

Recommandation d'apprentissage gratuite : Tutoriel vidéo MySQL
Table des matières
1. Introduction
2. Refaire le journal
3. binlog
4. 🎜 >Colonne d'apprentissage MySQL
1 Explication détaillée de l'infrastructure MySQL2. L'index MySQL sous-jacent à la structure et à l'algorithme de données
3. et Exemple simple de récupération de données
4. Module de journal MySQL
1 IntroductionMySQL a deux modules de journal importants : redo log (redo log) et
binlog (archive log).redo log : également appelé fichier (redo log), utilisé pour enregistrer les modifications dans les opérations de transaction, ce qui est enregistré estLe redo log est le journal de la couche du moteur de stockage InnoDB, et le binlog est le journal enregistré par la couche MySQL Server. Les deux sont des journaux qui enregistrent certaines opérations, mais les formats des deux enregistrements sont différents.
2. redo log
La valeur après modification des données sera enregistrée, que la transaction soit soumise ou non
.En cas de panne de support, le fichier de journalisation peut s'avérer utile. Si la base de données perd de l'alimentation, le moteur de stockage InnoDB utilisera le fichier de journalisation pour restaurer le moment précédant la panne de courant afin de garantir l'intégrité. des données. Lorsqu'un enregistrement doit être mis à jour, le moteur InnoDB écrira d'abord l'enregistrement dans le journal redo et mettra à jour la mémoire. À ce moment, la mise à jour est terminée.
Le moteur InnoDB mettra à jour cet enregistrement d'opération sur le disque au moment approprié, et cette mise à jour est généralement terminée lorsque le système est relativement inactif pour améliorer l'efficacité de la mise à jour. Cela impliqueWAL
c'est-à-dire Write-Ahead Logging la technologie, sa clé Le fait est d'écrire d'abord le journal, puis d'écrire sur le disque . Le journal redo d'InnoDB a une taille fixe. Par exemple, il peut être configuré comme un ensemble de 4 fichiers, chaque fichier a une taille de 1 Go, donc un total de 4 Go d'opérations peuvent être enregistrés. Le journal redo commencera depuis le début, écrira jusqu'à la fin, puis reviendra au début pour écrire en boucle, comme le montre la figure ci-dessous.
write pos est la position de l'enregistrement actuel Il recule lors de l'écriture. Après avoir écrit jusqu'à la fin du fichier n°3, il revient. au début du dossier n°0. . 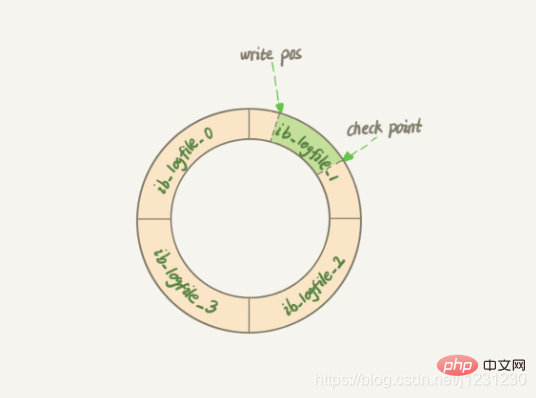
point de contrôle est la position actuelle à effacer, qui recule également et circule. Avant d'effacer l'enregistrement, l'enregistrement doit être mis à jour dans le fichier de données. La zone entre
write pos et check point
est la partie inutilisée et peut être utilisée pour enregistrer de nouvelles opérations.Si write pos rattrape le point de contrôle
, cela signifie que l'enregistrement du journal de rétablissement est plein. À ce stade, aucune nouvelle mise à jour ne peut être effectuée. pour arrêter et effacer certains enregistrements en premier, poussezpoint de contrôle vers l'avant. Avec le redo log, InnoDB peut garantir que même si la base de données redémarre anormalement, les enregistrements précédemment soumis ne seront pas perdus. Cette fonctionnalité est appelée crash-safe.
Pourquoi utiliser le redo log ?
Si nous effectuons des opérations DML sur la base de données et écrivons directement le SQL exécuté sur le disque, lorsque la concurrence d'écriture est importante, la pression sur l'écriture des données sur le disque sera affectée dans une certaine mesure,Lorsque nous insérons l'opération et constatons que le nœud non-feuille actuel a des données insuffisantes sur une page, nous devons exécuter un algorithme de pagination, qui sera moins efficace
Lorsque j'utilise ; refaire les journaux, écrivez d'abord nos opérations DML dans le journal, via une "station de transfert", puis écrivez sur le disque viapoint de contrôle
lorsqu'il est libre, l'efficacité sera beaucoup plus élevéeRefaire le journal des paramètres MySQL
3. binlog
redo log est un journal unique au moteur InnoDB, et Server La couche possède également son propre journal, appelé binlog (journal archivé) .
Pourquoi y a-t-il deux journaux ?
Parce qu'il n'y avait pas de moteur InnoDB dans MySQL au début. Le propre moteur de MySQL est MyISAM, mais MyISAM n'a pas de fonctionnalités de sécurité contre les pannes et les journaux binlog ne peuvent être utilisés qu'à des fins d'archivage.
InnoDB a été introduit dans MySQL sous la forme d'un plug-in par une autre société. Puisque le fait de s'appuyer uniquement sur binlog n'a pas de fonctionnalités de sécurité contre les pannes, InnoDB utilise un autre système de journalisation, c'est-à-dire redo log pour y parvenir. Capacité anti-collision.
Ces deux journaux présentent les trois différences suivantes.
4. Workflow interne
Prenons une instruction de mise à jour de table comme exemple pour jeter un œil au workflow interne de l'exécuteur et du moteur InnoDB :
mysql> update T set c=c+1 where ID=2;
Comme le montre la figure ci-dessous, la case lumineuse indique qu'il est exécuté dans InnoDB, et la case sombre indique qu'il est exécuté dans l'exécuteur :
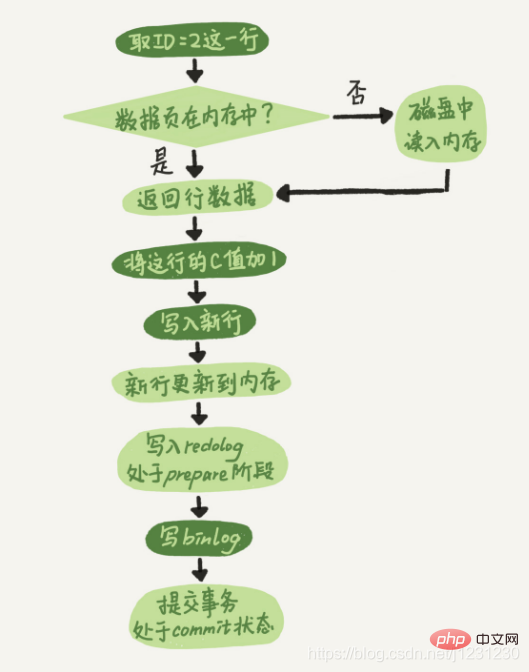
Les trois dernières étapes semblent un peu "circulaires". L'écriture du redo log est divisée en deux étapes : préparer et valider. En fait, c'est "Deux étapes. commettre".
Pourquoi le journal a-t-il besoin d'un « engagement en deux phases » ? Cela peut s'expliquer par la preuve par contradiction.
Étant donné que le redo log et le binlog sont deux logiques indépendantes, si la soumission en deux étapes n'est pas requise, soit le redo log doit être écrit en premier, puis le binlog, soit l'ordre inverse doit être adopté. En utilisant l'instruction de mise à jour précédente comme exemple, voyons quels problèmes existent dans ces deux méthodes.
Supposons que dans la ligne actuelle avec ID=2, la valeur du champ c est 0, et supposons également que lors de l'exécution de l'instruction de mise à jour, après l'écriture du premier journal, un crash se produit avant le second le journal est écrit. Que se passe-t-il ?
1. Écrivez d'abord le redo log, puis binlog. Supposons que le processus MySQL redémarre anormalement lorsque le redo log est terminé mais avant que le binlog ne soit terminé. Une fois le journal redo écrit, même si le système tombe en panne, les données peuvent toujours être restaurées, donc la valeur de c dans cette ligne après la récupération est 1.
Mais comme le binlog s'est écrasé avant d'être terminé, cette déclaration n'a pas été enregistrée dans le binlog pour le moment. Par conséquent, lorsque le journal sera sauvegardé ultérieurement, cette instruction ne sera pas incluse dans le journal binaire enregistré.
Ensuite, vous constaterez que si vous devez utiliser ce binlog pour restaurer la bibliothèque temporaire, car le binlog de cette instruction est perdu, la bibliothèque temporaire perdra cette mise à jour et la valeur de c dans la ligne restaurée sera 0 , qui est le même que l'original. La valeur de la bibliothèque est différente.
2. Écrivez d'abord le binlog, puis refaites le journal. S'il y a un crash après l'écriture du binlog, puisque le redo log n'a pas encore été écrit, la transaction sera invalide après la récupération sur crash, donc la valeur de c dans cette ligne est 0.
Mais le journal "Changer c de 0 à 1" a été enregistré dans le binlog. Par conséquent, lorsque binlog est utilisé pour restaurer ultérieurement, une transaction supplémentaire sera générée. La valeur de c dans la ligne restaurée est 1, ce qui est différent de la valeur dans la base de données d'origine.
Comme vous pouvez le constater, si la « validation en deux phases » n'est pas utilisée, alors l'état de la base de données peut être incohérent avec l'état de la bibliothèque restaurée à l'aide de son journal .
Recommandations d'apprentissage gratuites associées : base de données mysql(vidéo)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Méthode de récupération de base de données Oracle
Méthode de récupération de base de données Oracle
 La solution à Google Chrome ne fonctionne pas
La solution à Google Chrome ne fonctionne pas
 Linux trouver
Linux trouver
 quels sont les fichiers
quels sont les fichiers
 Comment installer WordPress après l'avoir téléchargé
Comment installer WordPress après l'avoir téléchargé
 variables membres Java
variables membres Java
 Que sont les éditeurs de texte Java ?
Que sont les éditeurs de texte Java ?
 Récupérer les données du disque dur mobile
Récupérer les données du disque dur mobile
 Requête de temps Internet
Requête de temps Internet










![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



