
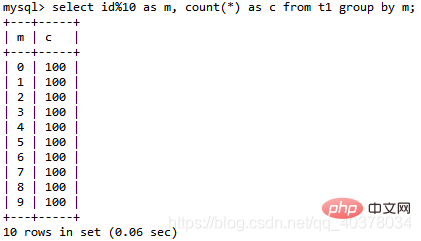
select id%10 as m, count(*) as c from t1 group by m;
 base de données
tutoriel mysql
Explication détaillée des instructions count(), union() et group by dans MySQL
base de données
tutoriel mysql
Explication détaillée des instructions count(), union() et group by dans MySQL
Explication détaillée des instructions count(), union() et group by dans MySQL

Cet article vous guidera à travers les instructions count(), union() et group by, et complétera les points de connaissances MySQL (utilisation de différents count(), processus d'exécution d'union, instruction group by).

1. Différentes utilisations de count() dans MySQL
count() est une fonction d'agrégation. L'ensemble de résultats renvoyé est jugé ligne par ligne. Si le paramètre de la fonction count n'est pas NULL, le cumulatif. la valeur est ajoutée 1, sinon ne pas ajouter. Enfin, la valeur cumulée est renvoyée. [Recommandations associées : Tutoriel vidéo mysql]
1. Pour le nombre (identifiant de clé primaire), le moteur InnoDB parcourra toute la table, supprimera la valeur d'identifiant de chaque ligne et la renverra à la couche serveur. Une fois que la couche serveur a obtenu l'identifiant, elle juge qu'il ne peut pas être vide, elle l'accumule donc par ligne
2 Pour count(1), le moteur InnoDB parcourt la table entière mais ne prend pas de valeur. La couche serveur met un numéro 1 dans chaque ligne renvoyée. Il est jugé qu'il ne peut pas être vide et est accumulé par ligne 3. Pour le nombre (champ), si ce champ est défini comme non nul, ligne par ligne, lisez ce champ à partir de. l'enregistrement, juge qu'il ne peut pas être nul et accumule-le par ligne ; si la définition du champ autorise null, alors lors de l'exécution, il est jugé qu'il peut être nul, et la valeur doit être retirée et jugée pour voir si elle l'est. non nul. Accumuler
4. Pour
, il ne doit pas être nul. Accumuler par lignecount(*)来说,并不会把全部字段取出来,而是专门做了优化。不取值,count(*)

Afin de faciliter l'analyse quantitative, prenons le tableau t1 suivant comme exemple
.create table t1(id int primary key, a int, b int, index(a));
CREATE DEFINER=`root`@`%` PROCEDURE `idata`()
BEGIN
declare i int;
set i=1;
while(i<=1000)do
insert into t1 values(i, i, i);
set i=i+1;
end while;
ENDanalysez l'instruction SQL suivante : La sémantique de
(select 1000 as f) union (select id from t1 order by id desc limit 2);
union est de prendre l'union des résultats de ces deux sous-requêtes. L'union signifie que les deux ensembles sont additionnés et qu'une seule ligne de lignes en double est conservée

- Champ supplémentaire dans la troisième row, Indique que lors de l'exécution de l'union sur l'ensemble de résultats de la sous-requête, une table temporaire est utilisée. Le flux d'exécution de cette instruction est le suivant :
- 1 Créez une table temporaire en mémoire. Cette table temporaire n'a qu'un seul champ entier f. , et f est le champ de clé primaire
obtenez l'identifiant de la première ligne = 1000 et essayez de l'insérer dans la table temporaire. Mais comme la valeur 1000 existe déjà dans la table temporaire, ce qui viole la contrainte d'unicité, l'insertion échoue, puis l'exécution continue
La deuxième ligne id=999 est obtenue, et l'insertion dans la table temporaire est réussie
- 4. Appuyez sur depuis la table temporaire Retirez les données ligne par ligne, renvoyez le résultat et supprimez la table temporaire. Le résultat contient deux lignes de données, qui sont 1000 et 999
La table temporaire de mémoire joue ici le rôle. rôle de stockage temporaire des données, et le processus de calcul utilise également la table temporaire. La contrainte d'unicité de l'identifiant de clé primaire implémente la sémantique de l'union
Si l'union dans l'instruction ci-dessus est modifiée en union all, il n'y aura pas de sémantique de déduplication. Lorsqu'elles sont exécutées de cette manière, les sous-requêtes sont exécutées dans l'ordre et les résultats obtenus sont directement envoyés au client dans le cadre de l'ensemble de résultats. Par conséquent, il n'est pas nécessaire d'avoir une table temporaire
Le champ Extra dans la deuxième ligne indique Using index, ce qui signifie que seul l'index de couverture est utilisé et que la table temporaire n'est pas utilisée
1 , group by processus d'exécution
Utilisez toujours le tableau t1 ci-dessus pour analyser l'instruction SQL suivante :select id%10 as m, count(*) as c from t1 group by m;
Copier après la connexionLa logique de cette instruction est de regrouper les données dans la table t1 selon id%10, et effectue des statistiques en fonction du résultat de m Sortie après tri. Le résultat de l'explication est le suivant :
Dans le champ Extra, vous pouvez voir trois informations : select id%10 as m, count(*) as c from t1 group by m;
Using index, ce qui signifie que cette instruction utilise un index de couverture, sélectionne l'index a et n'a pas besoin de retourner la table 
Utiliser temporaire, ce qui signifie utiliser La table temporaire
- Utiliser filesort signifie qu'un tri est requis
- Le flux d'exécution de cette instruction est le suivant :
- 1. Créez une table temporaire en mémoire. m et c dans le tableau, et la clé primaire est m
内存临时表排序流程图:
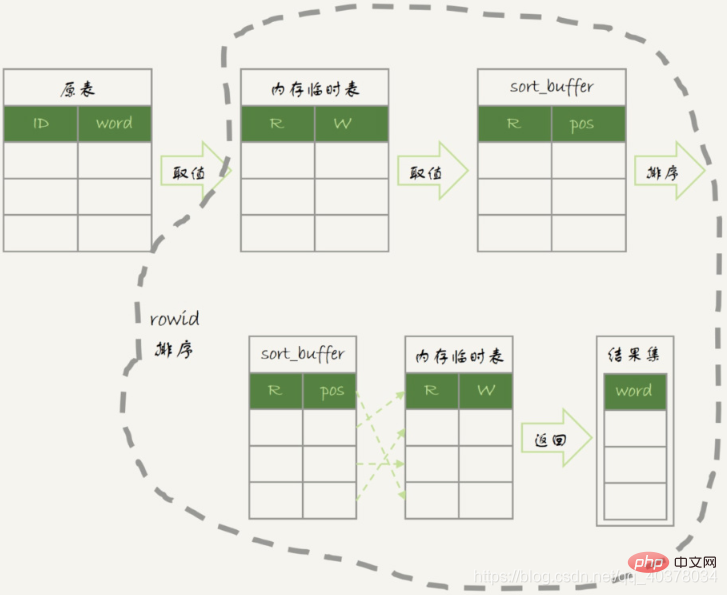
如果并不需要对结果进行排序,在SQL语句末尾增加order by null:
select id%10 as m, count(*) as c from t1 group by m order by null;
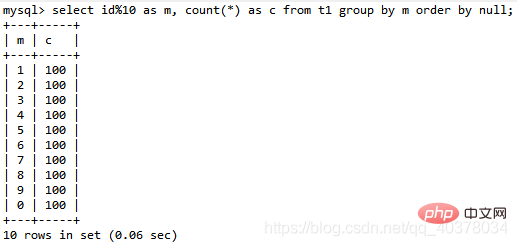
由于表t1中的id值是从1开始的,因此返回的结果集中第一行是id=1
这个例子里由于临时表只有10行,内存可以放得下,因此全程只使用了内存临时表。但是,内存临时表的大小是有限的,参数tmp_table_size就是控制整个内存大小的,默认是16M
set tmp_table_size=1024; select id%100 as m, count(*) as c from t1 group by m order by null limit 10;
把内存临时表的大小限制为最大1024字节,并把语句改成id%100,这样返回结果里有100行数据。但是,这时的内存临时表大小不够存下这100行数据,也就是说,执行过程中会发现内存临时表大小达到了上限。那么,这时候会把内存临时表转成磁盘临时表,磁盘临时表默认使用的引擎是InnoDB
2、group by优化方法——索引
group by的语义逻辑,是统计不同的值的个数。但是,由于每一行的id%100的结果是无序的,所以就需要有一个临时表来记录并统计结果。那么,如果扫描过程中可以保证出现的数据是有序的就可以了
假设,现在有一个类似下图的这么一个数据结构

如果可以确保输入的数据是有序的,那么计算group by的时候,就只需要从左到右,顺序扫描,依次累加。也就是下面这个流程:
- 当碰到第一个1的时候,已经知道累积了X个0,结果集里的第一行就是(0,X)
- 当碰到第一个2的时候,已经知道累积了Y个1,结果集里的第一行就是(1,Y)
按照这个逻辑执行的话,扫描到整个输入的数据结束,就可以拿到group by的结果,不需要临时表,也需要再额外排序
在MySQL5.7版本支持了generated column机制,用来实现列数据的关联更新。创建一个列z,在z列上创建一个索引
alter table t1 add column z int generated always as(id % 100), add index(z);
这样,索引z上的数据就是有序的了。group by语句就可以改成:
select z, count(*) as c from t1 group by z;

从这个Extra字段可以看到,这个语句的执行不再需要临时表,也不需要排序了
3、group by优化方法——直接排序
在group by语句中加入SQL_BIG_RESULT这个提示,就可以告诉优化器:这个语句涉及的数据量很大,直接用磁盘临时表。因为磁盘临时表是B+树存储,存储效率不如数组来得高。所以MySQL优化器直接用数组来存
select SQL_BIG_RESULT id%100 as m, count(*) as c from t1 group by m;
1.初始化sort_buffer,确定放入一个整型字段,记为m
2.扫描表t1的索引a,依次取出里面的id值,将id%100的值存入sort_buffer中
3.扫描完成后,对sort_buffer的字段m做排序(如果sort_buffer内存不够用,就会利用磁盘临时文件辅助排序)
4.排序完成后,就得到了一个有序数组
根据有序数组,得到数组里面的不同值,以及每个值的出现次数
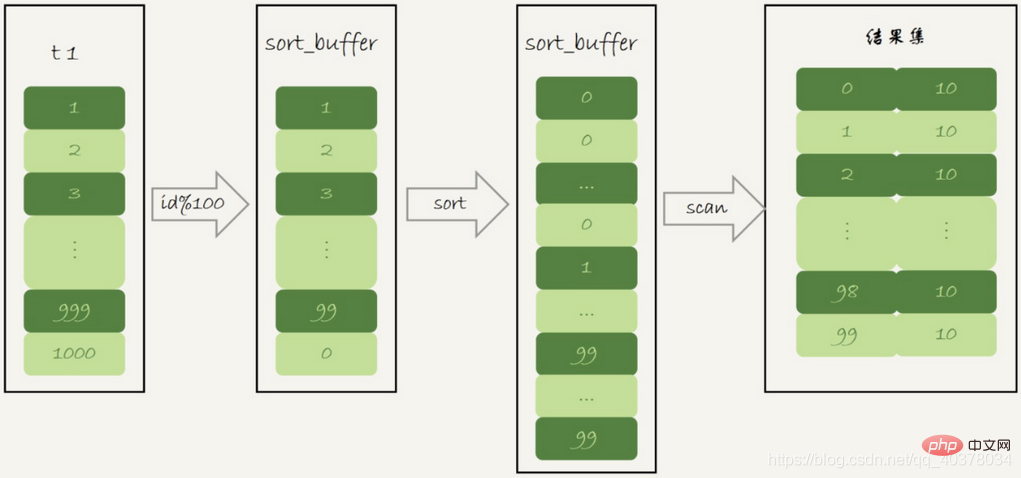
这个语句的执行没有再使用临时表,而是直接用了排序算法
,%20union()%20et%20group%20by%20dans%20MySQL)
更多编程相关知识,请访问:编程入门!!
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1393
1393
 52
1207
24
52
1207
24

 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Apache se connecte à une base de données nécessite les étapes suivantes: Installez le pilote de base de données. Configurez le fichier web.xml pour créer un pool de connexion. Créez une source de données JDBC et spécifiez les paramètres de connexion. Utilisez l'API JDBC pour accéder à la base de données à partir du code Java, y compris l'obtention de connexions, la création d'instructions, les paramètres de liaison, l'exécution de requêtes ou de mises à jour et de traitement des résultats.
 Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Le processus de démarrage de MySQL dans Docker se compose des étapes suivantes: Tirez l'image MySQL pour créer et démarrer le conteneur, définir le mot de passe de l'utilisateur racine et mapper la connexion de vérification du port Créez la base de données et l'utilisateur accorde toutes les autorisations sur la base de données
 CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
L'installation de MySQL sur CENTOS implique les étapes suivantes: Ajout de la source MySQL YUM appropriée. Exécutez la commande YUM Install MySQL-Server pour installer le serveur MySQL. Utilisez la commande mysql_secure_installation pour créer des paramètres de sécurité, tels que la définition du mot de passe de l'utilisateur racine. Personnalisez le fichier de configuration MySQL selon les besoins. Écoutez les paramètres MySQL et optimisez les bases de données pour les performances.
 Comment installer MySQL dans CentOS7
Apr 14, 2025 pm 08:30 PM
Comment installer MySQL dans CentOS7
Apr 14, 2025 pm 08:30 PM
La clé de l'installation de MySQL est d'élégance pour ajouter le référentiel MySQL officiel. Les étapes spécifiques sont les suivantes: Téléchargez la clé GPG officielle MySQL pour empêcher les attaques de phishing. Ajouter un fichier de référentiel MySQL: RPM -UVH https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm Mise à jour du référentiel Cache: Yum Update Installation Mysql: Yum install install install starting starting mysql Service: SystemCTL start start mysqld starger bugo boartup Service mysql Service: SystemCTL start start mysqld starger bugo bo onthing staring Service mysql Service: SystemCTL Start Start MySQLD Set Out Up Boaching Staring Service MySQL Service: SystemCTL Start Start MysQL
