

Quel est le cœur du Big Data

Le cœur du Big Data est la prédiction. L'essence du Big Data est de résoudre des problèmes, et la valeur fondamentale du Big Data est la prédiction ; le Big Data consiste à appliquer des algorithmes mathématiques aux données massives pour prédire la possibilité que des choses se produisent ; et les modèles de prédiction la probabilité que quelque chose se produise.

L'environnement d'exploitation de ce tutoriel : système Windows 7, ordinateur Dell G3.
Le cœur du Big Data est la prédiction. Il est souvent considéré comme faisant partie de l’intelligence artificielle, ou plutôt comme un type d’apprentissage automatique. Mais cette définition est trompeuse. Le Big Data ne consiste pas à apprendre aux machines à penser comme les humains.
Au contraire, il applique des algorithmes mathématiques à des quantités massives de données pour prédire la probabilité que quelque chose se produise. La probabilité qu'un e-mail soit filtré comme spam, la probabilité que le "teh" saisi soit "le", la probabilité qu'une personne puisse traverser la route à temps en fonction de la trajectoire et de la vitesse d'une personne traversant le jaywalk, sont toutes dans la plage que le big data peut prédire. Bien sûr, si une personne peut traverser la rue à temps, la voiture n’aura qu’à ralentir légèrement lorsqu’elle traverse la rue. La clé du succès de ces systèmes de prévision réside dans le fait qu’ils reposent sur des quantités massives de données. De plus, à mesure que les systèmes reçoivent de plus en plus de données, ils peuvent devenir suffisamment intelligents pour rechercher automatiquement les meilleurs signaux et modèles et s’améliorer.
Prédiction du Big Data (application principale du Big Data)
La prédiction du Big Data est l'application principale du Big Data, qui combine la prédiction traditionnelle "tests en direct". L’avantage de la prédiction du Big Data est qu’elle transforme un problème de prédiction très difficile en un problème de description relativement simple, qui est tout simplement hors de portée des petits ensembles de données traditionnels. Du point de vue de la prédiction, les résultats obtenus par la prédiction du Big Data ne sont pas seulement des conclusions simples et objectives utilisées pour traiter des affaires réelles, mais peuvent également être utilisés pour aider à prendre des décisions commerciales.
1. La prédiction est la valeur fondamentale du Big Data.
L'essence du Big Data est de résoudre des problèmes. La valeur fondamentale du Big Data réside dans la prédiction, et la. le cœur des opérations commerciales est également de porter des jugements corrects basés sur des prédictions. Lorsqu'on parle d'applications Big Data, les cas d'application les plus courants sont « prédire la bourse », « prédire la grippe », « prédire le comportement des consommateurs », etc.
La prédiction du Big Data est basée sur le Big Data et des modèles de prédiction pour prédire la probabilité de quelque chose dans le futur. La plus grande différence entre le big data et l'analyse traditionnelle des données réside dans le fait de déplacer l'analyse de « faire face au passé qui s'est produit » à « faire face à l'avenir qui est sur le point de se produire ».
La base logique de la prédiction du Big Data est que chaque changement non conventionnel doit avoir des signes au préalable, et tout a des traces à suivre. Si vous trouvez le modèle entre les signes et les changements, vous pouvez procéder à la prédiction. La prédiction du Big Data ne peut pas déterminer si quelque chose va se produire. Il s’agit plutôt de donner la probabilité qu’un événement se produise.
La répétition continue des expériences et l'accumulation croissante de big data permettent aux humains de découvrir en permanence divers modèles et ainsi d'être capables de prédire l'avenir. Utiliser le Big Data pour prédire d’éventuelles catastrophes, utiliser le Big Data pour analyser les causes possibles du cancer et trouver des traitements sont autant d’entreprises qui peuvent profiter à l’humanité à l’avenir.
Par exemple, les mégadonnées ont été utilisées par le département de police de Los Angeles et l'Université de Californie pour prédire la survenue d'un crime ; Google Flu Trends utilise des mots-clés de recherche pour prédire la propagation de la grippe aviaire ; le MIT utilise le téléphone portable ; données de localisation et données de trafic Réaliser la planification urbaine ; le Bureau météorologique rassemble les conditions météorologiques récentes et les images satellite des nuages pour évaluer plus précisément les conditions météorologiques futures.
2. Changements dans la réflexion sur la prédiction du Big Data
Dans le passé, la prise de décision des gens reposait principalement sur 20 % de données structurées, alors que la prédiction du Big Data pouvait utiliser 80 % supplémentaires des données non structurées sont utilisées pour prendre des décisions. La prédiction du Big Data comporte davantage de dimensions de données, une fréquence de données plus rapide et une largeur de données plus large. Par rapport à l’ère des petites données, la réflexion sur la prédiction des mégadonnées présente trois changements majeurs : des échantillons réels au lieu de l’efficacité de la prédiction par échantillonnage au lieu de la précision, plutôt que de la causalité ;
1) Des échantillons réels plutôt que des échantillonnages
À l'ère des petites données, en raison du manque de moyens pour obtenir tous les échantillons, les gens ont inventé la méthode des « données d'enquête aléatoires ». En théorie, plus un échantillon est tiré au hasard, plus il est représentatif de l’échantillon global. Mais le problème est que l’obtention d’un échantillon aléatoire est extrêmement coûteuse et prend beaucoup de temps. Les enquêtes démographiques en sont un exemple typique. Il est difficile pour un pays de réaliser une enquête démographique chaque année car les enquêtes aléatoires prennent trop de temps et demandent trop de main-d'œuvre. Cependant, l'émergence du cloud computing et de la technologie du big data permet d'obtenir des résultats importants. suffisamment d'échantillons de données et même la population entière devient possible.
2) L'efficacité plutôt que la précision
En raison de la méthode d'échantillonnage utilisée à l'ère des petites données, il est nécessaire d'être très précis dans le calcul spécifique des échantillons de données, sinon ce sera " une légère différence, mille milles manqués" ". Par exemple, si 1 000 personnes sont sélectionnées au hasard pour un recensement sur un échantillon total de 100 millions de personnes, s’il y a une erreur dans le calcul sur 1 000 personnes, l’écart sera très important lorsqu’on l’élargit à 100 millions de personnes. Mais dans le cas de l’échantillon complet, il y a autant d’écart qu’il y a, et il ne sera pas amplifié.
À l'ère du big data, obtenir rapidement une ébauche et un contexte de développement est bien plus important qu'une stricte précision. Parfois, lorsque nous disposons de grandes quantités de nouveaux types de données, la précision est moins importante car nous pouvons toujours avoir une idée de la façon dont les choses se déroulent. Les algorithmes simples basés sur le Big Data sont plus efficaces que les algorithmes complexes basés sur les petites données. Le but de l’analyse des données n’est pas seulement l’analyse des données, mais aussi la prise de décision, la rapidité est donc également très importante.
3) Corrélation plutôt que causalité
La recherche sur les mégadonnées est différente de la recherche traditionnelle sur le raisonnement logique. Elle nécessite une recherche statistique, une comparaison, un regroupement et une classification d'énormes quantités de données. faites attention à la corrélation ou à la corrélation des données. La corrélation fait référence à l'existence d'une certaine régularité entre les valeurs de deux ou plusieurs variables. Il n’y a pas d’absolu en matière de corrélation, seulement des possibilités. Cependant, si la corrélation est forte, la probabilité qu’elle réussisse est très élevée.
La corrélation nous aide à capturer le présent et à prédire l'avenir. Si A et B surviennent souvent ensemble, il suffit alors de noter que B se produit pour prédire que A se produira également.
Selon la corrélation, notre compréhension du monde n'a plus besoin d'être basée sur des hypothèses. Cette hypothèse fait référence à l'hypothèse établie pour un phénomène sur son mécanisme de production et son mécanisme interne. Nous n'avons donc pas besoin de faire d'hypothèses sur les termes de recherche qui indiquent quand et où la grippe se propage ; sur la manière dont les compagnies aériennes fixent les prix des vols ou sur les préférences culinaires des clients de Walmart ; Au lieu de cela, nous pouvons effectuer une analyse de corrélation sur les mégadonnées pour savoir quels termes de recherche sont les plus révélateurs de la propagation de la grippe, si le prix des billets d'avion va monter en flèche et quels aliments sont les plus recherchés par les personnes qui restent à la maison pendant les ouragans.
L'analyse de corrélation basée sur les données du Big Data remplace les méthodes sujettes aux erreurs basées sur des hypothèses. Les méthodes d’analyse de corrélation des Big Data sont plus précises, plus rapides et moins sujettes aux biais. La prédiction basée sur l’analyse de corrélation est au cœur du Big Data.
L'analyse de corrélation elle-même est d'une grande importance et jette également les bases de l'étude des relations causales. En identifiant les éléments qui peuvent être liés, nous pouvons nous appuyer sur ces données pour mener une analyse causale plus approfondie. S’il existe une relation causale, allez plus loin pour découvrir pourquoi. Ce mécanisme pratique réduit le coût de l’analyse causale grâce à des expériences rigoureuses. Nous pouvons également trouver des variables importantes issues des corrélations, qui peuvent être utilisées dans des expériences pour vérifier les relations causales.
3. Domaines d'application typiques de la prédiction du Big Data
Internet a facilité la vulgarisation des applications de prédiction du Big Data. Sur la base de cas nationaux et étrangers, ce qui suit. 11 Ce domaine est le domaine d’application de prédiction du Big Data le plus prometteur.
1) Prévisions météorologiques
Les prévisions météorologiques sont un domaine d'application typique de la prévision du Big Data. La granularité des prévisions météorologiques a été réduite de quelques jours à quelques heures, et les exigences en matière de délais sont strictes. Si les calculs sont effectués à l’aide de méthodes traditionnelles basées sur des données massives, demain sera déjà arrivé et les prédictions n’auront aucune valeur une fois les conclusions tirées. Cependant, le développement de la technologie du Big Data offre des capacités de calcul à grande vitesse, ce qui améliore considérablement l’efficacité. et l'exactitude des prévisions météorologiques.
2) Prédiction d'événements sportifs
Lors de la Coupe du monde 2014, des sociétés telles que Google, Baidu, Microsoft et Goldman Sachs ont toutes lancé des plateformes de prédiction des résultats de jeux. Les résultats des prédictions de Baidu sont les plus accrocheurs, avec une précision de prédiction de 67 % sur l'ensemble des 64 matchs et une précision de 94 % après le début des huitièmes de finale. Cela signifie que les futurs événements sportifs seront contrôlés par les prédictions du Big Data.
Les prévisions Google pour la Coupe du Monde sont basées sur les données massives d'événements d'Opta Sports pour construire le modèle de prédiction final. Baidu a recherché 37 000 données de jeux de 987 équipes (y compris les équipes nationales et les équipes de clubs) à travers le monde au cours des cinq dernières années
En même temps, il a coopéré avec le site de loterie chinois Lecai.com et l'European Betfair. Fournisseur de données d'index Grâce à la coopération en matière de données avec SPdex, la société a importé des données de prédiction du marché du jeu, a établi un modèle de prédiction comprenant 199 972 joueurs et 112 millions de données, et sur cette base, les résultats ont été prédits.
À en juger par l'expérience réussie des sociétés Internet, tant qu'il existe des données historiques sur les événements sportifs et une coopération avec les sociétés d'indexation, des prédictions sur d'autres événements, tels que la Ligue des Champions, la NBA et d'autres événements, peuvent être faites .
3) Prédiction du marché boursier
L'année dernière, une étude de la Warwick Business School au Royaume-Uni et du Département de physique de l'Université de Boston aux États-Unis a révélé que les mots-clés financiers recherchés par les utilisateurs sur Google pouvaient être capable de prédire la direction du marché financier. Les rendements de la stratégie d'investissement atteignent 326 %. Auparavant, certains experts essayaient de prédire les fluctuations du marché boursier à partir des sentiments exprimés dans les articles de blog Twitter.
4) Prévisions des prix du marché
L'IPC est utilisé pour caractériser les fluctuations de prix qui se sont produites, mais les données du Bureau des statistiques ne font pas autorité. Les mégadonnées peuvent aider les gens à comprendre la tendance future des prix et à prédire à l’avance l’inflation ou la crise économique. Le cas le plus typique est que Jack Ma a appris à l'avance la crise financière asiatique grâce au Big Data Alibaba B2B.
Il est plus facile de prédire le prix d'un seul produit, en particulier pour les produits standardisés tels que les billets d'avion. Le « calendrier des billets d'avion » fourni par « Qunar » est une prévision de prix, qui peut vous indiquer le prix approximatif. de billets d'avion en quelques mois.
Étant donné que la production, le coût de canalisation et la marge brute des biens sont relativement stables dans un marché pleinement concurrentiel, les variables liées au prix sont relativement fixes et la relation entre l'offre et la demande de biens peut être surveillée en temps réel sur l'e- plateforme de commerce, afin que le prix puisse être prédit. Sur la base des résultats des prédictions, des recommandations sur les délais d'achat peuvent être fournies, ou les commerçants peuvent être guidés pour mener des ajustements de prix dynamiques et des activités de marketing afin de maximiser les profits.
5) Prédiction du comportement des utilisateurs
Sur la base de données telles que le comportement de recherche des utilisateurs, le comportement de navigation, l'historique des commentaires et les informations personnelles, les entreprises Internet peuvent avoir un aperçu des besoins globaux des consommateurs, puis effectuer production, amélioration et commercialisation de produits ciblés. "House of Cards" sélectionne les acteurs et les intrigues, Baidu mène une publicité et un marketing précis en fonction des préférences des utilisateurs, Alibaba emballe des produits personnalisés pour la ligne de production en fonction des caractéristiques des utilisateurs de Tmall, et Amazon prédit le comportement des clics des utilisateurs et expédie les produits à l'avance, tout cela bénéficier de prédictions sur le comportement des internautes. Comme le montre la figure 1.
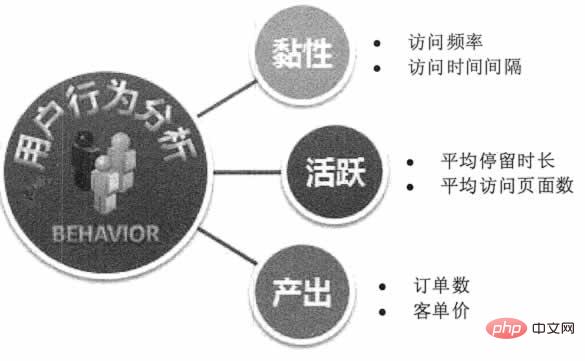
Figure 1 Prédiction du comportement des utilisateurs
Bénéficiant du développement de la technologie des capteurs et de l'Internet des objets, des informations sur le comportement des utilisateurs hors ligne se préparent. Le Wi-Fi commercial gratuit, la technologie iBeacon, la surveillance des images de caméra, la technologie de positionnement intérieur, le réseau de capteurs NFC et le système de file d'attente peuvent détecter les mouvements hors ligne, les séjours, les schémas de voyage et d'autres données des utilisateurs, afin d'effectuer un marketing précis ou une personnalisation des produits.
6) Prédiction de la santé humaine
La MTC peut découvrir certaines maladies chroniques cachées dans le corps humain en regardant, en sentant et en demandant, et peut même savoir quels symptômes une personne pourrait avoir à l'avenir en regardant à leur constitution physique. Les signes physiques du corps changent selon certaines règles, et le corps humain présentera déjà des anomalies persistantes avant l'apparition de maladies chroniques. Théoriquement, si le Big Data détecte de telles anomalies, il peut prédire les maladies chroniques.
Nature News & Views a rendu compte d'une étude de Zeevi et al. La question complexe de savoir comment la concentration de glucose dans le sang d'une personne est affectée par des aliments spécifiques. L'étude propose un modèle prédictif capable de fournir des recommandations alimentaires personnalisées basées sur les microbes présents dans l'intestin et d'autres aspects de la physiologie, et de prédire les réponses glycémiques avec plus de précision que les normes actuelles. Comme le montre la figure 2.
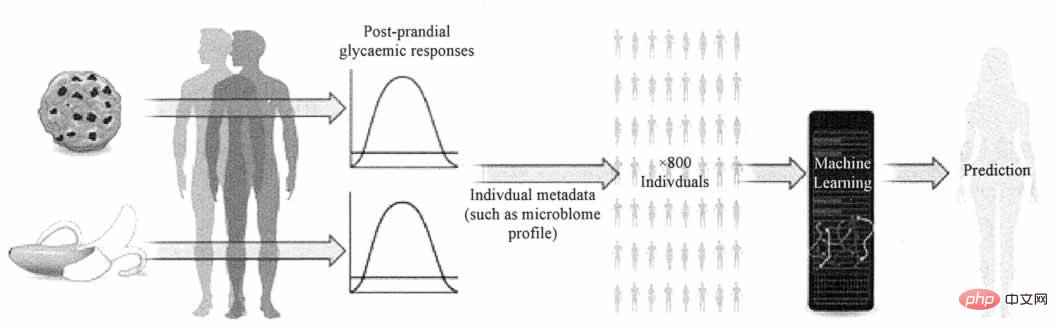
Figure 2 Modèle de prédiction de la concentration de glycémie
Le matériel intelligent rend possible la prédiction par mégadonnées des maladies chroniques. Les appareils portables et les appareils de santé intelligents peuvent aider le réseau à collecter des données sur la santé humaine, telles que la fréquence cardiaque, le poids, les lipides sanguins, la glycémie, la quantité d'exercice, la quantité de sommeil, etc. Si ces données sont suffisamment précises et complètes et disposent de modèles de prédiction des maladies chroniques capables de former des algorithmes, peut-être qu'à l'avenir, ces appareils portables rappelleront aux utilisateurs le risque de certaines maladies chroniques.
7) Prédiction des épidémies de maladies
La prédiction des épidémies de maladies fait référence à la prévision de la possibilité d'épidémies à grande échelle en fonction des conditions de recherche et des comportements d'achat des gens. La « prédiction de la grippe » la plus classique s'inscrit dans cette catégorie. catégorie . S'il y a de plus en plus de demandes de recherche pour « grippe » et « racine d'isatis » dans une certaine région, il est naturel de supposer qu'il y a une tendance à la grippe dans cette région.
Baidu a lancé un produit de prévision des maladies. Il peut actuellement analyser les graphiques d'activité et de tendance de chaque province du pays et de la plupart des villes, districts et comtés au niveau des préfectures pour quatre maladies : la grippe, l'hépatite, la tuberculose et la tuberculose. situation des maladies sexuellement transmissibles et effectuer une surveillance complète. À l'avenir, les types de maladies surveillés par Baidu Disease Prediction passeront de 4 actuellement à plus de 30, couvrant des maladies et des épidémies plus courantes. Les utilisateurs peuvent effectuer une prévention ciblée basée sur les résultats des prédictions locales.
8) Prédiction des catastrophes
La prévision météorologique est la prévision des catastrophes la plus courante. Si les catastrophes naturelles telles que les tremblements de terre, les inondations, les températures élevées et les fortes pluies peuvent être prédites et informées à l’avance grâce à la puissance des mégadonnées, cela contribuera à réduire, à prévenir et à fournir des secours en cas de catastrophe. Ce qui est différent du passé, c'est que les anciennes méthodes de collecte de données présentaient des problèmes tels que des impasses et des coûts élevés. À l'ère de l'Internet des objets, les gens peuvent utiliser des caméras à capteur bon marché et des réseaux de communication sans fil pour effectuer une surveillance et des données en temps réel. collecte, puis utilise l'analyse des prédictions du Big Data pour obtenir des prévisions plus précises des catastrophes naturelles.
9) Prédiction des changements environnementaux
En plus des prévisions micro-météo et des catastrophes à court terme, des prévisions de changements environnementaux et écologiques à plus long terme et macro peuvent également être faites. La diminution des superficies forestières et agricoles, la faune et la flore menacées, l'élévation du littoral et l'effet de serre sont des « problèmes chroniques » auxquels la planète est confrontée. Plus les humains disposeront de données sur les changements dans les écosystèmes et les conditions météorologiques de la Terre, plus il sera facile de modéliser les futurs changements environnementaux et d'éviter que de mauvais changements ne se produisent. Les mégadonnées peuvent aider les humains à collecter, stocker et exploiter davantage de données terrestres, tout en fournissant également des outils de prédiction.
10) Prédiction du comportement de la circulation
La prédiction du comportement de la circulation fait référence à la prédiction du comportement de la circulation basée sur les données de positionnement LBS des utilisateurs et des véhicules, analysant les caractéristiques individuelles et de groupe des personnes et des véhicules voyageant. Le service des transports peut effectuer une planification intelligente des véhicules ou appliquer des voies de marée en prédisant le flux de circulation sur différentes routes à différents moments. Les utilisateurs peuvent choisir des routes présentant une probabilité de congestion plus faible en fonction des résultats de la prévision.
La prédiction LBS de Baidu basée sur des applications cartographiques couvre une gamme plus large. Il peut prédire les tendances migratoires des personnes pendant la Fête du Printemps pour guider la configuration des lignes et des itinéraires de train. Il peut prédire le flux de personnes dans les sites pittoresques pendant les vacances pour guider la sélection des sites pittoresques par les gens. Il dispose également de cartes thermiques Baidu pour informer les utilisateurs. les quartiers d’affaires de la ville, les zoos et d’autres lieux. Le flux de personnes peut guider les choix de voyage des utilisateurs et la sélection de l’emplacement des entreprises.
11) Prévisions de consommation d'énergie
Le centre d'exploitation du système de réseau de l'État de Likou gère plus de 80 % du réseau électrique de Californie, fournissant 289 millions de mégawatts d'électricité à 35 millions d'utilisateurs chaque année, et l'électricité la longueur de la ligne dépasse 40 000 km. Le centre utilise le logiciel Space-Time Insight pour une gestion intelligente, analyse de manière exhaustive des données massives provenant de diverses sources de données telles que la météo, les capteurs et les équipements de mesure, prédit les changements dans la demande d'énergie à divers endroits, effectue une répartition intelligente de l'énergie et équilibre l'alimentation électrique des l’ensemble du réseau et des besoins, et réagir rapidement aux crises potentielles. L'industrie chinoise des réseaux intelligents teste déjà des applications similaires de prévision du Big Data.
En plus des 11 domaines répertoriés ci-dessus, la prédiction du Big Data peut également être appliquée à la prédiction de l'immobilier, à la prédiction de la situation de l'emploi, à la prédiction des résultats à l'examen d'entrée à l'université, à la prédiction des résultats des élections, à la prédiction des Oscars, à l'évaluation des risques des assurés, finance Dans des domaines tels que l'évaluation de la capacité de remboursement des emprunteurs, les humains ont la capacité d'acquérir des informations quantifiables, convaincantes et vérifiables sur l'avenir, et le charme de la prédiction du Big Data se déchaîne.
Pour plus de connaissances connexes, veuillez visiter la colonne FAQ !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Compétences de traitement de structures de données volumineuses de PHP
May 08, 2024 am 10:24 AM
Compétences de traitement de structures de données volumineuses de PHP
May 08, 2024 am 10:24 AM
Compétences en matière de traitement de la structure des Big Data : Chunking : décomposez l'ensemble de données et traitez-le en morceaux pour réduire la consommation de mémoire. Générateur : générez des éléments de données un par un sans charger l'intégralité de l'ensemble de données, adapté à des ensembles de données illimités. Streaming : lisez des fichiers ou interrogez les résultats ligne par ligne, adapté aux fichiers volumineux ou aux données distantes. Stockage externe : pour les ensembles de données très volumineux, stockez les données dans une base de données ou NoSQL.
 Partage d'expérience en développement C++ : Expérience pratique en programmation Big Data C++
Nov 22, 2023 am 09:14 AM
Partage d'expérience en développement C++ : Expérience pratique en programmation Big Data C++
Nov 22, 2023 am 09:14 AM
À l'ère d'Internet, le Big Data est devenu une nouvelle ressource. Avec l'amélioration continue de la technologie d'analyse du Big Data, la demande de programmation Big Data est devenue de plus en plus urgente. En tant que langage de programmation largement utilisé, les avantages uniques du C++ dans la programmation Big Data sont devenus de plus en plus importants. Ci-dessous, je partagerai mon expérience pratique dans la programmation Big Data C++. 1. Choisir la structure de données appropriée Le choix de la structure de données appropriée est une partie importante de l'écriture de programmes Big Data efficaces. Il existe une variété de structures de données en C++ que nous pouvons utiliser, telles que des tableaux, des listes chaînées, des arbres, des tables de hachage, etc.
 Cinq tendances majeures de développement dans l'industrie AEC/O en 2024
Apr 19, 2024 pm 02:50 PM
Cinq tendances majeures de développement dans l'industrie AEC/O en 2024
Apr 19, 2024 pm 02:50 PM
AEC/O (Architecture, Engineering & Construction/Operation) fait référence aux services complets qui assurent la conception architecturale, la conception technique, la construction et l’exploitation dans le secteur de la construction. En 2024, l’industrie de l’AEC/O est confrontée à des défis changeants au milieu des progrès technologiques. Cette année devrait voir l’intégration de technologies avancées, annonçant un changement de paradigme dans la conception, la construction et l’exploitation. En réponse à ces changements, les industries redéfinissent les processus de travail, ajustent les priorités et renforcent la collaboration pour s'adapter aux besoins d'un monde en évolution rapide. Les cinq tendances majeures suivantes dans l'industrie AEC/O deviendront des thèmes clés en 2024, lui recommandant d'évoluer vers un avenir plus intégré, réactif et durable : chaîne d'approvisionnement intégrée, fabrication intelligente.
 Application d'algorithmes dans la construction de 58 plateformes de portraits
May 09, 2024 am 09:01 AM
Application d'algorithmes dans la construction de 58 plateformes de portraits
May 09, 2024 am 09:01 AM
1. Contexte de la construction de la plateforme 58 Portraits Tout d'abord, je voudrais partager avec vous le contexte de la construction de la plateforme 58 Portraits. 1. La pensée traditionnelle de la plate-forme de profilage traditionnelle ne suffit plus. La création d'une plate-forme de profilage des utilisateurs s'appuie sur des capacités de modélisation d'entrepôt de données pour intégrer les données de plusieurs secteurs d'activité afin de créer des portraits d'utilisateurs précis. Elle nécessite également l'exploration de données pour comprendre le comportement et les intérêts des utilisateurs. et besoins, et fournir des capacités côté algorithmes ; enfin, il doit également disposer de capacités de plate-forme de données pour stocker, interroger et partager efficacement les données de profil utilisateur et fournir des services de profil. La principale différence entre une plate-forme de profilage d'entreprise auto-construite et une plate-forme de profilage de middle-office est que la plate-forme de profilage auto-construite dessert un seul secteur d'activité et peut être personnalisée à la demande. La plate-forme de mid-office dessert plusieurs secteurs d'activité et est complexe ; modélisation et offre des fonctionnalités plus générales. 2.58 Portraits d'utilisateurs de l'arrière-plan de la construction du portrait sur la plate-forme médiane 58
 Discussion sur les raisons et les solutions au manque de framework Big Data en langage Go
Mar 29, 2024 pm 12:24 PM
Discussion sur les raisons et les solutions au manque de framework Big Data en langage Go
Mar 29, 2024 pm 12:24 PM
À l’ère actuelle du Big Data, le traitement et l’analyse des données sont devenus un support important pour le développement de diverses industries. En tant que langage de programmation doté d'une efficacité de développement élevée et de performances supérieures, le langage Go a progressivement attiré l'attention dans le domaine du big data. Cependant, par rapport à d'autres langages tels que Java, Python, etc., le langage Go prend en charge relativement mal les frameworks Big Data, ce qui a causé des problèmes à certains développeurs. Cet article explorera les principales raisons du manque de framework Big Data dans le langage Go, proposera des solutions correspondantes et l'illustrera avec des exemples de code spécifiques. 1. Allez dans la langue
 Premiers pas : utiliser le langage Go pour traiter le Big Data
Feb 25, 2024 pm 09:51 PM
Premiers pas : utiliser le langage Go pour traiter le Big Data
Feb 25, 2024 pm 09:51 PM
En tant que langage de programmation open source, le langage Go a progressivement reçu une attention et une utilisation généralisées ces dernières années. Il est privilégié par les programmeurs pour sa simplicité, son efficacité et ses puissantes capacités de traitement simultané. Dans le domaine du traitement du Big Data, le langage Go a également un fort potentiel. Il peut être utilisé pour traiter des données massives, optimiser les performances et peut être bien intégré à divers outils et frameworks de traitement du Big Data. Dans cet article, nous présenterons quelques concepts et techniques de base du traitement du Big Data en langage Go, et montrerons comment utiliser le langage Go à travers des exemples de code spécifiques.
 IA, jumeaux numériques, visualisation... Points forts de la conférence de lancement de produit d'automne 2023 de Yizhiwei !
Nov 14, 2023 pm 05:29 PM
IA, jumeaux numériques, visualisation... Points forts de la conférence de lancement de produit d'automne 2023 de Yizhiwei !
Nov 14, 2023 pm 05:29 PM
Le lancement du produit d'automne 2023 de Yizhiwei s'est terminé avec succès ! Revoyons ensemble les moments forts de la conférence ! 1. Une ouverture intelligente et inclusive, permettant aux jumeaux numériques de devenir productifs Ning Haiyuan, co-fondateur de Kangaroo Cloud et PDG de Yizhiwei, a déclaré dans son discours d'ouverture : Lors de la réunion stratégique de l'entreprise de cette année, nous avons positionné l'orientation principale de la recherche et du développement de produits comme « Ouverture intelligente et inclusive » « Trois capacités principales, en nous concentrant sur les trois mots-clés fondamentaux de « l'ouverture intelligente et inclusive », nous avons en outre proposé l'objectif de développement consistant à « faire des jumeaux numériques une force productive ». 2. EasyTwin : explorez un nouveau moteur de jumeau numérique plus facile à utiliser 1. De la version 0.1 à 1.0, continuez à explorer le moteur de rendu de fusion jumelle numérique pour obtenir de meilleures solutions avec un mode d'édition 3D mature, des plans interactifs pratiques et des ressources de modèle massives.
 Golang et big data : une adéquation parfaite ou en contradiction ?
Mar 05, 2024 pm 01:57 PM
Golang et big data : une adéquation parfaite ou en contradiction ?
Mar 05, 2024 pm 01:57 PM
Golang et big data : une adéquation parfaite ou en contradiction ? Avec le développement rapide de la technologie du Big Data, de plus en plus d’entreprises commencent à optimiser leurs activités et leur prise de décision grâce à l’analyse des données. Pour le traitement du Big Data, des langages de programmation efficaces sont cruciaux. Parmi les nombreux langages de programmation, Golang (langage Go) est devenu l'un des choix populaires pour le traitement du Big Data en raison de sa concurrence, de son efficacité, de sa simplicité et d'autres caractéristiques. Alors, Golang et big data sont-ils parfaitement compatibles ou contradictoires ? Cet article partira de l'application de Golang dans le traitement du Big Data,