

Quelles sont les structures de données couramment utilisées en Java ?

Les structures de données Java comprennent : 1. Tableau ; 2. Liste chaînée, une structure de données récursive ; 3. Pile, qui stocke les données selon les principes « dernier entré, premier sorti » et « premier entré, dernier out"; 4. File d'attente; 5. Arbre, qui est une collection de relations hiérarchiques composées de n (n>0) nœuds limités; 6. Tas; 7. Graphique; 8. Table de hachage.

L'environnement d'exploitation de ce tutoriel : système windows7, version java8, ordinateur DELL G3.
Structures de données communes Java
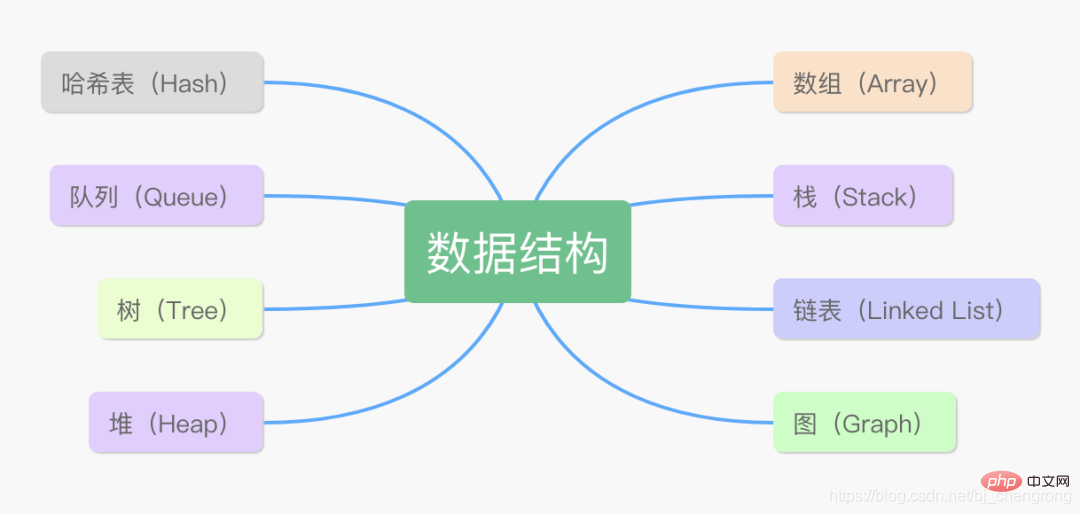
Quelles sont les différences entre ces 8 structures de données ?
①, tableau
Avantages :
L'interrogation des éléments par index est très rapide ; 🎜>
- Il est également pratique de parcourir le tableau par index.
- La taille du tableau est déterminée après la création et ne peut pas être étendue ; 🎜 >Les tableaux ne peuvent stocker qu'un seul type de données ;
- Les opérations d'ajout et de suppression d'éléments prennent du temps car d'autres éléments doivent être déplacés.
Le livre "Algorithm (4th Edition)" définit la liste chaînée comme ceci :
- Une liste chaînée est une structure de données récursive. Elle est soit vide (nulle), soit une référence à un nœud (node). Le nœud possède également un élément et un pointeur vers une autre liste chaînée.
-
La classe LinkedList de Java peut exprimer la structure d'une liste chaînée de manière très vivante sous forme de code :
C'est un Il s'agit d'une liste doublement chaînée. L'élément d'élément actuel a à la fois le précédent et le suivant, mais le précédent du premier est nul et le suivant du dernier est nul. S'il s'agit d'une liste chaînée à sens unique, il n'y a que le suivant et pas de précédent.public class LinkedList<E> { transient Node<E> first; transient Node<E> last; private static class Node<E> { E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } } }Copier après la connexion
- Comme elle n'a pas besoin d'être stockée de manière séquentielle, la liste chaînée peut atteindre une complexité temporelle O(1) lors de l'insertion et de la suppression ( il suffit de re-pointer simplement sur la référence, pas besoin de déplacer d'autres éléments comme un tableau). De plus, les listes chaînées surmontent également l'inconvénient des tableaux selon lesquels la taille des données doit être connue à l'avance, permettant une gestion flexible de la mémoire dynamique.
Avantages : 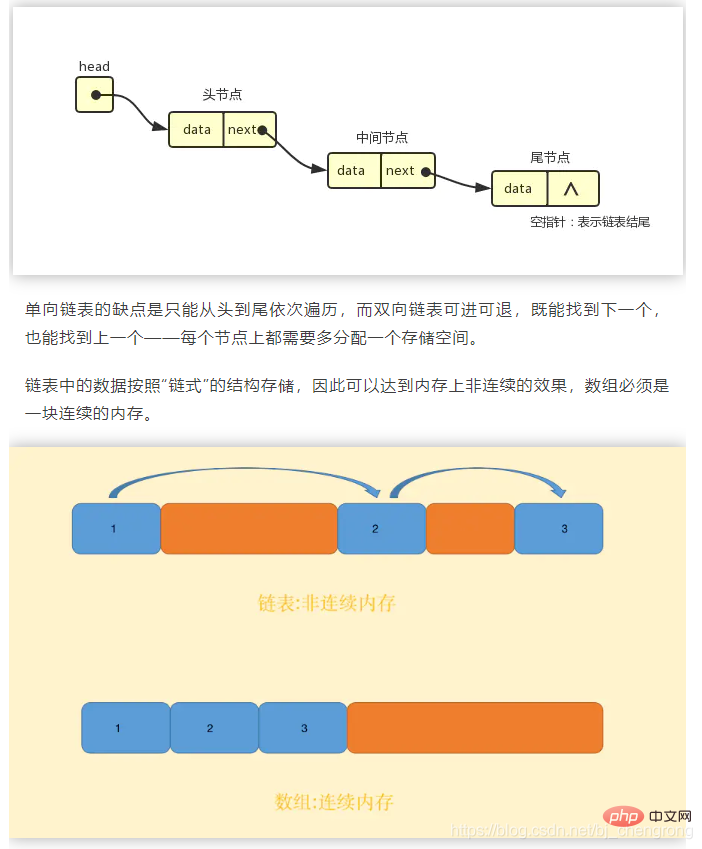
- Vous pouvez ajouter n'importe quel élément
- Seule la référence doit être mise à jour lors de l'insertion et de la suppression.
- Inconvénients :
- recherche Les éléments doivent parcourir toute la liste chaînée, ce qui prend du temps.
- ③, pile
La pile est comme un seau, le fond est scellé et le haut est ouvert, l'eau peut Vous pouvez entrer et sortir. Les amis qui ont utilisé des seaux doivent comprendre ce principe : l'eau qui entre en premier est au fond du seau, et l'eau qui entre plus tard est en haut du seau ; l'eau qui entre en dernier est versée en premier ; et l'eau qui entre en premier est versée en dernier. De même, la pile stocke les données selon les principes « dernier entré, premier sorti » et « premier entré, dernier sorti ». Les données insérées en premier sont poussées vers le bas de la pile et les données insérées. plus tard se trouve en haut de la pile. Les données sont lues au moment où elles sont lues séquentiellement en commençant par le haut de la pile.
④, File d'attente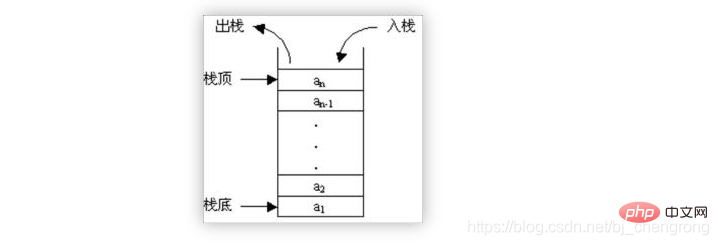
La file d'attente est comme une conduite d'eau, avec des ouvertures aux deux extrémités. L'eau entre par un bout et ressort par l'autre bout. L’eau qui entre en premier sort en premier et l’eau qui entre en dernier sort en dernier. Un peu différente de la conduite d'eau, la file d'attente définira deux extrémités, une extrémité est appelée tête de file d'attente et l'autre extrémité est appelée queue de file d'attente. La tête de file d'attente autorise uniquement les opérations de suppression (dequeuing) et la queue de la file d'attente autorise uniquement les opérations d'insertion (mise en file d'attente).
⑤, arbre 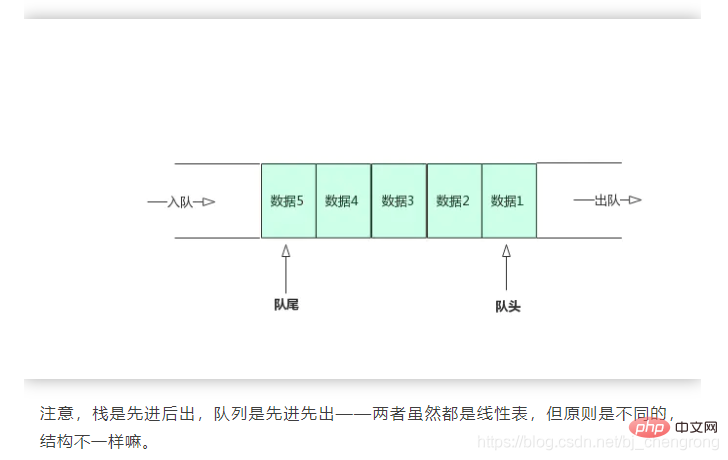
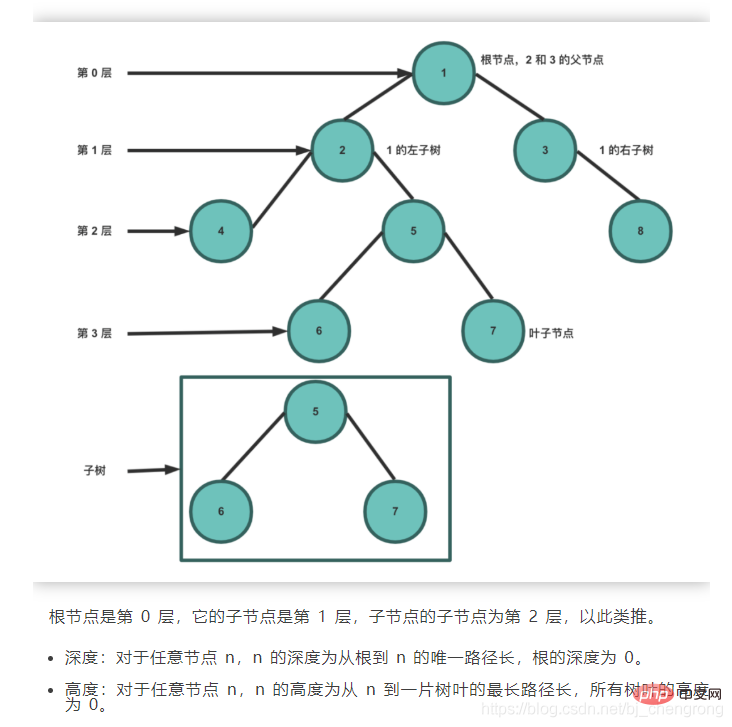
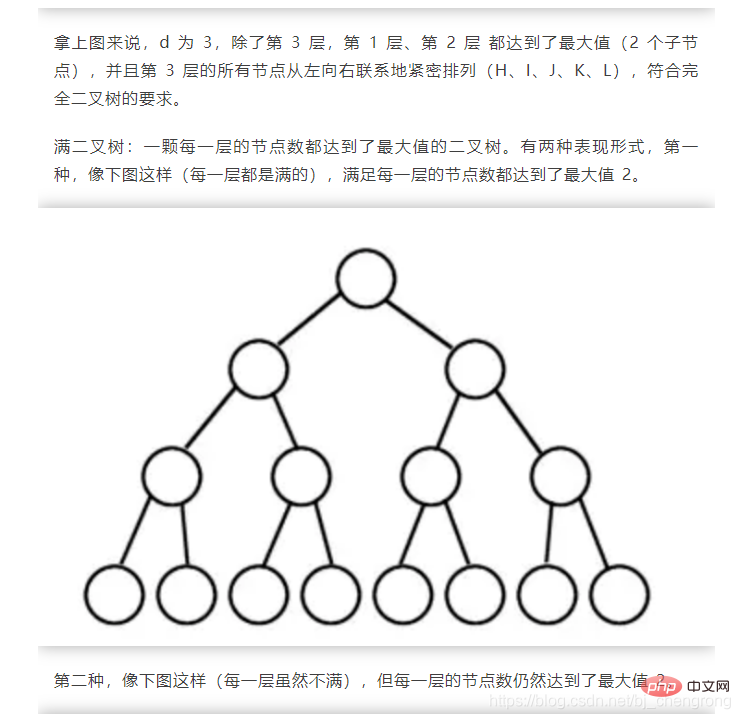
L'arbre est une structure non linéaire typique, qui est composée de n Un ensemble de relations hiérarchiques composées de (n>0) nœuds limités.
La raison pour laquelle on l'appelle "arbre" est que cette structure de données ressemble à un arbre à l'envers, sauf que la racine est en haut et les feuilles sont en le bas. La structure de données arborescente a les caractéristiques suivantes :
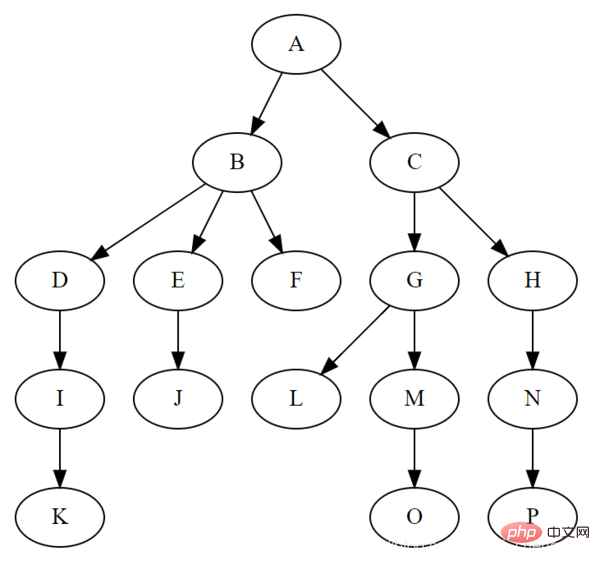
- n'a pas de nœud parent ; le nœud est appelé le nœud racine
- Chaque nœud non racine a et n'a qu'un seul nœud parent
- À l'exception du nœud racine, chaque nœud enfant peut être divisé en plusieurs sous-arbres disjoints.
- L'image ci-dessous montre quelques termes désignant les arbres :

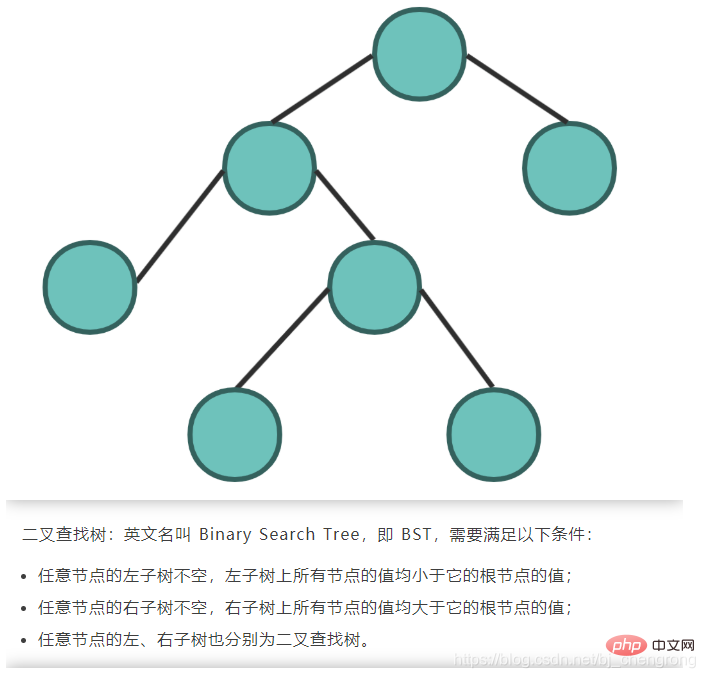
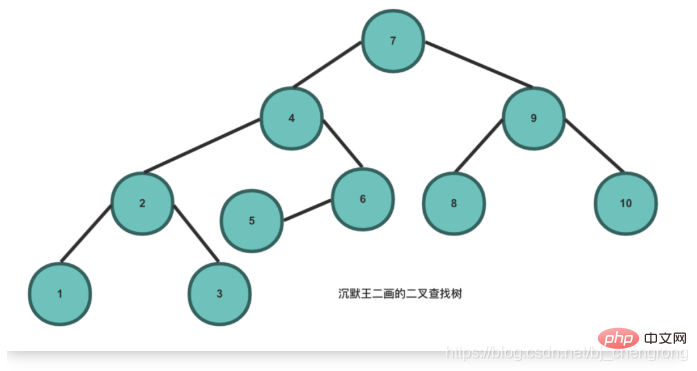
Basé sur les caractéristiques de l'arbre de recherche binaire, son avantage par rapport aux autres structures de données est que la complexité temporelle de la recherche et de l'insertion est faible, ce qui est O(logn). Si nous voulons trouver 5 éléments de l'image ci-dessus, nous partons du nœud racine 7. Si nous trouvons 5, il doit être à gauche de 7. Si nous trouvons 4, alors 5 doit être à droite de 4. Si on trouve 6, alors 5 doit être à gauche de 6. Côté, trouvé.
Idéalement, en recherchant des nœuds via BST, le nombre de nœuds à vérifier peut être réduit de moitié.
Arbre binaire équilibré : un arbre binaire si et seulement si la différence de hauteur entre les deux sous-arbres d'un nœud n'est pas supérieure à 1. L'arbre binaire hautement équilibré proposé par les anciens mathématiciens soviétiques Adelse-Velskil et Landis en 1962 est également appelé arbre AVL d'après le nom anglais des scientifiques.
Un arbre binaire équilibré est essentiellement un arbre de recherche binaire. Cependant, afin de limiter la différence de hauteur entre les sous-arbres gauche et droit et d'éviter des situations telles que des arbres asymétriques qui ont tendance à évoluer vers des structures linéaires, chacun des arbres binaires est équilibré. Les arbres de recherche binaires sont restreints. Les sous-arbres gauche et droit du nœud sont restreints. La différence de hauteur entre les sous-arbres gauche et droit est appelée facteur d'équilibre. La valeur absolue du facteur d'équilibre de chaque nœud de l'arbre n'est pas supérieure à 1.
La difficulté d'équilibrer un arbre binaire est de savoir comment maintenir l'équilibre gauche-droite en tournant à gauche ou à droite lorsque des nœuds sont supprimés ou ajoutés.
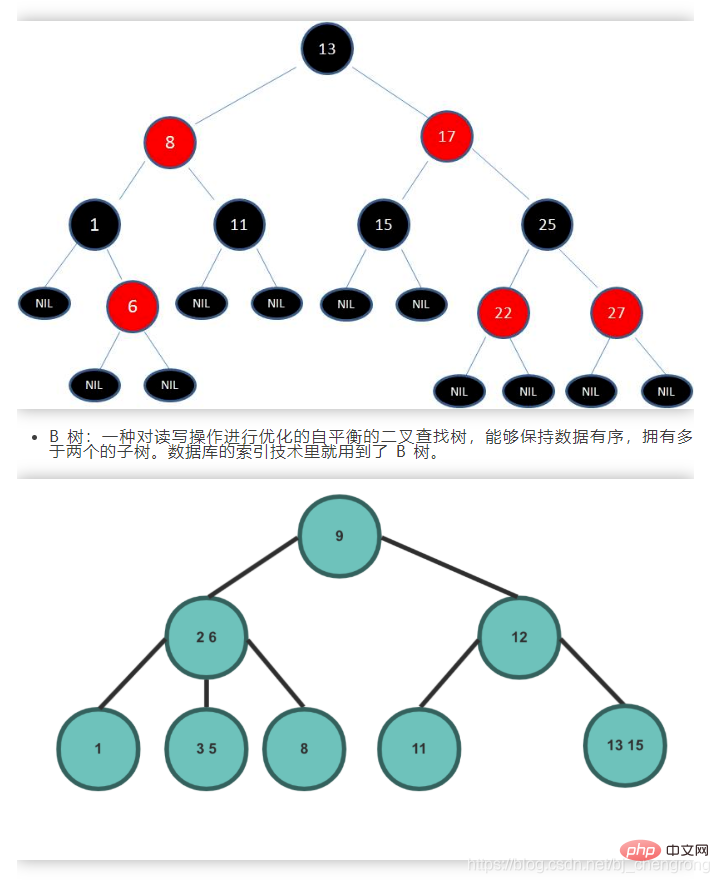
L'arbre binaire équilibré le plus courant en Java est l'arbre rouge-noir. Les nœuds sont rouges ou noirs. L'équilibre de l'arbre binaire est maintenu grâce à des contraintes de couleur :
1) Chaque nœud. ne peut être que rouge ou noir
2) Le nœud racine est noir
3) Chaque nœud feuille (nœud NIL, nœud vide) est noir.
4) Si un nœud est rouge, alors ses deux nœuds enfants sont noirs. C’est-à-dire que deux nœuds rouges adjacents ne peuvent pas apparaître sur un chemin.
5) Tous les chemins d'un nœud à chacune de ses feuilles contiennent le même nombre de nœuds noirs.
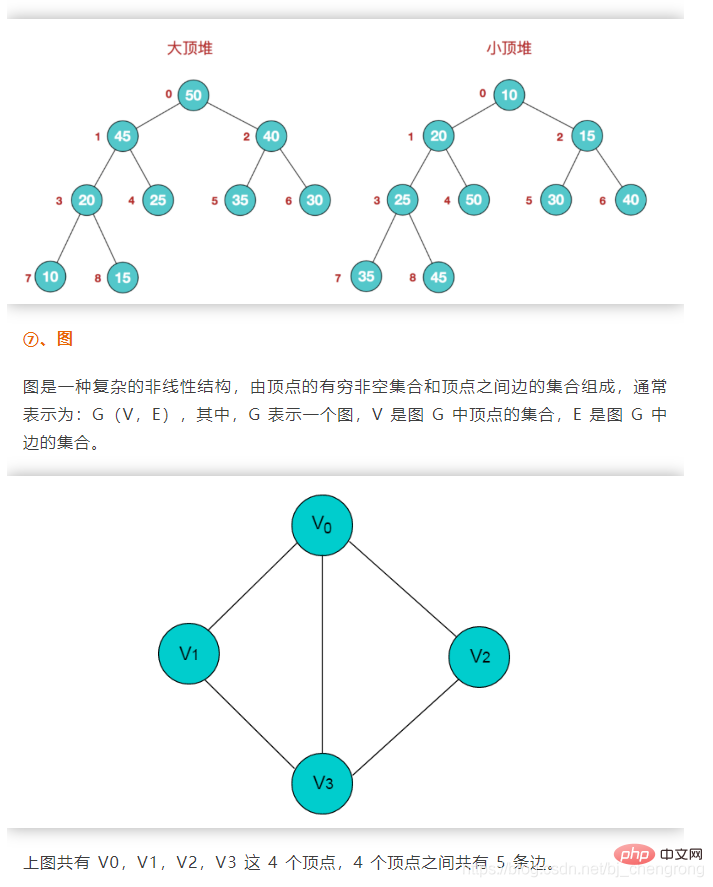
⑥, Heap
Heap peut être considéré comme un objet tableau d'un arbre, avec Le caractéristiques suivantes :
La valeur d'un nœud dans le tas n'est toujours ni supérieure ni inférieure à la valeur de son nœud parent
- Le tas est toujours un arbre binaire complet.
Dans une structure linéaire, une relation linéaire unique est satisfaite entre les éléments de données, et chaque élément de données (sauf le premier et le dernier) Chacun a un "prédécesseur" et "successeur" uniques ; Dans la structure arborescente, il existe une relation hiérarchique évidente entre les éléments de données, et chaque élément de données n'est lié qu'à un élément de la couche précédente (nœud parent) et à plusieurs les éléments (nœuds enfants) de la couche suivante sont liés ; Dans la structure du graphique, la relation entre les nœuds est arbitraire et deux éléments de données quelconques dans le graphique peuvent être liés.⑧, table de hachage
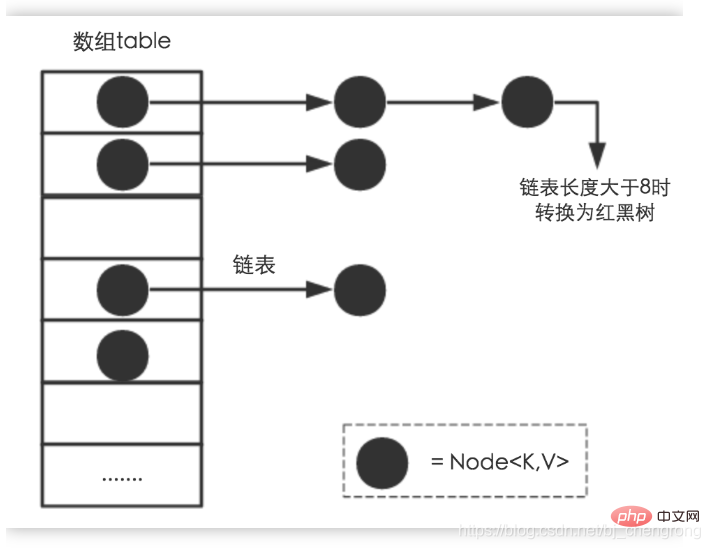
Hash Table (Hash Table), également appelée table de hachage, est une sorte de valeur de code clé (key- valeur) structure de données à accès direct, sa plus grande caractéristique est qu'elle peut rapidement mettre en œuvre la recherche, l'insertion et la suppression. La plus grande caractéristique des tableaux est qu'ils sont faciles à trouver, mais difficiles à insérer et à supprimer ; au contraire, la liste chaînée est difficile à trouver, mais facile à insérer et à supprimer ; Les tables de hachage combinent parfaitement les avantages des deux. Le HashMap de Java ajoute également les avantages des arbres sur cette base.
La fonction de hachage joue un rôle très clé dans la table de hachage. Elle peut transformer une entrée de n'importe quelle longueur en une sortie de longueur fixe, la sortie. est la valeur de hachage. La fonction de hachage rend le processus d'accès à une séquence de données plus rapide et plus efficace. Grâce à la fonction de hachage, les éléments de données peuvent être rapidement localisés. Si le mot-clé est k, sa valeur est stockée dans l'emplacement de stockage de. Par conséquent, la valeur correspondant à k peut être obtenue directement sans parcours.
hash(k)Pour deux blocs de données différents, la possibilité d'avoir la même valeur de hachage est extrêmement faible. C'est-à-dire que pour un bloc de données donné, il est extrêmement difficile de trouver un bloc de données avec la même valeur de hachage. De plus, pour un bloc de données, même si un seul bit est modifié, la modification de la valeur de hachage sera très importante - c'est la valeur de Hash !
Bien que la possibilité soit extrêmement faible, cela se produira quand même. Si un conflit de hachage se produit, HashMap de Java ajoutera une liste chaînée à la même position dans le tableau si la longueur de la liste chaînée est supérieure à 8. , il sera converti en rouge et noir. L'arborescence est traitée - c'est la méthode dite de fermeture éclair (tableau + liste chaînée).
Pour plus de connaissances sur la programmation, veuillez visiter : Vidéo de programmation ! !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1393
1393
 52
1205
24
52
1205
24

 Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre de Smith en Java. Nous discutons ici de la définition, comment vérifier le numéro Smith en Java ? exemple avec implémentation de code.
 Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Dans cet article, nous avons conservé les questions d'entretien Java Spring les plus posées avec leurs réponses détaillées. Pour que vous puissiez réussir l'interview.
 Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Java 8 présente l'API Stream, fournissant un moyen puissant et expressif de traiter les collections de données. Cependant, une question courante lors de l'utilisation du flux est: comment se casser ou revenir d'une opération FOREAK? Les boucles traditionnelles permettent une interruption ou un retour précoce, mais la méthode Foreach de Stream ne prend pas directement en charge cette méthode. Cet article expliquera les raisons et explorera des méthodes alternatives pour la mise en œuvre de terminaison prématurée dans les systèmes de traitement de flux. Lire plus approfondie: Améliorations de l'API Java Stream Comprendre le flux Forach La méthode foreach est une opération terminale qui effectue une opération sur chaque élément du flux. Son intention de conception est
 Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Guide de TimeStamp to Date en Java. Ici, nous discutons également de l'introduction et de la façon de convertir l'horodatage en date en Java avec des exemples.
 Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Les capsules sont des figures géométriques tridimensionnelles, composées d'un cylindre et d'un hémisphère aux deux extrémités. Le volume de la capsule peut être calculé en ajoutant le volume du cylindre et le volume de l'hémisphère aux deux extrémités. Ce tutoriel discutera de la façon de calculer le volume d'une capsule donnée en Java en utilisant différentes méthodes. Formule de volume de capsule La formule du volume de la capsule est la suivante: Volume de capsule = volume cylindrique volume de deux hémisphères volume dans, R: Le rayon de l'hémisphère. H: La hauteur du cylindre (à l'exclusion de l'hémisphère). Exemple 1 entrer Rayon = 5 unités Hauteur = 10 unités Sortir Volume = 1570,8 unités cubes expliquer Calculer le volume à l'aide de la formule: Volume = π × r2 × h (4
 Créer l'avenir : programmation Java pour les débutants absolus
Oct 13, 2024 pm 01:32 PM
Créer l'avenir : programmation Java pour les débutants absolus
Oct 13, 2024 pm 01:32 PM
Java est un langage de programmation populaire qui peut être appris aussi bien par les développeurs débutants que par les développeurs expérimentés. Ce didacticiel commence par les concepts de base et progresse vers des sujets avancés. Après avoir installé le kit de développement Java, vous pouvez vous entraîner à la programmation en créant un simple programme « Hello, World ! ». Une fois que vous avez compris le code, utilisez l'invite de commande pour compiler et exécuter le programme, et « Hello, World ! » s'affichera sur la console. L'apprentissage de Java commence votre parcours de programmation et, à mesure que votre maîtrise s'approfondit, vous pouvez créer des applications plus complexes.
 Comment exécuter votre première application Spring Boot dans Spring Tool Suite?
Feb 07, 2025 pm 12:11 PM
Comment exécuter votre première application Spring Boot dans Spring Tool Suite?
Feb 07, 2025 pm 12:11 PM
Spring Boot simplifie la création d'applications Java robustes, évolutives et prêtes à la production, révolutionnant le développement de Java. Son approche "Convention sur la configuration", inhérente à l'écosystème de ressort, minimise la configuration manuelle, allo
 PHP vs Python: comprendre les différences
Apr 11, 2025 am 12:15 AM
PHP vs Python: comprendre les différences
Apr 11, 2025 am 12:15 AM
PHP et Python ont chacun leurs propres avantages, et le choix doit être basé sur les exigences du projet. 1.Php convient au développement Web, avec une syntaxe simple et une efficacité d'exécution élevée. 2. Python convient à la science des données et à l'apprentissage automatique, avec une syntaxe concise et des bibliothèques riches.
