
 Java
JavaBase
Comprendre les niveaux de journaux Java, les enregistrements en double et les problèmes de perte de journaux
Java
JavaBase
Comprendre les niveaux de journaux Java, les enregistrements en double et les problèmes de perte de journaux
Comprendre les niveaux de journaux Java, les enregistrements en double et les problèmes de perte de journaux

Tutoriel Java BasicLa colonne présente comment résoudre des problèmes tels que les niveaux de journalisation Java

Recommandations d'apprentissage gratuites associées : Tutoriel Java Basic
1 Causes courantes de journalisation
1.1 Il existe de nombreux frameworks de journalisation
Différentes bibliothèques de classes peuvent utiliser différents frameworks de journalisation, et la compatibilité est un problème
1.2 La configuration est complexe et sujette aux erreurs
Les fichiers de configuration des journaux sont généralement très compliqués. De nombreux étudiants sont habitués à copier des fichiers de configuration directement à partir d'autres projets ou de blogs en ligne, mais ne le font pas. étudiez attentivement comment les modifier. Des erreurs courantes se produisent lors de la journalisation en double, des performances de la journalisation synchrone et de la mauvaise configuration de la journalisation asynchrone.
1.3 Il y a quelques malentendus dans la journalisation elle-même
Par exemple, le coût d'obtention du contenu du journal n'est pas pris en compte, le niveau de journalisation est utilisé sans discernement, etc.
2 SLF4J
Logback, Log4j, Log4j2, commons-logging, java.util.logging du JDK, etc. sont tous des frameworks de journalisation du système Java, et il y en a en effet beaucoup. Différentes bibliothèques de classes peuvent également choisir d'utiliser différents frameworks de journalisation. En conséquence, la gestion unifiée des journaux devient très difficile.
- SLF4J (Simple Logging Facade For Java) fournit une API de façade de journal unifiée pour résoudre ce problème
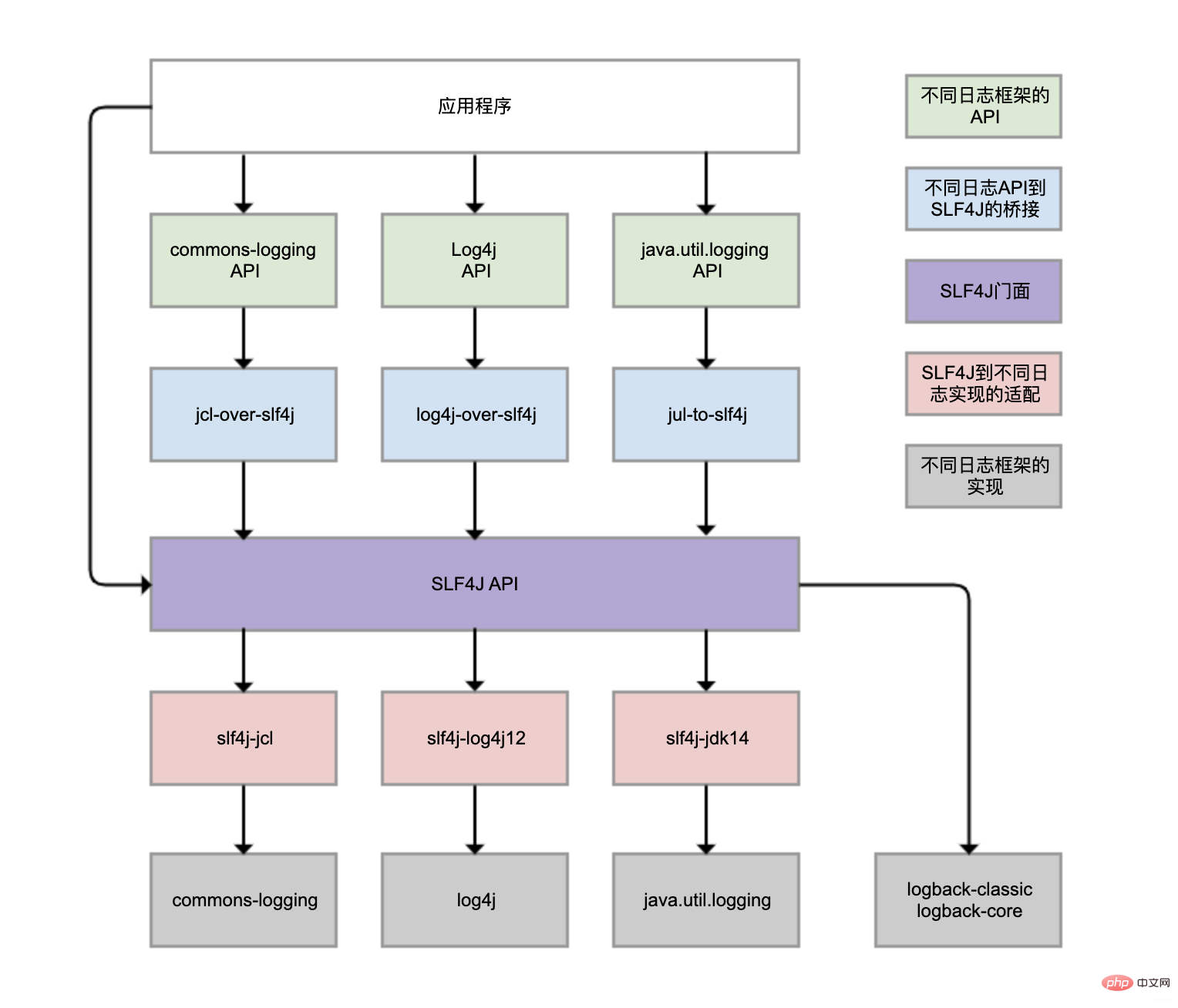
- C'est-à-dire , la partie violette de la figure implémente la fonction de pontage de l'API de journalisation neutre
- , et la partie bleue relie diverses API du cadre de journalisation (partie verte) à l'API SLF4J. De cette façon, même si vous utilisez diverses API de journalisation pour enregistrer les journaux dans votre programme, vous pouvez éventuellement accéder à l'API de façade SLF4J.
- La fonction d'adaptation, la partie rouge, peut réaliser la liaison entre l'API SLF4J et le framework de journalisation réel (partie grise).
SLF4J n'est qu'un standard de journalisation, nécessite-t-il toujours un véritable framework de journalisation ? Le framework de journalisation lui-même n'implémente pas l'API SLF4J, une pré-conversion est donc requise. Logback est implémenté selon la norme API SLF4J, il n'est donc pas nécessaire de lier des modules pour la conversion.
Bien que vous puissiez utiliser log4j-over-slf4j pour implémenter le pont Log4j vers SLF4J, vous pouvez également utiliser slf4j-log4j12 pour implémenter SLF4J pour vous adapter à Log4j, et les dessiner dans une colonne, mais il ne peut pas les utiliser en même temps, sinon cela créera une boucle infinie. Il en va de même pour jcl et jul.
Bien qu'il y ait 4 frameworks d'implémentation de journaux gris dans l'image, les plus utilisés dans les affaires quotidiennes sont Logback et Log4j, tous deux développés par la même personne. Logback peut être considéré comme une version améliorée de Log4j, qui est plus recommandée et fondamentalement courante.
Le framework de journalisation de Spring Boot est également Logback. Alors pourquoi pouvons-nous utiliser Logback directement sans introduire manuellement le package Logback ?
le module spring-boot-starter dépend despring-boot-starter-loggingmodule
spring-boot-starter-loggingle module introduit automatiquement logback -classic (contient SLF4J et le framework de journalisation Logback) et quelques adaptateurs pour SLF4J. Parmi eux, log4j-to-slf4j est utilisé pour relier l'API Log4j2 à SLF4J, et jul-to-slf4j est utilisé pour relier l'API java.util.logging à SLF4J.
3 Enregistrements de journaux en double
Les enregistrements de journaux en double entraînent non seulement des problèmes inutiles dans la visualisation des journaux et le travail statistique, mais augmentent également la charge sur le disque et le système de collecte de journaux.
La relation d'héritage de la configuration de l'enregistreur conduit à un enregistrement de journal en double
Définir une méthode pour implémenter l'enregistrement des journaux de débogage, d'informations, d'avertissement et d'erreur

Configuration de la connexion
La configuration semble correcte, mais des enregistrements de journal en double apparaissent après l'exécution de la méthode
Analyse
Le CONSOLE Appender est monté sur deux Loggers en même temps, le<logger>et le<root>définis puisque le<logger>défini hérite de , le même article Les journaux seront enregistrés via l'enregistreur et envoyés à la racine pour enregistrement, il y aura donc des enregistrements en double dans les journaux sous le package d'application.<root>

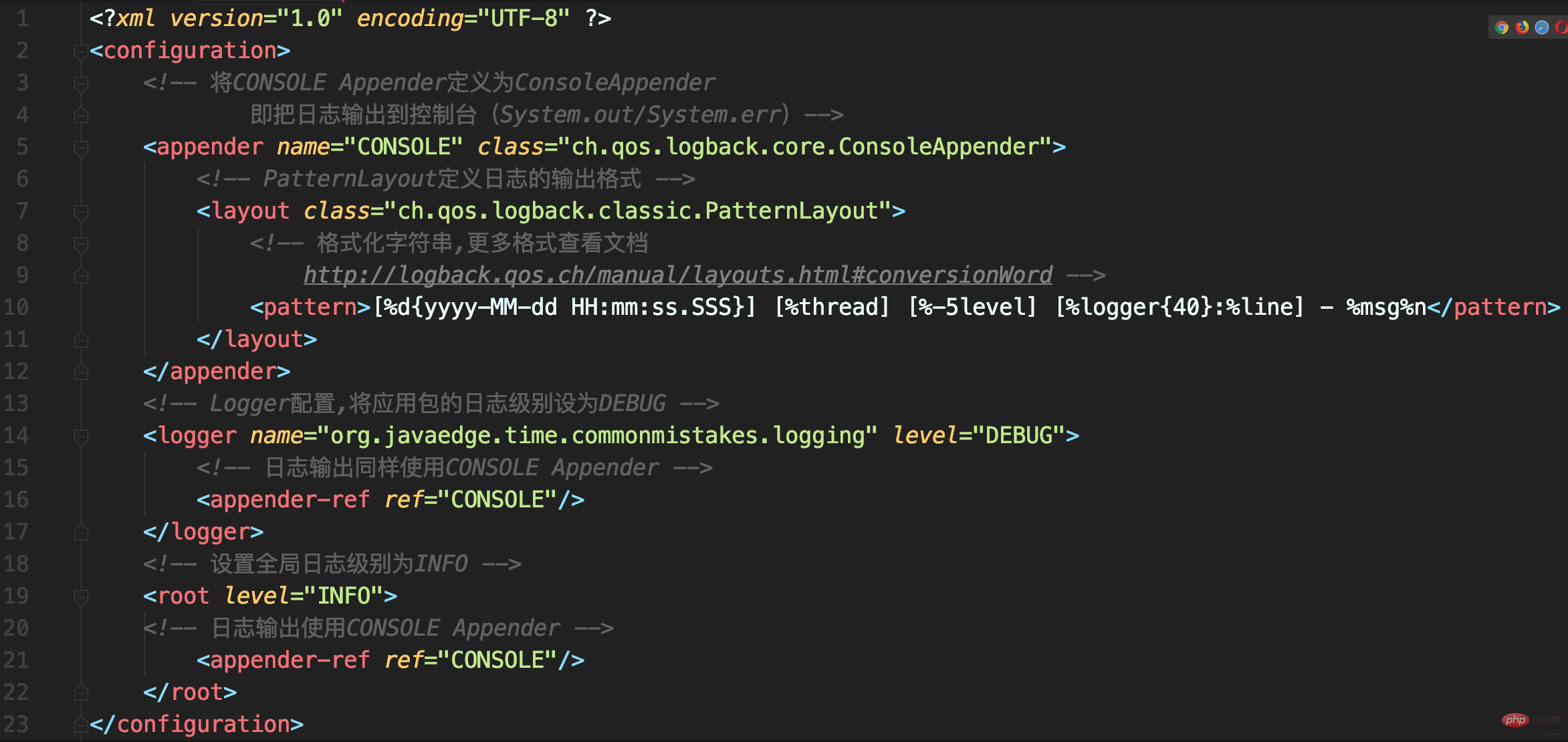
Dans mon cœur, je souhaite implémenter une configuration d'enregistreur personnalisée afin que les journaux de l'application puissent temporairement activer la journalisation au niveau DEBUG. En fait, il n'est pas nécessaire de monter l'Appender à plusieurs reprises, supprimez simplement l'Appender monté sous
: <logger>
<logger name="org.javaedge.time.commonmistakes.logging" level="DEBUG"/>
et devez exporter le journal vers un autre Appender : <logger> Par exemple,
- Le journal de l'application est affiché dans le fichier app.log
- D'autres journaux du framework sont affichés dans la console
additivité<logger> attribut de à false, cela n'héritera pas de l'Appender de <root>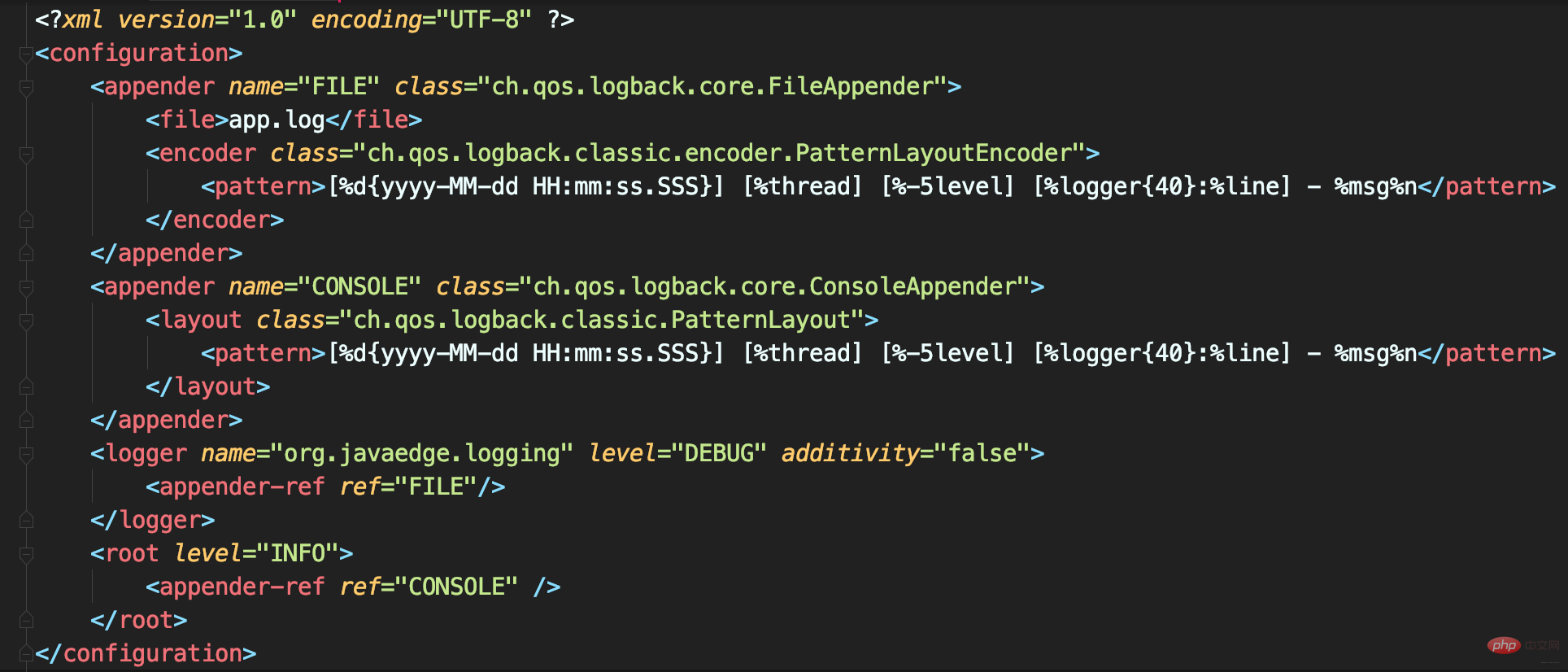
Une configuration incorrecte de LevelFilter provoque des journaux en double
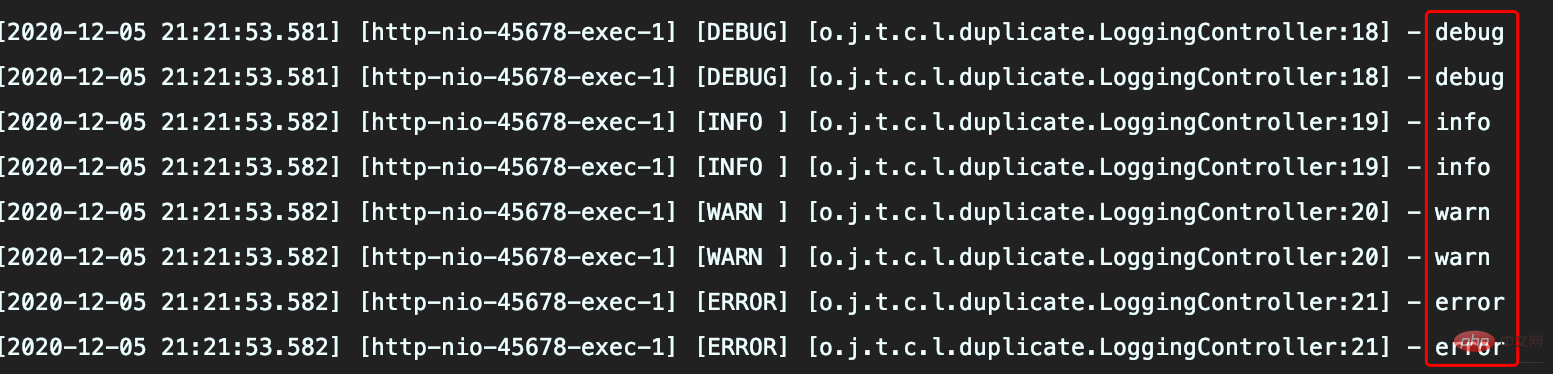
Lors de l'enregistrement des journaux sur la console, les enregistrements de journaux sont enregistrés dans deux fichiers à des niveaux différents
Résultats de l'exécution
Le fichier info.log contient des journaux à trois niveaux INFO, WARN et ERROR, ce qui n'est pas comme prévu
error.log contient des journaux de niveau WARN et ERROR, ce qui entraîne une collecte de journaux en double
Responsabilité des accidents
Certaines entreprises utilisent ELK automatisé solutions pour collecter les journaux, le journal sera affiché sur la console et le fichier en même temps. Les développeurs ne se soucieront pas des journaux enregistrés dans le fichier lors des tests locaux, car les développeurs n'ont pas de droits d'accès au serveur. les problèmes répétés dans le fichier journal d’origine sont difficiles à trouver.



Pourquoi les logs sont-ils répétés ?
Analyse du code source ThresholdFilter
- Lorsque
日志级别 ≥ 配置级别renvoie NEUTRE, continuez à appeler le filtre suivant dans la chaîne de filtres - sinon retournez DENY, refuser directement de se connecter

Dans ce cas, nous définirons ThresholdFilter sur WARN, afin qu'il puisse être enregistré dans les journaux de niveau WARN et ERROR.
LevelFilter
est utilisé pour comparer les niveaux de journalisation, puis traiter en conséquence.
- S'il y a une correspondance, appelez onMatch pour définir la méthode de traitement : par défaut au filtre suivant (valeur par défaut définie dans la classe de base AbstractMatcherFilter)
- Sinon La méthode de traitement définie en appelant onMismatch : par défaut elle est également transmise au filtre suivant
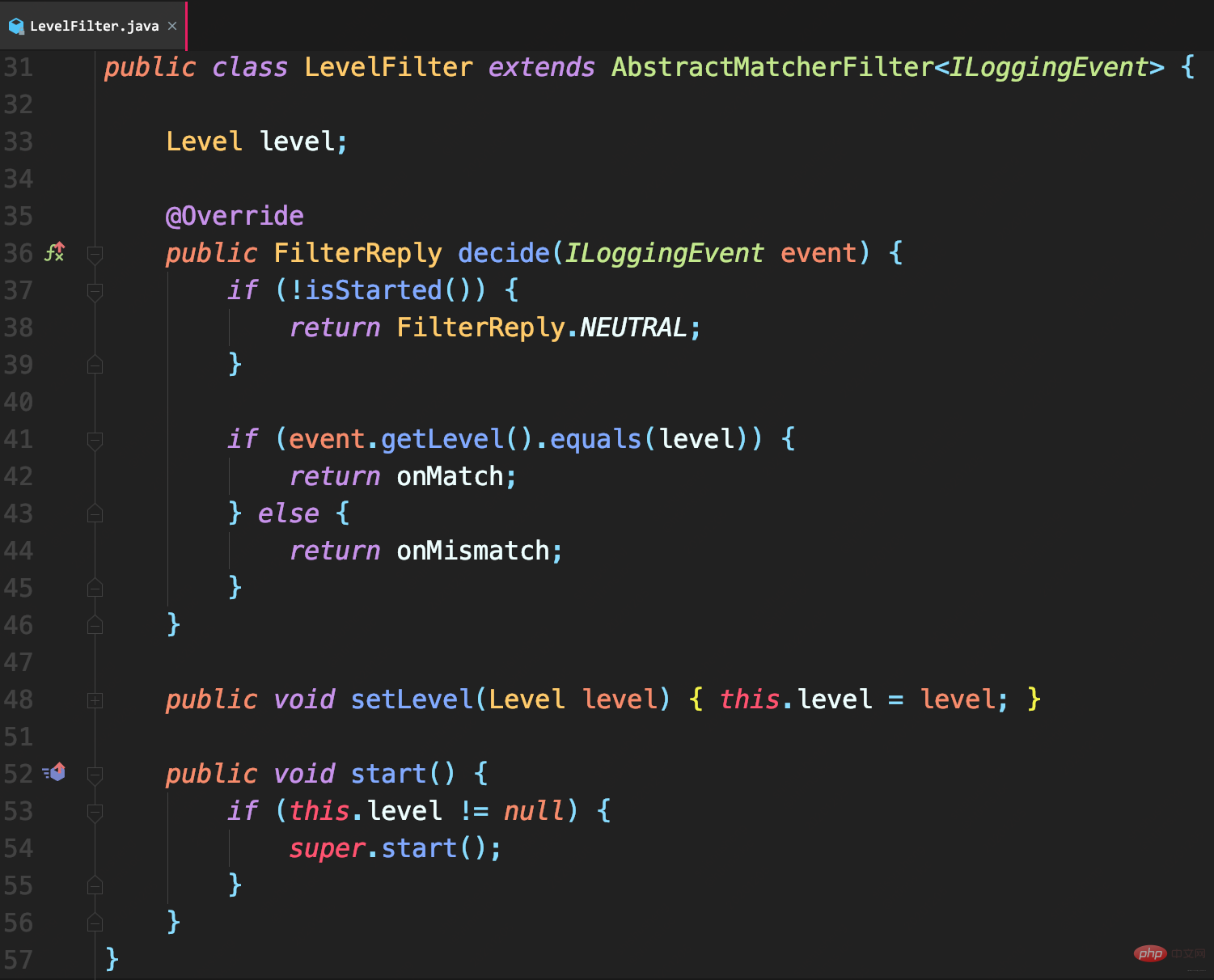

et ThresholdFilter est différent de LevelFilter仅配置level无法真正起作用.
Étant donné que les attributs onMatch et onMismatch ne sont pas configurés, le filtre échoue, provoquant l'enregistrement des journaux de niveaux INFO et supérieurs.
Correction
Configurer l'attribut onMatch de LevelFilter sur ACCEPT signifie recevoir des journaux de niveau INFO ; configurer l'attribut onMismatch sur DENY signifie ne pas enregistrer sauf le niveau INFO : 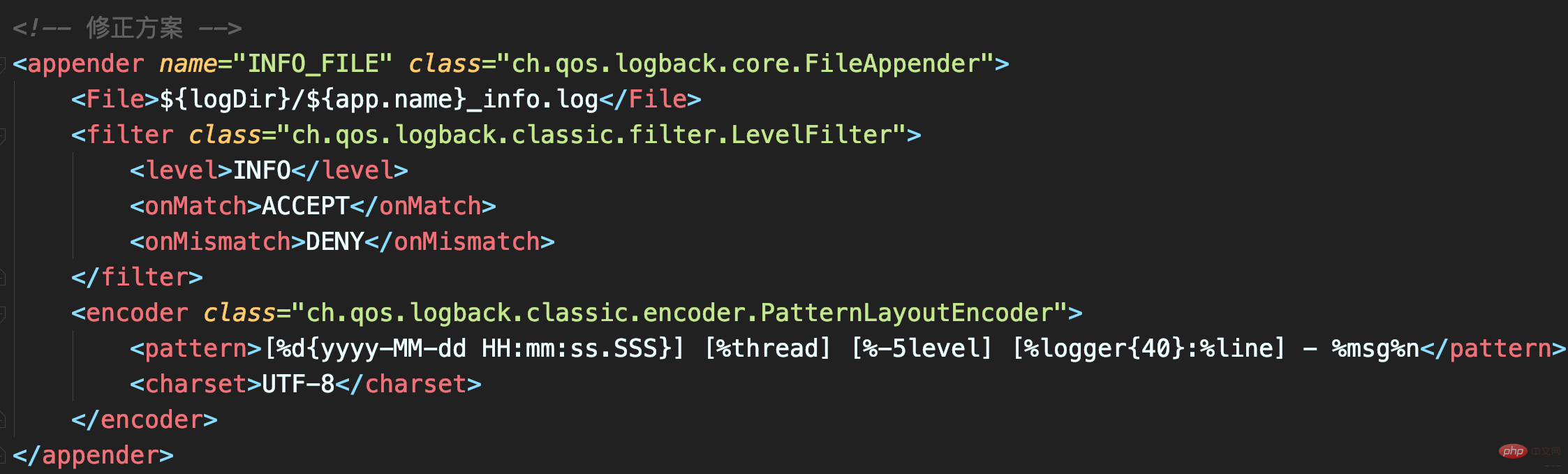
Dans ce cas, le fichier _info.log n'aura que des journaux de niveau INFO, et il n'y aura pas de journaux en double.
4 La journalisation asynchrone améliore-t-elle les performances ?
Une fois que vous savez comment générer correctement les journaux dans des fichiers, vous devez réfléchir à la manière d'éviter que la journalisation ne devienne un goulot d'étranglement des performances du système. Cela peut résoudre le problème de l'enregistrement des journaux lorsque les performances d'E/S des disques (tels que les disques mécaniques) sont médiocres et que le volume des journaux est important.
Définissez la configuration de journal suivante. Il y a deux Appenders au total :
FILE est un FileAppender utilisé pour enregistrer tous les journaux
CONSOLE est un ConsoleAppender utilisé pour enregistrer des enregistrements avec des journaux marqués par le temps ; . 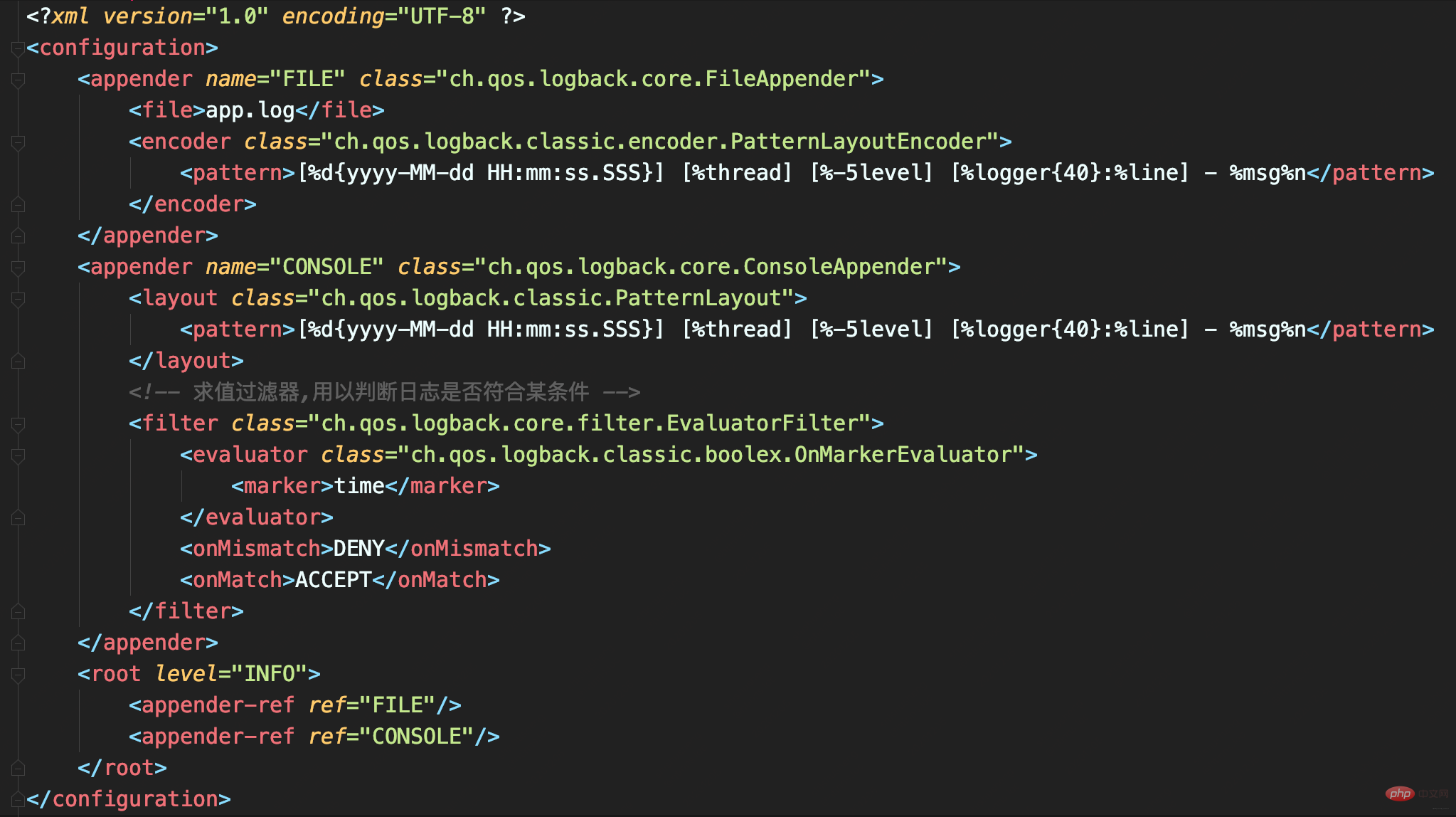
Générez un grand nombre de journaux dans un fichier. Le fichier journal sera très volumineux si les résultats des tests de performances sont également mélangés, il sera difficile de trouver ce journal. Par conséquent, EvaluatorFilter est utilisé ici pour filtrer les journaux en fonction des balises, et les journaux filtrés sont affichés séparément sur la console. Dans ce cas, une marque temporelle est ajoutée au journal qui génère les résultats du test.
Utilisez les balises et EvaluatorFilter ensemble pour filtrer les journaux par balises.
- Code de test : enregistrez un nombre spécifié de journaux volumineux, chaque journal contient 1 Mo de données simulées, et enfin enregistrez un journal chronophage d'exécution de méthode marqué du temps :
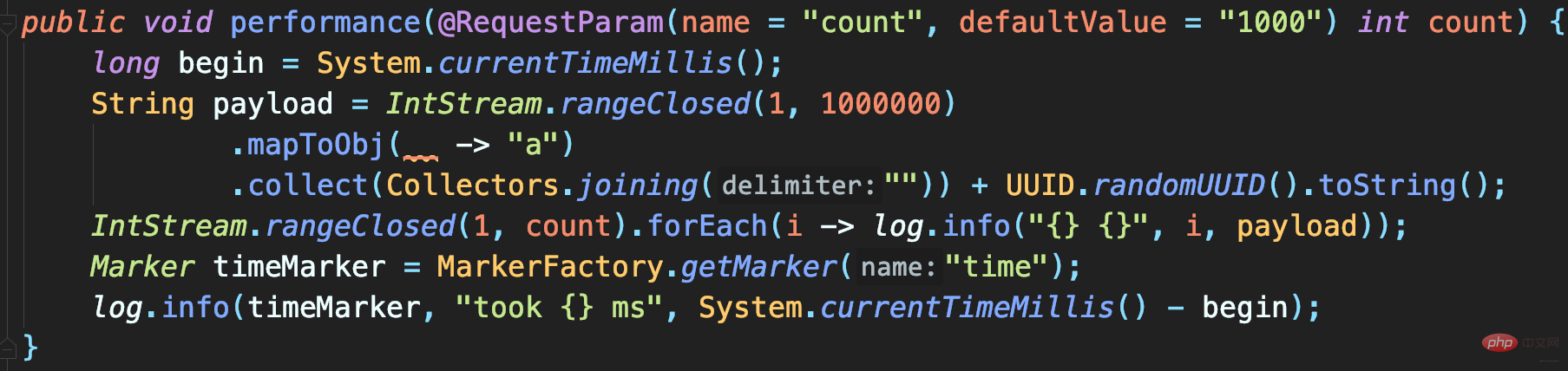
Après avoir exécuté le programme, vous pouvez voir que le temps nécessaire pour enregistrer 1 000 journaux et 10 000 appels de journal est respectivement de 5,1 secondes et 39 secondes

Pour code qui enregistre uniquement les journaux de fichiers, cela prend trop de temps.
Analyse du code source
FileAppender hérite de OutputStreamAppender
Lors de l'ajout de journaux, les journaux sont écrits directement dans OutputStream, qui est un journal synchrone 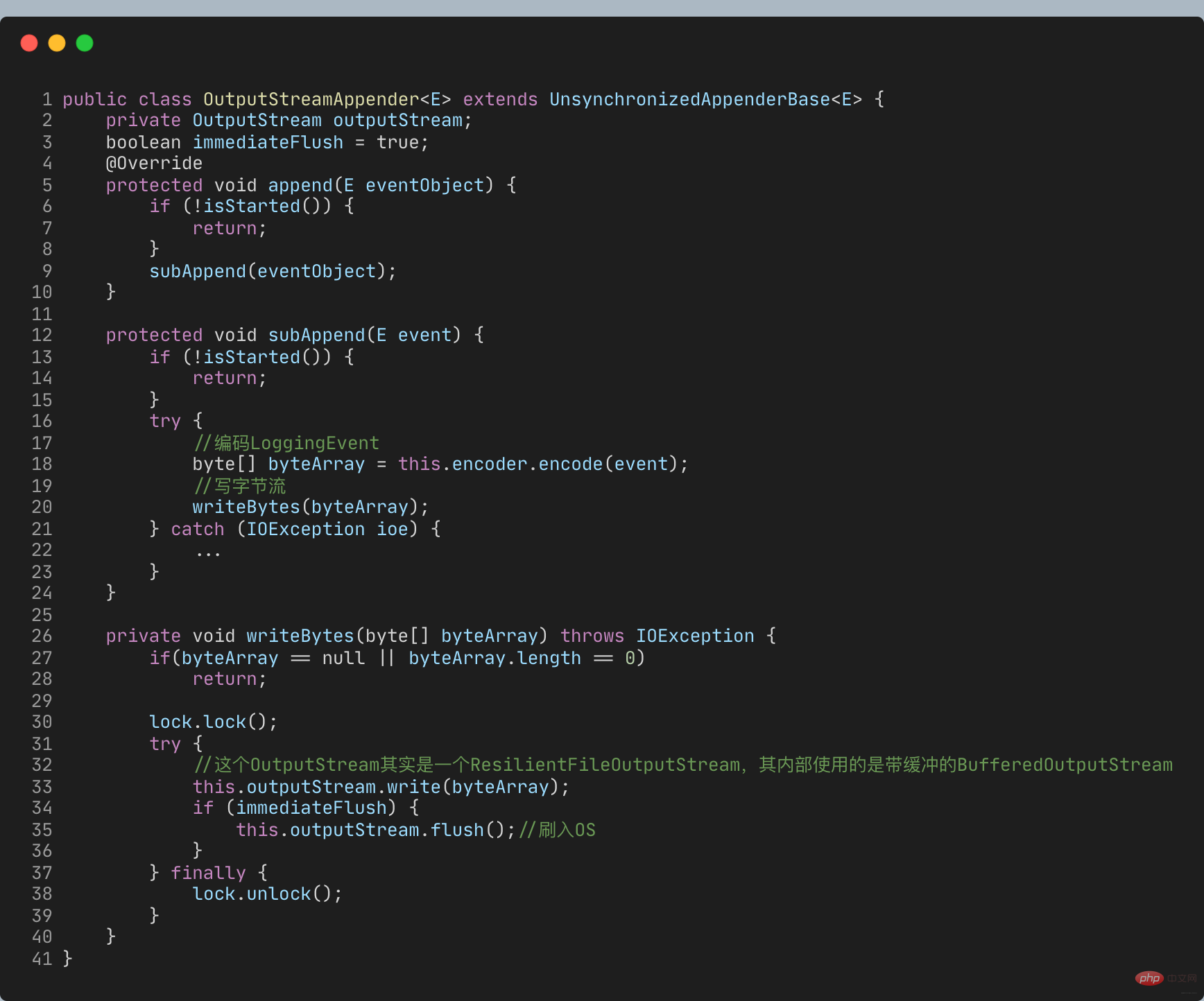
所以日志大量写入才会旷日持久。如何才能实现大量日志写入时,不会过多影响业务逻辑执行耗时而影响吞吐量呢?
AsyncAppender
使用Logback的AsyncAppender
即可实现异步日志记录。AsyncAppender类似装饰模式,在不改变类原有基本功能情况下为其增添新功能。这便可把AsyncAppender附加在其他Appender,将其变为异步。
定义一个异步Appender ASYNCFILE,包装之前的同步文件日志记录的FileAppender, 即可实现异步记录日志到文件
- 记录1000次日志和10000次日志的调用耗时,分别是537毫秒和1019毫秒


异步日志真的如此高性能?并不,因为这并没有记录下所有日志。
AsyncAppender异步日志坑
- 记录异步日志撑爆内存
- 记录异步日志出现日志丢失
- 记录异步日志出现阻塞。
案例
模拟慢日志记录场景:
首先,自定义一个继承自ConsoleAppender的MySlowAppender,作为记录到控制台的输出器,写入日志时休眠1秒。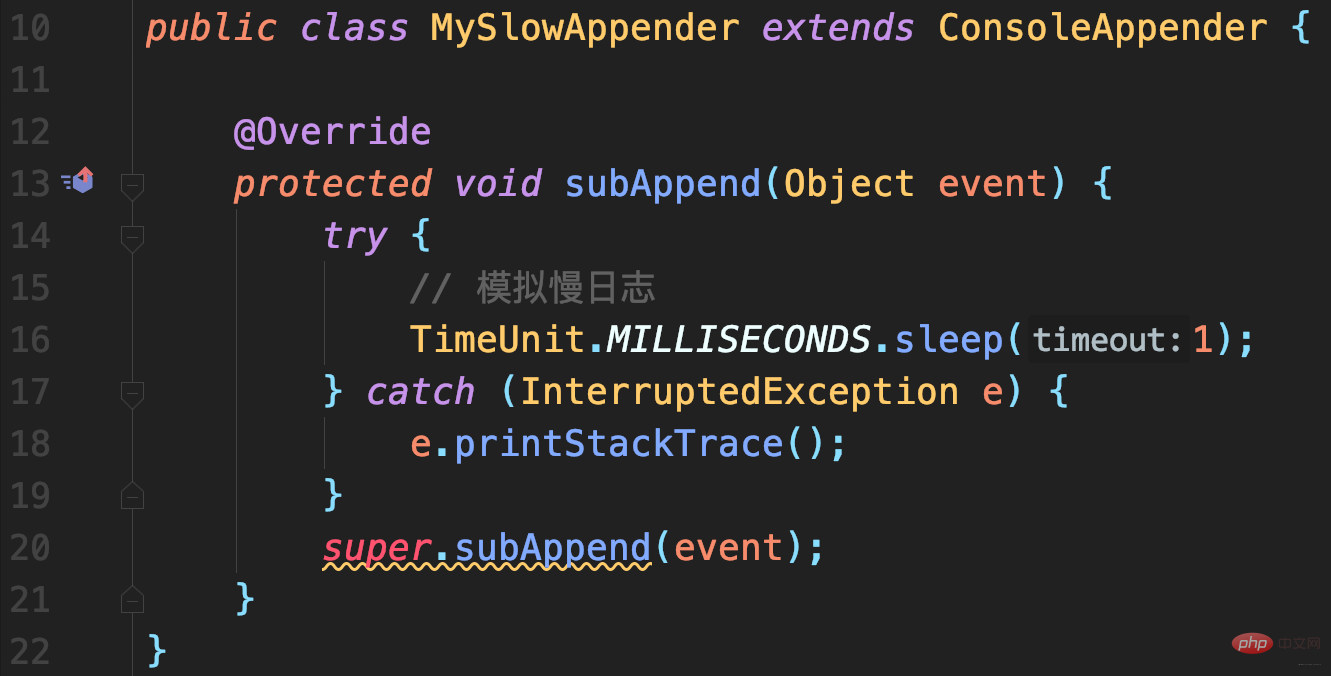
配置文件中使用AsyncAppender,将MySlowAppender包装为异步日志记录
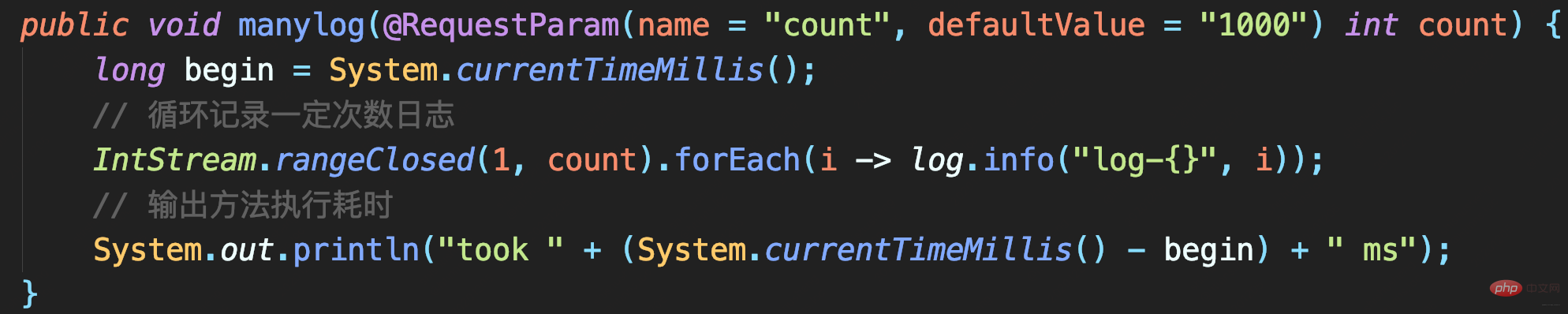
测试代码
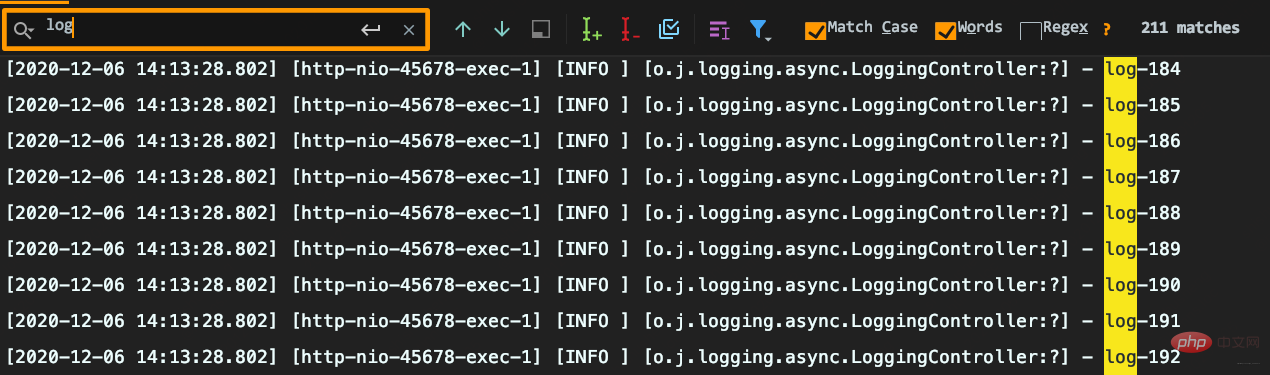
耗时很短但出现日志丢失:要记录1000条日志,最终控制台只能搜索到215条日志,而且日志行号变问号。
原因分析
AsyncAppender提供了一些配置参数,而当前没用对。
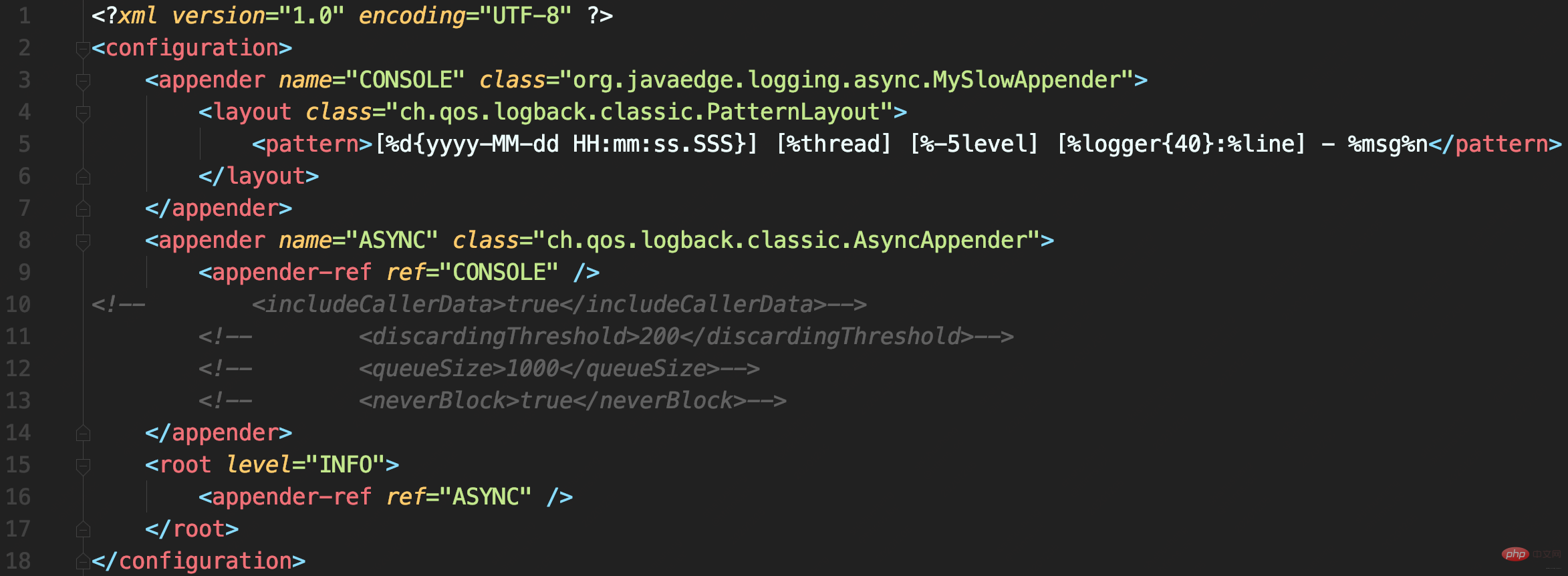
源码解析
- includeCallerData
默认false:方法行号、方法名等信息不显示 - queueSize
控制阻塞队列大小,使用的ArrayBlockingQueue阻塞队列,默认容量256:内存中最多保存256条日志 - discardingThreshold
丢弃日志的阈值,为防止队列满后发生阻塞。默认队列剩余容量 < 队列长度的20%,就会丢弃TRACE、DEBUG和INFO级日志 - neverBlock
控制队列满时,加入的数据是否直接丢弃,不会阻塞等待,默认是false- 队列满时:offer不阻塞,而put会阻塞
- neverBlock为true时,使用offer
public class AsyncAppender extends AsyncAppenderBase<ILoggingEvent> {
// 是否收集调用方数据
boolean includeCallerData = false;
protected boolean isDiscardable(ILoggingEvent event) {
Level level = event.getLevel();
// 丢弃 ≤ INFO级日志
return level.toInt() <= Level.INFO_INT;
}
protected void preprocess(ILoggingEvent eventObject) {
eventObject.prepareForDeferredProcessing();
if (includeCallerData)
eventObject.getCallerData();
}}public class AsyncAppenderBase<E> extends UnsynchronizedAppenderBase<E> implements AppenderAttachable<E> {
// 阻塞队列:实现异步日志的核心
BlockingQueue<E> blockingQueue;
// 默认队列大小
public static final int DEFAULT_QUEUE_SIZE = 256;
int queueSize = DEFAULT_QUEUE_SIZE;
static final int UNDEFINED = -1;
int discardingThreshold = UNDEFINED;
// 当队列满时:加入数据时是否直接丢弃,不会阻塞等待
boolean neverBlock = false;
@Override
public void start() {
...
blockingQueue = new ArrayBlockingQueue<E>(queueSize);
if (discardingThreshold == UNDEFINED)
//默认丢弃阈值是队列剩余量低于队列长度的20%,参见isQueueBelowDiscardingThreshold方法
discardingThreshold = queueSize / 5;
...
}
@Override
protected void append(E eventObject) {
if (isQueueBelowDiscardingThreshold() && isDiscardable(eventObject)) { //判断是否可以丢数据
return;
}
preprocess(eventObject);
put(eventObject);
}
private boolean isQueueBelowDiscardingThreshold() {
return (blockingQueue.remainingCapacity() < discardingThreshold);
}
private void put(E eventObject) {
if (neverBlock) { //根据neverBlock决定使用不阻塞的offer还是阻塞的put方法
blockingQueue.offer(eventObject);
} else {
putUninterruptibly(eventObject);
}
}
//以阻塞方式添加数据到队列
private void putUninterruptibly(E eventObject) {
boolean interrupted = false;
try {
while (true) {
try {
blockingQueue.put(eventObject);
break;
} catch (InterruptedException e) {
interrupted = true;
}
}
} finally {
if (interrupted) {
Thread.currentThread().interrupt();
}
}
}}默认队列大小256,达到80%后开始丢弃<=INFO级日志后,即可理解日志中为什么只有两百多条INFO日志了。
queueSize 过大
可能导致OOM
queueSize 较小
默认值256就已经算很小了,且discardingThreshold设置为大于0(或为默认值),队列剩余容量少于discardingThreshold的配置就会丢弃<=INFO日志。这里的坑点有两个:
- 因为discardingThreshold,所以设置queueSize时容易踩坑。
比如本案例最大日志并发1000,即便置queueSize为1000,同样会导致日志丢失 - discardingThreshold参数容易有歧义,它
不是百分比,而是日志条数。对于总容量10000队列,若希望队列剩余容量少于1000时丢弃,需配置为1000
neverBlock 默认false
意味总可能会出现阻塞。
- 若discardingThreshold = 0,那么队列满时再有日志写入就会阻塞
- 若discardingThreshold != 0,也只丢弃≤INFO级日志,出现大量错误日志时,还是会阻塞
queueSize、discardingThreshold和neverBlock三参密不可分,务必按业务需求设置:
- 若优先绝对性能,设置
neverBlock = true,永不阻塞 - 若优先绝不丢数据,设置
discardingThreshold = 0,即使≤INFO级日志也不会丢。但最好把queueSize设置大一点,毕竟默认的queueSize显然太小,太容易阻塞。 - 若兼顾,可丢弃不重要日志,把queueSize设置大点,再设置合理的discardingThreshold
以上日志配置最常见两个误区
Regardez les malentendus dans le journal lui-même.
L'utilisation d'espaces réservés de journal élimine le besoin de juger le niveau de journalisation ?
La syntaxe d'espace réservé {} de SLF4J n'obtiendra les paramètres réels que lorsque le journal est réellement enregistré, résolvant ainsi le problème de Problèmes de performances liés à l'acquisition de données.
Est-ce exact ?
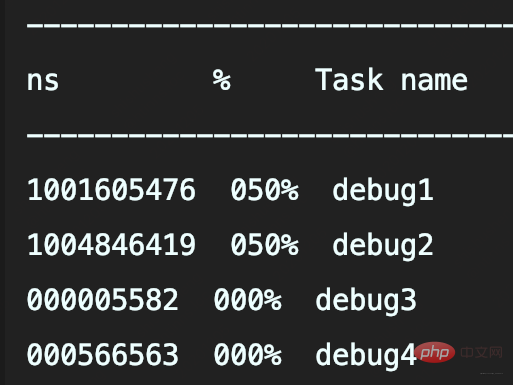
- Code de vérification : il faut 1 seconde pour renvoyer le résultat
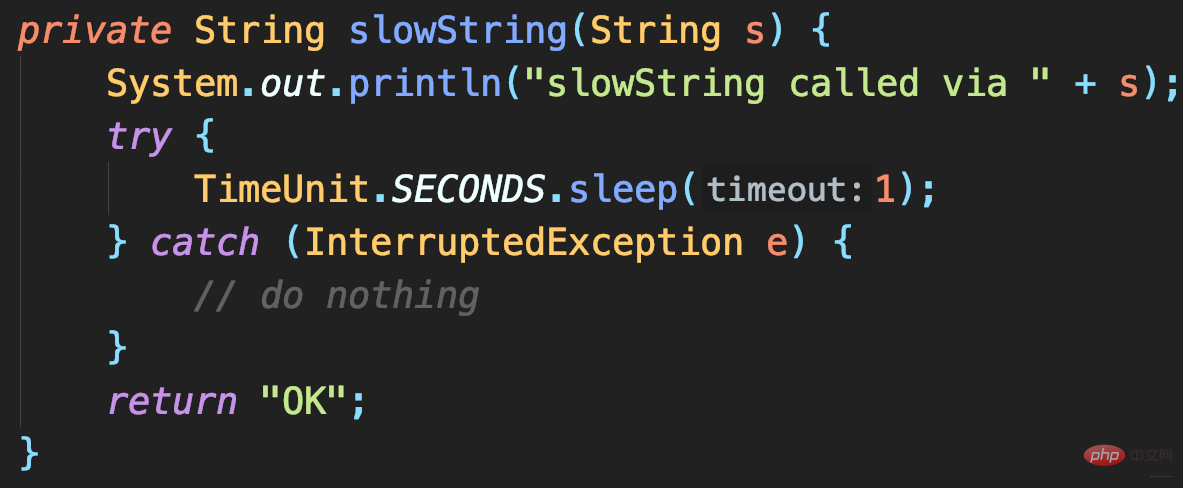
Si le journal DEBUG est enregistré et configuré pour enregistrer uniquement> =Log niveau INFO, le programme prendra-t-il également 1 seconde ?
Trois méthodes pour tester :
- Concaténation de chaînes pour enregistrer slowString
- Utilisation de la méthode d'espace réservé pour enregistrer slowString
- Déterminez d'abord si le niveau de journalisation est activé pour le DEBUG.
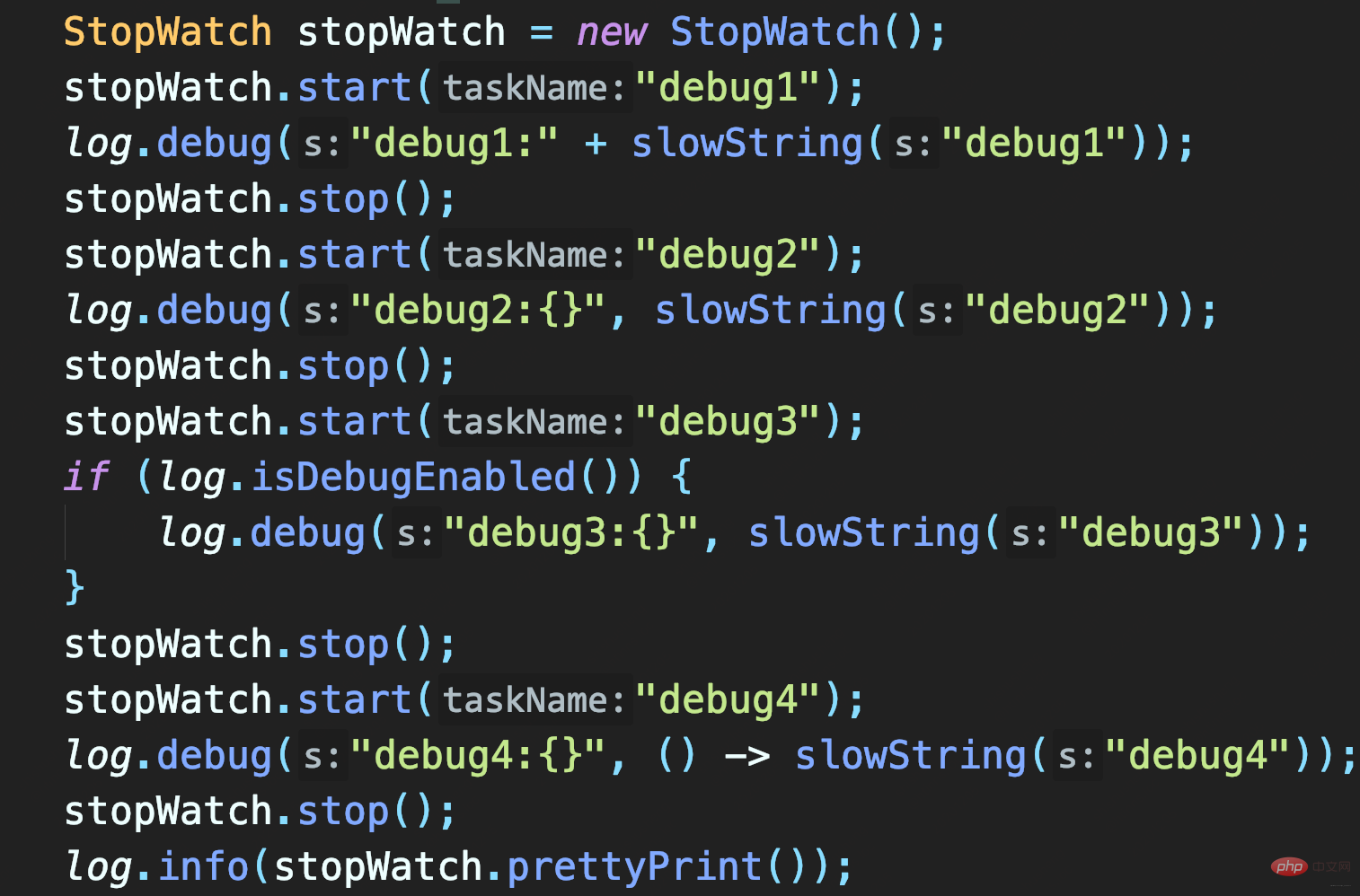
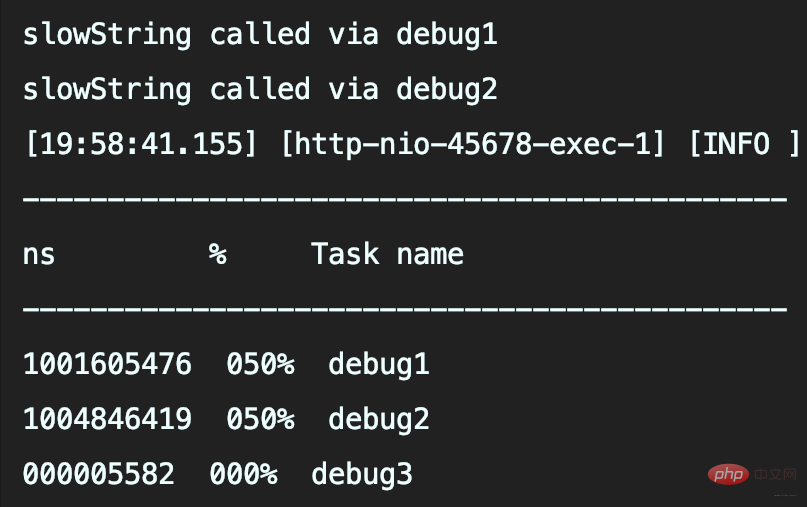
Les deux premières méthodes appellent slowString, donc elles prennent toutes les deux 1 s. Et la deuxième méthode consiste à utiliser des espaces réservés pour enregistrer slowString. Bien que cette méthode permette de passer Object sans épisser explicitement String, ce n'est qu'un délai (si le journal n'est pas enregistré, il sera omis) Paramètre du journal object.toString( ) et .
Dans ce cas, slowString doit être appelé sauf si le niveau de journalisation est déterminé à l'avance. Par conséquent, l'utilisation de
ne peut pas résoudre le problème de performances de l'acquisition des données de journal en retardant l'acquisition de la valeur des paramètres. {}占位符
de Lombok par l'annotation **@Log4j2** pour fournir une méthode pour les paramètres d'expression lambda : 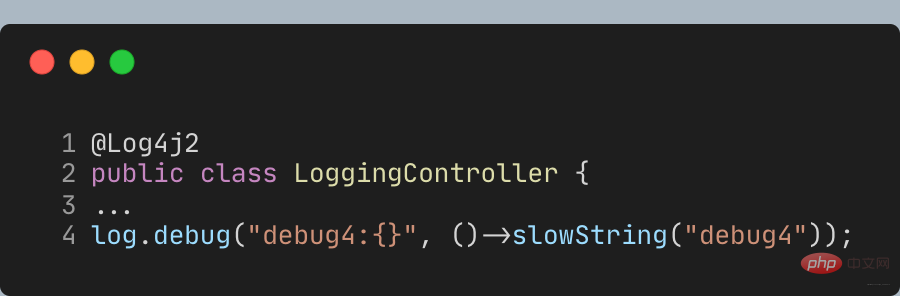 Appelez debug comme ceci, signature
Appelez debug comme ceci, signature
, les paramètres seront retardés jusqu'à ce que le journal soit réellement nécessaire pour être obtenu : 


 Donc, debug4 n'appellera pas la méthode slowString
Donc, debug4 n'appellera pas la méthode slowString
 remplacez-la simplement par
remplacez-la simplement par
, la vraie journalisation se fait via Logback, c'est l'avantage de l'adaptation SLF4J. Résumé
SLF4J unifie le framework de journalisation Java. Lorsque vous utilisez SLF4J, il est important de comprendre son API de pontage et ses liaisons. Si un message d'erreur SLF4J apparaît au démarrage du programme, il peut s'agir d'un problème de configuration. Vous pouvez utiliser la commande dependency:tree de Maven pour trier les dépendances.- Les journaux asynchrones résolvent les problèmes de performances en échangeant de l'espace contre du temps. Mais l'espace est après tout limité. Lorsque l'espace est plein, vous devriez envisager de bloquer et d'attendre ou de supprimer le journal. Si vous préférez ne pas supprimer les journaux importants, choisissez le blocage en attente ; si vous préférez que le programme ne se bloque pas à cause de la journalisation, vous devez alors supprimer les journaux.
- La méthode de journalisation paramétrée fournie par le framework de journalisation ne peut pas remplacer complètement le jugement au niveau du journal. Si votre volume de journaux est important et que le coût d'obtention des paramètres de journalisation est également élevé, vous devez déterminer le niveau de journalisation pour éviter une acquisition fastidieuse des paramètres de journal sans journalisation.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre parfait en Java. Nous discutons ici de la définition, comment vérifier le nombre parfait en Java ?, des exemples d'implémentation de code.
 Weka en Java
Aug 30, 2024 pm 04:28 PM
Weka en Java
Aug 30, 2024 pm 04:28 PM
Guide de Weka en Java. Nous discutons ici de l'introduction, de la façon d'utiliser Weka Java, du type de plate-forme et des avantages avec des exemples.
 Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre de Smith en Java. Nous discutons ici de la définition, comment vérifier le numéro Smith en Java ? exemple avec implémentation de code.
 Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Dans cet article, nous avons conservé les questions d'entretien Java Spring les plus posées avec leurs réponses détaillées. Pour que vous puissiez réussir l'interview.
 Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Java 8 présente l'API Stream, fournissant un moyen puissant et expressif de traiter les collections de données. Cependant, une question courante lors de l'utilisation du flux est: comment se casser ou revenir d'une opération FOREAK? Les boucles traditionnelles permettent une interruption ou un retour précoce, mais la méthode Foreach de Stream ne prend pas directement en charge cette méthode. Cet article expliquera les raisons et explorera des méthodes alternatives pour la mise en œuvre de terminaison prématurée dans les systèmes de traitement de flux. Lire plus approfondie: Améliorations de l'API Java Stream Comprendre le flux Forach La méthode foreach est une opération terminale qui effectue une opération sur chaque élément du flux. Son intention de conception est
 Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Guide de TimeStamp to Date en Java. Ici, nous discutons également de l'introduction et de la façon de convertir l'horodatage en date en Java avec des exemples.
 Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Les capsules sont des figures géométriques tridimensionnelles, composées d'un cylindre et d'un hémisphère aux deux extrémités. Le volume de la capsule peut être calculé en ajoutant le volume du cylindre et le volume de l'hémisphère aux deux extrémités. Ce tutoriel discutera de la façon de calculer le volume d'une capsule donnée en Java en utilisant différentes méthodes. Formule de volume de capsule La formule du volume de la capsule est la suivante: Volume de capsule = volume cylindrique volume de deux hémisphères volume dans, R: Le rayon de l'hémisphère. H: La hauteur du cylindre (à l'exclusion de l'hémisphère). Exemple 1 entrer Rayon = 5 unités Hauteur = 10 unités Sortir Volume = 1570,8 unités cubes expliquer Calculer le volume à l'aide de la formule: Volume = π × r2 × h (4
 Comment exécuter votre première application Spring Boot dans Spring Tool Suite?
Feb 07, 2025 pm 12:11 PM
Comment exécuter votre première application Spring Boot dans Spring Tool Suite?
Feb 07, 2025 pm 12:11 PM
Spring Boot simplifie la création d'applications Java robustes, évolutives et prêtes à la production, révolutionnant le développement de Java. Son approche "Convention sur la configuration", inhérente à l'écosystème de ressort, minimise la configuration manuelle, allo
