
 cadre php
PensezPHP
Opérations de base de données ThinkPHP, procédures stockées, ensembles de données, bases de données distribuées
cadre php
PensezPHP
Opérations de base de données ThinkPHP, procédures stockées, ensembles de données, bases de données distribuées
Opérations de base de données ThinkPHP, procédures stockées, ensembles de données, bases de données distribuées

La colonne tutorielle suivante de thinkphp vous présentera les procédures stockées, les ensembles de données et les bases de données distribuées des opérations de base de données ThinkPHP. J'espère qu'elle sera utile aux amis dans le besoin. !

Procédure stockée
5.0 prend en charge les procédures stockées si nous définissons une base de données La procédure stockée sp_query peut être appelée de la manière suivante :
$result = Db::query('call sp_query(8)');renvoie un tableau à deux dimensions, et la liaison de paramètres peut également être utilisée, par exemple :
$result = Db::query('call sp_query(?)',[8]);
// 或者命名绑定$result = Db::query('call sp_query(:id)',['id'=>8]);Ensemble de données
Le résultat de la requête de la base de données est également l'ensemble de données. Dans la configuration par défaut, le type de l'ensemble de données est un tableau bidimensionnel. configurez-le dans une classe d'ensemble de données, vous pouvez prendre en charge davantage d'opérations basées sur des objets sur l'ensemble de données. Vous devez utiliser la fonction de classe d'ensemble de données. Vous pouvez configurer le paramètre resultsset_type de la base de données comme suit :
return [ // 数据库类型 'type' => 'mysql', // 数据库连接DSN配置 'dsn' => '', // 服务器地址 'hostname' => '127.0.0.1', // 数据库名 'database' => 'thinkphp', // 数据库用户名 'username' => 'root', // 数据库密码 'password' => '', // 数据库连接端口 'hostport' => '', // 数据库连接参数 'params' => [], // 数据库编码默认采用utf8 'charset' => 'utf8', // 数据库表前缀 'prefix' => 'think_', // 数据集返回类型 'resultset_type' => 'collection',];
// 获取数据集
$users = Db::name('user')->select();
// 直接操作第一个元素
$item = $users[0];
// 获取数据集记录数
$count = count($users);
// 遍历数据集
foreach($users as $user){ echo $user['name']; echo $user['id'];
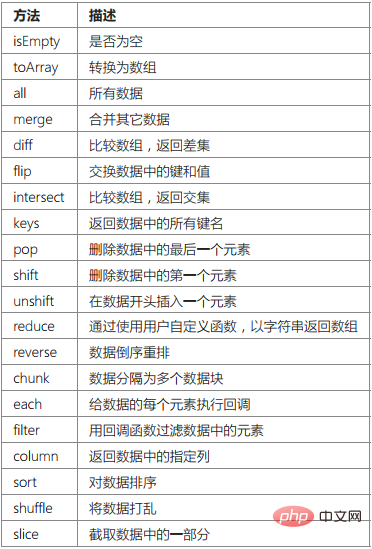
}Il convient de noter que si vous souhaitez juger si l'ensemble de données est vide, vous ne pouvez pas utiliser directement vide pour juger , mais vous devez utiliser le jugement de la méthode isEmpty de l'objet ensemble de données, par exemple :
$users = Db::name('user')->select();if($users->isEmpty()){ echo '数据集为空';
}
Db::name('user') ->fetchClass('\think\Collection') ->select();base de données distribuée
ThinkPHP prend en charge les bases de données distribuées, y compris la séparation maître-esclave en lecture et en écriture de la base de données traditionnelle, mais la base de données distribuée doit être du même type de base de données. Configurez database.deploy sur 1 pour utiliser la prise en charge des bases de données distribuées. Si une base de données distribuée est utilisée, la manière de définir les informations de configuration de la base de données est la suivante ://分布式数据库配置定义 return [ // 启用分布式数据库 'deploy' => 1, // 数据库类型 'type' => 'mysql', // 服务器地址 'hostname' => '192.168.1.1,192.168.1.2', // 数据库名 'database' => 'demo', // 数据库用户名 'username' => 'root', // 数据库密码 'password' => '', // 数据库连接端口 'hostport' => '',]
'hostport'=>'3306,3306'
'hostport'=>'3306'
'username'=>'user1', 'password'=>'pwd1',
'username'=>'user1,user1', 'password'=>'pwd1,pwd1',
'rw_separate' => true,
S'il y a une erreur dans la connexion à la base de données esclave, elle passera automatiquement à la connexion à la base de données principale.
Si vous appelez l'opération CURD du modèle, le système déterminera automatiquement si la méthode actuellement exécutée est une opération de lecture ou une opération d'écriture. Si vous utilisez du SQL natif, vous devez faire attention. aux règles par défaut du système :L'opération d'écriture doit utiliser la méthode d'exécution du modèle et l'opération de lecture doit utiliser la méthode de requête du modèle , sinon un chaos de lecture et d'écriture maître-esclave se produira.
Remarque : Le travail de synchronisation des données de la base de données maître-esclave n'est pas implémenté dans le framework et la base de données doit prendre en compte son propre mécanisme de synchronisation ou de réplication.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment exécuter le projet thinkphp
Apr 09, 2024 pm 05:33 PM
Comment exécuter le projet thinkphp
Apr 09, 2024 pm 05:33 PM
Pour exécuter le projet ThinkPHP, vous devez : installer Composer ; utiliser Composer pour créer le projet ; entrer dans le répertoire du projet et exécuter php bin/console serve ; visiter http://localhost:8000 pour afficher la page d'accueil.
 Il existe plusieurs versions de thinkphp
Apr 09, 2024 pm 06:09 PM
Il existe plusieurs versions de thinkphp
Apr 09, 2024 pm 06:09 PM
ThinkPHP dispose de plusieurs versions conçues pour différentes versions de PHP. Les versions majeures incluent 3.2, 5.0, 5.1 et 6.0, tandis que les versions mineures sont utilisées pour corriger les bogues et fournir de nouvelles fonctionnalités. La dernière version stable est ThinkPHP 6.0.16. Lorsque vous choisissez une version, tenez compte de la version PHP, des exigences en matière de fonctionnalités et du support de la communauté. Il est recommandé d'utiliser la dernière version stable pour de meilleures performances et une meilleure assistance.
 Comment exécuter thinkphp
Apr 09, 2024 pm 05:39 PM
Comment exécuter thinkphp
Apr 09, 2024 pm 05:39 PM
Étapes pour exécuter ThinkPHP Framework localement : Téléchargez et décompressez ThinkPHP Framework dans un répertoire local. Créez un hôte virtuel (facultatif) pointant vers le répertoire racine ThinkPHP. Configurez les paramètres de connexion à la base de données. Démarrez le serveur Web. Initialisez l'application ThinkPHP. Accédez à l'URL de l'application ThinkPHP et exécutez-la.
 Lequel est le meilleur, Laravel ou thinkphp ?
Apr 09, 2024 pm 03:18 PM
Lequel est le meilleur, Laravel ou thinkphp ?
Apr 09, 2024 pm 03:18 PM
Comparaison des performances des frameworks Laravel et ThinkPHP : ThinkPHP fonctionne généralement mieux que Laravel, en se concentrant sur l'optimisation et la mise en cache. Laravel fonctionne bien, mais pour les applications complexes, ThinkPHP peut être mieux adapté.
 Suggestions de développement : Comment utiliser le framework ThinkPHP pour implémenter des tâches asynchrones
Nov 22, 2023 pm 12:01 PM
Suggestions de développement : Comment utiliser le framework ThinkPHP pour implémenter des tâches asynchrones
Nov 22, 2023 pm 12:01 PM
"Suggestions de développement : comment utiliser le framework ThinkPHP pour implémenter des tâches asynchrones" Avec le développement rapide de la technologie Internet, les applications Web ont des exigences de plus en plus élevées pour gérer un grand nombre de requêtes simultanées et une logique métier complexe. Afin d'améliorer les performances du système et l'expérience utilisateur, les développeurs envisagent souvent d'utiliser des tâches asynchrones pour effectuer certaines opérations chronophages, telles que l'envoi d'e-mails, le traitement des téléchargements de fichiers, la génération de rapports, etc. Dans le domaine de PHP, le framework ThinkPHP, en tant que framework de développement populaire, offre des moyens pratiques d'implémenter des tâches asynchrones.
 Comment installer thinkphp
Apr 09, 2024 pm 05:42 PM
Comment installer thinkphp
Apr 09, 2024 pm 05:42 PM
Étapes d'installation de ThinkPHP : Préparez les environnements PHP, Composer et MySQL. Créez des projets à l'aide de Composer. Installez le framework ThinkPHP et ses dépendances. Configurez la connexion à la base de données. Générez le code de l'application. Lancez l'application et visitez http://localhost:8000.
 Quelles sont les performances de thinkphp ?
Apr 09, 2024 pm 05:24 PM
Quelles sont les performances de thinkphp ?
Apr 09, 2024 pm 05:24 PM
ThinkPHP est un framework PHP hautes performances présentant des avantages tels que le mécanisme de mise en cache, l'optimisation du code, le traitement parallèle et l'optimisation des bases de données. Les tests de performances officiels montrent qu'il peut gérer plus de 10 000 requêtes par seconde et qu'il est largement utilisé dans les sites Web à grande échelle et les systèmes d'entreprise tels que JD.com et Ctrip dans les applications réelles.
 Service RPC basé sur ThinkPHP6 et Swoole pour implémenter la fonction de transfert de fichiers
Oct 12, 2023 pm 12:06 PM
Service RPC basé sur ThinkPHP6 et Swoole pour implémenter la fonction de transfert de fichiers
Oct 12, 2023 pm 12:06 PM
Le service RPC basé sur ThinkPHP6 et Swoole implémente la fonction de transfert de fichiers Introduction : Avec le développement d'Internet, le transfert de fichiers est devenu de plus en plus important dans notre travail quotidien. Afin d'améliorer l'efficacité et la sécurité du transfert de fichiers, cet article présentera la méthode d'implémentation spécifique de la fonction de transfert de fichiers basée sur le service RPC basé sur ThinkPHP6 et Swoole. Nous utiliserons ThinkPHP6 comme framework Web et utiliserons la fonction RPC de Swoole pour réaliser le transfert de fichiers entre serveurs. 1. Norme environnementale
