
 développement back-end
tutoriel php
'Xiaobai' vous fera comprendre les modules et principes de fonctionnement de Nginx ! ! !
développement back-end
tutoriel php
'Xiaobai' vous fera comprendre les modules et principes de fonctionnement de Nginx ! ! !
'Xiaobai' vous fera comprendre les modules et principes de fonctionnement de Nginx ! ! !

NGINX est connu pour ses équilibreurs de charge, ses caches et ses serveurs Web hautes performances, qui alimentent plus de 40 % des sites Web les plus fréquentés au monde.
a donc Il a une certaine valeur de référence. Les amis dans le besoin peuvent s'y référer. J'espère qu'il sera utile à tout le monde

. 1. Modules Nginx et principes de fonctionnement
Nginx se compose d'un noyau et de modules. La conception du noyau est très petite et concise, et le travail effectué est également très simple. Il lui suffit de trouver le fichier de configuration vers lequel transférer les clients. La demande de fin est mappée à un bloc d'emplacement (l'emplacement est une directive dans la configuration de Nginx, utilisée pour la correspondance d'URL), et chaque directive configurée à cet emplacement démarrera différents modules à compléter. l'ouvrage correspondant.
Les modules Nginx sont structurellement divisés en modules de base, modules de base et modules tiers :
Modules de base : Module HTTP, module EVENT et module MAIL
Modules de base : Module d'accès HTTP, module HTTP FastCGI, module proxy HTTP et module de réécriture HTTP,
Chapitre trois -modules de fête : Module de hachage de requête HTTP en amont, module de notification et module de clé d'accès HTTP.
Les modules développés par les utilisateurs en fonction de leurs propres besoins sont des modules tiers. C'est précisément avec le support d'autant de modules que les fonctions de Nginx sont si puissantes.
Les modules Nginx sont fonctionnellement divisés dans les trois catégories suivantes.
Gestionnaires (modules de processeur). Ce type de module traite directement les requêtes et effectue des opérations telles que la sortie de contenu et la modification des informations d'en-tête. Généralement, il ne peut y avoir qu’un seul module processeur Handlers.
Filtres (module de filtrage). Ce type de module modifie principalement le contenu sorti par d'autres modules de processeur, et est finalement sorti par Nginx.
Proxies (module de classe proxy). Ces modules sont des modules tels que HTTP Upstream de Nginx. Ces modules interagissent principalement avec certains services back-end tels que FastCGI pour implémenter des fonctions telles que le proxy de service et l'équilibrage de charge.
La figure 1-1 montre le processus normal de requête et de réponse HTTP du module Nginx.
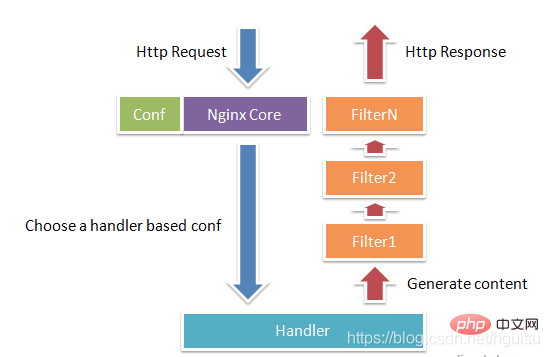
Nginx lui-même fait en réalité très peu de travail lorsqu'il reçoit une requête HTTP, il recherche simplement le fichier de configuration et cette requête est. mappé à un bloc d'emplacement, et chaque instruction configurée à cet emplacement démarrera différents modules pour terminer le travail, de sorte que les modules peuvent être considérés comme les véritables travailleurs de Nginx. Habituellement, les instructions dans un emplacement impliquent un module de gestion et plusieurs modules de filtrage (bien sûr, plusieurs emplacements peuvent réutiliser le même module). Le module gestionnaire est chargé de traiter les demandes et de terminer la génération du contenu de la réponse, tandis que le module de filtrage traite le contenu de la réponse.
Les modules Nginx sont directement compilés dans Nginx, il s'agit donc d'une méthode de compilation statique. Après le démarrage de Nginx, le module Nginx est automatiquement chargé. Contrairement à Apache, le module est d'abord compilé dans un fichier so, puis le chargement est spécifié dans le fichier de configuration. Lors de l'analyse du fichier de configuration, chaque module de Nginx peut traiter une certaine requête, mais la même requête de traitement ne peut être complétée que par un seul module.
2. Modèle de processus Nginx
En termes de méthode de travail, Nginx est divisé en un seul travailleur. processus et plusieurs processus de travail. En mode processus de travail unique, en plus du processus principal, il existe également un processus de travail, qui est monothread ; en mode processus multi-travailleurs, chaque processus de travail contient plusieurs threads. Nginx utilise par défaut le mode de processus de travail unique.
Après le démarrage de Nginx, il y aura un processus principal et plusieurs processus de travail.
1. Processus maître : processus de gestion
Le processus maître est principalement utilisé pour gérer le processus de travail, comprenant les 4 fonctions principales suivantes :
(1) Recevoir les signaux de le monde extérieur.
(2) Envoyez des signaux à chaque processus de travail.
(3) Surveillez l'état d'exécution du processus de travail.
(4) Lorsque le processus woker se termine (dans des circonstances anormales), le nouveau processus woker sera automatiquement redémarré.
Interface d'interaction utilisateur : Le processus maître sert d'interface interactive entre l'ensemble du groupe de processus et l'utilisateur, et surveille également le processus. Il n'a pas besoin de gérer les événements réseau et n'est pas responsable de l'exécution de l'entreprise. Il gérera uniquement les processus de travail pour implémenter des fonctions telles que le redémarrage du service, la mise à niveau en douceur, le remplacement des fichiers journaux et les fichiers de configuration prenant effet en temps réel.
Redémarrez le processus de travail : Pour contrôler nginx, il suffit d'envoyer un signal au processus maître via kill. Par exemple, kill -HUP pid indique à nginx de redémarrer nginx normalement. Nous utilisons généralement ce signal pour redémarrer nginx ou recharger la configuration. Parce qu'il redémarre correctement, le service n'est pas interrompu.
Que fait le processus maître après avoir reçu le signal HUP ?
1). Tout d'abord, après avoir reçu le signal, le processus maître rechargera le fichier de configuration, puis démarrera un nouveau processus de travail et enverra des signaux à tous les anciens processus de travail pour leur dire qu'ils peuvent être glorieux. Retraité.
2) Après le démarrage du nouveau travailleur, il commence à recevoir de nouvelles demandes, tandis que l'ancien travailleur cesse de recevoir de nouvelles demandes après avoir reçu le signal du maître, et dans le processus en cours Une fois toutes les demandes non traitées traitées, quittez .
Envoyer des signaux directement au processus maître. Il s'agit d'une méthode de fonctionnement plus traditionnelle. Après la version 0.8 de nginx, une série de paramètres de ligne de commande ont été introduits pour faciliter notre gestion. Par exemple, ./nginx -s reload consiste à redémarrer nginx, et ./nginx -s stop consiste à empêcher nginx de s'exécuter. Comment faire ? Prenons reload comme exemple. Nous voyons que lors de l'exécution de la commande, nous démarrons un nouveau processus nginx, et après que le nouveau processus nginx ait analysé le paramètre reload, nous savons que notre objectif est de contrôler nginx pour recharger le fichier de configuration. enverra un signal au processus maître, puis l'action suivante sera la même que si nous envoyions le signal directement au processus maître.
2. Processus de travail : traitement des demandes
Les événements réseau de base sont traités dans le processus de travail. Plusieurs processus de travail sont peer-to-peer. Ils sont en concurrence égale pour les demandes des clients et chaque processus est indépendant les uns des autres. Une demande ne peut être traitée que dans un seul processus de travail, et un processus de travail ne peut pas traiter les demandes provenant d'autres processus. Le nombre de processus de travail peut être défini. Généralement, nous le définirons pour qu'il soit cohérent avec le nombre de cœurs de processeur de la machine. La raison en est indissociable du modèle de processus et du modèle de traitement des événements de nginx.
Les processus de travail sont égaux et chaque processus a la même opportunité de traiter les demandes. Lorsque nous fournissons un service http sur le port 80 et qu'une demande de connexion arrive, chaque processus peut gérer la connexion. Comment faire cela ?
Nginx utilise une méthode asynchrone non bloquante pour gérer les événements réseau, similaire à Libevent. Le processus spécifique est le suivant :
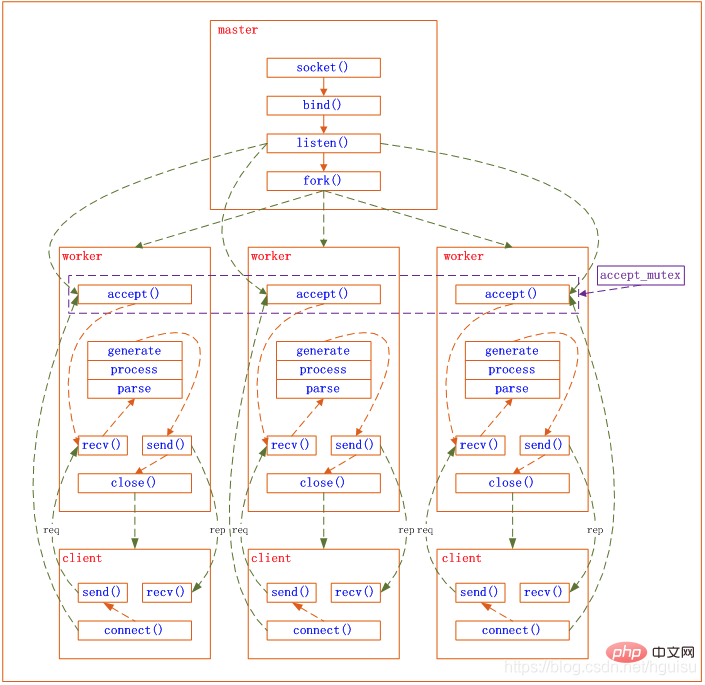
1) Recevoir les demandes : Tout d'abord, chacune. processus de travail Il est dérivé du processus maître. Une fois que le processus maître a établi le socket (listenfd) qui doit être écouté, il dérive ensuite plusieurs processus de travail. Le fichier d'écoute de tous les processus de travail deviendra lisible lorsqu'une nouvelle connexion arrivera, et chaque processus de travail pourra accepter ce socket (listenfd). Lorsqu'une connexion client arrive, tous les processus de travail d'acceptation seront notifiés, mais un seul processus pourra accepter avec succès et les autres ne parviendront pas à accepter. Pour garantir qu'un seul processus gère la connexion, Nginx fournit un verrou partagé accept_mutex pour garantir qu'un seul processus de travail accepte la connexion en même temps. Tous les processus de travail saisissent accept_mutex avant d'enregistrer l'événement de lecture Listenfd. Le processus qui récupère le verrou mutex enregistre l'événement de lecture Listenfd et appelle accept dans l'événement de lecture pour accepter la connexion.
2) Traitement des demandes : Une fois qu'un processus de travail a accepté la connexion, il commence à lire la demande, à analyser la demande, à traiter la demande, à générer des données, puis à les renvoyer au client , et enfin Déconnectez-vous, une demande aussi complète est comme ça.
Nous pouvons voir qu'une demande est entièrement traitée par le processus de travail, et n'est traitée que dans un seul processus de travail. Les processus de travail sont égaux et chaque processus a la même opportunité de traiter les demandes.
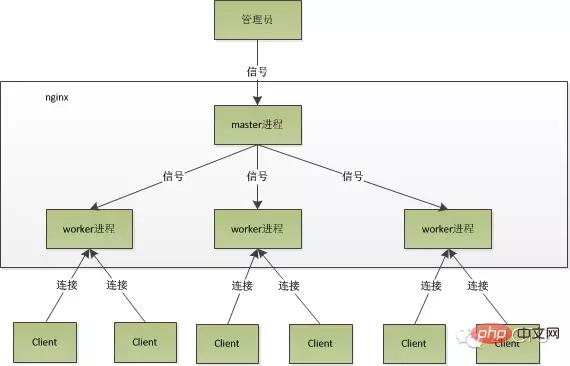
Le modèle de processus de nginx peut être représenté par la figure suivante :
3. Pourquoi Nginx a des performances élevées - modèle d'E/S multi-processus
Référence http://mp.weixin.qq.com/s?__biz=MjM5NTg2NTU0Ng==&mid=407889757&idx=3&sn=cfa8a70a5fd2a674a91076f67808273c&scene=23&srcid=0401aeJQEraSG6uvL j69Hfve#rd
1 , Les avantages de nginx en utilisant un modèle multi-processus
Tout d'abord, pour chaque processus de travail, il s'agit d'un processus indépendant et n'a pas besoin d'être verrouillé, donc la surcharge causé par le verrouillage est éliminé, et en même temps, cela sera également beaucoup plus pratique lors de la programmation et de la recherche de problèmes.
Deuxièmement, l'utilisation de processus indépendants ne s'affectera pas les uns les autres. Après la fin d'un processus, les autres processus fonctionnent toujours et le service ne sera pas interrompu. Bien sûr, si le processus de travail se termine anormalement, il doit y avoir un bogue dans le programme. Une sortie anormale entraînera l'échec de toutes les demandes sur le travailleur actuel, mais cela n'affectera pas toutes les demandes, le risque est donc réduit.
2. Modèle d'événement multi-processus nginx : asynchrone non bloquant
Bien que nginx utilise une méthode multi-travailleurs pour traiter les requêtes, il n'y a qu'un seul thread principal dans chaque travailleur, donc le nombre de simultanéités pouvant être traitées est très limité. Combien de simultanéités peuvent être traitées par combien de travailleurs ? atteint-il une concurrence élevée ? Non, c'est le génie de nginx. nginx utilise une méthode asynchrone non bloquante pour traiter les requêtes En d'autres termes, nginx peut les traiter en même temps. temps. Le nombre de requêtes qu'un processus de travail peut gérer en même temps n'est limité que par la taille de la mémoire, et en termes de conception architecturale, il n'y a presque aucune restriction de verrouillage de synchronisation lors du traitement de requêtes simultanées entre différents processus de travail et les processus de travail. les processus n'entrent généralement pas en état de veille. Par conséquent, lorsque le nombre de processus sur Nginx est égal au nombre de cœurs de processeur (il est préférable que chaque processus de travail soit lié à un cœur de processeur spécifique), le coût de commutation entre les processus. est minime.
Et le fonctionnement courant d'Apache (Apache a également une version asynchrone non bloquante, mais elle n'est pas couramment utilisée car elle entre en conflit avec certains de ses propres modules), chaque processus A ne traite qu'une seule demande à la fois Par conséquent, lorsque le nombre de concurrence atteint des milliers, il y aura des milliers de processus traitant les demandes en même temps. . C'est un grand défi pour le système d'exploitation. L'utilisation de la mémoire causée par le processus est très importante. Le changement de contexte du processus entraîne une surcharge du processeur, donc les performances augmenteront naturellement. . N'y allez pas, et la dépense n'a aucun sens.
Pourquoi nginx peut-il être traité de manière asynchrone non bloquante, ou qu'est-ce que le non bloquant asynchrone exactement ? Pour plus de détails, veuillez consulter : Utiliser libevent et libev pour améliorer les performances des applications réseau - Historique de l'évolution du modèle d'E/S
Revenons au point de départ et regardons le processus complet d'une requête : d'abord, la requête arrive et une connexion est établie. Ensuite, recevez les données, puis envoyez les données après avoir reçu les données.
Spécifique à la couche inférieure du système, ce sont les événements de lecture et d'écriture. Lorsque les événements de lecture et d'écriture ne sont pas prêts, ils doivent être inopérables si vous ne l'appelez pas de manière non bloquante. , vous devez bloquer l'appel et l'événement n'est pas prêt, vous ne pouvez alors qu'attendre que lorsque l'événement est prêt, vous pouvez continuer. Les appels bloquants entreront dans le noyau et attendront, et le CPU sera utilisé par d'autres. Pour les travailleurs monothread, cela ne convient évidemment pas. Lorsqu'il y a plus d'événements réseau, tout le monde attend et personne n'utilise le CPU quand c'est le cas. utilisation du processeur inactive. Naturellement, le taux ne peut pas augmenter, encore moins une concurrence élevée. Eh bien, vous avez dit augmenter le nombre de processus, quelle est la différence entre cela et le modèle de thread d'Apache, veillez à ne pas augmenter les changements de contexte inutiles ? Par conséquent, dans nginx, le blocage des appels système est le plus tabou. Ne bloquez pas, alors ce n'est pas bloquant. Non bloquant signifie que si l'événement n'est pas prêt, il reviendra immédiatement à EAGAIN pour vous dire que l'événement n'est pas encore prêt. Pourquoi revenez-vous plus tard ? D'accord, après un certain temps, vérifiez à nouveau l'événement jusqu'à ce qu'il soit prêt. Pendant cette période, vous pouvez d'abord faire autre chose, puis vérifier si l'événement est prêt. Bien qu'il ne soit plus bloqué, vous devez vérifier l'état de l'événement de temps en temps. Vous pouvez faire plus de choses, mais la surcharge n'est pas minime.
À propos du modèle IO : http://blog.csdn.net/hguisu/article/details/7453390
Les modèles d'événements pris en charge par nginx sont les suivants suit (wiki nginx) :
Nginx prend en charge les méthodes suivantes pour traiter les connexions (méthodes de multiplexage d'E/S), qui peuvent être spécifiées via la directive use.
- select – Méthode standard. Il s’agit de la méthode par défaut au moment de la compilation s’il n’existe pas de méthode plus efficace pour la plateforme actuelle. Vous pouvez activer ou désactiver ce module à l'aide des paramètres de configuration –with-select_module et –without-select_module.
- sondage – Méthode standard. Il s’agit de la méthode par défaut au moment de la compilation s’il n’existe pas de méthode plus efficace pour la plateforme actuelle. Vous pouvez activer ou désactiver ce module à l'aide des paramètres de configuration –with-poll_module et –without-poll_module.
- kqueue – Méthode efficace utilisée dans FreeBSD 4.1+, OpenBSD 2.9+, NetBSD 2.0 et MacOS X. Les systèmes MacOS X utilisant deux processeurs utilisent kqueue Peut provoquer un crash du noyau .
- epoll – Une méthode efficace, utilisée dans les systèmes du noyau Linux version 2.6 et ultérieures. Dans certaines distributions, comme SuSE 8.2, il existe un correctif pour prendre en charge epoll dans le noyau 2.4.
- rtsig – Signal exécutable en temps réel, utilisé dans les systèmes avec le noyau Linux version 2.2.19 ou ultérieure. Par défaut, pas plus de 1 024 signaux POSIX en temps réel (en file d’attente) peuvent apparaître dans l’ensemble du système. Cette situation est inefficace pour les serveurs très chargés ; il est donc nécessaire d'augmenter la taille de la file d'attente en ajustant le paramètre du noyau /proc/sys/kernel/rtsig-max. Cependant, à partir de la version 2.6.6-mm2 du noyau Linux, ce paramètre n'est plus utilisé et il existe une file d'attente de signaux indépendante pour chaque processus. La taille de cette file d'attente peut être ajustée avec le paramètre RLIMIT_SIGPENDING. Lorsque cette file d'attente devient trop encombrée, nginx l'abandonne et commence à utiliser la méthode poll pour gérer les connexions jusqu'au retour à la normale.
- /dev/poll – méthode efficace, utilisée sur Solaris 7 11/99+, HP/UX 11.22+ (eventport), IRIX 6.5.15+ et Tru64 UNIX 5.1A+ <.>
- eventport – Méthode efficace, utilisée sur Solaris 10. Afin d'éviter les plantages du noyau, il est nécessaire d'installer ce correctif de sécurité.
Epoll est créé par le noyau Linux pour gérer de gros lots de handles Amélioré sondage. Pour utiliser epoll, vous n'avez besoin que de ces trois appels système : epoll_create(2), epoll_ctl(2), epoll_wait(2). Elle a été introduite dans le noyau Linux 2.5.44 (epoll(4) est une nouvelle API introduite dans le noyau Linux 2.5.44) et est largement utilisée dans le noyau 2.6.
Avantages d'epoll
- Prend en charge un processus pour ouvrir un grand nombre de descripteurs de socket (FD)
- L'efficacité des E/S ne diminue pas linéairement à mesure que le nombre de FD augmente
Une autre faiblesse fatale de la sélection/interrogation traditionnelle est que lorsque vous disposez d'un grand jeu de sockets, en raison de la latence du réseau, Seules certaines sockets sont « actives » à tout moment, mais chaque appel à select/poll analysera linéairement l’ensemble de la collection, entraînant une baisse linéaire de l’efficacité. Mais epoll n'a pas ce problème, il ne fonctionnera que sur les sockets "actifs" - en effet, dans l'implémentation du noyau, epoll est implémenté sur la base de la fonction de rappel sur chaque fd. Ensuite, seules les sockets "actives" appelleront activement la fonction de rappel, et les autres sockets inactives ne le feront pas. À ce stade, epoll implémente un "pseudo" AIO, car à ce stade, la force motrice se trouve dans le noyau du système d'exploitation. Dans certains tests, si tous les sockets sont fondamentalement actifs - comme dans un environnement LAN haut débit, epoll n'est pas plus efficace que select/poll. Au contraire, si epoll_ctl est trop utilisé, l'efficacité diminuera légèrement. Mais une fois que les connexions inactives sont utilisées pour simuler un environnement WAN, l’efficacité d’epoll est bien supérieure à celle de select/poll.
- Utilisez mmap pour accélérer le passage des messages entre le noyau et l'espace utilisateur.
Ce point implique en fait la mise en œuvre spécifique d'epoll. Qu'il s'agisse de select, poll ou epoll, le noyau doit notifier l'espace utilisateur du message FD. Comment éviter les copies de mémoire inutiles est très important à ce stade, epoll est implémenté par mmap dans la même mémoire dans l'espace utilisateur. noyau. Et si comme moi vous suivez epoll depuis le noyau 2.5, vous n'oublierez certainement pas l'étape mmap manuelle.
- Réglage fin du noyau
Ce n'est en fait pas un avantage d'epoll, mais un avantage de l'ensemble de la plateforme Linux. Vous pouvez peut-être douter de la plate-forme Linux, mais vous ne pouvez pas éviter la possibilité que la plate-forme Linux vous offre d'affiner le noyau. Par exemple, la pile de protocole TCP/IP du noyau utilise un pool de mémoire pour gérer la structure sk_buff, puis la taille de ce pool de mémoire (skb_head_pool) peut être ajustée dynamiquement pendant l'exécution - complétée par echo XXXX>/proc/sys/net/core /hot_list_length. Un autre exemple est le deuxième paramètre de la fonction d'écoute (la longueur de la file d'attente des paquets une fois que TCP a terminé la négociation à trois), qui peut également être ajusté dynamiquement en fonction de la taille de la mémoire de votre plate-forme. Nous avons même essayé la dernière architecture de pilote de carte réseau NAPI sur un système spécial où le nombre de paquets de données est énorme mais la taille de chaque paquet de données lui-même est très petite.
(contenu epoll, reportez-vous à l'encyclopédie epoll_Interactive)
Il est recommandé de définir le nombre de travailleurs sur le nombre de cœurs du processeur , ce qui est très important ici. Il est facile de comprendre qu'un plus grand nombre de travailleurs ne fera qu'amener les processus à rivaliser pour les ressources CPU, ce qui entraînera un changement de contexte inutile. De plus, afin de mieux utiliser les fonctionnalités multicœurs, nginx fournit une option de liaison par affinité CPU. Nous pouvons lier un certain processus à un certain cœur, afin que le cache n'échoue pas en raison d'un changement de processus. De petites optimisations comme celle-ci sont très courantes dans nginx, et cela illustre également les efforts minutieux de l'auteur de nginx. Par exemple, lorsque nginx compare des chaînes de 4 octets, il convertit les 4 caractères en type int, puis les compare pour réduire le nombre d'instructions CPU, etc.
Code pour résumer le modèle de traitement des événements nginx :
while (true) {
for t in run_tasks:
t.handler();
update_time(&now);
timeout = ETERNITY;
for t in wait_tasks: /* sorted already */
if (t.time <= now) {
t.timeout_handler();
} else {
timeout = t.time - now;
break;
}
nevents = poll_function(events, timeout);
for i in nevents:
task t;
if (events[i].type == READ) {
t.handler = read_handler;
} else { /* events[i].type == WRITE */
t.handler = write_handler;
}
run_tasks_add(t);
}
4. Principe de fonctionnement de Nginx+FastCGI
1. Qu'est-ce que FastCGI
FastCGI est un An évolutif et rapide. interface de communication entre le serveur HTTP et le langage de script dynamique. Les serveurs HTTP les plus populaires prennent en charge FastCGI, notamment Apache, Nginx, lighttpd, etc. Dans le même temps, FastCGI est également pris en charge par de nombreux langages de script, dont PHP.
FastCGI est développé et amélioré à partir de CGI. Le principal inconvénient de la méthode d'interface CGI traditionnelle est la faible performance, car chaque fois que le serveur HTTP rencontre un programme dynamique, l'analyseur de script doit être redémarré pour effectuer l'analyse, puis les résultats sont renvoyés au serveur HTTP. Ceci est presque inutilisable lorsqu’il s’agit d’un accès simultané élevé. De plus, la méthode d'interface CGI traditionnelle est peu sécurisée et est rarement utilisée aujourd'hui.
Le mode d'interface FastCGI adopte la structure C/S, qui peut séparer le serveur HTTP et le serveur d'analyse de script, et démarrer un ou plusieurs démons d'analyse de script sur le serveur d'analyse de script. Chaque fois que le serveur HTTP rencontre un programme dynamique, celui-ci peut être transmis directement au processus FastCGI pour exécution, puis le résultat est renvoyé au navigateur. Cette méthode permet au serveur HTTP de traiter exclusivement les requêtes statiques ou de renvoyer les résultats du serveur de script dynamique au client, ce qui améliore considérablement les performances de l'ensemble du système d'application.
2. Principe de fonctionnement de Nginx+FastCGI
Nginx ne prend pas en charge l'appel direct ou l'analyse de tous les programmes externes (y compris PHP. ) doit être appelé via l'interface FastCGI. L'interface FastCGI est une socket sous Linux (cette socket peut être une socket file ou une socket ip).
wrapper : Pour appeler un programme CGI, un wrapper FastCGI est également nécessaire (un wrapper peut être compris comme un programme utilisé pour démarrer un autre programme. Ce wrapper est lié à un socket fixe). comme un port ou un socket de fichier. Lorsque Nginx envoie une requête CGI à ce socket, le wrapper reçoit la requête via l'interface FastCGI, puis force (dérive) un nouveau thread. Ce thread appelle l'interpréteur ou le programme externe pour traiter le script et lire ensuite les données de retour ; Le wrapper transmet ensuite les données renvoyées à Nginx via l'interface FastCGI et enfin, via le socket fixe, Nginx envoie les données renvoyées (page html ou image) au client. Il s'agit de l'ensemble du processus de fonctionnement de Nginx+FastCGI, comme le montre la figure 1-3.
>Communiquer avec Ningx via les sockets en appelant les fonctions fastcgi (bibliothèque) (les sockets de lecture et d'écriture sont des fonctions implémentées en interne par fastcgi et ne sont pas transparentes pour le wrapper) 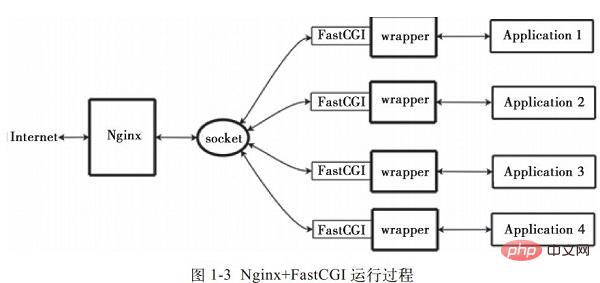 Planification des threads, forking et kill
Planification des threads, forking et kill
Communiquer avec l'application (php)
- 3. spawn-fcgi et PHP-FPM Interface FastCGI. La méthode démarre un serveur d'analyse de scripts. Ou plusieurs processus démons analysent des scripts dynamiques. Ces processus sont le gestionnaire de processus FastCGI ou le moteur FastCGI. spawn-fcgi et PHP-FPM sont deux gestionnaires de processus FastCGI prenant en charge PHP.
Les similitudes et les différences entre spawn-fcgi et PHP-FPM :
1) spawn-fcgi fait partie du serveur HTTP lighttpd Il est devenu un projet indépendant et est généralement. utilisé conjointement avec lighttpd. PHP est pris en charge. Cependant, spwan-fcgi de ligttpd peut provoquer des fuites de mémoire ou même redémarrer automatiquement FastCGI lors d'accès simultanés élevés. Autrement dit : le processeur de script PHP plante. Si l'utilisateur y accède à ce moment-là, une page blanche peut apparaître (c'est-à-dire que PHP ne peut pas être analysé ou qu'une erreur se produit). 2) Nginx est un serveur HTTP léger et doit utiliser un processeur FastCGI tiers pour analyser PHP Donc, cela ressemble en fait à ceci nginx
est. très flexible. Il peut être connecté à n'importe quel processeur d'analyse tiers pour réaliser l'analyse de
PHP
(Facilement configuré dans nginx.conf). nginx peut également utiliser spwan-fcgi ( doit être installé avec lighttpd, mais vous devez évitez les ports pour nginx Certains blogs plus anciens ont des tutoriels d'installation à cet égard<🎜)<🎜. >, mais comme spawn-fcgi présente les défauts progressivement découverts par les utilisateurs comme mentionné ci-dessus, l'utilisation de nginx+spawn-fcgi est désormais lentement réduite Combiné. En raison des défauts de spawn-fcgi, il existe désormais un processeur PHP FastCGI tiers (actuellement ajouté au noyau PHP) PHP-FPM. Par rapport à spawn-fcgi, il présente les avantages suivants. : Puisqu'il est développé en tant que patch PHP, il doit être compilé avec le code source PHP lors de l'installation, ce qui signifie qu'il est compilé dans le noyau PHP, il est donc meilleur en termes de performances <🎜 ; > En même temps, il est également meilleur que spawn-fcgi pour gérer une concurrence élevée, au moins il ne redémarrera pas automatiquement le processeur fastcgi. Par conséquent, il est recommandé d’utiliser la combinaison Nginx+PHP/PHP-FPM pour analyser PHP. Comparé à Spawn-FCGI, PHP-FPM a un meilleur contrôle du processeur et de la mémoire, et le premier plante facilement et doit être surveillé avec crontab, tandis que PHP-FPM n'a pas de tels problèmes. Le principal avantage de FastCGI est de séparer les langages dynamiques du serveur HTTP, donc Nginx et PHP/PHP-FPM sont souvent déployés sur des serveurs différents pour partager la pression sur le serveur Nginx front-end et permettre à Nginx de gérer exclusivement requêtes statiques et transmettent les requêtes dynamiques, tandis que le serveur PHP/PHP-FPM analyse exclusivement les requêtes dynamiques PHP.
4. Nginx+PHP-FPM
PHP-FPM est un gestionnaire pour FastCGI Il existe sous forme de plug-in pour PHP lorsque vous installez PHP et que vous souhaitez utiliser PHP. -FPM Dans l'ancienne version de l'ancien php (avant php5.3.3), PHP-FPM doit être installé dans PHP sous la forme d'un patch, et PHP doit être cohérent avec la version PHP-FPM, ce qui est indispensable)
PHP- FPM est en fait un patch du code source PHP, conçu pour intégrer la gestion des processus FastCGI dans le package PHP. Il doit être corrigé dans votre code source PHP et peut être utilisé après la compilation et l'installation de PHP.
PHP5.3.3 a intégré php-fpm et n'est plus un package tiers. PHP-FPM fournit une meilleure méthode de gestion des processus PHP, peut contrôler efficacement la mémoire et les processus et recharger en douceur la configuration PHP. Il présente plus d'avantages que spawn-fcgi, il est donc officiellement inclus dans PHP. Vous pouvez activer PHP-FPM en passant le paramètre –enable-fpm dans ./configure.
Fastcgi est déjà au cœur de php5.3.5 Il n'est pas nécessaire d'ajouter --enable-fastcgi lors de la configuration. Les anciennes versions telles que php5.2 doivent ajouter cet élément.
Lorsque nous installons Nginx et PHP-FPM, les informations de configuration :
Configuration par défaut de PHP-FPM php-fpm.conf :
Listen_address 127.0.0.1:9000 #Ceci représente l'adresse IP et le port que le processus fastcgi de PHP écoute
start_servers
min_spare_servers
max_spare_servers
Configuration Nginx pour exécuter php : modifiez nginx.conf et ajoutez l'instruction suivante :
emplacement ~ .php$ {
root html;
fastcgi_pass 127.0.0.1:9000 spécifie le port d'écoute du processus fastcgi, nginx; interagit avec php via ici
fastcgi_index index.php;
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME /usr/local/nginx/html$fastcgi_script_name;
}
Nginx utilise la commande location pour transmettre tous les fichiers avec php comme suffixe à 127.0.0.1:9000 pour le traitement, et l'adresse IP et le port voici les adresses IP et les ports que le processus FastCGI écoute .
Son flux de travail global :
1) Le gestionnaire de processus FastCGI php-fpm s'initialise, démarre le processus principal php-fpm et démarre start_servers le processus enfant CGI.
<<> Le processus principal PHP-FPM gère principalement les sous-processus FastCGI et surveille 9000 ports.
sous-processus fastcgi En attente d'une connexion depuis le serveur Web.
2) Lorsque la requête du client atteint le serveur Web Nginx,Nginx utilise la commande location pour remettre tous les fichiers avec php comme suffixe à 127.0.0.1:9000 Pour traiter , c'est-à-dire que Nginx utilise la commande location pour transmettre tous les fichiers avec php comme suffixe à 127.0.0.1:9000 pour traitement.
3) FastCGI Process Manager PHP-FPM sélectionne et se connecte à un interpréteur CGI de processus enfant. Le serveur Web envoie des variables d'environnement CGI et une entrée standard au processus enfant FastCGI. 4). Une fois le sous-processus FastCGI terminé, il renvoie la sortie standard et les informations d'erreur au serveur Web à partir de la même connexion. Lorsque le processus enfant FastCGI ferme la connexion, la demande est traitée. 5). Le processus enfant FastCGI attend et traite ensuite la prochaine connexion du gestionnaire de processus FastCGI (exécuté dans WebServer).5. Configuration correcte de Nginx+PHP
Généralement, le web a une entrée unifiée : put PHP request Tous sont envoyés dans le même fichier, puis le routage est implémenté en analysant "REQUEST_URI" dans ce fichier.
Le fichier de configuration Nginx est divisé en plusieurs blocs. Les plus courants de l'extérieur vers l'intérieur sont "http", "serveur", "emplacement", etc. La relation d'héritage par défaut est de l'extérieur vers l'intérieur. C'est-à-dire que le bloc interne obtiendra automatiquement la valeur du bloc externe comme valeur par défaut.
Par exemple :
server {
listen 80;
server_name foo.com;
root /path;
location / {
index index.html index.htm index.php;
if (!-e $request_filename) {
rewrite . /index.php last;
}
}
location ~ \.php$ {
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME /path$fastcgi_script_name;
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
}
}1) 不应该在location 模块定义index
一旦未来需要加入新的「location」,必然会出现重复定义的「index」指令,这是因为多个「location」是平级的关系,不存在继承,此时应该在「server」里定义「index」,借助继承关系,「index」指令在所有的「location」中都能生效。
2) 使用try_files
接下来看看「if」指令,说它是大家误解最深的Nginx指令毫不为过:
if (!-e $request_filename) {
rewrite . /index.php last;
}
很多人喜欢用「if」指令做一系列的检查,不过这实际上是「try_files」指令的职责:
try_files $uri $uri/ /index.php;
除此以外,初学者往往会认为「if」指令是内核级的指令,但是实际上它是rewrite模块的一部分,加上Nginx配置实际上是声明式的,而非过程式的,所以当其和非rewrite模块的指令混用时,结果可能会非你所愿。
3)fastcgi_params」配置文件:
include fastcgi_params;
Nginx有两份fastcgi配置文件,分别是「fastcgi_params」和「fastcgi.conf」,它们没有太大的差异,唯一的区别是后者比前者多了一行「SCRIPT_FILENAME」的定义:
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
注意:$document_root 和 $fastcgi_script_name 之间没有 /。
原本Nginx只有「fastcgi_params」,后来发现很多人在定义「SCRIPT_FILENAME」时使用了硬编码的方式,于是为了规范用法便引入了「fastcgi.conf」。
不过这样的话就产生一个疑问:为什么一定要引入一个新的配置文件,而不是修改旧的配置文件?这是因为「fastcgi_param」指令是数组型的,和普通指令相同的是:内层替换外层;和普通指令不同的是:当在同级多次使用的时候,是新增而不是替换。换句话说,如果在同级定义两次「SCRIPT_FILENAME」,那么它们都会被发送到后端,这可能会导致一些潜在的问题,为了避免此类情况,便引入了一个新的配置文件。
此外,我们还需要考虑一个安全问题:在PHP开启「cgi.fix_pathinfo」的情况下,PHP可能会把错误的文件类型当作PHP文件来解析。如果Nginx和PHP安装在同一台服务器上的话,那么最简单的解决方法是用「try_files」指令做一次过滤:
try_files $uri =404;
依照前面的分析,给出一份改良后的版本,是不是比开始的版本清爽了很多:
server {
listen 80;
server_name foo.com;
root /path;
index index.html index.htm index.php;
location / {
try_files $uri $uri/ /index.php;
}
location ~ \.php$ {
try_files $uri =404;
include fastcgi.conf;
fastcgi_pass 127.0.0.1:9000;
}
}六. Nginx优化
1. 编译安装过程优化
1).减小Nginx编译后的文件大小
在编译Nginx时,默认以debug模式进行,而在debug模式下会插入很多跟踪和ASSERT之类的信息,编译完成后,一个Nginx要有好几兆字节。而在编译前取消Nginx的debug模式,编译完成后Nginx只有几百千字节。因此可以在编译之前,修改相关源码,取消debug模式。具体方法如下:
在Nginx源码文件被解压后,找到源码目录下的auto/cc/gcc文件,在其中找到如下几行:
# debug CFLAGS=”$CFLAGS -g”
注释掉或删掉这两行,即可取消debug模式。
2.为特定的CPU指定CPU类型编译优化
在编译Nginx时,默认的GCC编译参数是“-O”,要优化GCC编译,可以使用以下两个参数:
- --avec-cc-opt='-O3'
- --avec-cpu -opt=CPU #Compile pour un CPU spécifique, les valeurs valides incluent :
pentium, pentiumpro, pentium3, #pentium4, athlon, opteron , amd64, sparc32, sparc64, ppc64
Pour déterminer le type de CPU, vous pouvez utiliser la commande suivante : #cat /proc/cpuinfo | grep "model name"
2. Utilisez TCMalloc pour optimiser les performances de Nginx
Le nom complet de TCMalloc est Thread-Caching Malloc, qui est l'un des les outils open source google-perftools développés par le membre Google. Par rapport au Malloc de la bibliothèque glibc standard, la bibliothèque TCMalloc est beaucoup plus efficace et rapide en termes d'allocation de mémoire, ce qui améliore considérablement les performances du serveur dans des situations de forte concurrence, réduisant ainsi la charge sur le système. Ce qui suit est une brève introduction sur la façon d'ajouter la prise en charge de la bibliothèque TCMalloc à Nginx.
Pour installer la bibliothèque TCMalloc, vous devez installer les deux packages logiciels libunwind (les systèmes d'exploitation 32 bits n'ont pas besoin d'être installés) et google-perftools. La bibliothèque libunwind fournit une chaîne d'appel de fonctions de base pour les programmes. basé sur des processeurs et des systèmes d'exploitation 64 bits et des fonctions de registre d'appel de fonction. Ce qui suit décrit le processus opérationnel spécifique d'utilisation de TCMalloc pour optimiser Nginx.
1). Installez la bibliothèque libunwind
Vous pouvez télécharger la version libunwind correspondante depuis http://download.savannah.gnu.org/releases/libunwind, téléchargée ici, c'est libunwind-0.99-alpha.tar.gz. Le processus d'installation est le suivant
#tar zxvf libunwind-0.99-alpha.tar.gz
# cd libunwind-0.99-alpha/
#CFLAGS=-fPIC ./configure
# make CFLAGS= -fPIC
#make CFLAGS=-fPIC install
2). Installez google-perftools
à partir de http://google-perftools.googlecode .com Téléchargez la version google-perftools correspondante. Celle téléchargée ici est google-perftools-1.8.tar.gz. Le processus d'installation est le suivant :
[root@localhost home]#tar zxvf google-perftools-1.8.tar.gz
[root@localhost home]#cd google-perftools-1.8/
[root @localhost google-perftools-1.8]# ./configure
[root@localhost google-perftools-1.8]#make && make install
[root@localhost google-perftools-1.8]#echo "/ usr/
local/lib" > /etc/ld.so.conf.d/usr_local_lib.conf
[root@localhost google-perftools-1.8]# ldconfig
À ce stade, l'installation de google-perftools est terminée.
3). Recompiler Nginx
Pour que Nginx prenne en charge google-perftools, vous devez ajouter l'option "-with-google_perftools_module" pendant le processus d'installation. recompiler Nginx. Le code d'installation est le suivant :
[root@localhostnginx-0.7.65]#./configure
>--with-google_perftools_module --with-http_stub_status_module --prefix=/opt/nginx
[ root@localhost nginx-0.7.65]#make
[root@localhost nginx-0.7.65]#make install
Ici, l'installation de Nginx est terminée.
4). Ajoutez un répertoire de threads pour google-perftools
Créez un répertoire de threads et placez le fichier sous /tmp/tcmalloc. Le fonctionnement est le suivant :
[root@localhost home]#mkdir /tmp/tcmalloc
[root@localhost home]#chmod 0777 /tmp/tcmalloc
5 ). Modification du fichier de configuration principal de Nginx
Modifiez le fichier nginx.conf et ajoutez le code suivant sous la ligne pid :
#pid logs/nginx.pid
google_perftools_profiles; /tmp/ tcmalloc;
Ensuite, redémarrez Nginx pour terminer le chargement de google-perftools.
6). Vérifier l'état d'exécution
Afin de vérifier que google-perftools a été chargé normalement, vous pouvez le visualiser via la commande suivante :
[root@localhost home]# lsof -n | grep tcmalloc
nginx 2395 personne 9w REG 8,8 0 1599440 /tmp/tcmalloc.2395
nginx 2396 personne 11 w REG 8,8 0 1599443 / tmp /tcmalloc.2396
nginx 2397 personne 13w REG 8,8 0 1599441 /tmp/tcmalloc.2397
nginx 2398 personne 15w REG 8,8 0 1599442 /tmp/tcmalloc.2398
En raison to La valeur de work_processes est définie sur 4 dans le fichier de configuration Nginx, donc 4 threads Nginx sont ouverts et chaque thread aura une ligne d'enregistrements. La valeur numérique après chaque fichier de thread est la valeur pid de Nginx démarré.
À ce stade, l'opération d'utilisation de TCMalloc pour optimiser Nginx est terminée.
3. Optimisation des paramètres du noyau Nginx
L'optimisation des paramètres du noyau est principalement l'optimisation des paramètres du noyau système pour les applications Nginx dans les systèmes Linux.
Un exemple d'optimisation est donné ci-dessous à titre de référence.
net.ipv4.tcp_max_tw_buckets = 6000
net.ipv4.ip_local_port_range = 1024 65000
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_tw_reuse = 1
net.ip v4 .tcp_syncookies = 1
net.core.somaxconn = 262144
net.core.netdev_max_backlog = 262144
net.ipv4.tcp_max_orphans = 262144
net.ipv4.tcp_max_syn_backlog = 262144
net. ipv4 .tcp_synack_retries = 1
net.ipv4.tcp_syn_retries = 1
net.ipv4.tcp_fin_timeout = 1
net.ipv4.tcp_keepalive_time = 30
Ajoutez les valeurs des paramètres du noyau ci-dessus au fichier /etc/sysctl.conf, puis exécutez la commande suivante pour la rendre efficace :
[root@localhost home]# /sbin/sysctl -p
Ce qui suit présente la signification des options dans l'exemple :
Paramètres TCP :
net .ipv4.tcp_max_tw_buckets : L'option est utilisée pour définir le nombre de délais d'attente. La valeur par défaut est 180 000, ici elle est définie sur 6000.
net.ipv4.ip_local_port_range : L'option est utilisée pour définir la plage de ports que le système est autorisé à ouvrir. Dans les situations de forte concurrence sinon le numéro de port ne suffira pas. Lorsque NGINX fait office de proxy, chaque connexion au serveur amont utilise un port éphémère ou éphémère.
net.ipv4.tcp_tw_recycle : l'option est utilisée pour définir et activer le recyclage rapide en attente.
L'option net.ipv4.tcp_tw_reuse : est utilisée pour configurer la réutilisation, permettant aux sockets TIME-WAIT d'être réutilisées pour de nouvelles connexions TCP.
net.ipv4.tcp_syncookies : L'option est utilisée pour configurer les cookies SYN Lorsque la file d'attente SYN déborde, les cookies sont activés pour le traitement.
net.ipv4.tcp_max_orphans : L'option est utilisée pour définir le nombre maximum de sockets TCP dans le système qui ne sont associés à aucun descripteur de fichier utilisateur. Si ce nombre est dépassé, la connexion orpheline sera immédiatement réinitialisée et un message d'avertissement imprimé. Cette restriction vise uniquement à empêcher de simples attaques DoS. Vous ne pouvez pas trop vous fier à cette limite ni même réduire artificiellement cette valeur. Dans la plupart des cas, vous devez augmenter cette valeur.
net.ipv4.tcp_max_syn_backlog : L'option est utilisée pour enregistrer la valeur maximale des demandes de connexion qui n'ont pas encore reçu d'informations de confirmation du client. La valeur par défaut de ce paramètre est 1024 pour les systèmes dotés de 128 Mo de mémoire et 128 pour les systèmes dotés de petite mémoire.
La valeur du paramètre net.ipv4.tcp_synack_retries détermine le nombre de paquets SYN+ACK envoyés avant que le noyau n'abandonne la connexion.
L'option net.ipv4.tcp_syn_retries indique le nombre de paquets SYN à envoyer avant que le noyau n'abandonne l'établissement de la connexion.
L'option net.ipv4.tcp_fin_timeout détermine la durée pendant laquelle le socket reste dans l'état FIN-WAIT-2. La valeur par défaut est de 60 secondes. Il est très important de définir correctement cette valeur. Parfois, même un serveur Web peu chargé aura un grand nombre de sockets morts et risquera un débordement de mémoire.
L'option net.ipv4.tcp_syn_retries indique le nombre de paquets SYN envoyés avant que le noyau n'abandonne l'établissement d'une connexion.
Si l'expéditeur demande la fermeture du socket, l'option net.ipv4.tcp_fin_timeout détermine la durée pendant laquelle le socket reste dans l'état FIN-WAIT-2. L'extrémité réceptrice peut commettre des erreurs et ne jamais fermer la connexion, voire même planter de manière inattendue.
La valeur par défaut de net.ipv4.tcp_fin_timeout est de 60 secondes. Il convient de noter que même un serveur Web avec une faible charge risque de déborder de mémoire en raison d'un grand nombre de sockets morts. FIN-WAIT-2 est moins dangereux que FIN-WAIT-1 car il ne peut consommer que 1,5 Ko de mémoire, mais sa durée de vie est plus longue.
L'option net.ipv4.tcp_keepalive_time indique la fréquence à laquelle TCP envoie des messages keepalive lorsque keepalive est activé. La valeur par défaut est 2 (les unités sont des heures).
File d'attente tampon :
net.core.somaxconn :
est déterminé par le nombre accepté par NGINX. La valeur par défaut est généralement faible, mais acceptable car NGINX reçoit les connexions très rapidement, mais vous devez augmenter cette valeur si votre site Web a un trafic important. Les messages d'erreur dans le journal du noyau vous rappelleront que cette valeur est trop petite. Augmentez la valeur jusqu'à ce que le message d'erreur disparaisse. Remarque : Si vous définissez cette valeur sur une valeur supérieure à 512, vous devez également modifier le paramètre backlog de la commande d'écoute NGINX en conséquence. L'option
net.core.netdev_max_backlog : indique quand chaque interface réseau reçoit des paquets plus rapidement que le noyau ne peut les traiter. Le nombre maximum de paquets autorisés à être envoyés dans la file d’attente.
4. Optimisation de PHP-FPM
Si votre site Web à forte charge utilise PHP-FPM pour gérer FastCGI, ces conseils peut être utile Utile pour vous :1) Augmentez le nombre de processus FastCGI
Ajustez le nombre de sous-processus PHP FastCGI à 100 ou plus sur un serveur. avec une mémoire 4G, 200 sont recommandés pour un test de résistance pour obtenir la meilleure valeur.2) Augmenter la limite des descripteurs de fichiers ouverts PHP-FPM
La balise rlimit_files est utilisée pour définir la limite de PHP-FPM sur les descripteurs de fichiers ouverts La valeur par défaut. la valeur est 1024 . La valeur de ce label doit être associée au nombre de fichiers ouverts dans le noyau Linux. Par exemple, pour définir cette valeur à 65 535, vous devez exécuter "ulimit -HSn 65536" sur la ligne de commande Linux. PuisAugmentez la limite des descripteurs de fichiers ouverts PHP-FPM : # vi /path/to/php-fpm.conf
Recherchez
«
. Redémarrez PHP-FPM.
ulimit -n doit être ajusté à 65536 ou même plus. Comment régler ce paramètre, vous pouvez vous référer à certains articles sur Internet. Exécutez ulimit -n 65536 sur la ligne de commande pour le modifier. S'il ne peut pas être modifié, vous devez définir /etc/security/limits.conf et ajouter
* hard nofile65536
* soft nofile 65536
3) Augmenter de manière appropriée max_requests
Le La balise max_requests spécifie chaque nombre maximum de requêtes qu'un enfant peut traiter avant d'être fermé. Le paramètre par défaut est 500.
Optimisation des paramètres 5.nginx.conf
Le nombre de processus à démarrer par nginx est généralement égal au nombre total de cœurs du CPU. En fait, généralement 4 ou 8 suffisent. Chaque processus nginx consomme 10 Mo de mémoireworker_cpu_affinity Applicable uniquement à Linux, utilisez cette option pour lier le processus de travail et le CPU (2.4 La machine du noyau ne peut pas être utilisé)
S'il s'agit de 8 cpu, l'allocation est la suivante :
worker_cpu_affinity 00000001 00000010 00000100 00001000 00010000
00100000 01000000 10000000
nginx peut utiliser plusieurs processus de travail pour les raisons suivantes :
pour utiliser SMP
pour diminuer la latence lorsque les travailleurs bloquent les E/S du disque
pour limiter le nombre de connexions par processus lorsque select() /poll() est
utilisé Les worker_processes et worker_connections des sections d'événements
vous permettent de calculer la valeur maxclients : k max_clients = work_processes * work_connections
work_rlimit_nofile 102400;
La configuration du nombre maximum de descripteurs de fichiers ouverts pour chaque processus nginx doit être cohérente avec le nombre de fichiers ouverts pour un seul processus dans le système. Le nombre de fichiers ouverts sous le noyau Linux 2.6. est 65535, et worker_rlimit_nofile doit être rempli avec 65535 en conséquence. Lorsque nginx planifie, la demande d'allocation est Le processus n'est pas aussi équilibré. S'il dépasse la limite, une erreur 502 sera renvoyée. Ce que j'écris ici est plus important
utiliser epoll
Nginx utilise le dernier modèle d'E/S réseau epoll (noyau Linux 2.6) et kqueue (freebsd), tandis qu'Apache The le modèle de sélection traditionnel est utilisé.
Pour gérer la lecture et l'écriture d'un grand nombre de connexions, le modèle d'E/S réseau sélectionné adopté par Apache est très inefficace. Sur les serveurs à haute concurrence, l'interrogation des E/S est l'opération la plus longue. Actuellement, Linux peut supporter une concurrence élevée
Les accès Squid et Memcached utilisent le modèle d'E/S du réseau epoll.
worker_processes
Nombre de processus de travail NGINX (la valeur par défaut est 1). Dans la plupart des cas, il est préférable d'exécuter un processus de travail par cœur de processeur et il est recommandé de définir cette instruction sur automatique. Parfois, vous souhaiterez peut-être augmenter cette valeur, par exemple lorsque le processus de travail doit effectuer de nombreuses E/S disque.
worker_connections 65535;
Le nombre maximum de connexions simultanées autorisées par processus de travail (Maxclient = work_processes * worker_connections)
keepalive_timeout 75
Keepalive timeout
Ici, vous devez faire attention à la phrase officielle :
Les paramètres peuvent différer les uns des autres :
timeout=time comprend. Mozilla et Konqueror. MSIE lui-même ferme la connexion
keep-alive après 60 secondes environ 🎜>Taille du tampon d'en-tête de la demande du client
Par défaut, nginx utilisera le tampon client_header_buffer_size pour lire la valeur de l'en-tête If. l'en-tête est trop grand, il utilisera large_client_header_buffers pour lire
Si l'en-tête HTTP est trop petit /Cookie signalera une erreur 400 nginx 400 mauvaise requête Si la requête dépasse le tampon, il signalera HTTP Erreur 414 (URI trop long) nginx accepte que la taille de l'en-tête HTTP la plus longue doit être supérieure à l'un des tampons, sinon il signalera une erreur HTTP 400 (mauvaise demande).
open_file_cache max 102400
Utiliser les champs : http, serveur, emplacement Cette directive précise si le cache est activé. S'il est activé, les informations suivantes sur le fichier seront enregistrées. : · Caractère de description du fichier ouvert, informations sur la taille et heure de modification. · Informations sur le répertoire existant. · Message d'erreur lors de la recherche de fichier - sans ce fichier, il ne peut pas être lu correctement, reportez-vous aux options de la directive open_file_cache_errors :
Exemple : open_file_cache max=1000 inactive=20s; open_file_cache_min_uses 2;
Syntaxe : open_file_cache_errors on | off Valeur par défaut : open_file_cache_errors off Champs utilisés : http, serveur, location Cette directive précise s'il faut rechercher un fichier et enregistrer les erreurs de cache.
open_file_cache_min_uses
Syntaxe : open_file_cache_min_uses number Valeur par défaut : open_file_cache_min_uses 1 Champs d'utilisation : http, serveur, emplacement Cette directive spécifie le nombre minimum de fichiers pouvant être utilisés dans une certaine plage de temps dans les paramètres invalides de la directive open_file_cache Si une plus grande. valeur est utilisée, la description du fichier Le symbole est toujours ouvert dans le cache
Syntaxe : open_file_cache_valid time Valeur par défaut : open_file_cache_valid 60 Champs d'utilisation : http, serveur, location Cette directive précise quand cela est nécessaire. pour vérifier la validité des éléments mis en cache dans open_file_cache Information.
Activer gzip gzip on;
gzip_min_length 1k; gzip_buffers 4 16k;
gzip_http_version 1.0;
gzip_types text/ plain application/x-javascript text/css
application/xml;
gzip_vary on;
Cache les fichiers statiques :
emplacement ~* ^.+.(swf |gif|png|jpg|js|css)$ {
racine /usr/local/ku6/ktv/show.ku6.com/;
}
Tampon de réponse :
Par exemple, notre JS d'accès proxy Nginx+Tomcat ne peut pas être entièrement chargé. Ces paramètres affectent :
proxy_buffer_size 128k;
proxy_buffers 32 128k;
proxy_busy_buffers_size 128k;
Nginx obtient le fichier correspondant après avoir proxy le service correspondant ou en fonction de l'UpStream et de l'emplacement que nous avons configurés. Tout d'abord, le fichier sera configuré. be Analyser dans la mémoire de nginx ou dans le répertoire de fichiers temporaires, puis nginx répondra. Ensuite, lorsque proxy_buffers, proxy_buffer_size et proxy_busy_buffers_size sont trop petits, le contenu sera généré dans un fichier temporaire selon la configuration de nginx, mais la taille du fichier temporaire a également une valeur par défaut. Ainsi, lorsque ces quatre valeurs sont trop petites, seule une partie de certains fichiers sera chargée. Par conséquent, proxy_buffers, proxy_buffer_size, proxy_busy_buffers_size, proxy_temp_file_write_size doivent être ajustés de manière appropriée en fonction des conditions de notre serveur. Les détails des paramètres spécifiques sont les suivants :
proxy_buffers 32 128k ; 32 zones tampons sont configurées, la taille de chacune est de 128k
proxy_buffer_size 128k ; La taille de chaque zone tampon est de 128k ; , lorsque Lorsque les deux valeurs sont incohérentes et qu'aucune valeur spécifique valide n'est trouvée, il est recommandé d'être cohérent avec les paramètres ci-dessus.
proxy_busy_buffers_size 128k ; Définir la taille de la zone tampon utilisée et contrôler le cache maximum transféré au client
proxy_temp_file_write_size taille du fichier cache
6. Optimiser les journaux d'accès
La journalisation de chaque requête consomme du processeur et des cycles d'E/S. Une façon de réduire cet impact consiste à mettre en mémoire tampon les journaux d'accès. En utilisant la mise en mémoire tampon, plutôt que d'effectuer une opération d'écriture distincte pour chaque enregistrement de journal, NGINX met en mémoire tampon une série d'enregistrements de journal et les écrit ensemble dans un fichier en une seule opération.
Pour activer le cache des logs d'accès, cela implique le paramètre buffer=size dans la directive access_log. Lorsque le tampon atteint la valeur de taille, NGINX écrira le contenu du tampon dans le journal. Pour que NGINX écrive dans le cache après une période de temps spécifiée, incluez le paramètre flush=time. Lorsque les deux paramètres sont définis, NGINX écrira l'entrée dans le fichier journal lorsque l'entrée de journal suivante dépasse la valeur du tampon ou que l'entrée du journal dans le tampon dépasse la valeur de temps définie. Ceci est également enregistré lorsque le processus de travail rouvre son fichier journal ou se ferme. Pour désactiver complètement la journalisation des accès, définissez la directive access_log sur le paramètre off.
7. Limite actuelle
Vous pouvez définir plusieurs limites pour empêcher les utilisateurs de consommer. Trop de ressources pour éviter d'affecter les performances du système, l'expérience utilisateur et la sécurité. Voici les directives pertinentes :
limit_conn et limit_conn_zone : NGINX accepte une limite sur le nombre de connexions client, comme les connexions à partir d'une seule adresse IP. La définition de ces directives empêche un seul utilisateur d'ouvrir trop de connexions et de consommer plus de ressources qu'il ne peut en utiliser.
limit_rate : Limite de transfert à la vitesse de réponse du client (chaque client ouvrant plusieurs connexions consomme plus de bande passante). Fixer cette limite évite de surcharger le système et garantit une qualité de service plus uniforme pour tous les clients.
limit_req et limit_req_zone : La limite de débit pour les requêtes de traitement NGINX, qui a la même fonction que limit_rate. Vous pouvez améliorer la sécurité, notamment pour les pages de connexion, en définissant une valeur raisonnable pour le taux de requêtes limite des utilisateurs afin d'éviter que des programmes trop lents n'écrasent les requêtes de vos applications (comme les attaques DDoS).
max_conns : paramètres de commande du serveur dans le bloc de configuration du jeu . Nombre maximum de simultanéités qu'un seul serveur peut accepter dans un groupe de serveurs en amont. Utilisez cette limite pour éviter de surcharger le serveur en amont. Définir une valeur de 0 (valeur par défaut) signifie aucune limite.
file d'attente (NGINX Plus) : Créez une file d'attente pour stocker le nombre de requêtes dans le serveur en amont qui dépassent leur limite maximale de max_cons. Cette directive définit le nombre maximum de requêtes en file d'attente et définit éventuellement le temps d'attente maximum avant de renvoyer une erreur (la valeur par défaut est de 60 secondes). Si cette directive est omise, la requête ne sera pas mise en file d'attente.
7. Dépannage des erreurs
1.
Un serveur fonctionnant comme passerelle ou proxy a reçu une réponse non valide du serveur en amont lors de la tentative d'exécution d'une requête.
Raisons courantes : 1. Lorsque le service backend raccroche, directement 502 (journal des erreurs nginx : connect() a échoué (111 : connexion refusée))
2. Backend Le service redémarre
Exemple : désactivez le service backend, puis envoyez une requête à l'interface backend à nginx. Vous pouvez voir une erreur 502 dans le journal nginx.
De manière générale, Nginx 502 Bad Gateway est lié aux paramètres de php-fpm.conf, tandis que Nginx 504 Gateway Time-out est lié aux paramètres de nginx.conf
1), vérifiez le courant PHP FastCGI Si le nombre de processus est suffisant :
netstat -anpo | grep "php-cgi" | wc -l
Si le "nombre de processus FastCGI" réel utilisé est proche du par défaut "nombre de processus FastCGI", cela signifie que le "Nombre de processus FastCGI" n'est pas suffisant et doit être augmenté.
2). Le temps d'exécution de certains programmes PHP dépasse le temps d'attente de Nginx. Vous pouvez augmenter de manière appropriée le délai d'attente de FastCGI dans le fichier de configuration nginx.conf, tel que :
http. {
... fastcgi_connect_timeout 300;
fastcgi_send_timeout 300;
fastcgi_read_timeout 300;
...
}
2. 504 Gateway Timeout :
nginxLorsqu'un serveur fonctionnant comme passerelle ou proxy tente d'effectuer une requête, échec de réception d'un réponse rapide du serveur en amont (le serveur identifié par l'URI, tel que HTTP, FTP, LDAP). Raisons courantes :
Cette interface prend trop de temps. Le service backend reçoit la requête et démarre l'exécution, mais ne parvient pas à renvoyer les données à nginx dans le délai imparti La charge globale du backend. le serveur est trop élevé. Accepter Après avoir reçu la requête, en raison du thread occupé, l'interface de la requête n'a pas pu être organisée, ce qui a entraîné l'échec du retour des données à nginx à l'heure définie
2 413 Entité de requête trop grande
Solution : Augmenter client_max_body_sizeclient_max_body_size : la directive spécifie la taille maximale autorisée de l'entité de demande de connexion client, qui apparaît dans le champ Content-Length de l'en-tête de la demande. Si la demande est supérieure à la valeur spécifiée, le client recevra une « Entité de demande trop grande » ( 413) N'oubliez pas que le navigateur ne sait pas comment l'afficher.
Augmentez
post_max_size et upload_max_filesize dans php.ini3. Ngnix error.log apparaît : en-tête envoyé en amont trop gros lors de la lecture de l'en-tête de réponse de l'erreur en amont
1) Si c'est le cas Proxy inverse nginx le proxy est transmis par nginx en tant que client Lorsqu'il est utilisé, si l'en-tête est trop grand, dépassant la valeur par défaut de 1 Ko, l'en-tête ci-dessus envoyé en amont sera trop gros (pour le dire franchement, nginx envoie un en-tête externe requêtes au serveur back-end, et l'en-tête renvoyé par le serveur back-end est trop volumineux pour que nginx puisse le gérer. Il en résulte.
serveur {
écoute 80; nom_serveur *.xywy.com; 16k;
#Ajoutez ces 3 lignes
proxy_buffer_size 64k; proxy_buffers 32 32k;
proxy_busy_buffers_size 128k;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
fastcgi_buffer_size 128k;
fastcgi_buffers 4 128k;serveur {
écoute 80; nom_serveur ddd.com;
utiliser PHP à l'aide de la vulnérabilité PHP de Nginx Analyse de vulnérabilité : nginx prend en charge php exécuté en mode cgi par défaut. Par exemple, dans le fichier de configuration, vous pouvez utiliser est pris en charge Lors de l'analyse de php, l'emplacement utilisera la variable d'environnement URI pour sélectionner la requête. La variable clé SCRIPT_FILENAME transmise au backend Fastcgi est déterminée par le $fastcgi_script_name généré par nginx. Grâce à l'analyse, nous pouvons voir que $fastcgi_script_name est directement déterminé par. l'URI. Il est contrôlé par des variables d'environnement, et c'est là que le problème se pose. Afin de mieux supporter l'extraction de PATH_INFO, l'option cgi.fix_pathinfo existe dans les options de configuration PHP. Son but est d'extraire le vrai nom du script de SCRIPT_FILENAME. Après la commande location, la demande sera transmise au fastcgi back-end pour traitement, et nginx définira la variable d'environnement SCRIPT_FILENAME pour cela, avec le contenu de
client_header_buffer_size 128k;
large_client_header_buffers 4 128k;
proxy_buffer_size 64k;
proxy_buffers 8 64k;
fastcgi_buffer_size 128k; fastcgi_buffers 4 128k;
emplacement / {location ~ .php$ {<!-- --><h1 id="root-html-span-style-color-fastcgi-pass-strong-fastcgi-index-index-php-strong-fastcgi-param-SCRIPT-FILENAME-scripts-fastcgi-script-name-span-include-fastcgi-params"> root. html;<span style="color:#336699;"> fastcgi_pass 127.0.0.1:9000;<strong> fastcgi_index index.php;</strong> fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name;</span> include fastcgi_params;</h1> }
Donc, en supposant qu'il y ait http://www.80sec.com/80sec.jpg, nous accédons à location ~ .php$ {<!-- --><br> root html;<br> fastcgi_pass 127.0.0.1:9000;<br> fastcgi_index index.php;<br> fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name;<br> include fastcgi_params;<br> }http://www.80sec.com/80sec.jpg/80sec de la manière suivante.
obtiendra un URI/80sec.jpg/80sec.php Dans d'autres serveurs Web tels que lighttpd, nous avons constaté que SCRIPT_FILENAME est correctement défini sur
donc ce problème n'existe pas. /scripts/80sec.jpg/80sec.php Lorsque le backend fastcgi reçoit cette option, il décidera s'il doit effectuer un traitement supplémentaire sur SCRIPT_FILENAME en fonction de la configuration fix_pathinfo. Généralement, si fix_pathinfo n'est pas défini, cela affectera les applications qui utilisent PATH_INFO pour le routage, donc cette option est généralement. configuré pour être activé. Après avoir passé cette option, Php recherchera le vrai nom du fichier de script. La méthode de recherche consiste également à vérifier si le fichier existe. À ce moment, SCRIPT_FILENAME et PATH_INFO seront séparés comme /scripts/80sec.jpg. /scripts/80sec.jpg est utilisé comme script qui doit être exécuté pour cette requête, et l'attaquant peut laisser nginx utiliser PHP pour analyser tout type de fichier.
POC : Visitez un site sur lequel nginx prend en charge PHP et ajoutez /80sec.php après tout fichier de ressources tel que robots.txt. À ce stade, vous pouvez voir la différence suivante : /scripts/80sec.jpg和80sec.phpVisitez. http://www.80sec.com/robots.txtHTTP/1.1 200 OK<p> Serveur : nginx/0.6.32</p> Date : jeu. 20 mai 2010 10 :05 : 30 GMT<p> Type de contenu : texte/plain<br> Longueur du contenu : 18<br> Dernière modification : jeu. 20 mai 2010 06:26:34 GMT<code>HTTP/1.1 200 OK<br> Server: nginx/0.6.32<br> Date: Thu, 20 May 2010 10:05:30 GMT<br> Content-Type: text/plain<br> Content-Length: 18<br> Last-Modified: Thu, 20 May 2010 06:26:34 GMT<br> Connection: keep-alive<br> Keep-Alive: timeout=20<br> Accept-Ranges: bytes Connexion : keep-alive
Keep-Alive : timeout=20
Accept-Ranges : octets
Visitez http://www.80sec.com/robots.txt/80sec.php
HTTP/1.1 200 OK<br> Server: nginx/0.6.32<br> Date: Thu, 20 May 2010 10:06:49 GMT<br> Content-Type: text/html<br> Transfer-Encoding: chunked<br> Connection: keep-alive<br> Keep-Alive: timeout=20<br> X-Powered-By: PHP/5.2.6HTTP/1.1 200 OK
Serveur : nginx/0.6.32 Date : jeu. 20 mai 2010 10:06:49 GMT
Type de contenu : text/html
Transfert -Encodage : chunkedConnexion : keep-alive
Keep-Alive : timeout=20 X-Powered-By : PHP/5.2.6
Contenu - Le changement de type indique le changement dans la responsabilité du backend en matière d'analyse, et le site peut présenter des vulnérabilités. 关闭cgi.fix_pathinfo为0
Vendeur de vulnérabilité : http://www.nginx.org
Solution : if ( $fastcgi_script_name ~ ..*/.*php ) {<!-- --><br> return 403;<br> }Nous avons essayé de contacter le responsable, mais avant cela, vous pouvez réduire les pertes grâce aux éléments suivants méthodes
if ( $fastcgi_script_name ~ ..*/.*php ) {<!-- --> return 403;PS : Merci à laruence Daniel pour son aide lors du processus d'analyse Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Curl dans PHP: Comment utiliser l'extension PHP Curl dans les API REST
Mar 14, 2025 am 11:42 AM
Curl dans PHP: Comment utiliser l'extension PHP Curl dans les API REST
Mar 14, 2025 am 11:42 AM
L'extension PHP Client URL (CURL) est un outil puissant pour les développeurs, permettant une interaction transparente avec des serveurs distants et des API REST. En tirant parti de Libcurl, une bibliothèque de transfert de fichiers multi-protocol très respectée, PHP Curl facilite Efficient Execu
 Erreur de transfert SDK Alipay PHP: comment résoudre le problème de 'Impossible de déclarer la classe SignData'?
Apr 01, 2025 am 07:21 AM
Erreur de transfert SDK Alipay PHP: comment résoudre le problème de 'Impossible de déclarer la classe SignData'?
Apr 01, 2025 am 07:21 AM
Alipay Php ...
 Expliquez les jetons Web JSON (JWT) et leur cas d'utilisation dans les API PHP.
Apr 05, 2025 am 12:04 AM
Expliquez les jetons Web JSON (JWT) et leur cas d'utilisation dans les API PHP.
Apr 05, 2025 am 12:04 AM
JWT est une norme ouverte basée sur JSON, utilisée pour transmettre en toute sécurité des informations entre les parties, principalement pour l'authentification de l'identité et l'échange d'informations. 1. JWT se compose de trois parties: en-tête, charge utile et signature. 2. Le principe de travail de JWT comprend trois étapes: la génération de JWT, la vérification de la charge utile JWT et l'analyse. 3. Lorsque vous utilisez JWT pour l'authentification en PHP, JWT peut être généré et vérifié, et les informations sur le rôle et l'autorisation des utilisateurs peuvent être incluses dans l'utilisation avancée. 4. Les erreurs courantes incluent une défaillance de vérification de signature, l'expiration des jetons et la charge utile surdimensionnée. Les compétences de débogage incluent l'utilisation des outils de débogage et de l'exploitation forestière. 5. L'optimisation des performances et les meilleures pratiques incluent l'utilisation des algorithmes de signature appropriés, la définition des périodes de validité raisonnablement,
 Expliquez le concept de liaison statique tardive en PHP.
Mar 21, 2025 pm 01:33 PM
Expliquez le concept de liaison statique tardive en PHP.
Mar 21, 2025 pm 01:33 PM
L'article traite de la liaison statique tardive (LSB) dans PHP, introduite dans PHP 5.3, permettant une résolution d'exécution de la méthode statique nécessite un héritage plus flexible. Problème main: LSB vs polymorphisme traditionnel; Applications pratiques de LSB et perfo potentiel
 Caractéristiques de sécurité du cadre: protection contre les vulnérabilités.
Mar 28, 2025 pm 05:11 PM
Caractéristiques de sécurité du cadre: protection contre les vulnérabilités.
Mar 28, 2025 pm 05:11 PM
L'article traite des fonctionnalités de sécurité essentielles dans les cadres pour se protéger contre les vulnérabilités, notamment la validation des entrées, l'authentification et les mises à jour régulières.
 Comment envoyer une demande post contenant des données JSON à l'aide de la bibliothèque Curl de PHP?
Apr 01, 2025 pm 03:12 PM
Comment envoyer une demande post contenant des données JSON à l'aide de la bibliothèque Curl de PHP?
Apr 01, 2025 pm 03:12 PM
Envoyant des données JSON à l'aide de la bibliothèque Curl de PHP dans le développement de PHP, il est souvent nécessaire d'interagir avec les API externes. L'une des façons courantes consiste à utiliser la bibliothèque Curl pour envoyer le post� ...
 Frameworks de personnalisation / d'extension: comment ajouter des fonctionnalités personnalisées.
Mar 28, 2025 pm 05:12 PM
Frameworks de personnalisation / d'extension: comment ajouter des fonctionnalités personnalisées.
Mar 28, 2025 pm 05:12 PM
L'article examine l'ajout de fonctionnalités personnalisées aux cadres, en se concentrant sur la compréhension de l'architecture, l'identification des points d'extension et les meilleures pratiques pour l'intégration et le débogage.
 Quelle est exactement la caractéristique non bloquante de ReactPHP? Comment gérer ses opérations d'E / S de blocage?
Apr 01, 2025 pm 03:09 PM
Quelle est exactement la caractéristique non bloquante de ReactPHP? Comment gérer ses opérations d'E / S de blocage?
Apr 01, 2025 pm 03:09 PM
Une introduction officielle à la caractéristique non bloquante de l'interprétation approfondie de ReactPHP de la caractéristique non bloquante de ReactphP a suscité de nombreux développeurs: "ReactPhpisnon-blockingByDefault ...
