
 développement back-end
Golang
Vous faire comprendre le pool de connexions à la base de données Golang MySQL
développement back-end
Golang
Vous faire comprendre le pool de connexions à la base de données Golang MySQL
Vous faire comprendre le pool de connexions à la base de données Golang MySQL

Ce qui suit est une introduction au pool de connexions à la base de données golang mysql de la colonne du didacticiel golang. J'espère que cela sera utile aux amis dans le besoin !
Récemment, j'utilisais le langage ORM go pour effectuer certaines opérations de base de données. Finalement, j'ai trouvé un bug appelé connexion invalide, je suis donc allé me renseigner sur le délai d'attente du pool de connexion et de MySQL. Ensuite, je le ferai. utilisez l'ORM go. + mysql pour expliquer (je comprends que les langages sont tous connectés et que les principes doivent être les mêmes).
Lorsque nous voulons ajouter, supprimer, modifier et vérifier la base de données, la première étape est de se connecter à la base de données
//conn the database
func ConnDb(dbConnString string, dbName string) error {
maxIdle := 50
maxConn := 50
err := orm.RegisterDataBase(dbName, "mysql", dbConnString+"?charset=utf8&loc=Asia%2FShanghai", maxIdle, maxConn)
if err != nil {
util.GLogger.Errorw("in Connect DB", "err", err)
}
return err
}Ce qui est connecté ici, c'est la base de données mysql. Le pool de connexion maximum est. défini sur 50. Le nombre maximum de connexions inactives est de 50.
A quoi sert principalement ce pool de connexion ? Pour faire simple, si vous souhaitez obtenir des données de la base de données et modifier les données, vous devez établir un pipeline avec la base de données. Il s'agit d'établir une connexion réseau. Nous savons tous que les connexions TCP prennent du temps, donc depuis. il a fallu un certain temps pour construire ce pipeline, alors comment puis-je le prendre et l'utiliser sans le jeter ? Ensuite, le pool de connexions est l'endroit où ces pipelines établis sont stockés. La valeur de 50 peut simplement être comprise comme un maximum de 50 pipelines. Notez que plus il est gros, mieux c'est, car s'il est trop grand, il occupera plus de mémoire. Bien sûr, cela prendra trop de mémoire. S'il est trop petit, il y aura une attente de blocage.
Puisque ces tuyaux sont placés dans le pool de connexions, alors la connexion inactive fait référence à ces tuyaux inactifs. Il est alors évident que la valeur de la connexion inactive ne doit pas être supérieure à la taille du pool de connexions, car plus la connexion est grande, le pool ne vous aidera pas à économiser autant de tuyaux de connexion inutilisés.
Après avoir compris ces concepts simples, quel est le flux de travail à chaque fois que vous accédez à la base de données ?
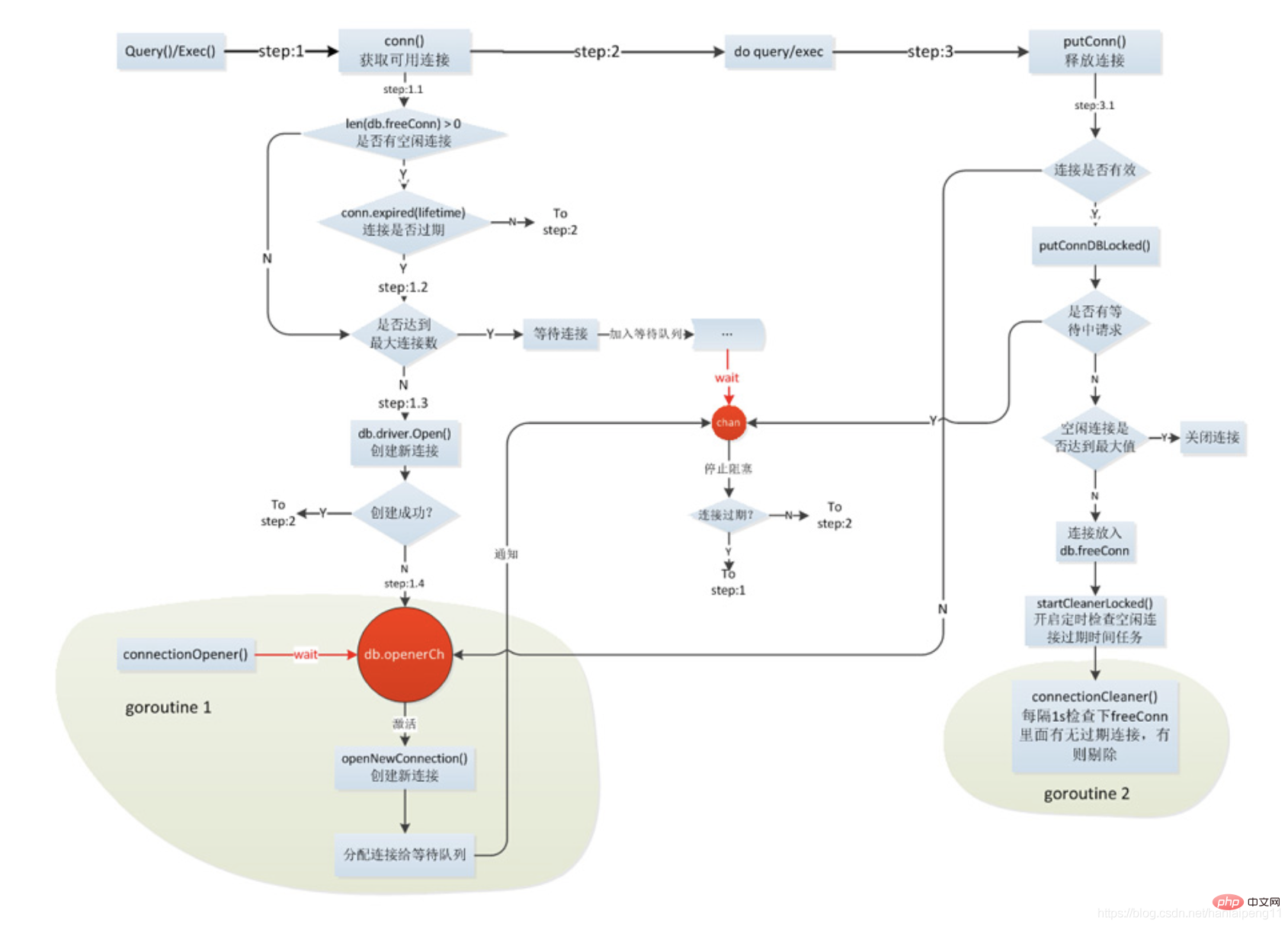
À travers cette image, nous pouvons voir clairement l'ensemble du processus d'accès à la connexion.
étape 1 (obtenir les connexions disponibles) accédez au pool de connexions pour rechercher les connexions inactives disponibles, puis jugez si le pool de connexions est plein. Sinon, créez une nouvelle connexion. elle est pleine, puis attendez que la connexion soit libérée ; bien sûr, s'il y a une connexion inactive, il déterminera directement si la connexion a expiré. Si elle n'a pas expiré, elle sera utilisée directement. réévaluera si le pool de connexions est plein. Non Si c'est le cas, créez une nouvelle connexion et attendez qu'elle soit pleine.
étape 2 (base de données d'exploitation) Après avoir obtenu cette connexion, effectuez les opérations d'ajout, de suppression, de modification et de vérification.
étape 3 (Libérer la connexion) Après avoir exploité la base de données, vous devez libérer la connexion, alors la connexion libérée sera inactive si elle dépasse le nombre de connexions inactives, elle sera fermée directement. sera utilisé pour l'attente.
Ensuite vous remarquerez que cette connexion échouera :
Le timeout de la base de données mysql, lorsque vous établissez une connexion avec la base de données, la base de données ne peut pas toujours vous faire confiance, alors la base de données Il y a un timeout, c'est-à-dire qu'après cette période, je ne ferai plus confiance à votre connexion. Vous devez vous reconnecter à moi. Vérifiez les différentes déclarations de timeout définies par la base de données comme suit :
show variables like '%timeout%';
où il y aura deux timeouts. ici : délai d'attente de connexion interactif (interactive_timeout) et délai d'attente de connexion non interactif (wait_timeout)
Connexion interactive : vous vous connectez à mysql via la ligne de commande
Connexion non interactive : il s'agit de se connecter à mysql dans le programme
et ce délai d'attente non interactif se produit lorsque le temps d'inactivité de la connexion inactive dans le pool de connexions dépasse le paramètre wait_timeout. Ensuite, à ce moment-là, lorsque le programme obtient la connexion inactive et effectue une requête, le problème d'origine apparaîtra, une connexion invalide.
Après avoir compris les principes de base, la solution à une connexion invalide est très simple :
1. Prolongez le délai d'attente de la base de données.
2. Le programme vérifie régulièrement ces connexions échouées et les rejette à temps. Notez que le temps de vérification du programme doit ici être inférieur à la valeur wait_timeout définie par mysql.
Ce qui précède est ma compréhension du pool de connexion. S'il y a des erreurs, veuillez les signaler ~
.Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment configurer le pool de connexions pour la connexion à la base de données Golang ?
Jun 06, 2024 am 11:21 AM
Comment configurer le pool de connexions pour la connexion à la base de données Golang ?
Jun 06, 2024 am 11:21 AM
Comment configurer le pool de connexions pour les connexions à la base de données Go ? Utilisez le type DB dans le package base de données/sql pour créer une connexion à la base de données ; définissez MaxOpenConns pour contrôler le nombre maximum de connexions simultanées ; définissez MaxIdleConns pour définir le nombre maximum de connexions inactives ; définissez ConnMaxLifetime pour contrôler le cycle de vie maximum de la connexion ;
 Compréhension approfondie du cycle de vie des fonctions Golang et de la portée variable
Apr 19, 2024 am 11:42 AM
Compréhension approfondie du cycle de vie des fonctions Golang et de la portée variable
Apr 19, 2024 am 11:42 AM
Dans Go, le cycle de vie de la fonction comprend la définition, le chargement, la liaison, l'initialisation, l'appel et le retour ; la portée des variables est divisée en niveau de fonction et au niveau du bloc. Les variables d'une fonction sont visibles en interne, tandis que les variables d'un bloc ne sont visibles que dans le bloc. .
 Comment faire correspondre les horodatages à l'aide d'expressions régulières dans Go ?
Jun 02, 2024 am 09:00 AM
Comment faire correspondre les horodatages à l'aide d'expressions régulières dans Go ?
Jun 02, 2024 am 09:00 AM
Dans Go, vous pouvez utiliser des expressions régulières pour faire correspondre les horodatages : compilez une chaîne d'expression régulière, telle que celle utilisée pour faire correspondre les horodatages ISO8601 : ^\d{4}-\d{2}-\d{2}T \d{ 2}:\d{2}:\d{2}(\.\d+)?(Z|[+-][0-9]{2}:[0-9]{2})$ . Utilisez la fonction regexp.MatchString pour vérifier si une chaîne correspond à une expression régulière.
 Comment envoyer des messages Go WebSocket ?
Jun 03, 2024 pm 04:53 PM
Comment envoyer des messages Go WebSocket ?
Jun 03, 2024 pm 04:53 PM
Dans Go, les messages WebSocket peuvent être envoyés à l'aide du package gorilla/websocket. Étapes spécifiques : Établissez une connexion WebSocket. Envoyer un message texte : appelez WriteMessage(websocket.TextMessage,[]byte("message")). Envoyez un message binaire : appelez WriteMessage(websocket.BinaryMessage,[]byte{1,2,3}).
 La différence entre la langue Golang et Go
May 31, 2024 pm 08:10 PM
La différence entre la langue Golang et Go
May 31, 2024 pm 08:10 PM
Go et le langage Go sont des entités différentes avec des caractéristiques différentes. Go (également connu sous le nom de Golang) est connu pour sa concurrence, sa vitesse de compilation rapide, sa gestion de la mémoire et ses avantages multiplateformes. Les inconvénients du langage Go incluent un écosystème moins riche que les autres langages, une syntaxe plus stricte et un manque de typage dynamique.
 Comment éviter les fuites de mémoire dans l'optimisation des performances techniques de Golang ?
Jun 04, 2024 pm 12:27 PM
Comment éviter les fuites de mémoire dans l'optimisation des performances techniques de Golang ?
Jun 04, 2024 pm 12:27 PM
Les fuites de mémoire peuvent entraîner une augmentation continue de la mémoire du programme Go en : fermant les ressources qui ne sont plus utilisées, telles que les fichiers, les connexions réseau et les connexions à la base de données. Utilisez des références faibles pour éviter les fuites de mémoire et ciblez les objets pour le garbage collection lorsqu'ils ne sont plus fortement référencés. En utilisant go coroutine, la mémoire de la pile de coroutines sera automatiquement libérée à la sortie pour éviter les fuites de mémoire.
 Comment utiliser le wrapper d'erreur de Golang ?
Jun 03, 2024 pm 04:08 PM
Comment utiliser le wrapper d'erreur de Golang ?
Jun 03, 2024 pm 04:08 PM
Dans Golang, les wrappers d'erreurs vous permettent de créer de nouvelles erreurs en ajoutant des informations contextuelles à l'erreur d'origine. Cela peut être utilisé pour unifier les types d'erreurs générées par différentes bibliothèques ou composants, simplifiant ainsi le débogage et la gestion des erreurs. Les étapes sont les suivantes : Utilisez la fonction error.Wrap pour envelopper les erreurs d'origine dans de nouvelles erreurs. La nouvelle erreur contient des informations contextuelles de l'erreur d'origine. Utilisez fmt.Printf pour générer des erreurs encapsulées, offrant ainsi plus de contexte et de possibilités d'action. Lors de la gestion de différents types d’erreurs, utilisez la fonction erreurs.Wrap pour unifier les types d’erreurs.
 Un guide pour les tests unitaires des fonctions simultanées Go
May 03, 2024 am 10:54 AM
Un guide pour les tests unitaires des fonctions simultanées Go
May 03, 2024 am 10:54 AM
Les tests unitaires des fonctions simultanées sont essentiels car cela permet de garantir leur comportement correct dans un environnement simultané. Des principes fondamentaux tels que l'exclusion mutuelle, la synchronisation et l'isolement doivent être pris en compte lors du test de fonctions concurrentes. Les fonctions simultanées peuvent être testées unitairement en simulant, en testant les conditions de concurrence et en vérifiant les résultats.
