


Répertoire d'articles
(recommandation d'apprentissage gratuite : tutoriel vidéo Python )
urllib
urllib est une boîte à outils pour traiter les URL en Python, le code source Situé sous /Lib/. Il contient plusieurs modules : le module request pour ouvrir, lire et écrire des URL, le module request pour provoquer des exceptions provoquées par le module error, le module parse pour analyser les URL et le module response pour traitement des réponses. 🎜> module, robotparser module qui analyse le fichier robots.txt.
Notez les différences de version. urllib a 3 versions : Python2.X contient les modules urllib et urllib2, Python3 des kits d'outils tiers supplémentaires. Si vous rencontrez des problèmes tels que « Aucun module nommé urllib2 », cela est presque toujours dû à des versions différentes de Python. urlliburllib2urlparse est une bibliothèque Python avec des fonctions puissantes et des règles claires pour les clients HTTP. Il fournit de nombreuses fonctionnalités introuvables dans la bibliothèque standard Python : encodage par compression, pooling de connexions, sécurité des threads, authentification SSL/TLS, proxys HTTP et SCOCKS, etc. Vous pouvez l'installer via pip : urlliburllib3
Vous pouvez également télécharger le dernier code via GitHub : urllib3
git clone git://github.com/shazow/urllib3.git python setup.py install
pip install urllib3
urllib3
définit des fonctions et des classes pour l'ouverture d'URL dans l'authentification, la redirection, les cookies et autres applications .
Présentons brièvement le package. urllib.requestL'utilisation d'urllib3, qui hérite des fonctionnalités d'urllib2, prend en charge la rétention et le regroupement de connexions HTTP, prend en charge la conservation de session à l'aide de cookies, le téléchargement de fichiers, la décompression automatique, la réponse Unicode, le proxy HTTP(S), etc. Pour plus de détails, veuillez vous référer au document http://requests.readthedocs.io.
Ce qui suit présentera les fonctions et classes communes du module request. requestrequest
urllib.request
1
urllib.request.urlopen(url,data=None,[timeout,]*,cafile=None,capath=None,cadefault=false,context=None)
urlopen()①Paramètre URL
from urllib import requestwith request.urlopen("http://www.baidu.com") as f:
print(f.status)
print(f.getheaders())#运行结果如下200[('Bdpagetype', '1'), ('Bdqid', '0x8583c98f0000787e'), ('Cache-Control', 'private'), ('Content-Type', 'text/html;charset=utf-8'), ('Date', 'Fri, 19 Mar 2021 08:26:03 GMT'), ('Expires', 'Fri, 19 Mar 2021 08:25:27 GMT'), ('P3p', 'CP=" OTI DSP COR IVA OUR IND COM "'), ('P3p', 'CP=" OTI DSP COR IVA OUR IND COM "'), ('Server', 'BWS/1.1'), ('Set-Cookie', 'BAIDUID=B050D0981EE3A706D726852655C9FA21:FG=1; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com'), ('Set-Cookie', 'BIDUPSID=B050D0981EE3A706D726852655C9FA21; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com'), ('Set-Cookie', 'PSTM=1616142363; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com'), ('Set-Cookie', 'BAIDUID=B050D0981EE3A706FA20DF440C89F27F:FG=1; max-age=31536000; expires=Sat, 19-Mar-22 08:26:03 GMT; domain=.baidu.com; path=/; version=1; comment=bd'), ('Set-Cookie', 'BDSVRTM=0; path=/'), ('Set-Cookie', 'BD_HOME=1; path=/'), ('Set-Cookie', 'H_PS_PSSID=33272_33710_33690_33594_33600_33624_33714_33265; path=/; domain=.baidu.com'), ('Traceid', '161614236308368819309620754845011048574'), ('Vary', 'Accept-Encoding'), ('Vary', 'Accept-Encoding'), ('X-Ua-Compatible', 'IE=Edge,chrome=1'), ('Connection', 'close'), ('Transfer-Encoding', 'chunked')]②paramètre de donnéesRequest Si des données sont envoyées au serveur, le paramètre de données doit être un
doit contenir le paramètre Content-Length. Lorsque la requête HTTP utilise la méthode
, les données doivent avoir des données ; lors de l'utilisation de la méthode, les données peuvent être écrites sous la forme None.
from urllib import parsefrom urllib import request
data = bytes(parse.urlencode({"pro":"value"}),encoding="utf8")response = request.urlopen("http://httpbin.org/post",data=data)print(response.read())#运行结果如下b'{\n "args": {}, \n "data": "", \n "files": {}, \n "form": {\n "pro": "value"\n }, \n "headers": {\n "Accept-Encoding": "identity", \n "Content-Length": "9", \n "Content-Type": "application/x-www-form-urlencoded", \n "Host": "httpbin.org", \n "User-Agent": "Python-urllib/3.9", \n "X-Amzn-Trace-Id": "Root=1-60545f5e-7428b29435ce744004d98afa"\n }, \n "json": null, \n "origin": "112.48.80.243", \n "url": "http://httpbin.org/post"\n}\n'byes fait une headers demande de données et doit transcoder le type POST ou le type GET. Ici, est utilisé pour la conversion d'octets. Étant donné que le premier paramètre est une chaîne, vous devez utiliser la méthode du module d'analyse (discutée ci-dessous) pour convertir les données téléchargées en chaîne et spécifier l'encodage. formater en utf8. Le site Web de test httpbin.org peut fournir des tests HTTP. À partir du contenu renvoyé, nous pouvons voir que la soumission utilise le formulaire comme attribut et un dictionnaire comme valeur d'attribut. POSTbytes③paramètre timeoutiterable Ce paramètre est facultatif et spécifie un délai d'attente en secondes. Si ce temps est dépassé, toute opération sera bloquée. Si elle n'est pas spécifiée, la valeur par défaut sera bytes(). Ce paramètre n'est valide que pour les connexions http, https et ftp. urlencode()
from urllib import request
response = request.urlopen("http://httpbin.org/get",timeout=1)print(response.read())#运行结果如下b'{\n "args": {}, \n "headers": {\n "Accept-Encoding": "identity", \n "Host": "httpbin.org", \n "User-Agent": "Python-urllib/3.9", \n "X-Amzn-Trace-Id": "Root=1-605469dd-76a6d963171127c213d9a9ab"\n }, \n "origin": "112.48.80.243", \n "url": "http://httpbin.org/get"\n}\n'sock.GLOBAL_DEFAULT_TIMEOUT En plus des trois premiers paramètres communs, cette fonction renvoie un objet de type fichier utilisé comme gestionnaire de contexte (gestionnaire de contexte) et contient les méthodes suivantes :
geturl() : renvoie l'URL demandée. Généralement, l'URL redirigée peut toujours être obtenue. urlopen()info() : renvoie l'objet httplib.HTTPMessage, indiquant. l'URL renvoyée par le serveur distant. Informations d'en-tête
from urllib import request
response = request.urlopen("http://httpbin.org/get")print(response.geturl())print("===========")print(response.info())print("===========")print(response.getcode())print("===========")print(response.status)print("===========")print(response.msg)二、build_opener()
urllib.request.build_opener([handler1 [handler2, ...]])
该函数不支持验证、cookie及其他HTTP高级功能。要支持这些功能必须使用build_opener()函数自定义OpenerDirector对象,称之为Opener。
build_opener()函数返回的是OpenerDirector实例,而且是按给定的顺序链接处理程序的。作为OpenerDirector实例,可以从OpenerDirector类的定义看出他具有addheaders、handlers、handle_open、add_handler()、open()、close()等属性或方法。open()方法与urlopen()函数的功能相同。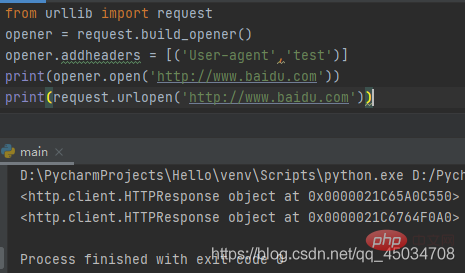
上述代码通过修改http报头进行HTTP高级功能操作,然后利用返回对象open()进行请求,返回结果与urlopen()一样,只是内存位置不同而已。
实际上urllib.request.urlopen()方法只是一个Opener,如果安装启动器没有使用urlopen启动,调用的就是OpenerDirector.open()方法。那么如何设置默认全局启动器呢?就涉及下面的install_opener函数。
三、install_opener()
urllib.request.install_opener(opener)
安装OpenerDirector实例作为默认全局启动器。
首先导入request模块,实例化一个HTTPBasicAuthHandler对象,然后通过利用add_password()添加用户名和密码来创建一个认证处理器,利用urllib.request.build_opener()方法来调用该处理器以构建Opener,并使其作为默认全局启动器,这样Opener在发生请求时具备了认证功能。通过Opener的open()方法打开链接完成认证。
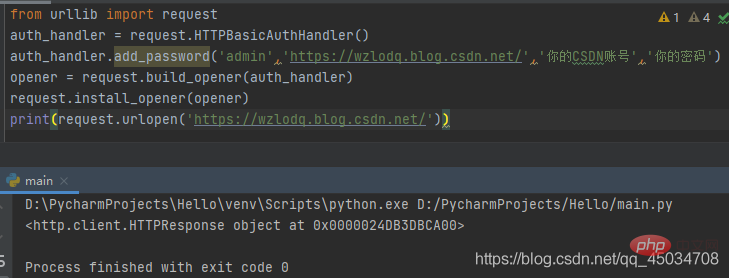
当然了,CSDN不需要账号密码也可以访问,读者还可以在其他网站上用自己的账号进行测试。
除了上述方法外,还有将路径转换为URL的pathname2url(path)、将URL转换为路径的url2pathname(path),以及返回方案至代理服务器URL映射字典的getproxies()等方法。
Request类
前面介绍的urlopen()方法可以满足一般基本URL请求,如果需要添加headers信息,就要考虑更为强大的Request类了。Request类是URL请求的抽象,包含了许多参数,并定义了一系列属性和方法。
一、定义
class urllib.request.Request(url,data=None,headers={},origin_req_host=None,unverifiable=False,method=None)urlopen()方法中一样,data参数也是。add_header()以键值进行调用。通常用于爬虫爬取数据时或者Web请求时更改User-Agent标头值参数来进行请求。代码示例:
from urllib import requestfrom urllib import parse
data = parse.urlencode({"name":"baidu"}).encode('utf-8')headers = {'User-Agent':'wzlodq'}req = request.Request(url="http://httpbin.org/post",data=data,headers=headers,method="POST")response = request.urlopen(req)print(response.read())#运行结果如下b'{\n "args": {}, \n "data": "", \n "files": {}, \n "form": {\n "name": "baidu"\n }, \n "headers": {\n "Accept-Encoding": "identity", \n "Content-Length": "10", \n "Content-Type": "application/x-www-form-urlencoded", \n "Host": "httpbin.org", \n "User-Agent": "wzlodq", \n "X-Amzn-Trace-Id": "Root=1-605491a4-1fcf3df01a8b3c3e22b5edce"\n }, \n "json": null, \n "origin": "112.48.80.34", \n "url": "http://httpbin.org/post"\n}\n'注意data参数和前面一样需是字节流类型的,不同的是调用Request类进行请求。
二、属性方法
①Request.full_url
full_url属性包含setter、getter和deleter。如果原始请求URL片段存在,那么得到的full_url将返回原始请求的URL片段,通过添加修饰器@property将原始URL传递给构造函数。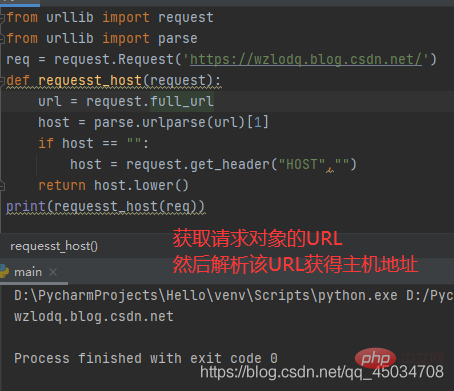
②Request.type:获取请求对象的协议类型。
③Request.host:获取URL主机,可能含有端口的主机。
④Request.origin_req_host:发出请求的原始主机,没有端口。
⑤Request.get_method():返回显示HTTP请求方法的字符串。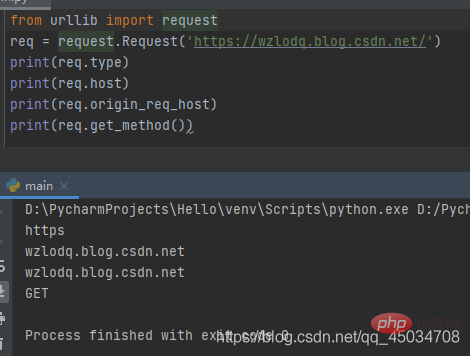
(插播反爬信息 )博主CSDN地址:https://wzlodq.blog.csdn.net/
⑥Request.add_header(key,val):向请求中添加标头。
from urllib import requestfrom urllib import parse
data = bytes(parse.urlencode({'name':'baidu'}),encoding='utf-8')req = request.Request('http://httpbin.org/post',data,method='POST')req.add_header('User-agent','test')response = request.urlopen(req)print(response.read().decode('utf-8'))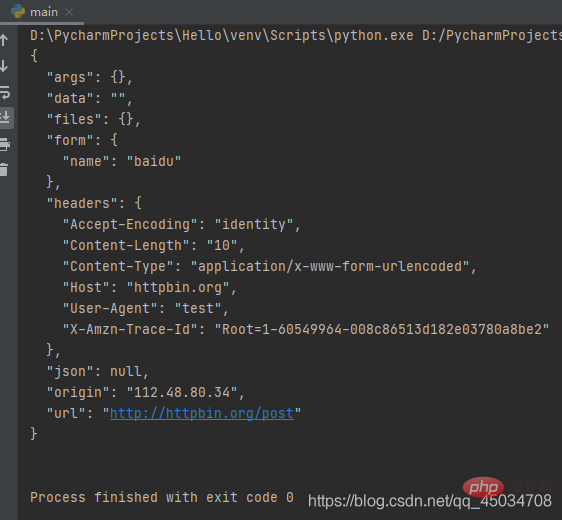
上述代码中,通过add_header()传入了User-Agent,在爬虫过程中,常常通过循环调用该方法来添加不同的User-Agent进行请求,避免服务器针对某一User-Agent的禁用。
其他类
BaseHandler为所有注册处理程序的基类,并且只处理注册的简单机制,从定义上看,BaseHandler提供了一个添加基类的add_parent()方法,后面介绍的类都是继承该类操作的。
parse模块
parse模块用于分解URL字符串为各个组成部分,包括寻址方案、网络位置、路径等,也可将这些部分组成URL字符串,同时可以对“相对URL"进行转换等。
解析URL
一、urllib.parse.urlparse(urlstring,scheme=’’,allow_fragments=True)
解析URL为6个部分,即返回一个6元组(tuple子类的实例),tuple类具有下标所示的属性:
| 属性 | 说明 | 对应下标指数 | 不存在时的取值 |
|---|---|---|---|
| scheme | URL方案说明符 0 | scheme参数 | |
| netloc | 网络位置部分 | 1 | 空字符串 |
| path | 分层路径 | 2 | 空字符串 |
| params | 最后路径元素的参数 | 3 | 空字符串 |
| query | 查询组件 | 4 | 空字符串 |
| fragment | 片段标识符 | 5 | 空字符串 |
| username | 用户名 | None | |
| password | 密码 | None | |
| hostname | 主机名 | None | |
| port | 端口号 | None |
最后组成的URL结构为scheme://netloc/path;parameters?query#fragment
举个栗子:
from urllib.parse import *res = urlparse('https://wzlodq.blog.csdn.net/article/details/113597816')print(res)print(res.scheme)print(res.netloc)print(res.path)print(res.params)print(res.query)print(res.username)print(res.password)print(res.hostname)print(res.port)print(res.geturl())print(tuple(res))print(res[0])print(res[1])print(res[2])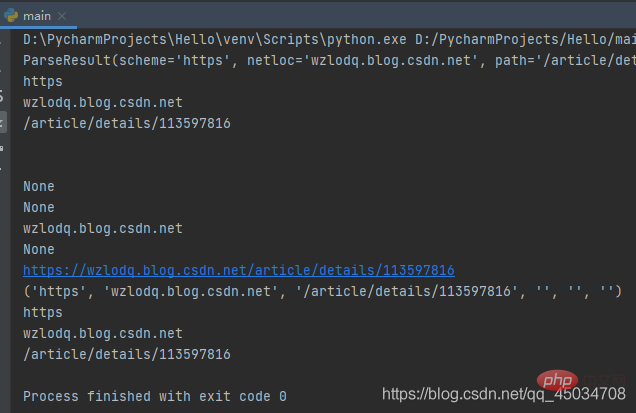
需要注意的是urlparse有时并不能很好地识别netloc,它会假定相对URL以路径分量开始,将其取值放在path中。
二、urllib.parse.urlunparse(parts)
是urlparse()的逆操作,即将urlparse()返回的原则构建一个URL。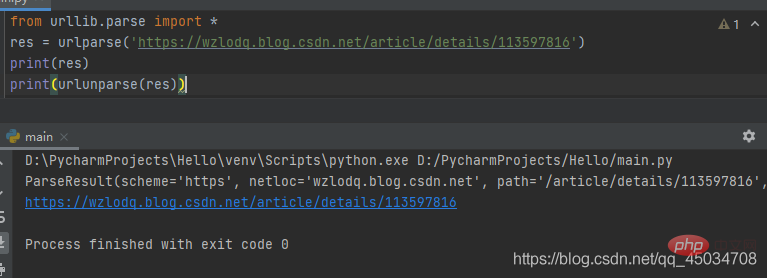
三、urllib.parse.urlsplit(urlstring,scheme=’’.allow_fragments=True)
类似urlparse(),但不会分离参数,即返回的元组对象没有params元素,是一个五元组,对应下标指数也发生了改变。
from urllib.parse import *sp = urlsplit('https://wzlodq.blog.csdn.net/article/details/113597816')print(sp)#运行结果如下SplitResult(scheme='https', netloc='wzlodq.blog.csdn.net', path='/article/details/113597816', query='', fragment='')四、urllib.parse.urlunsplit(parts)
类似urlunparse(),是urlsplit()的逆操作,不再赘述。
五、urllib.parse.urljoin(base,url,allow_fragments=True)
该函数主要组合基本网址(base)与另一个网址(url)以构建新的完整网址。
相对路径和绝对路径的url组合是不同的,而且相对路径是以最后部分路径进行替换处理的: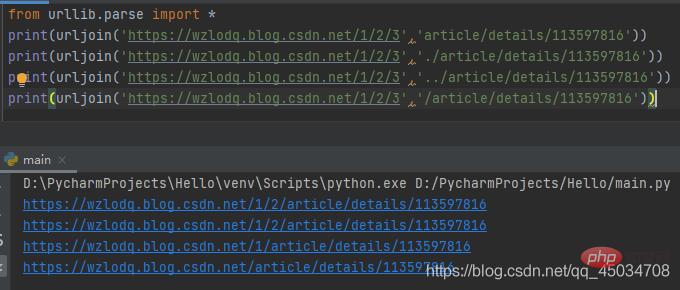
六、urllib.parse.urldefrag(url)
根据url进行分割,如果url包含片段标识符,就返回url对应片段标识符前的网址,fragment取片段标识符后的值。如果url没有片段标识符,那么fragment为空字符串。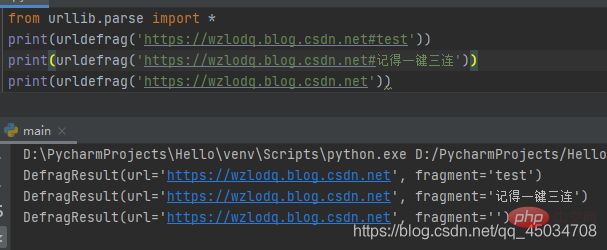
转义URL
URL转义可以避免某些字符引起歧义,通过引用特殊字符并适当编排非ASCII文本使其作为URL组件安全使用。同时也支持反转这些操作,以便从URL组件内容重新创建原始数据。
一、urllib.parse.quote(string,safe=’/’,encoding=None,errors=None)
使用%xx转义替换string中的特殊字符,其中字母、数字和字符’_.-‘不会进行转义。默认情况下,此函数用于转义URL的路径部分,可选的safe参数指定不应转义的其他ASCII字符——其默认值为’/’。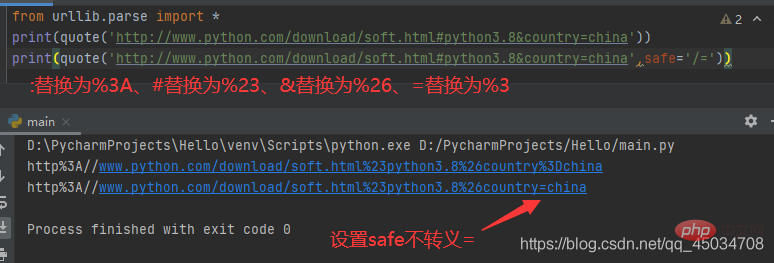
特别注意的是若string是bytes,encoding和errors就无法指定,否则报错TypeError。
二、urllib.parse.unquote(string,encoding=‘utf-8’,errors=‘replace’)
该函数时quote()的逆操作,即将%xx转义为等效的单字符。参数encoding和errors用来指定%xx编码序列解码为Unicode字符,同bytes.decode()方法。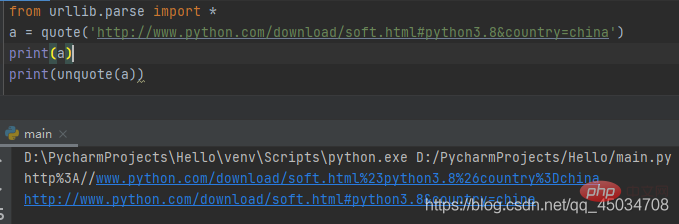
三、urllib.parse.quote_plus(string,safe=’’,encoding=None,errors=None)
该函数时quote()的增强版,与之不同的是用+替换空格,而且如果原始URL有字符,那么+将被转义。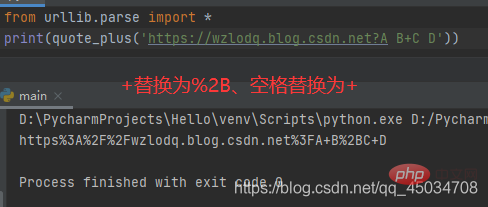
四、urllib.parse.unquote_plus(string,encoding=‘utf-8’,errors=‘replace’)
类似unquote(),不再赘述。
五、urllib.parse.urlencode(query,doseq=False,safe=’’,encoding=None,errors=None,quote_via=quote_plus)
该函数前面提到过,通常在使用HTTP进行POST请求传递的数据进行编码时使用。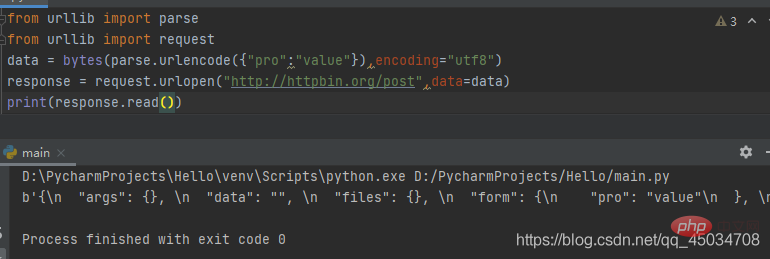
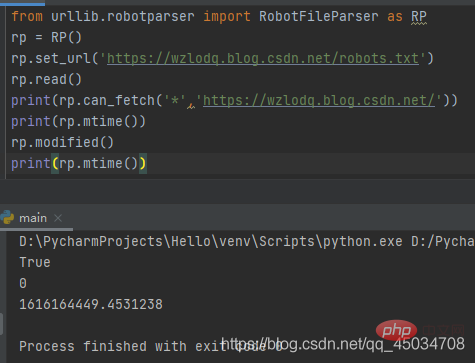
robots.txt文件
robotparser模块很简单,仅定义了3个类(RobotFileParser、RuleLine、Entry)。从__all__属性来看也就RobotFileParser一个类(用于处理有关特定用户代理是否可以发布robots.txt文件的网站上提前网址内容)。
robots文件类似一个协议文件,搜索引擎访问网站时查看的第一个文件,会告诉爬虫或者蜘蛛程序在服务器上可以查看什么文件。
RobotFileParser类有一个url参数,常用以下方法:
Un grand nombre de recommandations d'apprentissage gratuites, veuillez visiter le tutoriel Python(Vidéo)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!



















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



