


Recommandations d'apprentissage gratuites : base de données mysql(vidéo )
Contexte
La table commerciale de la base de données Alibaba Cloud RDS FOR MySQL (MySQL version 5.7) contient plus de 10 millions de nouvelles données ajoutées chaque mois. À mesure que la quantité de données continue d'augmenter, des requêtes lentes sur de grandes tables se produisent dans notre entreprise. Pendant les périodes de pointe, les requêtes lentes sur la table commerciale principale prennent des dizaines de secondes, ce qui affecte sérieusement l'activité
Présentation. de la solution
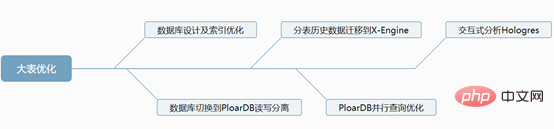
1. Conception de la base de données et optimisation de l'index
La base de données MySQL elle-même est très flexible, ce qui entraîne performances insuffisantes et forte dépendance aux capacités de conception de table et d'indexation des développeurs, voici quelques suggestions d'optimisation
Comme son nom l'indique, il s'agit de la priorité la plus à gauche lors de la création d'un index combiné, elle doit être utilisée dans la clause Where en fonction des besoins de l'entreprise. est placé à l'extrême gauche. Un problème très important dans un index composé est de savoir comment organiser l'ordre des colonnes. Par exemple, si les deux champs c1 et c2 sont utilisés après où, alors l'ordre de l'index est (c1, c2) ou (c2, c1). . La bonne approche est de répéter Plus la valeur est petite, plus elle est placée haut. Par exemple, si 95 % des valeurs d'une colonne ne sont pas répétées, alors cette colonne peut généralement être placée au premier plan
2. Basculez la base de données vers la séparation lecture-écriture PloarDB
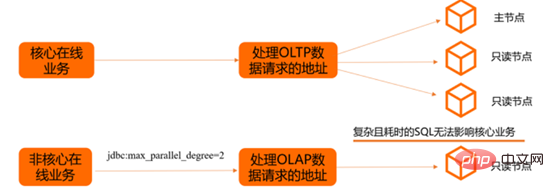
PolarDB est une base de données cloud relationnelle de nouvelle génération auto-développée par Alibaba Cloud. Elle est 100 % compatible avec MySQL Le stockage. la capacité peut atteindre 100 To. Une seule base de données peut être étendue jusqu'à 16 nœuds. Elle convient à divers scénarios d'application de base de données des entreprises. PolarDB adopte une architecture qui sépare le stockage et l'informatique. Tous les nœuds informatiques partagent une copie des données et fournissent des mises à niveau et des rétrogradations de configuration infimes, une récupération après panne de deuxième niveau, une cohérence globale des données et des services gratuits de sauvegarde des données et de reprise après sinistre.
Dans des scénarios mixtes hors ligne : différents services utilisent différentes adresses de connexion et différents nœuds de données pour éviter une influence mutuelle
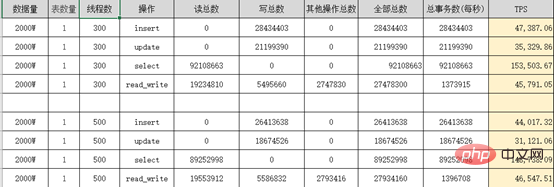
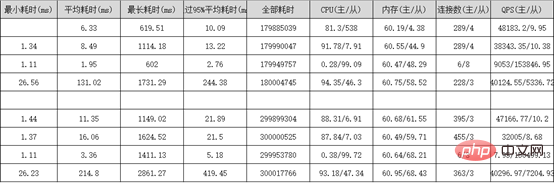
Rapport de test de résistance de performances Sysbench :
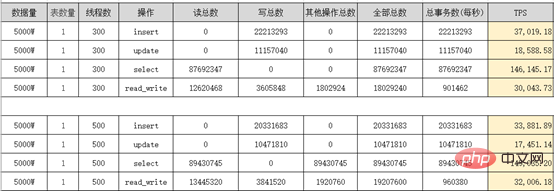
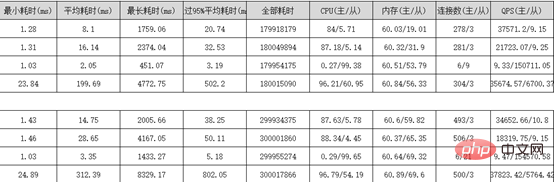
3. Migrer les données historiques des sous-tables vers le moteur de stockage MySQL8.0 X-Engine
La table commerciale divisée conserve 3 mois de données (cela est basé sur les besoins de l'entreprise) et les données historiques sont divisées en tables de moteur de stockage X-Engine de la base de données historique sur une base mensuelle. Pourquoi devrions-nous choisir les tables du moteur de stockage X-Engine. ? Quels sont ses avantages ?
X-Engine est un traitement de transactions en ligne (OLTP) auto-développé par Alibaba Cloud Database Product Division Processing) moteur de stockage de base de données.
Le moteur de stockage X-Engine est non seulement parfaitement compatible avec MySQL (grâce à la fonctionnalité MySQL Pluginable Storage Engine), mais X-Engine utilise également une architecture de stockage en couches. Étant donné que l'objectif est de stocker des données massives à grande échelle, de fournir des capacités élevées de traitement des transactions simultanées et de réduire les coûts de stockage, dans la plupart des scénarios de volumes de données importants, les opportunités d'accès aux données sont inégales et les données chaudes fréquemment consultées représentent en réalité Très rarement, X-Engine divise les données en plusieurs niveaux en fonction de la fréquence d'accès aux données. Selon les caractéristiques d'accès de chaque niveau de données, il conçoit la structure de stockage correspondante et l'écrit sur le périphérique de stockage approprié
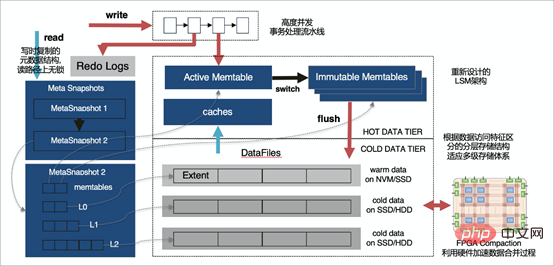
4. Requête parallèle d'Alibaba Cloud PloarDB MySQL8.0 version
Après avoir divisé les tables, notre volume de données est toujours très grand, cela ne résout pas complètement notre problème de requêtes lentes, mais réduit seulement la taille de nos tables métier. Pour ces requêtes lentes, nous devons utiliser l'optimisation des requêtes parallèles de PolarDB PolarDB MySQL 8.0 lance le. cadre de requêtes parallèles, lorsque la quantité de données de votre requête atteint un certain seuil, le cadre de requêtes parallèles sera automatiquement démarré, réduisant ainsi de manière exponentielle le temps de requête La couche de stockage fragmentera les données en différents threads et plusieurs threads fonctionneront calculs parallèles. Les résultats du pipeline sont résumés dans le thread principal, et enfin le thread principal effectue une simple fusion et la renvoie à l'utilisateur pour améliorer l'efficacité des requêtes.
Parallel Query utilise les capacités de traitement parallèle des processeurs multicœurs. En prenant comme exemple la configuration à 8 cœurs de 32 Go, le diagramme schématique est le suivant.
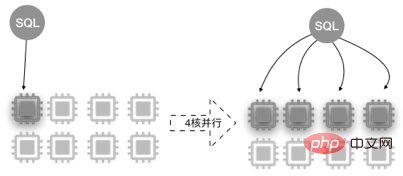
+PARALLEL(x)/ … FROM …; – x >0
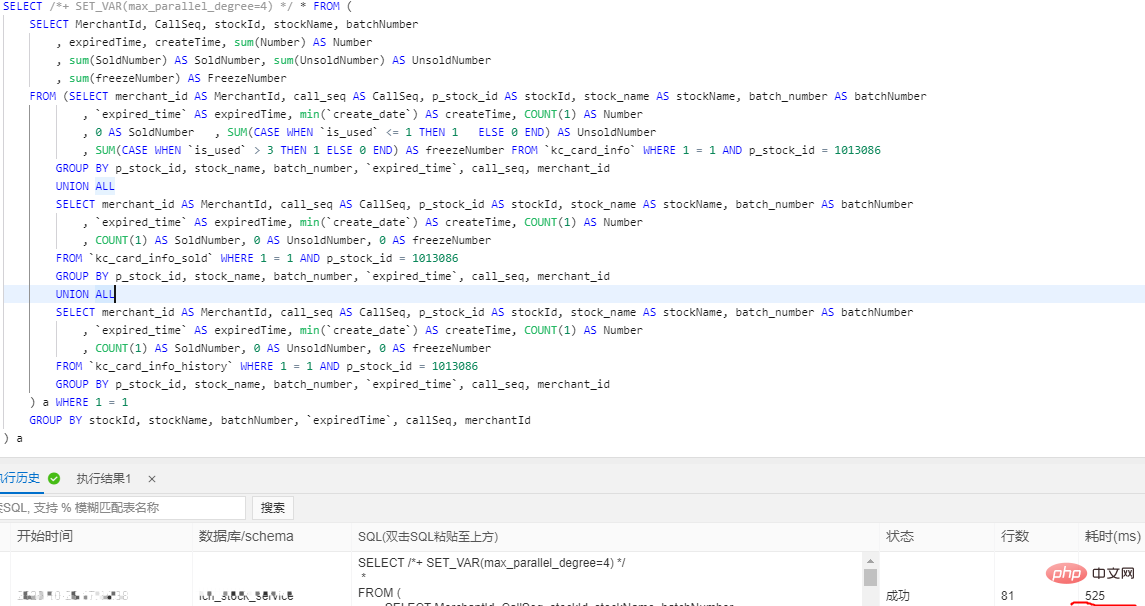
SELECT /*+ SET_VAR(max_parallel_degree=n) */ * FROM … // n > 0Test de requête : configuration de la base de données 16 cœurs 32G, le volume de données d'une seule table dépasse 30 millionsC'était 4326 ms avant l'ajout de la requête parallèle, et 525 ms après l'ajout l'optimisation des requêtes parallèles 8,24X a amélioré l'efficacité, mais nous ne pouvons toujours pas répondre à certaines exigences spécifiques en matière de rapports en temps réel et de grands écrans en temps réel, et ne pouvons compter que sur le Big Data pour le traitement.Nous recommandons ici l'analyse interactive Holologre d'Alibaba Cloud (
https://help.aliyun.com/product/113622.html)
L'optimisation de dizaines de millions de grandes tables est basée sur des scénarios commerciaux et au prix d'un coût. Il ne s'agit pas dès le départ de diviser et d'étendre horizontalement la base de données, ce qui entraînera des problèmes. pour l'exploitation, la maintenance et les affaires. Dans de nombreux cas, les résultats peuvent ne pas être bons. Que nos stratégies de conception de bases de données, d'optimisation d'index et de partitionnement de tables soient en place, nous devons choisir la technologie appropriée pour les mettre en œuvre en fonction de l'activité. besoins.
Plus de recommandations d'apprentissage gratuites associées : tutoriel MySQL(vidéo)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié









![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



