

redis introduit le principe du CAP de base de données distribuée


Recommandé (gratuit) : redis
Les ACID traditionnels sont quoi
A (Atomicité) C (Cohérence) Cohérence
I (Isolement) Indépendance
D (Durabilité) Durabilité
La base de données relationnelle suit les règles de transaction ACID. en anglais est très similaire aux transactions dans le monde réel. Il présente les quatre caractéristiques suivantes :
1 A (Atomicité) Atomicité
L'atomicité est facile à comprendre, c'est-à-direToutes les opérations de la transaction sont soit terminées, soit aucune. La condition de succès de la transaction est que toutes les opérations de la transaction réussissent. Si une opération échoue, la transaction entière échoue. et doit être annulé . Par exemple, un virement bancaire pour transférer 100 yuans du compte A vers le compte B est divisé en deux étapes : 1) retirer 100 yuans du compte A 2) déposer 100 yuans sur le compte B ; Ces deux étapes sont soit complétées ensemble, soit non complétées ensemble. Si seule la première étape est terminée et que la deuxième étape échoue, l'argent sera de 100 yuans de moins sans raison.
2. Cohérence C (Cohérence)
La cohérence est également plus facile à comprendre, ce qui signifie quela base de données doit toujours être dans un état cohérent . L'exécution de la transaction ne modifiera pas les contraintes de cohérence d'origine de la base de données.
3. I (Isolement) Indépendance
La soi-disant indépendancesignifie que les transactions simultanées ne s'affecteront pas , Si les données auxquelles une transaction doit accéder sont modifiées par une autre transaction, tant que l'autre transaction n'est pas validée, les données auxquelles elle accède ne seront pas affectées par la transaction non validée . Par exemple, il y a une transaction qui transfère 100 yuans du compte A vers le compte B. Si la transaction n'est pas encore terminée, si B vérifie son compte à ce moment-là, il ne verra pas les 100 yuans nouvellement ajoutés
4. D (Durabilité) Durabilité
La durabilité signifie qu'une fois qu'une transaction est validée, les modifications qu'elle apporte seront définitivement enregistrées dans la base de données, elle ne le sera pas. perdu même s'il y a un temps d'arrêt.
CAP
C : Cohérence (cohérence forte) A : Disponibilité (disponibilité)
P : Tolérance de partition (tolérance aux pannes de partition) ) ou tolérance distribuée
La théorie CAP signifie que dans un système de stockage distribué, au plus les deux points ci-dessus ne peuvent être atteints.
Forte cohérence : par exemple, ce qui se trouve dans les données est ce qu'elles sont.
Toutes les sauvegardes de données dans le système distribué ont la même valeur en même temps. (Équivalent à tous les nœuds accédant à la même dernière copie de données) Disponibilité : Par exemple, il est impossible de ne pas utiliser Taobao Double Eleven.
Après l'échec de certains nœuds du cluster, si l'ensemble du cluster peut toujours répondre aux demandes de lecture et d'écriture du client. (Haute disponibilité pour les mises à jour des données) Tolérance aux pannes de partition : En pratique, le partitionnement équivaut à l'exigence de délai de communication.
Si le système ne parvient pas à assurer la cohérence des données dans le délai imparti, cela signifie qu'une partition s'est produite et qu'un choix doit être fait entre C et A pour l'opération en cours. Par exemple : les sacs Taobao
Pour une forte cohérence, nous exigeons que le nombre de likes pour ce sac soit de 141, ce qui ne doit pas être faux. Des conseils précis sont nécessaires, mais il est difficile d'assurer l'uniformité des données en période de forte concurrence
Pour la haute disponibilité : une faible cohérence est autorisée, comme autoriser des erreurs dans le nombre de likes et de vues, mais cela ne peut pas provoquer la paralysie du site Web.
Ainsi, la plupart des architectures de sites Web utilisent AP. Faible cohérence + haute disponibilité
la tolérance de partition doit être atteinte Le système distribué n'est peut-être pas dans la même ville, comme Taobao, mais la distribution de contenu est la plus proche de chez vous. Les serveurs Taobao peuvent avoir des serveurs à Hangzhou, Shanghai et Suzhou. Étant donné que le matériel réseau actuel aura certainement des problèmes tels que la perte de paquets retardée,
la tolérance de partition est donc ce que nous devons atteindre. On ne peut donc faire qu'un compromis entre cohérence et disponibilité. Aucun système NoSQL ne peut garantir ces trois points à la fois.
AP Choix de la plupart des architectures de sites Web
CP Redis, Mongodb
Remarque : des compromis doivent être faits lors de l'utilisation d'une architecture distribuée.
Le choix entre cohérence et disponibilité
Pour les sites web web2.0, bon nombre des principales fonctionnalités des bases de données relationnelles sont souvent inutiles
Exigences de cohérence des transactions de base de données
De nombreux systèmes Web en temps réel ne nécessitent pas de transactions de base de données strictes et ont des exigences très faibles en matière de cohérence en lecture. Dans certains cas, les exigences en matière de cohérence en écriture ne sont pas élevées. Permet une cohérence éventuelle.
Exigences d'écriture et de lecture en temps réel de la base de données
Pour les bases de données relationnelles, si vous insérez une donnée et l'interrogez immédiatement, vous pouvez certainement lire les données, mais pour de nombreuses applications Web Par exemple, cela ne nécessite pas de performances en temps réel aussi élevées. Par exemple, après avoir publié un message sur Weibo, il est tout à fait acceptable que mes abonnés ne voient cette actualité qu'après quelques secondes, voire plus de dix secondes.
Exigences pour les requêtes SQL complexes, en particulier les requêtes liées à plusieurs tables
Tout système Web avec une grande quantité de données est très tabou concernant les requêtes liées à plusieurs grandes tables et à l'analyse de données complexes. Types de requêtes de rapport , en particulier les sites Web de type SNS, évitent cette situation du point de vue de la demande et de la conception des produits. Souvent, il n'y a que des requêtes de clé primaire d'une seule table et de simples requêtes de pagination conditionnelles d'une seule table. La fonction de SQL est considérablement affaiblie.
Diagramme CAP classique
Le cœur de la théorie CAP est le suivant : un système distribué ne peut pas satisfaire en même temps à la cohérence, à la disponibilité et à la tolérance aux pannes de partition. trois besoins, au plus deux peuvent être bien satisfaits en même temps.
Ainsi, selon le principe CAP, les bases de données NoSQL sont divisées en trois catégories : satisfaisant le principe CA, satisfaisant le principe CP et satisfaisant le principe AP :
CA - un cluster à point unique , un système qui répond à la cohérence et à la disponibilité , est généralement moins évolutif.
CP - Un système qui répond à la cohérence et doit tolérer les partitions. Habituellement, les performances ne sont pas particulièrement élevées.
AP - Un système qui répond à la disponibilité, à la tolérance de partition et peut généralement avoir des exigences de cohérence inférieures. 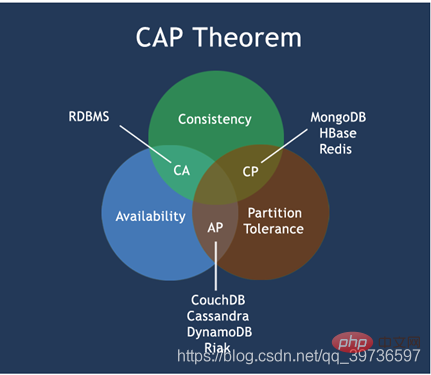
BASE
BASE est une solution proposée pour résoudre les problèmes causés par la forte cohérence des bases de données relationnelles et la disponibilité réduite.
BASE est en fait l'abréviation des trois termes suivants :
Basically Available (Basiquement disponible)
Soft state (Soft state)
Finalement cohérent (éventuellement cohérent)
L'idée est d'améliorer l'évolutivité et les performances globales du système en permettant au système d'assouplir ses exigences en matière de cohérence des données à un moment donné. Pourquoi disons-nous cela ?La raison est que les grands systèmes ne peuvent souvent pas utiliser de transactions distribuées pour compléter ces indicateurs en raison de la répartition géographique et des exigences de performance extrêmement élevées. Pour obtenir ces indicateurs, nous devons utiliser une autre façon de les compléter. la solution à ce problème
Introduction au cluster distribué +
Le système distribué (système distribué)
se compose de plusieurs ordinateurs et les composants logiciels communicants via l'ordinateur se composent de une connexion réseau (réseau local ou réseau étendu). Les systèmes distribués sont des systèmes logiciels construits sur le réseau. C'est précisément en raison des caractéristiques des logiciels que les systèmes distribués présentent un haut degré de cohésion et de transparence. Par conséquent, la différence entre les réseaux et les systèmes distribués réside davantage dans le logiciel de haut niveau (en particulier le système d’exploitation) que dans le matériel. Les systèmes distribués peuvent être appliqués sur différentes plates-formes telles que les PC, les postes de travail, les réseaux locaux et les réseaux étendus.
Pour faire simple :
Distribué : Différents modules de services (projets) sont déployés sur plusieurs serveurs. Ils communiquent et appellent via RPC/RMI pour fournir des services externes et au sein du groupe.
Cluster : le même module de service est déployé sur plusieurs serveurs différents et la planification unifiée est effectuée via un logiciel de planification distribué pour fournir des services et un accès externes.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Solution à l'erreur 0x80242008 lors de l'installation de Windows 11 10.0.22000.100
May 08, 2024 pm 03:50 PM
Solution à l'erreur 0x80242008 lors de l'installation de Windows 11 10.0.22000.100
May 08, 2024 pm 03:50 PM
1. Démarrez le menu [Démarrer], entrez [cmd], cliquez avec le bouton droit sur [Invite de commandes] et sélectionnez Exécuter en tant qu'[Administrateur]. 2. Entrez les commandes suivantes dans l'ordre (copiez et collez soigneusement) : SCconfigwuauservstart=auto, appuyez sur Entrée SCconfigbitsstart=auto, appuyez sur Entrée SCconfigcryptsvcstart=auto, appuyez sur Entrée SCconfigtrustedinstallerstart=auto, appuyez sur Entrée SCconfigwuauservtype=share, appuyez sur Entrée netstopwuauserv , appuyez sur Entrée netstopcryptS.
 Stratégie de mise en cache et optimisation de l'API Golang
May 07, 2024 pm 02:12 PM
Stratégie de mise en cache et optimisation de l'API Golang
May 07, 2024 pm 02:12 PM
La stratégie de mise en cache dans GolangAPI peut améliorer les performances et réduire la charge du serveur. Les stratégies couramment utilisées sont : LRU, LFU, FIFO et TTL. Les techniques d'optimisation incluent la sélection du stockage de cache approprié, la mise en cache hiérarchique, la gestion des invalidations, ainsi que la surveillance et le réglage. Dans le cas pratique, le cache LRU est utilisé pour optimiser l'API pour obtenir des informations utilisateur à partir de la base de données. Les données peuvent être rapidement récupérées du cache. Sinon, le cache peut être mis à jour après l'avoir obtenu à partir de la base de données.
 Mécanisme de mise en cache et pratique d'application dans le développement PHP
May 09, 2024 pm 01:30 PM
Mécanisme de mise en cache et pratique d'application dans le développement PHP
May 09, 2024 pm 01:30 PM
Dans le développement PHP, le mécanisme de mise en cache améliore les performances en stockant temporairement les données fréquemment consultées en mémoire ou sur disque, réduisant ainsi le nombre d'accès à la base de données. Les types de cache incluent principalement le cache de mémoire, de fichiers et de bases de données. En PHP, vous pouvez utiliser des fonctions intégrées ou des bibliothèques tierces pour implémenter la mise en cache, telles que cache_get() et Memcache. Les applications pratiques courantes incluent la mise en cache des résultats des requêtes de base de données pour optimiser les performances des requêtes et la mise en cache de la sortie des pages pour accélérer le rendu. Le mécanisme de mise en cache améliore efficacement la vitesse de réponse du site Web, améliore l'expérience utilisateur et réduit la charge du serveur.
 Comment utiliser le cache Redis dans la pagination des tableaux PHP ?
May 01, 2024 am 10:48 AM
Comment utiliser le cache Redis dans la pagination des tableaux PHP ?
May 01, 2024 am 10:48 AM
L'utilisation du cache Redis peut considérablement optimiser les performances de la pagination du tableau PHP. Cela peut être réalisé en suivant les étapes suivantes : Installez le client Redis. Connectez-vous au serveur Redis. Créez des données de cache et stockez chaque page de données dans un hachage Redis avec la clé « page : {page_number} ». Récupérez les données du cache et évitez les opérations coûteuses sur les grandes baies.
 Comment mettre à niveau Win11 anglais 21996 vers le chinois simplifié 22000_Comment mettre à niveau Win11 anglais 21996 vers le chinois simplifié 22000
May 08, 2024 pm 05:10 PM
Comment mettre à niveau Win11 anglais 21996 vers le chinois simplifié 22000_Comment mettre à niveau Win11 anglais 21996 vers le chinois simplifié 22000
May 08, 2024 pm 05:10 PM
Vous devez d’abord définir la langue du système sur l’affichage chinois simplifié et redémarrer. Bien sûr, si vous avez déjà modifié la langue d'affichage en chinois simplifié, vous pouvez simplement ignorer cette étape. Ensuite, commencez à utiliser le registre, regedit.exe, accédez directement à HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControlNlsLanguage dans la barre de navigation de gauche ou dans la barre d'adresse supérieure, puis modifiez la valeur de la clé InstallLanguage et la valeur de la clé par défaut sur 0804 (si vous souhaitez la changer en anglais en- nous, vous devez d'abord définir la langue d'affichage du système sur en-us, redémarrer le système, puis tout changer en 0409). Vous devez redémarrer le système à ce stade.
 Navicat peut-il se connecter à Redis ?
Apr 23, 2024 pm 05:12 PM
Navicat peut-il se connecter à Redis ?
Apr 23, 2024 pm 05:12 PM
Oui, Navicat peut se connecter à Redis, ce qui permet aux utilisateurs de gérer les clés, d'afficher les valeurs, d'exécuter des commandes, de surveiller l'activité et de diagnostiquer les problèmes. Pour vous connecter à Redis, sélectionnez le type de connexion « Redis » dans Navicat et saisissez les détails du serveur.
 Comment trouver le fichier de mise à jour téléchargé par Win11_Partager l'emplacement du fichier de mise à jour téléchargé par Win11
May 08, 2024 am 10:34 AM
Comment trouver le fichier de mise à jour téléchargé par Win11_Partager l'emplacement du fichier de mise à jour téléchargé par Win11
May 08, 2024 am 10:34 AM
1. Tout d'abord, double-cliquez sur l'icône [Ce PC] sur le bureau pour l'ouvrir. 2. Double-cliquez ensuite sur le bouton gauche de la souris pour accéder à [Lecteur C]. Les fichiers système seront généralement automatiquement stockés dans le lecteur C. 3. Recherchez ensuite le dossier [windows] dans le lecteur C et double-cliquez pour entrer. 4. Après avoir accédé au dossier [windows], recherchez le dossier [SoftwareDistribution]. 5. Après avoir entré, recherchez le dossier [télécharger], qui contient tous les fichiers de téléchargement et de mise à jour Win11. 6. Si nous souhaitons supprimer ces fichiers, supprimez-les simplement directement dans ce dossier.
 Applications de mise en cache PHP Redis et bonnes pratiques
May 04, 2024 am 08:33 AM
Applications de mise en cache PHP Redis et bonnes pratiques
May 04, 2024 am 08:33 AM
Redis est un cache clé-valeur hautes performances. L'extension PHPRedis fournit une API pour interagir avec le serveur Redis. Suivez les étapes suivantes pour vous connecter à Redis, stocker et récupérer des données : Connecter : utilisez les classes Redis pour vous connecter au serveur. Stockage : utilisez la méthode set pour définir des paires clé-valeur. Récupération : utilisez la méthode get pour obtenir la valeur de la clé.
