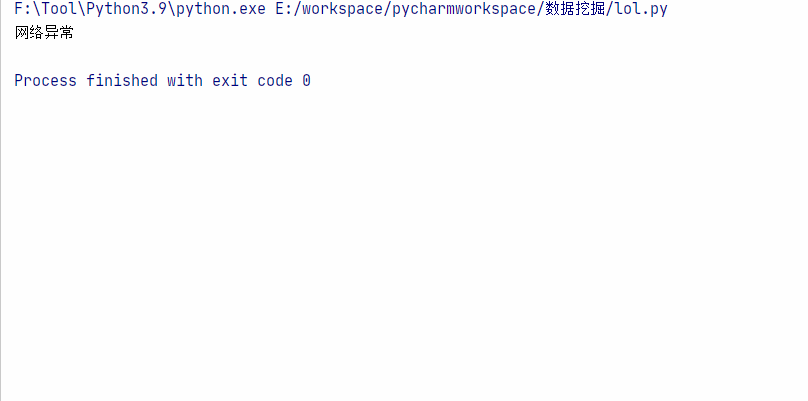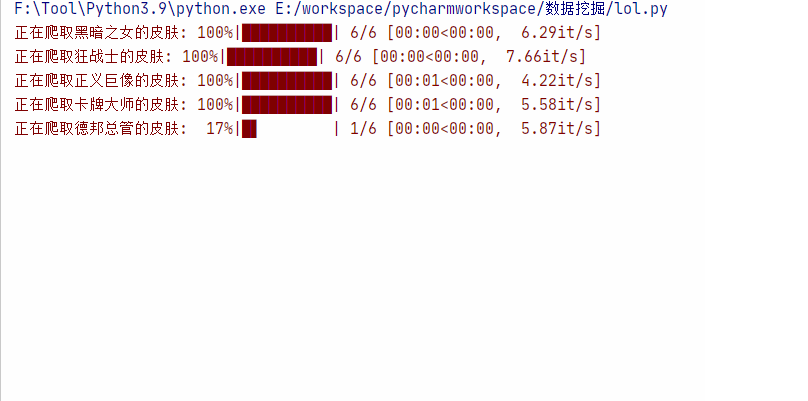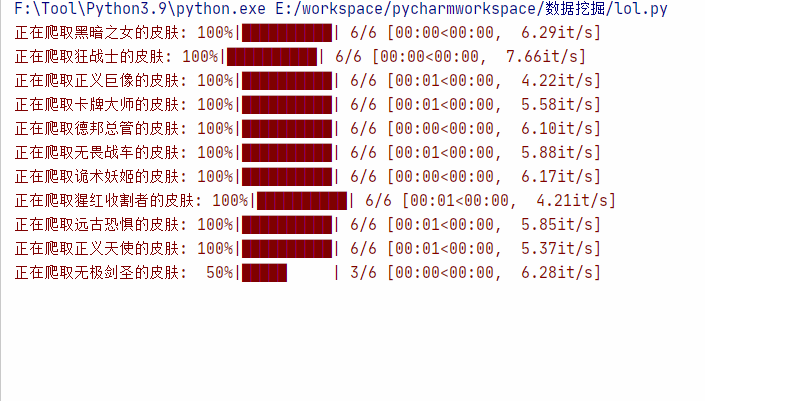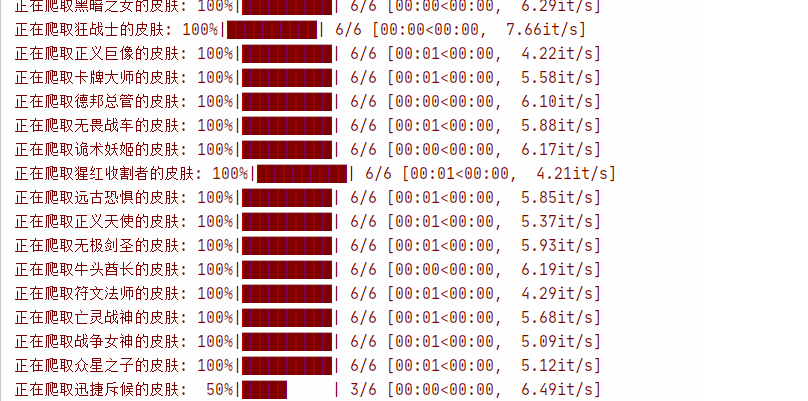
运行之前记得在桌面上创建一个lol文件夹,如果想改动的话也可以修改程序: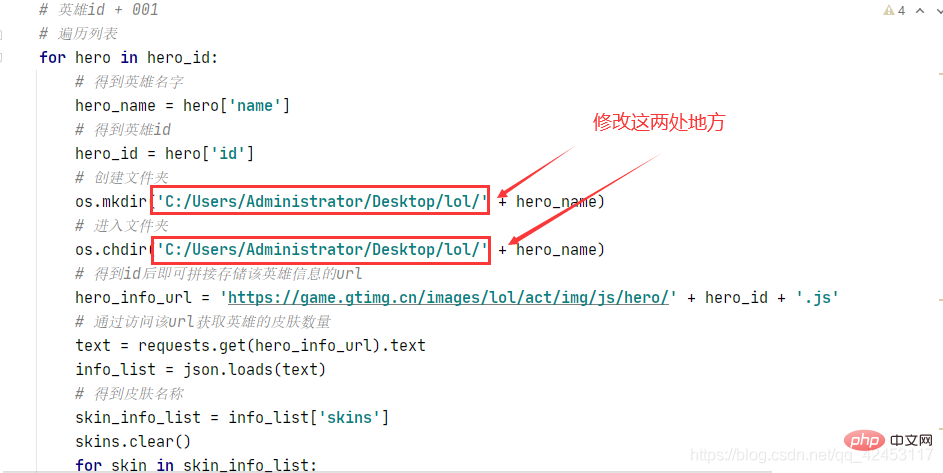
程序中还考虑到了一些其它情况,比如在爬取这个皮肤的时候会出现问题:
因为图片路径是以皮肤名字命名的,然而这个皮肤的名字中竟然有个/,它是会影响到我们的图片保存操作的,所以在保存前将斜杠替换成空字符即可。
还有一个问题就是即使是第一个皮肤,其编号也应该为000而不是0,所以还需要对其进行一个转化,让其始终是三位数。
本篇文章同样继承了上篇文章精简的特点,抛去注释的话总共30行代码左右,程序当然还有一些其它地方可以进一步优化,这就交给大家自由发挥了。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!


















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



