
 base de données
tutoriel mysql
En savoir plus sur l'incrémentation automatique des clés primaires dans MySQL
base de données
tutoriel mysql
En savoir plus sur l'incrémentation automatique des clés primaires dans MySQL
En savoir plus sur l'incrémentation automatique des clés primaires dans MySQL

Cet article vous amènera à comprendre la clé primaire à incrémentation automatique dans MySQL, à présenter le mécanisme de modification de la valeur à incrémentation automatique, le timing de modification de la valeur à incrémentation automatique, la méthode d'optimisation du verrouillage à incrémentation automatique, etc. Les amis dans le besoin peuvent en apprendre davantage ~

1. Où est stockée la valeur auto-augmentée ?
Différents moteurs ont des stratégies différentes pour enregistrer les valeurs auto-incrémentées
1 La valeur auto-incrémentée du moteur MyISAM est enregistrée dans le fichier de données
2 La valeur auto-incrémentée du moteur InnoDB, dans MySQL5. .7 et versions antérieures, la valeur auto-incrémentée est enregistrée en mémoire, il n'y a pas de persistance. Après chaque redémarrage, lorsque vous ouvrez la table pour la première fois, vous trouverez la valeur maximale d'auto-incrémentation max(id), puis utiliserez max(id) + step size comme valeur d'auto-incrémentation actuelle de la table
select max(ai_col) from table_name for update;
Dans MySQL version 8.0, enregistrez les modifications de la valeur d'auto-incrémentation dans le journal de rétablissement et comptez sur le journal de rétablissement pour restaurer la valeur avant le redémarrage lors du redémarrage
2. Mécanisme de modification de la valeur d'auto-incrémentation
Si le champ id est défini comme AUTO_INCREMENT, lors de l'insertion d'une ligne de données, le comportement de l'auto-incrémentation est le suivant :
1 Si le champ id est spécifié comme 0, valeur nulle ou non spécifiée lors de l'insertion de données, remplissez le champ. valeur AUTO_INCREMENT actuelle de cette table dans le champ d'incrémentation automatique
2. Si lors de l'insertion de données, id Si le champ spécifie une valeur spécifique, utilisez simplement la valeur spécifiée dans l'instruction. Supposons que la valeur à insérer est X, et. la valeur actuelle d'incrémentation automatique est Y. 1. Si Change
2. Si long, continuez à superposer jusqu'à la première valeur supérieure à Les instructions de création d'index et de table sont les suivantes :
CREATE TABLE `t` ( `id` int(11) NOT NULL AUTO_INCREMENT, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `c` (`c`)) ENGINE=InnoDB;
Supposons qu'il existe déjà un enregistrement ( 1,1,1) dans le tableau t. Exécutez ensuite une commande d'insertion de données :
insert into t values(null, 1, 1);
Le processus d'exécution est le suivant :
1 Exécuter Le processeur appelle l'interface du moteur InnoDB pour écrire une ligne. in est (0,1,1)2. InnoDB trouve une valeur qui ne spécifie pas d'identifiant d'auto-incrémentation et obtient la valeur actuelle d'auto-incrémentation 2 du tableau t
3. Modifiez la valeur de la ligne entrante en (2,1,1)4. Modifiez la valeur d'incrémentation automatique de la table en 3
5. Continuez à insérer des données puisqu'il y a déjà un enregistrement de c=1, donc erreur de clé en double (conflit de clé unique. ) est signalé et l'instruction renvoie
. L'organigramme d'exécution correspondant est le suivant :
Après cela, lors de l'insertion d'une nouvelle ligne de données, l'ID auto-incrémenté obtenu est 3. Il existe une situation dans laquelle la clé primaire auto-croissante est discontinueUn conflit de clé unique et l'annulation de la transaction conduiront à la situation où l'identifiant de clé primaire auto-croissante est discontinu
4.
Le verrouillage d'identification auto-augmentation n'est pas un verrouillage de transaction est libéré immédiatement après chaque application, afin de permettre à d'autres transactions de s'appliquer à nouveau
Mais dans la version MySQL 5.0, la portée du verrouillage auto-augmentation est la niveau de la déclaration. En d'autres termes, si une instruction demande un verrouillage par incrémentation automatique de table, le verrou ne sera pas libéré tant que l'instruction n'est pas exécutée. MySQL version 5.1.22 introduit une nouvelle stratégie, un nouveau paramètre innodb_autoinc_lock_mode, la valeur par défaut est 1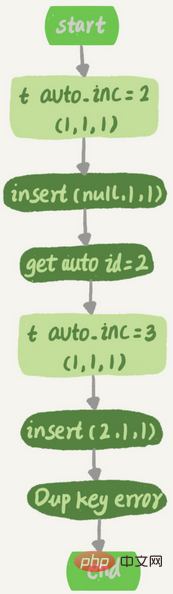
. 1. Ce paramètre est défini sur 0, ce qui signifie que la stratégie de la version précédente de MySQL 5.0 est adoptée, c'est-à-dire que le verrou est libéré après l'exécution de l'instruction
2 Ce paramètre est défini sur 1
Pour une insertion ordinaire. instructions, le verrouillage à incrémentation automatique est libéré immédiatement après l'applicationSemblable aux instructions insert...select qui insèrent des données par lots, le verrouillage à incrémentation automatique doit toujours attendre que l'instruction soit terminée avant de la libérer
3 . Ce paramètre est défini sur 2 et toutes les actions à appliquer pour les clés primaires à incrémentation automatique sont libérées après l'application de Lock
Pour la cohérence des données, le paramètre par défaut est 1
Si sessionB applique la valeur d'incrémentation automatique et libère la valeur. verrouille immédiatement l'incrémentation automatique, la situation suivante peut se produire :sessionB insère d'abord deux lignes de données (1, 1,1), (2,2,2)
- sessionA a demandé l'identifiant d'incrémentation automatique et a obtenu id=3. Après avoir inséré (3,5,5), sessionB a continué à s'exécuter et a inséré deux enregistrements (4, 3,3), (5,4,4)
1) Laissez les instructions d'insertion de données par lots de la bibliothèque d'origine générer des valeurs d'identification continues. Par conséquent, le verrou auto-croissant n'est pas libéré tant que l'instruction n'est pas exécutée, juste pour atteindre cet objectif
2)在binlog里面把插入数据的操作都如实记录进来,到备库执行的时候,不再依赖于自增主键去生成。也就是把innodb_autoinc_lock_mode设置为2,同时binlog_format设置为row
如果有批量插入数据(insert … select、replace … select和load data)的场景时,从并发插入数据性能的角度考虑,建议把innodb_autoinc_lock_mode设置为2,同时binlog_format设置为row,这样做既能并发性,又不会出现数据一致性的问题
对于批量插入数据的语句,MySQL有一个批量申请自增id的策略:
1.语句执行过程中,第一次申请自增id,会分配1个
2.1个用完以后,这个语句第二次申请自增id,会分配2个
3.2个用完以后,还是这个语句,第三次申请自增id,会分配4个
4.依次类推,同一个语句去申请自增id,每次申请到的自增id个数都是上一次的两倍
insert into t values(null, 1,1); insert into t values(null, 2,2); insert into t values(null, 3,3); insert into t values(null, 4,4); create table t2 like t; insert into t2(c,d) select c,d from t; insert into t2 values(null, 5,5);
insert … select,实际上往表t2中插入了4行数据。但是,这四行数据是分三次申请的自增id,第一次申请到了id=1,第二次被分配了id=2和id=3,第三次被分配到id=4到id=7
由于这条语句实际上只用上了4个id,所以id=5到id=7就被浪费掉了。之后,再执行insert into t2 values(null, 5,5),实际上插入了的数据就是(8,5,5)
这是主键id出现自增id不连续的第三种原因
五、自增主键用完了
自增主键字段在达到定义类型上限后,再插入一行记录,则会报主键冲突的错误
以无符号整型(4个字节,上限就是 2 32 − 1 2^{32}-1 232−1)为例,通过下面这个语句序列验证一下:
CREATE TABLE t ( id INT UNSIGNED auto_increment PRIMARY KEY ) auto_increment = 4294967295; INSERT INTO t VALUES(NULL); INSERT INTO t VALUES(NULL);
第一个insert语句插入数据成功后,这个表的AUTO_INCREMENT没有改变(还是4294967295),就导致了第二个insert语句又拿到相同的自增id值,再试图执行插入语句,报主键冲突错误
相关学习推荐:mysql教程(视频)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL est un système de gestion de base de données relationnel open source. 1) Créez une base de données et des tables: utilisez les commandes CreateDatabase et CreateTable. 2) Opérations de base: insérer, mettre à jour, supprimer et sélectionner. 3) Opérations avancées: jointure, sous-requête et traitement des transactions. 4) Compétences de débogage: vérifiez la syntaxe, le type de données et les autorisations. 5) Suggestions d'optimisation: utilisez des index, évitez de sélectionner * et utilisez les transactions.
 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL sont des compétences essentielles pour les développeurs. 1.MySQL est un système de gestion de base de données relationnel open source, et SQL est le langage standard utilisé pour gérer et exploiter des bases de données. 2.MySQL prend en charge plusieurs moteurs de stockage via des fonctions de stockage et de récupération de données efficaces, et SQL termine des opérations de données complexes via des instructions simples. 3. Les exemples d'utilisation comprennent les requêtes de base et les requêtes avancées, telles que le filtrage et le tri par condition. 4. Les erreurs courantes incluent les erreurs de syntaxe et les problèmes de performances, qui peuvent être optimisées en vérifiant les instructions SQL et en utilisant des commandes Explication. 5. Les techniques d'optimisation des performances incluent l'utilisation d'index, d'éviter la numérisation complète de la table, d'optimiser les opérations de jointure et d'améliorer la lisibilité du code.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Comment construire une base de données SQL
Apr 09, 2025 pm 04:24 PM
Comment construire une base de données SQL
Apr 09, 2025 pm 04:24 PM
La construction d'une base de données SQL comprend 10 étapes: sélectionner des SGBD; Installation de SGBD; créer une base de données; créer une table; insérer des données; récupération de données; Mise à jour des données; supprimer des données; gérer les utilisateurs; sauvegarde de la base de données.
