

Apprenons ce qu'est une base de données MySQL (3)

Recommandations d'apprentissage gratuites : tutoriel vidéo mysql
Répertoire
- Requête floue
- Contraintes des tables
- Associations entre tables
- Association plusieurs-à-un
- Association plusieurs-à-plusieurs
- Association un-à-un
Requête floue
peut trouver les données souhaitées en fonction du contenu grossièrement fourni. Elle est différente de la requête = char et des données de type varchar. exemples :
create table c1(x char(10));create table c2(x varchar(10));insert c1 values('io');insert c2 values('io');la requête floue utilise comme
select * from c1 where x like 'io';select * from c2 where x like 'io';
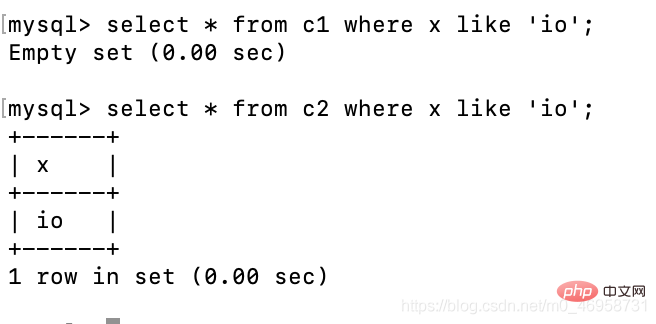
On peut constater que x dans c1 est de type char. Nous ne pouvons pas l'afficher via une requête floue. voyez s'il y a des données io, et nous pouvons les interroger via =

La requête floue est plus précise. Pour interroger de cette manière, vous devez saisir l'intégralité du contenu de ce champ avant de pouvoir le faire. interrogez-le. Les données stockées dans char tapez ici , la longueur est inférieure à 10, donc des espaces sont utilisés pour les compléter, donc lors de l'interrogation, vous devez apporter des espaces 
Nous pouvons également utiliser le méthode de requête fournie par requête floue, % signifie 0 ou plusieurs caractères.
select * from c1 where x like 'io%';

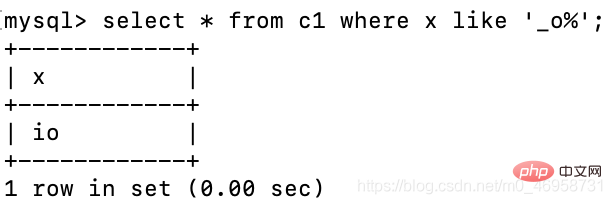
Si nous savons seulement que le deuxième chiffre est un o et que nous ne connaissons pas le début et la fin, nous pouvons utiliser : _ pour représenter n'importe quel caractère, puis utiliser % pour faire correspondre les multiples caractères suivants
select * from c1 where x like '_o%';
La syntaxe de la requête floue SQL est
"SELECT column FROM table WHERE column LIKE ';pattern';".
SQL propose quatre modes de correspondance :
- % représente 0 ou plusieurs caractères bai. L'instruction suivante :
SELECT * FROM user WHERE name LIKE ';%三%';
mettra les noms de "Zhang San", "Three-legged Cat", "Tang Sanzang" et ainsi de suite. it out ;- _ représente n'importe quel caractère. Instruction :
SELECT * FROM user WHERE name LIKE ';三';
Recherchez uniquement "Tang Sanzang" dont le nom comporte trois caractères et le caractère du milieu est "三";
SELECT * FROM utilisateur WHERE nom LIKE ';三__';
Recherchez uniquement "chat à trois pattes" dont le nom comporte trois caractères et le premier caractère est "三"- [ ] représente l'un des caractères répertoriés entre parenthèses (semblable à une expression régulière). Instruction :
SELECT * FROM user WHERE name LIKE ';[张李王]三';
trouvera "Zhang San", "Li San", "Wang San" (au lieu de "Zhang Li Wang San" ");
Si [ ] contient une série de caractères (01234, abcde, etc.), il peut être abrégé en "0-4", "a-e"
SELECT * FROM user WHERE nom LIKE '; old [1 -9]';
trouvera "Old 1", "Old 2",..., "Old 9"
Si vous souhaitez trouver le caractère "-", veuillez le mettre en premier : ';Zhang San [-1-9]';- [^ ] représente un seul caractère non répertorié entre parenthèses. Instruction :
SELECT * FROM user WHERE name LIKE ';[^Zhang Liwang]三';
trouvera "Zhao San", "Sun" qui ne sont pas surnommés "Zhang", "Li", "Wang" Trois" et ainsi de suite ;
SELECT * FROM user WHERE name LIKE ';老[^1-4]';
exclura "old 1" à "old 4" pour trouver "old 5", "old 6", ..., "Vieux 9".
Contraintes de table
Introduction :
Contraintes et types de données La largeur est les mêmes, et ce sont tous des paramètres facultatifs
Rôle : Utilisé pour assurer l'intégrité et la cohérence des données
Principalement divisé en :
PRIMARY KEY (PK) 标识该字段为该表的主键,可以唯一的标识记录FOREIGN KEY (FK) 标识该字段为该表的外键NOT NULL 标识该字段不能为空UNIQUE KEY (UK) 标识该字段的值是唯一的AUTO_INCREMENT 标识该字段的值自动增长(整数类型,而且为主键)DEFAULT 为该字段设置默认值UNSIGNED 无符号 ZEROFILL 使用0填充
not null : le sens littéral est qu'après la définition, chaque fois qu'une valeur est insérée, la valeur doit être définie pour le champ
par défaut : si aucune valeur n'est définie pour le champ, utilisez le valeur que nous avons définie dans Une valeur par défaut après défaut
CLÉ UNIQUE : Une fois qu'un champ a défini cette contrainte, la valeur qu'il définit ne peut avoir qu'une seule (unique)
CLÉ PRIMAIRE dans toute la table : La la clé primaire est la base sur laquelle le moteur de stockage innodb organise les données. Innodb l'appelle une table organisée en index. Il ne doit y avoir qu'une seule clé primaire dans une table. La clé primaire est l'identifiant unique qui peut déterminer un enregistrement
AUTO_INCREMENT : Après paramétrage, ce champ augmentera automatiquement d'un nombre à chaque fois qu'une valeur est insérée dans la table, mais ce champ doit être de type entier, et il doit également s'agir d'une clé primaire
CLÉ ÉTRANGÈRE : Clé étrangère, qui associe un champ de cette table à un champ d'une autre table Après l'association, la valeur de. ce champ doit correspondre à la valeur du champ associé.
我们创建表,通常会有一个id字段作为索引标识作用,并且会将它设置为主键和自增。
实例:
create table test(
id int primary key auto_increment,
identity varchar(18) not null unique key, --身份证必须唯一
gender varchar(18) default '男');insert test(identity) values('123456789012345678');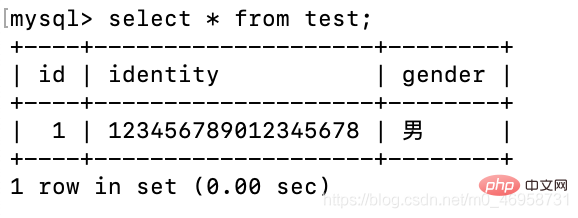
当身份字段插入相同值,则会报错,因为字段设置了唯一值
insert test(identity,gender) values('0123456789012345678','女');
我们会发现,id不对劲啊,那是因为笔者之前进行两次插入值操作,但是值并没有成功插入进去,但是这个自增却受到了影响.
这个时候,我们进行两部操作就可以解决这个问题。
alter table test drop id;alter table test add id int primary key auto_increment first;
删除id字段,再重新设置。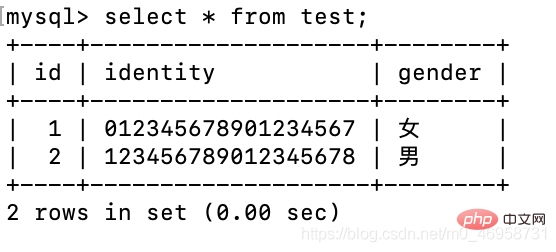
很神奇是不是,这个MySQL的底层机制。vary 良心
还需要注意的是:我们使用delete删除一条记录时,并不会影响自增
delete from test where id = 2;insert test(identity,gender) values('111111111111111111','男');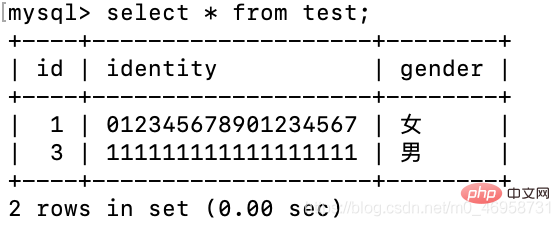
关于这个操作,如果我们只是删除单条记录的话,可以使用上序提供的方法还调整自增的值,而如果是删除整个表记录的话,使用以下方法:
truncate test;
效果演示:delete删除整个表记录
效果演示:truncate删除整个表记录
联合主键
确保设置为主键的某几个字段的数据相同
主键的一个目的就是确定数据的唯一性,它跟唯一约束的区别就是,唯一约束可以有一个NULL值,但是主键不能有NULL值,再说联合主键,联合主键就是说,当一个字段可能存在重复值,无法确定这条数据的唯一性时,再加上一个字,两个字段联合起来确定这条数据的唯一性。比如你提到的id和name为联合主键,在插入数据时,当id相同,name不同,或者id不同,name相同时数据是允许被插入的,但是当id和name都相同时,数据是不允许被插入的。
实例:
create table test( id int, name varchar(10), primary key(id,name)); insert test values(1,1);

如果再次插入两个主键相同的数据,则会报错
只要设置主键的两个字段,在一条记录内,数据不完全相同就没有问题。
外键的话,我们在表之间的关联进行演示
表之间的关联
我们这里先介绍表之间的关联,后面再学习联表查询
通过某一个字段,或者通过某一张表,将多个表关联起来。
我们一张表处理好不行吗,为什么要关联,像这样?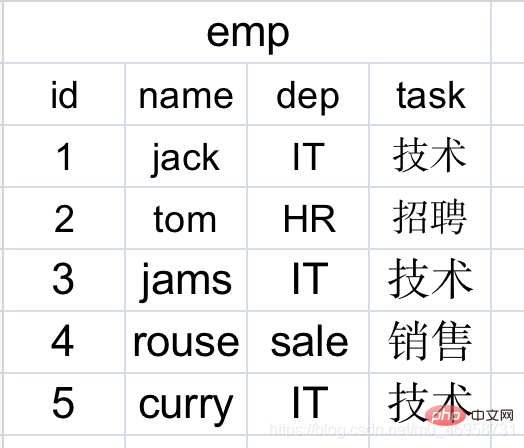
有没有发现一个问题,有些员工它们对应的是相同部门,一张表就重复了很多次记录,随着员工数量的增加,就会出现越来越多个重复记录,相对更占用空间了。
那么我们需要将部门单独使用一张表,再将员工这个使用一个字段关联到另一个表内,我们可以使用外键,也可以不使用外键,先来演示外键的好处吧
多对一关联
如:多个员工对应一个部门。
员工表,先别急着创建,请向下看
create table emp( id int primary key auto_increment, name varchar(10) not null, dep_id int, foreign key(dep_id) references dep(id) on update cascade # 级联更新 on delete cascade); # 级联删除
上面外键的作用就是:
dep_id字段关联了dep表的id字段:
当dep表的id字段值修改后,该表的dep_id字段下面如果有和dep表id相同值的则会一起更改。
如果dep表删除了某一条记录,当emp表的dep_id与dep表删除记录的id值对上以后,emp表这条记录也会被随之删除。
注意:必须是外键已存在,所以需要先创建部门表,再创建员工表
部门表
create table dep( id int primary key auto_increment, name varchar(16) not null unique key, task varchar(16) not null);
emp表的dep_id字段设置的数据必须是dep表已存在的id
所以我们需要先向dep表插入记录
insert dep(name,task) values('IT','技术'),('HR','招聘'),('sale','销售');员工表插入记录
insert emp(name,dep_id) values
('jack',1),
('tom',2),
('jams',1),
('rouse',3),
('curry',2);
# ('go',4) 报错,在关联外键的id字段中找不到注意:如果我们emp表的dep_id字段插入的数据,在dep表中的id字段不存在该数据时,就会报错。
查询我们创建后的效果
这样就把这两个表关联起来了,目前我们先不了解多表查询,这个先了解的是,表之间的关联。
我们再来看一下同步更新以及删除,外键的改动被关联表会受到影响
update dep set id=33333 where id = 3;
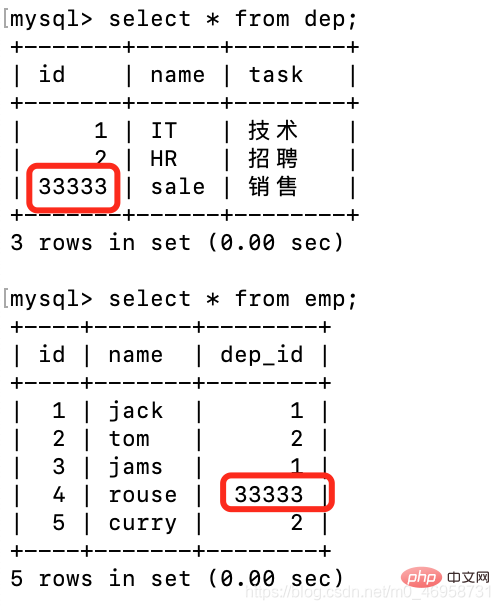
再来体验一下同步删除
delete from dep where id = 33333;

这就是外键带给我们的效果,有利也有弊:
- 优点:关联性强,只能设置已存在的内容,并且同步更新与删除
- 缺点:当删除外键表的某一条记录,关联表中有关联性的记录会被全部删除
多对多关联
多张表互相关联
如:一个作者可以写多本书,一本书也可以有多个作者,双向的一对多,即多对多
这时使用外键会出现一个弊端,那就是先创建哪张表呢?它们都互相对应,是不是很矛盾呢?解决办法:第三张表,关联书的id与作者的id
book表
create table book( id int primary key auto_increment, name varchar(30));
author表
create table author( id int primary key auto_increment, name varchar(30));
中间表:负责将两张表进行关联
create table authorRbook( id int primary key auto_increment, author_id int, book_id int, foreign key(book_id) references book(id) on update cascade on delete cascade, foreign key(author_id) references author(id) on update cascade on delete cascade);
多名作者关联一本书,或者一名作者关联多本书,书也要体现出谁关联了它
book表插入数据:
insert book(name) values
('斗破苍穹'),
('斗罗大陆'),
('武动乾坤');author表插入数据:
insert author(name) values
('jack'),
('tom'),
('jams'),
('rouse'),
('curry'),
('john');关联表插入数据:
insert authorRbook(author_id,book_id) values (1,1), (1,2), (1,3), (2,1), (2,3), (3,2), (4,1), (5,1), (5,3), (6,2);
目前的对应关系就是:
jack:斗破苍穹、斗罗大陆、武动乾坤
tom:斗破苍穹、武动乾坤
jams:斗罗大陆
rouse:斗破苍穹
curry:斗破苍穹、武动乾坤
jhon:斗罗大陆
一个作者可以产于多本书的编写,同时,每本书都会标明产于的作者
一对一关联
路人有可能变成某个学校的学生,即一对一关系。
在这之前,路人不属于学校。
原理就是:学校通过广告,或者通过电话邀请,将路人变成了学生。
路人表
create table passers_by(
id int primary key auto_increment,
name varchar(10),
age int);
insert passers_by(name,age) values
('jack',18),
('tom',19),
('jams',23);学校表
create table school(
id int primary key auto_increment,
class varchar(10),
student_id int unique key,
foreign key(student_id) references passers_by(id)
on update cascade
on delete cascade);insert school(class,student_id) values
('Mysql入门到放弃',1),
('Python入门到运维',3),
('Java从入门到音乐',2);数据存储的设计,需要提前设计好表的关联 关系,将关系全部设计好以后,剩下的只是往里存数据了,后续我们会了解到联表查询相关内容,将有关联性的内容,以虚拟表的形式查询出来,查询出来的数据可能来自多个表。
表的关联,建议使用以下方式
- 多对多 > 多对一 > 一对一
相关免费学习推荐:mysql数据库(视频)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1393
1393
 52
1206
24
52
1206
24

 Pratique de développement PHP : utilisez PHPMailer pour envoyer des e-mails aux utilisateurs de la base de données MySQL
Aug 05, 2023 pm 06:21 PM
Pratique de développement PHP : utilisez PHPMailer pour envoyer des e-mails aux utilisateurs de la base de données MySQL
Aug 05, 2023 pm 06:21 PM
Pratique de développement PHP : utilisez PHPMailer pour envoyer des e-mails aux utilisateurs de la base de données MySQL Introduction : Dans la construction de l'Internet moderne, l'e-mail est un outil de communication important. Qu’il s’agisse d’enregistrement d’utilisateur, de réinitialisation de mot de passe ou de confirmation de commande en e-commerce, l’envoi d’emails est une fonction essentielle. Cet article explique comment utiliser PHPMailer pour envoyer des e-mails et enregistrer les informations de courrier électronique dans le tableau d'informations utilisateur de la base de données MySQL. 1. Installez la bibliothèque PHPMailer PHPMailer est
 Go langage et base de données MySQL : Comment séparer les données chaudes et froides ?
Jun 18, 2023 am 08:26 AM
Go langage et base de données MySQL : Comment séparer les données chaudes et froides ?
Jun 18, 2023 am 08:26 AM
À mesure que la quantité de données continue d’augmenter, les performances des bases de données deviennent un problème de plus en plus important. Le traitement de séparation des données chaudes et froides est une solution efficace qui peut séparer les données chaudes et les données froides, améliorant ainsi les performances et l'efficacité du système. Cet article explique comment utiliser le langage Go et la base de données MySQL pour séparer les données chaudes et froides. 1. Qu'est-ce que le traitement de séparation des données chaudes et froides ? Le traitement de séparation des données chaudes et froides est un moyen de classer les données chaudes et les données froides. Les données chaudes font référence aux données avec une fréquence d'accès élevée et des exigences de performances élevées.
 Dans quelle mesure puis-je développer des compétences en matière de bases de données MySQL pour être employées avec succès ?
Sep 12, 2023 pm 06:42 PM
Dans quelle mesure puis-je développer des compétences en matière de bases de données MySQL pour être employées avec succès ?
Sep 12, 2023 pm 06:42 PM
Dans quelle mesure puis-je développer des compétences en matière de bases de données MySQL pour être employées avec succès ? Avec le développement rapide de l’ère de l’information, les systèmes de gestion de bases de données sont devenus un élément indispensable et important dans tous les domaines. En tant que système de gestion de bases de données relationnelles couramment utilisé, MySQL propose un large éventail de domaines d'application et d'opportunités d'emploi. Alors, dans quelle mesure les compétences en matière de bases de données MySQL doivent-elles être développées pour être utilisées avec succès ? Tout d’abord, maîtriser les principes de base et les connaissances de base de MySQL est la condition la plus fondamentale. MySQL est une gestion de base de données relationnelle open source
 Comment effectuer une sauvegarde incrémentielle des données de la base de données MySQL à l'aide du langage Go
Jun 17, 2023 pm 02:28 PM
Comment effectuer une sauvegarde incrémentielle des données de la base de données MySQL à l'aide du langage Go
Jun 17, 2023 pm 02:28 PM
À mesure que la quantité de données augmente, la sauvegarde des bases de données devient de plus en plus importante. Pour la base de données MySQL, nous pouvons utiliser le langage Go pour réaliser une sauvegarde incrémentielle automatisée. Cet article présentera brièvement comment utiliser le langage Go pour effectuer une sauvegarde incrémentielle des données de la base de données MySQL. 1. Installez l'environnement linguistique Go. Tout d'abord, nous devons installer l'environnement linguistique Go localement. Vous pouvez vous rendre sur le site officiel pour télécharger le package d'installation correspondant et l'installer. 2. Installez la bibliothèque correspondante. Le langage Go fournit de nombreuses bibliothèques tierces pour accéder aux bases de données MySQL, parmi lesquelles les plus couramment utilisées sont
 Comment utiliser la base de données MySQL pour l'analyse de séries chronologiques ?
Jul 12, 2023 am 08:39 AM
Comment utiliser la base de données MySQL pour l'analyse de séries chronologiques ?
Jul 12, 2023 am 08:39 AM
Comment utiliser la base de données MySQL pour l'analyse de séries chronologiques ? Les données de séries chronologiques font référence à une collection de données classées par ordre chronologique, qui présentent une continuité et une corrélation temporelles. L'analyse des séries chronologiques est une méthode d'analyse de données importante qui peut être utilisée pour prédire les tendances futures, découvrir les changements cycliques, détecter les valeurs aberrantes, etc. Dans cet article, nous présenterons comment utiliser une base de données MySQL pour l'analyse de séries chronologiques, ainsi que des exemples de code. Créer une table de données Tout d'abord, nous devons créer une table de données pour stocker les données de séries chronologiques. Supposons que nous voulions analyser le nombre
 Comment utiliser la base de données MySQL pour le traitement d'images ?
Jul 14, 2023 pm 12:21 PM
Comment utiliser la base de données MySQL pour le traitement d'images ?
Jul 14, 2023 pm 12:21 PM
Comment utiliser la base de données MySQL pour le traitement d'images ? MySQL est un puissant système de gestion de bases de données relationnelles. En plus d'être utilisé pour stocker et gérer des données, il peut également être utilisé pour le traitement d'images. Cet article explique comment utiliser une base de données MySQL pour le traitement d'images et fournit quelques exemples de code. Avant de commencer, assurez-vous d'avoir installé une base de données MySQL et d'être familiarisé avec les instructions SQL de base. Créer une table de base de données Commencez par créer une nouvelle table de base de données pour stocker les données d'image. La structure du tableau peut être la suivante
 Comment établir une connexion fiable à la base de données MySQL en utilisant le langage Go ?
Jun 17, 2023 pm 07:18 PM
Comment établir une connexion fiable à la base de données MySQL en utilisant le langage Go ?
Jun 17, 2023 pm 07:18 PM
Avec la grande quantité de données qui doivent être stockées et traitées, MySQL est devenue l'une des bases de données relationnelles les plus couramment utilisées dans le développement d'applications. Le langage Go devient de plus en plus populaire parmi les développeurs en raison de son traitement simultané efficace et de sa syntaxe concise. Cet article amènera les lecteurs à mettre en œuvre une connexion fiable à la base de données MySQL via le langage Go, permettant aux développeurs d'interroger et de stocker les données plus efficacement. 1. Plusieurs façons pour le langage Go de se connecter à la base de données MySQL. Il existe généralement trois façons de se connecter à la base de données MySQL en langage Go, à savoir : 1. Bibliothèque tierce.
 Base de données MySQL et langage Go : Comment effectuer la mise en cache des données ?
Jun 17, 2023 am 10:05 AM
Base de données MySQL et langage Go : Comment effectuer la mise en cache des données ?
Jun 17, 2023 am 10:05 AM
Ces dernières années, le langage Go est devenu de plus en plus populaire auprès des développeurs et est devenu l'un des langages privilégiés pour développer des applications Web performantes. MySQL est également une base de données populaire et largement utilisée. Dans le processus de combinaison de ces deux technologies, la mise en cache est un élément très important. Ce qui suit explique comment utiliser le langage Go pour gérer le cache de la base de données MySQL. Le concept de mise en cache Dans les applications Web, la mise en cache est une couche intermédiaire créée pour accélérer l'accès aux données. Il est principalement utilisé pour stocker les données fréquemment demandées afin de
