

Limiter l'optimisation dans MySQL

«Enfin, je vais commencer à optimiser MySQL. Cet article vous expliquera l'optimisation de la pagination. J'espère pouvoir trouver une solution qui vous convient
<.>”
Avant-propos
La pagination est un sujet courant, mais combien d'amis veulent l'optimiser D'un autre côté, je conserve toujours ma propre personnalité unique en termes de mon propre système. L'optimisation de cette affaire nécessite que vous preniez l'initiative par vous-même. Obtenez vos propres données de test Ce n'est que sur le chemin des tests que vous le découvrirez. plus. Des choses que vous ne savez pas. Cet article Kaka expliquera également le sujet de l'optimisation de la pagination. Ayez de la personnalité
Ayez de la personnalité1. Structure du tableau
Cette structure de base de données est le tableau des projets en ligne actuels de Kaka, mais Kaka vient de changer. le nom du champ et annulé le champ horaire. La structure de la base de données est la suivante<span style="display: block; background: url(https://files.mdnice.com/point.png); height: 30px; width: 100%; background-size: 40px; background-repeat: no-repeat; background-color: #282c34; margin-bottom: -7px; border-radius: 5px; background-position: 10px 10px;"></span><code class="hljs" style="overflow-x: auto; padding: 16px; color: #abb2bf; display: -webkit-box; font-family: Operator Mono, Consolas, Monaco, Menlo, monospace; font-size: 12px; -webkit-overflow-scrolling: touch; padding-top: 15px; background: #282c34; border-radius: 5px;"><span class="hljs-keyword" style="color: #c678dd; line-height: 26px;">CREATE</span> <span class="hljs-keyword" style="color: #c678dd; line-height: 26px;">TABLE</span> <span class="hljs-string" style="color: #98c379; line-height: 26px;">`tp_statistics`</span> (<br/> <span class="hljs-string" style="color: #98c379; line-height: 26px;">`ss_id`</span> <span class="hljs-built_in" style="color: #e6c07b; line-height: 26px;">int</span>(<span class="hljs-number" style="color: #d19a66; line-height: 26px;">11</span>) <span class="hljs-keyword" style="color: #c678dd; line-height: 26px;">NOT</span> <span class="hljs-literal" style="color: #56b6c2; line-height: 26px;">NULL</span> AUTO_INCREMENT,<br/> <span class="hljs-string" style="color: #98c379; line-height: 26px;">`ss_field1`</span> <span class="hljs-built_in" style="color: #e6c07b; line-height: 26px;">decimal</span>(<span class="hljs-number" style="color: #d19a66; line-height: 26px;">11</span>,<span class="hljs-number" style="color: #d19a66; line-height: 26px;">2</span>) <span class="hljs-keyword" style="color: #c678dd; line-height: 26px;">NOT</span> <span class="hljs-literal" style="color: #56b6c2; line-height: 26px;">NULL</span> <span class="hljs-keyword" style="color: #c678dd; line-height: 26px;">DEFAULT</span> <span class="hljs-string" style="color: #98c379; line-height: 26px;">'0.00'</span>,<br/> <span class="hljs-string" style="color: #98c379; line-height: 26px;">`ss_field2`</span> <span class="hljs-built_in" style="color: #e6c07b; line-height: 26px;">decimal</span>(<span class="hljs-number" style="color: #d19a66; line-height: 26px;">11</span>,<span class="hljs-number" style="color: #d19a66; line-height: 26px;">2</span>) <span class="hljs-keyword" style="color: #c678dd; line-height: 26px;">NOT</span> <span class="hljs-literal" style="color: #56b6c2; line-height: 26px;">NULL</span> <span class="hljs-keyword" style="color: #c678dd; line-height: 26px;">DEFAULT</span> <span class="hljs-string" style="color: #98c379; line-height: 26px;">'0.00'</span>,<br/> <span class="hljs-string" style="color: #98c379; line-height: 26px;">`ss_field3`</span> <span class="hljs-built_in" style="color: #e6c07b; line-height: 26px;">decimal</span>(<span class="hljs-number" style="color: #d19a66; line-height: 26px;">11</span>,<span class="hljs-number" style="color: #d19a66; line-height: 26px;">2</span>) <span class="hljs-keyword" style="color: #c678dd; line-height: 26px;">NOT</span> <span class="hljs-literal" style="color: #56b6c2; line-height: 26px;">NULL</span> <span class="hljs-keyword" style="color: #c678dd; line-height: 26px;">DEFAULT</span> <span class="hljs-string" style="color: #98c379; line-height: 26px;">'0.00'</span>,<br/> PRIMARY <span class="hljs-keyword" style="color: #c678dd; line-height: 26px;">KEY</span> (<span class="hljs-string" style="color: #98c379; line-height: 26px;">`ss_id`</span>)<br/>) <span class="hljs-keyword" style="color: #c678dd; line-height: 26px;">ENGINE</span>=<span class="hljs-keyword" style="color: #c678dd; line-height: 26px;">InnoDB</span> AUTO_INCREMENT=<span class="hljs-number" style="color: #d19a66; line-height: 26px;">3499994</span> <span class="hljs-keyword" style="color: #c678dd; line-height: 26px;">DEFAULT</span> <span class="hljs-keyword" style="color: #c678dd; line-height: 26px;">CHARSET</span>=utf8 <span class="hljs-keyword" style="color: #c678dd; line-height: 26px;">COLLATE</span>=utf8mb4_general_ci ROW_FORMAT=<span class="hljs-keyword" style="color: #c678dd; line-height: 26px;">COMPACT</span>;<br/><br/></code>
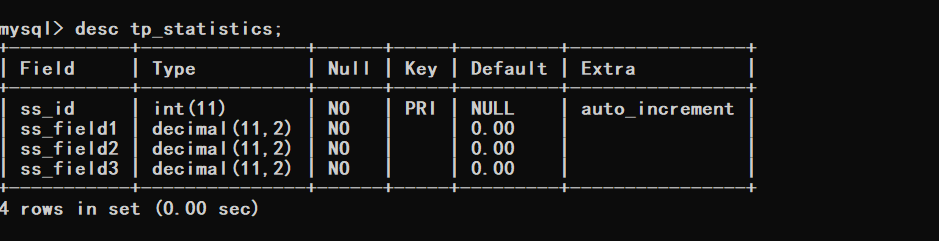 Structure des tables
Structure des tables2. Exploration préliminaire de l'efficacité des requêtes
Écrivons d'abord une instruction SQL de requête et examinons le temps consommé par la requête.
D'après la figure ci-dessous, vous pouvez voir que le temps de requête est fondamentalement ignoré, mais ce qu'il convient de noter, c'est la valeur de décalage de la limite.
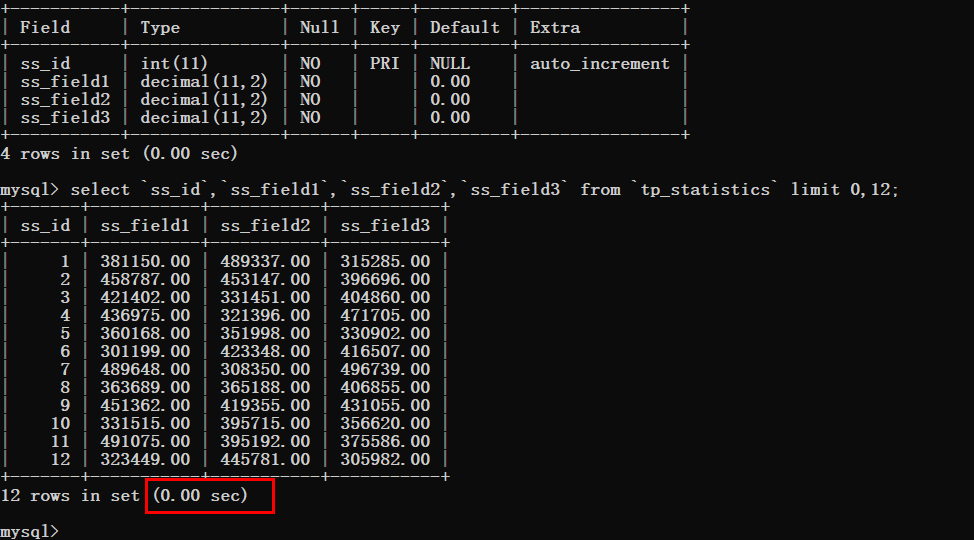
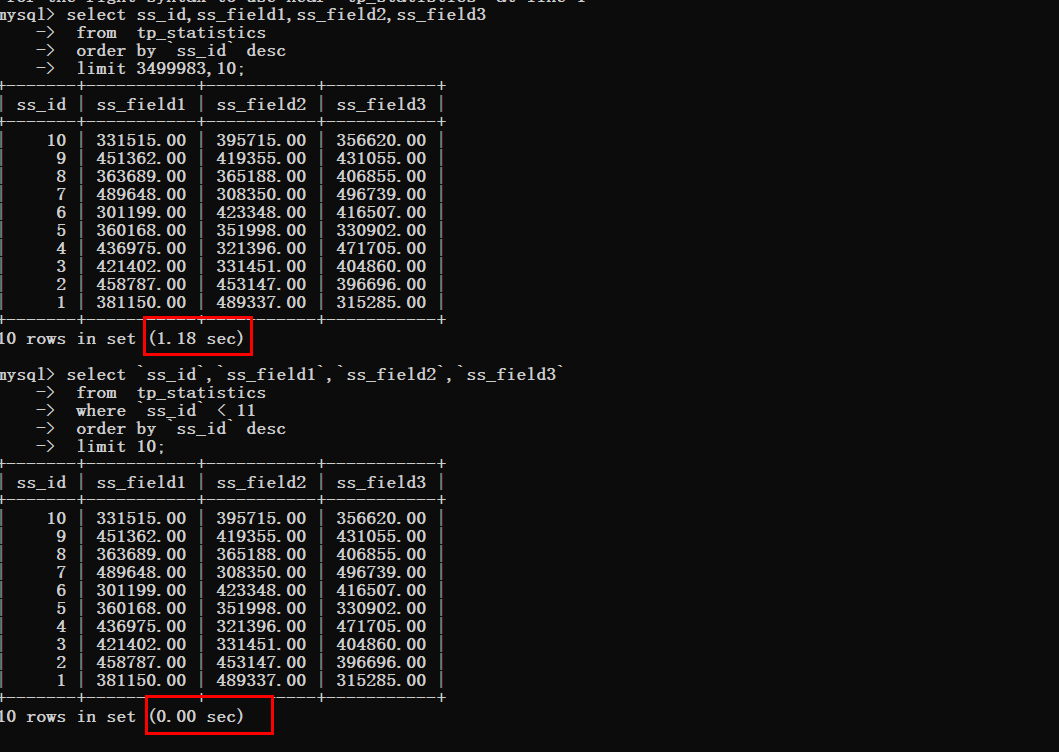
Nous devons donc augmenter le décalage étape par étape, puis le tester d'abord en modifiant le décalage à 10000
<🎜. >Vous pouvez voir que le temps de requête est toujours très idéal. Afin de gagner du temps, ajustez la valeur de décalage directement à 340W. Vous pouvez constater des changements très évidents à ce moment-là, et le temps de requête a grimpé à 0,79 s. Si une telle situation se produit, elle doit absolument être optimisée, il suffit de prendre le clavier et de le faire.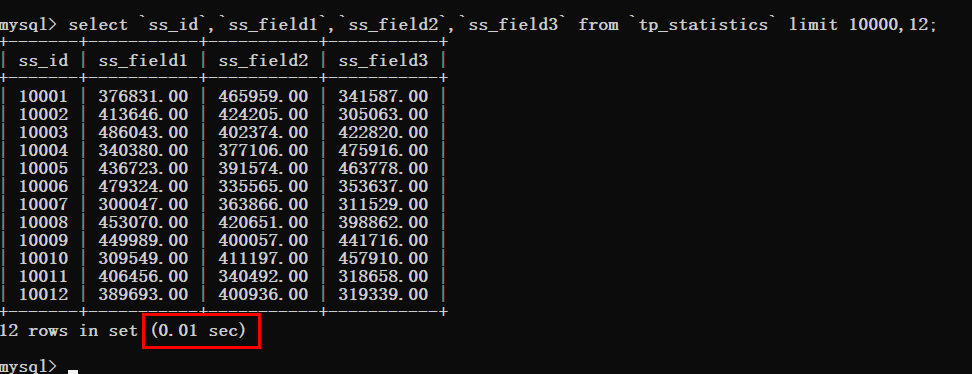 Requête Offset 10000
Requête Offset 10000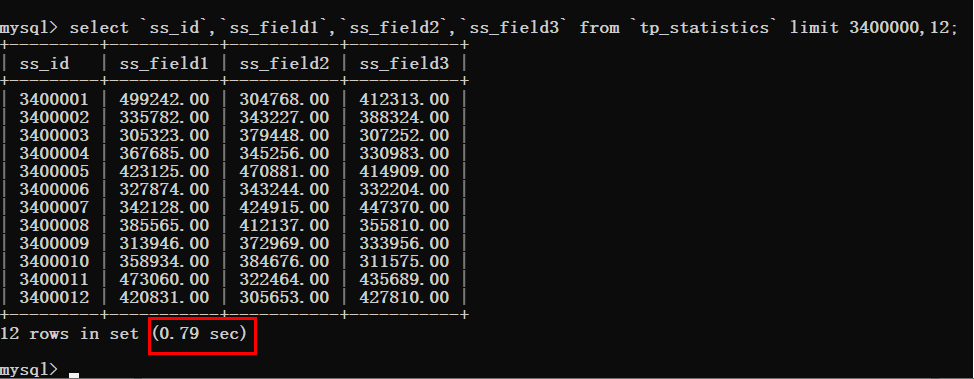 Requête Offset 340w
Requête Offset 340w 3. Raisons pour lesquelles la requête d'analyse prend du temps
Lorsqu'il s'agit d'analyser des instructions SQL, les points de connaissances nécessaires are Explain, si vous ne savez pas comment utiliser cet outil, vous pouvez jeter un œil à la partie de base de MySQL. D'après la figure ci-dessous, vous pouvez voir que les trois instructions de requête ont été analysées en table.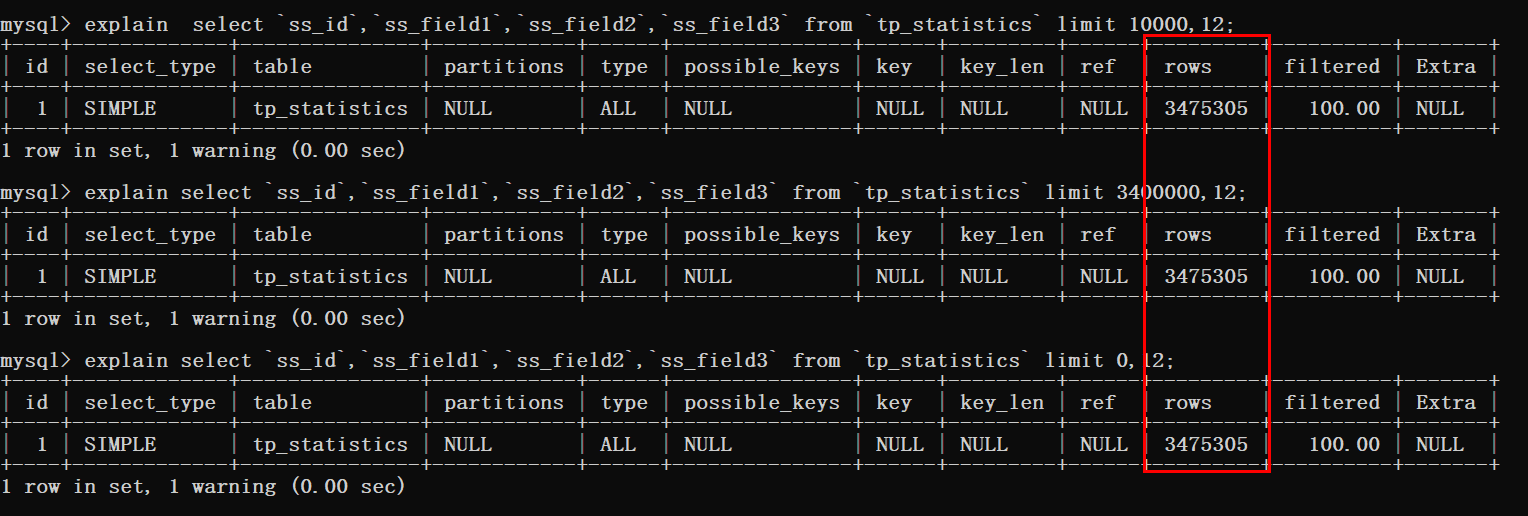
Nous savons tous que tant qu'il y a une pagination, il doit y avoir un tri, alors ajoutez un tri et regardez l'efficacité des requêtes.
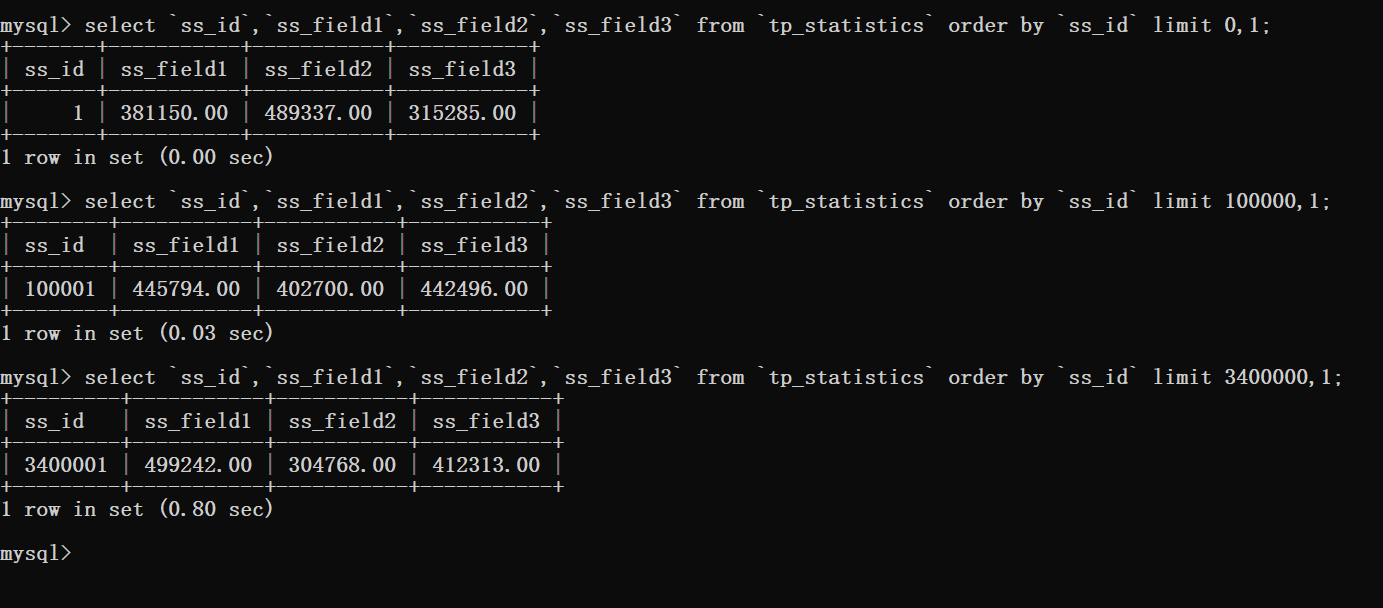
Ensuite, analysez et visualisez les déclarations triées.
Vous pouvez voir ici que lorsque le tri est utilisé, le nombre de lignes analysées par la base de données correspond au décalage plus le nombre de requêtes requises.
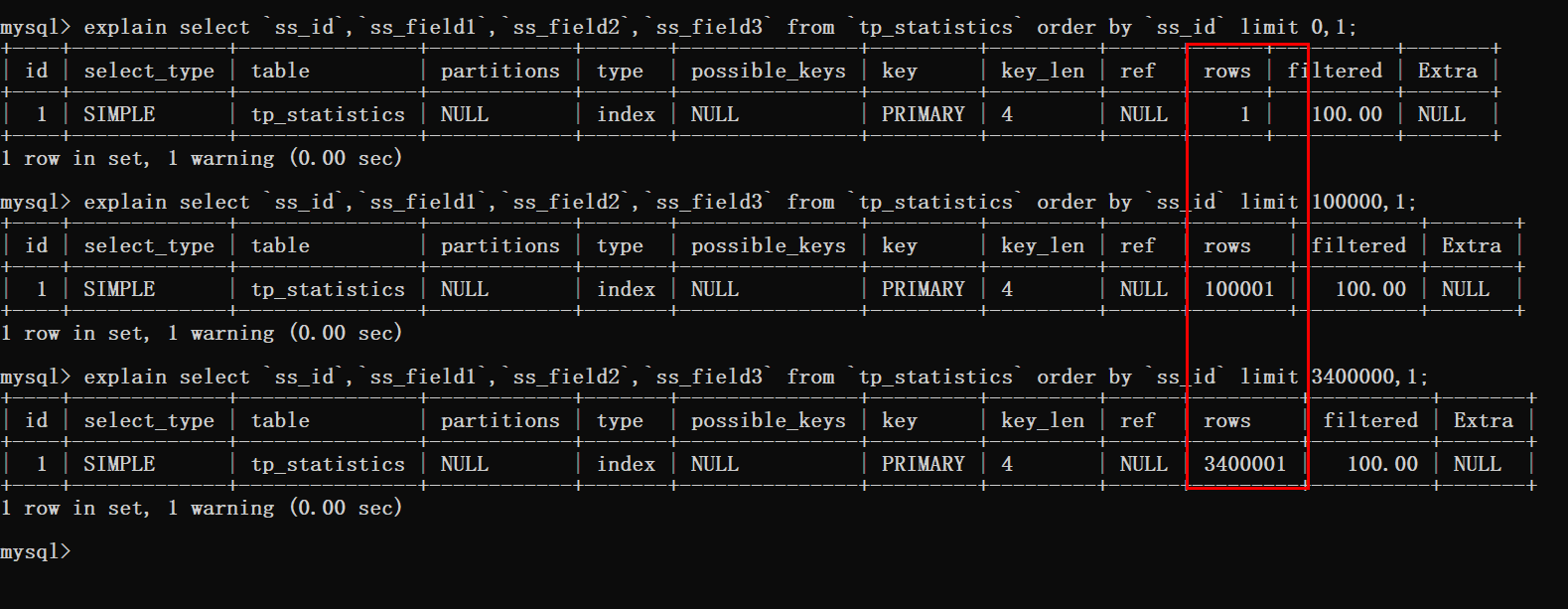
Ce que vous pouvez savoir à ce stade, c'est que lorsque le décalage est très grand, comme la limite dans le cas supérieur à 3400000,12 telle requête.
À l'heure actuelle, MySQL doit interroger 3 400 012 lignes de données, puis renvoyer les 12 dernières données.
Les données 340W interrogées précédemment seront ignorées. De tels résultats d'exécution ne sont pas ce que nous voulons.
Kaka a vu des articles connexes avant de dire que la solution à ce problème est soit de limiter directement le nombre de pagination, soit d'optimiser les performances lorsque le décalage est très important.
Si vous avez lu cet article jusqu'à présent, en quoi cela pourrait-il vous décevoir ? Il doit s'agir d'un problème de performances d'optimisation des grands offsets.
4. Optimisation
Puisque l'optimisation est mentionnée, il n'y a que deux points, ajouter un index et utiliser un autre programme. pour remplacer ce programme.
Les informations sur la structure du tableau de données fournies par Kaka peuvent être comprises comme l'enregistrement d'emprunt de la bibliothèque, et vous n'avez pas à vous soucier de quoi que ce soit dans les champs.
Pour le tri, dans ce scénario, l'heure ne sera pas triée, mais la clé primaire sera triée et le champ horaire sera annulé en raison de l'ajout de données de test.
接下来使用覆盖索引加inner join的方式来进行优化。
<span style="display: block; background: url(https://files.mdnice.com/point.png); height: 30px; width: 100%; background-size: 40px; background-repeat: no-repeat; background-color: #282c34; margin-bottom: -7px; border-radius: 5px; background-position: 10px 10px;"></span><code class="hljs" style="overflow-x: auto; padding: 16px; color: #abb2bf; display: -webkit-box; font-family: Operator Mono, Consolas, Monaco, Menlo, monospace; font-size: 12px; -webkit-overflow-scrolling: touch; padding-top: 15px; background: #282c34; border-radius: 5px;"><span class="hljs-keyword" style="color: #c678dd; line-height: 26px;">select</span> ss_id,ss_field1,ss_field2,ss_field3 <span class="hljs-keyword" style="color: #c678dd; line-height: 26px;">from</span> tp_statistics <span class="hljs-keyword" style="color: #c678dd; line-height: 26px;">inner</span> <span class="hljs-keyword" style="color: #c678dd; line-height: 26px;">join</span> ( <span class="hljs-keyword" style="color: #c678dd; line-height: 26px;">select</span> ss_id <span class="hljs-keyword" style="color: #c678dd; line-height: 26px;">from</span> tp_statistics <span class="hljs-keyword" style="color: #c678dd; line-height: 26px;">order</span> <span class="hljs-keyword" style="color: #c678dd; line-height: 26px;">by</span> ss_id <span class="hljs-keyword" style="color: #c678dd; line-height: 26px;">limit</span> <span class="hljs-number" style="color: #d19a66; line-height: 26px;">3000000</span>,<span class="hljs-number" style="color: #d19a66; line-height: 26px;">10</span>) b <span class="hljs-keyword" style="color: #c678dd; line-height: 26px;">using</span> (ss_id);<br/></code>
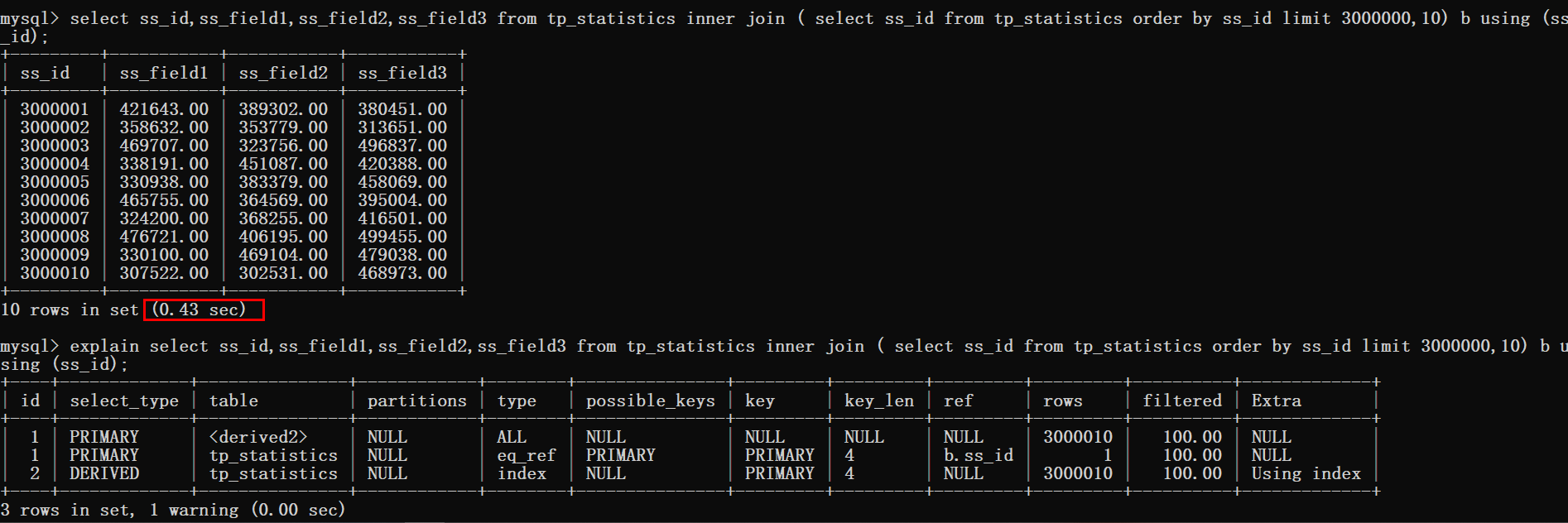
从上图可以看到查询时间从0.8s优化到了0.4s,但是这样的效果还是不尽人意。
于是只能更换一下思路再进行优化。

既然优化最大偏移量这条路有点坎坷,能不能从其它方面进行入手。
估计有很多同学已经知道咔咔将要抛出什么话题了。
没错,就是使用where > id 然后使用limit。
先来测试一波结果,在写具体实现方案。
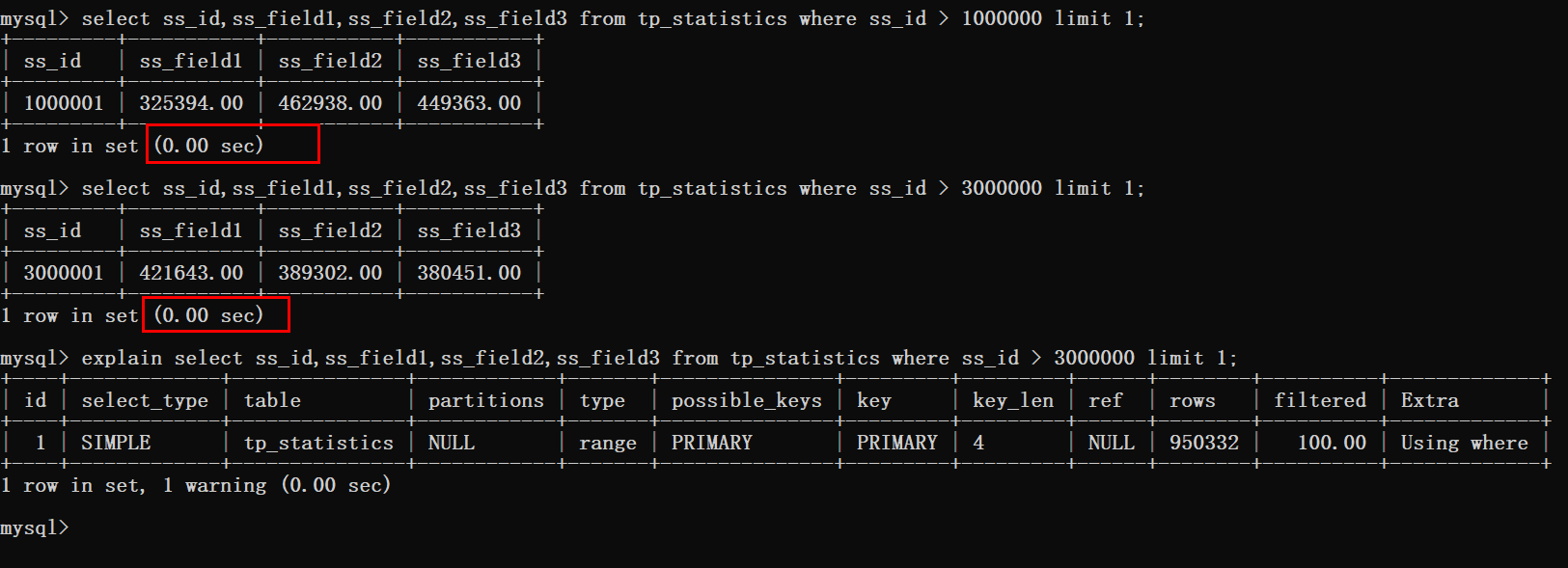
根据上图可以看到这种方式是十分可行的,分页在300W条数据以后的查询时间也基本忽略不计。
那么这种方案要怎么实现呢!
五、方案落地
其实这个方案真的很简单,只需要简单的转换一下思路即可。

Lorsque le client obtient des données pour la première fois, les paramètres de décalage et de limite sont transmis normalement.
Les données renvoyées pour la première fois sont obtenues en utilisant le décalage et la limite transmis par le client.
Lorsque les premières données sont renvoyées avec succès.
Lorsque le client extrait des données pour la deuxième fois, les paramètres ont changé et ils ne peuvent plus être compensés et limités.
Le paramètre qui doit être transmis à ce moment est l'identifiant de la dernière donnée obtenue pour la première fois.
Les paramètres actuels sont last_id et limit.
Après avoir obtenu le last_id en arrière-plan, vous pouvez utiliser la condition Where dans l'instruction SQL
Kaka La situation donnée ici est que lorsque les données sont en flashback, si la séquence positive est supérieur à last_id, c'est-à-dire Can.
Ensuite, Kaka utilisera un cas pour vous donner une explication directe et claire.
Cas pratique
Ce qui suit est un cas qui sera démontré dans la pratique, comme l'utilisation de la page et de la limite pour obtenir des données pour la première fois.
L'identifiant de la dernière donnée renvoyée est 3499984
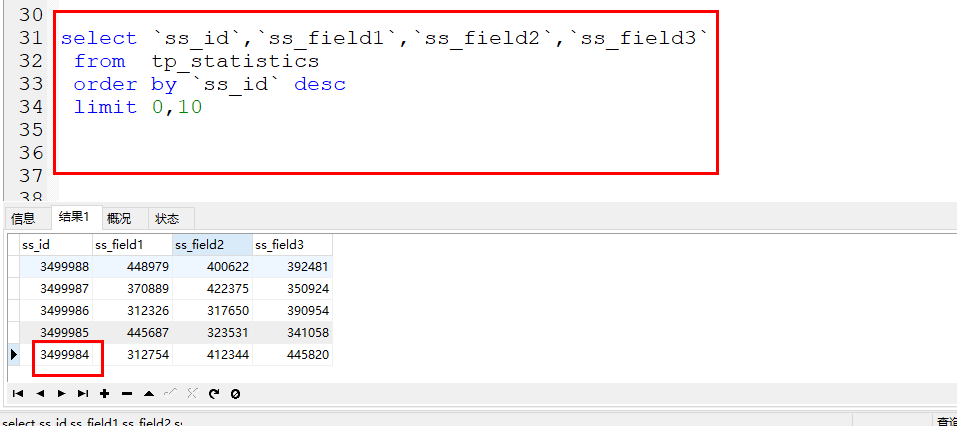
À ce moment , si vous obtenez le troisième Pour le deuxième enregistrement, soit offset et limit sont utilisés, soit last_id et limit sont transmis.
Comme indiqué ci-dessous
À ce stade, la condition Where est utilisée pour filtrer directement les données. La condition est que l'identifiant soit inférieur au dernier identifiant des données précédentes.
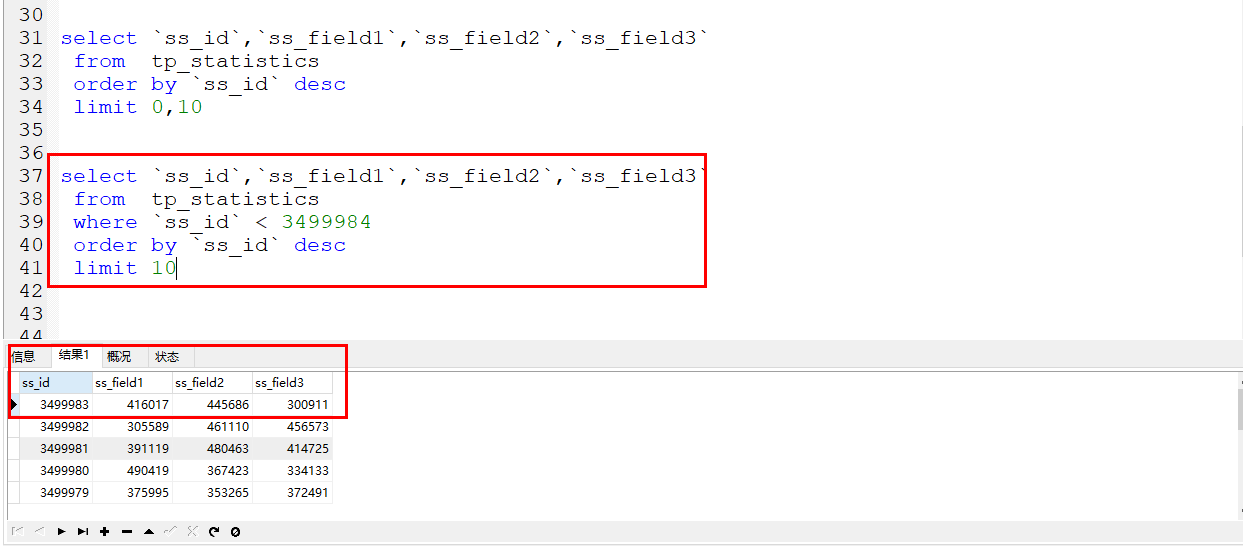
Comparaison temporelle
Supposons que vous souhaitiez obtenir le dernier élément de données maintenant
Avant l'optimisation
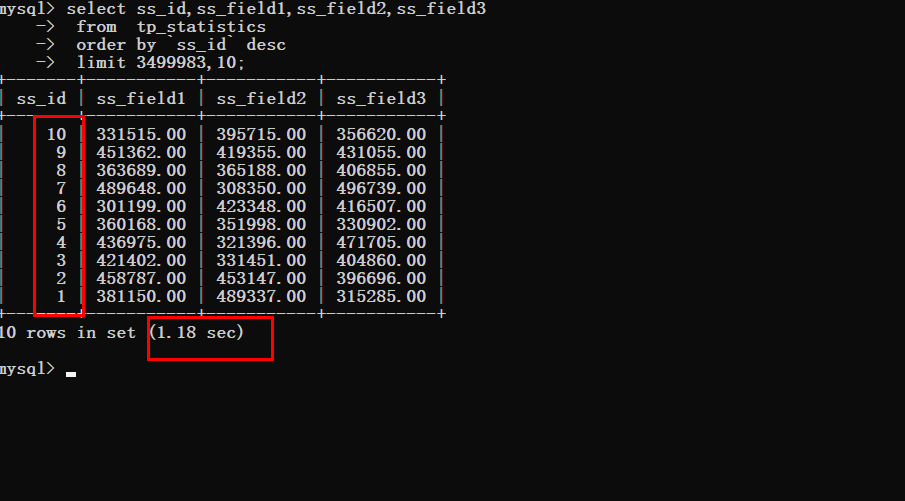
Après l'optimisation, vous pouvez clairement voir le changement dans le temps de requête
6. Résumé
Quelques mots sur l'optimisation des limites.
Lorsque la quantité de données est importante, le décalage et la limite ne peuvent pas être utilisés pour la pagination, car plus le décalage est grand, plus le temps de requête est long. Bien sûr, on ne peut pas dire que toute pagination n'est pas possible si vos données ne contiennent que des milliers ou des dizaines de milliers d'éléments, alors cela n'a pas d'importance, utilisez-les simplement avec désinvolture. Le plan de mise en œuvre est le plan au-dessus de Kaka. Utilisez le décalage et la limite pour obtenir les données pour la première fois, et utilisez la condition Where pour la deuxième fois pour obtenir les données jusqu'au dernier identifiant de. les premières données.
«La persévérance dans l'apprentissage, la persévérance dans les blogs et la persévérance dans le partage sont les convictions auxquelles Kaka a toujours adhéré depuis qu'il a commencé à travailler dans l'industrie. . J'espère que le succès de Kaka sur l'immense Internet Cet article pourra vous aider un peu. Je m'appelle Kaka, à la prochaine fois.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL: la facilité de gestion des données pour les débutants
Apr 09, 2025 am 12:07 AM
MySQL: la facilité de gestion des données pour les débutants
Apr 09, 2025 am 12:07 AM
MySQL convient aux débutants car il est simple à installer, puissant et facile à gérer les données. 1. Installation et configuration simples, adaptées à une variété de systèmes d'exploitation. 2. Prise en charge des opérations de base telles que la création de bases de données et de tables, d'insertion, d'interrogation, de mise à jour et de suppression de données. 3. Fournir des fonctions avancées telles que les opérations de jointure et les sous-questionnaires. 4. Les performances peuvent être améliorées par l'indexation, l'optimisation des requêtes et le partitionnement de la table. 5. Prise en charge des mesures de sauvegarde, de récupération et de sécurité pour garantir la sécurité et la cohérence des données.
 Comment créer Navicat Premium
Apr 09, 2025 am 07:09 AM
Comment créer Navicat Premium
Apr 09, 2025 am 07:09 AM
Créez une base de données à l'aide de NAVICAT Premium: Connectez-vous au serveur de base de données et entrez les paramètres de connexion. Cliquez avec le bouton droit sur le serveur et sélectionnez Créer une base de données. Entrez le nom de la nouvelle base de données et le jeu de caractères spécifié et la collation. Connectez-vous à la nouvelle base de données et créez le tableau dans le navigateur d'objet. Cliquez avec le bouton droit sur le tableau et sélectionnez Insérer des données pour insérer les données.
 Puis-je récupérer le mot de passe de la base de données dans Navicat?
Apr 08, 2025 pm 09:51 PM
Puis-je récupérer le mot de passe de la base de données dans Navicat?
Apr 08, 2025 pm 09:51 PM
Navicat lui-même ne stocke pas le mot de passe de la base de données et ne peut récupérer que le mot de passe chiffré. Solution: 1. Vérifiez le gestionnaire de mots de passe; 2. Vérifiez la fonction "Remember Motway" de Navicat; 3. Réinitialisez le mot de passe de la base de données; 4. Contactez l'administrateur de la base de données.
 MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL est un système de gestion de base de données relationnel open source. 1) Créez une base de données et des tables: utilisez les commandes CreateDatabase et CreateTable. 2) Opérations de base: insérer, mettre à jour, supprimer et sélectionner. 3) Opérations avancées: jointure, sous-requête et traitement des transactions. 4) Compétences de débogage: vérifiez la syntaxe, le type de données et les autorisations. 5) Suggestions d'optimisation: utilisez des index, évitez de sélectionner * et utilisez les transactions.
 MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL sont des compétences essentielles pour les développeurs. 1.MySQL est un système de gestion de base de données relationnel open source, et SQL est le langage standard utilisé pour gérer et exploiter des bases de données. 2.MySQL prend en charge plusieurs moteurs de stockage via des fonctions de stockage et de récupération de données efficaces, et SQL termine des opérations de données complexes via des instructions simples. 3. Les exemples d'utilisation comprennent les requêtes de base et les requêtes avancées, telles que le filtrage et le tri par condition. 4. Les erreurs courantes incluent les erreurs de syntaxe et les problèmes de performances, qui peuvent être optimisées en vérifiant les instructions SQL et en utilisant des commandes Explication. 5. Les techniques d'optimisation des performances incluent l'utilisation d'index, d'éviter la numérisation complète de la table, d'optimiser les opérations de jointure et d'améliorer la lisibilité du code.
 Comment afficher le mot de passe de la base de données dans NAVICAT pour MARIADB?
Apr 08, 2025 pm 09:18 PM
Comment afficher le mot de passe de la base de données dans NAVICAT pour MARIADB?
Apr 08, 2025 pm 09:18 PM
NAVICAT pour MARIADB ne peut pas afficher directement le mot de passe de la base de données car le mot de passe est stocké sous forme cryptée. Pour garantir la sécurité de la base de données, il existe trois façons de réinitialiser votre mot de passe: réinitialisez votre mot de passe via Navicat et définissez un mot de passe complexe. Affichez le fichier de configuration (non recommandé, haut risque). Utilisez des outils de ligne de commande système (non recommandés, vous devez être compétent dans les outils de ligne de commande).
 Comment créer une nouvelle connexion à MySQL dans Navicat
Apr 09, 2025 am 07:21 AM
Comment créer une nouvelle connexion à MySQL dans Navicat
Apr 09, 2025 am 07:21 AM
Vous pouvez créer une nouvelle connexion MySQL dans NAVICAT en suivant les étapes: ouvrez l'application et sélectionnez une nouvelle connexion (CTRL N). Sélectionnez "MySQL" comme type de connexion. Entrez l'adresse Hostname / IP, le port, le nom d'utilisateur et le mot de passe. (Facultatif) Configurer les options avancées. Enregistrez la connexion et entrez le nom de la connexion.
 Comment exécuter SQL dans Navicat
Apr 08, 2025 pm 11:42 PM
Comment exécuter SQL dans Navicat
Apr 08, 2025 pm 11:42 PM
Étapes pour effectuer SQL dans NAVICAT: Connectez-vous à la base de données. Créez une fenêtre d'éditeur SQL. Écrivez des requêtes ou des scripts SQL. Cliquez sur le bouton Exécuter pour exécuter une requête ou un script. Affichez les résultats (si la requête est exécutée).
