
 base de données
tutoriel mysql
Utilisez des exemples pour vous expliquer comment optimiser SQL
base de données
tutoriel mysql
Utilisez des exemples pour vous expliquer comment optimiser SQL
Utilisez des exemples pour vous expliquer comment optimiser SQL

Bien que les coûts du matériel aient baissé de nos jours, l'amélioration des performances du système en mettant à niveau le matériel est également une méthode d'optimisation courante. Les systèmes ayant des exigences élevées en temps réel doivent encore être optimisés du point de vue SQL. Aujourd'hui, nous allons présenter comment optimiser SQL à l'aide d'exemples.
Juge problème SQL
Vous pouvez juger s'il y a un problème avec SQL à travers deux symptômes :
-
Symptômes au niveau du système
La consommation du CPU est sérieuse
L'attente IO est sérieuse
La page le temps de réponse est trop long Si le journal d'une longue
application présente un délai d'attente et d'autres erreurs
, vous pouvez utiliser la commande sar et la commande top pour afficher l'état actuel du système. Vous pouvez également observer l'état du système grâce à des outils de surveillance tels que Prometheus et Grafana.
-
Représentation des instructions SQL
Long
Le temps d'exécution est trop long
Obtenir les données de l'analyse complète de la table
-
Les lignes et les coûts dans le plan d'exécution sont très grand
Le SQL long est facile à comprendre. Si un SQL est trop long, la lisibilité sera mauvaise et la fréquence des problèmes sera certainement plus élevée. Pour mieux juger du problème SQL, nous devons commencer par le plan d'exécution, comme indiqué ci-dessous :

Le plan d'exécution nous indique que cette requête utilise une analyse de table complète Type=ALL et que les lignes sont très grandes (9950400 ). Nous pouvons essentiellement juger qu'il s'agit d'un paragraphe. Il y a une saveur dans SQL.
Obtenir le problème SQL
Différentes bases de données ont différentes méthodes pour l'obtenir. Ce qui suit est l'outil d'acquisition SQL de requêtes lentes pour les bases de données grand public actuelles
-
MySQL
Journal des requêtes lentes
-
Outil de test Loadrunner
. Percona ptquery et autres outils de l'entreprise
-
Oracle
Rapport AWR
outil de test Loadrunner etc.
-
Vues internes associées telles que v$, _attendre, etc.
Outil de surveillance GRID CONTROL
-
Base de données Dameng
Rapport AWR
Outil de test LoadRunner, etc.
Vues internes associées telles que comme v$, $session_wait, etc.Compétences en écriture SQL
Il existe plusieurs compétences générales en écriture SQL :
• Utiliser les index de manière rationnelle
• Utilisez UNION ALL au lieu de UNIONUNION ALL a une efficacité d'exécution supérieure à UNION, et UNION doit être dédupliqué lors de l'exécution. UNION doit trier les données
• Évitez d'écrire * select
Lors de l'exécution de SQL, l'optimiseur doit convertir * en colonnes spécifiques ; chaque requête doit revenir à la table et les index de couverture ne peuvent pas être utilisés.
• Il est recommandé de créer un index pour les champs JOIN
Généralement, les champs JOIN sont indexés à l'avance
• Évitez les instructions SQL complexes
Améliorez la lisibilité ; évitez la probabilité que des requêtes lentes puissent être converties en ; plusieurs requêtes courtes, utilisez le traitement final de l'entreprise
• Évitez l'écriture où 1 = 1
• Évitez l'écriture similaire order by rand()RAND() provoquant l'analyse de la colonne de données plusieurs fois
Optimisation SQL
plan d'exécutionterminé Lors de l'optimisation de SQL, vous devez d'abord lire le plan d'exécution. Le plan d'exécution vous indiquera où l'efficacité est faible et où une optimisation est nécessaire. Prenons MYSQL comme exemple pour voir quel est le plan d'exécution. (Le plan d'exécution de chaque base de données est différent, vous devez le comprendre par vous-même)
| Champ | Explication |
|---|---|
| id | Chaque identification d'opération exécutée indépendamment identifie l'ordre dans lequel l'objet est utilisé. Plus la valeur de l'identifiant est grande, la première à être exécutée si elles sont identiques. l'ordre d'exécution est de haut en bas Ci-dessous |
| select_type | Le type de chaque clause select dans la requête |
| table | Le nom de l'objet sur lequel l'opération est effectuée, généralement le nom de la table, mais il en existe d'autres formats |
| partitions | Les informations de partition correspondantes (pour les tables non partitionnées, la valeur est NULL) |
| type | Type d'opération de jointure |
| possible_keys | index possibles |
| clé | L'index réellement utilisé par l'optimiseur (la colonne la plus importante) Les types de jointure du meilleur au pire sont const, eq_reg, ref, range, index et ALL. Quand ALL apparaît, cela signifie que le SQL actuel a une "mauvaise odeur" |
| key_len | La longueur de la clé d'index sélectionnée par l'optimiseur, l'unité est en octets |
| ref | Indique l'objet de référence de l'objet opéré dans cette ligne, l'objet non-référence est NULL |
| rows | Le nombre de tuples analysés par l'exécution de la requête (pour innodb, cette valeur est une estimation) |
| filtered | Le nombre de tuples dans la table conditionnelle où sont filtrées les données Pourcentage |
| extra | Information supplémentaire importante du plan d'exécution, soyez prudent lorsque les mots Using filesort, Using Temporary apparaissent dans cette colonne, il est très probable que l'instruction SQL doive être optimisé |
Ensuite, nous utilisons un cas d'optimisation pratique pour expliquer le processus d'optimisation SQL et les techniques d'optimisation.
Cas d'optimisation
Structure des tables
CREATE TABLE `a`
(
`id` int(11) NOT NULLAUTO_INCREMENT,
`seller_id` bigint(20) DEFAULT NULL,
`seller_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL,
`gmt_create` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
);
CREATE TABLE `b`
(
`id` int(11) NOT NULLAUTO_INCREMENT,
`seller_name` varchar(100) DEFAULT NULL,
`user_id` varchar(50) DEFAULT NULL,
`user_name` varchar(100) DEFAULT NULL,
`sales` bigint(20) DEFAULT NULL,
`gmt_create` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
);
CREATE TABLE `c`
(
`id` int(11) NOT NULLAUTO_INCREMENT,
`user_id` varchar(50) DEFAULT NULL,
`order_id` varchar(100) DEFAULT NULL,
`state` bigint(20) DEFAULT NULL,
`gmt_create` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
);Trois tables sont liées pour interroger l'état de la commande de l'utilisateur actuel 10 heures avant et après l'heure actuelle, et les trier par ordre croissant en fonction de l'heure de création de la commande. Le SQL spécifique est le suivant.
select a.seller_id,
a.seller_name,
b.user_name,
c.state
from a,
b,
c
where a.seller_name = b.seller_name
and b.user_id = c.user_id
and c.user_id = 17
and a.gmt_create
BETWEEN DATE_ADD(NOW(), INTERVAL – 600 MINUTE)
AND DATE_ADD(NOW(), INTERVAL 600 MINUTE)
order by a.gmt_create;Afficher le volume de données

Temps d'exécution d'origine

Plan d'exécution d'origine
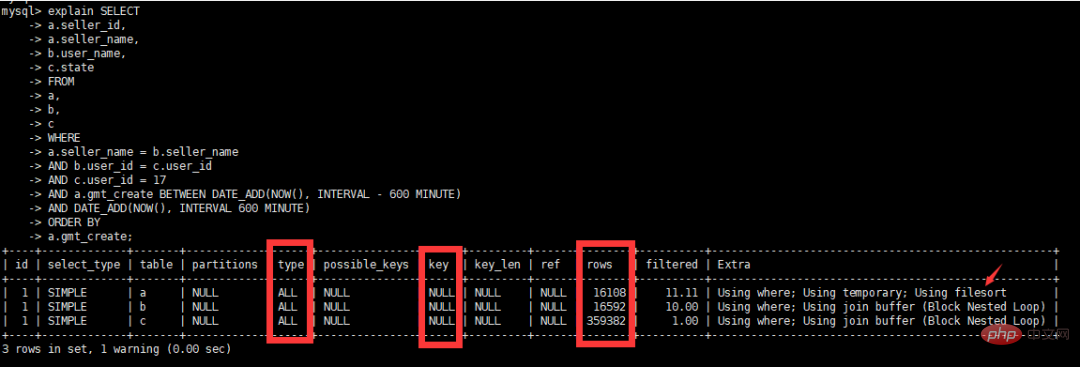
Idées d'optimisation initiales
Le type du champ de condition Where dans SQL doit être cohérent avec le structure de la table. L'ID utilisateur dans la table est de type varchar(50). SQL réel Le type int utilisé a une conversion implicite et aucun index n'est ajouté. Modifiez le champ user_id dans les tableaux b et c en type int.
Parce qu'il y a une association entre la table b et la table c, créez un index sur le user_id de la table b et de la table c
Parce qu'il y a une association entre la table a et la table b, créez un index sur le seller_name champ de la table a et b
Utiliser un index composite Supprimer les tables temporaires et le tri
Optimisation préliminaire de SQL
alter table b modify `user_id` int(10) DEFAULT NULL; alter table c modify `user_id` int(10) DEFAULT NULL; alter table c add index `idx_user_id`(`user_id`); alter table b add index `idx_user_id_sell_name`(`user_id`,`seller_name`); alter table a add index `idx_sellname_gmt_sellid`(`gmt_create`,`seller_name`,`seller_id`);
Visualiser le temps d'exécution après optimisation

Voir le plan d'exécution après optimisation
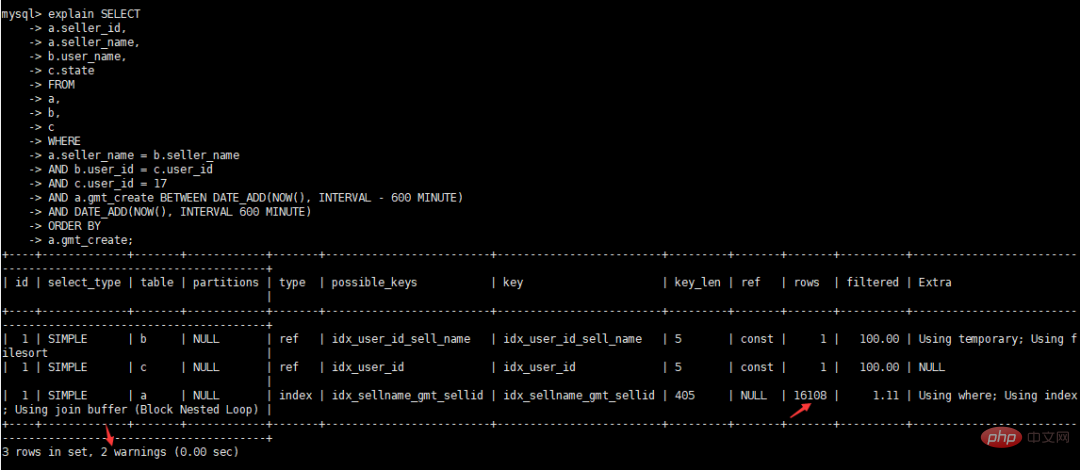
Afficher les informations sur les avertissements
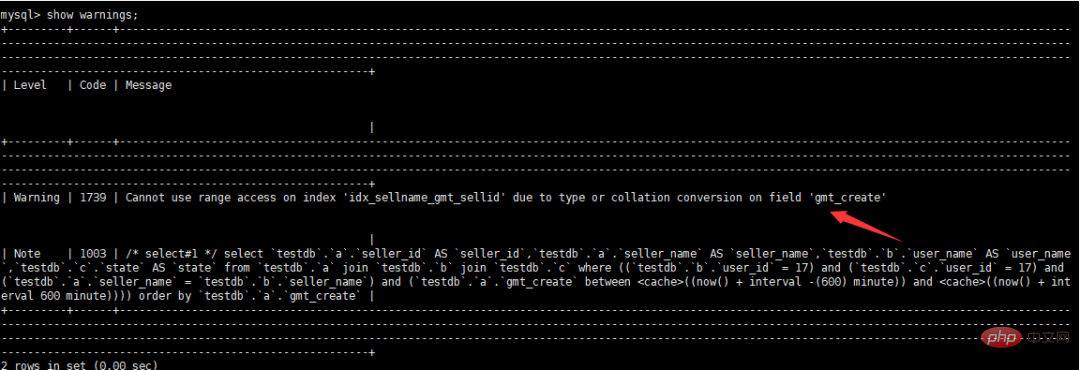
Continuer à optimiser, modifier la table et modifier "gmt_create" datetime DEFAULT NULL;
Résumé

S'il y a un message d'alarme, vérifiez les informations d'alarme qui affichent des avertissements ;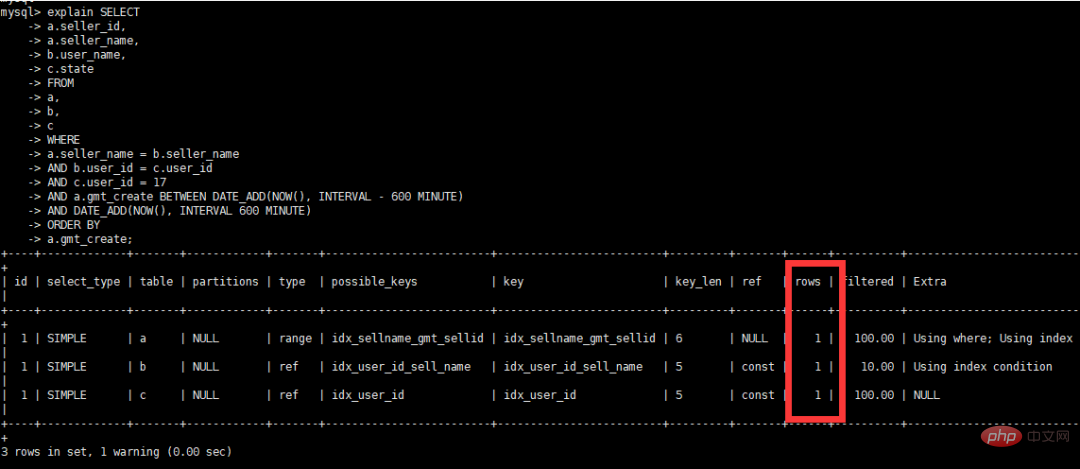
Affichez la structure de la table et les informations d'index impliquées dans SQL
Réfléchissez aux points d'optimisation possibles en fonction le plan d'exécution
Effectuer des modifications de structure de table, ajouter des index, réécrire SQL, etc. en fonction des points d'optimisation possibles. Opération
Afficher le temps d'exécution optimisé et le plan d'exécution
Si l'effet d'optimisation n'est pas évident, répétez la quatrième étape
-
Recommandations associées : "
tutoriel mysql "
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment optimiser les performances du forum Discuz ?
Mar 12, 2024 pm 06:48 PM
Comment optimiser les performances du forum Discuz ?
Mar 12, 2024 pm 06:48 PM
Comment optimiser les performances du forum Discuz ? Introduction : Discuz est un système de forum couramment utilisé, mais il peut rencontrer des goulots d'étranglement en termes de performances lors de son utilisation. Afin d'améliorer les performances de Discuz Forum, nous pouvons l'optimiser sous de nombreux aspects, notamment l'optimisation de la base de données, les paramètres de cache, l'ajustement du code, etc. Ce qui suit présentera comment optimiser les performances du forum Discuz à travers des opérations spécifiques et des exemples de code. 1. Optimisation de la base de données : Optimisation des index : la création d'index pour les champs de requête fréquemment utilisés peut considérablement améliorer la vitesse des requêtes. Par exemple
 Comment optimiser les performances de SQL Server et MySQL afin qu'ils puissent fonctionner au mieux ?
Sep 11, 2023 pm 01:40 PM
Comment optimiser les performances de SQL Server et MySQL afin qu'ils puissent fonctionner au mieux ?
Sep 11, 2023 pm 01:40 PM
Comment optimiser les performances de SQLServer et MySQL afin qu'ils puissent fonctionner au mieux ? Résumé : Dans les applications de bases de données actuelles, SQLServer et MySQL sont les deux systèmes de gestion de bases de données relationnelles (SGBDR) les plus courants et les plus populaires. À mesure que la quantité de données augmente et que les besoins des entreprises continuent d’évoluer, l’optimisation des performances des bases de données devient particulièrement importante. Cet article présentera quelques méthodes et techniques courantes pour optimiser les performances de SQLServer et MySQL afin d'aider les utilisateurs à tirer parti de
 Réglage des performances Linux ~
Feb 12, 2024 pm 03:30 PM
Réglage des performances Linux ~
Feb 12, 2024 pm 03:30 PM
Le système d'exploitation Linux est un produit open source, et c'est également une plate-forme de pratique et d'application pour les logiciels open source. Sous cette plateforme, il existe d'innombrables supports de logiciels open source, tels qu'apache, tomcat, mysql, php, etc. Le concept le plus important des logiciels open source est la liberté et l’ouverture. Par conséquent, en tant que plate-forme open source, l'objectif de Linux est d'obtenir des performances applicatives optimales au moindre coût grâce à la prise en charge de ces logiciels open source. En ce qui concerne les problèmes de performances, ce qui est principalement obtenu est la meilleure combinaison du système d'exploitation Linux et des applications. 1. Présentation des problèmes de performances Les performances du système font référence à l'efficacité, à la stabilité et à la vitesse de réponse du système d'exploitation dans l'exécution des tâches. Les administrateurs système Linux peuvent souvent rencontrer des problèmes tels qu'une instabilité du système et une vitesse de réponse lente, tels que
 Différences fondamentales entre les systèmes de gestion de bases de données Sybase et Oracle
Mar 08, 2024 pm 05:54 PM
Différences fondamentales entre les systèmes de gestion de bases de données Sybase et Oracle
Mar 08, 2024 pm 05:54 PM
Les principales différences entre les systèmes de gestion de bases de données Sybase et Oracle nécessitent des exemples de code spécifiques. Les systèmes de gestion de bases de données jouent un rôle essentiel dans le domaine des technologies de l'information modernes, car deux systèmes de gestion de bases de données relationnelles bien connus occupent une place importante dans le domaine. champ de base de données. Bien qu’il s’agisse tous deux de systèmes de gestion de bases de données relationnelles, il existe certaines différences fondamentales dans les applications pratiques. Cet article comparera Sybase et Oracle sous plusieurs angles, notamment l'architecture, la syntaxe, les performances, etc.
 Que signifie tout en SQL
May 01, 2024 pm 11:03 PM
Que signifie tout en SQL
May 01, 2024 pm 11:03 PM
Le mot-clé ANY en SQL est utilisé pour vérifier si une sous-requête renvoie des lignes qui satisfont une condition donnée : Syntaxe : ANY (sous-requête) Utilisation : utilisée avec les opérateurs de comparaison, si la sous-requête renvoie des lignes qui satisfont à la condition, l'expression ANY est évaluée à vrai Avantages : simplifie les requêtes, améliore l'efficacité et convient au traitement de grandes quantités de données. Limitations : ne fournit pas de lignes spécifiques qui remplissent la condition. Si la sous-requête renvoie plusieurs lignes qui remplissent la condition, seul vrai est renvoyé.
 Optimisation des performances de SQL Server et MySQL : bonnes pratiques et conseils clés.
Sep 11, 2023 pm 12:46 PM
Optimisation des performances de SQL Server et MySQL : bonnes pratiques et conseils clés.
Sep 11, 2023 pm 12:46 PM
Réglage des performances SQLServer et MySQL : meilleures pratiques et conseils clés Résumé : Cet article présentera les méthodes de réglage des performances de deux systèmes de bases de données relationnelles courants, SQLServer et MySQL, et fournira quelques bonnes pratiques et conseils clés pour aider les développeurs et les administrateurs de bases de données à améliorer les performances et efficacité des systèmes de bases de données. Introduction : Dans le développement d'applications modernes, les systèmes de bases de données sont un élément indispensable. À mesure que la quantité de données augmente et que les demandes des utilisateurs augmentent, l’optimisation des performances des bases de données devient particulièrement importante. SQ
 Plan d'exécution des instructions MySQL SQL : comment optimiser le processus de requête MySQL
Jun 16, 2023 am 09:15 AM
Plan d'exécution des instructions MySQL SQL : comment optimiser le processus de requête MySQL
Jun 16, 2023 am 09:15 AM
Avec le développement rapide d’Internet, le stockage et le traitement des données deviennent de plus en plus importants. Par conséquent, les bases de données relationnelles font partie intégrante des plateformes logicielles modernes. La base de données MySQL est devenue l'une des bases de données relationnelles les plus populaires car elle est simple à utiliser, facile à déployer et à gérer. Cependant, les problèmes de performances des bases de données MySQL deviennent souvent un problème lorsqu'il s'agit de traiter de grandes quantités de données. Dans cet article, nous examinerons le plan d'exécution des instructions SQL de MySQL et présenterons comment améliorer les données MySQL en optimisant le processus de requête.
 Comment réaliser une optimisation de bas niveau de MySQL : conseils et bonnes pratiques pour une optimisation avancée des instructions SQL
Nov 08, 2023 pm 04:32 PM
Comment réaliser une optimisation de bas niveau de MySQL : conseils et bonnes pratiques pour une optimisation avancée des instructions SQL
Nov 08, 2023 pm 04:32 PM
MySQL est un système de gestion de bases de données relationnelles largement utilisé pour le développement d'applications Web et le stockage de données. Dans les applications pratiques, l'optimisation sous-jacente de MySQL est particulièrement importante, parmi laquelle l'optimisation avancée des instructions SQL est la clé pour améliorer les performances de la base de données. Cet article présentera quelques conseils et bonnes pratiques pour implémenter l'optimisation sous-jacente de MySQL, ainsi que des exemples de code spécifiques. Déterminer les conditions de requête Lors de l'écriture d'instructions SQL, vous devez d'abord définir clairement les conditions de requête et éviter d'utiliser des requêtes génériques illimitées, c'est-à-dire éviter d'utiliser « % » pour ouvrir la requête.
