

En savoir plus sur le mécanisme de boucle d'événements dans Nodejs

Cet article vous fera découvrir le mécanisme de boucle d'événements nodejs. Il a une certaine valeur de référence. Les amis dans le besoin peuvent s'y référer. J'espère qu'il sera utile à tout le monde.

Recommandations associées : "Tutoriel nodejs"
Node.js utilise des E/S asynchrones et événementielles pour réaliser un seul Un environnement d'exécution JavaScript à haute concurrence et un thread unique signifie qu'une seule chose peut être faite en même temps. Alors, comment Node.js atteint-il une concurrence élevée et des E/S asynchrones grâce au thread unique ? Cet article se concentrera sur cette question pour discuter du modèle monothread de Node.js.
Stratégie de haute concurrence
De manière générale, la solution à la haute concurrence consiste à fournir un modèle multithread. Le serveur alloue un thread pour chaque requête client et utilise la synchronisation. E/S, le système utilise la commutation de threads pour compenser la surcharge temporelle des appels d'E/S synchrones. Par exemple, Apache a cette stratégie, étant donné que les E/S sont généralement une opération qui prend du temps, cette stratégie est difficile à atteindre des performances élevées, mais elle est très simple et peut mettre en œuvre une logique d'interaction complexe.
En fait, le côté serveur de la plupart des sites Web ne fait pas trop de calculs. Après avoir reçu la demande, ils la transmettent à d'autres services pour traitement (comme la lecture de la base de données), puis attendent le résultat. . Revenez, et enfin envoyez le résultat au client. Par conséquent, Node.js adopte un modèle à thread unique pour gérer ce fait. Il n'alloue pas de thread pour chaque demande d'accès, mais utilise un thread principal pour traiter toutes les demandes, puis traite les opérations d'E/S de manière asynchrone. , évitant ainsi la surcharge et la complexité requises pour créer, détruire et basculer entre les threads.
Boucle d'événements
Node.js maintient une file d'attente d'événements dans le thread principal Lorsqu'une demande est reçue, la demande est traitée comme An. l'événement est placé dans cette file d'attente et continue de recevoir d'autres demandes. Lorsque le thread principal est inactif (quand il n'y a pas de demande d'accès), il commence à faire circuler la file d'attente des événements et vérifie s'il y a des événements à traiter dans la file d'attente. Il existe deux situations : s'il s'agit d'une non-E/S. tâche, gérez-la personnellement et rappelez-la. La fonction revient à l'appel de la couche supérieure ; s'il s'agit d'une tâche d'E/S, retirez un thread du pool de threads pour gérer l'événement, spécifiez le rappel. fonction, puis continuez à parcourir les autres événements de la file d'attente.
Lorsque la tâche d'E/S dans le thread est terminée, la fonction de rappel spécifiée est exécutée et l'événement terminé est placé à la fin de la file d'attente des événements, en attendant la boucle d'événement lorsque le thread principal boucle. à nouveau à l'événement, il est traité directement et renvoyé à l'appel de couche supérieure. Ce processus est appelé Event Loop (Event Loop), et son principe de fonctionnement est illustré dans la figure suivante :
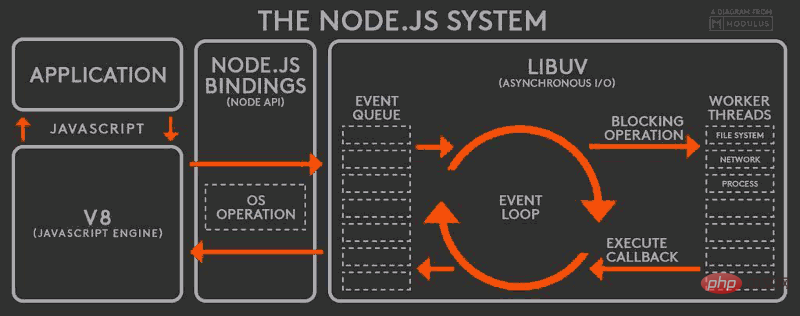
Cette figure est le principe de fonctionnement de l'ensemble de Node.js, de gauche à droite, de haut en bas, Node.js est divisé en quatre couches, à savoir Couche d'application, Couche moteur V8, API Node couche et couche LIBUV.
Couche d'application : c'est-à-dire la couche d'interaction JavaScript, les plus courantes sont les modules Node.js, tels que http, fs
Couche moteur V8 : c'est-à-dire, utiliser le moteur V8 pour analyser la syntaxe JavaScript, puis interagir avec l'API inférieure
Couche NodeAPI : fournit des appels système pour le module supérieur, généralement implémenté en langage C, pour interagir avec le système d'exploitation.
Couche LIBUV : il s'agit d'une encapsulation multiplateforme de niveau inférieur qui implémente des boucles d'événements, des opérations sur les fichiers, etc. C'est le cœur de l'implémentation asynchrone de Node.js.
Qu'il s'agisse d'une plate-forme Linux ou d'une plate-forme Windows, Node.js effectue en interne les opérations d'E/S asynchrones via le pool de threads , et LIBUV est implémenté différemment pour différentes plates-formes unifiées appel. Par conséquent, Le monothreading de Node.js signifie uniquement que JavaScript s'exécute dans un seul thread, et non que Node.js est monothread.
Principe de fonctionnement
Le cœur de l'implémentation asynchrone de Node.js est constitué d'événements, c'est-à-dire qu'il traite chaque tâche comme un événement à traiter, puis via Event Loop simule l'effet asynchrone. Afin de comprendre et d'accepter ce fait plus spécifiquement et clairement, utilisons du pseudo-code pour décrire son principe de fonctionnement.
【1】Définir la file d'attente des événements
Puisqu'il s'agit d'une file d'attente, il s'agit d'une structure de données premier entré, premier sorti (FIFO). tableau pour le décrire, comme suit :
/** * 定义事件队列 * 入队:push() * 出队:shift() * 空队列:length == 0 */ globalEventQueue: []
Nous utilisons des tableaux pour simuler la structure de la file d'attente : le premier élément du tableau est la tête de la file d'attente, le dernier élément du tableau est la queue de la file d'attente, push() consiste à insérer un élément à la fin de la file d'attente, shift() consiste à extraire un élément de la tête de la file d'attente. Cela implémente une simple file d’attente d’événements.
[2] Définir recevoir l'entrée de la demande
Chaque demande sera interceptée et saisie dans la fonction de traitement, comme indiqué ci-dessous :
/**
* 接收用户请求
* 每一个请求都会进入到该函数
* 传递参数request和response
*/
processHttpRequest:function(request,response){
// 定义一个事件对象
var event = createEvent({
params:request.params, // 传递请求参数
result:null, // 存放请求结果
callback:function(){} // 指定回调函数
});
// 在队列的尾部添加该事件
globalEventQueue.push(event);
}这个函数很简单,就是把用户的请求包装成事件,放到队列里,然后继续接收其他请求。
【3】定义 Event Loop
当主线程处于空闲时就开始循环事件队列,所以我们还要定义一个函数来循环事件队列:
/**
* 事件循环主体,主线程择机执行
* 循环遍历事件队列
* 处理非IO任务
* 处理IO任务
* 执行回调,返回给上层
*/
eventLoop:function(){
// 如果队列不为空,就继续循环
while(this.globalEventQueue.length > 0){
// 从队列的头部拿出一个事件
var event = this.globalEventQueue.shift();
// 如果是耗时任务
if(isIOTask(event)){
// 从线程池里拿出一个线程
var thread = getThreadFromThreadPool();
// 交给线程处理
thread.handleIOTask(event)
}else {
// 非耗时任务处理后,直接返回结果
var result = handleEvent(event);
// 最终通过回调函数返回给V8,再由V8返回给应用程序
event.callback.call(null,result);
}
}
}主线程不停的检测事件队列,对于 I/O 任务,就交给线程池来处理,非 I/O 任务就自己处理并返回。
【4】处理 I/O 任务
线程池接到任务以后,直接处理IO操作,比如读取数据库:
/**
* 处理IO任务
* 完成后将事件添加到队列尾部
* 释放线程
*/
handleIOTask:function(event){
//当前线程
var curThread = this;
// 操作数据库
var optDatabase = function(params,callback){
var result = readDataFromDb(params);
callback.call(null,result)
};
// 执行IO任务
optDatabase(event.params,function(result){
// 返回结果存入事件对象中
event.result = result;
// IO完成后,将不再是耗时任务
event.isIOTask = false;
// 将该事件重新添加到队列的尾部
this.globalEventQueue.push(event);
// 释放当前线程
releaseThread(curThread)
})
}当 I/O 任务完成以后就执行回调,把请求结果存入事件中,并将该事件重新放入队列中,等待循环,最后释放当前线程,当主线程再次循环到该事件时,就直接处理了。
总结以上过程我们发现,Node.js 只用了一个主线程来接收请求,但它接收请求以后并没有直接做处理,而是放到了事件队列中,然后又去接收其他请求了,空闲的时候,再通过 Event Loop 来处理这些事件,从而实现了异步效果,当然对于IO类任务还需要依赖于系统层面的线程池来处理。
因此,我们可以简单的理解为:Node.js 本身是一个多线程平台,而它对 JavaScript 层面的任务处理是单线程的。
CPU密集型是短板
至此,对于 Node.js 的单线程模型,我们应该有了一个简单而又清晰的认识,它通过事件驱动模型实现了高并发和异步 I/O,然而也有 Node.js 不擅长做的事情:
上面提到,如果是 I/O 任务,Node.js 就把任务交给线程池来异步处理,高效简单,因此 Node.js 适合处理I/O密集型任务。但不是所有的任务都是 I/O 密集型任务,当碰到CPU密集型任务时,即只用CPU计算的操作,比如要对数据加解密(node.bcrypt.js),数据压缩和解压(node-tar),这时 Node.js 就会亲自处理,一个一个的计算,前面的任务没有执行完,后面的任务就只能干等着 。如下图所示:
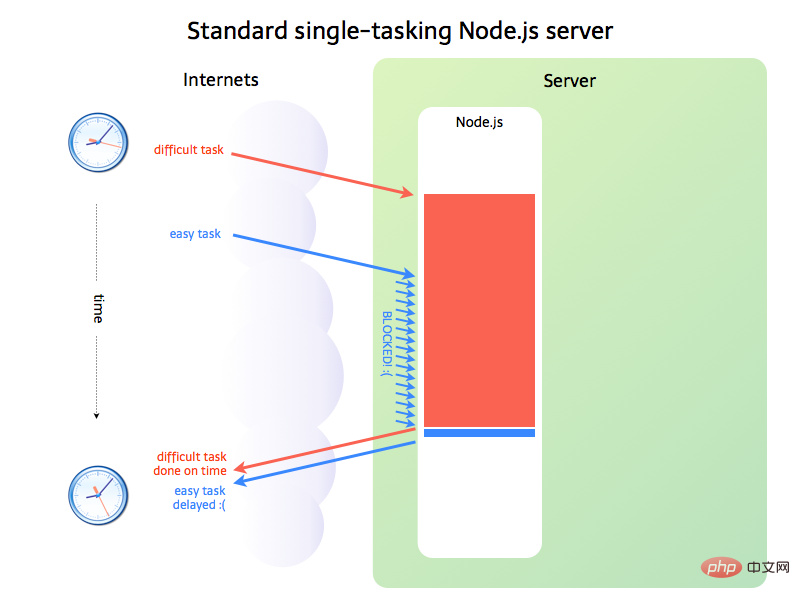
在事件队列中,如果前面的 CPU 计算任务没有完成,后面的任务就会被阻塞,出现响应缓慢的情况,如果操作系统本身就是单核,那也就算了,但现在大部分服务器都是多 CPU 或多核的,而 Node.js 只有一个 EventLoop,也就是只占用一个 CPU 内核,当 Node.js 被CPU 密集型任务占用,导致其他任务被阻塞时,却还有 CPU 内核处于闲置状态,造成资源浪费。
因此,Node.js 并不适合 CPU 密集型任务。
适用场景
RESTful API - 请求和响应只需少量文本,并且不需要大量逻辑处理, 因此可以并发处理数万条连接。
聊天服务 - 轻量级、高流量,没有复杂的计算逻辑。
更多编程相关知识,请访问:编程教学!!
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 La différence entre nodejs et vuejs
Apr 21, 2024 am 04:17 AM
La différence entre nodejs et vuejs
Apr 21, 2024 am 04:17 AM
Node.js est un environnement d'exécution JavaScript côté serveur, tandis que Vue.js est un framework JavaScript côté client permettant de créer des interfaces utilisateur interactives. Node.js est utilisé pour le développement côté serveur, comme le développement d'API de service back-end et le traitement des données, tandis que Vue.js est utilisé pour le développement côté client, comme les applications monopage et les interfaces utilisateur réactives.
 Nodejs est-il un framework backend ?
Apr 21, 2024 am 05:09 AM
Nodejs est-il un framework backend ?
Apr 21, 2024 am 05:09 AM
Node.js peut être utilisé comme framework backend car il offre des fonctionnalités telles que des performances élevées, l'évolutivité, la prise en charge multiplateforme, un écosystème riche et une facilité de développement.
 Comment connecter Nodejs à la base de données MySQL
Apr 21, 2024 am 06:13 AM
Comment connecter Nodejs à la base de données MySQL
Apr 21, 2024 am 06:13 AM
Pour vous connecter à une base de données MySQL, vous devez suivre ces étapes : Installez le pilote mysql2. Utilisez mysql2.createConnection() pour créer un objet de connexion contenant l'adresse de l'hôte, le port, le nom d'utilisateur, le mot de passe et le nom de la base de données. Utilisez connection.query() pour effectuer des requêtes. Enfin, utilisez connection.end() pour mettre fin à la connexion.
 Quelles sont les variables globales dans nodejs
Apr 21, 2024 am 04:54 AM
Quelles sont les variables globales dans nodejs
Apr 21, 2024 am 04:54 AM
Les variables globales suivantes existent dans Node.js : Objet global : global Module principal : processus, console, nécessiter Variables d'environnement d'exécution : __dirname, __filename, __line, __column Constantes : undefined, null, NaN, Infinity, -Infinity
 Quelle est la différence entre les fichiers npm et npm.cmd dans le répertoire d'installation de nodejs ?
Apr 21, 2024 am 05:18 AM
Quelle est la différence entre les fichiers npm et npm.cmd dans le répertoire d'installation de nodejs ?
Apr 21, 2024 am 05:18 AM
Il existe deux fichiers liés à npm dans le répertoire d'installation de Node.js : npm et npm.cmd. Les différences sont les suivantes : différentes extensions : npm est un fichier exécutable et npm.cmd est un raccourci de fenêtre de commande. Utilisateurs Windows : npm.cmd peut être utilisé à partir de l'invite de commande, npm ne peut être exécuté qu'à partir de la ligne de commande. Compatibilité : npm.cmd est spécifique aux systèmes Windows, npm est disponible multiplateforme. Recommandations d'utilisation : les utilisateurs Windows utilisent npm.cmd, les autres systèmes d'exploitation utilisent npm.
 Y a-t-il une grande différence entre nodejs et java ?
Apr 21, 2024 am 06:12 AM
Y a-t-il une grande différence entre nodejs et java ?
Apr 21, 2024 am 06:12 AM
Les principales différences entre Node.js et Java résident dans la conception et les fonctionnalités : Piloté par les événements ou piloté par les threads : Node.js est piloté par les événements et Java est piloté par les threads. Monothread ou multithread : Node.js utilise une boucle d'événements monothread et Java utilise une architecture multithread. Environnement d'exécution : Node.js s'exécute sur le moteur JavaScript V8, tandis que Java s'exécute sur la JVM. Syntaxe : Node.js utilise la syntaxe JavaScript, tandis que Java utilise la syntaxe Java. Objectif : Node.js convient aux tâches gourmandes en E/S, tandis que Java convient aux applications de grande entreprise.
 Nodejs est-il un langage de développement back-end ?
Apr 21, 2024 am 05:09 AM
Nodejs est-il un langage de développement back-end ?
Apr 21, 2024 am 05:09 AM
Oui, Node.js est un langage de développement backend. Il est utilisé pour le développement back-end, notamment la gestion de la logique métier côté serveur, la gestion des connexions à la base de données et la fourniture d'API.
 Comment déployer le projet nodejs sur le serveur
Apr 21, 2024 am 04:40 AM
Comment déployer le projet nodejs sur le serveur
Apr 21, 2024 am 04:40 AM
Étapes de déploiement de serveur pour un projet Node.js : Préparez l'environnement de déploiement : obtenez l'accès au serveur, installez Node.js, configurez un référentiel Git. Créez l'application : utilisez npm run build pour générer du code et des dépendances déployables. Téléchargez le code sur le serveur : via Git ou File Transfer Protocol. Installer les dépendances : connectez-vous en SSH au serveur et installez les dépendances de l'application à l'aide de npm install. Démarrez l'application : utilisez une commande telle que node index.js pour démarrer l'application ou utilisez un gestionnaire de processus tel que pm2. Configurer un proxy inverse (facultatif) : utilisez un proxy inverse tel que Nginx ou Apache pour acheminer le trafic vers votre application
