
Recommandé (gratuit) : SQL
Zéro, pilote de base de données
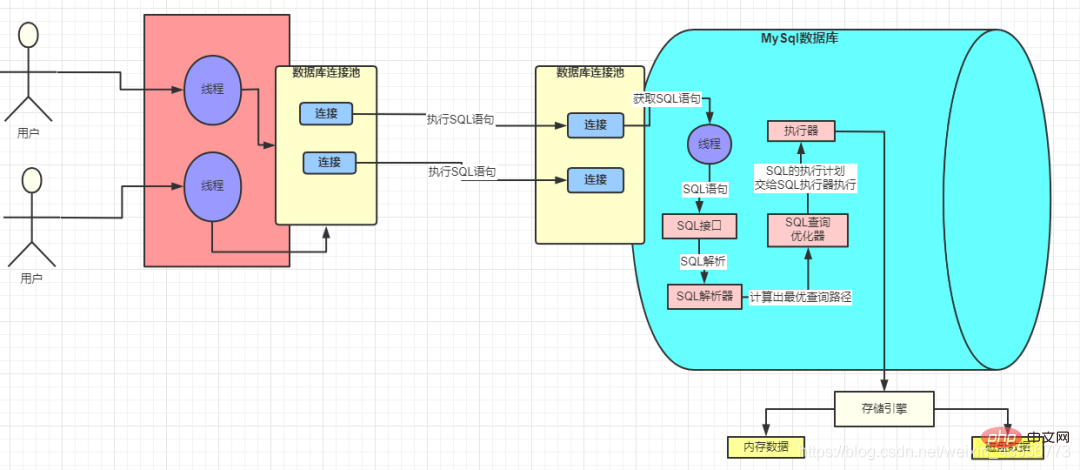
- Le pilote MySQL nous aide à nous connecter à la base de données au niveau inférieur Ce n'est qu'une fois la connexion établie que des interactions ultérieures peuvent être possibles.
1. Pool de connexions à la base de données
- Les pools de connexions à la base de données incluent Druid, C3P0, DBCP
- L'utilisation des pools de connexions permet d'économiser beaucoup d'argent La surcharge liée à la création et à la destruction constante de threads est la fameuse idée de "pooling". Qu'il s'agisse d'un pool de threads ou d'un pool de connexions HTTP, vous pouvez le voir
2. Interface SQL.
- Après avoir reçu la requête, le thread qui traite la requête dans MySQL obtient l'instruction SQL et la transmet à l'interface SQL pour traitement.
3. Analyseur de requêtes
- Analyse l'instruction SQL transmise par l'interface SQL et la traduit dans un langage que MySQL peut comprendre.
4. MySQL Query Optimizer
- MySQL sélectionnera l'index correspondant en fonction du principe du coût minimum
- Coût = coût IO + coût CPU
-
Coût IO : c'est-à-dire le coût de chargement des données du disque vers la mémoire. Par défaut, le coût IO de la lecture d'une page de données est. 1 , MySQL lit les données sous forme de pages, c'est-à-dire que lorsqu'une certaine donnée est utilisée, il lira non seulement ces données, mais lira également les données adjacentes à ces données dans la mémoire. C'est le fameux principe du programme. localité, donc MySQL lira une page entière à chaque fois, et le coût d'une page est de 1. Par conséquent, le coût des IO est principalement lié à la taille de la page
-
Coût du CPU : Après avoir lu les données dans la mémoire, il est également nécessaire de détecter si les données remplissent les conditions et le coût du tri et d'autres opérations du processeur. Évidemment, cela est lié au nombre de lignes, par défaut, le coût de détection des enregistrements est de 0,2.
- L'optimiseur MySQL calculera l'index avec le plus petit coût de "Coût IO + CPU" pour exécuter
Moteur de stockage
L'optimiseur de requêtes appellera l'interface du moteur de stockage pour exécuter SQL, ce qui signifie que l'- exécution réelle de SQL est terminée dans le moteur de stockage.
Les données sont stockées en mémoire ou sur le disque - Chaque fois que SQL est exécuté, ses données seront chargées en mémoire. Cette mémoire est un composant très important dans InnoDB :
- Buffer Pool<.>
6. Exécuteur
L'exécuteur se déroule enfin selon une série de plans d'exécution Appelez l'interface du moteur de stockage pour terminer l'exécution SQL
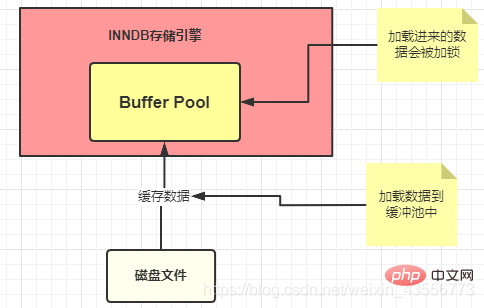
7. Buffer Pool
Buffer Pool ( Buffer Pool) est une structure de mémoire très importante dans le Moteur de stockage InnoDB. Il fonctionne comme un cache
- Buffer Pool signifie que lorsque nous interrogeons pour la première fois, nous enregistrerons les résultats de la requête dans le Buffer Pool, de sorte que plus tard, lorsqu'il y aura une autre requête, ce sera d'abord le cas. être interrogé à partir du pool de tampons. S'il n'y a pas de recherche, il sera recherché sur le disque, puis placé dans le pool de tampons
- Les données utilisées dans le pool de tampons seront verrouillées.
-
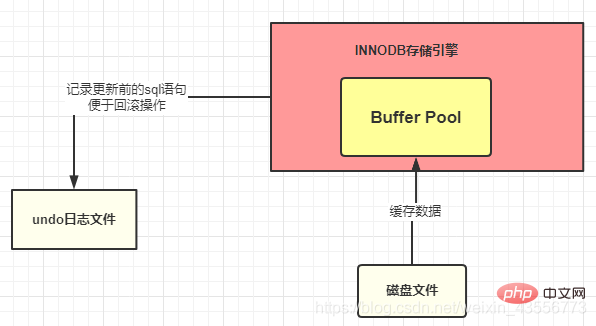
8. Trois fichiers journaux
Annuler le fichier journal
: avant que les données enregistrées ne soient modifiées. Cela ressemble à
Fonction : utiliser les fichiers journaux d'annulation pour terminer l'annulation des transactions
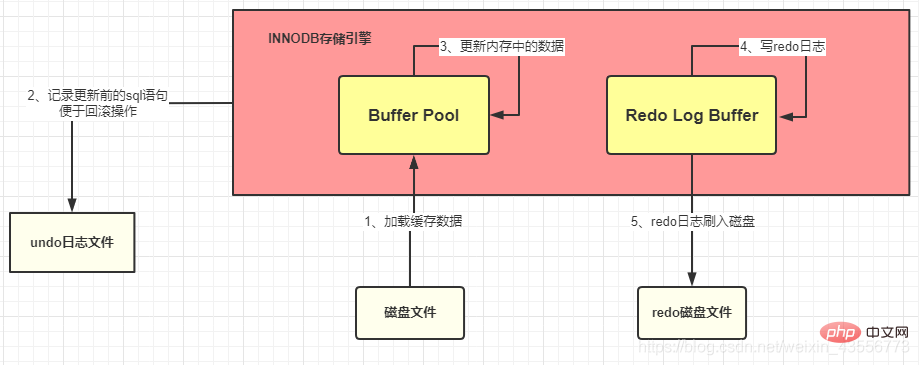
2. : Enregistrez l'apparence des données après avoir été modifiées
redo enregistre la valeur une fois les données modifiées. Elle sera enregistrée, que la transaction soit soumise ou non
Dans. Afin d'améliorer l'efficacité, MySQL effectuera ces opérations. Elles sont d'abord placées en mémoire pour terminer. Les données mises à jour seront enregistrées dans le tampon de journalisation, puis conservées sur le disque à une certaine occasion. -
-
3. Fichier journal Bin :
enregistre l'ensemble du processus d'opération
| 性质 |
redo Log |
bin Log |
| 文件大小 |
redo log 的大小是固定的(配置中也可以设置,一般默认的就足够了) |
bin log 可通过配置参数max_bin log_size设置每个bin log文件的大小(但是一般不建议修改)。 |
| 实现方式 |
redo log是InnoDB引擎层实现的(也就是说是 Innodb 存储引起过独有的) |
bin log是 MySQL 层实现的,所有引擎都可以使用 bin log日志 |
| 记录方式 |
redo log 采用循环写的方式记录,当写到结尾时,会回到开头循环写日志。 |
bin log 通过追加的方式记录,当文件大小大于给定值后,后续的日志会记录到新的文件上 |
| 使用场景 |
redo log适用于崩溃恢复(crash-safe)(这一点其实非常类似与 Redis 的持久化特征) |
bin log适用于主从复制和数据恢复 |
le journal bin enregistre l'intégralité de l'enregistrement de l'opération (ceci est très important pour la réplication maître-esclave)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!


 Quels sont les outils d'analyse des données ?
Quels sont les outils d'analyse des données ?
 Utilisation de distinct en SQL
Utilisation de distinct en SQL
 Comment utiliser mois_entre dans SQL
Comment utiliser mois_entre dans SQL
 Solution d'erreur SQL 5120
Solution d'erreur SQL 5120
 Solution à l'erreur de syntaxe de la procédure SQL
Solution à l'erreur de syntaxe de la procédure SQL
 base de données Oracle exécutant la méthode SQL
base de données Oracle exécutant la méthode SQL
 La signification de où dans SQL
La signification de où dans SQL
 Quelle est l'instruction pour supprimer une table dans SQL
Quelle est l'instruction pour supprimer une table dans SQL









![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



