


Recommandations d'apprentissage gratuites : Tutoriel vidéo Python
xpath – exemple de robot simple – extraire le fond d'écran original d'Onmyoji
Répertoire d'articles
1.
Beaucoup de gens ont joué à Onmyoji. Entre autres choses, les peintures originales d'Onmyoji sont assez détaillées. Pendant mon temps libre, je peux les explorer avec quelques lignes de code simples. c'est beau si tu l'enlèves ?
2. Les bibliothèques qui doivent être utilisées
import requestsfrom lxml import etreefrom fake_useragent import UserAgentimport os
Amis qui n'ont pas besoin d'installer des bibliothèques, vous pouvez jeter un œil à cet article que j'ai écrit auparavant, qui contient de nombreuses sources nationales sont liées pour faciliter votre téléchargement.
Portail
3. Processus de mise en œuvre
Ouvrez d'abord le site officiel, le portail du site officiel. , cliquez sur " "Fond d'écran de peinture originale" dans le Centre audiovisuel"
Après avoir accédé à la page Fond d'écran de peinture originale, sélectionnez un fond d'écran et vérifiez-le.
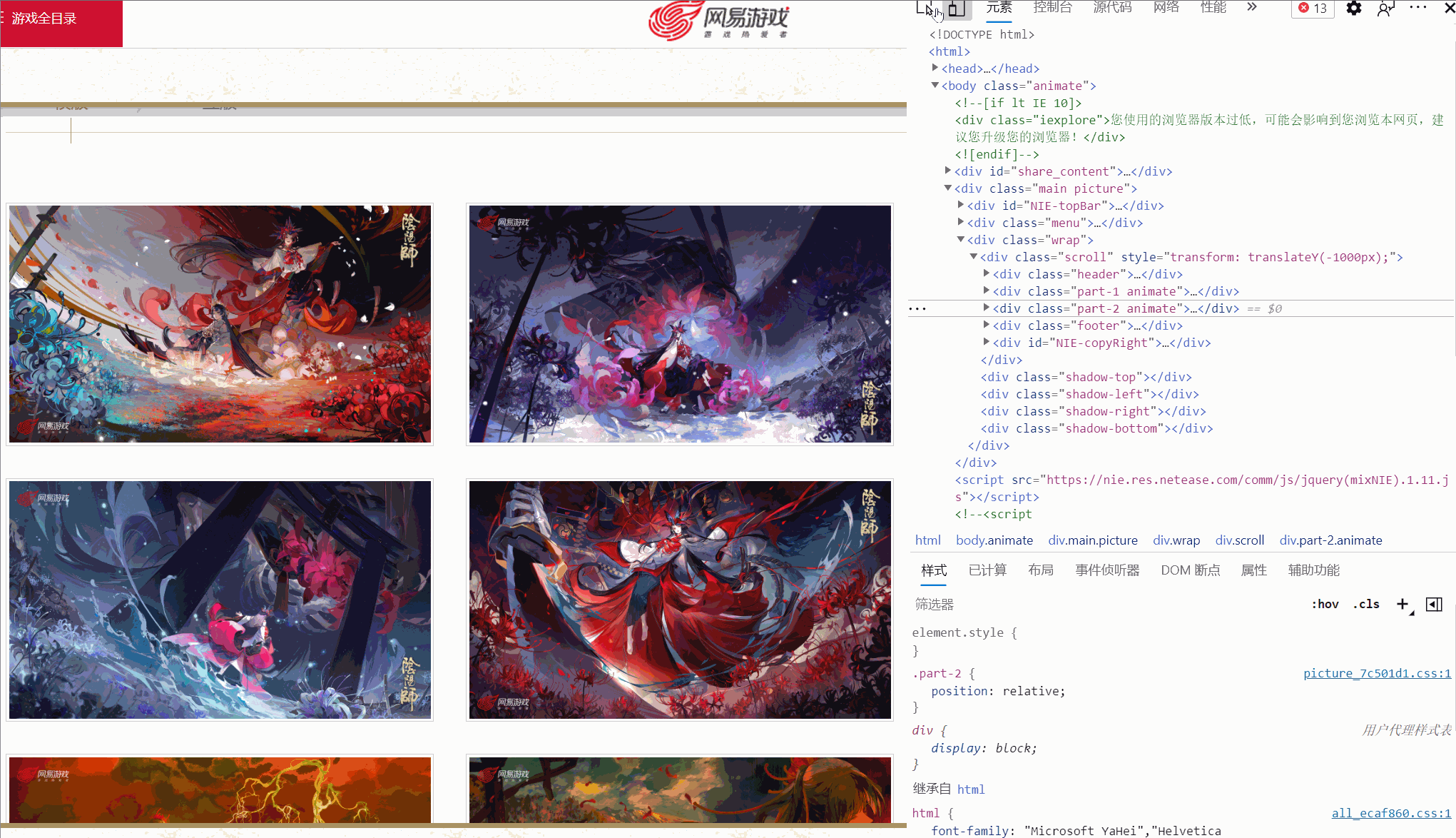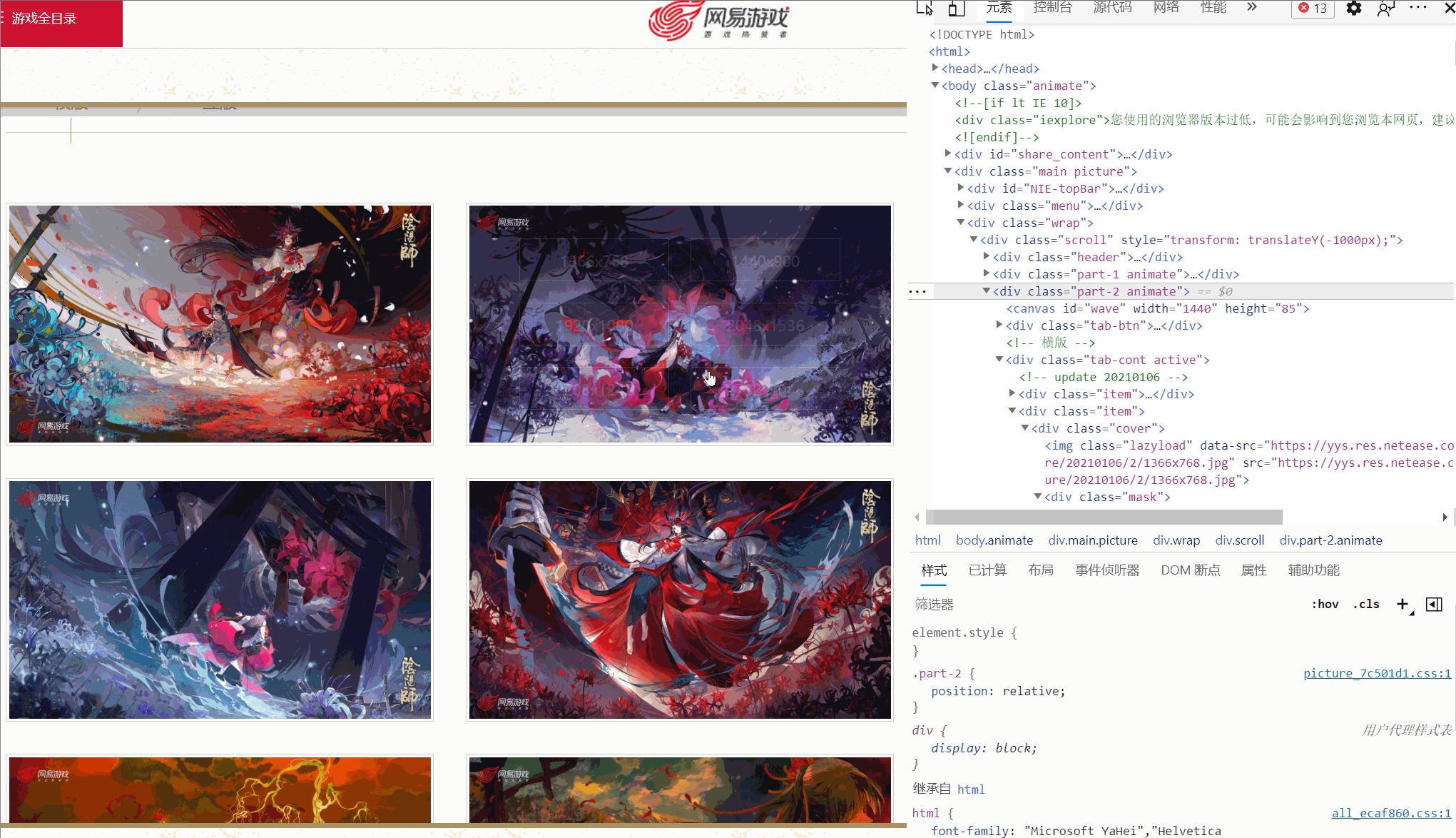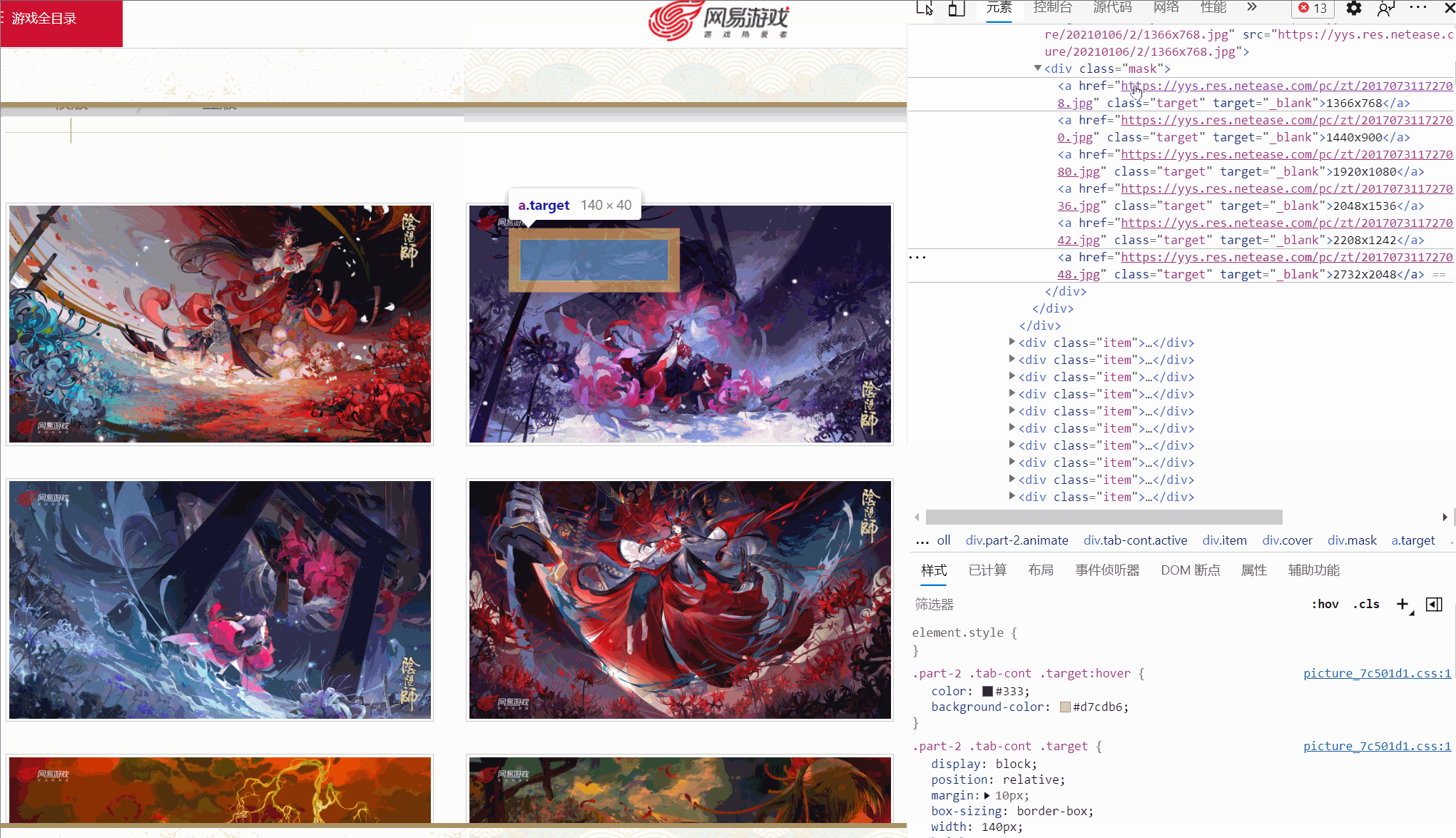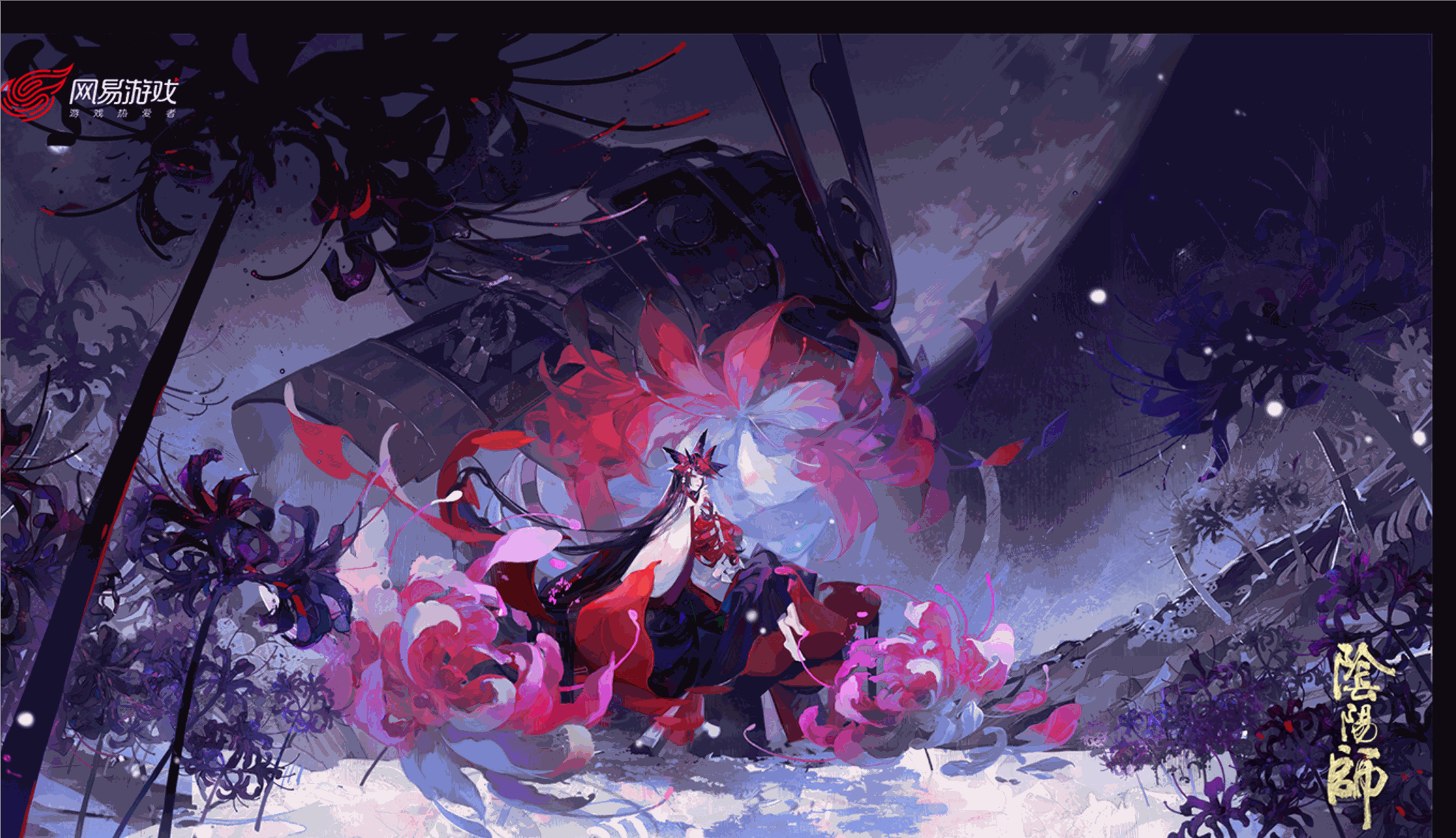
J'ai constaté qu'il existe différents liens correspondant à différentes résolutions, et l'image que j'ai vérifiée a six résolutions. Toutes les images sont-elles comme celle-ci ?
Plus tard, j'ai découvert que ce n'était pas le cas ! 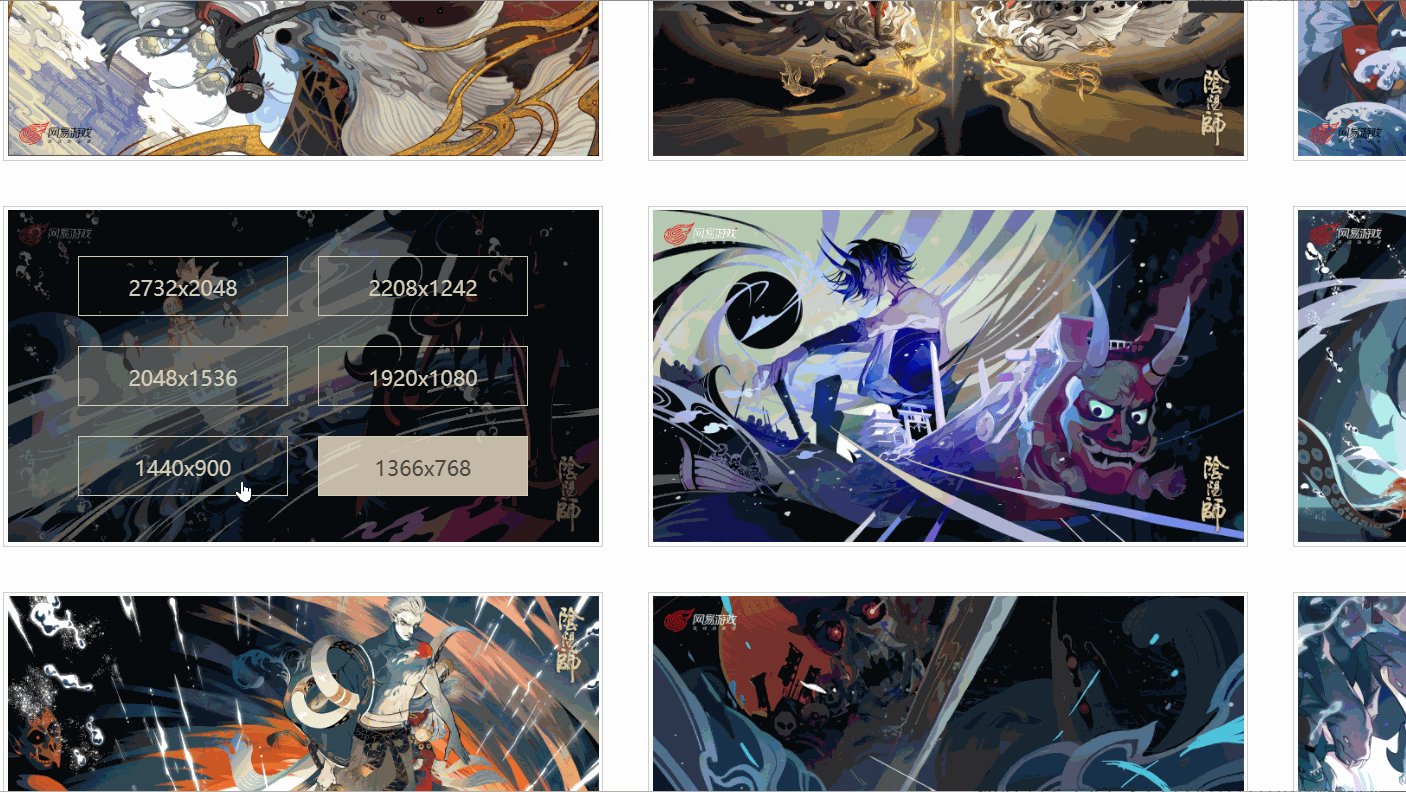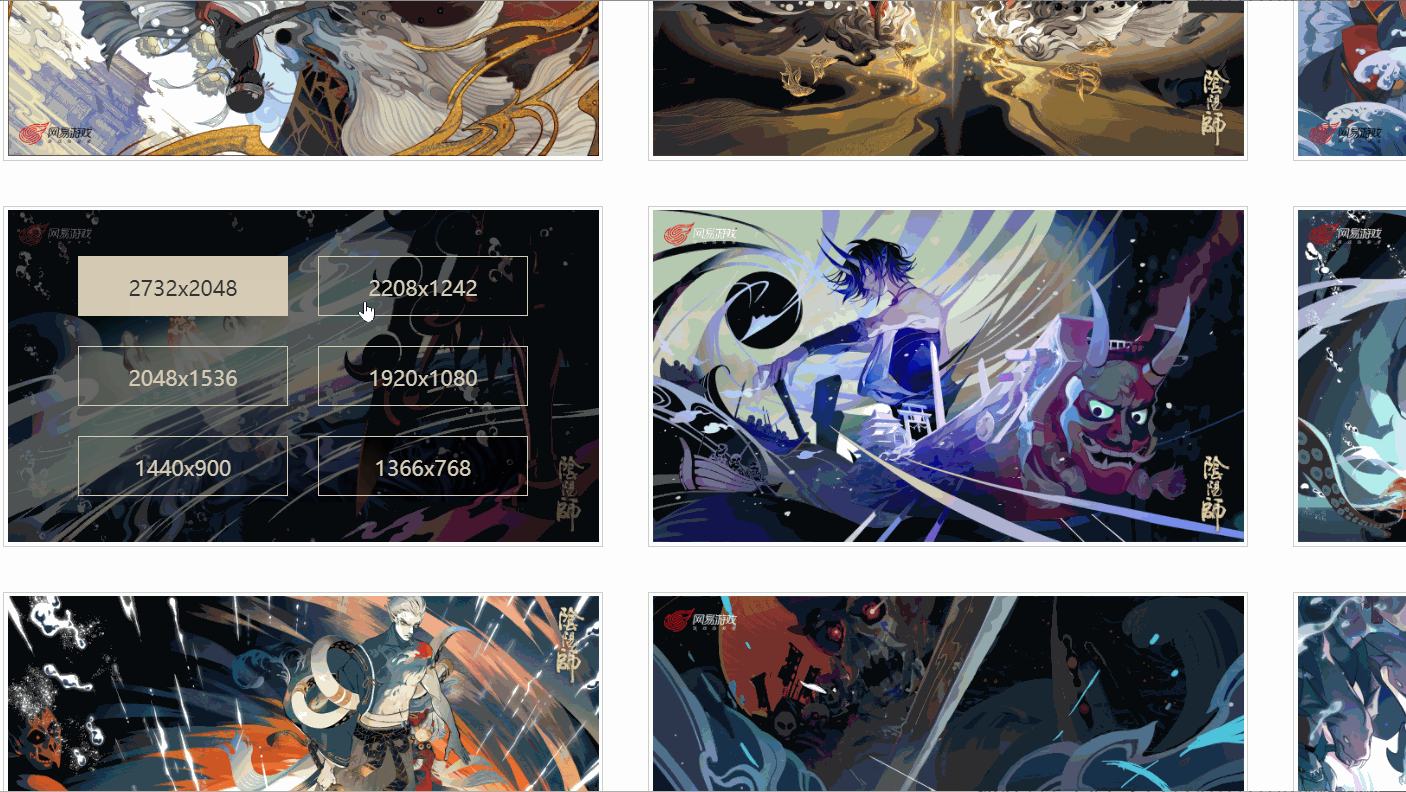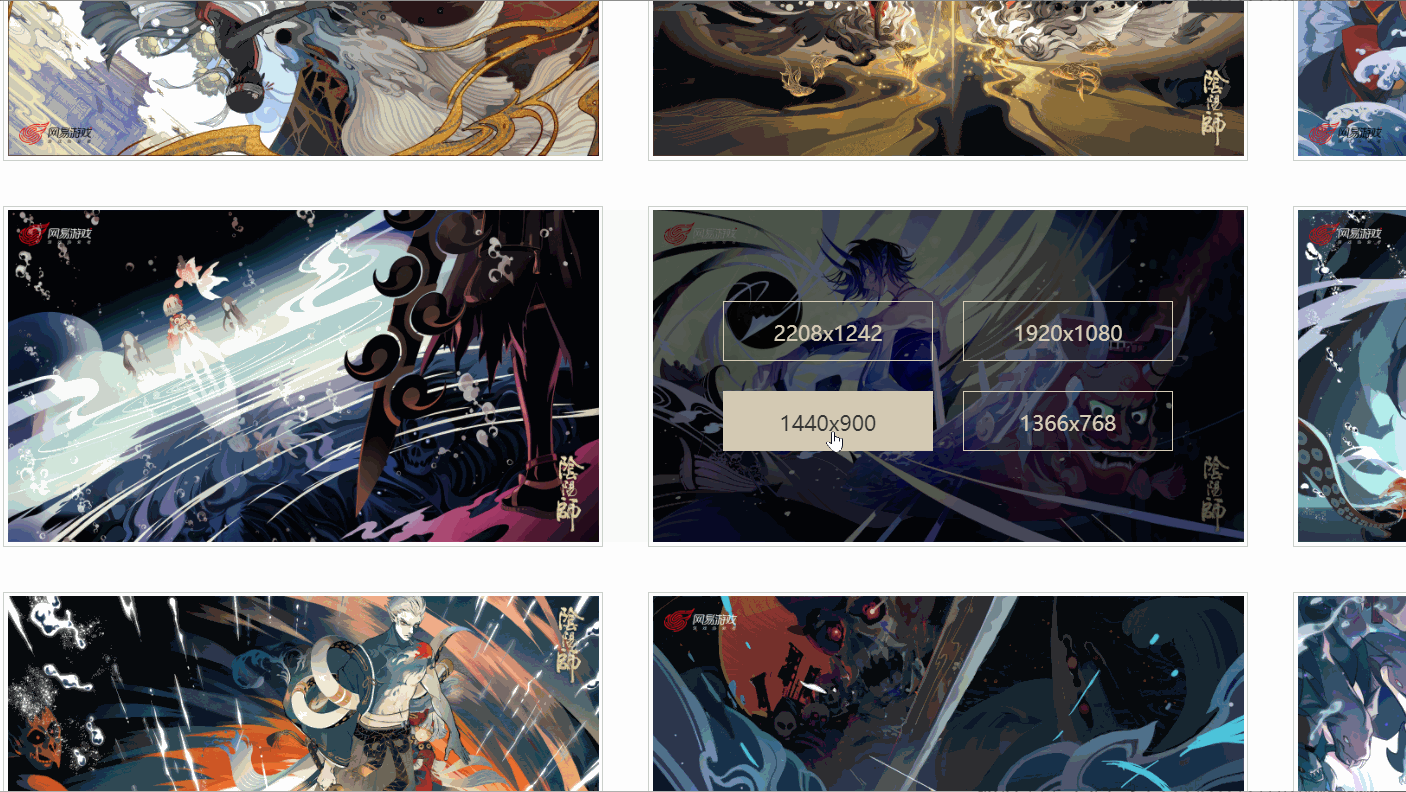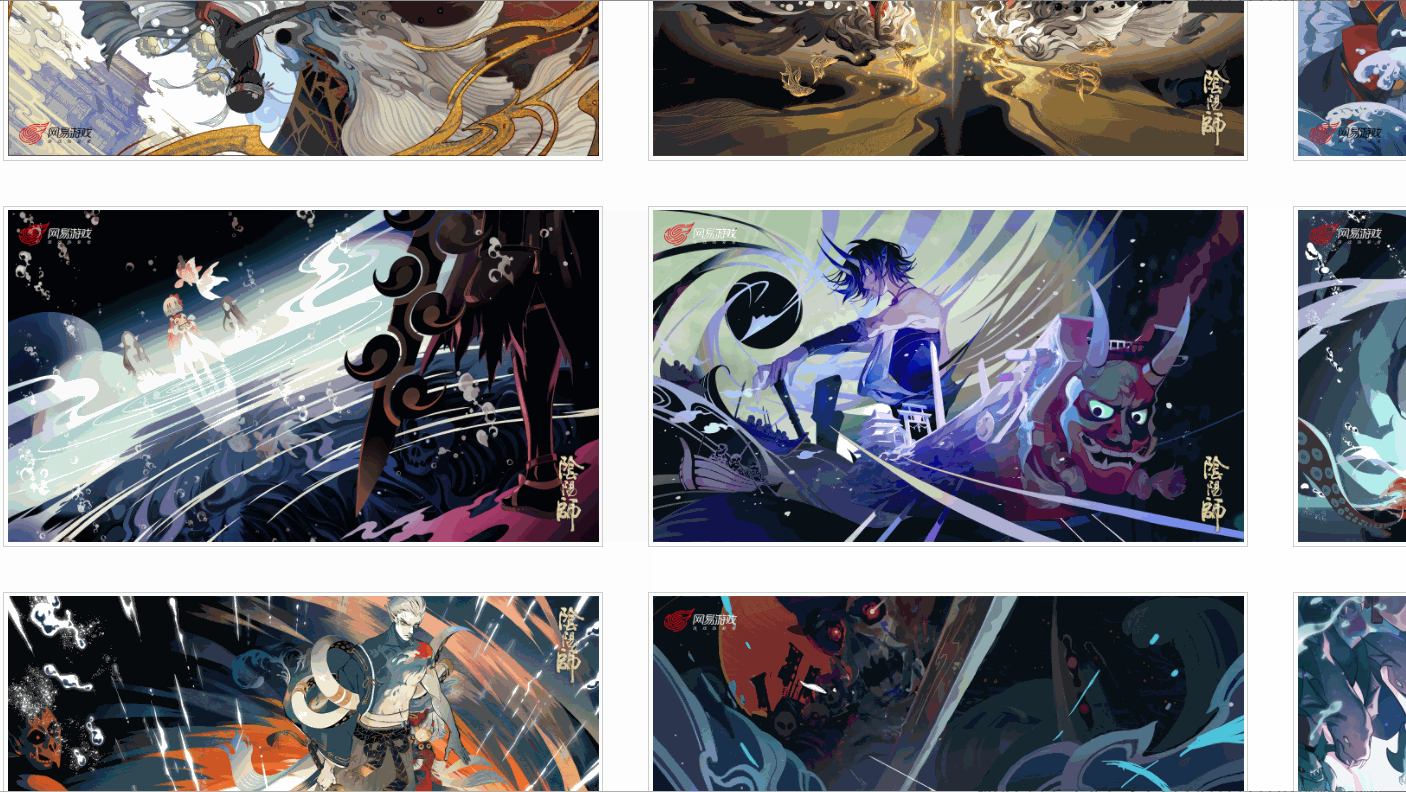
Comme indiqué ci-dessus, une image n'a même que quatre résolutions, et la résolution et la position de chaque image ne sont pas cohérentes. Alors, comment extraire le lien de la peinture originale ?
A : Utilisez XPath pour extraire des nœuds en fonction du contenu du texte
a = lists[i].xpath('./p/p/a[contains(text(), "1920x1080")]')[0]De cette façon, un nœud avec une résolution de "1920x1080" peut être extrait.
Q : Qu'est-ce que lists[i] ?
R : Vous le saurez après avoir lu le code complet.
import requestsfrom lxml import etreefrom fake_useragent import UserAgentimport os
path = 'D:/阴阳师'if not os.path.exists(path):
os.mkdir(path)# 随机产生请求头ua = UserAgent(verify_ssl=False, path='fake_useragent.json')url = 'https://yys.163.com/media/picture.html' # 原画壁纸的页面链接response = requests.get(url=url).text
html = etree.HTML(response)lists = html.xpath('/html/body/p[2]/p[3]/p[1]/p[3]/p[2]/p')num = 1for i in range(len(lists)):
a = lists[i].xpath('./p/p/a[contains(text(), "1920x1080")]')[0] # 根据文本内容锁定节点a
image_url = a.xpath('./@href')[0] # 获取原画壁纸链接
image_data = requests.get(url=image_url).content
image_name = '{}.jpg'.format(num) # 给每张图片命名
save_path = path + '/' + image_name # 图片的保存地址
with open(save_path, 'wb') as f:
f.write(image_data)
print(image_name, '=======================>下载成功!!!')
f.close()
num += 1Les résultats en cours sont les suivants :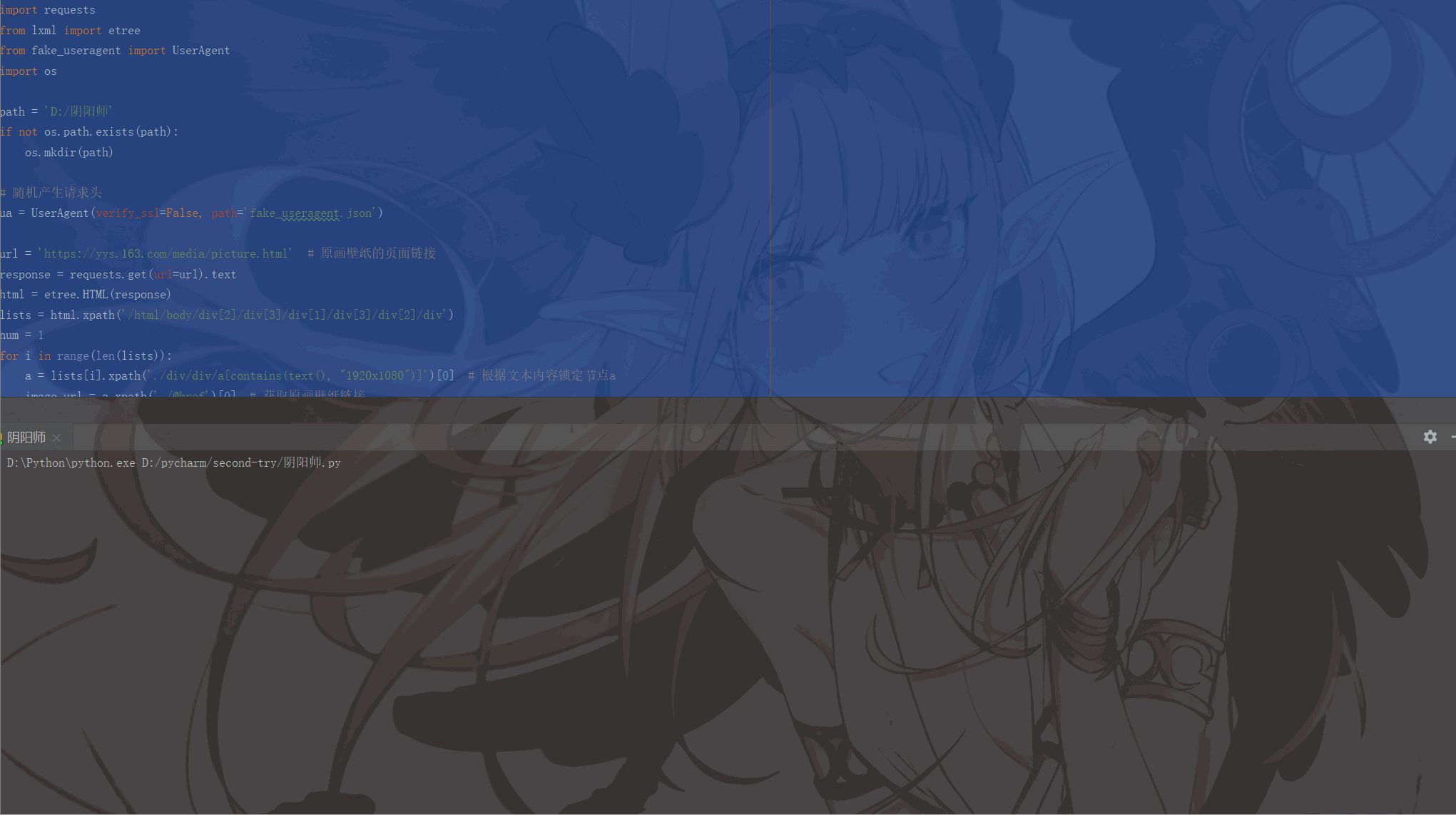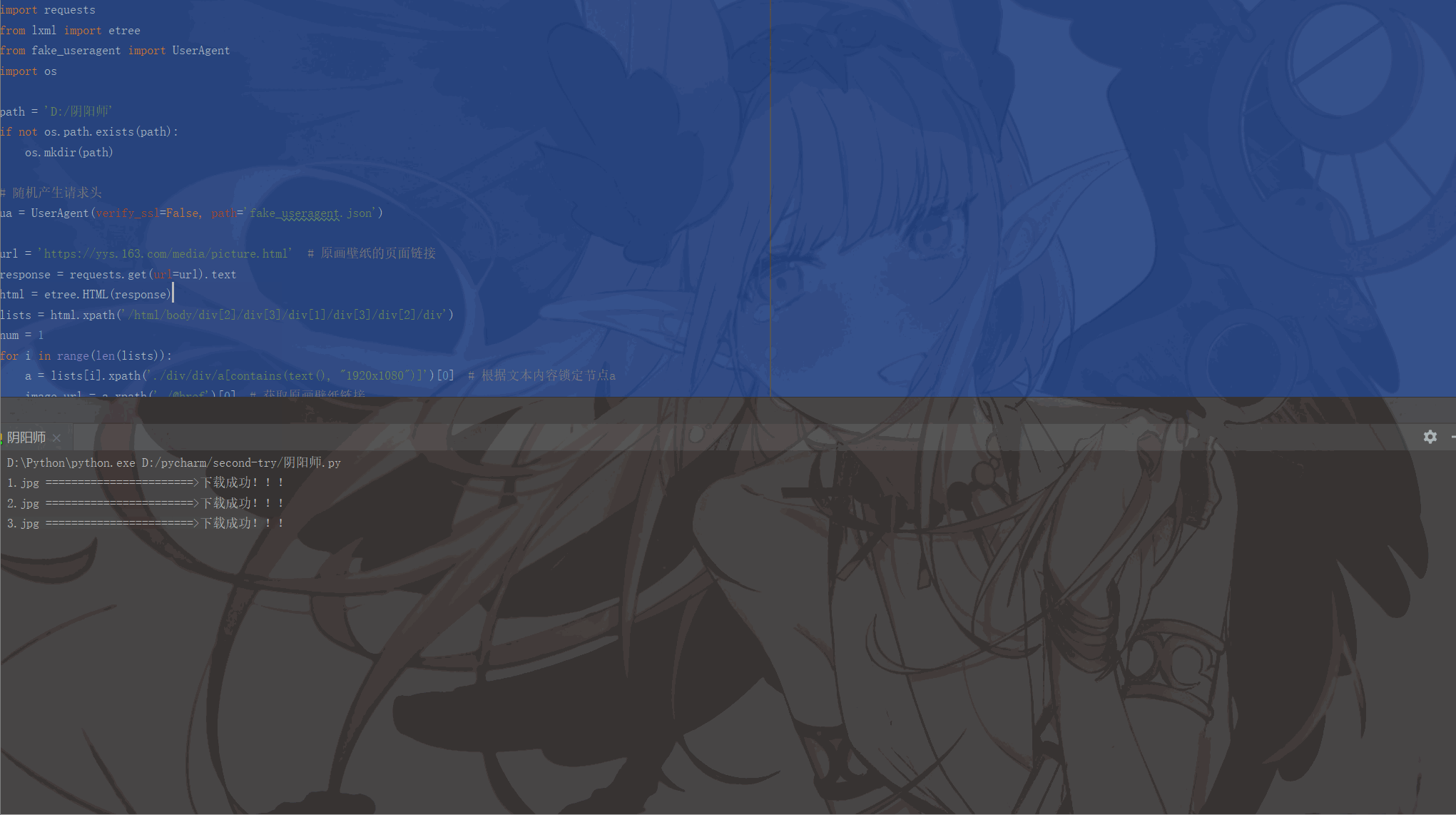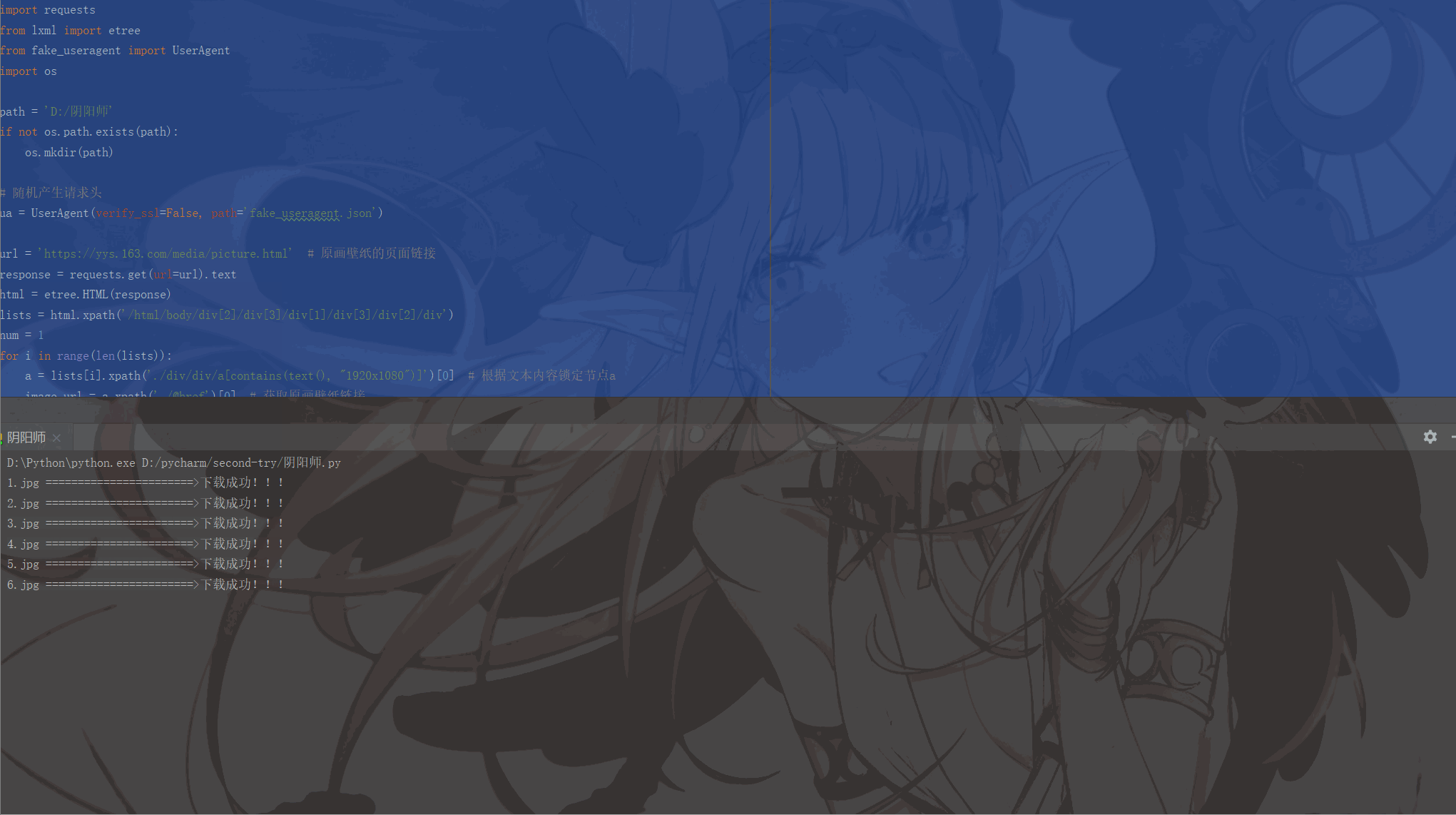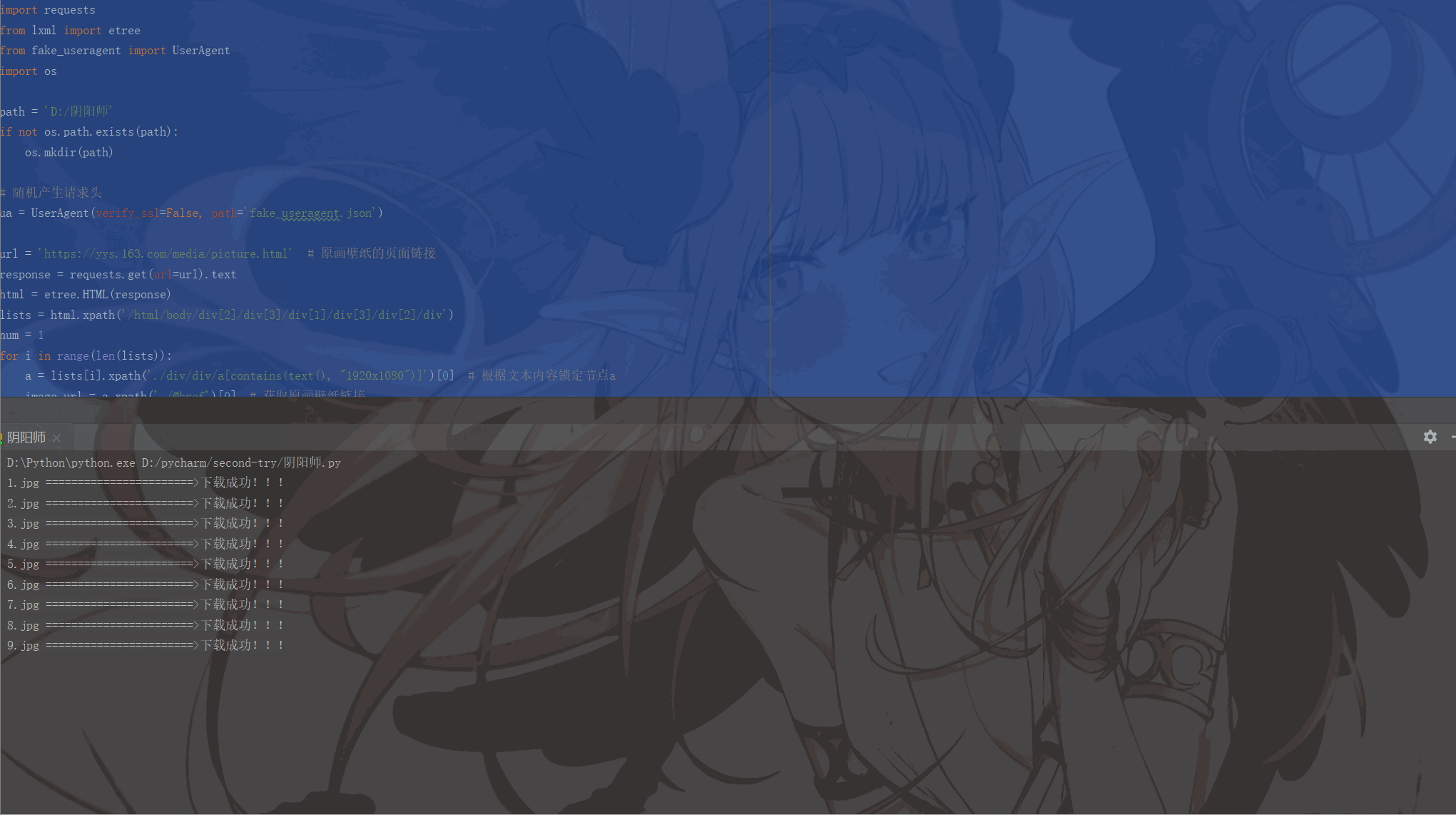

4.
En synthétisant la vidéo, vous pouvez lentement profiter de la peinture originale rampée, ce qui est très confortable.
Le code est le suivant :
import cv2import os# 输出视频的保存路径video_dir = 'D:/yinyangshi/result.mp4'# 帧率fps = 0.2# 图片尺寸img_size = (1920, 1080)fourcc = cv2.VideoWriter_fourcc('M', 'P', '4', 'V') # opencv3.0 mp4会有警告但可以播放videoWriter = cv2.VideoWriter(video_dir, fourcc, fps, img_size)img_files = os.listdir('D:/yinyangshi/')for i in range(1, 397):
img_path = 'D:/yinyangshi/tupian/' + '{}.jpg'.format(i)
frame = cv2.imread(img_path)
frame = cv2.resize(frame, img_size) # 生成视频 图片尺寸和设定尺寸相同
videoWriter.write(frame) # 写进视频里
print(f'======== 按照视频顺序第{i}张图片合进视频 ========')videoWriter.release() # 释放资源Remarque : lors de la composition d'une vidéo, le chemin de sauvegarde de l'image et le chemin de génération de la vidéo ne peuvent pas contenir de caractères chinois ! ! !
Une collection de peintures originales d'Onmyoji
Recommandations d'apprentissage gratuites associées : Tutoriel Python(vidéo)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!


















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



