

Comprenons ensemble le mécanisme de verrouillage de MySQL


Les verrous sont une partie très importante de MySQL. Les verrous ont un impact décisif sur la concurrence d'accès aux données de MySQL. Il y a aussi beaucoup de connaissances impliquées dans les mèches, donc pour le finir et le digérer dans votre estomac, vous devez vous calmer et le savourer encore et encore plusieurs fois. Cet article est un aperçu général des verrous. Pour certains détails approfondis, vous devez toujours trouver des livres pertinents pour continuer à consolider.
Recommandations d'apprentissage gratuites associées : tutoriel vidéo MySQL
Compréhension des verrous
1.1 Explication des verrous
计算机协调多个进程或线程并发访问某一资源的机制。
1.2 Importance des verrous
在数据库中,除传统计算资源(CPU、RAM、I\O等)的争抢,数据也是一种供多用户共享的资源。 如何保证数据并发访问的一致性,有效性,是所有数据库必须要解决的问题。 锁冲突也是影响数据库并发访问性能的一个重要因素,因此锁对数据库尤其重要。
1.3 Inconvénients des serrures
加锁是消耗资源的,锁的各种操作,包括获得锁、检测锁是否已解除、释放锁等 ,都会增加系统的开销。
1.4 Exemple simple
现如今网购已经特别普遍了,比如淘宝双十一活动,当天的人流量是千万及亿级别的,但商家的库存是有限的。 系统为了保证商家的商品库存不发生超卖现象,会对商品的库存进行锁控制。当有用户正在下单某款商品最后一件时, 系统会立马对该件商品进行锁定,防止其他用户也重复下单,直到支付动作完成才会释放(支付成功则立即减库存售罄,支付失败则立即释放)。
Types de serrures
2.1 Verrouillage de la table
Type
读锁(read lock),也叫共享锁(shared lock) 针对同一份数据,多个读操作可以同时进行而不会互相影响(select)
写锁(write lock),也叫排他锁(exclusive lock) 当前操作没完成之前,会阻塞其它读和写操作(update、insert、delete)
Verrouillage par défaut du moteur de stockage
MyISAM
Caractéristiques
1. 对整张表加锁 2. 开销小 3. 加锁快 4. 无死锁 5. 锁粒度大,发生锁冲突概率大,并发性低
Conclusion
1. 读锁会阻塞写操作,不会阻塞读操作 2. 写锁会阻塞读和写操作
Recommandations
MyISAM的读写锁调度是写优先,这也是MyISAM不适合做写为主表的引擎,因为写锁以后,其它线程不能做任何操作,大量的更新使查询很难得到锁,从而造成永远阻塞。
2.2 Verrouillage de rangée
Types
读锁(read lock),也叫共享锁(shared lock) 允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁
写锁(write lock),也叫排他锁(exclusive lock) 允许获得排他锁的事务更新数据,阻止其他事务取得相同数据集的共享锁和排他锁
意向共享锁(IS) 一个事务给一个数据行加共享锁时,必须先获得表的IS锁
意向排它锁(IX) 一个事务给一个数据行加排他锁时,必须先获得该表的IX锁
Verrouillage par défaut du moteur de stockage
InnoDB
Fonctionnalités
1. 对一行数据加锁 2. 开销大 3. 加锁慢 4. 会出现死锁 5. 锁粒度小,发生锁冲突概率最低,并发性高
Problèmes causés par la concurrence des transactions
1. 更新丢失 解决:让事务变成串行操作,而不是并发的操作,即对每个事务开始---对读取记录加排他锁 2. 脏读 解决:隔离级别为Read uncommitted 3. 不可重读 解决:使用Next-Key Lock算法来避免 4. 幻读 解决:间隙锁(Gap Lock)
2.3 Verrouillage de page
开销、加锁时间和锁粒度介于表锁和行锁之间,会出现死锁,并发处理能力一般(此锁不做多介绍)
Comment verrouiller ?
3.1 Verrouillage de la table
Verrouillage implicite (par défaut, verrouillage automatique et déverrouillage automatique)
select //上读锁
Verrouillage explicite (manuel)
insert、update、delete //上写锁
Déverrouiller (manuel)
lock table tableName read;//读锁 lock table tableName write;//写锁
| session01 | session02 |
|---|---|
| lock table teacher read;//上读锁 | |
| select * from teacher; //可以正常读取 | select * from teacher;//可以正常读取 |
| update teacher set name = 3 where id =2;//报错因被上读锁不能写操作 | update teacher set name = 3 where id =2;//被阻塞 |
| unlock tables;//解锁 | |
| update teacher set name = 3 where id =2;//更新操作成功 |
| session01 | session02 |
|---|---|
| lock table teacher write;//上写锁 | |
| select * from teacher; //可以正常读取 | select * from teacher;//被阻塞 |
| update teacher set name = 3 where id =2;//可以正常更新操作 | update teacher set name = 4 where id =2;//被阻塞 |
| unlock tables;//解锁 | |
| select * from teacher;//读取成功 | |
| update teacher set name = 4 where id =2;//更新操作成功 |
3.2 Verrouillage de ligne
Verrouillage implicite (par défaut, verrouiller et libérer automatiquement)
unlock tables;//所有锁表
Verrouillage explicite (manuel)
select //不会上锁
Déverrouiller (manuel)
insert、update、delete //上写锁
| session01 | session02 |
|---|---|
| begin; | |
| select * from teacher where id = 2 lock in share mode;//上读锁 | |
| select * from teacher where id = 2;//可以正常读取 | |
| update teacher set name = 3 where id =2;// 可以更新操作 | update teacher set name = 5 where id =2;//被阻塞 |
| commit; | |
| update teacher set name = 5 where id =2;//更新操作成功 |
| session01 | session02 |
|---|---|
| begin; | |
| select * from teacher where id = 2 for update;//上写锁 | |
| select * from teacher where id = 2;//可以正常读取 | |
| update teacher set name = 3 where id =2;// 可以更新操作 | update teacher set name = 5 where id =2;//被阻塞 |
| rollback; | |
| update teacher set name = 5 where id =2;//更新操作成功 |
为什么上了写锁,别的事务还可以读操作? 因为InnoDB有MVCC机制(多版本并发控制),可以使用快照读,而不会被阻塞。
行锁的实现算法
4.1 Record Lock锁
单个行记录上的锁 Record Lock总是会去锁住索引记录,如果InnoDB存储引擎表建立的时候没有设置任何一个索引,这时InnoDB存储引擎会使用隐式的主键来进行锁定
4.2 Gap Lock锁
当我们用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据记录的索引加锁,对于键值在条件范围内但并不存在的记录。 优点:解决了事务并发的幻读问题 不足:因为query执行过程中通过范围查找的话,他会锁定争个范围内所有的索引键值,即使这个键值并不存在。 间隙锁有一个致命的弱点,就是当锁定一个范围键值之后,即使某些不存在的键值也会被无辜的锁定,而造成锁定的时候无法插入锁定键值范围内任何数据。在某些场景下这可能会对性能造成很大的危害。
4.3 Next-key Lock锁
同时锁住数据+间隙锁 在Repeatable Read隔离级别下,Next-key Lock 算法是默认的行记录锁定算法。
4.4 行锁的注意点
1. 只有通过索引条件检索数据时,InnoDB才会使用行级锁,否则会使用表级锁(索引失效,行锁变表锁) 2. 即使是访问不同行的记录,如果使用的是相同的索引键,会发生锁冲突 3. 如果数据表建有多个索引时,可以通过不同的索引锁定不同的行
如何排查锁?
5.1 表锁
查看表锁情况
show open tables;
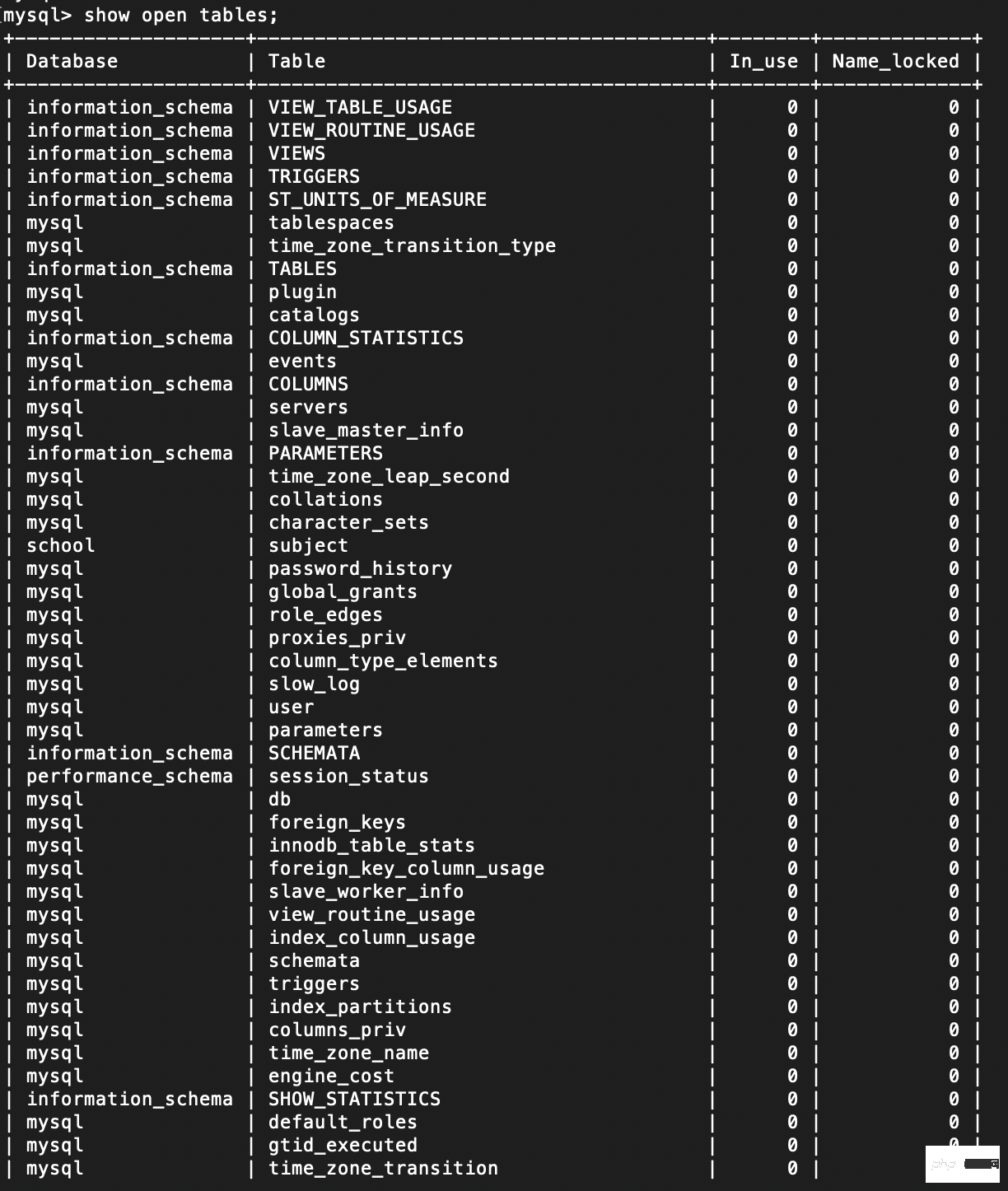
表锁分析
show status like 'table%';
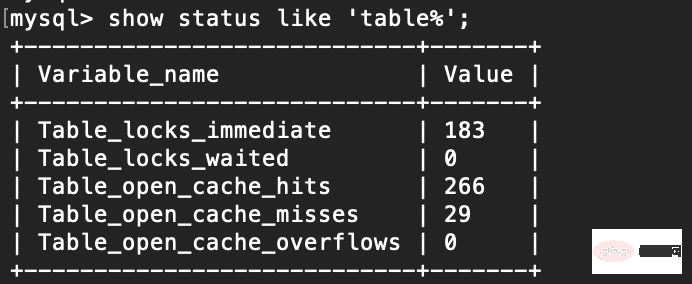
1. table_locks_waited 出现表级锁定争用而发生等待的次数(不能立即获取锁的次数,每等待一次值加1),此值高说明存在着较严重的表级锁争用情况 2. table_locks_immediate 产生表级锁定次数,不是可以立即获取锁的查询次数,每立即获取锁加1
5.2 行锁
行锁分析
show status like 'innodb_row_lock%';
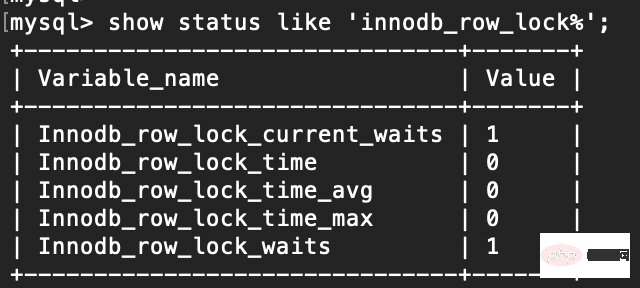
1. innodb_row_lock_current_waits //当前正在等待锁定的数量 2. innodb_row_lock_time //从系统启动到现在锁定总时间长度 3. innodb_row_lock_time_avg //每次等待所花平均时间 4. innodb_row_lock_time_max //从系统启动到现在等待最长的一次所花时间 5. innodb_row_lock_waits //系统启动后到现在总共等待的次数
information_schema库
1. innodb_lock_waits表 2. innodb_locks表 3. innodb_trx表
优化建议
1. 尽可能让所有数据检索都通过索引来完成,避免无索引行锁升级为表锁 2. 合理设计索引,尽量缩小锁的范围 3. 尽可能较少检索条件,避免间隙锁 4. 尽量控制事务大小,减少锁定资源量和时间长度 5. 尽可能低级别事务隔离
死锁
6.1 解释
指两个或者多个事务在同一资源上相互占用,并请求锁定对方占用的资源,从而导致恶性循环的现象
6.2 产生的条件
1. 互斥条件:一个资源每次只能被一个进程使用 2. 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放 3. 不剥夺条件:进程已获得的资源,在没有使用完之前,不能强行剥夺 4. 循环等待条件:多个进程之间形成的一种互相循环等待的资源的关系
6.1 解决
1. 查看死锁:show engine innodb status \G 2. 自动检测机制,超时自动回滚代价较小的事务(innodb_lock_wait_timeout 默认50s) 3. 人为解决,kill阻塞进程(show processlist) 4. wait for graph 等待图(主动检测)
6.1 如何避免
1. 加锁顺序一致,尽可能一次性锁定所需的数据行 2. 尽量基于primary(主键)或unique key更新数据 3. 单次操作数据量不宜过多,涉及表尽量少 4. 减少表上索引,减少锁定资源 5. 尽量使用较低的隔离级别 6. 尽量使用相同条件访问数据,这样可以避免间隙锁对并发的插入影响 7. 精心设计索引,尽量使用索引访问数据 8. 借助相关工具:pt-deadlock-logger
乐观锁与悲观锁
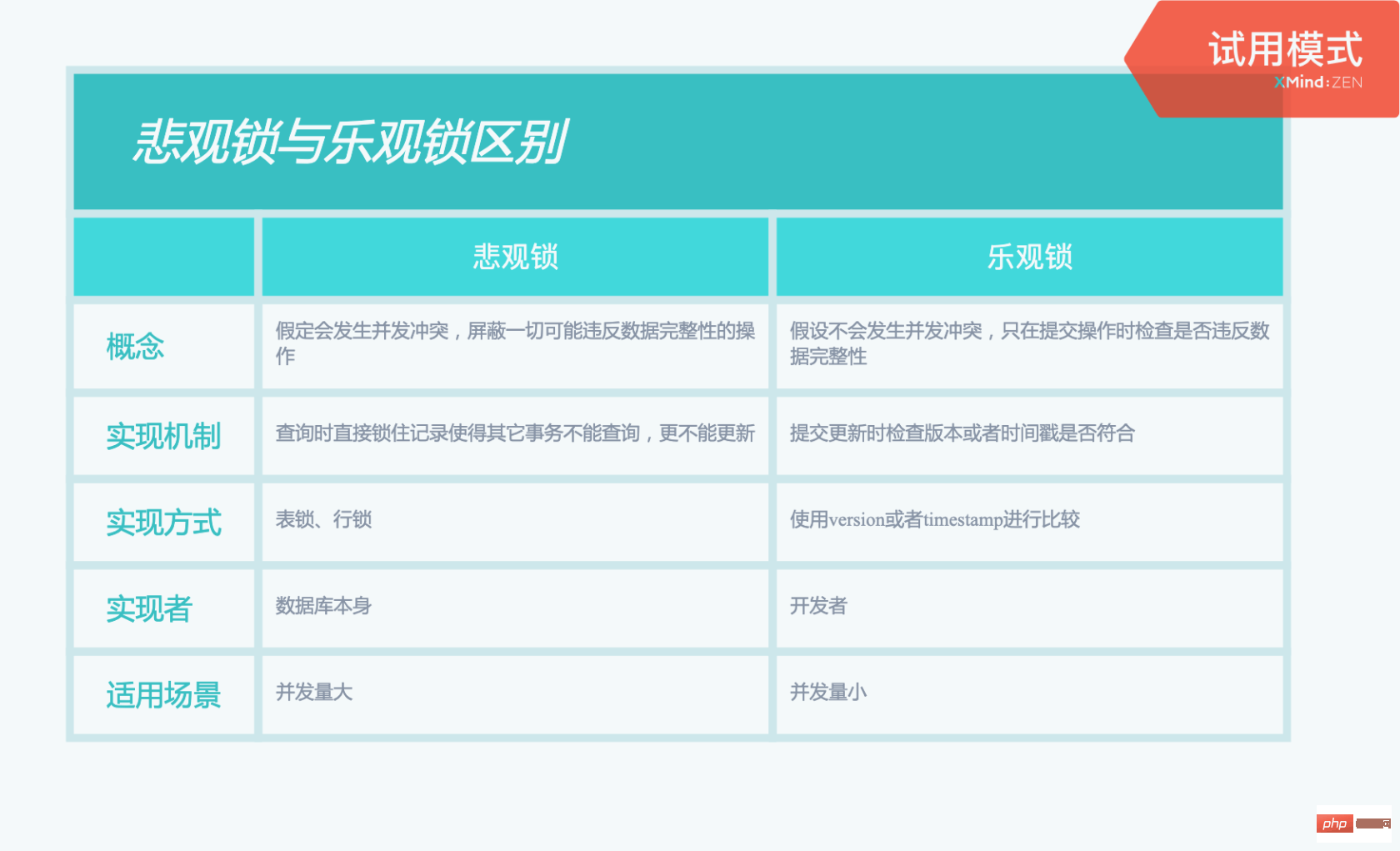
7.1 悲观锁
解释
假定会发生并发冲突,屏蔽一切可能违反数据完整性的操作
实现机制
表锁、行锁等
实现层面
数据库本身
适用场景
并发量大
7.2 乐观锁
解释
假设不会发生并发冲突,只在提交操作时检查是否违反数据完整性
实现机制
提交更新时检查版本号或者时间戳是否符合
实现层面
业务代码
适用场景
并发量小
更多相关免费学习推荐:mysql教程(视频)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL est un système de gestion de base de données relationnel open source. 1) Créez une base de données et des tables: utilisez les commandes CreateDatabase et CreateTable. 2) Opérations de base: insérer, mettre à jour, supprimer et sélectionner. 3) Opérations avancées: jointure, sous-requête et traitement des transactions. 4) Compétences de débogage: vérifiez la syntaxe, le type de données et les autorisations. 5) Suggestions d'optimisation: utilisez des index, évitez de sélectionner * et utilisez les transactions.
 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL sont des compétences essentielles pour les développeurs. 1.MySQL est un système de gestion de base de données relationnel open source, et SQL est le langage standard utilisé pour gérer et exploiter des bases de données. 2.MySQL prend en charge plusieurs moteurs de stockage via des fonctions de stockage et de récupération de données efficaces, et SQL termine des opérations de données complexes via des instructions simples. 3. Les exemples d'utilisation comprennent les requêtes de base et les requêtes avancées, telles que le filtrage et le tri par condition. 4. Les erreurs courantes incluent les erreurs de syntaxe et les problèmes de performances, qui peuvent être optimisées en vérifiant les instructions SQL et en utilisant des commandes Explication. 5. Les techniques d'optimisation des performances incluent l'utilisation d'index, d'éviter la numérisation complète de la table, d'optimiser les opérations de jointure et d'améliorer la lisibilité du code.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Comment récupérer les données après que SQL supprime les lignes
Apr 09, 2025 pm 12:21 PM
Comment récupérer les données après que SQL supprime les lignes
Apr 09, 2025 pm 12:21 PM
La récupération des lignes supprimées directement de la base de données est généralement impossible à moins qu'il n'y ait un mécanisme de sauvegarde ou de retour en arrière. Point clé: Rollback de la transaction: Exécutez Rollback avant que la transaction ne s'engage à récupérer les données. Sauvegarde: la sauvegarde régulière de la base de données peut être utilisée pour restaurer rapidement les données. Instantané de la base de données: vous pouvez créer une copie en lecture seule de la base de données et restaurer les données après la suppression des données accidentellement. Utilisez la déclaration de suppression avec prudence: vérifiez soigneusement les conditions pour éviter la suppression accidentelle de données. Utilisez la clause WHERE: Spécifiez explicitement les données à supprimer. Utilisez l'environnement de test: testez avant d'effectuer une opération de suppression.
