

Qu'est-ce que l'acide dans MySQL

Cet article vous présentera l'acide dans MySQL. Il a une certaine valeur de référence. Les amis dans le besoin peuvent s'y référer. J'espère qu'il sera utile à tout le monde.

1. Éléments de base de la transaction (ACID)
1. Atomicité : toutes les opérations après le début de la transaction, soit faites-la du tout, ou ne le faites pas du tout. Il est impossible de rester coincé au milieu. Si une erreur se produit lors de l'exécution de la transaction, elle sera rétablie à l'état avant le début de la transaction et toutes les opérations se dérouleront comme si elles ne s'étaient pas produites. C’est-à-dire que les choses forment un tout indivisible, tout comme les atomes appris en chimie, qui sont les unités de base de la matière.
2. Cohérence : avant et après le début et la fin de la transaction, les contraintes d'intégrité de la base de données ne sont pas violées. Par exemple, si A transfère de l’argent à B, il est impossible pour A de déduire l’argent mais B de ne pas le recevoir. En fait, la cohérence est aussi une manifestation de l'atomicité
3. Isolement : Dans le même temps, une seule transaction est autorisée à demander les mêmes données, et il n'y a aucune interférence entre les différentes transactions. Par exemple, A retire de l'argent d'une carte bancaire. B ne peut pas transférer d'argent sur cette carte avant que le processus de retrait de A ne soit terminé. Sérialisation
4. Durabilité : une fois la transaction terminée, toutes les mises à jour de la base de données par la transaction seront enregistrées dans la base de données et ne pourront pas être annulées.
2. Problèmes de concurrence des transactions
1. Lecture sale : la transaction A lit les données mises à jour par la transaction B, puis B annule l'opération, puis A lit The les données reçues sont des données sales et sont incohérentes avec les données finales réelles du tableau
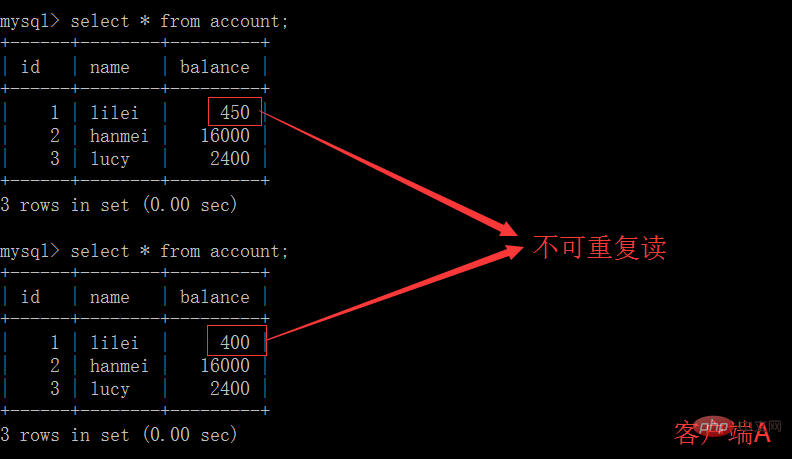
2. Lecture non répétable : la transaction A lit les mêmes données plusieurs fois et la transaction B lit les mêmes données plusieurs fois dans la transaction A. . Les données ont été mises à jour et soumises, ce qui a entraîné des résultats incohérents lorsque la transaction A a lu les mêmes données plusieurs fois. Le résultat de la lecture est incohérent avec le dernier résultat
3. Lecture fantôme : l'administrateur système A a modifié les notes de tous les étudiants dans la base de données des notes spécifiques aux notes ABCDE, mais l'administrateur système B a inséré un enregistrement à ce moment-là. Concernant l'enregistrement de score spécifique, lorsque l'administrateur système A a terminé la modification, il a constaté qu'il y avait encore un enregistrement qui n'avait pas été modifié. C'était comme si une hallucination s'était produite. Il a été modifié mais ensuite changé, ce qui a abouti à un résultat différent de celui attendu
Résumé : Il est facile de confondre la lecture non répétable et la lecture fantôme se concentre sur la modification, et la lecture fantôme se concentre sur l'ajout ou l'ajout de ou. suppression. Pour résoudre le problème des lectures non répétables, il vous suffit de verrouiller les lignes qui remplissent les conditions. Pour résoudre le problème des lectures fantômes, vous devez verrouiller la table
3. Isolation des transactions MySQL. niveau
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
| 读未提交(read-uncommitted) | 是 | 是 | 是 |
| 读已提交(read-committed) | 否 | 是 | 是 |
| 可重复读(repeatable-read) | 否 | 否 | 是 |
| 串行化(serializable) | 否 | 否 | 否 |
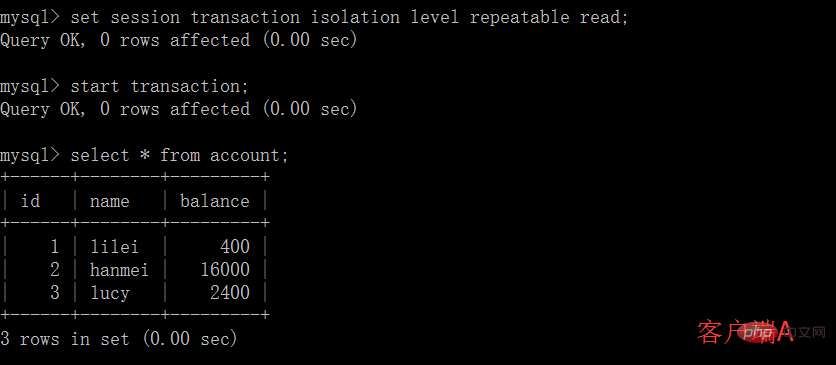
Le niveau d'isolement des transactions par défaut de MySQL est à lecture répétable
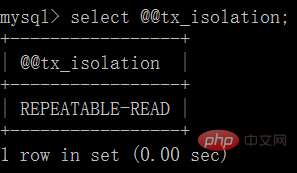
4 Utilisez des exemples pour illustrer chaque niveau d'isolement
1. Lecture non validée :
(1) Ouvrez un client A, définissez le mode de transaction actuel sur lecture non validée (lecture non validée) et interrogez la valeur initiale du compte de table :
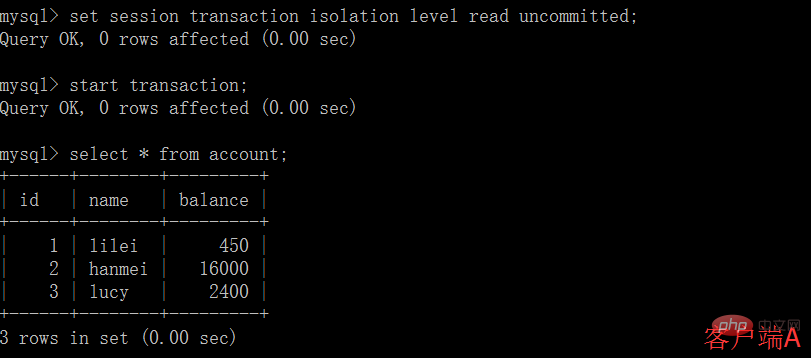
(2) Avant de soumettre la transaction du client A, ouvrez un autre client B et mettez à jour le compte de la table :
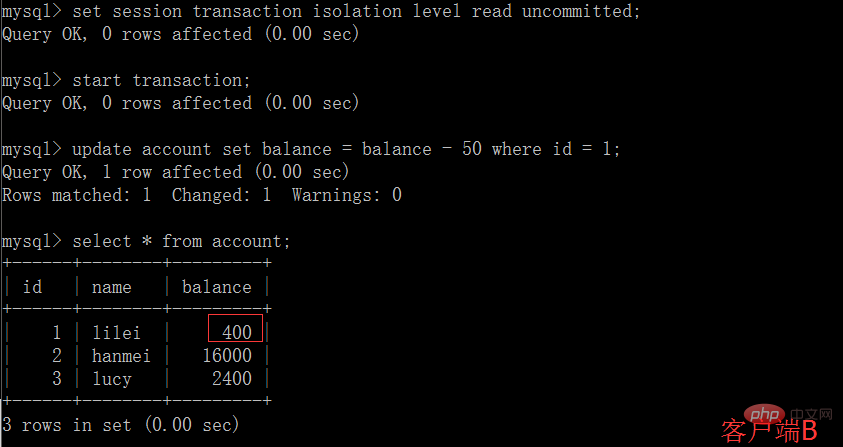
(3) À ce moment, bien que le client La transaction de B n'a pas encore été soumise, le client A peut interroger les données mises à jour de B :
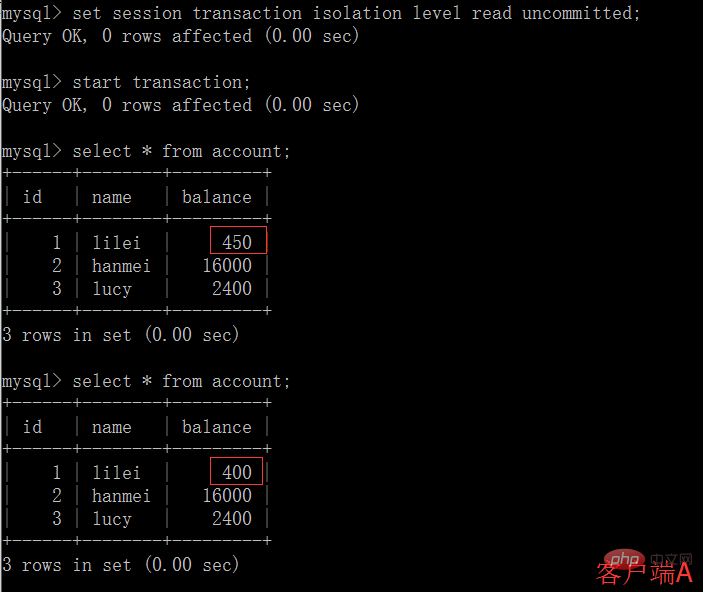
(4) Une fois le client B La transaction est annulée pour une raison quelconque, et toutes les opérations seront annulées. Ensuite, les données interrogées par le client A sont en fait des données sales :
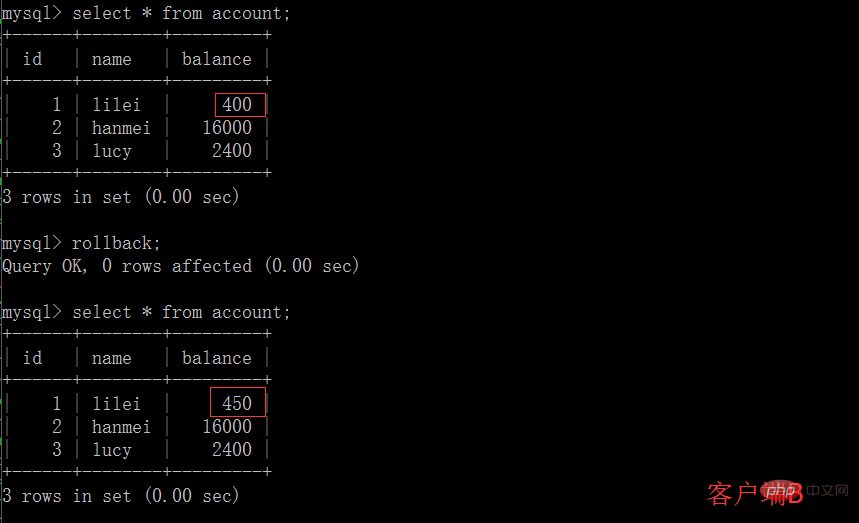
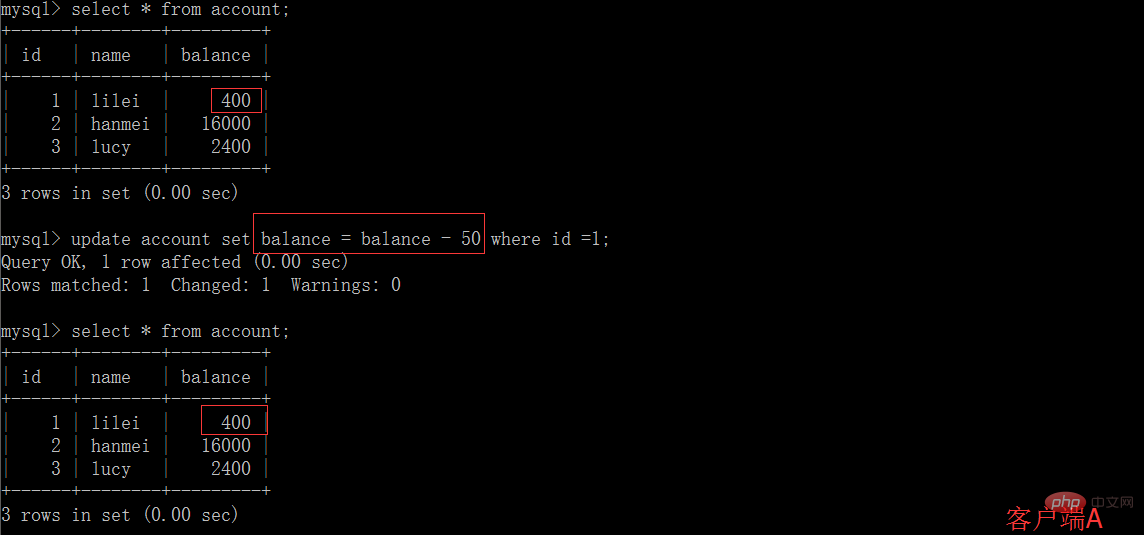
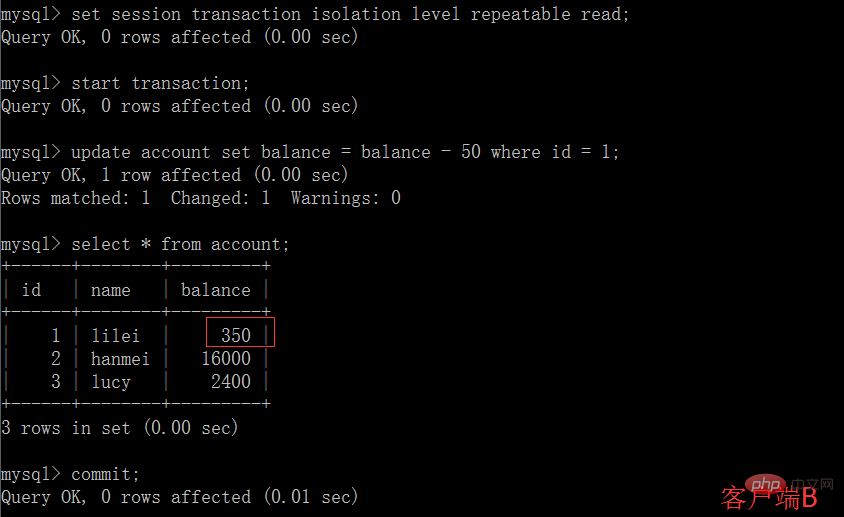
(5) Dans le client A, exécute l'instruction de mise à jour update account set balance = balance - 50 où id =1. Le solde de lilei n'est pas devenu 350, mais en réalité 400. N'est-ce pas étrange ? Si vous le pensez, vous êtes trop naïf dans l'application, nous utiliserons 400-50=350. , et nous ne savons pas que d'autres sessions ont été annulées. Pour résoudre ce problème, nous pouvons utiliser le niveau d'isolement en lecture validée
2. Lecture validée
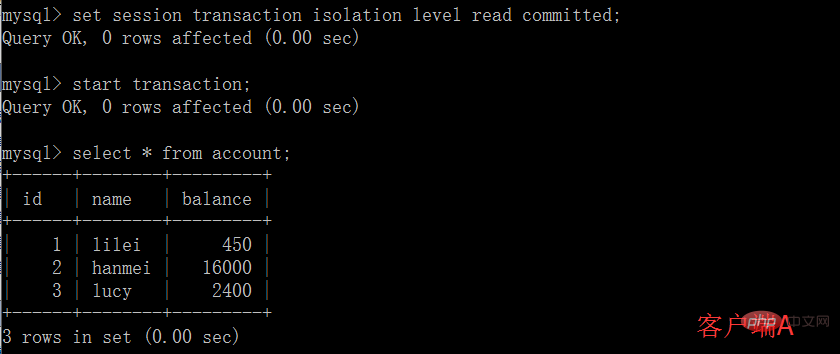
(1) Ouvrez un client A et définissez le mode de transaction actuel sur lecture validée (lecture non validée), interrogez la valeur initiale du compte de table :
( 2) Avant que la transaction du client A ne soit soumise, ouvrez un autre client B et mettez à jour le compte de table :
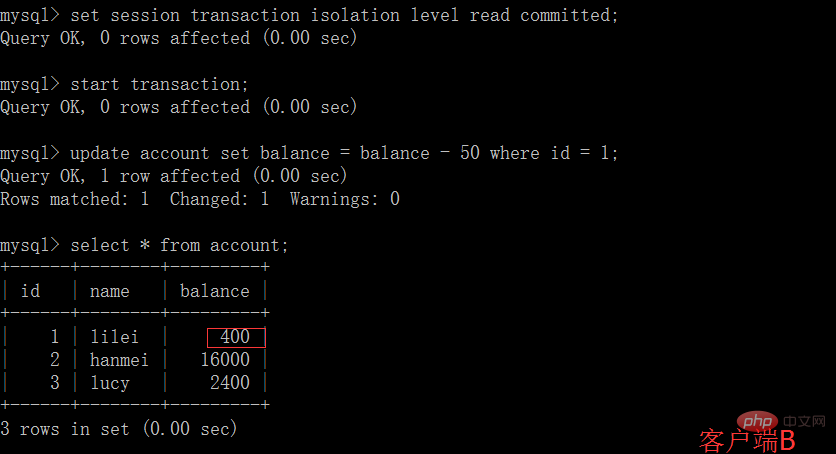
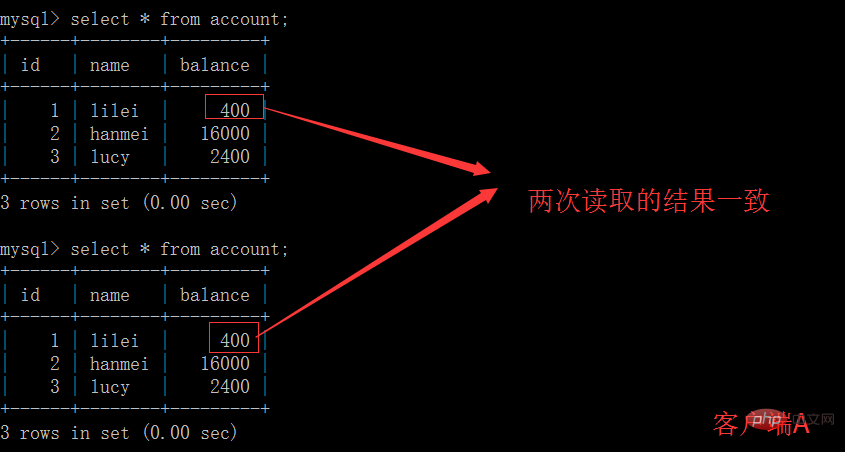
(3) À ce moment, la transaction du client B n'a pas encore été soumis. Le client A ne peut pas interroger les données mises à jour de B, ce qui résout le problème de lecture sale :
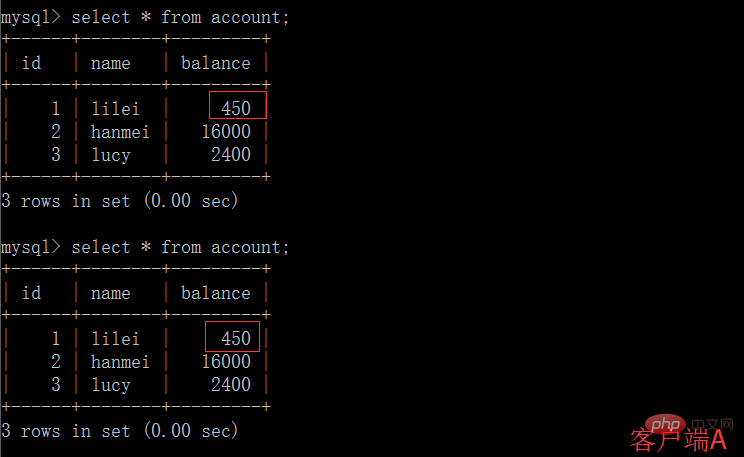
(4) Transaction du client B Soumettre
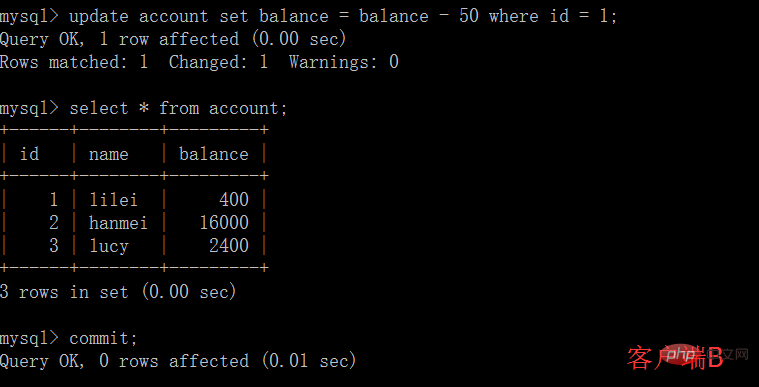
mysql> select * from account; +------+--------+---------+ | id | name | balance | +------+--------+---------+ | 1 | lilei | 400 | | 2 | hanmei | 16000 | | 3 | lucy | 2400 | +------+--------+---------+ 3 rows in set (0.00 sec) mysql> update account set balance = balance - 50 where id = 1; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> select * from account; +------+--------+---------+ | id | name | balance | +------+--------+---------+ | 1 | lilei | 300 | | 2 | hanmei | 16000 | | 3 | lucy | 2400 | +------+--------+---------+ 3 rows in set (0.00 sec)
mysql> commit; Query OK, 0 rows affected (0.00 sec) mysql> select * from account; +------+--------+---------+ | id | name | balance | +------+--------+---------+ | 1 | lilei | 300 | | 2 | hanmei | 16000 | | 3 | lucy | 2400 | +------+--------+---------+ 3 rows in set (0.00 sec)
mysql> start transaction; Query OK, 0 rows affected (0.00 sec) mysql> insert into account values(4,'lily',600); Query OK, 1 row affected (0.00 sec) mysql> commit; Query OK, 0 rows affected (0.01 sec)
.
,站在客户的角度,客户是看不到客户端B的,它会觉得是天下掉馅饼了,多了600块,这就是幻读,站在开发者的角度,数据的 一致性并没有破坏。但是在应用程序中,我们得代码可能会把18700提交给用户了,如果你一定要避免这情况小概率状况的发生,那么就要采取下面要介绍的事务隔离级别“串行化”
mysql> select sum(balance) from account; +--------------+ | sum(balance) | +--------------+ | 18700 | +--------------+ 1 row in set (0.00 sec) mysql> commit; Query OK, 0 rows affected (0.00 sec) mysql> select sum(balance) from account; +--------------+ | sum(balance) | +--------------+ | 19300 | +--------------+ 1 row in set (0.00 sec)
4.串行化
(1)打开一个客户端A,并设置当前事务模式为serializable,查询表account的初始值:
mysql> set session transaction isolation level serializable; Query OK, 0 rows affected (0.00 sec) mysql> start transaction; Query OK, 0 rows affected (0.00 sec) mysql> select * from account; +------+--------+---------+ | id | name | balance | +------+--------+---------+ | 1 | lilei | 10000 | | 2 | hanmei | 10000 | | 3 | lucy | 10000 | | 4 | lily | 10000 | +------+--------+---------+ 4 rows in set (0.00 sec)
(2)打开一个客户端B,并设置当前事务模式为serializable,插入一条记录报错,表被锁了插入失败,mysql中事务隔离级别为serializable时会锁表,因此不会出现幻读的情况,这种隔离级别并发性极低,开发中很少会用到。
mysql> set session transaction isolation level serializable; Query OK, 0 rows affected (0.00 sec) mysql> start transaction; Query OK, 0 rows affected (0.00 sec) mysql> insert into account values(5,'tom',0); ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
补充:
1、SQL规范所规定的标准,不同的数据库具体的实现可能会有些差异
2、mysql中默认事务隔离级别是可重复读时并不会锁住读取到的行
3、事务隔离级别为读提交时,写数据只会锁住相应的行
4、事务隔离级别为可重复读时,如果有索引(包括主键索引)的时候,以索引列为条件更新数据,会存在间隙锁间隙锁、行锁、下一键锁的问题,从而锁住一些行;如果没有索引,更新数据时会锁住整张表。
5、事务隔离级别为串行化时,读写数据都会锁住整张表
6、隔离级别越高,越能保证数据的完整性和一致性,但是对并发性能的影响也越大,鱼和熊掌不可兼得啊。对于多数应用程序,可以优先考虑把数据库系统的隔离级别设为Read Committed,它能够避免脏读取,而且具有较好的并发性能。尽管它会导致不可重复读、幻读这些并发问题,在可能出现这类问题的个别场合,可以由应用程序采用悲观锁或乐观锁来控制。
相关推荐:《mysql教程》
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Quand une analyse de table complète pourrait-elle être plus rapide que d'utiliser un index dans MySQL?
Apr 09, 2025 am 12:05 AM
Quand une analyse de table complète pourrait-elle être plus rapide que d'utiliser un index dans MySQL?
Apr 09, 2025 am 12:05 AM
La numérisation complète de la table peut être plus rapide dans MySQL que l'utilisation d'index. Les cas spécifiques comprennent: 1) le volume de données est petit; 2) Lorsque la requête renvoie une grande quantité de données; 3) Lorsque la colonne d'index n'est pas très sélective; 4) Lorsque la requête complexe. En analysant les plans de requête, en optimisant les index, en évitant le sur-index et en maintenant régulièrement des tables, vous pouvez faire les meilleurs choix dans les applications pratiques.
 Expliquez les capacités de recherche en texte intégral InNODB.
Apr 02, 2025 pm 06:09 PM
Expliquez les capacités de recherche en texte intégral InNODB.
Apr 02, 2025 pm 06:09 PM
Les capacités de recherche en texte intégral d'InNODB sont très puissantes, ce qui peut considérablement améliorer l'efficacité de la requête de la base de données et la capacité de traiter de grandes quantités de données de texte. 1) INNODB implémente la recherche de texte intégral via l'indexation inversée, prenant en charge les requêtes de recherche de base et avancées. 2) Utilisez la correspondance et contre les mots clés pour rechercher, prendre en charge le mode booléen et la recherche de phrases. 3) Les méthodes d'optimisation incluent l'utilisation de la technologie de segmentation des mots, la reconstruction périodique des index et l'ajustement de la taille du cache pour améliorer les performances et la précision.
 Puis-je installer mysql sur Windows 7
Apr 08, 2025 pm 03:21 PM
Puis-je installer mysql sur Windows 7
Apr 08, 2025 pm 03:21 PM
Oui, MySQL peut être installé sur Windows 7, et bien que Microsoft ait cessé de prendre en charge Windows 7, MySQL est toujours compatible avec lui. Cependant, les points suivants doivent être notés lors du processus d'installation: téléchargez le programme d'installation MySQL pour Windows. Sélectionnez la version appropriée de MySQL (communauté ou entreprise). Sélectionnez le répertoire d'installation et le jeu de caractères appropriés pendant le processus d'installation. Définissez le mot de passe de l'utilisateur racine et gardez-le correctement. Connectez-vous à la base de données pour les tests. Notez les problèmes de compatibilité et de sécurité sur Windows 7, et il est recommandé de passer à un système d'exploitation pris en charge.
 MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL est un système de gestion de base de données relationnel open source. 1) Créez une base de données et des tables: utilisez les commandes CreateDatabase et CreateTable. 2) Opérations de base: insérer, mettre à jour, supprimer et sélectionner. 3) Opérations avancées: jointure, sous-requête et traitement des transactions. 4) Compétences de débogage: vérifiez la syntaxe, le type de données et les autorisations. 5) Suggestions d'optimisation: utilisez des index, évitez de sélectionner * et utilisez les transactions.
 Différence entre l'index cluster et l'index non cluster (index secondaire) dans InnODB.
Apr 02, 2025 pm 06:25 PM
Différence entre l'index cluster et l'index non cluster (index secondaire) dans InnODB.
Apr 02, 2025 pm 06:25 PM
La différence entre l'index cluster et l'index non cluster est: 1. Index en cluster stocke les lignes de données dans la structure d'index, ce qui convient à la requête par clé et plage primaire. 2. L'index non clumpant stocke les valeurs de clé d'index et les pointeurs vers les lignes de données, et convient aux requêtes de colonne de clés non primaires.
 Mysql et Mariadb peuvent-ils coexister
Apr 08, 2025 pm 02:27 PM
Mysql et Mariadb peuvent-ils coexister
Apr 08, 2025 pm 02:27 PM
MySQL et MARIADB peuvent coexister, mais doivent être configurés avec prudence. La clé consiste à allouer différents numéros de port et répertoires de données à chaque base de données et ajuster les paramètres tels que l'allocation de mémoire et la taille du cache. La mise en commun de la connexion, la configuration des applications et les différences de version doivent également être prises en compte et doivent être soigneusement testées et planifiées pour éviter les pièges. L'exécution de deux bases de données simultanément peut entraîner des problèmes de performances dans les situations où les ressources sont limitées.
 La relation entre l'utilisateur de MySQL et la base de données
Apr 08, 2025 pm 07:15 PM
La relation entre l'utilisateur de MySQL et la base de données
Apr 08, 2025 pm 07:15 PM
Dans la base de données MySQL, la relation entre l'utilisateur et la base de données est définie par les autorisations et les tables. L'utilisateur a un nom d'utilisateur et un mot de passe pour accéder à la base de données. Les autorisations sont accordées par la commande Grant, tandis que le tableau est créé par la commande Create Table. Pour établir une relation entre un utilisateur et une base de données, vous devez créer une base de données, créer un utilisateur, puis accorder des autorisations.
 Expliquez différents types d'index MySQL (B-Tree, hachage, texte intégral, spatial).
Apr 02, 2025 pm 07:05 PM
Expliquez différents types d'index MySQL (B-Tree, hachage, texte intégral, spatial).
Apr 02, 2025 pm 07:05 PM
MySQL prend en charge quatre types d'index: B-Tree, hachage, texte intégral et spatial. 1. L'indice de tree B est adapté à la recherche de valeur égale, à la requête de plage et au tri. 2. L'indice de hachage convient aux recherches de valeur égale, mais ne prend pas en charge la requête et le tri des plages. 3. L'index de texte complet est utilisé pour la recherche en texte intégral et convient pour le traitement de grandes quantités de données de texte. 4. L'indice spatial est utilisé pour la requête de données géospatiaux et convient aux applications SIG.
