

Introduction à l'organisation de la syntaxe MySQL


J'apprends MySQL depuis quelques semaines récemment, et ce blog est dédié au tri de la syntaxe de base de MySQL.
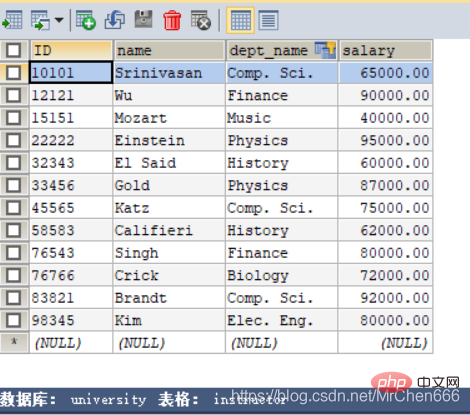
Regardons d'abord les trois déclarations les plus élémentaires de MySQL Par exemple : je souhaite trouver les noms des enseignants dont le salaire est supérieur à 80 000 dans le tableau des instructeurs ci-dessous
Recommandations d'apprentissage gratuites associées : Tutoriel vidéo MySQL
select name -- 这是最后筛选的元素,注意,在MySQL中一切结果都是以表的形式,哪怕这个表只有一个记录 from instructor -- from语句表示从哪个表中进行查询 where salary > 80000; -- where语句相当于选择语句,限定条件,找出所需的记录
 Le les résultats de la requête sont comme indiqué sur l'image ! Ces trois instructions sont les trois plus importantes dans MySQL, et fondamentalement, toutes les requêtes sont indissociables de ces trois instructions. Mais si vous souhaitez satisfaire des requêtes complexes, davantage d’instructions doivent être prises en charge.
Le les résultats de la requête sont comme indiqué sur l'image ! Ces trois instructions sont les trois plus importantes dans MySQL, et fondamentalement, toutes les requêtes sont indissociables de ces trois instructions. Mais si vous souhaitez satisfaire des requêtes complexes, davantage d’instructions doivent être prises en charge.
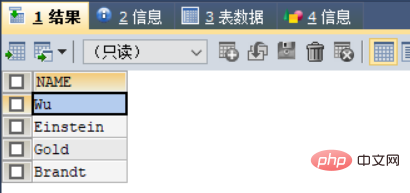
distinct : Dédupliquez les résultats/*用法如下,假如我想在上表instructor中,找出所有系的名字,可以发现在dept_name中,有的系是出现了一次以上,
因此要对系的名字进行去重*/select distinct dept_name
from instructor; -- 这里不需要限定条件,因此不用where语句
Copier après la connexion
/*用法如下,假如我想在上表instructor中,找出所有系的名字,可以发现在dept_name中,有的系是出现了一次以上, 因此要对系的名字进行去重*/select distinct dept_name from instructor; -- 这里不需要限定条件,因此不用where语句
* : Représente toutes les clés de la table actuelle. Les soi-disant clés sont en fait les champs de ligne de la. table, comme l'ID de la table de l'instructeur, le nom, le nom du département, etc./*类似上一个例子,我想找出instructor表中salary大于80000的教师,并显示这些老师的所有信息*/select *
from instructor
where salary > 80000; -- 其实不加分号也行,分号表示执行到此结束,接下来的语句不执行
Copier après la connexion
/*类似上一个例子,我想找出instructor表中salary大于80000的教师,并显示这些老师的所有信息*/select * from instructor where salary > 80000; -- 其实不加分号也行,分号表示执行到此结束,接下来的语句不执行
Lorsque nous filtrons plus d'une condition, par exemple, je souhaite trouver les enseignants dont le salaire est supérieur à 80 000, et je dois également préciser les enseignants du département informatique, c'est-à-dire I Pour connaître les enseignants du département informatique dont le salaire est supérieur à 80 000, nous devons utiliser la déclaration et select *
from instructor
where salary > 80000 and dept_name = 'Comp. Sci.';/*同样有and语句就有or语句,or表示或,即满足一个条件即可。比如我想找出工资小于60000或者大于80000的教师*/select *
from instructor
where salary > 80000 or salary
Copier après la connexion
select * from instructor where salary > 80000 and dept_name = 'Comp. Sci.';/*同样有and语句就有or语句,or表示或,即满足一个条件即可。比如我想找出工资小于60000或者大于80000的教师*/select * from instructor where salary > 80000 or salary
puis lancez la requête entre plusieurs tables, ce que nous ferons ensuite en difficulté. Ajoutons d'abord le concept de base des clés. Nous avons déjà parlé de ce qu'est une clé. Ici, nous parlons de la clé primaire, également appelée clé primaire. La clé primaire représente la clé qui détermine de manière unique un certain enregistrement. Par exemple, notre carte d'étudiant est le seul moyen de nous identifier sur le campus. Même si quelqu'un dans l'école porte le même nom que moi, je peux séparer nos identités grâce à notre carte d'étudiant. On peut voir que le nom n'est pas la clé primaire. Lorsqu'il existe un nom en double, le nom ne peut pas identifier de manière unique un étudiant.
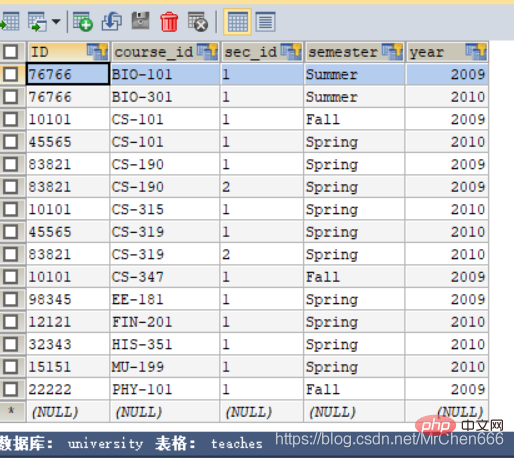 Il s'agit de la table des enseignants. La clé ID représente l'ID de l'enseignant, course_id représente l'identifiant du cours et semestre représente le semestre au cours duquel le cours est commencé. pour savoir quels cours l'enseignant enseigne et afficher le nom et l'identifiant du cours de l'enseignant.
Il s'agit de la table des enseignants. La clé ID représente l'ID de l'enseignant, course_id représente l'identifiant du cours et semestre représente le semestre au cours duquel le cours est commencé. pour savoir quels cours l'enseignant enseigne et afficher le nom et l'identifiant du cours de l'enseignant.
/*这条语句可以实现,但是请问为什么可以实现呢?那是因为两个表都有共同的主键:ID,当然teaches不止这一个主 键,我们看键旁边有个key,都是主键。但是我们不用管其他键,只要关注ID键就可以了,因为这是两个表中共有的。这 里我还要特意提一下两个表查询,其实是一个表的一个记录去遍历另外一个表的记录,当找到某一条instruction的id等 于teaches的id,就将这条记录保存到结果表中*/ SELECT NAME,course_id where instructor.`ID` = teaches.`ID`;
Ça y est, parlons de la jointure nature : la jointure naturelle. L'opération de modification est très simple. Il s'agit de sauvegarder les enregistrements avec des clés primaires égales dans les deux tables. Si les deux tables ont plusieurs clés identiques, alors vous devez vous assurer que chaque clé primaire identique est la même avant de sauvegarder.
/*上述例子完全可以用自然连接来查询*/ SELECT NAME,course_id FROM instructor NATURAL JOIN teaches;/*如果你想知道自然连接后的表长啥样,我满足你*/ SELECT * -- 显示结果表的所有键 FROM instructor NATURAL JOIN teaches;
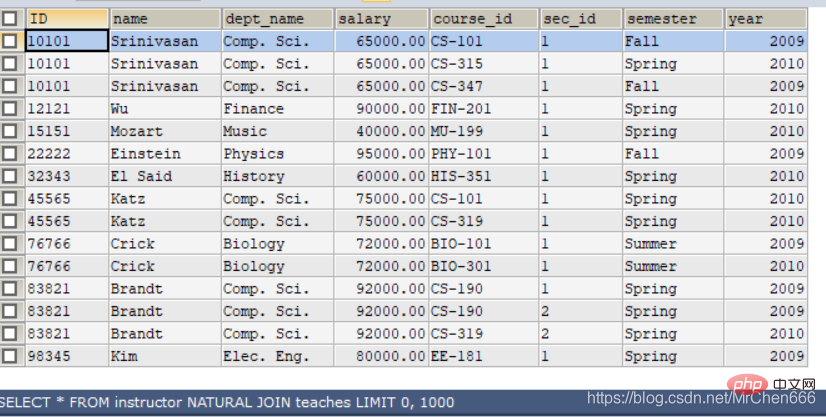 On constate que les colonnes du tableau ont été considérablement augmentées, ce qui intègre en fait les clés des deux tableaux. Si vous ne comprenez toujours pas complètement les liens naturels, laissez-moi vous donner un autre exemple. Par exemple, nous avons une table d'étudiants
On constate que les colonnes du tableau ont été considérablement augmentées, ce qui intègre en fait les clés des deux tableaux. Si vous ne comprenez toujours pas complètement les liens naturels, laissez-moi vous donner un autre exemple. Par exemple, nous avons une table d'étudiants
['Xu Xiaoming, n° 1', 'Huang Xiaoshan, n° 2'], où. la clé primaire est le numéro d'étudiant. Il existe également un tableau de scores
['No. 1, Chinois : 87, Mathématiques : 98', 'No. 2, Chinois : 94, Mathématiques : 82'], où le numéro d'élève est également la clé primaire de celui-ci. tableau. Lorsque nous voulons imprimer le tableau des étudiants, il suffit de connecter naturellement les deux tableaux. Au cours du processus de connexion naturel, les mêmes enregistrements appris seront intégrés en un seul enregistrement, et deviendront finalement
['No. , Chinois : 87, Mathématiques : 98', 'No. 2, Huang Xiaoshan, Chinois : 94, Mathématiques : 82']. En fait, la connexion naturelle est une version optimisée du produit Descartes. Vous pouvez comprendre le produit Descartes par vous-même.
Nous pouvons interroger des variables ou des fonctions via selectSELECT 'dd';SELECT 10*20;SELECT NOW(),UNIX_TIMESTAMP();
Copier après la connexion
Je veux en fait que tout le monde fasse attention ici. La clé après l'instruction select deviendra le nom de clé du résultat. . Sachez-le. Le suivi sera d'une grande aide à notre opération de changement de nom. Par exemple, dans cet exemple : SELECT 'dd';SELECT 10*20;SELECT NOW(),UNIX_TIMESTAMP();

concat() : Il s'agit d'une fonction qui connecte deux clés. Son utilisation est similaire à printf/*通过concat函数来连接那么和dept_name*/
SELECT NAME,CONCAT(NAME,' : ',dept_name)FROM instructor;
Copier après la connexion
/*通过concat函数来连接那么和dept_name*/ SELECT NAME,CONCAT(NAME,' : ',dept_name)FROM instructor;
Non seulement les noms de clés, mais également les enregistrements des clés connectées seront connectés entre eux. 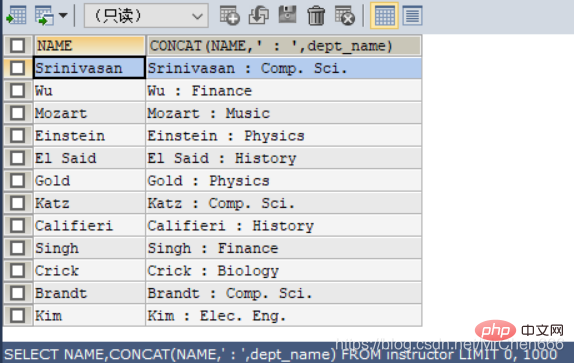
/*比如刚刚那个例子*/
SELECT NAME,CONCAT(NAME,' : ',dept_name) as 'name+dept'FROM instructor;/*或者给表改名*/
SELECT NAME
FROM instructor as i
WHERE i.salary > 70000; -- 注意改名后,要想引用该表的键,要加上引用符号:.
Copier après la connexion
/*比如刚刚那个例子*/ SELECT NAME,CONCAT(NAME,' : ',dept_name) as 'name+dept'FROM instructor;/*或者给表改名*/ SELECT NAME FROM instructor as i WHERE i.salary > 70000; -- 注意改名后,要想引用该表的键,要加上引用符号:.
讲了这么就查询,这里讲一下创建表:create table。其实这个命令一般用的很少,我更喜欢用鼠标点击来创建表,而不是敲代码来创建。
/*创建一个与student表一样结构的表,什么叫一样结构,就是ss_1表中键于student一样*/ CREATE TABLE ss_1 LIKE student;
刚刚例子中出现了like,其实like还可以用于字符匹配
/*like语句来进行字符匹配*/ SELECT dept_name FROM department WHERE building LIKE 'Watson%'; -- 这里用到%,类似于正则中的?,表示任意多个字符。这个查询是想找出building -- 中含有Watson的记录。
order by:对结果表中的键进行排序,默认是升序,即记录从上往下逐个递增
/*order by 按照某个属性进行排序*/ /*这个查询是想找出物理系的老师,并按工资进行排序*/ SELECT NAME , salary FROM instructor WHERE dept_name = 'Physics'ORDER BY salary;/*既然有升序,那就有降序*/ SELECT NAME , salary FROM instructor WHERE dept_name = 'Physics'ORDER BY salary DESC; -- DESC表示降序 /*我们还可以对多个键进行排序*/ SELECT * FROM instructor ORDER BY salary DESC , NAME ASC; -- 这里是先对工资进行降序排序,当工资一样时,按英文首字母的ASC码值升序排 -- 序
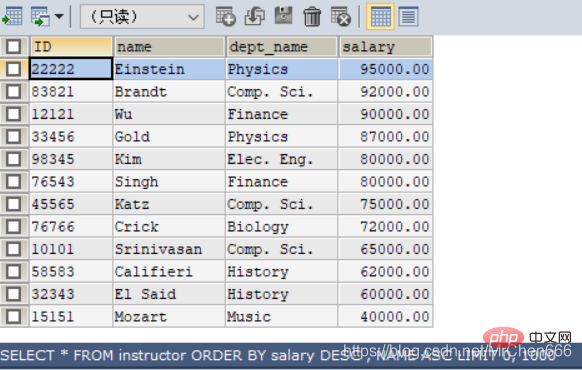
有没有想过为什么order by要在where语句后面呢?因为order by语句时针对结果表的,where语句之后才有结果表,这也与我之前强调MySQL查询结果一切都是表!哪怕这个表只有一个键甚至一条记录!
between and:选择区间内的记录
/*区间范围,注意是闭区间,即[90000 , 100000]*/ SELECT NAME FROM instructor WHERE salary BETWEEN 90000 AND 1000000;
当我们对查询多个条件时,有时候可以通过键匹配
/*类似于python的字典,里面的元素逐个对应*/ SELECT NAME,course_id FROM instructor,teaches WHERE (instructor.`ID`,dept_name) = (teaches.`ID`,'Biology');
下一篇博客将重点介绍多个表之间的查询,这也是重中之重,难点之一!
更多相关免费学习推荐:mysql教程(视频)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1393
1393
 52
1205
24
52
1205
24

 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Apache se connecte à une base de données nécessite les étapes suivantes: Installez le pilote de base de données. Configurez le fichier web.xml pour créer un pool de connexion. Créez une source de données JDBC et spécifiez les paramètres de connexion. Utilisez l'API JDBC pour accéder à la base de données à partir du code Java, y compris l'obtention de connexions, la création d'instructions, les paramètres de liaison, l'exécution de requêtes ou de mises à jour et de traitement des résultats.
 Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Le processus de démarrage de MySQL dans Docker se compose des étapes suivantes: Tirez l'image MySQL pour créer et démarrer le conteneur, définir le mot de passe de l'utilisateur racine et mapper la connexion de vérification du port Créez la base de données et l'utilisateur accorde toutes les autorisations sur la base de données
 CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
L'installation de MySQL sur CENTOS implique les étapes suivantes: Ajout de la source MySQL YUM appropriée. Exécutez la commande YUM Install MySQL-Server pour installer le serveur MySQL. Utilisez la commande mysql_secure_installation pour créer des paramètres de sécurité, tels que la définition du mot de passe de l'utilisateur racine. Personnalisez le fichier de configuration MySQL selon les besoins. Écoutez les paramètres MySQL et optimisez les bases de données pour les performances.
