


Recommandations d'apprentissage gratuites : tutoriel vidéo python
micro Boresou d'exploration de python est stocké dans Mysql
Effet final
Pas beaucoup de bêtises , allez simplement à l'image ci-dessus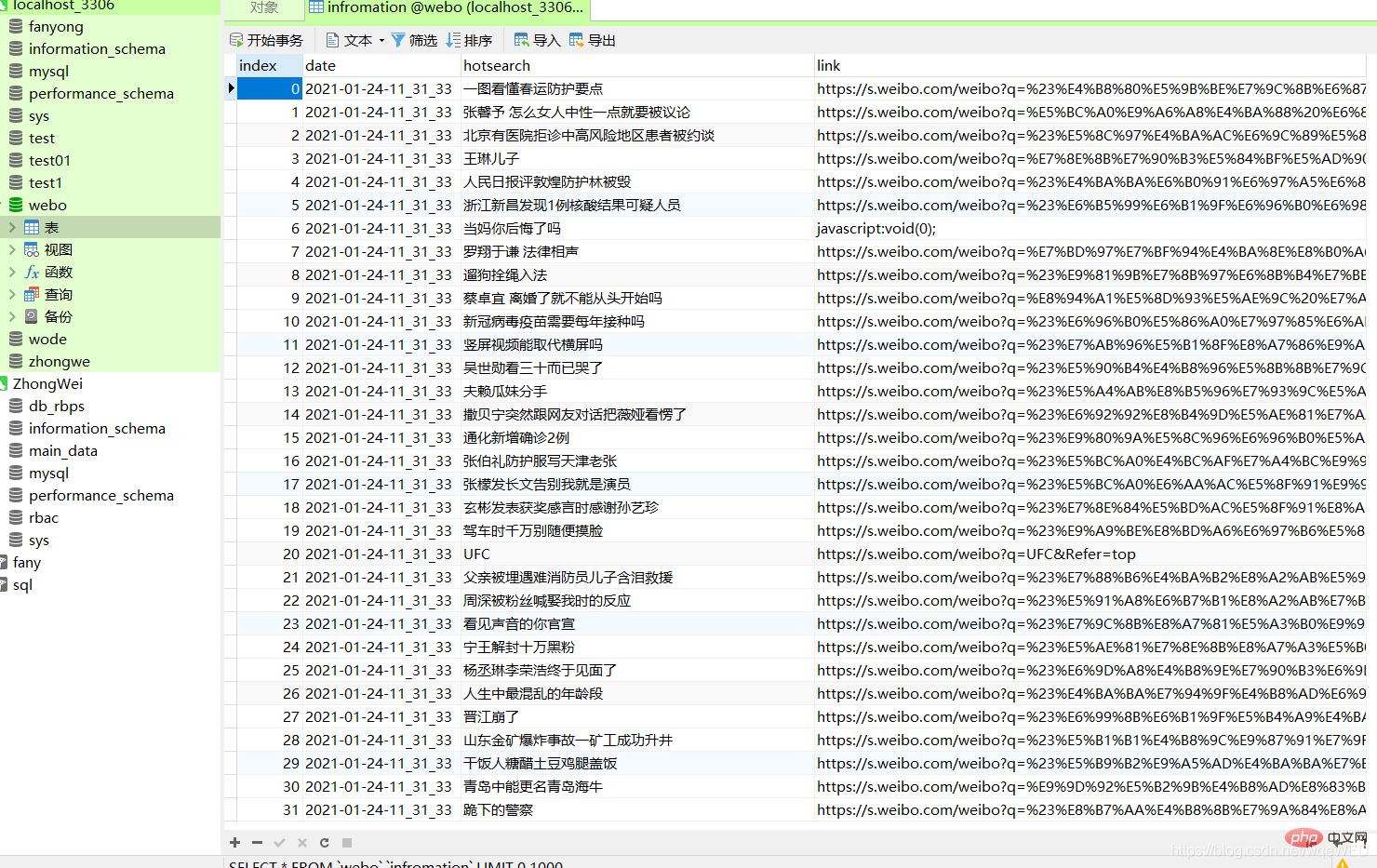
Ici, vous pouvez clairement voir que la base de données contient la date, le contenu et le lien du site Web
Analysons comment la mettre en œuvre
Bibliothèque utilisée
import requests from selenium.webdriver import Chrome, ChromeOptions import time from sqlalchemy import create_engine import pandas as pd
Analyse cible
Ceci est un lien très recherché sur Weibo : Cliquez sur moi pour accéder à la page Web cible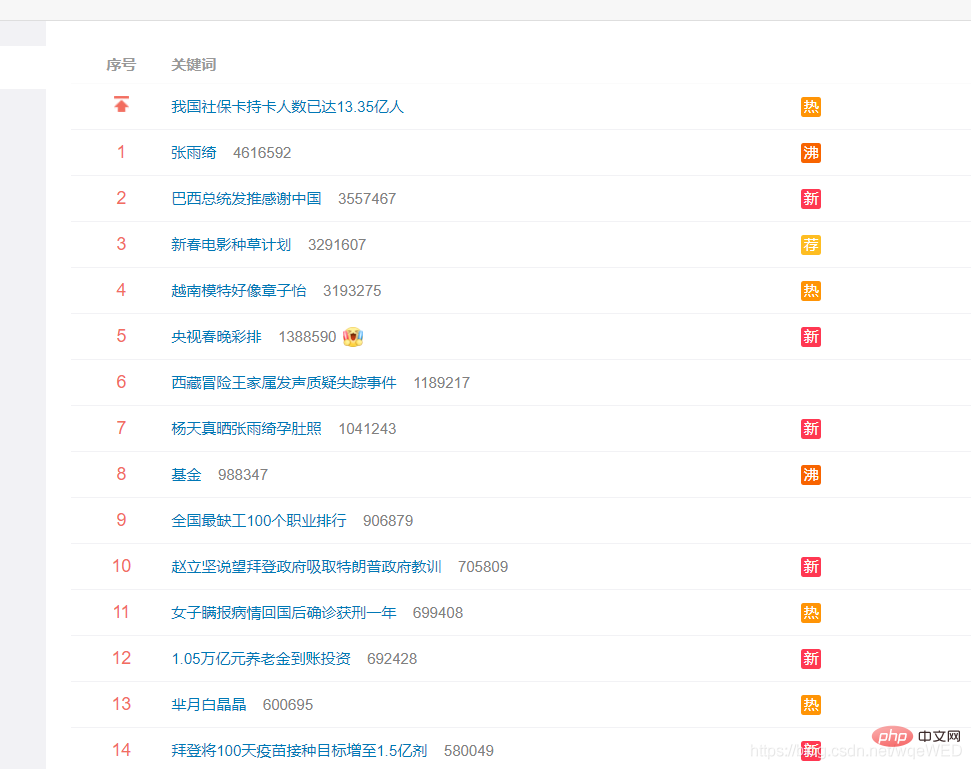
Nous utilisons d'abord Selenium pour demander la page Web cible
Ensuite, nous utilisons XPath pour localiser les éléments de la page Web et les parcourir pour obtenir toutes les données
Ensuite, nous utilisons des pandas pour générer un objet Dataframe et le stocker directement dans le base de données
1 : Obtenir des données
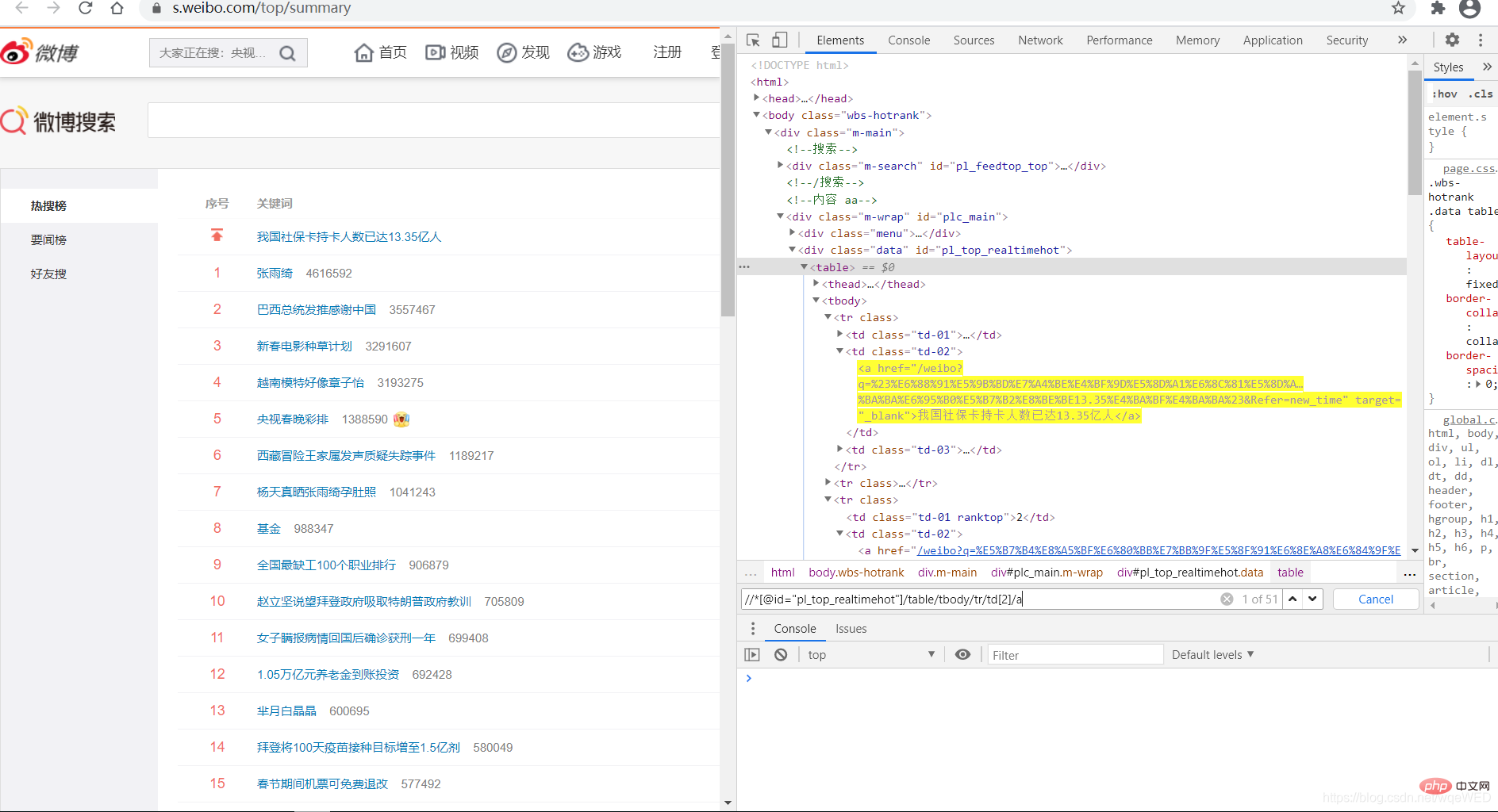
Nous voyons qu'en utilisant XPath, nous pouvons obtenir 51 éléments de données, qui sont les recherches chaudes, à partir desquelles nous pouvons obtenir les liens et le contenu du titre
all = browser.find_elements_by_xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr/td[2]/a') #得到所有数据
context = [i.text for i in c] # 得到标题内容
links = [i.get_attribute('href') for i in c] # 得到link Ensuite, nous utilisons la fonction zip pour fusionner la date, le contexte et les liens
La fonction zip combine plusieurs listes en une seule liste et divise les données de la liste en fonction de l'index pour fusionner en un tuple, cela peut produire des objets pandas.
dc = zip(dates, context, links) pdf = pd.DataFrame(dc, columns=['date', 'hotsearch', 'link'])
La date peut être obtenue à l'aide du module heure
2 : Lier la base de données
C'est facile
enging = create_engine("mysql+pymysql://root:123456@localhost:3306/webo?charset=utf8")
pdf.to_sql(name='infromation', con=enging, if_exists="append")Total Code
from selenium.webdriver import Chrome, ChromeOptions
import time
from sqlalchemy import create_engine
import pandas as pd
def get_data():
url = r"https://s.weibo.com/top/summary" # 微博的地址
option = ChromeOptions()
option.add_argument('--headless')
option.add_argument("--no-sandbox")
browser = Chrome(options=option)
browser.get(url)
all = browser.find_elements_by_xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr/td[2]/a')
context = [i.text for i in all]
links = [i.get_attribute('href') for i in all]
date = time.strftime("%Y-%m-%d-%H_%M_%S", time.localtime())
dates = []
for i in range(len(context)):
dates.append(date)
# print(len(dates),len(context),dates,context)
dc = zip(dates, context, links)
pdf = pd.DataFrame(dc, columns=['date', 'hotsearch', 'link'])
# pdf.to_sql(name=in, con=enging, if_exists="append")
return pdf
def w_mysql(pdf):
try:
enging = create_engine("mysql+pymysql://root:123456@localhost:3306/webo?charset=utf8")
pdf.to_sql(name='infromation', con=enging, if_exists="append")
except:
print('出错了')
if __name__ == '__main__':
xx = get_data()
w_mysql(xx) J'espère que cela pourra vous aider un peu, et permettre à tous de progresser et de grandir ensemble !
Bonne année à tous ! ! !
Recommandations d'apprentissage gratuites associées : Tutoriel Python(vidéo)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!


















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



