

Quelles sont les méthodes de pagination dans SQL Server ?

Cet article parle de la méthode de pagination de SQL Server, en utilisant la version SQL Server 2012. Dans ce qui suit, pageIndex est utilisé pour représenter le nombre de pages et pageSize représente les enregistrements contenus sur une page. Et ce qui suit implique des exemples spécifiques, définissez la page de requête 2, chaque page contient 10 enregistrements.
Tout d'abord, parlons de la différence entre la pagination du serveur SQL et la pagination de MySQL. La pagination de MySQL peut être complétée directement en utilisant limit (pageIndex-1) et pageSize. Cependant, le serveur SQL n'a pas le mot-clé limit, seulement le top. mot-clé similaire à limit . La pagination est donc plus gênante.
Je ne connais que quatre types de pagination de serveur SQL : triple boucle ; utilisation de max (clé primaire) ; utilisation du mot-clé row_number, offset/fetch next (résumé en collectant les méthodes d'autres personnes sur Internet, cela devrait être le seul on actuellement les idées de ces quatre méthodes, d'autres méthodes sont basées sur cette déformation).
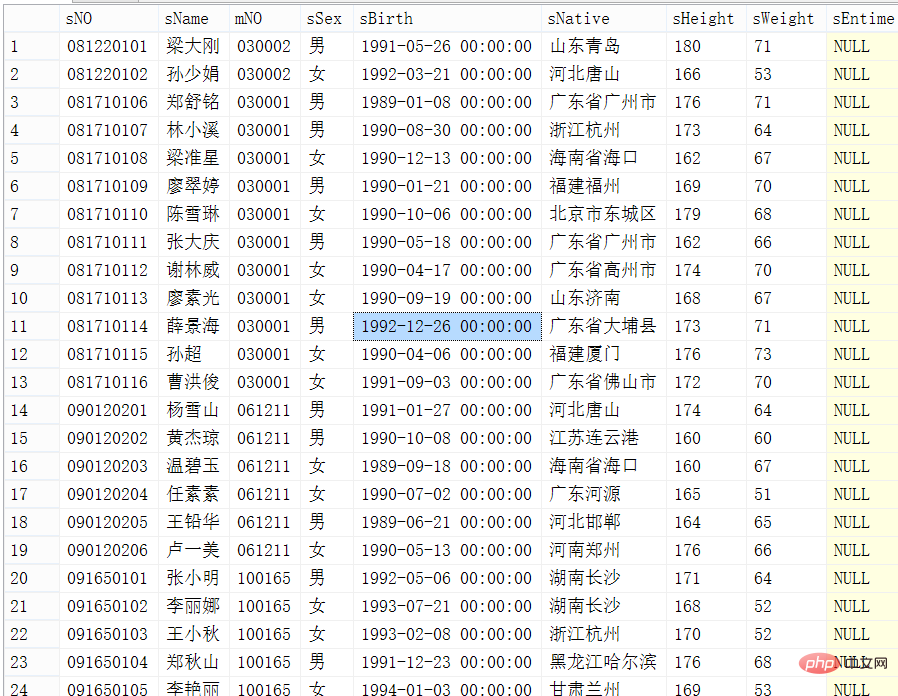
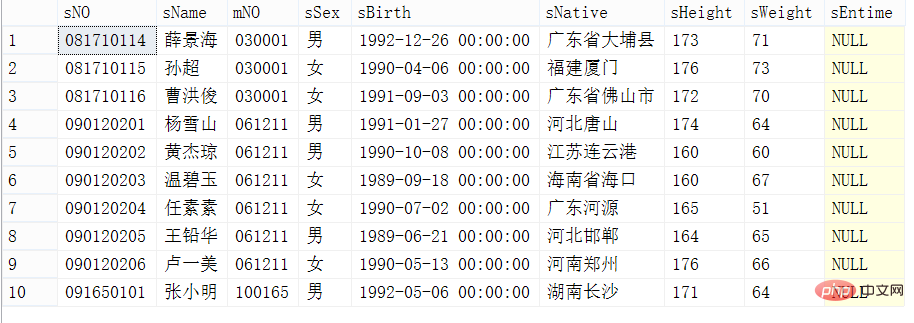
Partie des enregistrements de la table des étudiants à interroger
Méthode 1 : Triple boucle
Idée
Prenez d'abord les 20 premières pages, puis l'ordre inverse, et prenez les 10 premiers enregistrements dans l'ordre inverse, donc que vous pouvez obtenir les données nécessaires à la pagination, mais que l'ordre est inversé. Vous pouvez ensuite inverser l'ordre, ou vous pouvez arrêter le tri et le remettre directement au front-end pour le tri.
Il existe une autre méthode qui peut être considérée comme étant de ce type. Je ne mettrai pas le code ici, je parlerai juste de l'idée, qui est d'abord d'interroger les 10 premiers enregistrements, puis d'utiliser not in pour exclure ces 10. enregistrements, puis interrogez à nouveau.
Implémentation du code
-- 设置执行时间开始,用来查看性能的 set statistics time on ; -- 分页查询(通用型) select * from (select top pageSize * from (select top (pageIndex*pageSize) * from student order by sNo asc ) -- 其中里面这层,必须指定按照升序排序,省略的话,查询出的结果是错误的。 as temp_sum_student order by sNo desc ) temp_order order by sNo asc -- 分页查询第2页,每页有10条记录 select * from (select top 10 * from (select top 20 * from student order by sNo asc ) -- 其中里面这层,必须指定按照升序排序,省略的话,查询出的结果是错误的。 as temp_sum_student order by sNo desc ) temp_order order by sNo asc ;
Résultats et heure de la requête
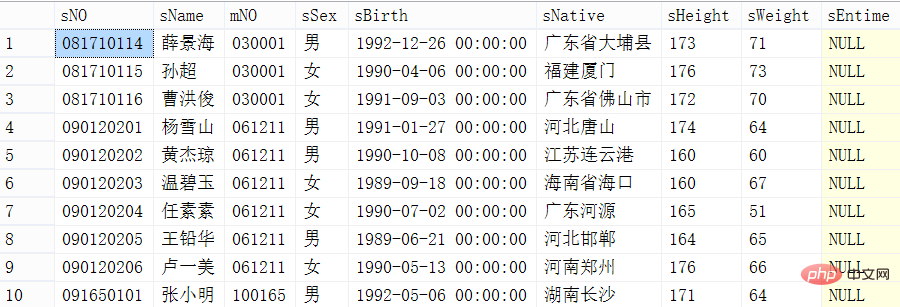

Méthode 2 : utilisez max (clé primaire)
Commencez par terminer les 11 premières lignes d'enregistrements, puis utilisez max (id) pour obtenir le plus grand id. Après cela, réinterrogez les 10 premiers éléments de ce tableau, mais ajoutez la condition, où id>max(id).
Implémentation du code
set statistics time on; -- 分页查询(通用型) select top pageSize * from student where sNo>= (select max(sNo) from (select top ((pageIndex-1)*pageSize+1) sNo from student order by sNo asc) temp_max_ids) order by sNo; -- 分页查询第2页,每页有10条记录 select top 10 * from student where sNo>= (select max(sNo) from (select top 11 sNo from student order by sNo asc) temp_max_ids) order by sNo;
Résultats et heure de la requête
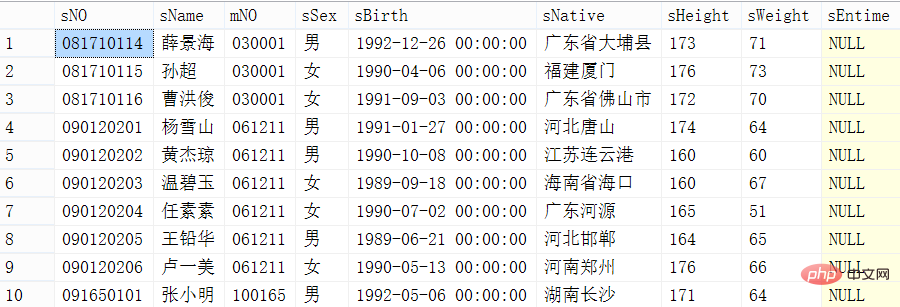

Méthode 3 : utilisez le mot-clé row_number
Utilisez directement la fonction row_number() over(order by id) pour calculer le nombre de lignes et sélectionnez le ligne correspondante Renvoyez simplement le numéro, mais ce mot-clé n'est disponible que dans SQL Server 2005 et versions ultérieures.
Implémentation SQL
set statistics time on; -- 分页查询(通用型) select top pageSize * from (select row_number() over(order by sno asc) as rownumber,* from student) temp_row where rownumber>((pageIndex-1)*pageSize); set statistics time on; -- 分页查询第2页,每页有10条记录 select top 10 * from (select row_number() over(order by sno asc) as rownumber,* from student) temp_row where rownumber>10;
Résultats et heure de la requête
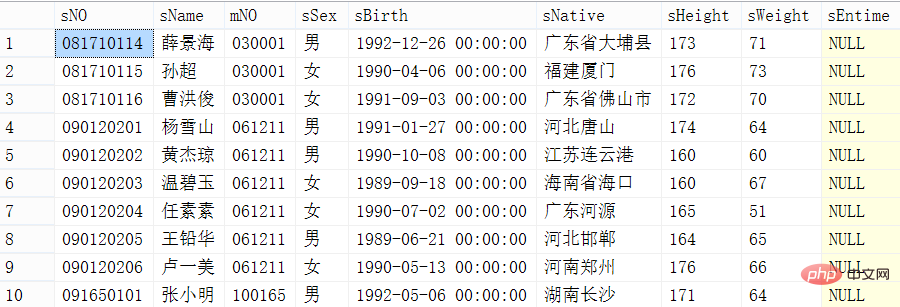

Quatrième méthode : offset /fetch next (disponible uniquement dans la version 2012 et supérieure)
Implémentation du code
set statistics time on; -- 分页查询(通用型) select * from student order by sno offset ((@pageIndex-1)*@pageSize) rows fetch next @pageSize rows only; -- 分页查询第2页,每页有10条记录 select * from student order by sno offset 10 rows fetch next 10 rows only ;
offset A rows, Le premier enregistrement A est ignoré, récupère uniquement les lignes B suivantes et les données B sont lues à rebours.
Résultats et durée d'exécution
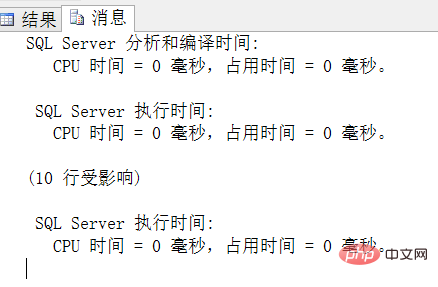
Procédure stockée encapsulée
Enfin, j'ai encapsulé une procédure stockée de pagination pour la commodité de tout le monde, afin que lorsque vient le temps d'écrire la pagination, vous puissiez appeler directement cette procédure stockée .
Procédure stockée de pagination
create procedure paging_procedure ( @pageIndex int, -- 第几页 @pageSize int -- 每页包含的记录数 ) as begin select top (select @pageSize) * -- 这里注意一下,不能直接把变量放在这里,要用select from (select row_number() over(order by sno) as rownumber,* from student) temp_row where rownumber>(@pageIndex-1)*@pageSize; end -- 到时候直接调用就可以了,执行如下的语句进行调用分页的存储过程 exec paging_procedure @pageIndex=2,@pageSize=10;
Résumé
Sur la base du temps d'exécution des quatre méthodes de pagination ci-dessus, nous pouvons savoir que parmi les quatre méthodes de pagination ci-dessus, les performances des deuxième, troisième et troisième méthodes sont presque les mêmes, mais les performances des troisième et quatrième méthodes de pagination sont similaires. L'une d'elles a des performances médiocres et n'est pas recommandée. De plus, ce blog teste une petite quantité de données et n'a pas encore paginé une grande quantité de données, il n'est donc pas clair quelle méthode a les meilleures performances lorsqu'une grande quantité de données doit être paginée. Je recommande la quatrième méthode ici. Après tout, la quatrième méthode est une nouvelle méthode introduite après la mise à niveau de la société SQL Server, elle devrait donc théoriquement avoir de meilleures performances et une meilleure lisibilité.
Recommandations associées : "Tutoriel mysql"
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quels sont les différents types de partitionnement des données dans SQL (horizontal, vertical)?
Mar 13, 2025 pm 02:01 PM
Quels sont les différents types de partitionnement des données dans SQL (horizontal, vertical)?
Mar 13, 2025 pm 02:01 PM
L'article traite du partitionnement des données horizontal et vertical dans SQL, en se concentrant sur leur impact sur les performances et l'évolutivité. Il compare les avantages et les considérations pour choisir entre eux.
 Comment utiliser les fonctions agrégées dans SQL pour résumer les données (SUM, AVG, COUNT, MIN, MAX)?
Mar 13, 2025 pm 01:50 PM
Comment utiliser les fonctions agrégées dans SQL pour résumer les données (SUM, AVG, COUNT, MIN, MAX)?
Mar 13, 2025 pm 01:50 PM
L'article explique comment utiliser les fonctions d'agrégats SQL (SUM, AVG, COUNT, MIN, MAX) pour résumer les données, détaillant leurs utilisations et leurs différences, et comment les combiner dans les requêtes. COMPAT DE CHARACTER: 159
 Quels sont les risques de sécurité d'utiliser Dynamic SQL et comment puis-je les atténuer?
Mar 13, 2025 pm 01:59 PM
Quels sont les risques de sécurité d'utiliser Dynamic SQL et comment puis-je les atténuer?
Mar 13, 2025 pm 01:59 PM
L'article traite des risques de sécurité de Dynamic SQL, en se concentrant sur l'injection SQL, et fournit des stratégies d'atténuation telles que l'utilisation de requêtes paramétrées et de validation d'entrée.
 Quels sont les différents niveaux d'isolement des transactions dans SQL (lire non engagée, lire engagée, lecture reproductible, sérialisable)?
Mar 13, 2025 pm 01:56 PM
Quels sont les différents niveaux d'isolement des transactions dans SQL (lire non engagée, lire engagée, lecture reproductible, sérialisable)?
Mar 13, 2025 pm 01:56 PM
L'article traite des niveaux d'isolement des transactions SQL: lire non engagée, lire engagée, lecture reproductible et sérialisable. Il examine leur impact sur la cohérence et les performances des données, notant qu'une isolation plus élevée garantit une plus grande cohérence mais MA
 Quelles sont les propriétés acides des transactions dans SQL?
Mar 13, 2025 pm 01:54 PM
Quelles sont les propriétés acides des transactions dans SQL?
Mar 13, 2025 pm 01:54 PM
L'article traite des propriétés acides (atomicité, cohérence, isolement, durabilité) dans les transactions SQL, cruciale pour maintenir l'intégrité et la fiabilité des données.
 Comment puis-je me conformer aux réglementations de confidentialité des données (RGPD, CCPA) à l'aide de SQL?
Mar 18, 2025 am 11:22 AM
Comment puis-je me conformer aux réglementations de confidentialité des données (RGPD, CCPA) à l'aide de SQL?
Mar 18, 2025 am 11:22 AM
L'article discute de l'utilisation de SQL pour le RGPD et la conformité CCPA, en se concentrant sur l'anonymisation des données, les demandes d'accès et la suppression automatique des données obsolètes (159 caractères)
 Comment sécuriser ma base de données SQL contre les vulnérabilités communes comme l'injection SQL?
Mar 18, 2025 am 11:18 AM
Comment sécuriser ma base de données SQL contre les vulnérabilités communes comme l'injection SQL?
Mar 18, 2025 am 11:18 AM
L'article traite de la sécurisation des bases de données SQL par rapport aux vulnérabilités comme l'injection SQL, mettant l'accent sur les déclarations préparées, la validation des entrées et les mises à jour régulières.
 Comment implémenter le partitionnement des données dans SQL pour les performances et l'évolutivité?
Mar 18, 2025 am 11:14 AM
Comment implémenter le partitionnement des données dans SQL pour les performances et l'évolutivité?
Mar 18, 2025 am 11:14 AM
L'article discute de la mise en œuvre du partitionnement des données dans SQL pour de meilleures performances et de meilleures évolutives, des méthodes de détail, des meilleures pratiques et des outils de surveillance.
