
 développement back-end
Tutoriel Python
Présentation de 60 lignes de code python pour écrire un simple robot d'exploration Biquge
développement back-end
Tutoriel Python
Présentation de 60 lignes de code python pour écrire un simple robot d'exploration Biquge
Présentation de 60 lignes de code python pour écrire un simple robot d'exploration Biquge


推荐(免费):Python视频教程
文章目录
- 系列文章目录
- 前言
- 一、网页解析
- 二、代码填写
- 1.获取Html及写入方法
- 2.其余代码
- 总结
前言
利用python写一个简单的笔趣阁爬虫,根据输入的小说网址爬取整个小说并保存到txt文件。爬虫用到了BeautifulSoup库的select方法
结果如图所示: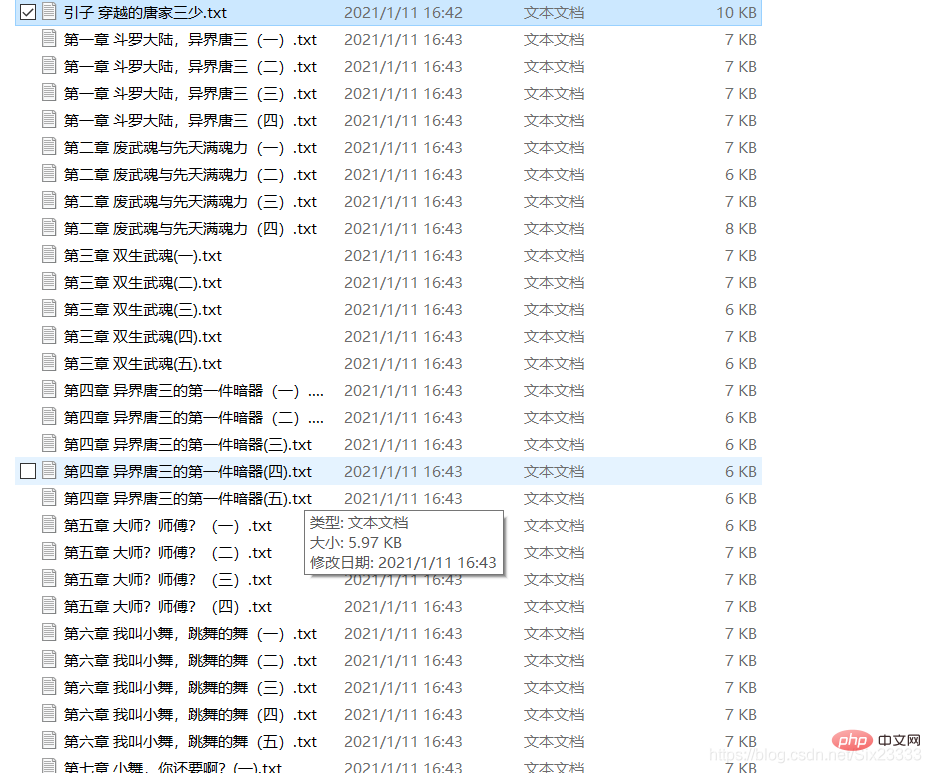
本文只用于学习爬虫
一、网页解析
这里以斗罗大陆小说为例 网址:
http://www.biquge001.com/Book/2/2486/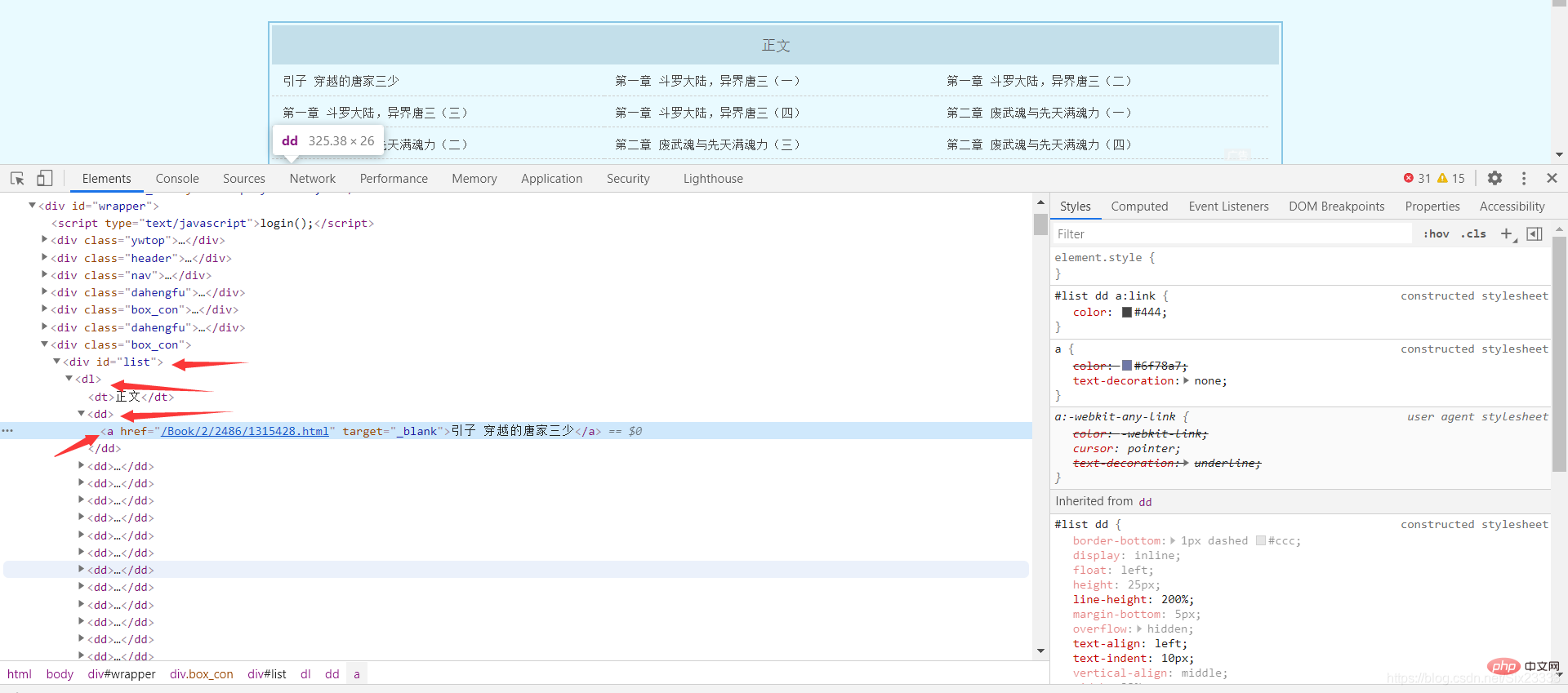
可以发现每章的网页地址和章节名都放在了 中的a标签中,所以利用BeautfulSoup中的select方法可以得到网址和章节名
Tag = BeautifulSoup(getHtmlText(url), "html.parser") #这里的getHtmlText是自己写的获取html的方法urls = Tag.select("p #list dl dd a")然后遍历列表
for url in urls: href = "http://www.biquge001.com/" + url['href'] # 字符串的拼接 拼接成正确的网址 pageName = url.text # 每章的章名
然后每章小说的内容都存放在
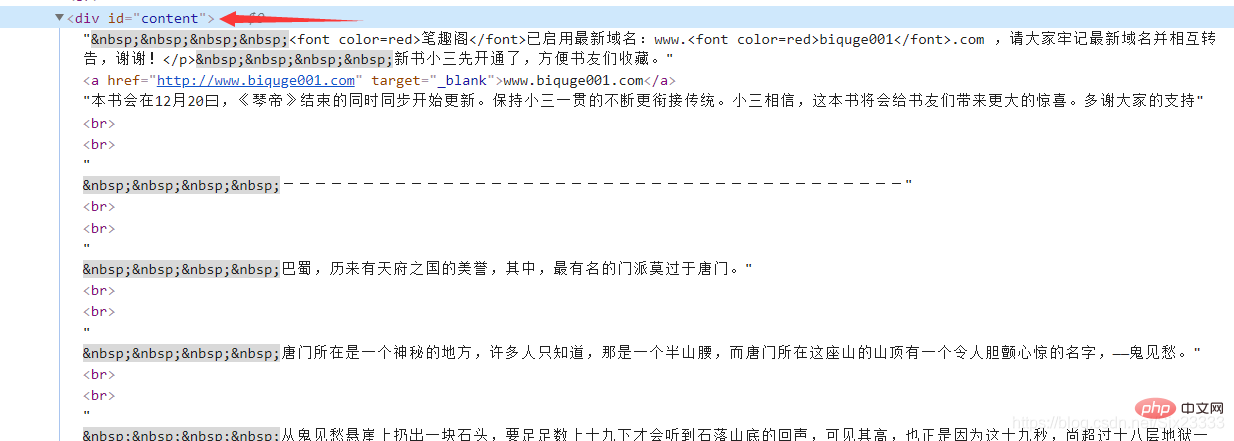
substance = Tag.select("p #content") # 文章的内容最后同理在首页获取小说的名称
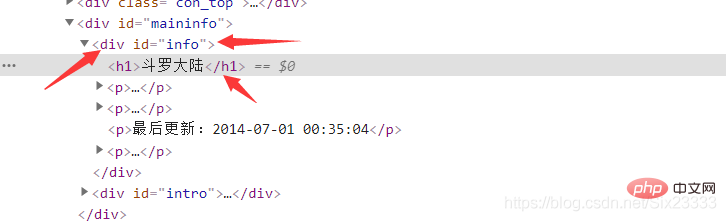
bookName = Tag.select("p #info h1")
二、代码填写
1.获取Html及写入方法
def getHtmlText(url): r = requests.get(url, headers=headers) r.encoding = r.apparent_encoding # 编码转换 r.raise_for_status() return r.textdef writeIntoTxt(filename, content): with open(filename, "w", encoding="utf-8") as f: f.write(content) f.close() print(filename + "已完成")
2.其余代码
代码如下(示例):
url = "http://www.biquge001.com/Book/2/2486/"substanceStr = ""bookName1 = ""html = getHtmlText(url)# 判断是否存在这个文件Tag = BeautifulSoup(getHtmlText(url), "html.parser")urls = Tag.select("p #list dl dd a")bookName = Tag.select("p #info h1")for i in bookName:
bookName1 = i.textif not os.path.exists(bookName1):
os.mkdir(bookName1)
print(bookName1 + "创建完成")else:
print("文件已创建")for url in urls:
href = "http://www.biquge001.com/" + url['href'] # 字符串的拼接 拼接成正确的网址
pageName = url.text # 每章的章名
path = bookName1 + "\\" # 路径
fileName = path + url.text + ".txt" # 文件名 = 路径 + 章节名 + ".txt"
Tag = BeautifulSoup(getHtmlText(href), "html.parser") # 解析每张的网页
substance = Tag.select("p #content") # 文章的内容
for i in substance:
substanceStr = i.text
writeIntoTxt(fileName, substanceStr)
time.sleep(1)
总结
简单利用了BeautfulSoup的select方法对笔趣阁的网页进行了爬取
更多相关学习敬请关注Python教程栏目!
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment résoudre le problème des autorisations rencontré lors de la visualisation de la version Python dans le terminal Linux?
Apr 01, 2025 pm 05:09 PM
Comment résoudre le problème des autorisations rencontré lors de la visualisation de la version Python dans le terminal Linux?
Apr 01, 2025 pm 05:09 PM
Solution aux problèmes d'autorisation Lors de la visualisation de la version Python dans Linux Terminal Lorsque vous essayez d'afficher la version Python dans Linux Terminal, entrez Python ...
 Comment copier efficacement la colonne entière d'une dataframe dans une autre dataframe avec différentes structures dans Python?
Apr 01, 2025 pm 11:15 PM
Comment copier efficacement la colonne entière d'une dataframe dans une autre dataframe avec différentes structures dans Python?
Apr 01, 2025 pm 11:15 PM
Lorsque vous utilisez la bibliothèque Pandas de Python, comment copier des colonnes entières entre deux frames de données avec différentes structures est un problème courant. Supposons que nous ayons deux dats ...
 Comment enseigner les bases de la programmation novice en informatique dans le projet et les méthodes axées sur les problèmes dans les 10 heures?
Apr 02, 2025 am 07:18 AM
Comment enseigner les bases de la programmation novice en informatique dans le projet et les méthodes axées sur les problèmes dans les 10 heures?
Apr 02, 2025 am 07:18 AM
Comment enseigner les bases de la programmation novice en informatique dans les 10 heures? Si vous n'avez que 10 heures pour enseigner à l'informatique novice des connaissances en programmation, que choisissez-vous d'enseigner ...
 Comment Uvicorn écoute-t-il en permanence les demandes HTTP sans servir_forever ()?
Apr 01, 2025 pm 10:51 PM
Comment Uvicorn écoute-t-il en permanence les demandes HTTP sans servir_forever ()?
Apr 01, 2025 pm 10:51 PM
Comment Uvicorn écoute-t-il en permanence les demandes HTTP? Uvicorn est un serveur Web léger basé sur ASGI. L'une de ses fonctions principales est d'écouter les demandes HTTP et de procéder ...
 Comment créer dynamiquement un objet via une chaîne et appeler ses méthodes dans Python?
Apr 01, 2025 pm 11:18 PM
Comment créer dynamiquement un objet via une chaîne et appeler ses méthodes dans Python?
Apr 01, 2025 pm 11:18 PM
Dans Python, comment créer dynamiquement un objet via une chaîne et appeler ses méthodes? Il s'agit d'une exigence de programmation courante, surtout si elle doit être configurée ou exécutée ...
 Comment éviter d'être détecté par le navigateur lors de l'utilisation de Fiddler partout pour la lecture de l'homme au milieu?
Apr 02, 2025 am 07:15 AM
Comment éviter d'être détecté par le navigateur lors de l'utilisation de Fiddler partout pour la lecture de l'homme au milieu?
Apr 02, 2025 am 07:15 AM
Comment éviter d'être détecté lors de l'utilisation de FiddlereVerywhere pour les lectures d'homme dans le milieu lorsque vous utilisez FiddlereVerywhere ...
 Quelles sont les bibliothèques Python populaires et leurs utilisations?
Mar 21, 2025 pm 06:46 PM
Quelles sont les bibliothèques Python populaires et leurs utilisations?
Mar 21, 2025 pm 06:46 PM
L'article traite des bibliothèques Python populaires comme Numpy, Pandas, Matplotlib, Scikit-Learn, Tensorflow, Django, Flask et Demandes, détaillant leurs utilisations dans le calcul scientifique, l'analyse des données, la visualisation, l'apprentissage automatique, le développement Web et H et H
 Que sont les expressions régulières?
Mar 20, 2025 pm 06:25 PM
Que sont les expressions régulières?
Mar 20, 2025 pm 06:25 PM
Les expressions régulières sont des outils puissants pour la correspondance des motifs et la manipulation du texte dans la programmation, améliorant l'efficacité du traitement de texte sur diverses applications.
