

MYSQL Advanced pour l'apprentissage du Big Data

Recommandations d'apprentissage gratuites : tutoriel vidéo MySQL
Répertoire d'articles
- 1 Plusieurs aspects qui affectent les performances
- 1.1 Aspects matériels
- 1.2 Système serveur
- 1.3 Moteur de stockage de base de données sélection
- 1.4 Configuration des paramètres de la base de données
- 1.5 Conception de la structure de la base de données et instructions SQL (points clés)
- 2 Aspects matériels
-
- 2.1 Ressources CPU et taille de mémoire disponible
- 2.1.1 Comment choisir le CPU
- 2.1.2 Mémoire
- 2.1.2.1 Moteurs de stockage MySQL couramment utilisés
- 2.1.2.2 Conseils
- 2.1.2.3 Comment choisir la mémoire
- 2.2 Configuration et sélection des disques
- 2.2.1 Utilisation des disques durs des machines traditionnelles
- 2.2.2 Utilisation du RAID pour améliorer les performances des disques durs des machines traditionnelles
- 2.2.2.1 Qu'est-ce que le RAID
- 2.2.2.2 Niveau RAID
- 2.2.2.2.1 RAID 0
- 2.2.2.2.2 RAID 1
- 2.2.2.2.3 RAID 5 - Groupes RAID communs
- 2.2.2.2.4 RAID 10 - Groupes RAID communs
- 2.2.2.3 Sélection du niveau RAID
- 2.2.3 Utilisation de cartes SSD et PCIe de stockage à semi-conducteurs
- 2.2.4 Utilisation de stockage réseau NAS et SAN
- 2.2.4.1 Scénarios d'utilisation du stockage réseau
- 2.2.4.2 Limitations des performances du réseau
- 2.2.4.3 Impact du réseau sur les performances
- Résumé 2.3
- 3 Impact du système d'exploitation sur les performances
- 3.1 Optimisation des paramètres du système CentOS
- 4 Impact du système de fichiers sur les performances
- 5 Architecture MySQL
1 Plusieurs aspects qui affectent les performances
1.1 Matériel
Habituellement, les ordinateurs personnels sont lents, et nous disons tous que c'est à cause de problèmes matériels informatiques, généralement des facteurs tels que le processeur, la mémoire, les E/S du disque, etc. donc ce problème se produira également sur le serveur.
1.2 Système serveur
Généralement, le système d'exploitation des ordinateurs personnels est Windows. Les performances des différentes versions des systèmes Windows sont différentes ou certains paramètres sont configurés pour provoquer. performances différentes. C'est la même chose pour les systèmes serveur, et les paramètres définis affecteront également les performances du serveur.
1.3 Sélection du moteur de stockage de base de données
MySQL dispose d'un moteur de stockage plug-in, et différents moteurs de stockage peuvent être sélectionnés en fonction des différents besoins de l'entreprise.
Différents moteurs de stockage ont également des caractéristiques différentes :
- MyISAM : ne prend pas en charge les transactions et les verrous au niveau des tables.
- InnoDB : moteur de stockage au niveau des transactions, prend parfaitement en charge les verrous au niveau des lignes et les fonctionnalités ACID des transactions.
1.4 Configuration des paramètres de base de données
Pour différents moteurs de stockage, leurs configurations de paramètres sont différentes. Certains paramètres ont un impact minimal sur le moteur de stockage, mais certains paramètres jouent. un rôle déterminant dans la performance. Par conséquent, il est également important d’optimiser les paramètres en fonction du moteur de stockage sélectionné et des différents besoins de l’entreprise.
1.5 Conception de la structure de la base de données et instructions SQL (points clés)
Lorsque nous concevons la structure de la base de données, nous devons réfléchir au type d'instructions SQL que nous exécuterons sur la base de données à l'avenir, pour interroger et mettre à jour la structure de la table. Ce n'est qu'ainsi qu'une structure de table répondant aux exigences peut être conçue.
Pour les requêtes lentes, c'est le principal responsable des faibles performances, et cela est dû à notre conception déraisonnable de la structure des tables de la base de données. Ce type de SQL est également le plus difficile à optimiser, car une fois le projet mis en ligne, il est difficile de modifier la structure des tables de la base de données.
Nous nous concentrons donc sur l'optimisation des performances de la base de données :
Conception de la structure des tables de base de données
Rédaction et optimisation d'instructions SQL
Ce qui suit est une description détaillée de chaque aspect.
2 Aspects matériels
2.1 Ressources CPU et taille de mémoire disponible
2.1.1 Comment choisir le CPU
Habituellement, lors du choix d'un processeur, nous espérons tous que la fréquence et le nombre de cœurs du processeur sont aussi élevés que possible, mais en raison du coût ou de divers facteurs, nous sommes souvent obligés de choisir un seul d'entre eux. Alors, comment choisir la meilleure solution ? Par conséquent, nous devons prêter attention à plusieurs problèmes lors de l’achat d’un processeur :
- Notre application est-elle gourmande en CPU ?
- Si notre application est gourmande en CPU, pour accélérer le traitement SQL, nous avons évidemment besoin de meilleurs processeurs, plutôt que de plus processeurs.
- Pour MySQL actuel, le dualCPU ne prend pas en charge le traitement simultané du même SQL.
- Quelle est la concurrence de notre système ?
- Si notre système a besoin de plus de débit, alors plus nous avons de processeurs, mieux c'est. En supposant que nous ayons 40 processeurs, pouvons-nous traiter 40 SQL en même temps ?
- Mesure des capacités de traitement de la base de données : QPS, qui fait référence au nombre de SQL traités simultanément. Mais cet indicateur est le nombre de SQL traités en 1s, mais le traitement simultané expliqué au point précédent est dans la dimension nanoseconde.
- MySQL est généralement utilisé dans les applications Web, et le degré de concurrence est souvent relativement important. À l'heure actuelle, le nombre de processeurs est plus important que la fréquence du processeur.
- La version de MySQL que nous utilisons
- Avant la version 5.0, MySQL n'avait pas un bon support pour les processeurs multicœurs et les restrictions du système étaient très sérieuses. versions actuelles 5.6 et 5.7, la prise en charge des processeurs multicœurs a été grandement améliorée. Par conséquent, il est recommandé d’utiliser la dernière version de MySQL pour obtenir de meilleures performances.
- Choisir un processeur 32 bits ou 64 bits ?
- Actuellement, les processeurs des serveurs sont tous dotés d'une architecture 64 bits par défaut, mais veuillez noter que vous devez vérifier si le système dispose d'une version de serveur 32 bits installée au-dessus du système 64 bits, ce qui affectera sérieusement performances du serveur.
2.1.2 Mémoire
La taille de la mémoire affecte directement les performances de la base de données. La mémoire est actuellement bien plus efficace que le disque. Par conséquent, la mise en cache des données en mémoire peut améliorer considérablement les performances du serveur.
2.1.2.1 Moteurs de stockage MySQL couramment utilisés
Il existe deux moteurs de stockage couramment utilisés : MyISAM et InnoDB.
MyISAM :
L'index est stocké en mémoire et les données sont enregistrées sur le disque dur. 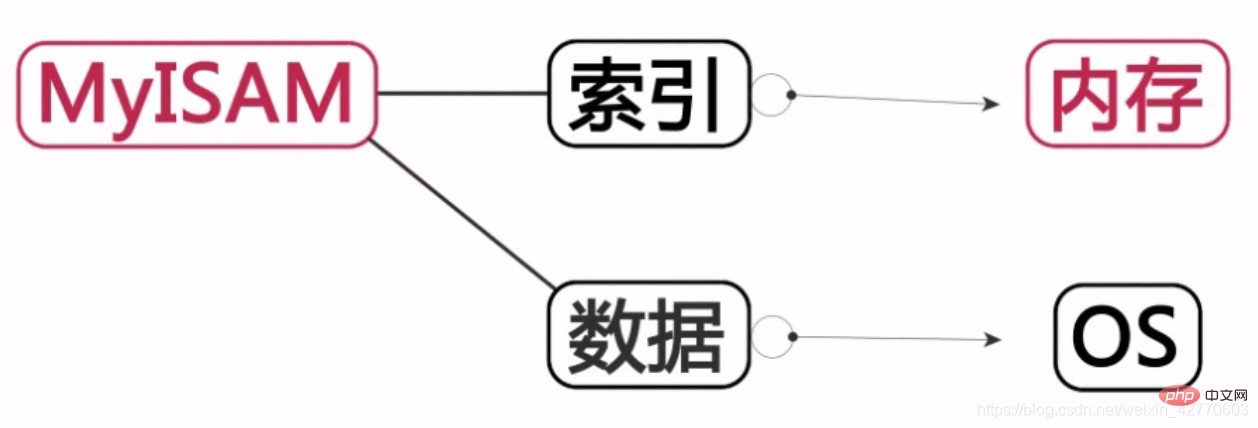
InnoDB :
Les index et les données sont stockés en mémoire, améliorant ainsi l'efficacité opérationnelle de la base de données. 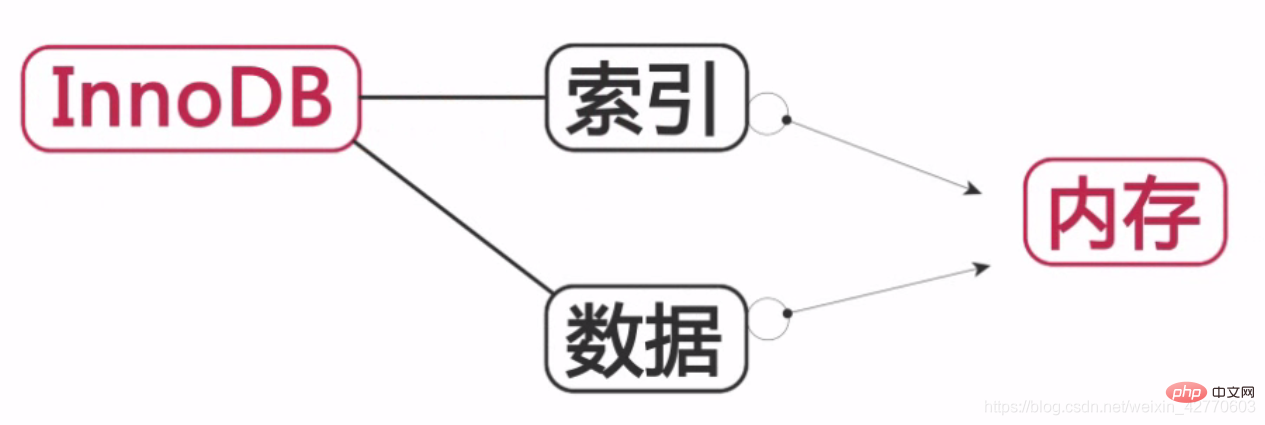
2.1.2.2 Conseils
- Bien que plus il y a de mémoire, mieux c'est, l'impact sur les performances du système est limité.
Si les données de notre base de données sont de 100 Go, alors les performances maximales peuvent être obtenues en sélectionnant la mémoire autour de 128 Go. À ce stade, si toutes les données sont des données chaudes, elles seront mises en cache dans la mémoire. utiliser une mémoire de 256 Go. Cependant, choisir une mémoire plus grande améliorera également les performances d'autres services tels que le système d'exploitation, et il n'est pas nécessaire d'envisager une mise à niveau de la mémoire à court terme. - Lors de l'écriture des opérations dans le cache mémoire, vous pouvez retarder l'écriture pour réduire la pression sur la base de données.
La mémoire prend déjà en charge les opérations de lecture, et les opérations d'écriture peuvent également être effectuées sur la mémoire. En fin de compte, nous devons écrire les données sur le disque. Bien que nous ne puissions pas éviter l'opération d'écriture sur le disque, nous pouvons retarder les opérations d'écriture et fusionner plusieurs écritures en une seule pour réduire la pression sur la base de données. La base de données fournit une fonction similaire, qui peut fusionner plusieurs opérations d'écriture en une seule dans le pool de cache et enfin les écrire sur le disque.
2.1.2.3 Comment choisir la mémoire
-
Essayez d'utiliser la mémoire que la carte mère peut prendre en charge à la fréquence maximale
- Afin de constituer une mise à niveau achetée, la mémoire de chaque canal doit être de la même marque, granulométrie, fréquence, tension, technologie de vérification et modèle.
- Sélectionnez la mémoire en fonction de la taille de la base de données.
2.2 Configuration et sélection du disque
Bien que la mémoire joue un rôle important dans les performances de la base de données, nous ne pouvons pas ignorer l'impact du sous-système IO sur les performances . À l'heure actuelle, nous utilisons couramment les 4 types d'options de disque suivants :
2.2.1 Utilisation de disques durs de machines traditionnels
Caractéristiques : grand espace de stockage, prix bas, la plupart utilisé, le plus courant, la lecture et l'écriture sont lentes
- Comment choisir un disque dur de machine traditionnelle ?
- Capacité de stockage
- Vitesse de transmission
- Temps d'accès
- Vitesse de broche
- Dimensions physiques
2.2.2 Utiliser le RAID pour améliorer les performances des disques durs des machines traditionnelles
2.2.2.1 Qu'est-ce que le RAID
RAID est la redondance des disques L'abréviation de Redundant Arrays of Independent Disks. En termes simples, la fonction du RAID est de combiner plusieurs disques de plus petite capacité en un groupe de disques de plus grande capacité et de fournir une redondance des données pour garantir l'intégrité des données.
2.2.2.2 RAID级别
2.2.2.2.1 RAID 0
RAID 0 est le premier mode RAID, également appelé répartition des données. Il s'agit de la forme la plus simple parmi les baies de disques de composants. Elle ne nécessite que plus de 2 disques durs. Elle est peu coûteuse et peut améliorer les performances et le débit de l'ensemble du disque. RAID 0 ne fournit pas de capacités de redondance ou de récupération d'erreur, mais constitue le coût de mise en œuvre le plus bas. Cependant, si l'on considère les facteurs de récupération des données et de fiabilité, RAID 0 est devenu la configuration la plus coûteuse, car il n'y a pas de redondance dans RAID 0 et la probabilité d'endommagement des données est plus élevée que dans un seul disque. Parce que des dommages aux données sur n'importe quel disque entraîneront une perte de données. Par exemple, un RAID 0 composé de trois disques est trois fois plus susceptible d'être endommagé qu'un seul disque dur.
Par conséquent, RAID 0 convient aux situations dans lesquelles aucune donnée ne sera perdue, telles que : une base de données de secours qui peut être clonée à partir d'autres bases de données à tout moment ou certaines bases de données qui ne doivent être utilisées qu'une seule fois. 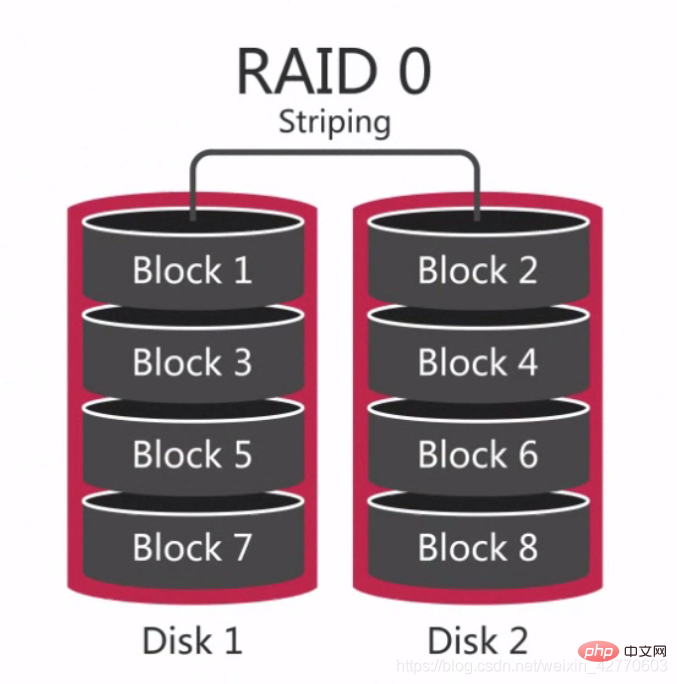
En termes simples, RAID 0 consiste à connecter des disques durs en série pour former un disque plus grand, tel que : 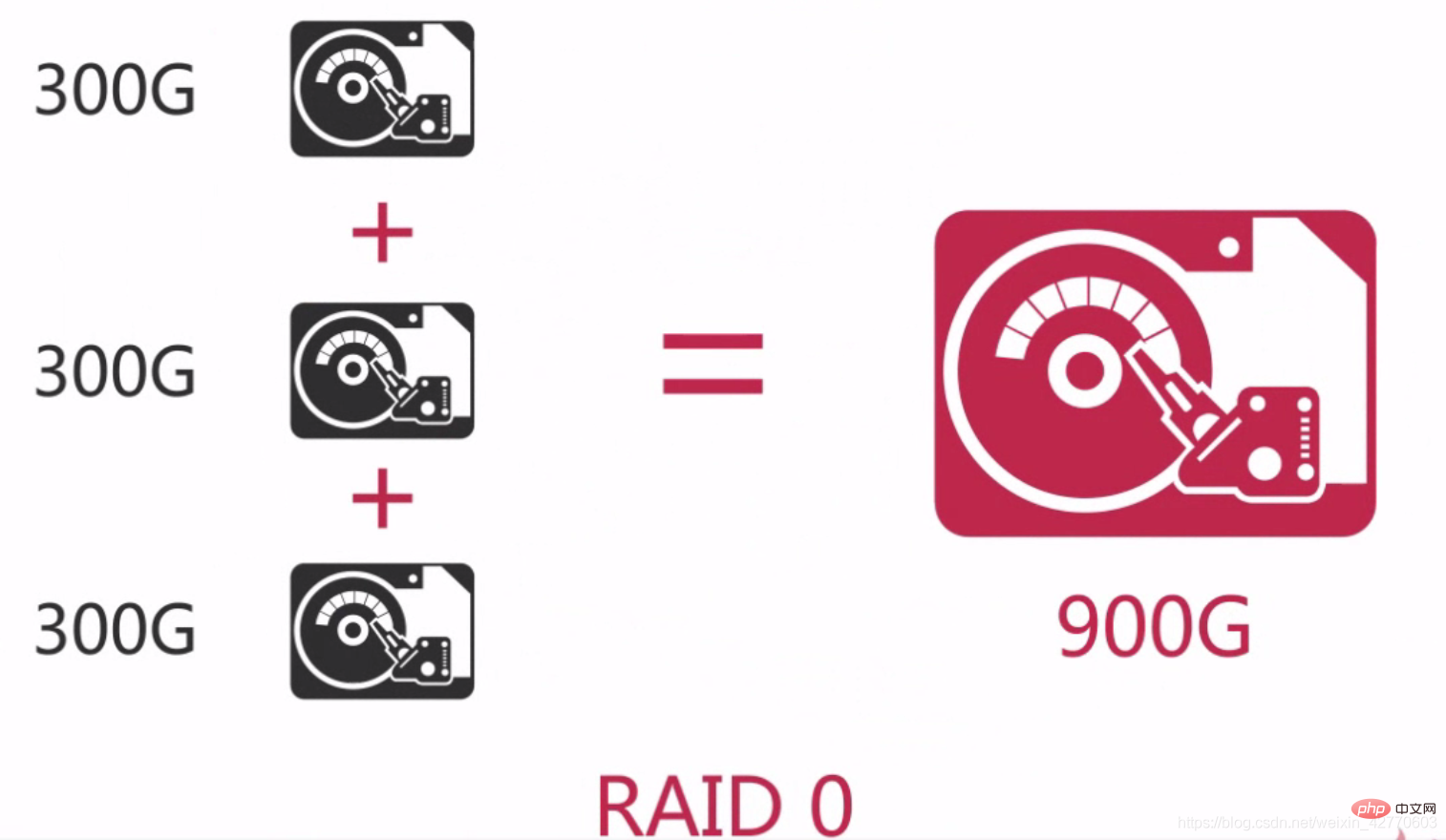
Et dans le processus simultané, il peut atteindre l'équivalent de 3 fois les performances d’un seul disque dur.
2.2.2.2.2 RAID 1
RAID 1 est aussi appelé mirorisation de disque Le principe est de mettre en miroir les données d'un disque sur un autre disque, c'est-à-dire de mettre en miroir les données d'un disque sur un autre disque. disons, les données Lors de l'écriture sur un disque, un fichier image sera généré sur un autre disque restreint pour maximiser la fiabilité et la réparabilité du système sans affecter les performances. 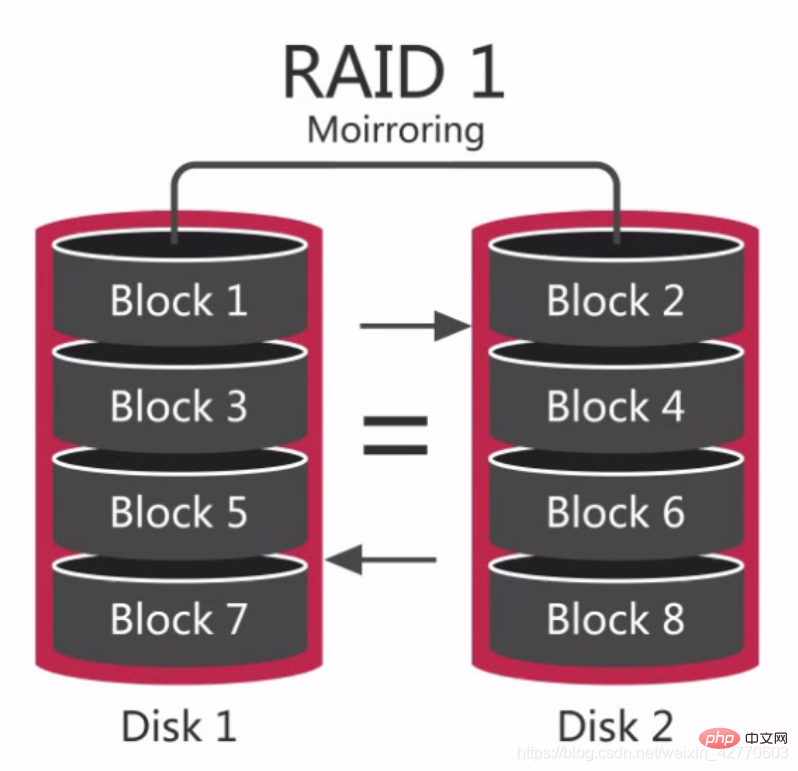
La différence entre celui-ci et RAID 0 est qu'il y a un signe égal au milieu. Les données sur les deux disques sont les mêmes et ont de bonnes capacités de redondance, mais le coût augmentera en conséquence. Il peut fonctionner normalement même en cas de panne de disque, mais le disque défaillant doit être remplacé, sinon le système plantera.
Après le remplacement d'un nouveau disque, la synchronisation des données prendra beaucoup de temps. Même si cela n'affectera pas l'accès aux données, les performances du système seront réduites.
RAID 1 peut fournir de bonnes performances de lecture dans de nombreux cas, ainsi que des données redondantes entre différents disques, la redondance des données est donc très bonne. RAID 1 est meilleur en lecture que RAID 0, il est donc plus adapté au stockage de journaux ou de tâches similaires.
2.2.2.2.3 RAID 5 - Groupes RAID communs
RAID 5 est également appelé matrice de disques à parité distribuée. Les données sont réparties sur plusieurs disques via des blocs de parité distribués, de sorte que si des données de disque échouent, elles peuvent être reconstruites à partir des blocs de parité. Mais si deux disques tombent en panne, l'intégralité des données du volume ne peut pas être récupérée. 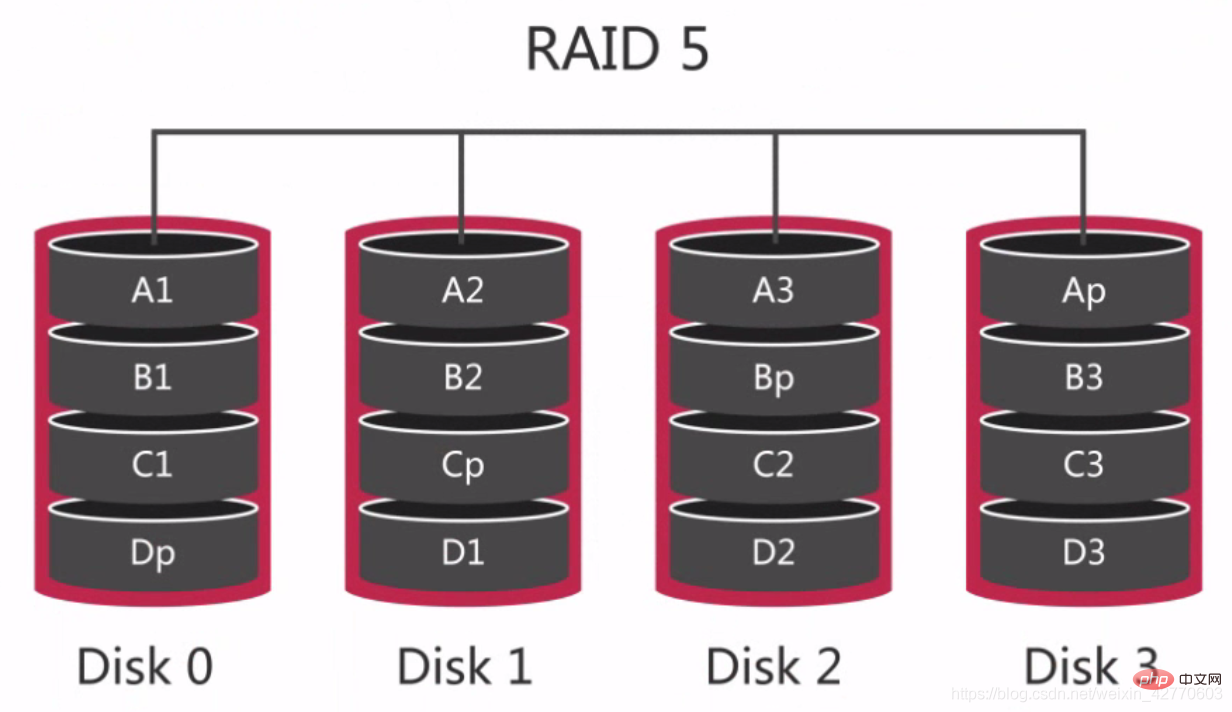
On peut voir que chaque disque a respectivement Dp, Cp, Bp et Ap. S'il y a un problème avec l'un des disques, le disque peut être recalculé en fonction des données et des valeurs de parité. des trois autres disques.
Pour RAID 0 et RAID 1, il s'agit de la configuration redondante la plus économique, car l'ensemble de la configuration de la matrice ne nécessite que la capacité d'un seul disque.
Les écritures sont plus lentes sur RAID 5 car chaque écriture nécessite 2 lectures et 2 écritures entre disques pour calculer la valeur du chiffre de contrôle stocké. Cependant, les lectures aléatoires et séquentielles sont rapides, car il n'est pas nécessaire de calculer les bits de parité lorsque lecture, donc RAID 5 est plus adapté aux services de bases de données orientés lecture.
Le plus gros problème avec RAID 5 est lorsque le disque tombe en panne, car les données doivent être réaffectées à d'autres disques, ce qui affectera sérieusement les performances du disque, il est donc préférable d'utiliser RAID 5 en cas de lecture importante .
2.2.2.2.4 RAID 10 - Groupes RAID couramment utilisés
RAID 10 est également appelé mise en miroir partagée. Il exécute d'abord le RAID 1 sur les disques, puis exécute le RAID 0 sur les deux ensembles de disques RAID 1, ce qui lui confère de bonnes performances en lecture et en écriture. Par rapport au RAID 5, il est plus facile à reconstruire et plus rapide. 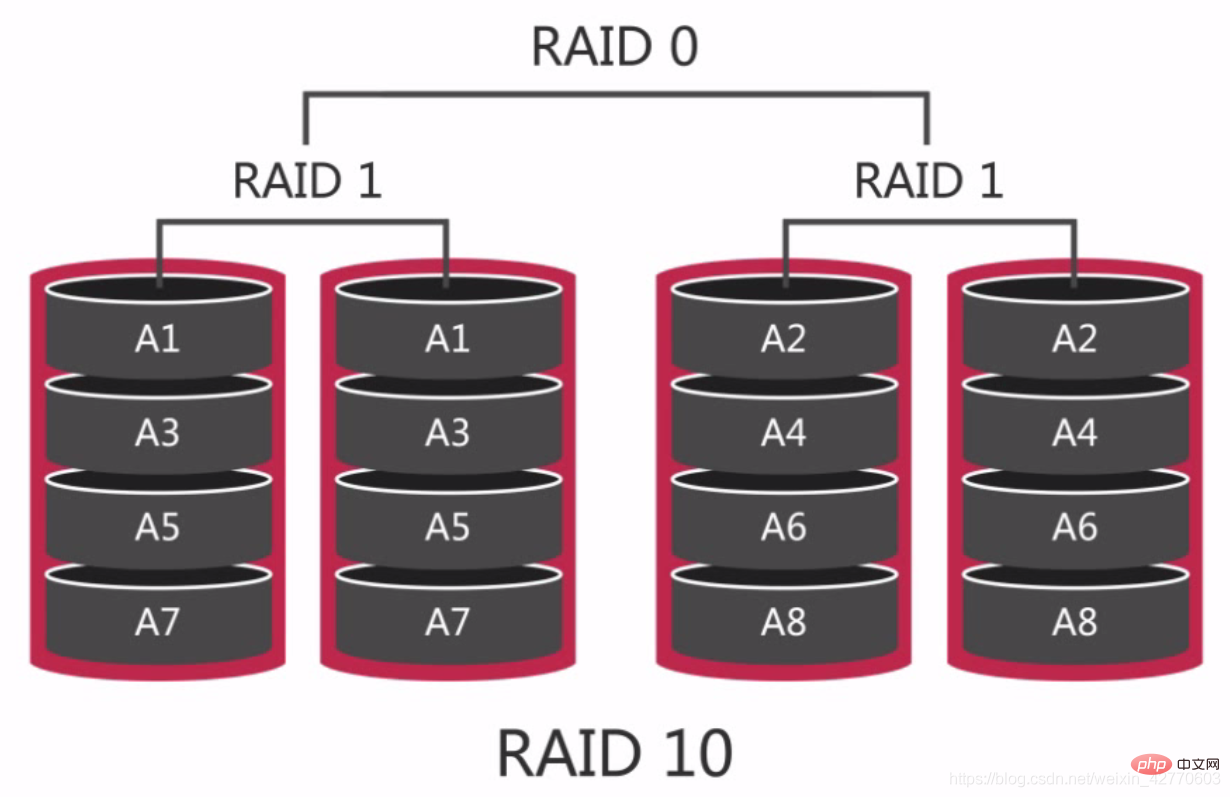
Sur RAID 10, si un disque dur est endommagé, cela aura un impact sérieux sur les performances, car pendant le processus de lecture et d'écriture, deux disques adjacents peuvent être lus en même temps. est endommagé, alors seules les lectures peuvent être effectuées à partir d'un seul disque, donc dans le pire des cas, nos performances seront réduites de 50 %.
2.2.2.3 Sélection du niveau RAID
| 等级 | 特点 | 是否冗余 | 盘数 | 读 | 写 |
|---|---|---|---|---|---|
| RAID 0 | 便宜,快速,危险 | 否 | N | 快 | 快 |
| RAID 1 | 高速读,简单,安全 | 有 | 2 | 快 | 慢 |
| RAID 5 | 安全,成本折中 | 有 | N+1 | 快 | 取决于最慢的盘 |
| RAID 10 | 贵,高速,安全 | 有 | 2N | 快 | 快 |
2.2.3 Utilisation du stockage SSD et des cartes PCIe
Le stockage SSD est également appelé mémoire flash.
Caractéristiques :
- Par rapport aux disques mécaniques, les disques SSD ont de meilleures performances de lecture et d'écriture aléatoires
- Par rapport aux disques mécaniques, les disques SSD ont une meilleure prise en charge de la concurrence.
- Par rapport aux disques mécaniques, les disques SSD sont plus susceptibles d'être endommagés
Caractéristiques du SSD :
- Grâce à l'interface SATA, les disques traditionnels peuvent être remplacé sans aucune modification
- Le SSD avec interface SATA prend également en charge la technologie RAID
Caractéristiques de la carte PCIe de stockage à semi-conducteurs :
- L'interface SATA ne peut pas être utilisée et nécessite des pilotes et une configuration uniques
- Le prix est plus cher que le SSD, mais les performances sont meilleures que le SSD
Scénarios d'utilisation du stockage SSD
- Convient aux situations où il existe un grand nombre de scénarios d'E/S aléatoires
- Utilisé pour résoudre le goulot d'étranglement d'E/S de la charge monothread
2.2.4 Utiliser le stockage réseau NAS et SAN
SAN (Strorage Area Network) et NAS (Network-Attached Storage) sont deux méthodes pour monter des périphériques de stockage de fichiers externes sur le serveur.
SAN :
Le périphérique SAN est connecté au serveur via la fibre optique. L'appareil est accessible via l'interface de bloc et le serveur peut l'utiliser comme disque dur.

Fonctionnalités du SAN : 
NAS :
Les appareils NAS utilisent des connexions réseau, via des protocoles basés sur des fichiers tels que NFS ou PME pour y accéder.
2.2.4.1 Scénarios d'utilisation du stockage réseau
Convient à la sauvegarde de base de données.
2.2.4.2 Limitations des performances du réseau
Les limitations des performances du réseau sont principalement la latence et la bande passante.
2.2.4.3 L'impact du réseau sur les performances
- L'impact de la bande passante du réseau sur les performances
- L'impact de la qualité du réseau sur les performances
Recommandation :- Utilisez des équipements et des commutateurs d'interface réseau hautes performances et à large bande passante
- Liez plusieurs cartes réseau pour améliorer la disponibilité et la bande passante
- Isolez autant le réseau que possible
Résumé 2.3
CPU :
- Le processeur 64 bits doit fonctionner en 64 -bit Sous le système
- Pour les scénarios à forte concurrence, le nombre de CPU est plus important que la fréquence
- Pour les scénarios gourmands en CPU et SQL complexe, plus la fréquence est élevée, mieux c'est
Mémoire :
- Choisissez la mémoire avec la fréquence la plus élevée que la carte mère peut utiliser
- La taille de la mémoire est très importante pour les performances, alors faites-la aussi grand que possible
Sous-système E/S :
- PCIe -> SSD -> Disque ->
Systèmes d'exploitation adaptés à MySQL : Windows, FreeBSD, Solaris, Linux
3.1 Optimisation des paramètres du système CentOSParamètres liés au noyau (/etc/sysctl.conf)
-
net.core.somaxconn = 65535
Pour un port en état d'écoute, il possède sa propre file d'attente d'écoute. Ce paramètre détermine la longueur maximale de la file d'attente d'écoute pour chaque port. La valeur par défaut de ce paramètre peut être relativement petite, ce qui n'est pas suffisant pour les grands serveurs. Elle est généralement modifiée à une valeur de 2048 ou plus. -
net.core.netdev_max_backlog=65535net.ipv4.tcp_max_syn_backlog=65535
Le paramètre backlog détermine les paquets autorisés à être envoyés dans la file d'attente lorsque la vitesse à laquelle chaque interface réseau reçoit les paquets de données est plus rapide que le processeur du noyau . Le nombre maximum de paquets de données, et un autre paramètre détermine le nombre maximum de demandes de ce type pouvant être conservées dans la file d'attente pour lesquelles l'autre partie n'a pas encore obtenu de connexion. Les connexions dépassant cette valeur peuvent être rejetées, donc augmentez la taille en même temps. -
net.ipv4.tcp_fin_timeout = 10
Ce paramètre est utilisé pour contrôler le délai d'expiration de l'état d'attente du traitement de la connexion TCP. Pour les systèmes avec des connexions relativement fréquentes, un grand nombre de connexions sont généralement en attente. Le réglage de ce paramètre vise à réduire le délai d'expiration de la connexion et à accélérer le recyclage TCP. Il existe également les deux paramètres suivants qui ont un impact sur les connexions TCP :net.ipv4.tcp_tw_reuse = 1,net.ipv4.tcp_tw_recycle = 1
Ces trois paramètres accélèrent principalement le recyclage TCP sous les systèmes à forte charge, si la connexion TCP est Si elle est activée. est plein, il y aura une erreur de connexion à la base de données 500, ces trois paramètres sont donc très importants. -
net.core.wmem_default = 87380,net.core.wmem_max = 16777216,net.core.r0mem_default = 87380,net.core.rmem_max = 16777216
Les 4 paramètres ci-dessus déterminent les valeurs par défaut et maximales des tailles de tampon de réception et d'envoi de la connexion TCP. Pour la base de données, les valeurs de ces paramètres doivent être légèrement plus grandes. -
net.ipv4.tcp_keepalive_time = 120,net.ipv4.tcp_keepalive_intvl = 30,net.ipv4.tcp_keepalive_probes = 3
Les trois paramètres ci-dessus sont utilisés pour réduire le nombre de ressources du système TCP occupées par des connexions défaillantes et accélérer l'efficacité du recyclage des ressourcesnet.ipv4.tcp_keepalive_time. signifie tcp L'intervalle de temps d'envoi des messages de détection tcp_keepalive, en secondes, utilisé pour confirmer si la connexion TCP est valide.net.ipv4.tcp_keepalive_intvlest utilisé pour renvoyer le message de détection après avoir détecté que la connexion TCP ne répond pas. L'unité est en secondesnet.ipv4.tcp_keepalive_probesindique combien de messages de détection tcp_keepalive doivent être envoyés avant que la connexion TCP ne soit considérée comme invalide. Les valeurs par défaut de ces trois paramètres sont un peu trop grandes pour un système ordinaire, elles sont donc ici modifiées par des valeurs plus petites. -
kernel.shmmax = 4294967295
Ce paramètre est l'un des paramètres les plus importants des paramètres du noyau Linux et est utilisé pour définir la valeur maximale d'un seul segment de mémoire partagée.
Remarque :- Ce paramètre doit être défini suffisamment grand pour accueillir la taille entière du pool de tampons Innodb dans un segment de mémoire partagée.
- Pour les systèmes Linux 64 bits, la valeur maximale pouvant être prise est la valeur de la mémoire physique - 1 octet. La valeur recommandée est supérieure à la moitié du segment de mémoire physique. du pool de tampons Innodb. Peut prendre de la mémoire physique - 1 octet.
-
vm.swappiness = 0
Ce paramètre aura un impact significatif sur les performances lorsque la mémoire est insuffisante. Ce paramètre indique au noyau du système Linux de ne pas utiliser la zone de swap à moins que la mémoire virtuelle ne soit complètement pleine.
Partition d'échange de mémoire système Linux :
Lorsque le système Linux est installé, il y aura une partition de disque spéciale, appelée partition d'échange système . Si nous utilisonsfree -mpour afficher le système, nous pouvons voir quelque chose de similaire à ce qui suit, où swap est la partition d'échange. Lorsque le système d'exploitation ne dispose pas de suffisamment de mémoire, il écrira de la mémoire virtuelle dans la zone d'échange du disque et un échange de mémoire se produira.
Désactiver complètement la partition swap sur le système Linux où se trouve le service MySQL entraînera les deux risques suivants :- Réduire les performances du système d'exploitation
- Facile à provoquer débordement de mémoire, a planté , ou ont été Tués par le système d'exploitation
Augmenter les limites de ressources (/etc/security /limit.conf )limit.confCe fichier est en fait le fichier de configuration de Linx PAM, qui est le module d'authentification du plug-in.
L'une des configurations de paramètres les plus importantes est la limite du nombre de fichiers ouverts. 
Conclusion : augmentez le nombre de fichiers ouverts à 65 535 pour garantir que suffisamment de descripteurs de fichiers peuvent être ouverts.
Remarque : les modifications apportées à ce fichier doivent être redémarrées pour prendre effet.
Politique de planification de disque (/sys/block/devname/queue/scheduler)
Vous pouvez utiliser la commande cat /sys/block/sda/queue/scheduler pour afficher la politique de planification utilisée par le disque actuel. Le noop anticipatory deadline [cfq] suivant est la politique de planification cfq par défaut du système.
Sous le service de base de données MySQL, cfq ne convient pas car pendant le processus de travail de MySQL, cfq insérera des requêtes inutiles dans la file d'attente, ce qui entraînera un mauvais temps de réponse. 
En plus de la stratégie de planification cfq, il existe également les stratégies suivantes :
noop (stratégie de planification des ascenseurs) : 
date limite (stratégie de planification des délais) : 
anticipative (politique de planification d'E/S anticipative) : 
Nous pouvons saisir la commande suivante pour modifier la politique de planification des disques : echo schedulerName > /sys/block/sda/queue/scheduler
Par exemple : echo deadline > /sys/block/sda/queue/scheduler
4 Impact du système de fichiers sur les performances
Il est recommandé d'utiliser le système de fichiers XFS Les paramètres suivants doivent être configurés sous EXT3. et EXT4 : 
Paramètres de montage du système EXT3/4 (/etc/fstab) :
-
data=writeback | ordered | journal
Il existe trois valeurs facultatives pour cela Le paramètrewritebacksignifie que seul l'élément Data est écrit dans le journal et que l'écriture des métadonnées et l'écriture des données ne sont pas synchronisées. Il s'agit de la configuration la plus rapide et constitue généralement le meilleur choix pour InnoDB car InnoDB possède à l'origine son propre journal de transactions.orderedn'enregistrera que les métadonnées, mais offre certaines garanties de cohérence. Avant d'écrire les métadonnées, les données seront d'abord écrites pour les rendre cohérentes. Cette option est légèrement plus lente quewriteback, mais elle sera plus sûre en cas de crash. .journalFournit un comportement de journalisation atomique, où les données seront enregistrées dans le journal avant d'être écrites dans le journal final. Cette option est évidemment inutile pour InnoDB et est la plus lente des trois. -
noatime,nodiratime
Ces deux options permettent d'enregistrer l'heure d'accès au fichier et l'heure de lecture du répertoire. La définition de ces deux paramètres peut réduire certaines opérations d'écriture. Le système n'a pas besoin d'écrire des opérations pour enregistrer les deux fois ci-dessus lors de la lecture de fichiers et de répertoires.
Voici quelques configurations dans le fichier/dev/sda1/ext4:noatime,nodiratime,data=writeback 1 1
5 Architecture MySQL
L'architecture est au top Le niveau est appelé client. Cette couche représente le client qui peut se connecter à mysql via le protocole de connexion mysql, tel que PHP, JAVA, API C, .Net, ODBC, JDBC, etc. On peut voir d'ici que cette couche est pas unique à l'architecture MySQL. La plupart des services d'architecture CS adoptent cette architecture. Cette couche remplit principalement certaines fonctions telles que le traitement des connexions, l'authentification des autorisations et la sécurité. Chaque client connecté à MySQL a un thread dans le processus serveur. La requête de cette connexion ne sera exécutée que dans ce thread. Comme nous l'avons mentionné précédemment, chaque requête de connexion n'utilise qu'un seul cœur de processeur.
Ensuite, dans la deuxième couche de ce système, la plupart des services MySQL de base se trouvent dans cette couche, comme le montre la figure ci-dessous. 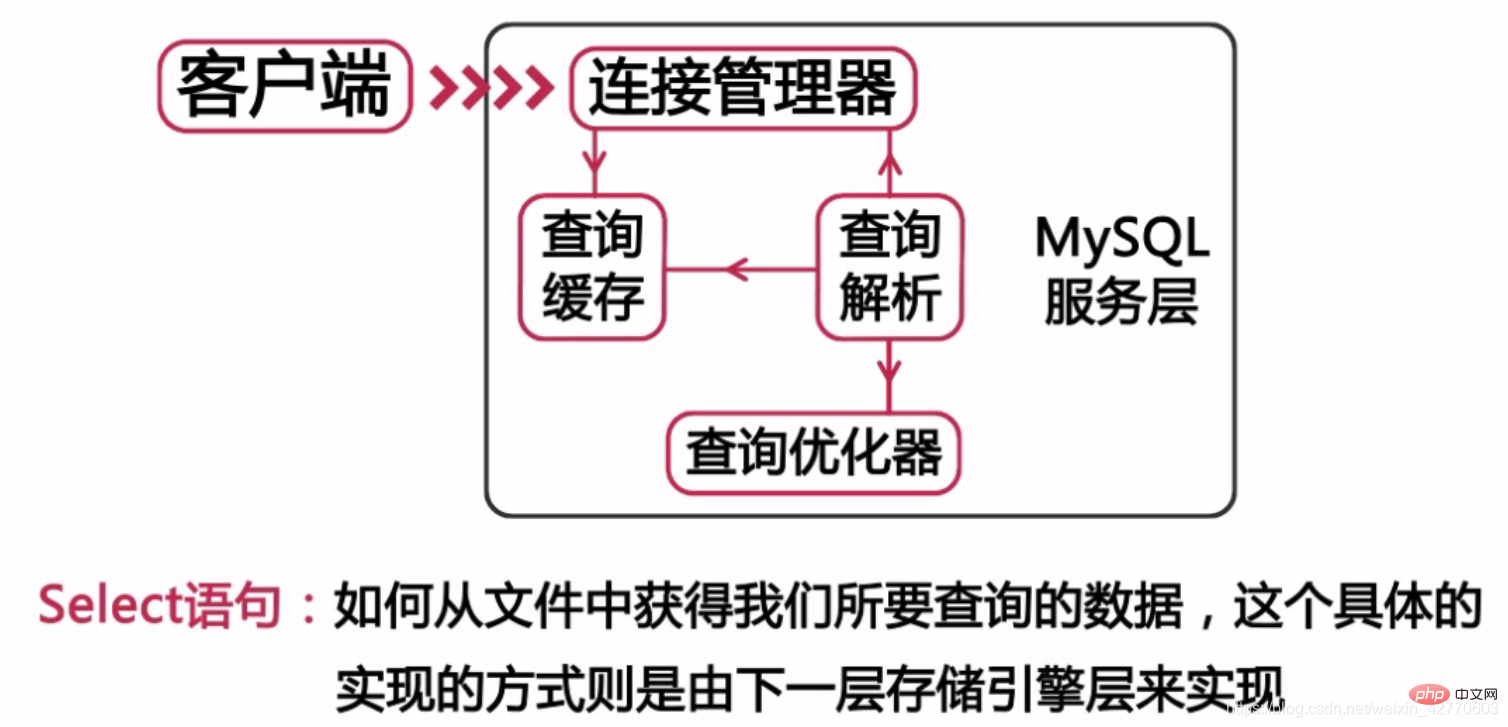
Nos instructions DDL ou DML couramment utilisées sont définies au niveau de cette couche. Mais nous devons juste nous rappeler une chose : toutes les fonctions du moteur de stockage croisé sont implémentées dans cette couche, car cette couche est également appelée couche de service.
La troisième couche de notre système structurel est la couche du moteur de stockage. MySQL est une très excellente base de données open source, qui définit une série d'interfaces du moteur de stockage, tant qu'elle répond aux exigences du moteur de stockage, nous pouvons développer MySQL. Créez un moteur de stockage qui répond pleinement à vos besoins, comme notre InnoDB couramment utilisé. Actuellement, il existe de nombreux moteurs de stockage pris en charge par MySQL, comme le montre la figure ci-dessous : 
Remarque : Moteur de stockage Il est destiné aux tables plutôt qu'aux bibliothèques (différentes tables d'une bibliothèque peuvent utiliser différents moteurs de stockage) Ci-dessous, nous sélectionnons certains des moteurs de stockage les plus couramment utilisés pour une brève explication. Le moteur de stockage utilisé par MySQL sera. Les performances de la base de données ont un impact direct. J'espère également que vous pourrez bien comprendre certaines des caractéristiques du moteur de stockage avant d'utiliser le moteur de stockage.
Plus de recommandations d'apprentissage gratuites connexes : tutoriel MySQL(vidéo)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Apache se connecte à une base de données nécessite les étapes suivantes: Installez le pilote de base de données. Configurez le fichier web.xml pour créer un pool de connexion. Créez une source de données JDBC et spécifiez les paramètres de connexion. Utilisez l'API JDBC pour accéder à la base de données à partir du code Java, y compris l'obtention de connexions, la création d'instructions, les paramètres de liaison, l'exécution de requêtes ou de mises à jour et de traitement des résultats.
 CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
L'installation de MySQL sur CENTOS implique les étapes suivantes: Ajout de la source MySQL YUM appropriée. Exécutez la commande YUM Install MySQL-Server pour installer le serveur MySQL. Utilisez la commande mysql_secure_installation pour créer des paramètres de sécurité, tels que la définition du mot de passe de l'utilisateur racine. Personnalisez le fichier de configuration MySQL selon les besoins. Écoutez les paramètres MySQL et optimisez les bases de données pour les performances.
 Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Le processus de démarrage de MySQL dans Docker se compose des étapes suivantes: Tirez l'image MySQL pour créer et démarrer le conteneur, définir le mot de passe de l'utilisateur racine et mapper la connexion de vérification du port Créez la base de données et l'utilisateur accorde toutes les autorisations sur la base de données
