
 base de données
tutoriel mysql
Une explication détaillée des tables, bases de données, fragments et partitions MySql
base de données
tutoriel mysql
Une explication détaillée des tables, bases de données, fragments et partitions MySql
Une explication détaillée des tables, bases de données, fragments et partitions MySql

1. Avant-propos 的 Une fois que la quantité de données de la base de données atteint un certain degré, pour éviter de créer des goulots d'étranglement dans les performances du système. Les données doivent être traitées au moyen de partitionnement, de partitionnement, de bases de données et de tables.
2. Sharding (similaire au sharding)
Le Sharding est un moyen efficace d'étendre la base de données à plusieurs nœuds physiques. Son objectif principal est de dépasser les limitations de capacité d'E/S du serveur. problèmes d’évolutivité de la base de données. Le mot fragment signifie « fragment ». Si une base de données est traitée comme un gros morceau de verre et que le verre est brisé, alors chaque petit morceau est appelé un fragment de la base de données (Database Shard). Le processus consistant à diviser l'ensemble de la base de données en morceaux est appelé sharding, qui peut être traduit par sharding. Formellement, le partitionnement peut être simplement défini comme un schéma de partitionnement qui distribue une grande base de données sur plusieurs nœuds physiques. Chaque partition contient une certaine partie de la base de données, appelée tranche. La méthode de partitionnement peut être arbitraire et ne se limite pas au partitionnement horizontal et vertical traditionnel. Un fragment peut contenir le contenu de plusieurs tables ou même de plusieurs instances de base de données. Chaque fragment est placé sur un serveur de base de données. Un serveur de base de données peut gérer une ou plusieurs fragments de données. Un serveur est requis dans le système pour le routage et le transfert des requêtes, et est responsable du transfert de la requête vers le fragment ou le nœud de collecte de fragments contenant les données auxquelles la requête accède pour exécution.
3. Scale Out/Scale Up et Splittage vertical/Horizontal Splitting
Les solutions d'expansion de MySQL incluent Scale Out et Scale Up. Scale Out (expansion horizontale) signifie que l'application peut être étendue dans le sens horizontal. De manière générale, pour les applications de centre de données, Scale-out signifie que lorsque davantage de machines sont ajoutées, l'application peut toujours faire bon usage des ressources de ces machines pour améliorer sa propre efficacité et atteindre une bonne évolutivité.
Scale Up (expansion verticale) signifie que l'application peut se développer dans le sens vertical. De manière générale, pour une seule machine, la valeur de Scale Up est que lorsqu'un nœud informatique (machine) ajoute plus de cœurs de processeur, de périphériques de stockage et utilise plus de mémoire, l'application peut utiliser pleinement ces ressources pour améliorer son efficacité. atteindre une bonne évolutivité.
La stratégie de partitionnement de MySql comprend le partitionnement vertical et le partitionnement horizontal.
Répartition verticale (verticale) : fait référence à la division par modules fonctionnels pour résoudre la compétition io entre les tables. Par exemple, elle est divisée en base de données de commandes, base de données de produits, base de données d'utilisateurs... De cette façon, les structures de tables de plusieurs bases de données sont différentes.
Division horizontale (horizontale) : enregistrez les données de la même table en blocs et enregistrez-les dans différentes bases de données pour résoudre la pression de l'augmentation du volume de données dans une seule table. Les structures de tables dans ces bases de données sont exactement les mêmes.
La conception de la structure de la table est divisée verticalement. Certains scénarios courants incluent la
segmentation verticale de grands champs. Créez des champs volumineux séparément dans une autre table pour améliorer les performances d'accès de la table de base. En principe, les champs volumineux dans la base de données doivent être évités dans les applications critiques en termes de performances
. Par exemple, les attributs matériels de l'entreprise peuvent être segmentés verticalement en fonction des attributs de base, des attributs de vente, des attributs d'achat, des attributs de fabrication, des attributs de comptabilité financière, etc. Segmentés verticalement en fonction de la fréquence d'accès. Par exemple, dans les systèmes de commerce électronique et Web 2.0, s'il existe de nombreux paramètres d'attributs utilisateur, les attributs de base fréquemment utilisés et les attributs rarement utilisés peuvent être séparés verticalement et la conception de la structure du tableau peut être divisée horizontalement. Certains scénarios courants incluent
Par exemple, sur un site Web de commerce électronique en ligne, la quantité de données du tableau de commande est trop importante et elle est divisée en fonction des niveaux annuels et mensuels
Le site Web 2.0 en a également. de nombreux utilisateurs enregistrés et utilisateurs actifs en ligne, en fonction de la plage d'ID utilisateur, etc. Méthode, segmenter horizontalement les utilisateurs pertinents et les tableaux étroitement liés à l'utilisateur
Par exemple, le premier message d'un forum doit être affiché sur chaque page à cause du problème de pagination, dans ce cas, le message du haut peut être divisé horizontalement. Venez, évitez de lire dans le tableau tous les messages lors de la récupération du message épinglé
- 4. Sous-tableau et partition
Sous-tableau. superficiellement signifie diviser une table en plusieurs petites tables, et le partitionnement signifie diviser une table en plusieurs petites tables. Les données d'une table sont divisées en N blocs. Ces blocs peuvent être sur le même disque ou sur des disques différents.
La différence entre les tables fractionnées et les partitions
Les tables fractionnées de mysql sont de véritables tables fractionnées Une fois qu'une table est divisée en plusieurs tables, chaque petite table est une table complète. à trois fichiers (moteur MyISAM : un fichier de données .MYD, un fichier d'index .MYI et un fichier de structure de table .frm).
- En termes de traitement des données
Après avoir divisé la table, les données sont stockées dans les tables divisées. La table principale n'est qu'un shell et l'accès aux données s'effectue dans chaque table divisée. Il n'y a pas de concept de partitionnement de table dans le partitionnement. Le partitionnement divise simplement le fichier stockant les données en plusieurs petits blocs. La table partitionnée est toujours une table et le traitement des données est toujours effectué par vous-même.
- Amélioration des performances
Après le fractionnement des tables, la capacité de concurrence d'une seule table a été améliorée et les performances d'E/S du disque ont également été améliorées. La partition surmonte le goulot d'étranglement des E/S du disque et je souhaite améliorer les capacités de lecture et d'écriture du disque pour augmenter les performances de MySQL.
À ce stade, l'objectif des tests des partitions et des sous-tables est différent. L'objectif des sous-tables est de savoir comment améliorer la simultanéité de MySQL lors de l'accès aux données et pour les partitions, comment percer les capacités de lecture et d'écriture de ; le disque, améliorant ainsi les performances de mysql Purpose.
- Il existe de nombreuses façons de diviser des tables en termes de difficulté de mise en œuvre. Utiliser la fusion pour diviser les tables est le moyen le plus simple. Cette méthode est aussi simple que le partitionnement et peut être transparente pour le code du programme. Si vous utilisez d'autres méthodes de partitionnement de table, cela sera plus gênant que le partitionnement. L'implémentation du partitionnement est relativement simple. La création d'une table partitionnée n'est pas différente de la construction d'une table ordinaire, et elle est transparente du côté du code.
Lorsque la vitesse de requête d'une table a été suffisamment lente pour affecter son utilisation.
- Les données du tableau sont segmentées
- Les opérations sur les données n'impliquent souvent qu'une partie des données, pas toutes les données
-
CREATE TABLE sales ( id INT AUTO_INCREMENT, amount DOUBLE NOT NULL, order_day DATETIME NOT NULL, PRIMARY KEY(id, order_day)) ENGINE=InnodbPARTITION BY RANGE(YEAR(order_day)) ( PARTITION p_2010 VALUES LESS THAN (2010), PARTITION p_2011 VALUES LESS THAN (2011), PARTITION p_2012 VALUES LESS THAN (2012),PARTITION p_catchall VALUES LESS THAN MAXVALUE);
Copier après la connexion
Une table Le la vitesse des requêtes a été si lente qu’elle affecte l’utilisation.
- Lors de l'insertion fréquente ou de la participation à des requêtes, la vitesse ralentira.
- La mise en œuvre de sous-tables nécessite une combinaison de mise en œuvre métier et de migration, ce qui est relativement complexe.
Le partage de table peut résoudre le problème de la réduction de l'efficacité des requêtes causée par un volume de données excessif dans une seule table, mais il ne peut pas apporter une amélioration qualitative des capacités de traitement simultané de la base de données. Face à un accès en lecture et en écriture hautement concurrent, lorsque le serveur maître de base de données ne peut pas supporter la pression des opérations d'écriture, cela n'a aucun sens, quelle que soit la manière d'étendre le serveur esclave. Par conséquent, nous devons changer notre façon de penser et diviser la base de données pour améliorer la capacité d'écriture de la base de données. C'est ce qu'on appelle la sous-base de données.
Semblable à la stratégie de partitionnement, le partitionnement peut utiliser un mot-clé modulo pour acheminer l'accès aux données, comme le montre la figure ci-dessous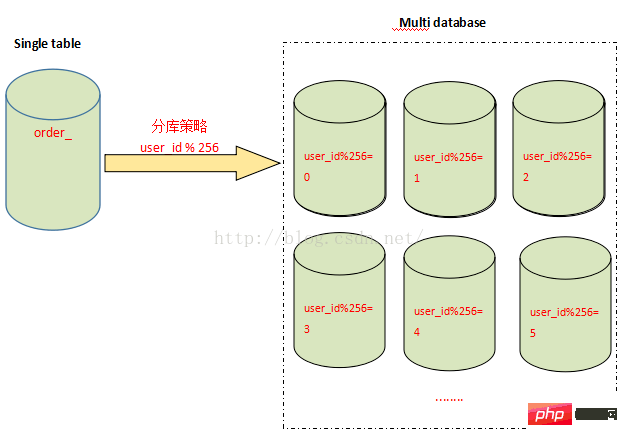
Recommandé : " 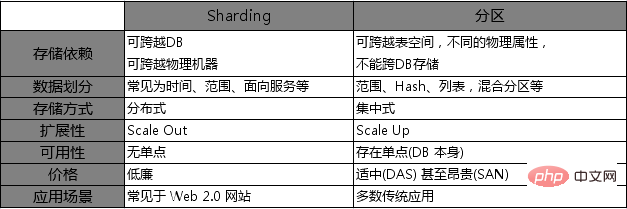 Tutoriel vidéo MySQL
Tutoriel vidéo MySQL
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Apache se connecte à une base de données nécessite les étapes suivantes: Installez le pilote de base de données. Configurez le fichier web.xml pour créer un pool de connexion. Créez une source de données JDBC et spécifiez les paramètres de connexion. Utilisez l'API JDBC pour accéder à la base de données à partir du code Java, y compris l'obtention de connexions, la création d'instructions, les paramètres de liaison, l'exécution de requêtes ou de mises à jour et de traitement des résultats.
 Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Le processus de démarrage de MySQL dans Docker se compose des étapes suivantes: Tirez l'image MySQL pour créer et démarrer le conteneur, définir le mot de passe de l'utilisateur racine et mapper la connexion de vérification du port Créez la base de données et l'utilisateur accorde toutes les autorisations sur la base de données
 CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
L'installation de MySQL sur CENTOS implique les étapes suivantes: Ajout de la source MySQL YUM appropriée. Exécutez la commande YUM Install MySQL-Server pour installer le serveur MySQL. Utilisez la commande mysql_secure_installation pour créer des paramètres de sécurité, tels que la définition du mot de passe de l'utilisateur racine. Personnalisez le fichier de configuration MySQL selon les besoins. Écoutez les paramètres MySQL et optimisez les bases de données pour les performances.
