

Tutoriel mysqlRésumé des transactions de base de données et des transactions MySQL

Recommandé (gratuit) : Tutoriel MySQL
Fonctionnalités de transaction : ACID
D'un point de vue commercial, Un ensemble d'opérations dans la base de données est nécessaire pour maintenir 4 caractéristiques :
Afin de mieux comprendre ACID, considérez le virement bancaire comme un exemple :
START TRANSACTION;SELECT balance FROM checking WHERE customer_id = 10233276;UPDATE checking SET balance = balance - 200.00 WHERE customer_id = 10233276;UPDATE savings SET balance = balance + 200.00 WHERE customer_id = 10233276;COMMIT;
Niveau d'isolement de la transaction
Problèmes causés par des transactions simultanées
La différence entre la lecture fantôme et la lecture non répétable :
Solution aux problèmes causés par le traitement simultané des transactions :
Les « mises à jour perdues » sont généralement quelque chose qui devrait être complètement évité. Cependant, la prévention de la perte de mise à jour ne peut pas être résolue par le seul contrôleur de transactions de base de données. L'application doit ajouter les verrous nécessaires aux données à mettre à jour. Par conséquent, la prévention de la perte de mise à jour doit relever de la responsabilité de l'application.
"Lecture sale", "lecture non répétable" et "lecture fantôme" sont en fait des problèmes de cohérence de lecture de la base de données, qui doivent être résolus par la base de données fournissant un certain mécanisme d'isolation des transactions :
L'une est le verrouillage : avant de lire les données, verrouillez-les pour empêcher d'autres transactions de modifier les données.
L'autre est le contrôle de concurrence de données multi-versions (MVCC ou MCC en abrégé), également connu sous le nom de base de données multi-versions : sans ajouter de verrous, une donnée est générée via un certain mécanisme. Demandez un instantané de données cohérent (Snapshot) à un moment donné et utilisez cet instantané pour fournir un certain niveau (niveau d'instruction ou niveau de transaction) de lectures cohérentes. Du point de vue de l'utilisateur, il semble que la base de données puisse fournir plusieurs versions des mêmes données.
Le standard SQL définit 4 types de niveaux d'isolement. Chaque niveau précise les modifications apportées dans une transaction, celles qui sont visibles au sein et entre les transactions, et celles qui ne le sont pas. Des niveaux d’isolement inférieurs prennent généralement en charge une concurrence plus élevée et entraînent une surcharge système inférieure.
Niveau 1 : Lire non validé
Niveau 2 : Lecture validée (lecture du contenu soumis)
Il s'agit du niveau d'isolement par défaut pour la plupart des systèmes de bases de données (mais pas le niveau par défaut de MySQL)
Cela répond à la définition simple de l'isolement : une transaction ne peut voir que ce qui a été commis par la transaction. Le problème avec la modification du niveau d'isolement de
est - Lecture non répétable : la lecture non répétable signifie que lorsque nous exécutons exactement la même instruction select dans la même transaction, il est possible de voir des résultats différents. Les raisons possibles de cette situation incluent :
Il y a une transaction croisée avec un nouveau commit, entraînant des modifications de données
A Lorsque la base de données ; est exploité par plusieurs instances, d'autres instances de la même transaction peuvent avoir de nouveaux commits lors du traitement de l'instance
Niveau 3 : Lecture répétable (lisible )
Contrôle de concurrence multi-version :
La plupart des implémentations de moteur de stockage transactionnel de Mysql Il ne s'agit pas d'un simple verrouillage au niveau des lignes. Sur la base de l'amélioration de la concurrence, le contrôle de concurrence multiversion (MVCC) est généralement implémenté en même temps, y compris Oracle et PostgreSQL. Cependant, les implémentations varient.
MVCC est implémenté en enregistrant un instantané des données à un moment donné. En d’autres termes, quel que soit le temps nécessaire à la mise en œuvre, les données vues par chaque élément sont cohérentes.
Il est divisé en contrôle de concurrence optimiste et contrôle de concurrence pessimiste.
Comment fonctionne MVCC :
Le MVCC d'InnoDB est implémenté en enregistrant deux colonnes cachées derrière chaque ligne d'enregistrements. L'une de ces deux colonnes stocke l'heure de création de la ligne et l'autre stocke l'heure d'expiration (heure de suppression) de la ligne. Bien entendu, ce qui est stocké n’est pas l’heure réelle mais le numéro de version du système. Chaque fois qu'une nouvelle transaction est démarrée, le numéro de version du système sera automatiquement ajouté. Le numéro de version du système au début de la transaction sera utilisé comme numéro de version de la transaction, qui est utilisé pour interroger le numéro de version de chaque ligne d'enregistrements à des fins de comparaison.
Comment fonctionne MVCC sous le niveau d'isolement REPEATABLE READ :
InnoDB vérifiera chaque ligne d'enregistrements selon les conditions suivantes :
Seules celles qui remplissent les deux conditions ci-dessus seront interrogées
InnoDB enregistre le numéro de version actuel du système comme numéro de version de ligne pour chaque ligne nouvellement insérée
InnoDB enregistre le numéro de version actuel du système comme ligne supprimée pour chaque ligne supprimée Identification
InnoDB enregistre le numéro de version actuel du système comme numéro de version de ligne pour le nouvel enregistrement inséré, et enregistre le numéro de version actuel du système dans la ligne d'origine comme identifiant de suppression
Enregistrez ces deux numéros de version afin que la plupart des opérations ne nécessitent pas de verrouillage. Il simplifie les opérations sur les données, fonctionne bien et garantit que seules les lignes requises par des exigences complexes sont lues. Les inconvénients sont que chaque ligne d'enregistrements nécessite un espace de stockage supplémentaire, davantage de vérifications de lignes et des travaux de maintenance supplémentaires.
MVCC ne fonctionne que sous deux niveaux d'isolement : COMMITTED READ (soumission en lecture) et REPEATABLE READ (lecture répétable).
On peut considérer que MVCC est une variante du verrouillage au niveau des lignes, mais il évite les opérations de verrouillage dans de nombreux cas et entraîne une surcharge moindre. Bien que les mécanismes d'implémentation des différentes bases de données soient différents, la plupart d'entre elles implémentent des opérations de lecture non bloquantes (la lecture ne nécessite pas de verrouillage et peut éviter les lectures non répétables et les lectures fantômes), et les opérations d'écriture verrouillent uniquement les lignes nécessaires (l'écriture doit être verrouillée). ). , sinon l'écriture simultanée par différentes transactions entraînera une incohérence des données).
Niveau 4 : Sérialisable
Comparaison du niveau d'isolement

Chaque base de données spécifique peut ne pas mettre entièrement en œuvre les quatre niveaux d'isolement ci-dessus, par exemple :
Oracle ne fournit que deux normes : Lecture validée et le niveau d'isolement sérialisable, en outre, il fournit également son propre niveau d'isolement en lecture seule défini
En plus de prendre en charge les quatre niveaux d'isolement définis par ISO/ANSI SQL92 ci-dessus, SQL Server également prend en charge un niveau d'isolement appelé "instantané", mais à proprement parler, il s'agit d'un niveau d'isolement sérialisable implémenté à l'aide de MVCC.
MySQL prend en charge les 4 niveaux d'isolement, mais dans l'implémentation spécifique, il existe certaines caractéristiques, telles que la lecture de cohérence MVCC est utilisée dans certains niveaux d'isolement, mais dans certains cas, ce n'est pas le cas.
Mysql peut définir le niveau d'isolement en exécutant la commande set transaction isolation level. Le nouveau niveau d'isolement prendra effet au démarrage de la prochaine transaction. Par exemple : définir le niveau d'isolement des transactions de session en lecture validée ;
Journal des transactions
Le journal des transactions peut aider à améliorer l'efficacité des transactions :
Actuellement, la plupart des moteurs de stockage sont implémentés de cette manière. Nous appelons généralement cela la journalisation à écriture anticipée (la modification des données nécessite une écriture deux fois sur le disque).
Principe d'implémentation des transactions dans Mysql
L'implémentation des transactions est basée sur le moteur de stockage de la base de données. Différents moteurs de stockage ont différents niveaux de prise en charge des transactions. Les moteurs de stockage qui prennent en charge les transactions dans MySQL incluent innoDB et NDB.
innoDB est le moteur de stockage par défaut de MySQL. Le niveau d'isolement par défaut est RR (Repeatable Read), et il va encore plus loin sous le niveau d'isolement de RR, via le Contrôle de concurrence (MVCC, Multiversion Concurrency Control) résout le problème de lecture non répétable, et le verrouillage des espaces (c'est-à-dire le contrôle de concurrence) résout le problème de lecture fantôme. Par conséquent, le niveau d'isolation RR d'innoDB produit réellement l'effet du niveau de sérialisation et conserve des performances de concurrence relativement bonnes.
事务的隔离性是通过锁实现,而事务的原子性、一致性和持久性则是通过事务日志实现。说到事务日志,不得不说的就是redo和undo。
1.redo log
在innoDB的存储引擎中,事务日志通过重做(redo)日志和innoDB存储引擎的日志缓冲(InnoDB Log Buffer)实现。事务开启时,事务中的操作,都会先写入存储引擎的日志缓冲中,在事务提交之前,这些缓冲的日志都需要提前刷新到磁盘上持久化,这就是DBA们口中常说的“日志先行”(Write-Ahead Logging)。当事务提交之后,在Buffer Pool中映射的数据文件才会慢慢刷新到磁盘。此时如果数据库崩溃或者宕机,那么当系统重启进行恢复时,就可以根据redo log中记录的日志,把数据库恢复到崩溃前的一个状态。未完成的事务,可以继续提交,也可以选择回滚,这基于恢复的策略而定。
在系统启动的时候,就已经为redo log分配了一块连续的存储空间,以顺序追加的方式记录Redo Log,通过顺序IO来改善性能。所有的事务共享redo log的存储空间,它们的Redo Log按语句的执行顺序,依次交替的记录在一起。如下一个简单示例:
记录1:
记录2:
记录3:
记录4:
记录5:
2.undo log
undo log主要为事务的回滚服务。在事务执行的过程中,除了记录redo log,还会记录一定量的undo log。undo log记录了数据在每个操作前的状态,如果事务执行过程中需要回滚,就可以根据undo log进行回滚操作。单个事务的回滚,只会回滚当前事务做的操作,并不会影响到其他的事务做的操作。
以下是undo+redo事务的简化过程
假设有2个数值,分别为A和B,值为1,2
1. start transaction;
2. 记录 A=1 到undo log;
3. update A = 3;
4. 记录 A=3 到redo log;
5. 记录 B=2 到undo log;
6. update B = 4;
7. 记录B = 4 到redo log;
8. 将redo log刷新到磁盘
9. commit
在1-8的任意一步系统宕机,事务未提交,该事务就不会对磁盘上的数据做任何影响。如果在8-9之间宕机,恢复之后可以选择回滚,也可以选择继续完成事务提交,因为此时redo log已经持久化。若在9之后系统宕机,内存映射中变更的数据还来不及刷回磁盘,那么系统恢复之后,可以根据redo log把数据刷回磁盘。
所以,redo log其实保障的是事务的持久性和一致性,而undo log则保障了事务的原子性。
Mysql中的事务使用
MySQL的服务层不管理事务,而是由下层的存储引擎实现。比如InnoDB。
MySQL支持本地事务的语句:
START TRANSACTION | BEGIN [WORK] COMMIT [WORK] [AND [NO] CHAIN] [[NO] RELEASE] ROLLBACK [WORK] [AND [NO] CHAIN] [[NO] RELEASE] SET AUTOCOMMIT = {0 | 1}事务使用注意点:
自动提交(autocommit):
Mysql默认采用自动提交模式,可以通过设置autocommit变量来启用或禁用自动提交模式
InnoDB在事务执行过程中,使用两阶段锁协议:
随时都可以执行锁定,InnoDB会根据隔离级别在需要的时候自动加锁;
锁只有在执行commit或者rollback的时候才会释放,并且所有的锁都是在同一时刻被释放。
InnoDB也支持通过特定的语句进行显示锁定(存储引擎层):
select ... lock in share mode //共享锁 select ... for update //排他锁
MySQL Server层的显示锁定:
lock table和unlock table
(更多阅读:MySQL锁总结)
MySQL对分布式事务的支持
分布式事务的实现方式有很多,既可以采用innoDB提供的原生的事务支持,也可以采用消息队列来实现分布式事务的最终一致性。这里我们主要聊一下innoDB对分布式事务的支持。
MySQL 从 5.0.3 开始支持分布式事务,当前分布式事务只支持 InnoDB 存储引擎。一个分布式事务会涉及多个行动,这些行动本身是事务性的。所有行动都必须一起成功完成,或者一起被回滚。
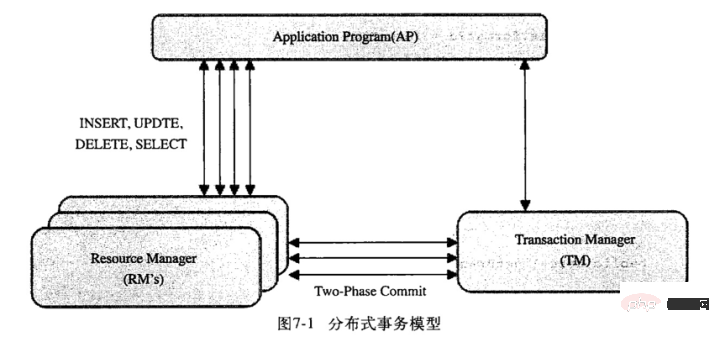
如图,mysql的分布式事务模型。模型中分三块:应用程序(AP)、资源管理器(RM)、事务管理器(TM):
分布式事务采用两段式提交(two-phase commit)的方式:
分布式事务(XA 事务)的 SQL 语法主要包括:
XA {START|BEGIN} xid [JOIN|RESUME]虽然 MySQL 支持分布式事务,但是在测试过程中,还是发现存在一些问题:
如果分支事务在达到 prepare 状态时,数据库异常重新启动,服务器重新启动以后,可以继续对分支事务进行提交或者回滚得操作,但是提交的事务没有写 binlog,存在一定的隐患,可能导致使用 binlog 恢复丢失部分数据。如果存在复制的数据库,则有可能导致主从数据库的数据不一致。
如果分支事务在执行到 prepare 状态时,数据库异常,且不能再正常启动,需要使用备份和 binlog 来恢复数据,那么那些在 prepare 状态的分支事务因为并没有记录到 binlog,所以不能通过 binlog 进行恢复,在数据库恢复后,将丢失这部分的数据。
如果分支事务的客户端连接异常中止,那么数据库会自动回滚未完成的分支事务,如果此时分支事务已经执行到 prepare 状态, 那么这个分布式事务的其他分支可能已经成功提交,如果这个分支回滚,可能导致分布式事务的不完整,丢失部分分支事务的内容。
总之, MySQL 的分布式事务还存在比较严重的缺陷, 在数据库或者应用异常的情况下,
可能会导致分布式事务的不完整。如果应用对于数据的完整性要求不是很高,则可以考虑使
用。如果应用对事务的完整性有比较高的要求,那么对于当前的版本,则不推荐使用分布式
事务。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



