
 développement back-end
Tutoriel Python
Présentation pratique de l'analyse des données Python Analyse des données
développement back-end
Tutoriel Python
Présentation pratique de l'analyse des données Python Analyse des données
Présentation pratique de l'analyse des données Python Analyse des données

Tutoriel PythonLa colonne présente les données de présentation.

Recommandé (gratuit) : Tutoriel Python
Répertoire d'articles
- 1. Introduction à l'analyse des données
- 1. Fondamentaux de l'ère du big data
- 2. 🎜 > 3. Le chemin pour devenir analyste de données
2. Installation et configuration de l'environnement Python-
- 1.Version Python
- 1.Version Python
- 🎜 >
- 2. Installer Python sur différents systèmes
- 3. Configuration des variables d'environnement
- 5. >
- 3. Introduction et installation d'Anaconda
- 1. Qu'est-ce qu'Anaconda
- 2. Téléchargez et installez Anaconda
- 4. Jupyter Notebook
- 1.Introduction de base à Jupyter Notebook
- 2. .Jupyter Notebook Utilisation
- 3. Utilisation de Python dans Jupyter
- 4. Cas d'interaction avec les données
- Charger les données CSV, traiter les données et enregistrer dans MongoDB. base de données
Analyse des données d'introduction
1. Fondamentaux de l'ère du Big Data
L'état de développement de l'industrie du Big Data : Les données ont désormais montré une croissance
- , et il se peut qu'il y ait soyez 100 000 nouvelles données chaque minute :
- Plus de 13 000 téléchargements d'applications iPhone
- Publication de plus de 98 000 nouveaux messages Weibo sur Twitter
- Envoyé de plus de 168 millions d'e-mails
- Taobao Double Eleven 10680+ nouvelles commandes
- À l'ère du big data, trois changements majeurs se sont produits :
- De l'échantillon aléatoire aux données complètes
- De l'exactitude à la confusion
Un homme va au Les supermarchés pour acheter des couches achèteront de la bière avec. Les résultats de l'analyse des mégadonnées incitent les supermarchés à mettre de la bière près des étagères à couches, augmentant ainsi les ventes. Il n'y a pas de relation causale entre l'achat de couches et l'achat de bière, mais il existe une certaine relation. corrélation.  Le statut de l'application nationale du Big Data est le suivant (du CSDN) :
Le statut de l'application nationale du Big Data est le suivant (du CSDN) :
On peut voir que l'application du Big Data a atteint une certaine échelle, mais là il y a encore beaucoup de marge de développement.
- Les besoins en talents comprennent principalement :
-
- Analyste de données
- Analyse statistique
- Analyse prédictive
-
- Ingénieur Big data
- Développement de plateforme
- Développement d'applications
-
- Architecte de données
- Compréhension des affaires
- Déploiement d'applications
La raison pour laquelle vous devriez apprendre l'analyse des données est que les données sont Devenant de plus en plus courante et moins chère, l'analyse peut fournir un service rare qui apporte une
valeur supplémentairepour les données.
2. Perspectives de carrière des analystes de données- Problèmes que les analystes de données doivent résoudre :
Demande estimée, allocation Production Capacité
À l'ère du big data, la capacité à interpréter les données est encore plus nécessaire. Q : La capacité du four est limitée, quels types de pain faut-il produire ? A : Lister les pains les plus appréciés et privilégier la production des
produits phares
. L'essentiel est de trouver le produit star, ce qui nécessite de compter le chiffre d'affaires total du pain, puis de calculer la proportion relative de chaque type de pain dans le chiffre d'affaires total, et de privilégier la réalisation de combinaisons de produits pouvant représenter 70 % du chiffre d'affaires. Cela utilisera le tableau de distribution statistique et l'histogramme. Cette méthode d'analyse est également appelée méthode d'analyse ABC, comme suit :
L'essentiel est de trouver le produit star, ce qui nécessite de compter le chiffre d'affaires total du pain, puis de calculer la proportion relative de chaque type de pain dans le chiffre d'affaires total, et de privilégier la réalisation de combinaisons de produits pouvant représenter 70 % du chiffre d'affaires. Cela utilisera le tableau de distribution statistique et l'histogramme. Cette méthode d'analyse est également appelée méthode d'analyse ABC, comme suit : -
expériences contrôlées randomisées
Évaluer l'efficacité du plan marketing Les statistiques ne consistent pas seulement à analyser des données. La clé est de déduire comment influencer le comportement des clients à partir des résultats de l'analyse, de le formuler dans un
plan d'affaires
spécifique et d'agir en conséquence.
Q : Si vous souhaitez vendre du pain en ligne, quel type de publicité est le plus efficace ? A : Écrivez deux types de rédaction et faites-en la publicité pendant un certain temps pour voir leur efficacité. Pour comparer l'efficacité de la publicité, le meilleur moyen est d'utiliser des statistiques pour laisser deux types de publicités apparaître de manière aléatoire. Après un certain temps, observez quel effet publicitaire est le meilleur, puis utilisez-le. à grande échelle, une publicité plus efficace.
Contrôle de la qualité des produits
Il est très important de découvrir la relation entre les résultats et les causes des résultats.
Q : Comment savoir à partir du pain si le boulanger a fait des économies ?
A : Vérifiez quelques pains au hasard et mesurez-les pour voir si la différence de poids est trop importante. Vous devez d'abord connaître le poids moyen du pain, puis goûter le pain pour voir si le poids du pain présente une répartition normale en forme de cloche ? S'il s'écarte de la courbe, cela peut indiquer un problème de qualité du pain. Comme suit :
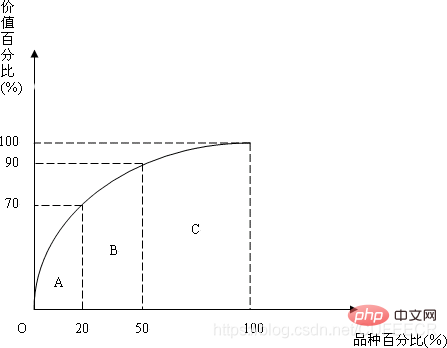 L'essentiel est de trouver le produit star, ce qui nécessite de compter le chiffre d'affaires total du pain, puis de calculer la proportion relative de chaque type de pain dans le chiffre d'affaires total, et de privilégier la réalisation de combinaisons de produits pouvant représenter 70 % du chiffre d'affaires. Cela utilisera le tableau de distribution statistique et l'histogramme. Cette méthode d'analyse est également appelée méthode d'analyse ABC, comme suit :
L'essentiel est de trouver le produit star, ce qui nécessite de compter le chiffre d'affaires total du pain, puis de calculer la proportion relative de chaque type de pain dans le chiffre d'affaires total, et de privilégier la réalisation de combinaisons de produits pouvant représenter 70 % du chiffre d'affaires. Cela utilisera le tableau de distribution statistique et l'histogramme. Cette méthode d'analyse est également appelée méthode d'analyse ABC, comme suit : 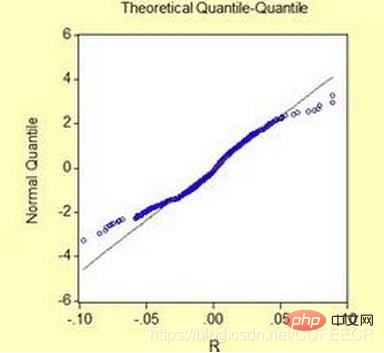 Vous devez d'abord connaître le poids moyen du pain, puis goûter le pain pour voir si le poids du pain présente une répartition normale en forme de cloche ? S'il s'écarte de la courbe, cela peut indiquer un problème de qualité du pain. Comme suit :
Vous devez d'abord connaître le poids moyen du pain, puis goûter le pain pour voir si le poids du pain présente une répartition normale en forme de cloche ? S'il s'écarte de la courbe, cela peut indiquer un problème de qualité du pain. Comme suit : Un bon analyste de données est un bon planificateur de produits et un leader de l'industrie
Dans les entreprises informatiques, les excellents analystes de données sont très prometteurs. Devenez membre senior du entreprise.
Le workflow d'un analyste de données est le suivant : 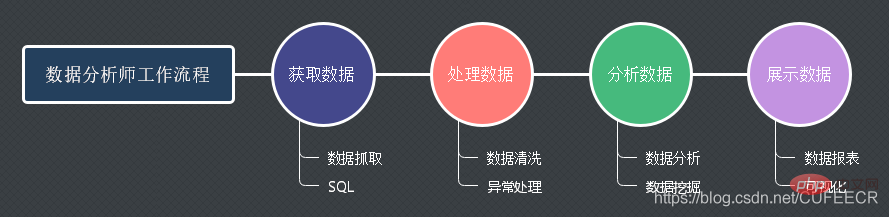
Les trois tâches principales d'un analyste de données :
- Analyser l'historique
- Prédire l'avenir
- Optimiser la sélection
8 compétences requises par les analystes de données :
- Statistiques
- Tests statistiques, Valeurs P, distributions, estimation
- Outils de base
- Python
- SQL
- Calcul multivariable Somme Linéaire Algèbre
- Data Wrangling
- Visualisation des données
- Génie logiciel
- Apprentissage automatique
- La pensée des data scientists
- Résolution de problèmes
Trois capacités majeures requises par les analystes de données :
- Bases statistiques et application des outils analytiques
- Compétences en codage informatique
- Connaissance de domaines d'application ou d'industries spécifiques
Historique de croissance d'un analyste de données typique : 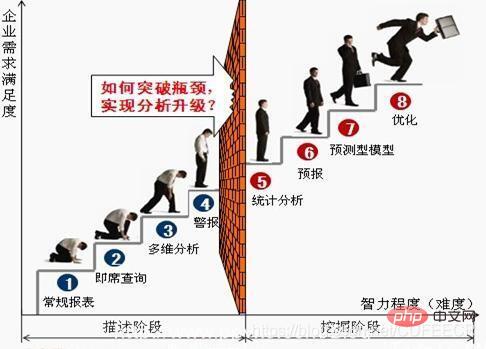
3. Le chemin pour devenir analyste de données
Culture de soi pour devenir analyste de données :
- Sensible
- Exploration
- Détaillé
- Pragmatique
Les compétences qu'un analyste de données doit posséder sont les suivantes :
- Familier avec le traitement des données Excel
- Diplôme spécialisé sensible aux données
- Familier avec les connaissances commerciales et industrielles de l'entreprise
- Méthodes d'analyse des données de base
-
Méthodes d'analyse de base
- Méthode d'analyse contrastée
- Méthode d'analyse de groupe
- Méthode d'analyse croisée
- Méthode d'analyse structurelle
- Méthode d'analyse en entonnoir
- Méthode d'analyse d'évaluation complète
- Méthode d'analyse factorielle
- Analyse de corrélation matricielle
-
Méthode d'analyse avancée
- Méthode d'analyse de corrélation
- Méthode d'analyse de régression
- Méthode d'analyse de cluster
- Méthode d'analyse discriminante
- Méthode d'analyse en composantes principales
- Méthode d'analyse factorielle
- Méthode d'analyse des correspondances
- Séries chronologiques
-
Méthodes d'analyse de base
Pratique de l'analyse de données dans différentes industries Contenu du poste et responsabilités du personnel :
- S'engager dans l'analyse des données
- Apprendre à faire des rapports quotidiens
- Ventes quotidiennes et tableaux d'inventaire
- Ventes de produits prévisions
- Calcul d'inventaire et alerte précoce
- Tableaux liés à l'analyse du trafic
- Révision
- Analyse des données et personnel d'exploitation
- Fournir un support de données pour l'optimisation des produits
- Vérifier les effets d'amélioration du produit
- Fournir des e-mails et des rapports à la haute direction
- Internet + analyse
- Suivi des indicateurs KPI
- Divers rapports périodiques
- Rapports analytiques pour une certaine problématique métier
- Modélisation et analyse hors ligne de l'entreprise
Le fondement très important de l'analyse des données est les mathématiques, mais peu importe si vous n'êtes pas bon en mathématiques. Vous pouvez utiliser Python pour vous aider à apprendre :
Python est. pas seulement un langage de programmation, et c'est la base de technologies telles que l'exploration de données et l'apprentissage automatique, qui facilite la mise en place de flux de travail automatisés
Il n'est pas difficile de démarrer avec Python. Cela ne nécessite pas trop de mathématiques ; Ce qui est important, c'est que vous devez savoir comment exprimer une logique algorithmique dans un langage ;
Python possède de nombreuses bibliothèques d'outils et de commandes packagées. Ce qu'il faut faire, c'est utiliser des méthodes mathématiques pour résoudre un problème et le construire.
Pour démarrer rapidement avec l'analyse de données Python, vous devez utiliser les boîtes à outils liées à Python :
(1) La plus grande caractéristique de Python est qu'il dispose d'un informatique scientifique énorme et actif. communauté , la tendance à utiliser python pour le calcul scientifique devient de plus en plus évidente.
(2) Parce que Python a continuellement amélioré les bibliothèques, il est devenu une alternative majeure pour les tâches de traitement de données. Combiné à sa forte force en programmation générale, vous pouvez simplement utiliser Python comme langage pour créer des applications centrales. , notamment :
- Bibliothèques communes d'analyse de données
- Numpy
- Scipy
- Pandas
- matplotlib
- Bibliothèques d'analyse de données avancées couramment utilisées
- nltk
- igraph
- scikit-learn
(3) En tant que plateforme de calcul scientifique, Python peut facilement intégrer les codes C, C++ et Fortran.
Préparation à l'analyse des données :
- Comprendre les données
- Nettoyage des données et analyse préliminaire
- Dessin et visualisation
- Données Traitement d'agrégation et de regroupement
- Exploration de données
Algorithmes courants pour l'analyse et l'exploration de données :
- Régression linéaire
- Analyse de séries chronologiques
- Algorithme de classification
- Algorithme de clustering
- Algorithme de réduction de dimensionnalité
La méthode d'apprentissage et d'engagement dans l'analyse des données est :
- Réfléchissez avec diligence
- Faites plus de travail pratique
- Résumé plus
2. Installation et configuration de l'environnement Python
1.Version Python
Python est divisé en deux versions majeures : 3.X et 2.X.
La version 3.0 de Python est souvent appelée Python 3000, ou Py3k en abrégé. Il s'agit d'une mise à niveau majeure par rapport aux versions précédentes de Python.
Afin de ne pas alourdir la tâche, Python 3.X n'a pas été conçu dans un souci de compatibilité descendante. De nombreux programmes conçus pour les versions antérieures de Python ne peuvent pas fonctionner normalement sur Python 3.X.
La plupart des bibliothèques tierces travaillent dur pour être compatibles avec la version Python 3.X.
2. Installez Python sur différents systèmes
(1) Systèmes Unix et Linux
- Visitez http://www.python. org /download/
- Sélectionnez le package compressé de code source adapté à Unix/Linux
- Téléchargez et décompressez le package compressé
- Si vous devez personnaliser certaines options, modifiez Modules/ Configuration
- Exécuter
./configurescript makemake install
(2) Système de fenêtres
- Visitez http://www.python.org/download/
- Sélectionnez le package d'installation de la plateforme Windows dans la liste de téléchargement
Le téléchargement depuis le site officiel étant très lent, j'ai réglé le package d'installation se télécharge pour chaque version de Python Oui, vous pouvez directement cliquer pour rejoindre le groupe QQ.963624318 Téléchargez-le simplement dans le dossier du groupe Package d'installation lié à Python . - Après le téléchargement, double-cliquez sur le package de téléchargement pour accéder à l'assistant d'installation de Python. L'installation est très simple. Utilisez simplement les paramètres par défaut et cliquez sur Suivant jusqu'à ce que l'installation soit terminée.
(3) Le système Mac
est livré avec python 2.7, vous pouvez exécuter brew install python pour installer la nouvelle version.
3. Configuration des variables d'environnement
Le système Windows doit configurer les variables d'environnement.
Si vous n'avez pas choisi d'ajouter des variables d'environnement lors de l'installation de Python, vous devez les ajouter manuellement. Vous devez ajouter le chemin pour installer Python XXXPythonXXX et XXXPythonXXXScripts aux variables d'environnement. façons :
- Ajoutez
à la ligne de commande et exécutezpath=%path%;XXXPythonXXXetpath=%path%;XXXPythonXXXScriptsrespectivement dans CMD. - Ajoutez
dans les paramètres système. Cliquez avec le bouton droit sur l'ordinateur → Propriétés → Paramètres système avancés → Propriétés système → Variables d'environnement → Double-cliquez sur le chemin → Ajoutez les chemins d'installationXXXPythonXXXetXXXPythonXXXScriptscomme suit. :

Cliquez enfin sur Confirmer pour quitter.
4. Installer pip
pip est un outil d'installation et de gestion de packages en Python Vous pouvez choisir d'installer pip lors de l'installation de Python 2 >=2.7. .9 ou Python 3>=3.4.
Si pip n'est pas installé, vous pouvez l'installer via la commande :
- Linux ou Mac
pip install -U pip - Windows (entrée cmd)
python -m pip install -U pip
5. Sélection de l'environnement de développement intégré
Python a de nombreux éditeurs, dont PyCharm, etc. Ici, choisissez PyCharm :
PyCharm est construit par JetBrains, un IDE Python qui prend en charge les systèmes Mac OS, Windows et Linux.
Comprend le Débogage, la coloration syntaxique, la gestion de projet, le Saut de code, les Invites intelligentes, la saisie semi-automatique, les tests unitaires, le contrôle de version et d'autres fonctions.
Vous pouvez choisir la version appropriée à télécharger et à installer sur https://www.jetbrains.com/pycharm/download/.
3. Introduction et installation d'Anaconda
1. Qu'est-ce qu'Anaconda
Anaconda est un logiciel qui peut être utilisé. pour La distribution Python de Scientific Computing prend en charge les systèmes Linux, Mac et Windows et intègre des bibliothèques de calcul scientifique couramment utilisées.
Il résout deux problèmes majeurs du Python officiel :
(1) Fournit une fonction de gestion des packages, qui résout le problème des échecs fréquents lors de l'installation de packages tiers sur la plate-forme Windows
(2) Fournit la gestion de l'environnement ; fonction, La fonction est similaire à virtualenv, qui résout le problème de la coexistence et du changement de plusieurs versions de Python.
2. Téléchargez et installez Anaconda
Téléchargez le package d'installation directement depuis le site officiel https://www.anaconda.com/products/inpidual et choisissez de télécharger Python3 Le package d'installation de .8Version personnelle est suffisant, mais la vitesse de téléchargement depuis le site officiel est lente, j'ai donc téléchargé et trié le package d'installation d'Anaconda correspondant à Python 3.8 . Vous pouvez directement cliquer pour rejoindre le groupe QQ.
 963624318 Téléchargez-le simplement dans le dossier du groupe Package d'installation lié à Python .
963624318 Téléchargez-le simplement dans le dossier du groupe Package d'installation lié à Python .
Installez directement après le téléchargement. Veuillez noter que pendant le processus de clic, une invite pour ajouter des variables d'environnement apparaîtra, comme suit : 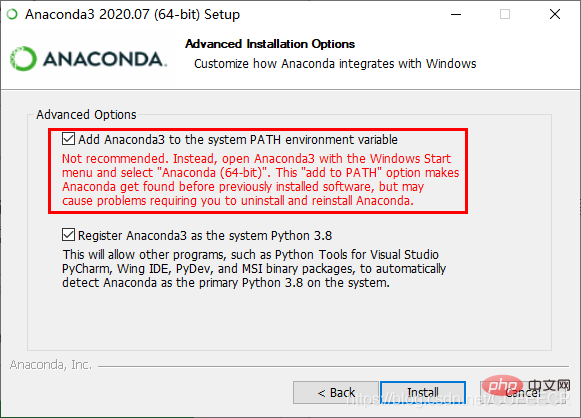
Enfin, cliquez sur Suivant. Une fois l'installation terminée, cliquez sur la touche Win (sous le système Windows) pour voir la liste des applications récemment ajoutées ou A, comme indiqué ci-dessous : 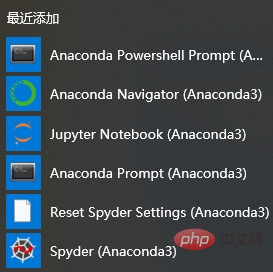
À ce stade, vous pouvez cliquer sur Anaconda Navigator, comme indiqué ci-dessous : 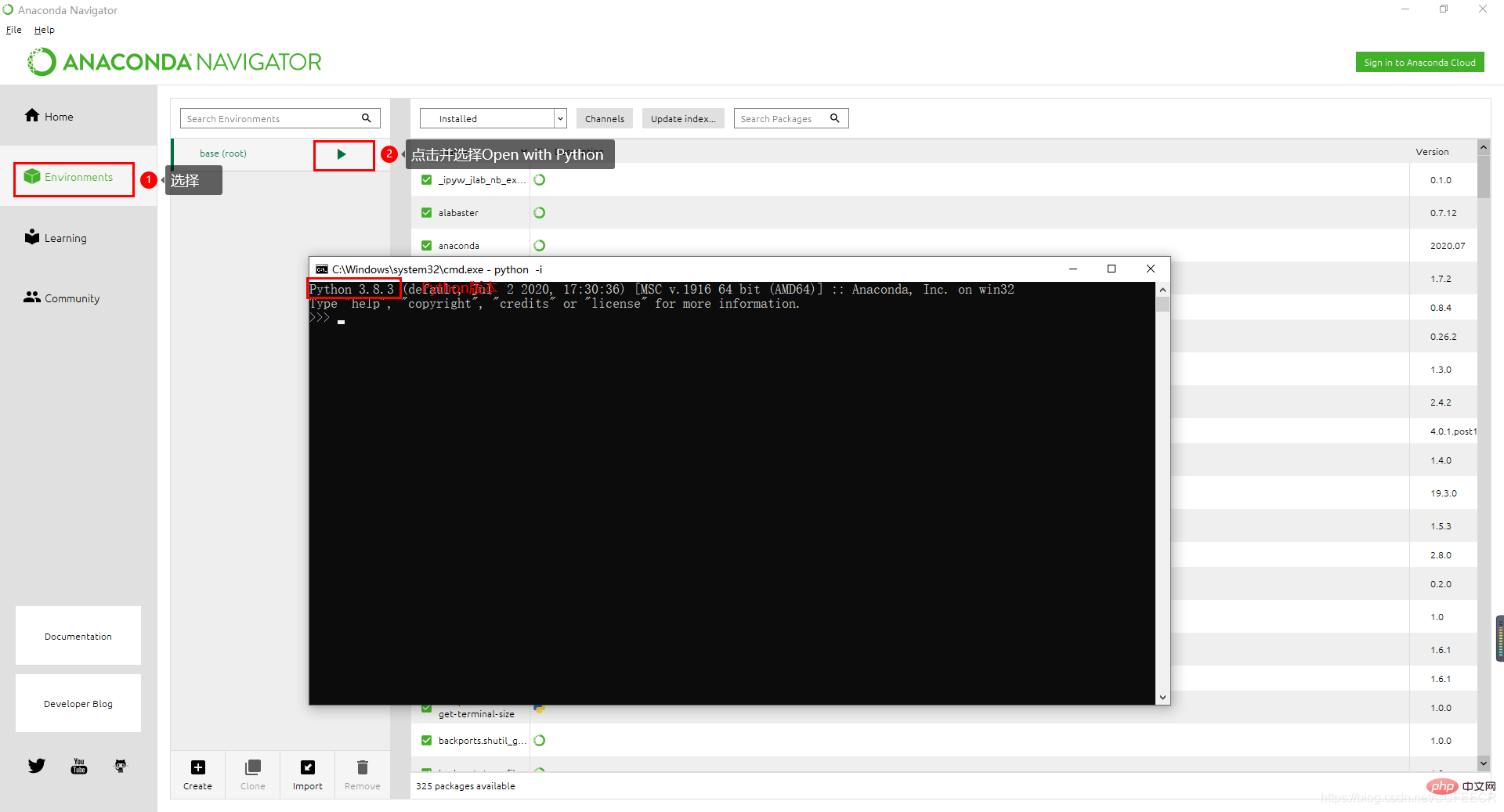
Vous pouvez voir que l'environnement est Python 3.8.3 et que la base L'environnement créé par Anaconda est nommé base. C'est également l'environnement par défaut, et vous pouvez également voir les bibliothèques installées par défaut.
Ouvrez l'outil de ligne de commande Anaconda Anaconda Powershell Prompt, saisissez python -V et imprimez également Python 3.8.3.
Vous pouvez également créer un nouvel environnement conda via des commandes. Par exemple, après l'exécution de conda create --name py27 python=2.7, un environnement conda avec Python version 2.7 nommé py27 est créé.
Activez la commande d'exécution de l'environnement conda activate py27, et désactivez la commande d'utilisation conda deactivate.
Vous pouvez exécuter conda list dans la ligne de commande pour afficher les bibliothèques installées, comme suit :
# packages in environment at E:\Anaconda3: # # Name Version Build Channel _ipyw_jlab_nb_ext_conf 0.1.0 py38_0 alabaster 0.7.12 py_0 anaconda 2020.07 py38_0 anaconda-client 1.7.2 py38_0 anaconda-navigator 1.9.12 py38_0 ... zlib 1.2.11 h62dcd97_4 zope 1.0 py38_1 zope.event 4.4 py38_0 zope.interface 4.7.1 py38he774522_0 zstd 1.4.5 ha9fde0e_0
3. Introduction à l'outil conda et à la gestion des packages
Conda est un outil sous Anaconda pour lagestion des packages et la gestion de l'environnement Sa fonction est similaire à la combinaison de pip et virtualenv. La gestion de l'environnement et virtualenv sont fondamentalement des opérations similaires. . Après une installation réussie, conda sera ajouté par défaut aux variables d'environnement, vous pourrez donc exécuter la commande conda directement dans la fenêtre de ligne de commande.
| 命令含义 | conda命令 |
|---|---|
| conda –h | 查看帮助 |
| 基于python3.6版本创建名为python36的环境 | conda create --name python36 python=3.6 |
| 激活此环境 | activate python36(Windows)、source activate python36(linux/mac) |
| 查看python版本 | python -V |
| 退出当前环境 | deactivate python36 |
| 删除环境 | conda remove -n py27 --all |
| 查看所有安装的环境 | conda info -e |
| 包管理命令意义 | 包管理命令 |
|---|---|
| 安装matplotlib | conda install matplotlib |
| 查看已安装的包 | conda list |
| 包更新 | conda update matplotlib |
| 删除包 | conda remove matplotlib |
, conda lui-même Il peut être considéré comme un package, l'environnement python peut être considéré comme un package et anaconda peut également être considéré comme un package. Par conséquent, en plus des packages tiers ordinaires prenant en charge les mises à jour, ces trois packages prennent également en charge le. commandes suivantes : anything is a package一切皆是包
四、Jupyter Notebook
1.Jupyter Notebook基本介绍
Jupyter Notebook(此前被称为IPython notebook)是一个交互式笔记本,支持运行40多种编程语言。
在开始使用notebook之前,需要先安装该库:
(1)在命令行中执行pip install jupyter来安装;
(2)安装Anaconda后自带Jupyter Notebook。
在命令行中执行jupyter notebook,就会在当前目录下启动Jupyter服务并使用默认浏览器打开页面,还可以复制链接到其他浏览器中打开,如下:
可以看到,notebook界面由以下部分组成:
(1)notebook名称;
(2)主工具栏,提供了保存、导出、重载notebook,以及重启内核等选项;
(3)notebook主要区域,包含了notebook的内容编辑区。
2.Jupyter Notebook的使用
在Jupyter页面下方的主要区域,由被称为单元格的部分组成。每个notebook由多个单元格构成,而每个单元格又可以有不同的用途。
上图中看到的是一个代码单元格(code cell),以[ ]开头,在这种类型的单元格中,可以输入任意代码并执行。
例如,输入1 + 2并按下Shift + Enter,单元格中的代码就会被计算,光标也会被移动到一个新的单元格中。
如果想新建一个notebook,只需要点击New,选择希望启动的notebook类型即可。
简单使用示意如下: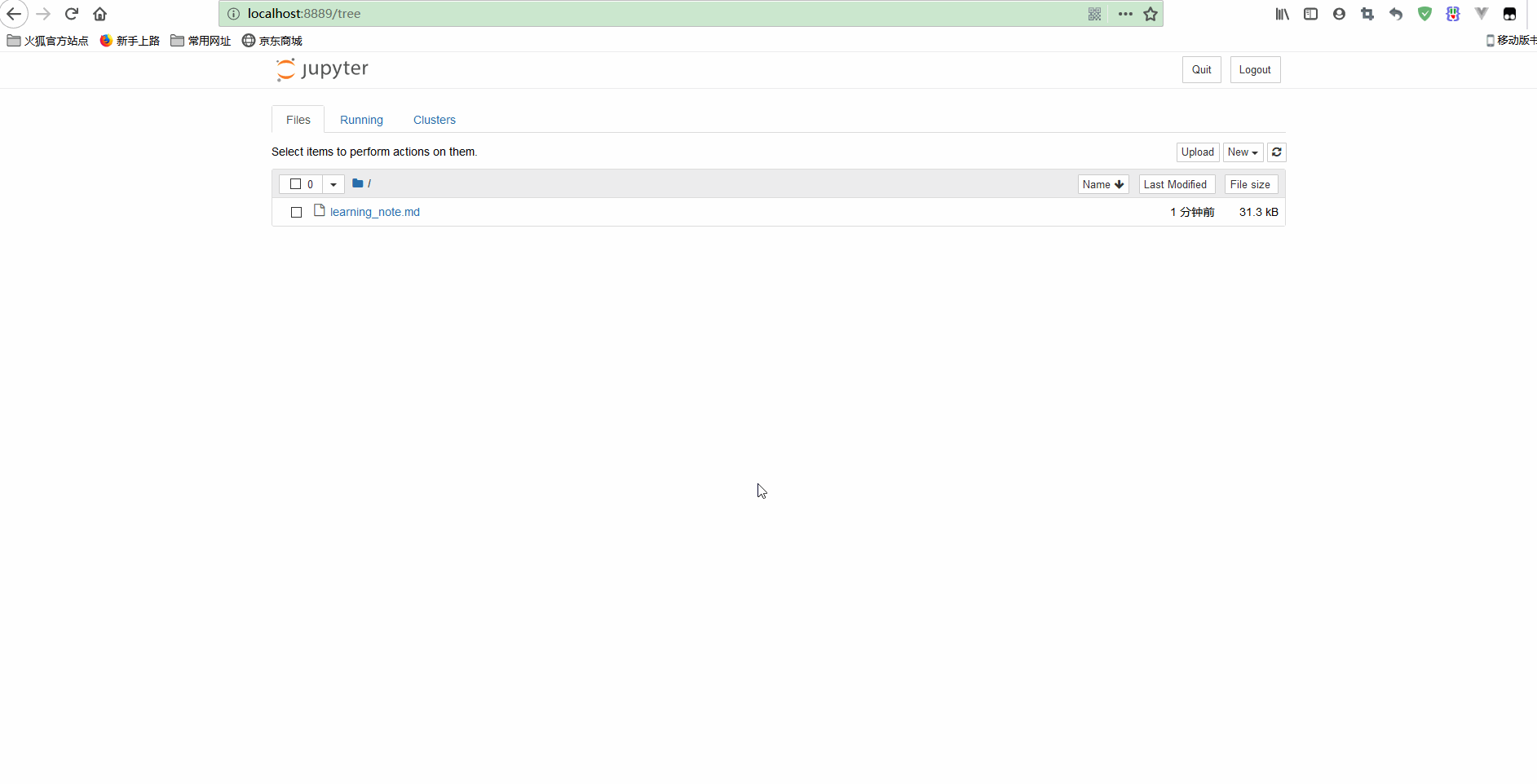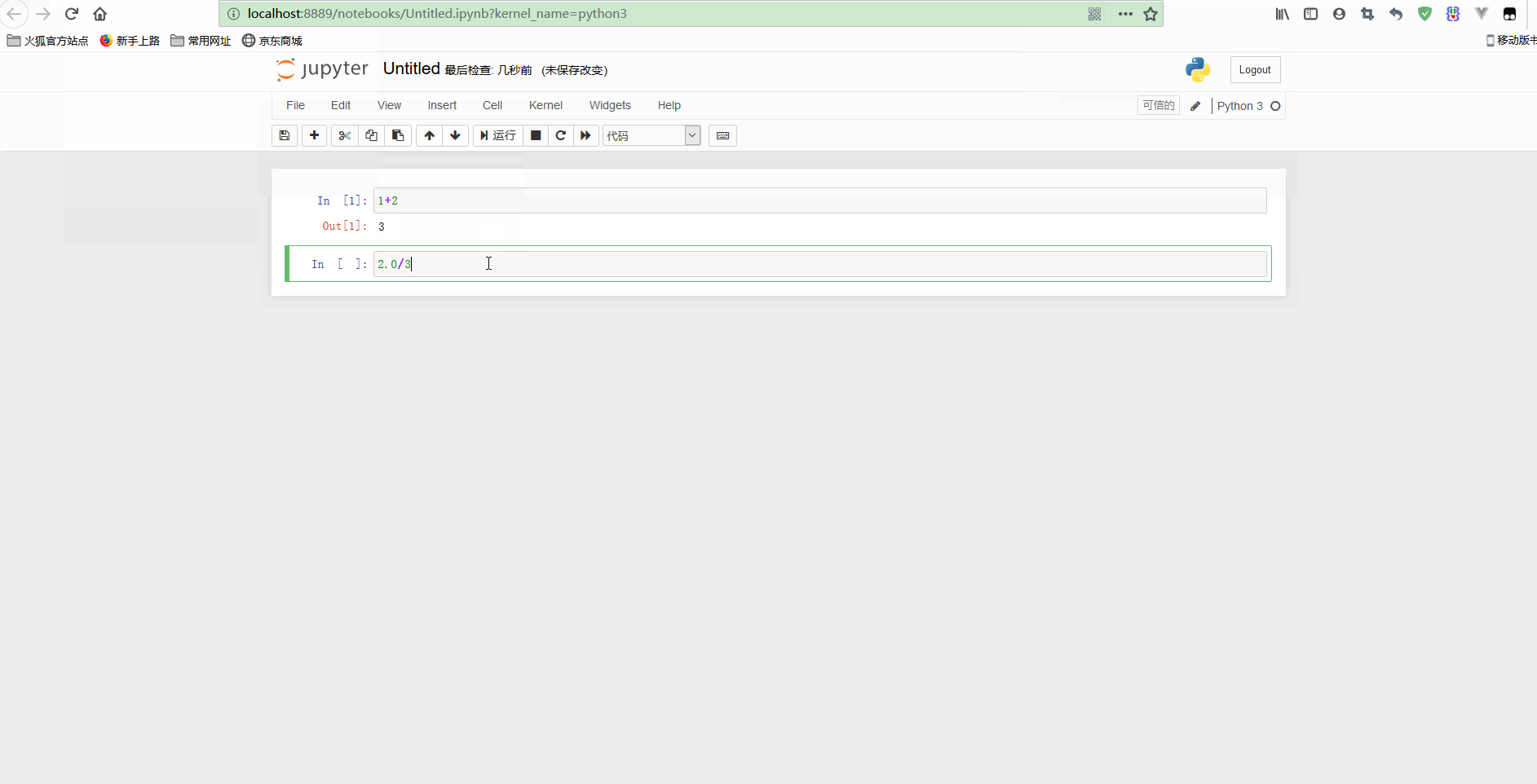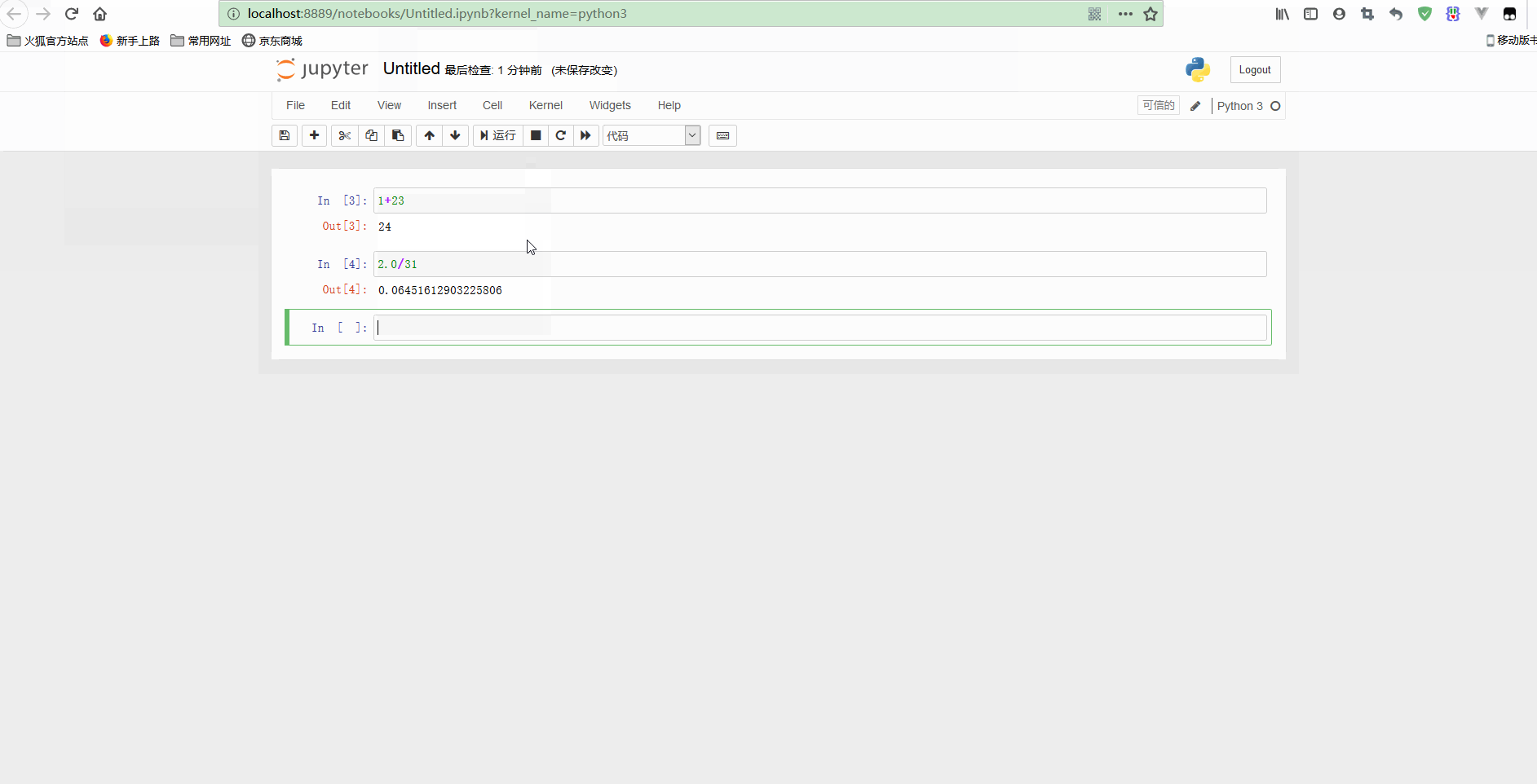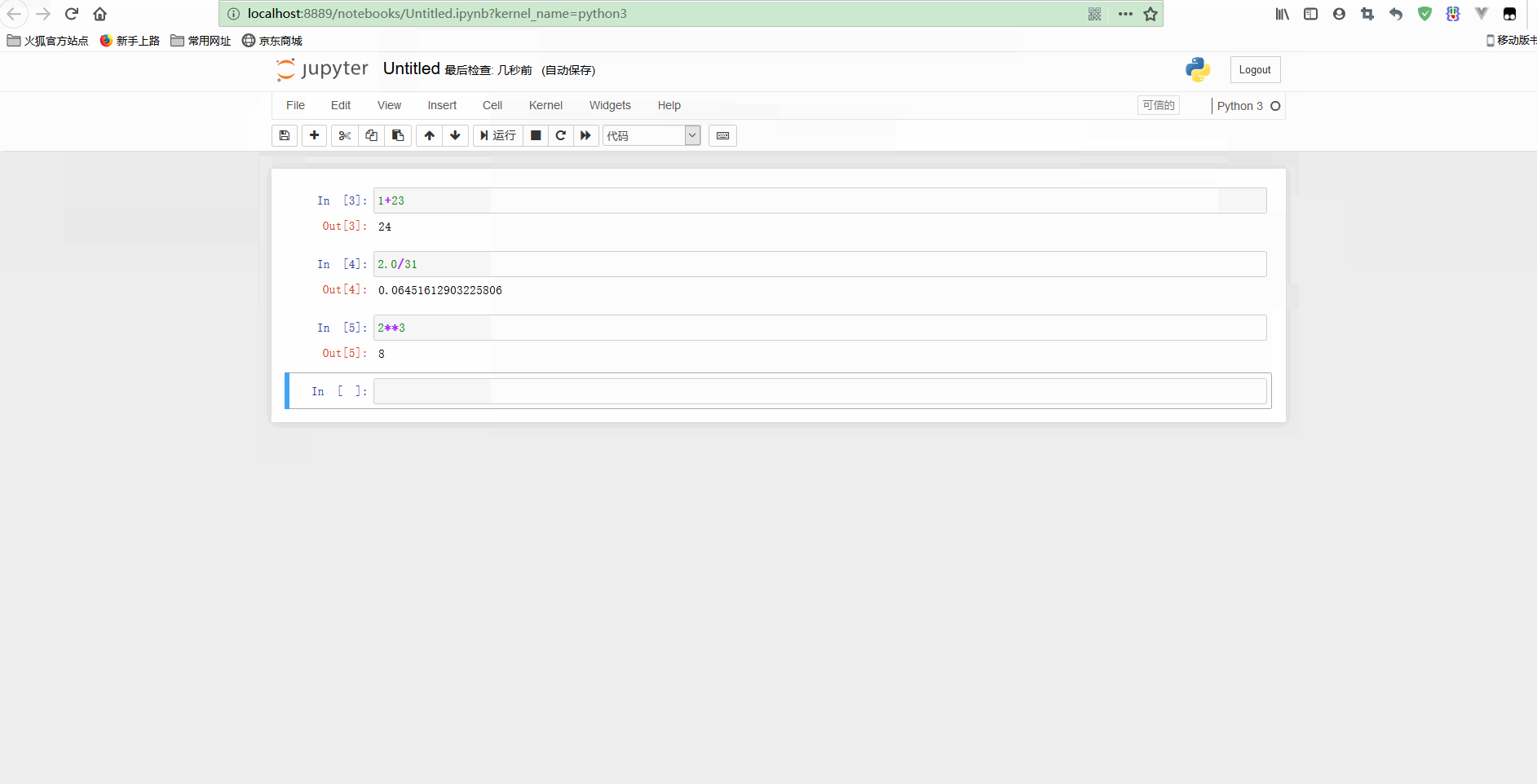
可以看到,notebook可以修改之前的单元格,对其重新计算,这样就可以更新整个文档了。如果你不想重新运行整个脚本,只想用不同的参数测试某个程式的话,这个特性显得尤其强大。
不过,也可以重新计算整个notebook,只要点击Cell -> Run all即可。
再测试标题和其他代码如下: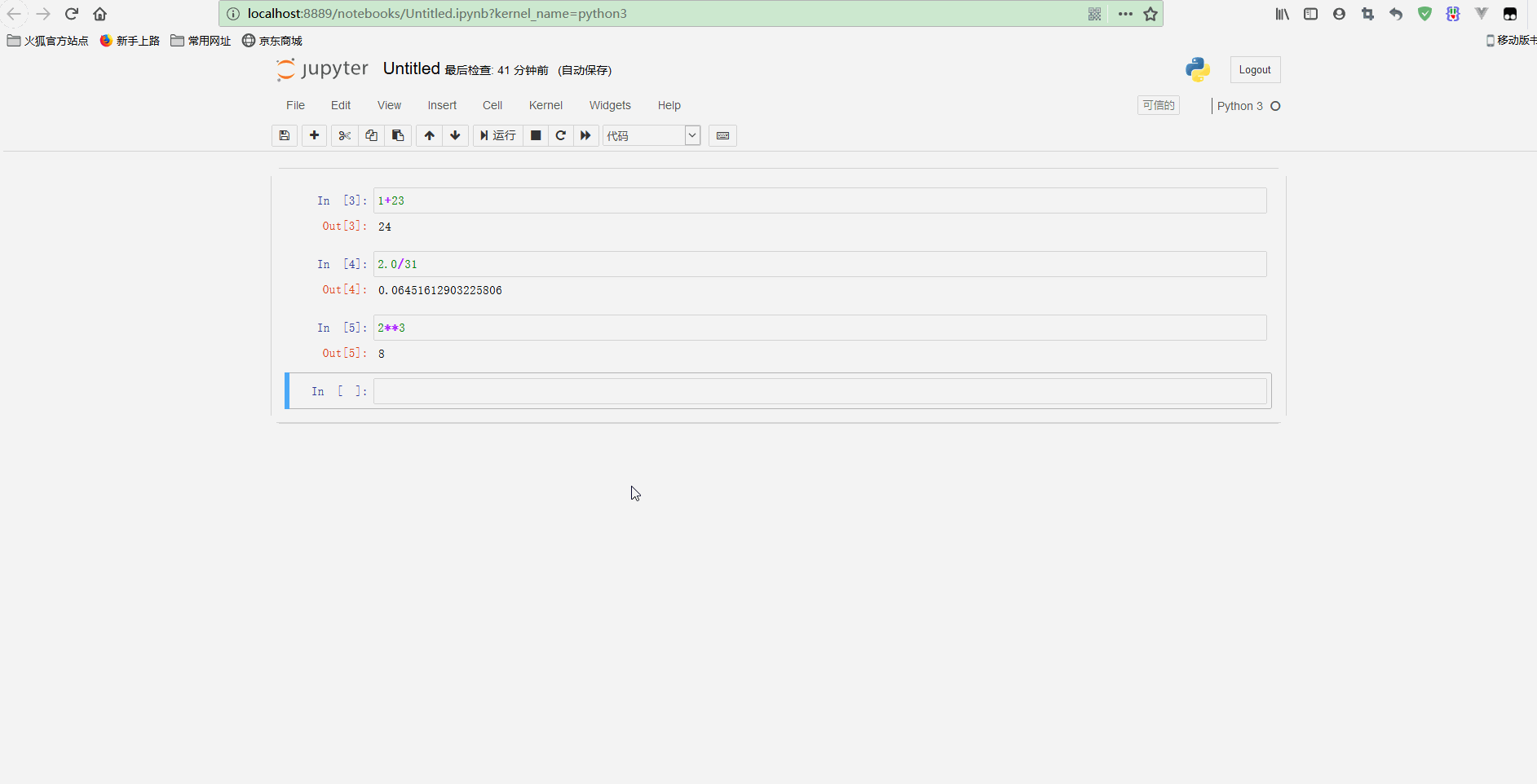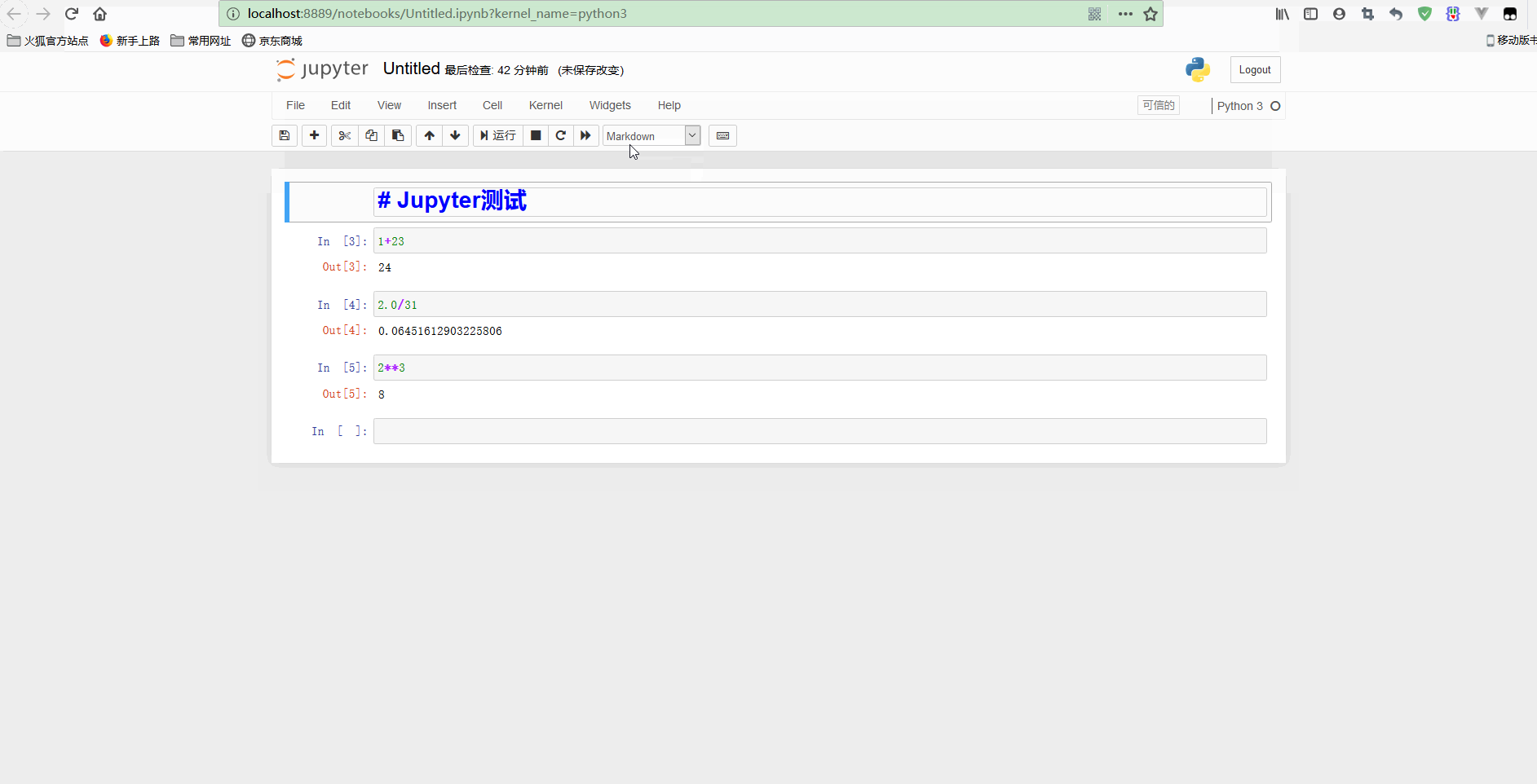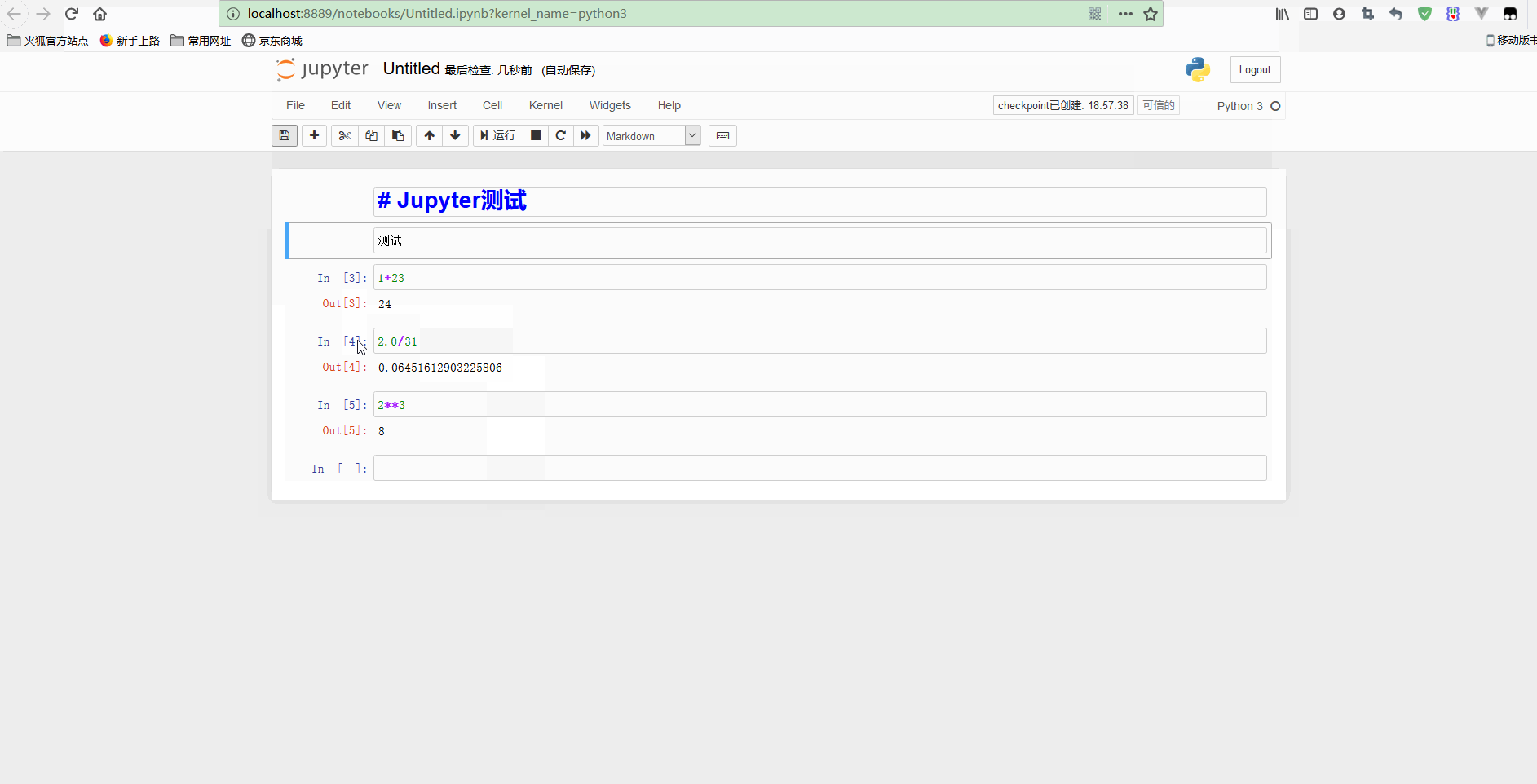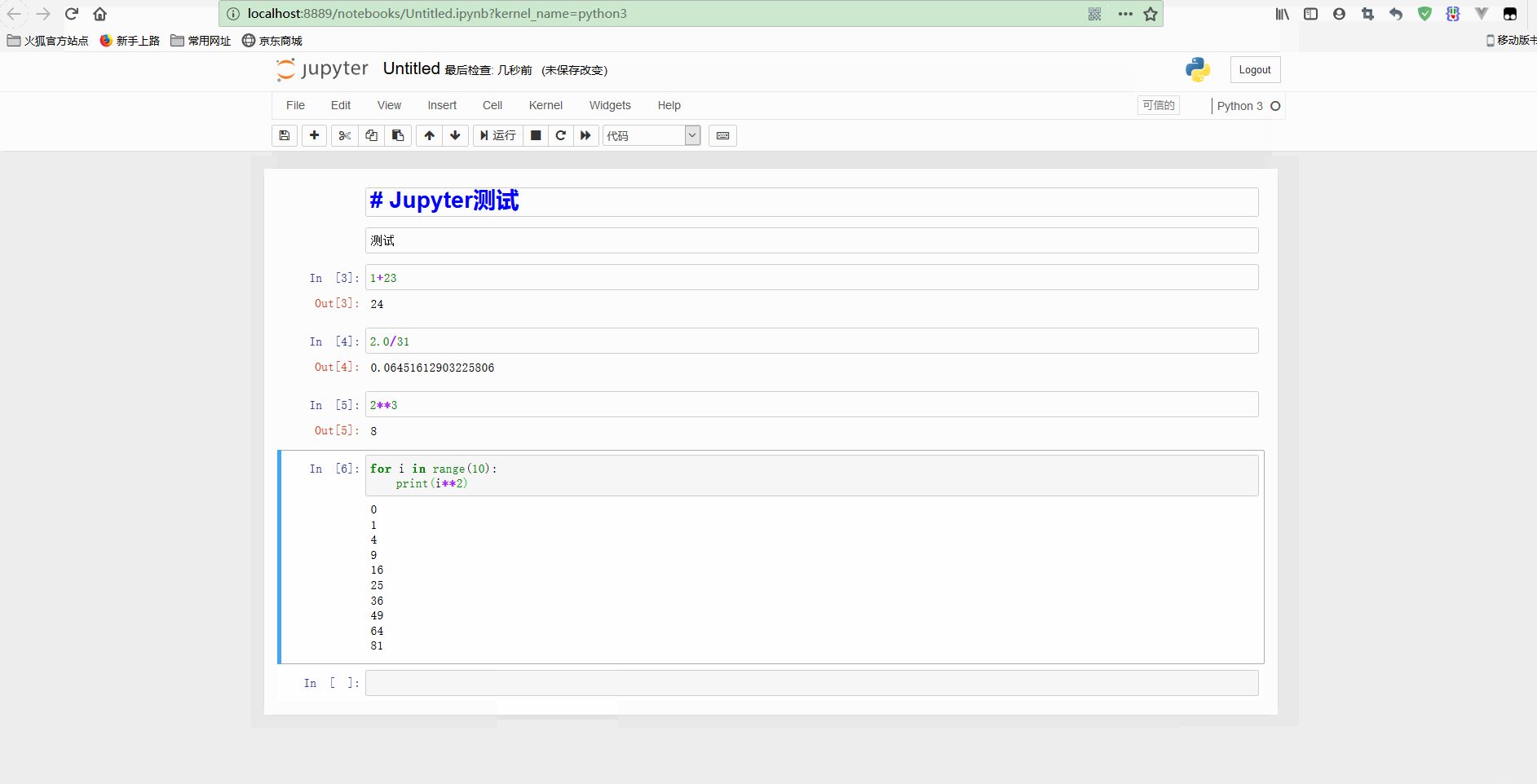
可以看到,在顶部添加了一个notebook的标题,还可以执行for循环等语句。
3.Jupyter中使用Python
Jupyter测试Python变量和数据类型如下:
测试Python函数如下:
测试Python模块如下:
可以看到,在执行出错时,也会抛出异常。
测试数据读写如下:
数据读写很重要,因为进行数据分析时必须先读取数据,进行数据处理后也要进行保存。
4.数据交互案例
加载csv数据,处理数据,保存到MongoDB数据库
有csv文件Présentation pratique de lanalyse des données Python Analyse des données.csv和Présentation pratique de lanalyse des données Python Analyse des données.csv,分别是商品数据和用户评分数据,如下:
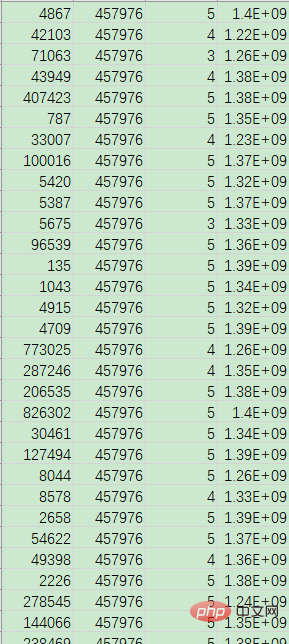
如需获取数据、代码等相关文件进行测试学习,可以直接点击加QQ群
现在需要通过Python将其读取出来,并将指定的字段保存到MongoDB中,需要在Anaconda中执行命令conda install pymongo安装pymongo。
Python代码如下:
import pymongoclass Product:
def __init__(self,productId:int ,name, imageUrl, categories, tags):
self.productId = productId
self.name = name
self.imageUrl = imageUrl
self.categories = categories
self.tags = tags def __str__(self) -> str:
return self.productId +'^' + self.name +'^' + self.imageUrl +'^' + self.categories +'^' + self.tagsclass Rating:
def __init__(self, userId:int, productId:int, score:float, timestamp:int):
self.userId = userId
self.productId = productId
self.score = score
self.timestamp = timestamp def __str__(self) -> str:
return self.userId +'^' + self.productId +'^' + self.score +'^' + self.timestampif __name__ == '__main__':
myclient = pymongo.MongoClient("mongodb://127.0.0.1:27017/")
mydb = myclient["goods-users"]
# val attr = item.split("\\^")
# // 转换成Product
# Product(attr(0).toInt, attr(1).trim, attr(4).trim, attr(5).trim, attr(6).trim)
Présentation pratique de lanalyse des données Python Analyse des données = mydb['Présentation pratique de lanalyse des données Python Analyse des données']
with open('Présentation pratique de lanalyse des données Python Analyse des données.csv', 'r',encoding='UTF-8') as f:
item = f.readline()
while item:
attr = item.split('^')
product = Product(int(attr[0]), attr[1].strip(), attr[4].strip(), attr[5].strip(), attr[6].strip())
Présentation pratique de lanalyse des données Python Analyse des données.insert_one(product.__dict__)
# print(product)
# print(json.dumps(obj=product.__dict__,ensure_ascii=False))
item = f.readline()
# val attr = item.split(",")
# Rating(attr(0).toInt, attr(1).toInt, attr(2).toDouble, attr(3).toInt)
Présentation pratique de lanalyse des données Python Analyse des données = mydb['Présentation pratique de lanalyse des données Python Analyse des données']
with open('Présentation pratique de lanalyse des données Python Analyse des données.csv', 'r',encoding='UTF-8') as f:
item = f.readline()
while item:
attr = item.split(',')
rating = Rating(int(attr[0]), int(attr[1].strip()), float(attr[2].strip()), int(attr[3].strip()))
Présentation pratique de lanalyse des données Python Analyse des données.insert_one(rating.__dict__)
# print(rating)
item = f.readline()在启动MongoDB服务后,运行Python代码,运行完成后,再通过Robo 3T查看数据库如下: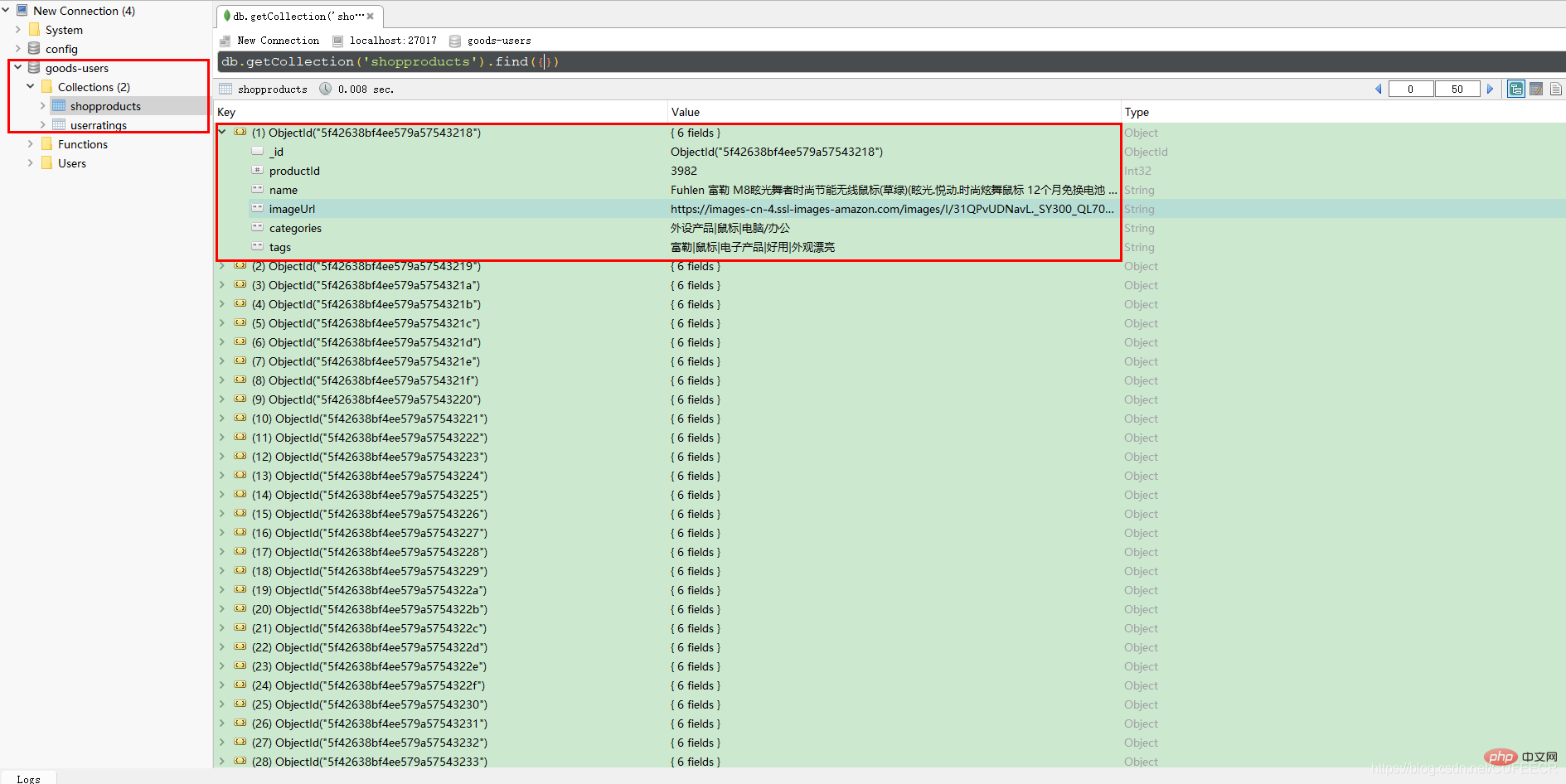
显然,保存数据成功。
使用Jupyter处理商铺数据
待处理的数据是商铺数据,如下: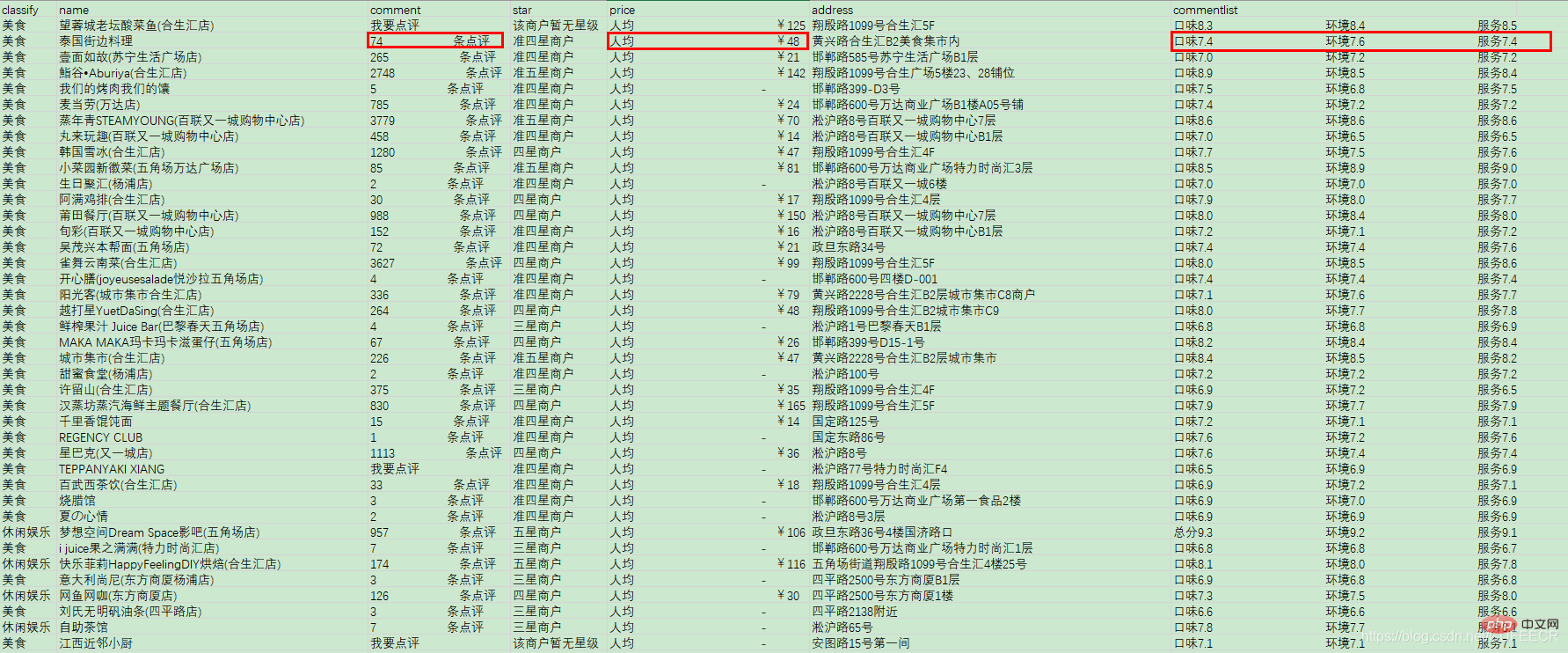
包括名称、评论数、价格、地址、评分列表等,其中评论数、价格和评分均不规则、需要进行数据清洗。
如需获取数据、代码等相关文件进行测试学习,可以直接点击加QQ群
Jupyter中处理如下: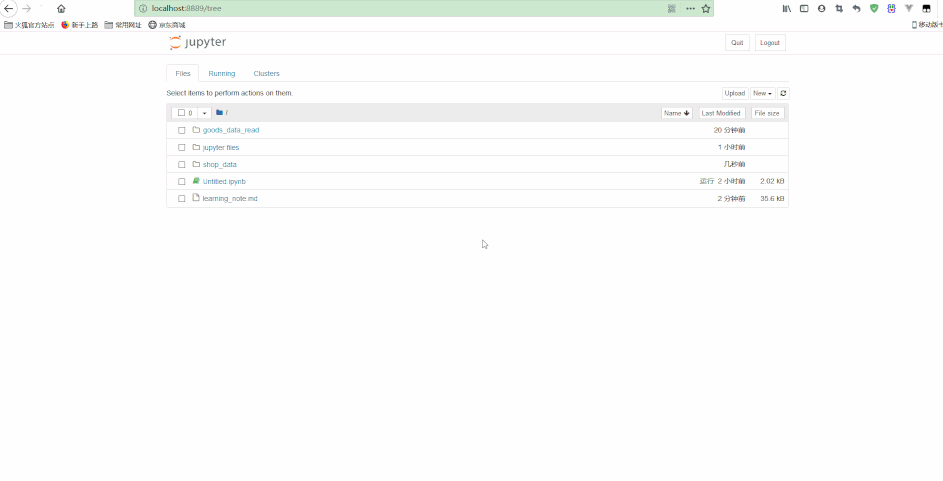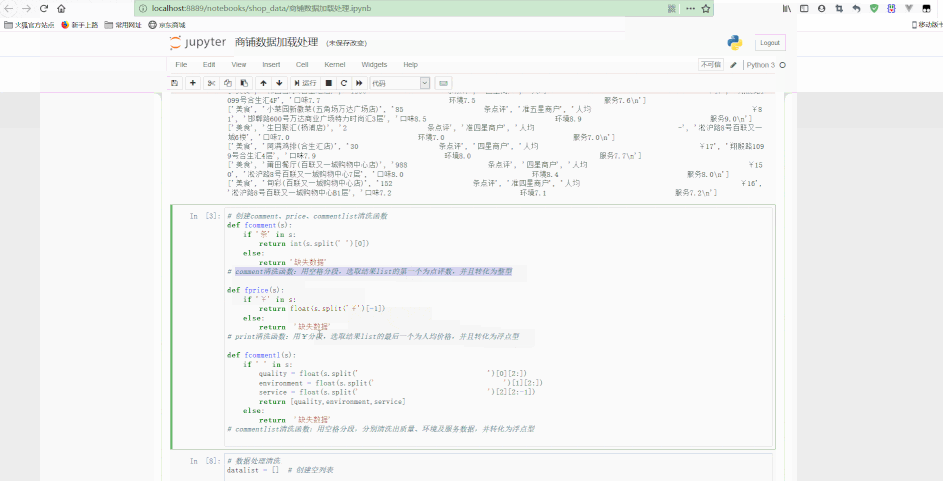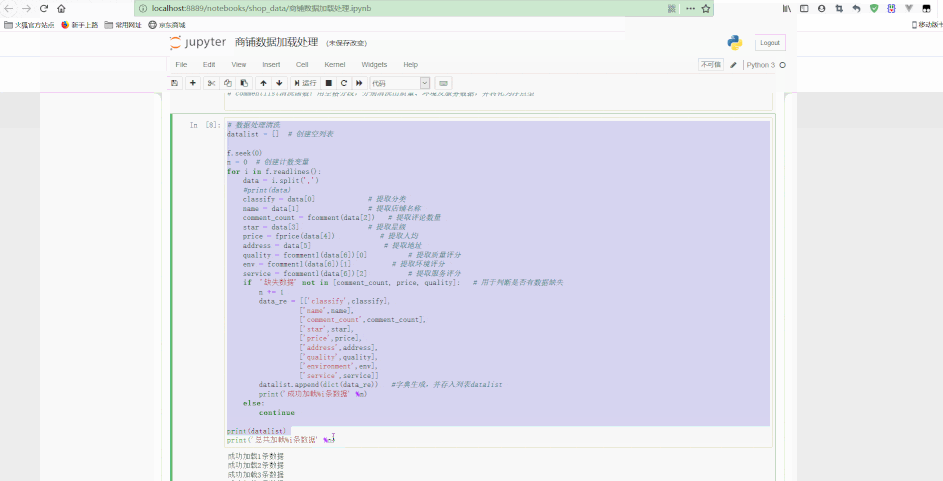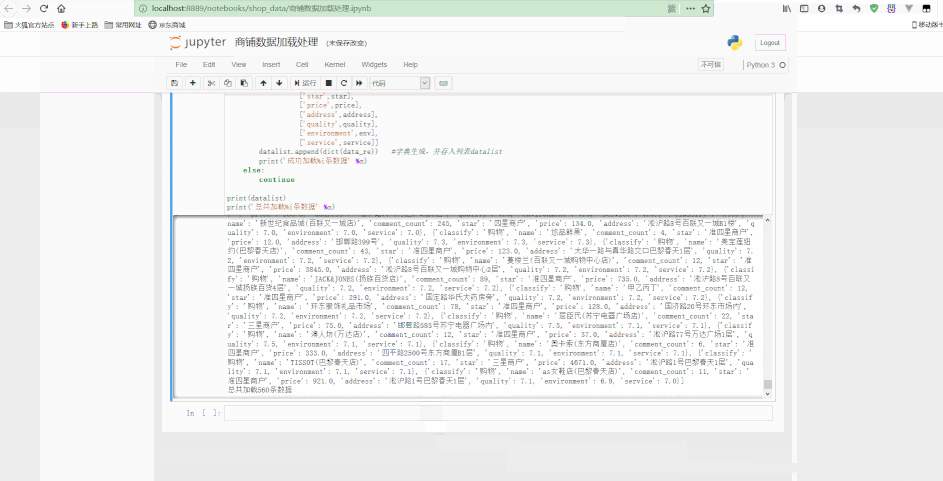
可以看到,最后得到了经过清洗后的规则数据。
完整Python代码如下:
# 数据读取f = open('商铺数据.csv', 'r', encoding='utf8')for i in f.readlines()[1:15]:
print(i.split(','))# 创建comment、price、commentlist清洗函数def fcomment(s):
'''comment清洗函数:用空格分段,选取结果list的第一个为点评数,并且转化为整型'''
if '条' in s:
return int(s.split(' ')[0])
else:
return '缺失数据'def fprice(s):
'''price清洗函数:用¥分段,选取结果list的最后一个为人均价格,并且转化为浮点型'''
if '¥' in s:
return float(s.split('¥')[-1])
else:
return '缺失数据'def fcommentl(s):
'''commentlist清洗函数:用空格分段,分别清洗出质量、环境及服务数据,并转化为浮点型'''
if ' ' in s:
quality = float(s.split(' ')[0][2:])
environment = float(s.split(' ')[1][2:])
service = float(s.split(' ')[2][2:-1])
return [quality, environment, service]
else:
return '缺失数据'# 数据处理清洗datalist = [] # 创建空列表f.seek(0)n = 0 # 创建计数变量for i in f.readlines():
data = i.split(',')
# print(data)
classify = data[0] # 提取分类
name = data[1] # 提取店铺名称
comment_count = fcomment(data[2]) # 提取评论数量
star = data[3] # 提取星级
price = fprice(data[4]) # 提取人均
address = data[5] # 提取地址
quality = fcommentl(data[6])[0] # 提取质量评分
env = fcommentl(data[6])[1] # 提取环境评分
service = fcommentl(data[6])[2] # 提取服务评分
if '缺失数据' not in [comment_count, price, quality]: # 用于判断是否有数据缺失
n += 1
data_re = [['classify', classify],
['name', name],
['comment_count', comment_count],
['star', star],
['price', price],
['address', address],
['quality', quality],
['environment', env],
['service', service]]
datalist.append(dict(data_re)) # 字典生成,并存入列表datalist
print('成功加载%i条数据' % n)
else:
continueprint(datalist)print('总共加载%i条数据' % n)f.close()更多编程相关知识,请访问:编程教学!!
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1369
1369
 52
52

 Quelle est la fonction de la somme du langage C?
Apr 03, 2025 pm 02:21 PM
Quelle est la fonction de la somme du langage C?
Apr 03, 2025 pm 02:21 PM
Il n'y a pas de fonction de somme intégrée dans le langage C, il doit donc être écrit par vous-même. La somme peut être obtenue en traversant le tableau et en accumulant des éléments: Version de boucle: la somme est calculée à l'aide de la longueur de boucle et du tableau. Version du pointeur: Utilisez des pointeurs pour pointer des éléments de tableau, et un résumé efficace est réalisé grâce à des pointeurs d'auto-incitation. Allouer dynamiquement la version du tableau: allouer dynamiquement les tableaux et gérer la mémoire vous-même, en veillant à ce que la mémoire allouée soit libérée pour empêcher les fuites de mémoire.
 Est-ce que distincte est lié?
Apr 03, 2025 pm 10:30 PM
Est-ce que distincte est lié?
Apr 03, 2025 pm 10:30 PM
Bien que distincts et distincts soient liés à la distinction, ils sont utilisés différemment: distinct (adjectif) décrit le caractère unique des choses elles-mêmes et est utilisée pour souligner les différences entre les choses; Distinct (verbe) représente le comportement ou la capacité de distinction, et est utilisé pour décrire le processus de discrimination. En programmation, distinct est souvent utilisé pour représenter l'unicité des éléments d'une collection, tels que les opérations de déduplication; Distinct se reflète dans la conception d'algorithmes ou de fonctions, tels que la distinction étrange et uniforme des nombres. Lors de l'optimisation, l'opération distincte doit sélectionner l'algorithme et la structure de données appropriés, tandis que l'opération distincte doit optimiser la distinction entre l'efficacité logique et faire attention à l'écriture de code clair et lisible.
 Qui est payé plus de python ou de javascript?
Apr 04, 2025 am 12:09 AM
Qui est payé plus de python ou de javascript?
Apr 04, 2025 am 12:09 AM
Il n'y a pas de salaire absolu pour les développeurs Python et JavaScript, selon les compétences et les besoins de l'industrie. 1. Python peut être davantage payé en science des données et en apprentissage automatique. 2. JavaScript a une grande demande dans le développement frontal et complet, et son salaire est également considérable. 3. Les facteurs d'influence comprennent l'expérience, la localisation géographique, la taille de l'entreprise et les compétences spécifiques.
 Comment comprendre! X en C?
Apr 03, 2025 pm 02:33 PM
Comment comprendre! X en C?
Apr 03, 2025 pm 02:33 PM
! x Compréhension! X est un non-opérateur logique dans le langage C. Il booléen la valeur de x, c'est-à-dire que les véritables modifications sont fausses et fausses modifient true. Mais sachez que la vérité et le mensonge en C sont représentés par des valeurs numériques plutôt que par les types booléens, le non-zéro est considéré comme vrai, et seul 0 est considéré comme faux. Par conséquent,! X traite des nombres négatifs de la même manière que des nombres positifs et est considéré comme vrai.
 Que signifie la somme dans la langue C?
Apr 03, 2025 pm 02:36 PM
Que signifie la somme dans la langue C?
Apr 03, 2025 pm 02:36 PM
Il n'y a pas de fonction de somme intégrée en C pour la somme, mais il peut être implémenté par: en utilisant une boucle pour accumuler des éléments un par un; Utilisation d'un pointeur pour accéder et accumuler des éléments un par un; Pour les volumes de données importants, envisagez des calculs parallèles.
 La production de pages H5 nécessite-t-elle une maintenance continue?
Apr 05, 2025 pm 11:27 PM
La production de pages H5 nécessite-t-elle une maintenance continue?
Apr 05, 2025 pm 11:27 PM
La page H5 doit être maintenue en continu, en raison de facteurs tels que les vulnérabilités du code, la compatibilité des navigateurs, l'optimisation des performances, les mises à jour de sécurité et les améliorations de l'expérience utilisateur. Des méthodes de maintenance efficaces comprennent l'établissement d'un système de test complet, à l'aide d'outils de contrôle de version, de surveiller régulièrement les performances de la page, de collecter les commentaires des utilisateurs et de formuler des plans de maintenance.
 Copier et coller le code d'amour Copier et coller le code d'amour gratuitement
Apr 04, 2025 am 06:48 AM
Copier et coller le code d'amour Copier et coller le code d'amour gratuitement
Apr 04, 2025 am 06:48 AM
Copier et coller le code n'est pas impossible, mais il doit être traité avec prudence. Des dépendances telles que l'environnement, les bibliothèques, les versions, etc. dans le code peuvent ne pas correspondre au projet actuel, entraînant des erreurs ou des résultats imprévisibles. Assurez-vous de vous assurer que le contexte est cohérent, y compris les chemins de fichier, les bibliothèques dépendantes et les versions Python. De plus, lors de la copie et de la collation du code pour une bibliothèque spécifique, vous devrez peut-être installer la bibliothèque et ses dépendances. Les erreurs courantes incluent les erreurs de chemin, les conflits de version et les styles de code incohérents. L'optimisation des performances doit être redessinée ou refactorisée en fonction de l'objectif d'origine et des contraintes du code. Il est crucial de comprendre et de déboguer le code copié, et de ne pas copier et coller aveuglément.
 Comment obtenir des données d'application et de visionneuse en temps réel sur la page de travail 58.com?
Apr 05, 2025 am 08:06 AM
Comment obtenir des données d'application et de visionneuse en temps réel sur la page de travail 58.com?
Apr 05, 2025 am 08:06 AM
Comment obtenir des données dynamiques de la page de travail 58.com tout en rampant? Lorsque vous rampez une page de travail de 58.com en utilisant des outils de chenilles, vous pouvez rencontrer cela ...
