


Recommandations d'apprentissage gratuites : tutoriel vidéo mysql
Répertoire
bibliothèque
MySQL une bibliothèque par défaut
information_schema : bibliothèque virtuelle, qui n'occupe pas d'espace disque. Elle stocke certains paramètres après le démarrage de la base de données, tels que les informations sur la table utilisateur, les informations sur les colonnes, les informations sur les autorisations, les informations sur les caractères, etc. .
performance_schema : MySQL 5.5 a ajouté une nouvelle base de données : principalement utilisée pour collecter les paramètres de performances du serveur de base de données et enregistrer divers événements, verrous et autres phénomènes qui se produisent lors du traitement des requêtes de requête
mysql : bibliothèque d'autorisations, stockant principalement les autorisations des utilisateurs du système. informations
test : Base de données de test créée automatiquement par le système de base de données MySQL
ps : Certains MySQL peuvent ne pas avoir de bibliothèque de test, comme la 8.0 de l'auteur, qui est utilisée pour sys à la place de la bibliothèque de tests
Inutile de dire, créez une base de données (mentionnée dans l'article précédent). Comprenons les règles de dénomination lors de la création d'une base de données :
peut être composé. de lettres, chiffres, traits de soulignement, @, #, $
Sensible à la casse
Unicité
Impossible d'utiliser des mots-clés tels que create select
Impossible d'utiliser des chiffres seuls
Jusqu'à 128 caractères
Généralement, les noms sont des lettres, des chiffres. Il est recommandé de ne pas utiliser de traits de soulignement, comme le @#$ ci-dessus. Si nous connectons ultérieurement la bibliothèque via du code, les symboles à l'intérieur peuvent entrer en conflit avec la syntaxe du code.
Opérations détaillées de la table
Conditions de contraintes pour la création de la table (les détails sont laissés au chapitre suivant)
create table student( id int not null, name varchar(10) not null # 最后一个字段不能使用逗号);
L'opération ci-dessus indique que lors de l'insertion de valeurs dans les champs id et name de la table student, il est contraint qu'elles ne puissent pas être nulles
insert student values(null,'jack');
Un message d'erreur est généré : ERREUR 1048 (23000 ): La colonne 'id' ne peut pas être nulle
Dites-nous que l'id ne peut pas être vide
Opérations supplémentaires pour changer la table
Les conditions de contrainte sont facultatif, en fonction de vos propres besoins pour la table.
Modifier le nom de la table
alter table 表名 rename 新表名;
Ajouter un champ
alter table 表名 add 字段名 数据类型 约束条件(根据需求添加);# 添加多个字段alter table 表名 add 字段名1 数据类型,add 字段名2 数据类型;# 在开头增加字段alter table 表名 add 字段 数据类型 first;# 在某个字段后面增加字段alter table 表名 add 字段 数据类型 after 字段;
Supprimer le champ
alter table 表名 drop 字段
Modifier le champ
# 修改字段的类型或者约束条件alter table 表名 modify 新的数据类型 新的约束条件;# 修改整个字段alter table 表名 change 旧字段名 新字段名 新字段数据类型;# 修改字段名alter table 表名 rename column 原字段名 to 新字段名;
Copier la table
Lorsque nous interrogeons la table via select, ce qui nous est présenté est : Table virtuelle, c'est-à-dire que le contenu qui existe dans la mémoire ne peut pas être enregistré. Nous pouvons obtenir ce que nous voulons en copiant les données de la table<.>
Créer une démonstration de tableinsert student values(1,'jack'),(2,'tom'),(3,'jams'),(4,'rous');

create table new_studnet select * from student where id > 2;
 Ou nous voulons simplement copier la structure des données de la table, à l'exception des enregistrements (données), toutes les autres informations
Ou nous voulons simplement copier la structure des données de la table, à l'exception des enregistrements (données), toutes les autres informations
create table new_student2 select * from student where 0 > 1;

Type de données
1. Type entier : TINYINT SMALLINT MEDIUMINT INT BIGINT
Fonction : stocker l'âge, le niveau, l'identifiant, divers numéros, etc.Différents types d'entiers stockent différentes plages numériques.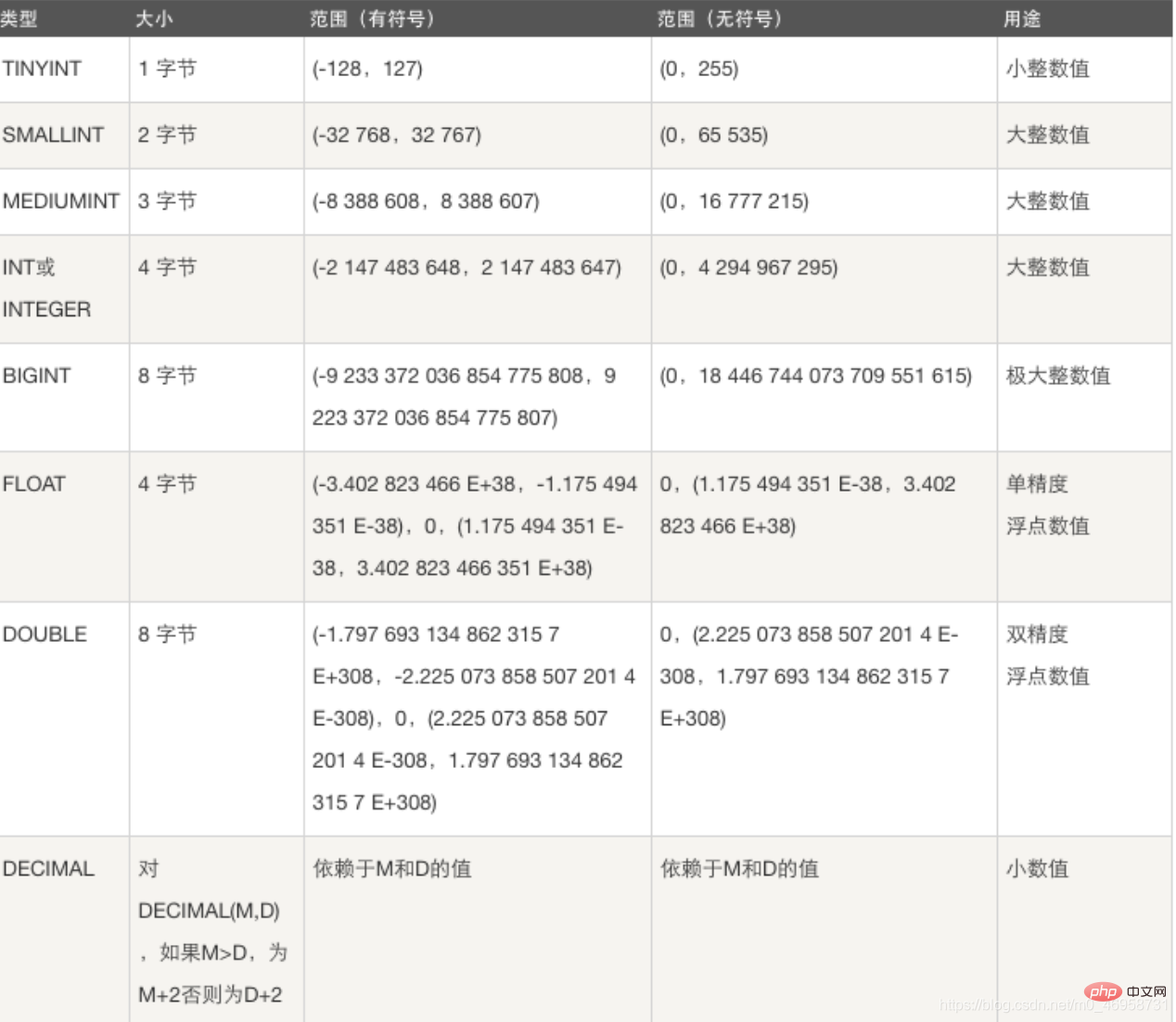 Par exemple : lorsque l'on choisit le type int pour créer un champ, la table occupera 4 octets supplémentaires. Nous devons choisir le type entier en fonction de la plage de valeurs que nous stockons, ce qui peut économiser de l'espace.
Par exemple : lorsque l'on choisit le type int pour créer un champ, la table occupera 4 octets supplémentaires. Nous devons choisir le type entier en fonction de la plage de valeurs que nous stockons, ce qui peut économiser de l'espace.
2. Types à virgule flottante : float, double, décimal (peut être écrit en déc)
Fonction : stocker le salaire, la taille, le poids, les paramètres physiques, etc.float(255,30) : les entiers peuvent prendre en charge jusqu'à 255 chiffres et prendre en charge les décimales jusqu'à 30 chiffresAlors, quelle est la différence entre ces trois types à virgule flottante ? La réponse est : PrécisionExemple : Créer 3 tableaux de types à virgule flottante différentsdouble(255,30) : les entiers peuvent prendre en charge jusqu'à 255 et prendre en charge 30 Décimales inférieures à 60 chiffres
dec(65,30) : les nombres entiers peuvent être pris en charge dans la plage de 60, et les décimales inférieures à 30 chiffres sont prises en charge
Nombres à virgule flottante simple précision (valeurs décimales non précises), m est le nombre total de nombres, d est le nombre après la virgule. La valeur maximale de m est 255 et la valeur maximale de d est 30
create table f1(id float(255,30));create table f2(id double(255,30));create table f3(id dec(66,30));
insert f1 values(1.1111111111111111111111111111111); # 小数点后31个1insert f2 values(1.1111111111111111111111111111111);insert f3 values(1.1111111111111111111111111111111);
 décaimal peut Le La raison du stockage des valeurs exactes est qu'elles sont stockées en interne sous forme de chaînes.
décaimal peut Le La raison du stockage des valeurs exactes est qu'elles sont stockées en interne sous forme de chaînes.
3、日期类型:DATE TIME DATETIME TIMESTAMP YEAR
作用:存储用户注册时间,文章发布时间,员工入职时间,出生时间,过期时间等
在我们创建表字段时,可以指定某个字段传入的日期是什么,以下可选:
date # 1000-01-01/9999-12-31time # -838:59:59/838:59:59year # 支持1901/2155datetime # 日期时间 1000-01-01 00:00:00/9999-12-31 23:59:59timestamp # 日期时间 1970-01-01 00:00:00/2037 某时
实例:创建表
create table info( id int, name varchar(10), birth date, class_time time, reg_time datetime, born_year year);
插入记录
nsert info values( 1, 'jack', '1999-01-01', '08:30:00', '2020-01-01 10:15:00', '1999');

MySQL提供的两种日期时间都可以提供给我们使用,那它们之间的区别在哪里呢
datetime与timestamp的区别
首先占用空间:datetime占用8字节大小,timestamp占用4字节大小
在5.x以上版本,改动表后使用timestamp可以自动给我们填上当前系统时间,笔者的8.0不能自动填上系统时间,和datietime呈现的效果一样了,只是上限的时间不同。我们如果要达到这个效果,可以创建时补充如下参数
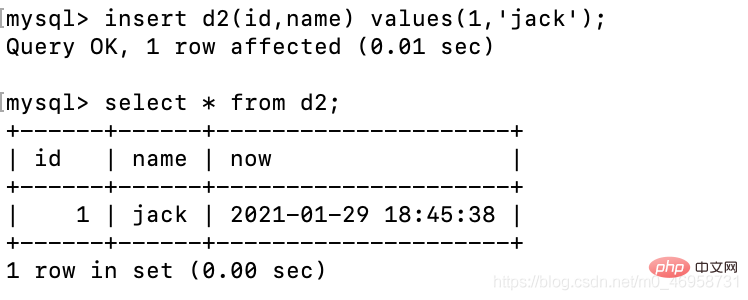
create table d2( id int, name varchar(10), now timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP);
我们添加数据时,可以根据前两个来字段添加,最后一个让它自动补充。
# insert d2 values(1,'jack'); 错误写法,因为这个必须要给所有字段设置值insert d2(id,name) values(1,'jack'); # 正确写法
4、字符串类型:char、varchar
char:简单粗暴,浪费空间,存取速度快
字符长度范围:0-255(一个中文是一个字符,是utf8编码的3个字节)
存储char类型的值时,会往右填充空格来满足长度
在检索或者说查询时,查出的结果会自动删除尾部的空格,除非我们打开pad_char_to_full_length SQL模式(SET sql_mode = ‘PAD_CHAR_TO_FULL_LENGTH’;)
varchar类型:变长,精准,节省空间,存取速度慢
| char(4) | Storage Required | varchar(4) | Storage Required |
|---|---|---|---|
| ’ ’ | 4字节 | ‘’ | 1字节 |
| 'ab ’ | 4字节 | ‘ab’ | 2字节 |
| ‘abcd’ | 4字节 | ‘abcd’ | 5字节 |
| ‘abcdef’ | 报错 | ‘abcde’ | 报错 |
区分介绍:
char类型定长,不管存多少数据,如果未达到指定长度,则空格补充
varchar类型变长:因为取的时候,不知道varchar类型取了多少个数据,所以默认会在开头放入1个字节的头部。(底层存储机制,只要我们自身输入的内容没有超过定义的长度就不会报错)
char一定比varchar更浪费空间?
如果存储内容相同长度的情况下,varchar占用大小会大于char
但是我们平常还是常使用varchar,因为我们存储内容时,无法确定内容的大小,所以通常使用varchar,也就多占那么1-2个字节,而char的话,则占用更多的大小。
注意:
如果存储的内容是网页或网络上的某一篇文章,建议不要把文字全部保存到数据库,直接将链接放上去保存即可。
严格模式下的MySQL,如果存储内容超过了字符串类型定义的长度,那么则会报错,而非严格模式下的MySQL,则是不保存超出的内容,并发出警告信息。
查看字符的个数
create table c1(x char(10));create table c2(x varchar(10));select char_length(x) as "内容长度" from c1;select char_length(x) as "内容长度" from c2;

很奇怪的就是,char类型并没有占用10个字节,是因为MySQL帮我们隐藏了,只呈现给我们自身存储的内容,调整一下就可以让它显出原形。
set sql_mode = 'PAD_CHAR_TO_FULL_LENGTH';
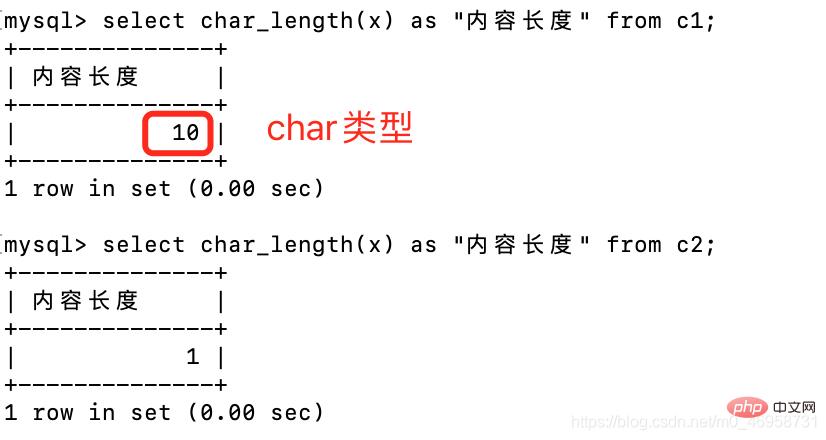
查询时候的问题
很明显,这两个类型虽然内容一样,但是char占用字符更长
枚举与集合
通过enum函数与set函数,在创建表时,定义某个字段在插入值时,值的内容是否匹配。
create table test(
id int,
name varchar(10),
gender enum('男','女','未知'),
hobbies set('game','music','book','movie'));enum:在向gender这个字段插入值时,只能输入其中一的值
set:在向hobbies这个字段插入值时,可以输入其中多个值,通过逗号隔开
insert test values(1,'jack','男','game,book');

如果我们输入的内容,与函数内定义的不符,非严格模式发出警告信息,严格模式直接报错

笔者的MySQL为严格模式(利于开发)
select @@sql_mode; # 查看当前模式
存储引擎(了解即可)
首先确定一点,存储引擎的概念是MySQL里面才有的,不是所有的关系型数据库都有存储引擎这个概念。
数据库中的表也应该有不同的类型,表的类型不同,会对应mysql不同的存取机制,表类型又称为存储引擎。
show engines; # 查看MySQL内的存储引擎

但是我们创建表时并没有指定存储引擎呐。
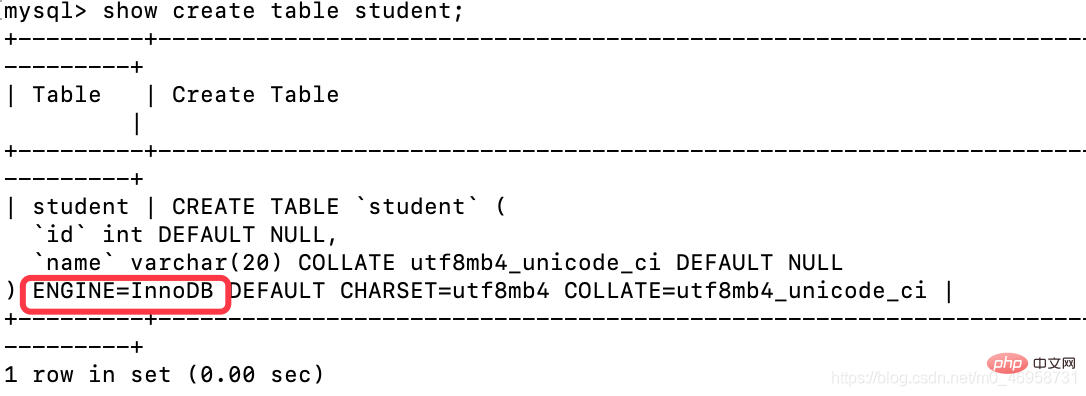
因为MySQL默认的是:InnoDB
查询表的存储引擎
show create table student;
从上至下查看: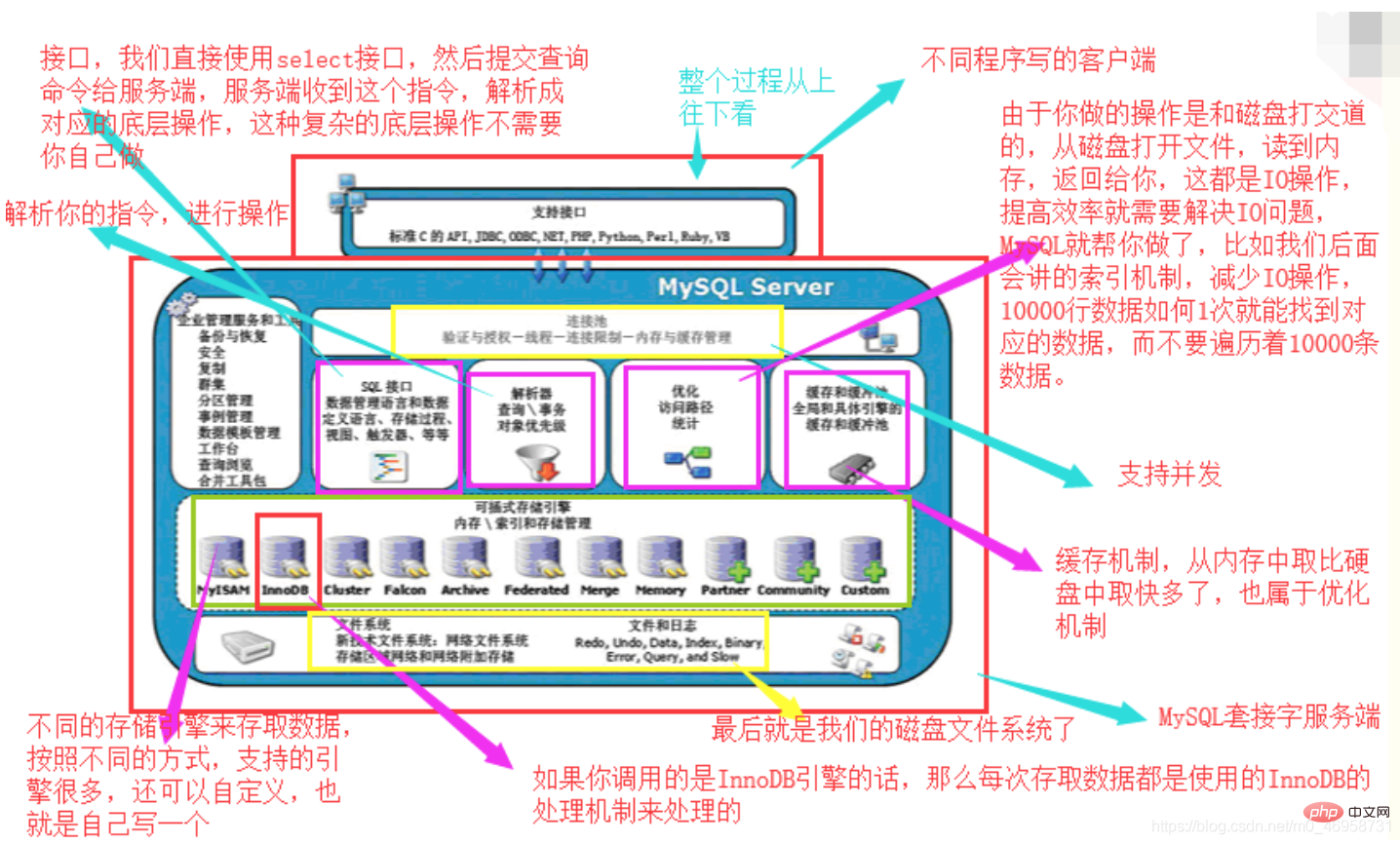
图片来源:秋月
MySQL架构总共四层,在上图中以虚线作为划分。
1、首先,最上层的服务并不是MySQL独有的,大多数给予网络的客户端/服务器的工具或者服务都有类似的架构。比如:连接处理、授权认证、安全等。
2、第二层的架构包括大多数的MySQL的核心服务。包括:查询解析、分析、优化、缓存以及所有的内置函数(例如:日期、时间、数学和加密函数)。同时,所有的跨存储引擎的功能都在这一层实现:存储过程、触发器、视图等。
3、第三层包含了存储引擎。存储引擎负责MySQL中数据的存储和提取。服务器通过API和存储引擎进行通信。这些接口屏蔽了不同存储引擎之间的差异,使得这些差异对上层的查询过程透明化。存储引擎API包含十几个底层函数,用于执行“开始一个事务”等操作。但存储引擎一般不会去解析SQL(InnoDB会解析外键定义,因为其本身没有实现该功能),不同存储引擎之间也不会相互通信,而只是简单的响应上层的服务器请求。
4、第四层包含了文件系统,所有的表结构和数据以及用户操作的日志最终还是以文件的形式存储在硬盘上。
MySQL存储引擎介绍:
InnoDB 存储引擎 支持事务,其设计目标主要面向联机事务处理(OLTP)的应用。其 特点是行锁设计、支持外键,并支持类似 Oracle 的非锁定读,即默认读取操作不会产生锁。 从 MySQL 5.5.8 版本开始是默认的存储引擎。 InnoDB 存储引擎将数据放在一个逻辑的表空间中,这个表空间就像黑盒一样由 InnoDB 存储引擎自身来管理。从 MySQL 4.1(包括 4.1)版本开始,可以将每个 InnoDB 存储引擎的 表单独存放到一个独立的 ibd 文件中。此外,InnoDB 存储引擎支持将裸设备(row disk)用 于建立其表空间。 InnoDB 通过使用多版本并发控制(MVCC)来获得高并发性,并且实现了 SQL 标准 的 4 种隔离级别,默认为 REPEATABLE 级别,同时使用一种称为 netx-key locking 的策略来 避免幻读(phantom)现象的产生。除此之外,InnoDB 存储引擎还提供了插入缓冲(insert buffer)、二次写(double write)、自适应哈希索引(adaptive hash index)、预读(read ahead) 等高性能和高可用的功能。 对于表中数据的存储,InnoDB 存储引擎采用了聚集(clustered)的方式,每张表都是按 主键的顺序进行存储的,如果没有显式地在表定义时指定主键,InnoDB 存储引擎会为每一 行生成一个 6 字节的 ROWID,并以此作为主键。 InnoDB 存储引擎是 MySQL 数据库最为常用的一种引擎,Facebook、Google、Yahoo 等 公司的成功应用已经证明了 InnoDB 存储引擎具备高可用性、高性能以及高可扩展性。对其 底层实现的掌握和理解也需要时间和技术的积累。如果想深入了解 InnoDB 存储引擎的工作 原理、实现和应用,可以参考《MySQL 技术内幕:InnoDB 存储引擎》一书。 MyISAM 存储引擎 不支持事务、表锁设计、支持全文索引,主要面向一些 OLAP 数 据库应用,在 MySQL 5.5.8 版本之前是默认的存储引擎(除 Windows 版本外)。数据库系统 与文件系统一个很大的不同在于对事务的支持,MyISAM 存储引擎是不支持事务的。究其根 本,这也并不难理解。用户在所有的应用中是否都需要事务呢?在数据仓库中,如果没有 ETL 这些操作,只是简单地通过报表查询还需要事务的支持吗?此外,MyISAM 存储引擎的 另一个与众不同的地方是,它的缓冲池只缓存(cache)索引文件,而不缓存数据文件,这与 大多数的数据库都不相同。 NDB 存储引擎 2003 年,MySQL AB 公司从 Sony Ericsson 公司收购了 NDB 存储引擎。 NDB 存储引擎是一个集群存储引擎,类似于 Oracle 的 RAC 集群,不过与 Oracle RAC 的 share everything 结构不同的是,其结构是 share nothing 的集群架构,因此能提供更高级别的 高可用性。NDB 存储引擎的特点是数据全部放在内存中(从 5.1 版本开始,可以将非索引数 据放在磁盘上),因此主键查找(primary key lookups)的速度极快,并且能够在线添加 NDB 数据存储节点(data node)以便线性地提高数据库性能。由此可见,NDB 存储引擎是高可用、 高性能、高可扩展性的数据库集群系统,其面向的也是 OLTP 的数据库应用类型。 Memory 存储引擎 正如其名,Memory 存储引擎中的数据都存放在内存中,数据库重 启或发生崩溃,表中的数据都将消失。它非常适合于存储 OLTP 数据库应用中临时数据的临时表,也可以作为 OLAP 数据库应用中数据仓库的维度表。Memory 存储引擎默认使用哈希 索引,而不是通常熟悉的 B+ 树索引。 Infobright 存储引擎 第三方的存储引擎。其特点是存储是按照列而非行的,因此非常 适合 OLAP 的数据库应用。其官方网站是 http://www.infobright.org/,上面有不少成功的数据 仓库案例可供分析。 NTSE 存储引擎 网易公司开发的面向其内部使用的存储引擎。目前的版本不支持事务, 但提供压缩、行级缓存等特性,不久的将来会实现面向内存的事务支持。 BLACKHOLE 黑洞存储引擎,可以应用于主备复制中的分发主库。
使用指定的存储引擎,两种方式:
1、创建表时指定
create table t2(id int)engine=innodb;
2、修改MySQL配置文件
# /etc/my.cnf [mysqld]default-storage-engine=INNODBinnodb_file_per_table=1
测试部分存储引擎的效果,创建几张表不同存储引擎的表
create table t1(id int)engine=innodb;create table t2(id int)engine=myisam;create table t3(id int)engine=memory;create table t4(id int)engine=blackhole;
注意:笔者安装的MySQL版本在8.0以上
进入MySQL下面data找到对应库下面,查看创建后的表文件类型

1.db.opt文件:用来记录该库的默认字符集编码和字符集排序规则用的。也就是说如果你创建数据库指定默认字符集和排序规则,那么后续创建的表如果没有指定字符集和排序规则,那么该新建的表将采用db.opt文件中指定的属性。
2.后缀名为.frm的文件:这个文件主要是用来描述数据表结构(id,name字段等)和字段长度等信息
3.后缀名为.ibd的文件:这个文件主要储存的是采用独立表储存模式时储存数据库的数据信息和索引信息;
4.后缀名为.MYD(MYData)的文件:从名字可以看出,这个是存储数据库数据信息的文件,主要是存储采用独立表储存模式时存储的数据信息;
5.后缀名为.MYI的文件:这个文件主要储存的是数据库的索引信息;
6.ibdata1文件:主要作用也是储存数据信息和索引信息,这个文件在mysql安装目录的data文件夹下。
从上面可以看出,.ibd储存的是数据信息和索引信息,ibdata1文件也是存储数据信息和索引信息,.MYD和.MYI也是分别储存数据信息和索引信息,那他们之间有什么区别呢?
主要区别是再于数据库的存储引擎不一样,如果储存引擎采用的是MyISAM,则生成的数据文件为表名.frm、表名.MYD、表名的MYI;而储存引擎如果是innoDB,开启了innodb_file_per_table=1,也就是采用独立储存的模式,生成的文件是表名.frm、表名.ibd,如果采用共存储模式的,数据信息和索引信息都存储在ibdata1(在里面进行分类,从外面看是一个文件)中;
在进行数据恢复的时候,如果用的是MYISAM数据引擎,那么数据很好恢复,只要将相应.frm, .MYD, .MYI文件拷贝过去即可。但是如果是innodb的话,则每一个数据表都是一个单独的文件,只将相应的.frm和.ibd文件拷贝过去是不够的,必须在你的ibd文件的tablespace id和ibdata1文件中的元信息的tablespace id一致才可以。
演示向不同存储引擎的表插入数据
insert t1 values(1);insert t2 values(2);insert t3 values(3);insert t4 values(4);
t1:innodb、t2:myisam、t3:memory、t4:blackhole存储引擎
t3的数据是存储在内存中的,t4写入的数据会被丢到,因为是黑洞引擎
我们通过select都能查询到内容,t4怎么查询都是空的,而t3在我们重启MySQL服务后,内容就会被清空,因为它是存入内存中的,重启等于释放掉整个MySQL服务再开启,
相关免费学习推荐:mysql数据库(视频)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Liste de prix du niveau Douyin 1-75
Liste de prix du niveau Douyin 1-75
 Icône Ali
Icône Ali
 Comment utiliser le survol en CSS
Comment utiliser le survol en CSS
 configuration des variables d'environnement python
configuration des variables d'environnement python
 Est-il nécessaire de mettre à niveau Windows 11 ?
Est-il nécessaire de mettre à niveau Windows 11 ?
 Utilisation du mot-clé Type dans Go
Utilisation du mot-clé Type dans Go
 Comment acheter et vendre du Bitcoin sur Binance
Comment acheter et vendre du Bitcoin sur Binance
 Plateforme de trading quantitatif de devises numériques
Plateforme de trading quantitatif de devises numériques









![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



