


J'ai écrit beaucoup de code sur Internet sur les robots qui explorent les pages Web. Récemment, je souhaite enregistrer les robots que j'ai écrits pour la commodité de tous. . Bar!
Le code est divisé en 4 parties :
Partie 1 : Trouver un site Web.
我这里还是找了一个比较简单的网站,就是大家都知道的https://movie.douban.com/top250?start= 大家可以登录里面看一下。
Ici, vous pouvez avoir des bibliothèques qui n'ont pas été installées. L'image ci-dessus vous permettra d'installer les bibliothèques nécessaires pour explorer les pages Web. Parmi elles, les bibliothèques que j'ai utilisées cette fois sont : bs4, urllib, xlwt, re.
(Recommandation d'apprentissage gratuite : Tutoriel vidéo Python)
Comme le montre l'image
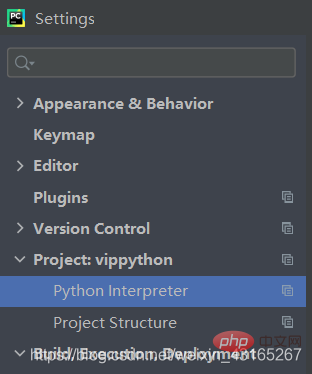
Sélectionnez le fichier ici -setting-Project-puis sélectionnez le signe plus dans le coin inférieur gauche et installez vous-même les fichiers dont vous avez besoin.
Le code suivant est le code source pour explorer les pages Web :
import urllib.requestfrom bs4 import BeautifulSoupimport xlwtimport redef main():
# 爬取网页
baseurl = 'https://movie.douban.com/top250?start='
datalist = getData(baseurl)
savepath = '豆瓣电影Top250.xls'
# 保存数据
saveData(datalist,savepath)
# askURL("https://movie.douban.com/top250?start=1")#影片详情的规则findLink = re.compile(r'<a>') #创建从正则表达式,表示规则findImgSrc = re.compile(r'<img class="title lazy" src="/static/imghw/default1.png" data-src="(.*?)" . alt="Introduction aux pages Web d'exploration Python" >(.*)')#影片的评分findReating = re.compile(r'<span>(.*)</span>')#找到评价人数findJudge = re.compile(r'<span>(\d*)人评价</span>')#找到概况findInq = re.compile(r'<span>(.*)</span>')#找到影片的相关内容findBb = re.compile(r'<p>(.*?)</p>', re.S)#re.S忽视换行符</a>Partie 2 : Explorer les pages Web.
def getData(baseurl):
datalist = []
for i in range(0, 10):
url = baseurl + str(i*25)
html = askURL(url) #保存获取到的网页源码
#对网页进行解析
soup = BeautifulSoup(html, 'html.parser')
for item in soup.find_all('p', class_="item"): #查找符合要求的字符串 形成列表
#print(item) #测试查看电影信息
data = []
item = str(item)
link = re.findall(findLink, item)[0] #re库用来查找指定的字符串
data.append(link)
imgSrc = re.findall(findImgSrc, item)[0]
data.append(imgSrc) #添加图片
titles = re.findall(finTitle, item) #
if (len(titles) == 2):
ctitle = titles[0] #添加中文名
data.append(ctitle)
otitle = titles[1].replace("/", "") #replace("/", "")去掉无关的符号
data.append(otitle) #添加英文名
else:
data.append(titles[0])
data.append(' ')#外国名字留空
rating = re.findall(findReating, item)[0] #添加评分
data.append(rating)
judgeNum = re.findall(findJudge,item) #评价人数
data.append(judgeNum)
inq = re.findall(findInq, item) #添加概述
if len(inq) != 0:
inq = inq[0].replace(".", "") #去掉句号
data.append(inq)
else:
data.append(" ") #留空
bd = re.findall(findBb,item)[0]
bd = re.sub('<br>(\s+)?',' ', bd) #去掉br 后面这个bd表示对bd进行操作
bd = re.sub('/', ' ', bd) #替换/
data.append(bd.strip()) #去掉前后的空格strip()
datalist.append(data) #把处理好的一部电影放入datalist当中
return datalistPartie 3 : Obtenez des informations d'URL spécifiées.
#得到指定的一个url网页信息def askURL(url):
head = {
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Mobile Safari/537.36"}
request = urllib.request.Request(url,headers=head) # get请求不需要其他的的,而post请求需要 一个method方法
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode('utf-8')
# print(html)
except Exception as e:
if hasattr(e,'code'):
print(e.code)
if hasattr(e,'reason'):
print(e.reason)
return htmlPartie 4 : Sauvegarde des données
# 3:保存数据def saveData(datalist,savepath):
book = xlwt.Workbook(encoding="utf-8", style_compression=0)
sheet = book.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True)
col = ('电影详情链接', '图片链接', '影片中文名', '影片外国名', '评分', '评价数', '概况', '相关信息')
for i in range(0,8):
sheet.write(0,i,col[i]) #列名
for i in range(0,250):
print("第%d条"%i)
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j])
book.save(savepath) #保存Ici, jetons un coup d'œil au code. Je l'ai écrit très clairement à propos de l'annotation du code.
Concernant l'apprentissage de ce robot, vous devez également apprendre quelques expressions régulières de base. Bien sûr, la syntaxe de base de Python est indispensable. J'espère qu'elle sera utile à tout le monde.
Recommandations d'apprentissage gratuites associées : Tutoriel Python(vidéo)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!



















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



