
 base de données
Redis
Vous présente la réplication maître-esclave, Sentinel et le clustering dans Redis.
base de données
Redis
Vous présente la réplication maître-esclave, Sentinel et le clustering dans Redis.
Vous présente la réplication maître-esclave, Sentinel et le clustering dans Redis.

Cet article vous présentera les connaissances pertinentes de la distribution Redis et vous guidera à travers la réplication maître-esclave, Sentinel et le clustering, afin de faire passer votre niveau Redis à un niveau supérieur !

1. Réplication maître-esclave
1. Introduction
La réplication maître-esclave est la pierre angulaire de la distribution Redis et la garantie de la haute disponibilité de Redis. Dans Redis, le serveur en cours de réplication est appelé serveur maître (Master) et le serveur répliquant le serveur maître est appelé serveur esclave (Slave). [Recommandations associées : Tutoriel vidéo Redis]
La configuration de la réplication maître-esclave est très simple. Il existe trois méthodes (IP-adresse IP du serveur principal/PORT-port du service Redis du serveur principal) :
- .
Fichier de configuration ——Dans le fichier redis.conf, configurez la commande slaveof ip port
——Entrez le client Redis pour exécuter slaveof ip port
Paramètres de démarrage——./redis-server --slaveof ip port
2 , L'évolution de la réplication maître-esclave
Le mécanisme de réplication maître-esclave de Redis n'était pas aussi parfait que la version 6.x au début, mais il a été itéré de version en version. Il a généralement connu trois versions d'itérations :
Avant la 2.8
2.8~4.0
Après la 4.0
Au fur et à mesure que la version grandit, le mécanisme de réplication maître-esclave Redis s'améliore progressivement mais leur ; Essentiellement, elles tournent autour des deux opérations de synchronisation (sync) et de propagation de commandes :
Synchronisation (sync) : fait référence à la mise à jour de l'état des données du serveur esclave vers l'état actuel des données du serveur principal, ce qui se produit principalement dans Initialisation ou synchronisation complète ultérieure.
Propagation de la commande : lorsque l'état des données du serveur maître est modifié (écriture/suppression, etc.) et que l'état des données entre le maître et l'esclave est incohérent, le service maître propage la commande de modification des données à l'esclave serveur, permettant au maître de L'état entre les serveurs esclaves est restauré pour être cohérent.
2.1 Avant la version 2.8
2.1.1 Synchronisation
Avant la version 2.8, la synchronisation du serveur esclave vers le serveur maître nécessite que la commande sync du serveur vers le serveur maître soit terminée :
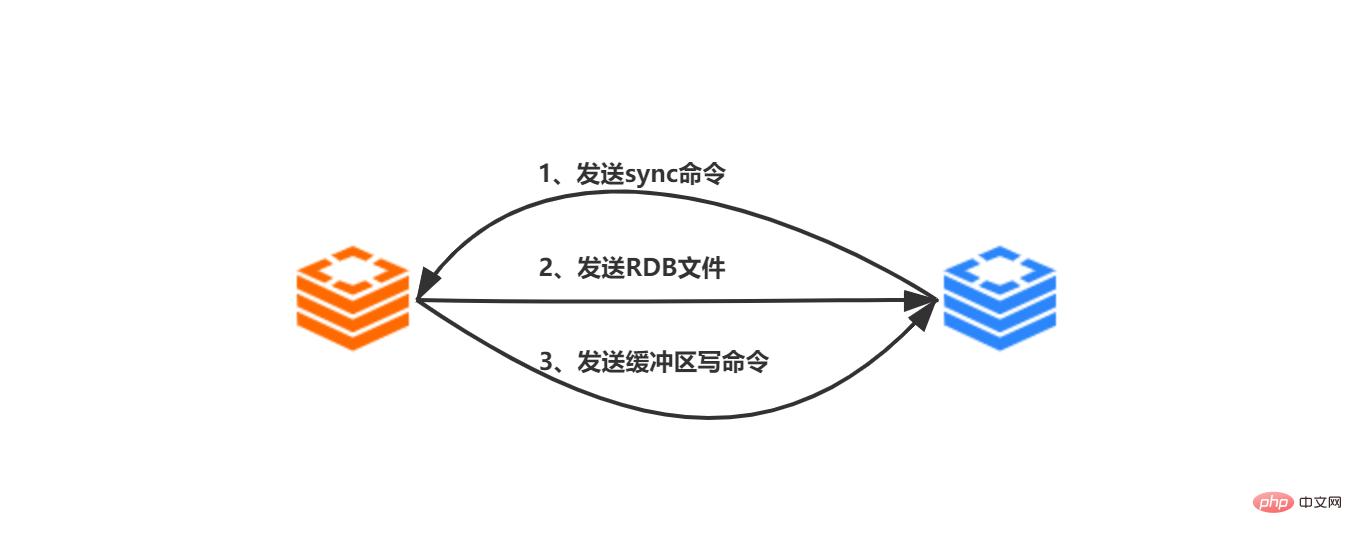
-
Reçu du serveur À la commande slaveof ip prot envoyée par le client, le serveur esclave crée une connexion socket au serveur maître basée sur ip:port
Une fois la socket connectée avec succès au serveur maître, le serveur esclave associera une connexion socket dédiée au serveur maître. Gestionnaire d'événements de fichiers utilisé pour gérer le travail de réplication, gérer les fichiers RDB ultérieurs et les commandes propagées envoyées par le serveur maître
-
Démarrer la réplication, envoyer les commandes de synchronisation du serveur au serveur maître
. Le serveur maître reçoit la commande sync. Après cela, exécutez la commande bgsave, le sous-processus du fork de processus principal du serveur principal générera un fichier RDB et enregistrera en même temps toutes les opérations d'écriture après l'instantané RDB. est généré dans le tampon
Après l'exécution de la commande bgsave, le serveur principal générera Le fichier RDB est envoyé au serveur esclave Après avoir reçu le fichier RDB du serveur esclave, il effacera d'abord toutes ses propres données, puis chargez le fichier RDB et mettez à jour son propre état de données avec l'état des données du fichier RDB du serveur maître
Le serveur maître Envoyez la commande d'écriture du tampon au serveur esclave, recevez la commande du serveur et exécutez il.
L'étape de synchronisation de la réplication maître-esclave est terminée
2.1.2 Propagation des commandes
Une fois le travail de synchronisation terminé, le maître-esclave doit maintenir la cohérence de l'état des données grâce à la propagation des commandes. Comme le montre la figure ci-dessous, une fois le travail de synchronisation entre les serveurs maître et esclave actuels terminé, le service maître supprime K6 après avoir reçu l'instruction DEL K6 du client. À ce moment, K6 existe toujours sur le serveur esclave et le. L'état des données maître-esclave est incohérent. Afin de maintenir l'état cohérent des serveurs maître et esclave, le serveur maître propagera les commandes qui entraînent le changement de son propre état des données vers le serveur esclave pour exécution. Lorsque le serveur esclave exécute également la même commande, l'état des données entre les deux. les serveurs maître et esclave resteront cohérents.
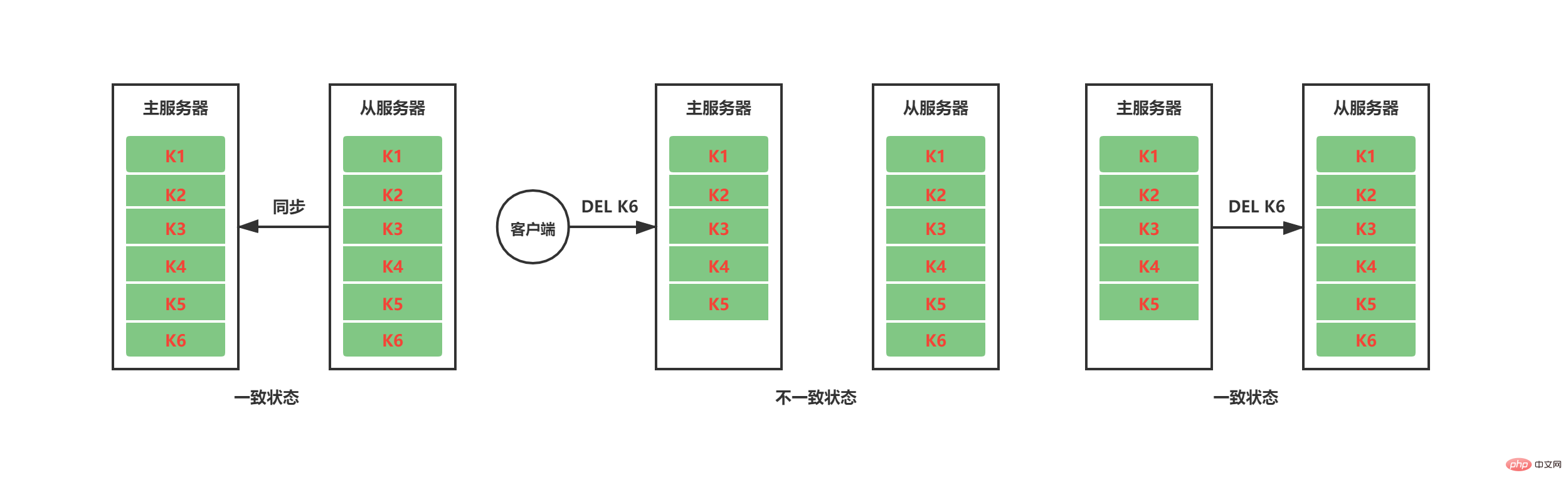
2.1.3 Défauts
D'après ce qui précède, nous ne voyons aucun défaut dans la réplication maître-esclave des versions antérieures à la 2.8. C'est parce que nous n'avons pas pris en compte les fluctuations du réseau. Les frères qui comprennent la distribution doivent avoir entendu parler de la théorie CAP.La théorie CAP est la pierre angulaire des systèmes de stockage distribués.Dans la théorie CAP, P (partition réseau de partition) doit exister, et la réplication maître-esclave Redis ne fait pas exception. Lorsqu'une panne de réseau se produit entre les serveurs maître et esclave, entraînant l'échec de la communication entre le serveur esclave et le serveur maître pendant un certain temps. Lorsque le serveur esclave se reconnecte au serveur maître, si l'état des données du serveur maître. change pendant cette période, des incohérences dans l'état des données du serveur maître-esclave se produiront entre les serveurs. Dans les versions de réplication maître-esclave antérieures à Redis 2.8, la manière de résoudre cette incohérence d'état des données consiste à renvoyer la commande de synchronisation. Bien que la synchronisation puisse garantir la cohérence de l'état des données des serveurs maître et esclave, il est évident que la synchronisation est une opération très gourmande en ressources.
exécution de la commande de synchronisation, les ressources requises par les serveurs maître et esclave :
Le serveur maître exécute BGSAVE pour générer des fichiers RDB, qui occuperont beaucoup de ressources CPU, E/S disque et mémoire
Le Le serveur maître enverra les fichiers RDB générés. Le donner au serveur esclave occupera beaucoup de bande passante réseau
La réception et le chargement du fichier RDB à partir du serveur entraîneront le blocage du serveur esclave et l'empêcheront de fournir des services
.
Comme le montrent les trois points ci-dessus, la commande sync entraînera non seulement le maître. Une diminution de la réactivité du serveur entraînera également le refus du serveur esclave de fournir des services externes pendant cette période.
2.2 Version 2.8-4.0
2.2.1 Améliorations
Pour les versions antérieures à la 2.8, Redis a amélioré la synchronisation de l'état des données après la reconnexion du serveur après la 2.8. La direction de l'amélioration est de réduire l'apparition d'une resynchronisation complète et d'utiliser autant que possible la resynchronisation partielle. Après la version 2.8, la commande psync est utilisée à la place de la commande sync pour effectuer les opérations de synchronisation. La commande psync a à la fois des fonctions de synchronisation complète et incrémentielle :
La synchronisation complète est cohérente avec la version précédente (sync)
Incrémentielle. synchronisation Pour la réplication après déconnexion et reconnexion, différentes mesures seront prises selon la situation ; si les conditions le permettent, seule une partie des données manquantes au service sera quand même envoyée.
2.2.2 Comment implémenter psync
Afin d'obtenir une synchronisation incrémentielle après déconnexion et reconnexion du serveur, Redis ajoute trois paramètres auxiliaires :
replication offset (replication offset)
Backlog buffer ( arriéré de réplication)
ID d'exécution du serveur (id d'exécution)
2.2.2.1 Décalage de réplication
Un décalage de réplication sera maintenu à la fois dans le serveur maître et dans le serveur esclave
-
Le serveur maître envoie données au service esclave, répartissant N octets de données, et le décalage de réplication du service maître augmente de N
Le serveur esclave reçoit les données envoyées par le serveur maître, reçoit N octets de données, et le serveur esclave Le le décalage de réplication augmente de N
La situation normale de synchronisation est la suivante :
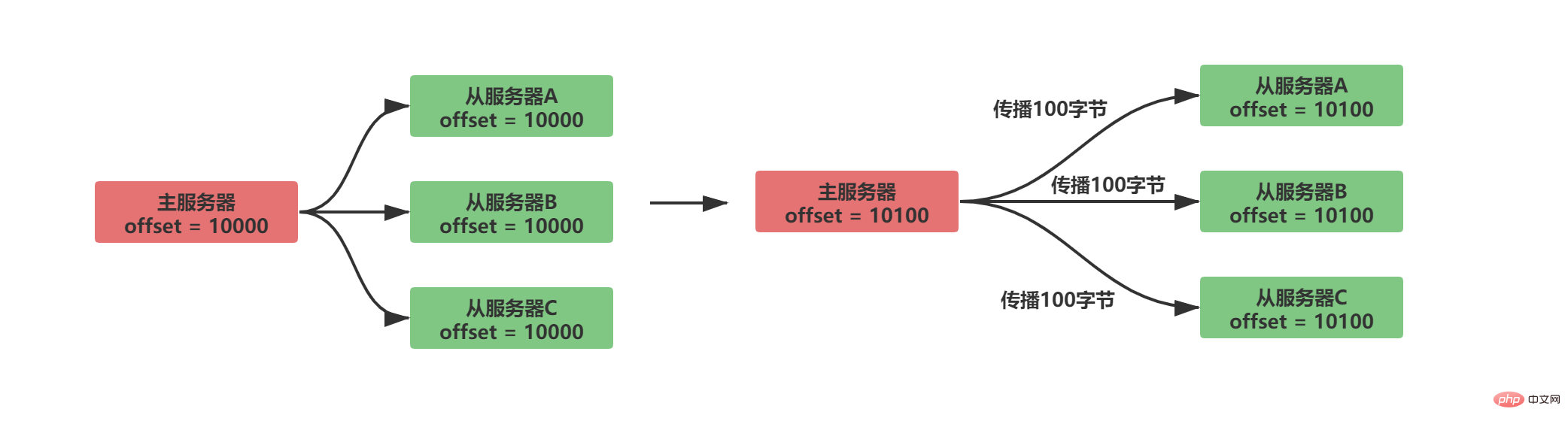
En comparant si les décalages de réplication entre les serveurs maître et esclave sont égaux, vous pouvez savoir si l'état des données entre le maître et les serveurs esclaves sont cohérents. Supposons que A/B se propage normalement à ce moment et que le serveur esclave C est déconnecté, alors la situation suivante se produira :
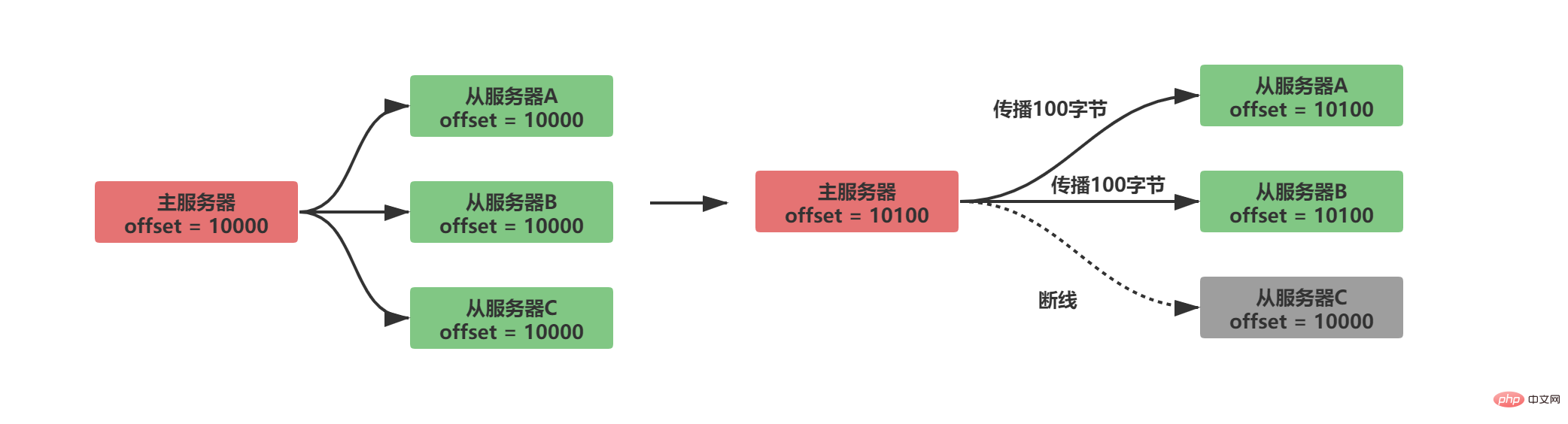
Évidemment, après que le décalage de réplication soit disponible, après que le serveur esclave C soit déconnecté et reconnecté , le serveur maître enverra uniquement les 100 octets de données manquants du serveur. Mais comment le serveur maître sait-il quelles données manquent sur le serveur esclave ?
2.2.2.2 Tampon de backlog de copie
Le tampon de backlog de copie est une file d'attente de longueur fixe avec une taille par défaut de 1 Mo. Lorsque l'état des données du serveur maître change, le serveur maître synchronise les données avec le serveur esclave et enregistre une copie dans le tampon du backlog de réplication.
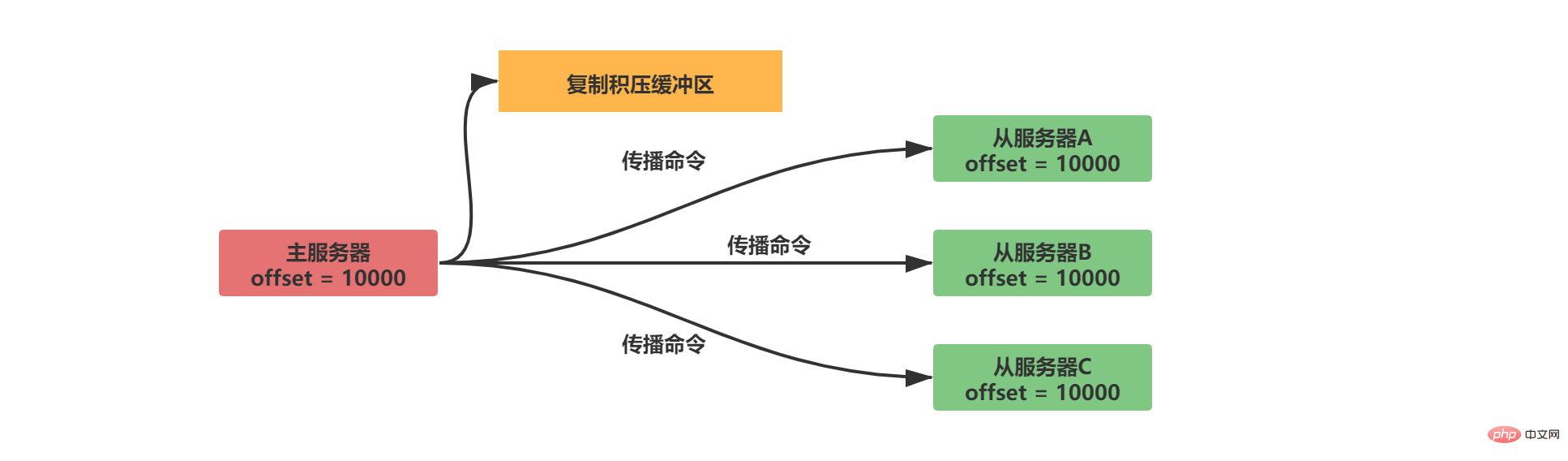
Afin de faire correspondre le décalage, le tampon du backlog de copie stocke non seulement le contenu des données, mais enregistre également le décalage correspondant à chaque octet :

Lorsque le serveur esclave est déconnecté et reconnecté Enfin, l'esclave Le serveur envoie son propre décalage de réplication (offset) au serveur maître via la commande psync. Le serveur maître peut utiliser ce décalage pour déterminer s'il doit effectuer une propagation incrémentielle ou une synchronisation complète.
Si les données à offset offset+1 sont toujours dans le tampon du backlog de copie, effectuez une opération de synchronisation incrémentielle
Sinon, effectuez une opération de synchronisation complète, cohérente avec la synchronisation
La taille du tampon de copie par défaut de Redis est de 1 Mo. Comment la définir si vous devez la personnaliser ? Évidemment, nous souhaitons utiliser la synchronisation incrémentielle autant que possible, mais nous ne voulons pas que le tampon occupe trop d'espace mémoire. Nous pouvons ensuite définir la taille du tampon de backlog de réplication S en estimant le temps de reconnexion T après la déconnexion du service esclave Redis et la taille de mémoire M des commandes d'écriture reçues par le serveur maître Redis par seconde.
S = 2 * M * T
Notez que l'expansion 2 fois ici vise à laisser une certaine marge pour garantir que la plupart des déconnexions et reconnexions peuvent utiliser la synchronisation incrémentielle.
2.2.2.3 Serveur exécutant l'ID
Après avoir vu cela, pensez-vous à nouveau que la synchronisation incrémentielle de la déconnexion et de la reconnexion peut être réalisée ci-dessus, pourquoi avez-vous encore besoin d'exécuter l'ID ? En fait, il existe une autre situation qui n'a pas été prise en compte, c'est-à-dire que lorsque le serveur maître tombe en panne, un serveur esclave est élu comme nouveau serveur maître. Dans ce cas, nous pouvons le distinguer en comparant l'ID en cours d'exécution.
L'ID d'exécution (run id) est constitué de 40 chaînes hexadécimales aléatoires générées automatiquement au démarrage du serveur. Le service maître et le serveur esclave génèreront l'ID d'exécution
Lorsque le serveur esclave synchronise celui du serveur maître pour le. la première fois Lorsque les données sont générées, le serveur maître enverra son propre ID d'exécution au serveur esclave, et le serveur esclave l'enregistrera dans le fichier RDB
Lorsque le serveur esclave sera déconnecté et reconnecté, le serveur esclave enverra l'ID d'exécution du serveur maître précédemment enregistré sur le serveur maître. Si l'ID d'exécution du serveur correspond, cela prouve que le serveur principal n'a pas changé, vous pouvez essayer la synchronisation incrémentielle
Si l'ID d'exécution du serveur ne correspond pas, effectuez une synchronisation complète. synchronisation
2.2.3 PPsync complète
Complet Le processus psync est très complexe, et il a été très complet dans la version de réplication maître-esclave 2.8-4.0. Les paramètres envoyés par la commande psync sont les suivants :
psync
Lorsque le serveur esclave n'a répliqué aucun serveur maître (ce n'est pas la première fois que le maître-esclave réplique, car le serveur maître peut changer, mais la première copie complète de la synchronisation du serveur esclave), le serveur esclave enverra :
psync ? SLAVEOF 127.0.0.1 est reçu du serveur 6379 La commande
renvoie OK du serveur à l'initiateur de la commande (il s'agit d'une opération asynchrone, retournez d'abord OK, puis enregistrez l'adresse et les informations de port) 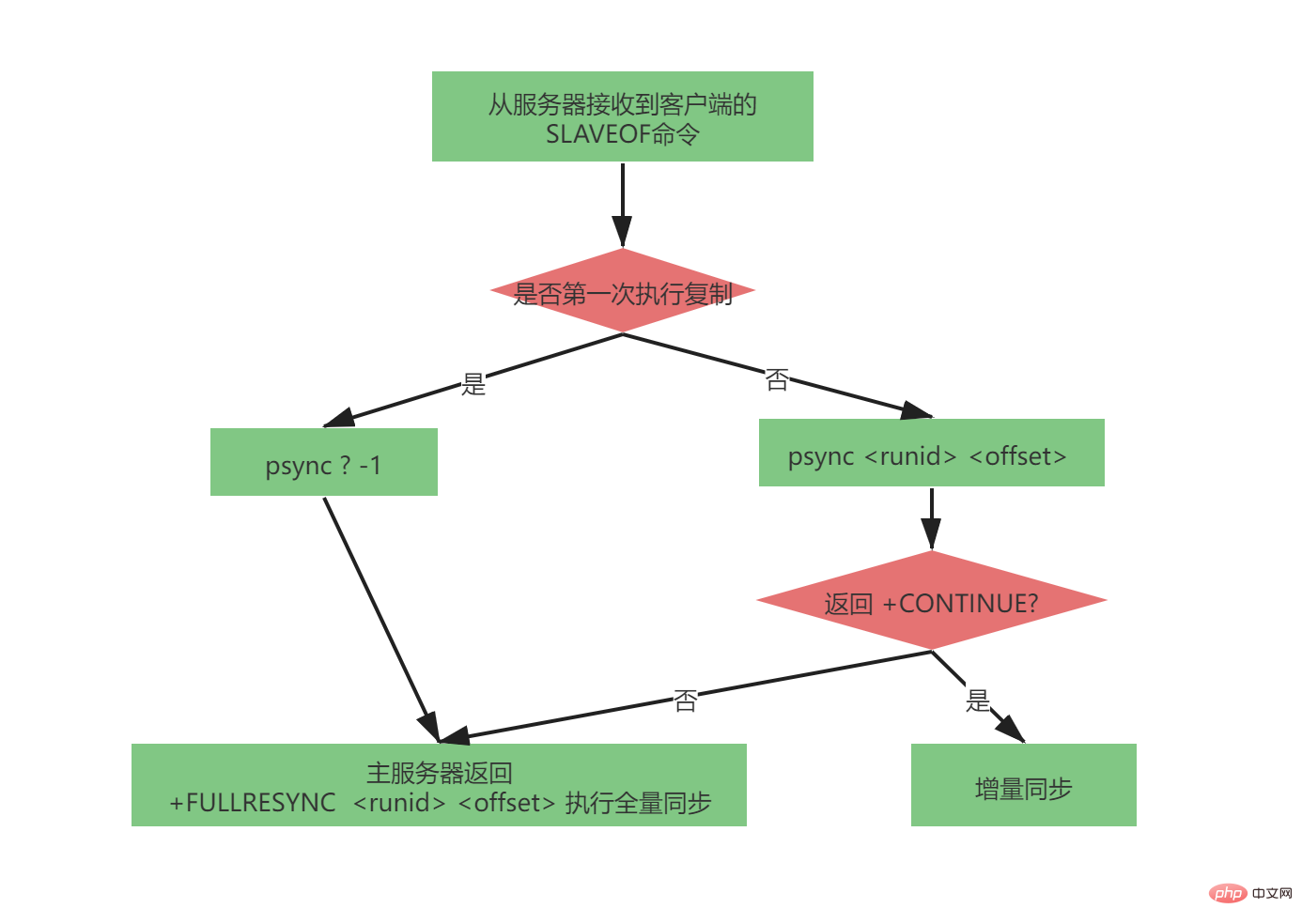
Enregistrer l'adresse IP et les informations de port du serveur vers l'hôte maître et le port maître
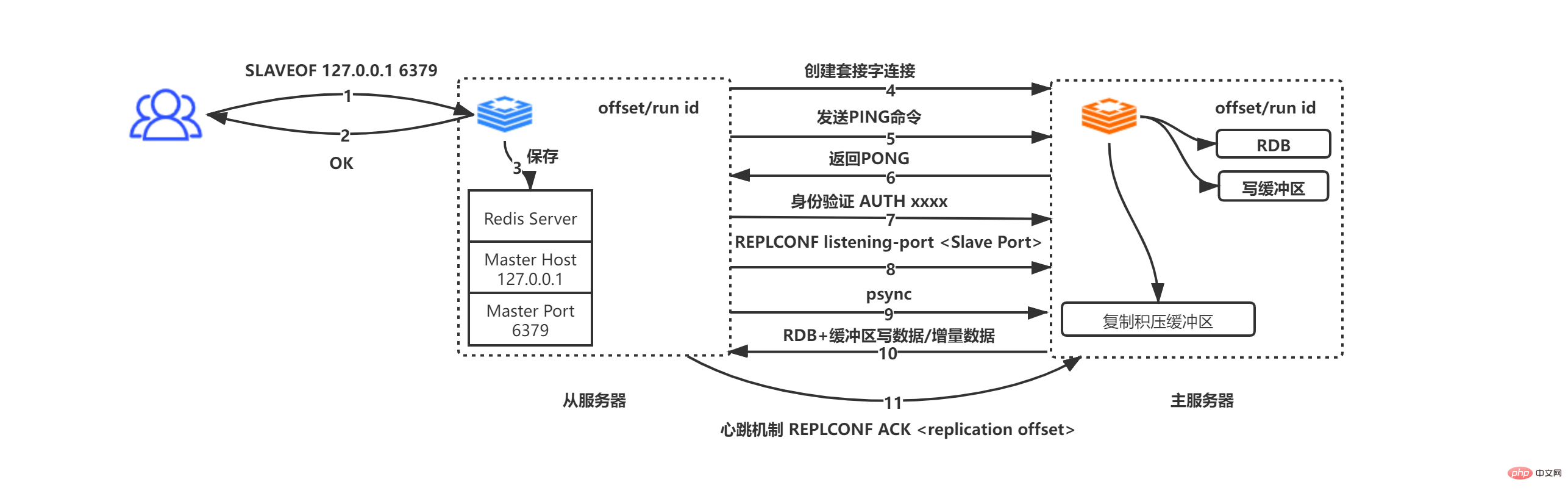 Le serveur esclave initie activement une connexion socket au serveur maître en fonction de l'hôte maître et du port maître. En même temps, le service esclave le fera. associez un gestionnaire d'événements de fichier spécifiquement utilisé pour la copie de fichiers à cette connexion socket pour une utilisation ultérieure de la copie de fichier RDB et d'autres travaux
Le serveur esclave initie activement une connexion socket au serveur maître en fonction de l'hôte maître et du port maître. En même temps, le service esclave le fera. associez un gestionnaire d'événements de fichier spécifiquement utilisé pour la copie de fichiers à cette connexion socket pour une utilisation ultérieure de la copie de fichier RDB et d'autres travaux
Le serveur maître reçoit la demande de connexion socket du serveur esclave, crée une connexion socket correspondante pour la demande, et regarde un client du serveur esclave (dans la réplication maître-esclave, le serveur maître et le serveur esclave sont en fait clients et serveurs l'un de l'autre)
La connexion socket est établie. Le serveur esclave envoie activement une commande PING. au service maître. Si le serveur maître renvoie PONG dans le délai d'attente spécifié, cela prouve que la connexion socket est disponible, sinon elle est déconnectée et reconnectée. Si le serveur maître a défini un mot de passe (masterauth), alors le serveur esclave envoie. la commande AUTH masterauth au serveur maître pour l'authentification. Notez que si le serveur esclave envoie un mot de passe mais que le service maître ne définit pas de mot de passe, le serveur maître enverra une erreur aucun mot de passe n'est défini ; si le serveur maître demande un mot de passe mais que le serveur esclave n'envoie pas de mot de passe, le maître ; le serveur enverra une erreur NOAUTH ; si les mots de passe ne correspondent pas, le serveur maître envoie une erreur de mot de passe invalide.
Le serveur esclave envoie le port d'écoute REPLCONF xxxx (xxxx représente le port du serveur esclave) au serveur maître. Après avoir reçu la commande, le serveur principal enregistrera les données. Lorsque le client utilise la réplication INFO pour interroger les informations maître-esclave, il peut renvoyer les données
Envoyer la commande psync depuis le serveur. les deux situations de psync dans l'image ci-dessus
Le serveur maître et le serveur esclave sont clients l'un de l'autre, effectuant des requêtes/réponses de données
Le serveur maître et le serveur esclave utilisent le mécanisme de paquet de battement de coeur pour déterminer si la connexion est déconnectée. Le serveur esclave envoie une commande au serveur maître toutes les 1 seconde, REPLCONF ACL offset (offset de réplication du serveur esclave). Ce mécanisme peut assurer la synchronisation correcte des données entre le maître et l'esclave. Si les offsets ne sont pas égaux, le maître. le serveur prendra des mesures de synchronisation incrémentielle/complète pour garantir un état cohérent des données entre le maître et l'esclave (le choix incrémentiel/complet dépend du fait que les données à offset+1 sont toujours dans le tampon du backlog de réplication)
2.3 version 4.0
Redis version 2.8-4.0 a encore quelques améliorations à apporter. La synchronisation incrémentielle peut-elle être effectuée lorsque le serveur principal est commuté ? Par conséquent, la version Redis 4.0 a été optimisée pour résoudre ce problème et psync a été mis à niveau vers psync2.0. pync2.0 a abandonné l'ID d'exécution du serveur et a utilisé replid et replid2 à la place. Replid stocke l'ID d'exécution du serveur principal actuel, et replid2 enregistre l'ID d'exécution du serveur principal précédent.
décalage de réplication
arriéré de réplication
identifiant d'exécution du serveur maître (replid)
dernier serveur maître exécutant l'identifiant (replid2)
Grâce à replid et replid2, nous pouvons résoudre le problème de l'incrémentation synchronisation lors du changement de serveur principal :
Si replid est égal à l'identifiant d'exécution du serveur principal actuel, alors déterminez la méthode de synchronisation synchronisation incrémentielle/complète
Si le replid n'est pas égal, déterminez si réplicad2 est égaux (qu'ils appartiennent au serveur esclave du serveur maître précédent). S'ils sont égaux, vous pouvez toujours choisir une synchronisation incrémentielle/complète. S'ils ne sont pas égaux, vous ne pouvez effectuer qu'une synchronisation complète.
2. Sentinel
1 Introduction
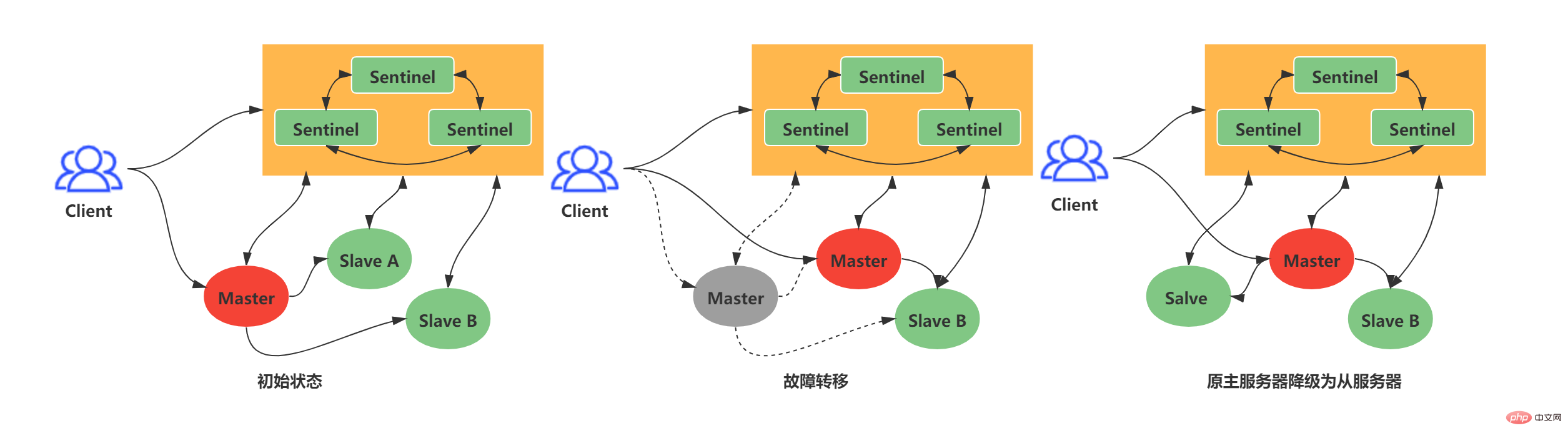
La réplication maître-esclave jette les bases de la distribution Redis, mais la réplication maître-esclave ordinaire ne peut pas atteindre une haute disponibilité. Dans le mode de réplication maître-esclave ordinaire, si le serveur maître tombe en panne, le personnel d'exploitation et de maintenance ne peut changer que manuellement le serveur maître. Évidemment, cette solution n'est pas recommandée. En réponse à la situation ci-dessus, Redis a officiellement lancé une solution à haute disponibilité capable de résister aux pannes de nœuds : Redis Sentinel. Redis Sentinel : un système Sentinel composé d'une ou plusieurs instances Sentinel. Il peut surveiller n'importe quel nombre de serveurs maîtres et esclaves. Lorsque le serveur maître surveillé tombe en panne, le serveur maître sera automatiquement hors ligne et le serveur esclave sera mis à niveau vers un nouveau maître. serveur.
L'exemple suivant : lorsque l'ancien maître est hors ligne pendant une durée supérieure à la limite supérieure de la durée hors ligne définie par l'utilisateur, le système Sentinel effectuera une opération de basculement sur l'ancien maître. L'opération de basculement comprend trois étapes :
- .
Sélectionner les données dans l'esclave Le dernier sert de nouveau maître
Envoie de nouvelles instructions de réplication à d'autres esclaves, permettant à d'autres serveurs esclaves de devenir les nouveaux esclaves du maître
Continuer à surveiller l'ancien maître, et s'il passe en ligne, définissez l'ancien maître sur le nouveau maître esclave
Cet article est basé sur la liste de ressources suivante :
| Adresse IP | Rôle du nœud | Port | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 192.168.211.104 | Redis Master/ Sentinelle 192.168.211.105 | Redis Esclave/ Sentinelle | ||||||||||||||||||||
| 192.168.211.106 | Esclave Redis/Sentinelle | |||||||||||||||||||||
2. Initialisation de Sentinel et connexion réseauIl n'y a rien de particulièrement magique dans Sentinel. Il s'agit d'un serveur Redis plus simple. Lorsque Sentinel démarre, il chargera différentes tables de commandes et fichiers de configuration, donc en substance, Sentinel est un service Redis. moins de commandes et quelques fonctions spéciales. Lorsqu'un Sentinel démarre, il doit suivre les étapes suivantes :
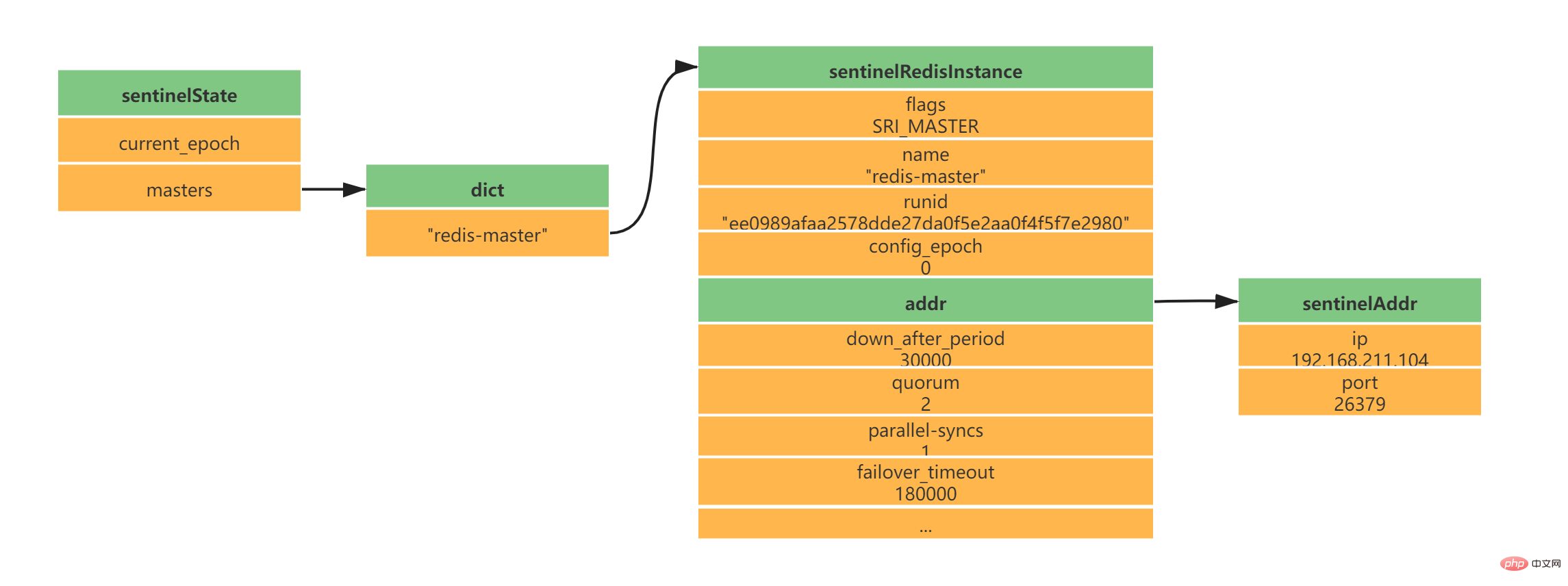
2.1 Initialiser le serveur SentinelSentinel est essentiellement un serveur Redis, donc démarrer Sentinel nécessite le démarrage d'un serveur Redis, mais Sentinel n'a pas besoin de lire les fichiers RDB/AOF pour restaurer l'état des données. 2.2 Remplacer le code Redis ordinaire par du code spécifique à SentinelSentinel est utilisé pour moins de commandes Redis. La plupart des commandes ne sont pas prises en charge par le client Sentinel, et Sentinel a certaines fonctions spéciales, qui nécessitent que Sentinel utilise Redis au démarrage. Le code utilisé par le serveur est remplacé par du code spécifique à Sentinel. Pendant cette période, Sentinel chargera une table de commandes différente de celle du serveur Redis ordinaire. Sentinel ne prend pas en charge les commandes telles que SET et DBSIZE ; il conserve la prise en charge de PING, PSUBSCRIBE, SUBSCRIBE, UNSUBSCRIBE, INFO et d'autres commandes fournissent des garanties pour le travail de Sentinel ; 2.3 Initialisation de l'état de SentinelAprès avoir chargé le code unique de Sentinel, Sentinel initialisera la structure sentinelState, qui est utilisée pour stocker les informations d'état liées à Sentinel, dont la plus importante est le dictionnaire maître. struct sentinelState {
//当前纪元,故障转移使用
uint64_t current_epoch;
// Sentinel监视的主服务器信息
// key -> 主服务器名称
// value -> 指向sentinelRedisInstance指针
dict *masters;
// ...
} sentinel;Copier après la connexion 2.4 Initialiser la liste des serveurs maîtres surveillés par SentinelLa liste des serveurs maîtres surveillés par Sentinel est stockée dans le dictionnaire des maîtres de sentinelState Lorsque sentinelState est créé, la liste des serveurs maîtres surveillés par Sentinel commence à être initialisée.
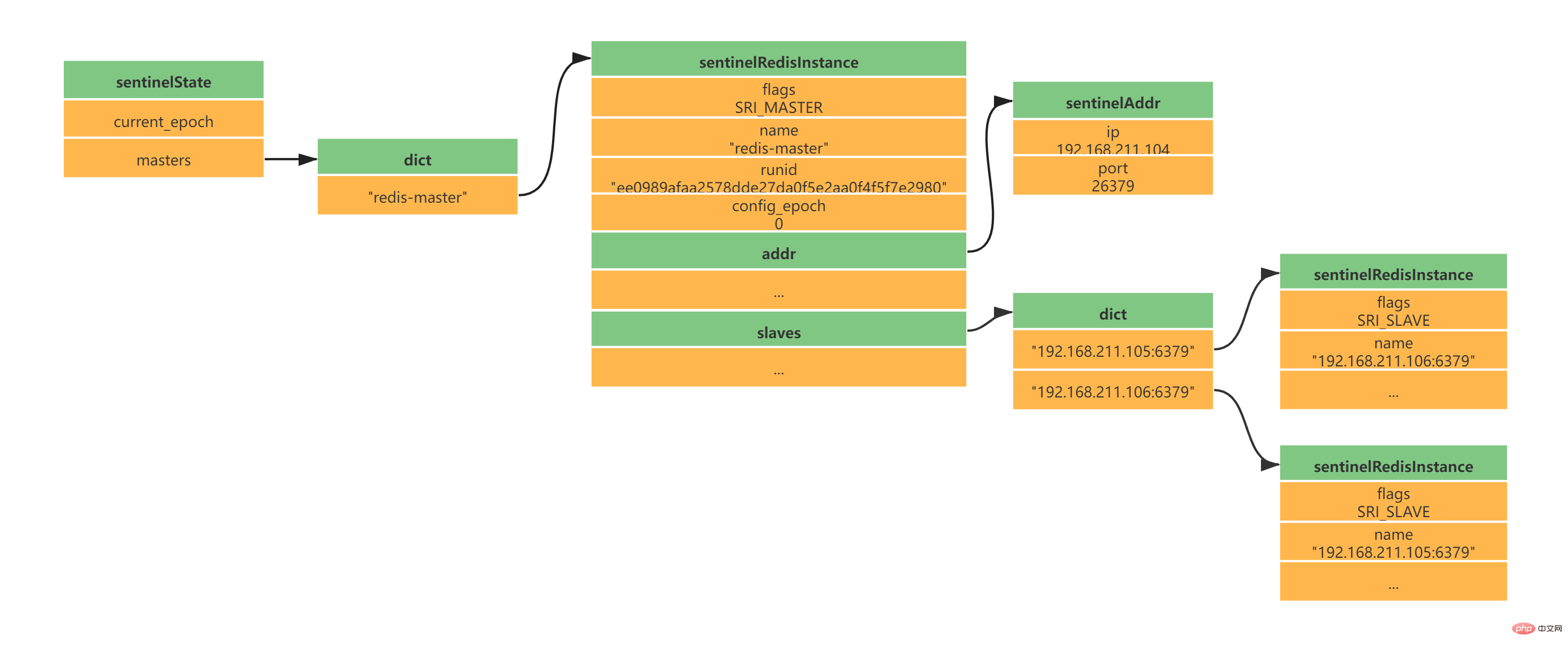
Le nom du serveur principal est spécifié par notre fichier de configuration sentinel.conf Le main. le nom du serveur est redis-master comme suit (voici la configuration d'un maître et de deux esclaves) : daemonize yes port 26379 protected-mode no dir "/usr/local/soft/redis-6.2.4/sentinel-tmp" sentinel monitor redis-master 192.168.211.104 6379 2 sentinel down-after-milliseconds redis-master 30000 sentinel failover-timeout redis-master 180000 sentinel parallel-syncs redis-master 1 Copier après la connexion l'instance sentinelRedisInstance enregistre les informations du serveur Redis (le serveur maître, le serveur esclave et les informations Sentinel sont tous enregistrés dans cette instance ). typedef struct sentinelRedisInstance {
// 标识值,标识当前实例的类型和状态。如SRI_MASTER、SRI_SLVAE、SRI_SENTINEL
int flags;
// 实例名称 主服务器为用户配置实例名称、从服务器和Sentinel为ip:port
char *name;
// 服务器运行ID
char *runid;
//配置纪元,故障转移使用
uint64_t config_epoch;
// 实例地址
sentinelAddr *addr;
// 实例判断为主观下线的时长 sentinel down-after-milliseconds redis-master 30000
mstime_t down_after_period;
// 实例判断为客观下线所需支持的投票数 sentinel monitor redis-master 192.168.211.104 6379 2
int quorum;
// 执行故障转移操作时,可以同时对新的主服务器进行同步的从服务器数量 sentinel parallel-syncs redis-master 1
int parallel-syncs;
// 刷新故障迁移状态的最大时限 sentinel failover-timeout redis-master 180000
mstime_t failover_timeout;
// ...
} sentinelRedisInstance;Copier après la connexion Selon la configuration ci-dessus d'un maître et de deux esclaves, vous obtiendrez la structure d'instance suivante :
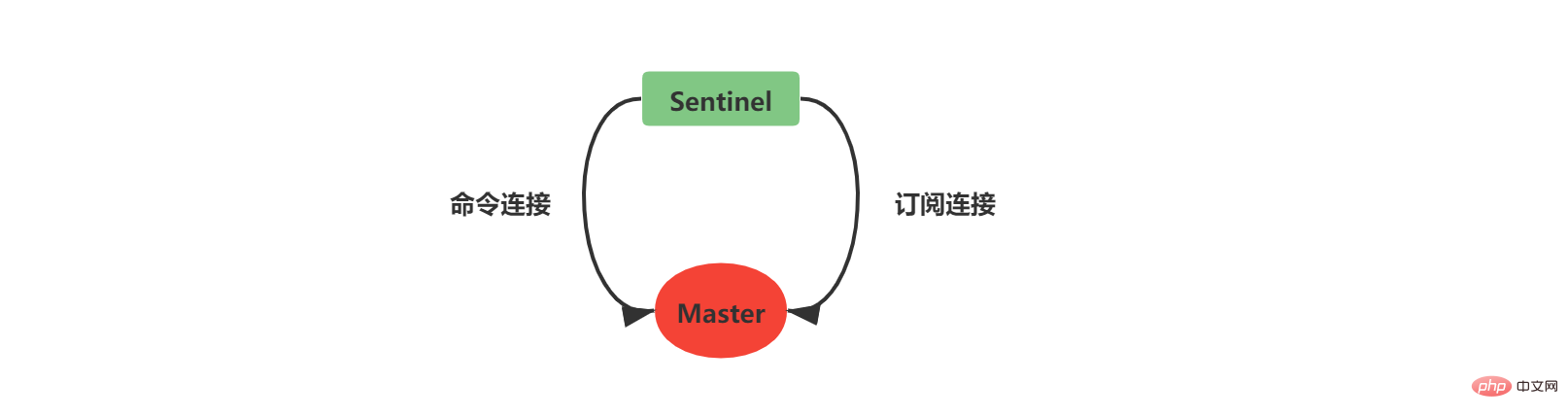
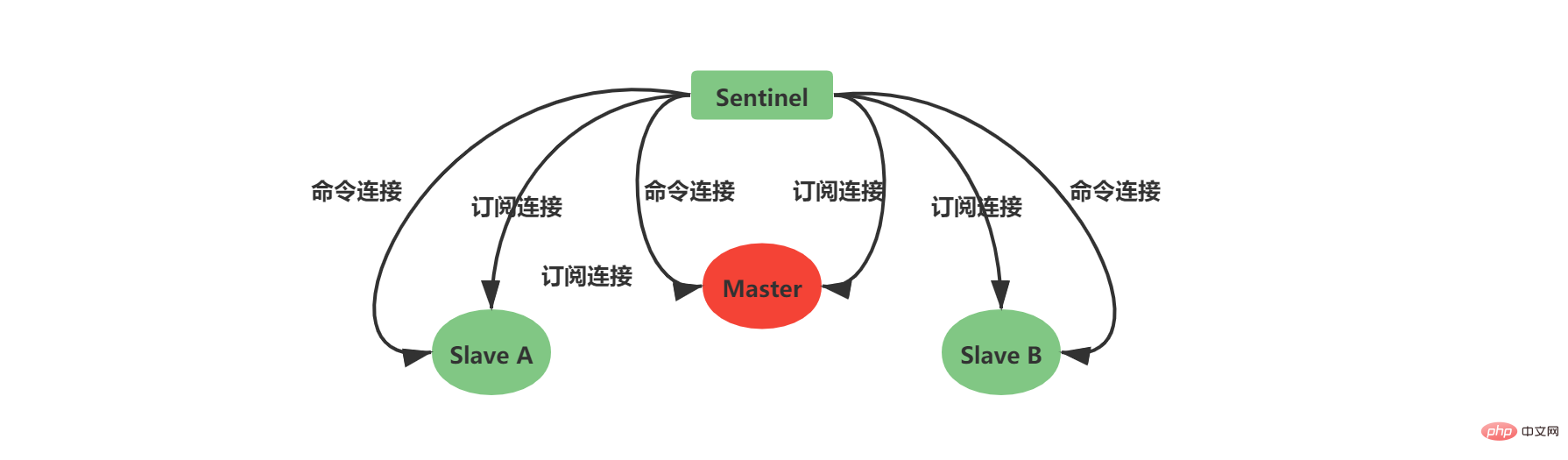
2.5 Créez une connexion réseau au serveur maîtreUne fois la structure d'instance initialisée, Sentinel commencera à créez une connexion réseau avec le Master, dans cette étape Sentinel deviendra le client du Master. Une connexion de commande et une connexion d'abonnement seront créées entre Sentinel et Master :
Sentinel crée un connexion de commande Une fois terminé, une commande INFO est envoyée au Maître toutes les 10 secondes. Deux aspects de la connaissance peuvent être obtenus grâce aux informations de réponse du Maître :
. 2.6 Créer une connexion réseau avec le serveur esclaveObtenez les informations du serveur esclave en fonction du service maître. Sentinel peut créer une connexion réseau avec l'esclave et des connexions d'abonnement seront également créées entre Sentinel et l'esclave.
当Sentinel和Slave之间创建网络连接之后,Sentinel成为了Slave的客户端,Sentinel也会每隔10秒钟通过INFO指令请求Slave获取服务器信息。 到这一步Sentinel获取到了Master和Slave的相关服务器数据。这其中比较重要的信息如下:
此时实例结构信息如下所示:
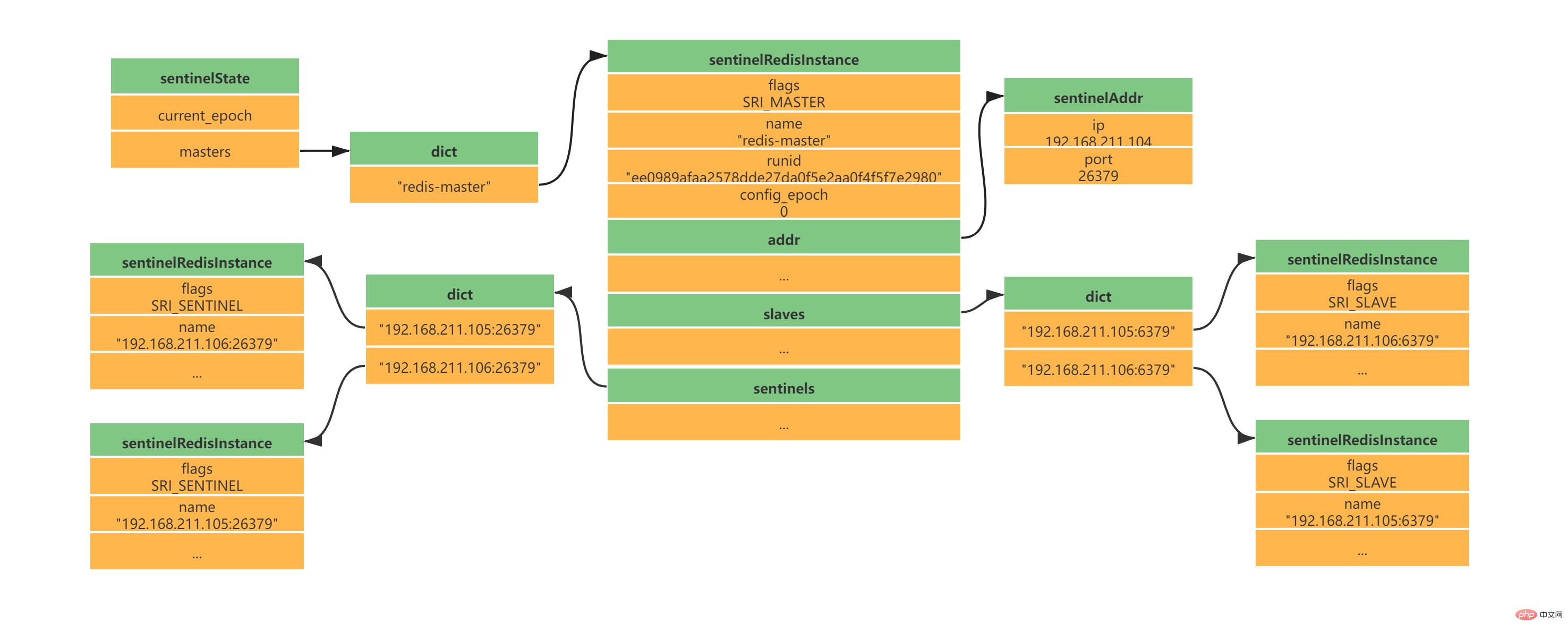
2.7 创建Sentinel之间的网络连接此时是不是还有疑问,Sentinel之间是怎么互相发现对方并且相互通信的,这个就和上面Sentinel与自己监视的主从之间订阅_sentinel_:hello频道有关了。 Sentinel会与自己监视的所有Master和Slave之间订阅_sentinel_:hello频道,并且Sentinel每隔2秒钟向_sentinel_:hello频道发送一条消息,消息内容如下:
其中s代码Sentinel,m代表Master;ip表示IP地址,port表示端口、runid表示运行id、epoch表示配置纪元。 多个Sentinel在配置文件中会配置相同的主服务器ip和端口信息,因此多个Sentinel均会订阅_sentinel_:hello频道,通过频道接收到的信息就可获取到其他Sentinel的ip和port,其中有如下两点需要注意:
Sentinel之间不会创建订阅连接,它们只会创建命令连接:
此时实例结构信息如下所示:
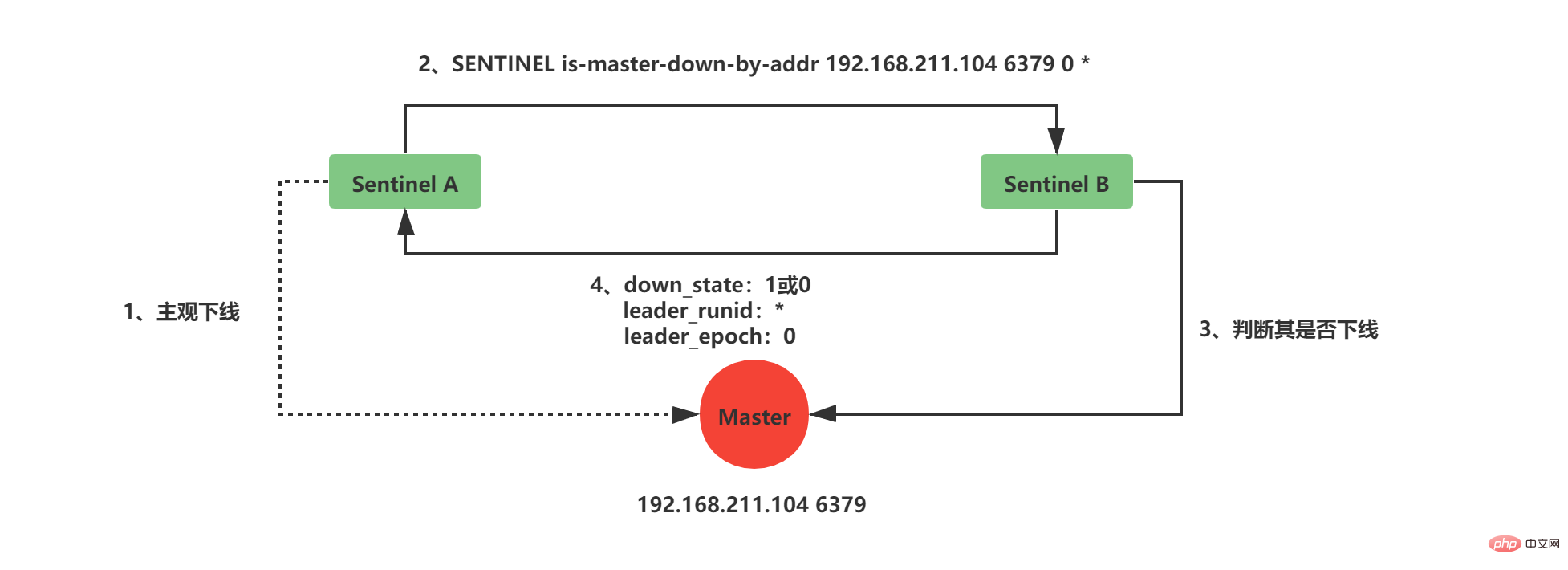
3、Sentinel工作Sentinel最主要的工作就是监视Redis服务器,当Master实例超出预设的时限后切换新的Master实例。这其中有很多细节工作,大致分为检测Master是否主观下线、检测Master是否客观下线、选举领头Sentinel、故障转移四个步骤。 3.1 检测Master是否主观下线Sentinel每隔1秒钟,向sentinelRedisInstance实例中的所有Master、Slave、Sentinel发送PING命令,通过其他服务器的回复来判断其是否仍然在线。 sentinel down-after-milliseconds redis-master 30000 Copier après la connexion 在Sentinel的配置文件中,当Sentinel PING的实例在连续down-after-milliseconds配置的时间内返回无效命令,则当前Sentinel认为其主观下线。Sentinel的配置文件中配置的down-after-milliseconds将会对其sentinelRedisInstance实例中的所有Master、Slave、Sentinel都适应。
如果当前Sentinel检测到Master处于主观下线状态,那么它将会修改其sentinelRedisInstance的flags为SRI_S_DOWN
3.2 检测Master是否客观下线当前Sentinel认为其下线只能处于主观下线状态,要想判断当前Master是否客观下线,还需要询问其他Sentinel,并且所有认为Master主观下线或者客观下线的总和需要达到quorum配置的值,当前Sentinel才会将Master标志为客观下线。
当前Sentinel向sentinelRedisInstance实例中的其他Sentinel发送如下命令: SENTINEL is-master-down-by-addr <ip> <port> <current_epoch> <runid> Copier après la connexion Copier après la connexion
current_epoch和runid均用于Sentinel的选举,Master下线之后,需要选举一个领头Sentinel来选举一个新的Master,current_epoch和runid在其中发挥着重要作用,这个后续讲解。 接收到命令的Sentinel,会根据命令中的参数检查主服务器是否下线,检查完成后会返回如下三个参数:
3.3 选举领头Sentineldown_state返回1,证明接收is-master-down-by-addr命令的Sentinel认为该Master也主观下线了,如果down_state返回1的数量(包括本身)大于等于quorum(配置文件中配置的值),那么Master正式被当前Sentinel标记为客观下线。 此时,Sentinel会再次发送如下指令: SENTINEL is-master-down-by-addr <ip> <port> <current_epoch> <runid> Copier après la connexion Copier après la connexion 此时的runid将不再是0,而是Sentinel自己的运行id(runid)的值,表示当前Sentinel希望接收到is-master-down-by-addr命令的其他Sentinel将其设置为领头Sentinel。这个设置是先到先得的,Sentinel先接收到谁的设置请求,就将谁设置为领头Sentinel。 发送命令的Sentinel会根据其他Sentinel回复的结果来判断自己是否被该Sentinel设置为领头Sentinel,如果Sentinel被其他Sentinel设置为领头Sentinel的数量超过半数Sentinel(这个数量在sentinelRedisInstance的sentinel字典中可以获取),那么Sentinel会认为自己已经成为领头Sentinel,并开始后续故障转移工作(由于需要半数,且每个Sentinel只会设置一个领头Sentinel,那么只会出现一个领头Sentinel,如果没有一个达到领头Sentinel的要求,Sentinel将会重新选举直到领头Sentinel产生为止)。 3.4 故障转移故障转移将会交给领头sentinel全权负责,领头sentinel需要做如下事情:
这其中最难的一步是如果选择最佳的新Master,领头Sentinel会做如下清洗和排序工作:
新的Master产生后,领头sentinel会向已下线主服务器的其他从服务器(不包括新Master)发送SLAVEOF ip port命令,使其成为新master的slave。 到这里Sentinel的的工作流程就算是结束了,如果新master下线,则循环流程即可! 三、集群1、简介Redis集群是Redis提供的分布式数据库方案,集群通过分片(sharding)进行数据共享,Redis集群主要实现了以下目标:
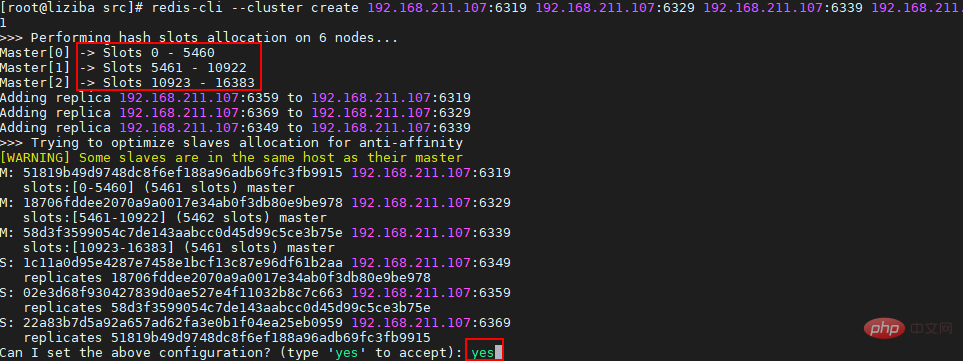
Concernant l'apprentissage du cluster Redis, si vous n'avez aucune expérience, il est recommandé de lire ces trois articles (série chinoise) : Tutoriel cluster Redis
Spécification du cluster Redis
Déploiement du pseudo-cluster esclave Redis3 maître 3
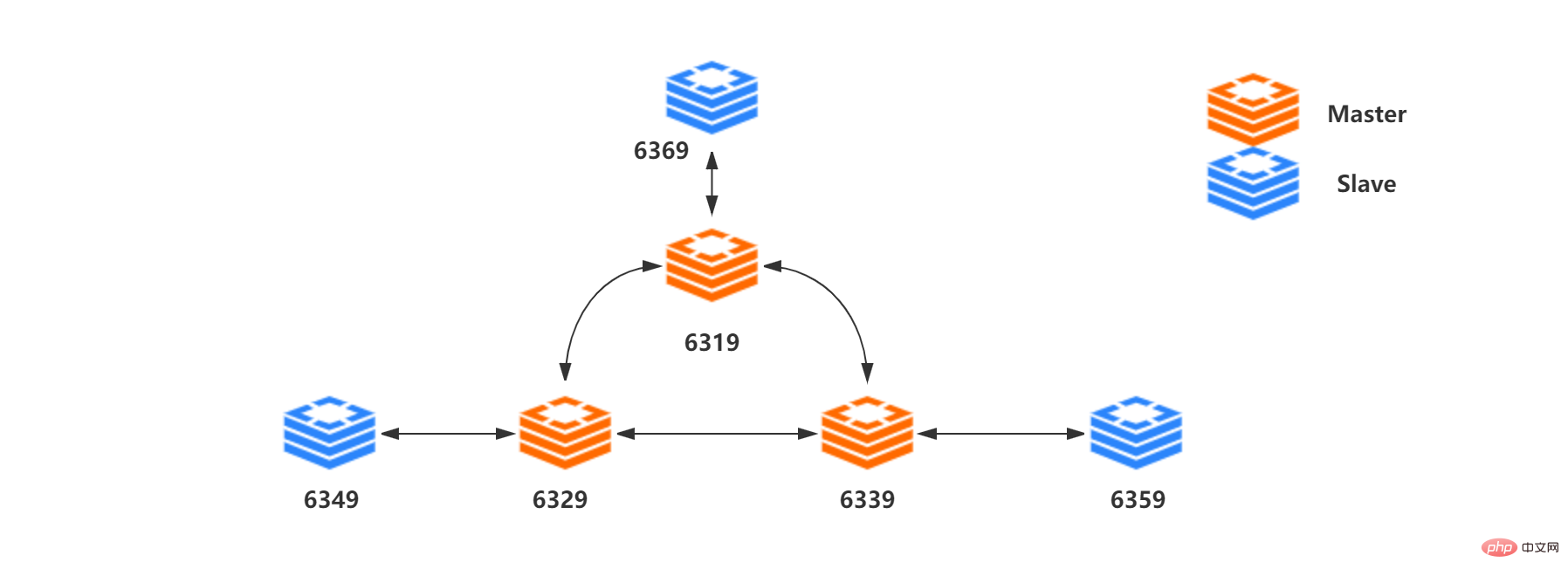
Le contenu suivant s'appuie sur la structure à trois maîtres et trois esclaves du figure ci-dessous :
Liste des ressources :
Vous présente la réplication maître-esclave, Sentinel et le clustering dans Redis. 2、集群内部Redis 集群没有使用一致性hash, 而是引入了 哈希槽的概念。Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽,这种结构很容易添加或者删除节点。集群的每个节点负责一部分hash槽,比如上面资源清单的集群有3个节点,其槽分配如下所示:
深入学习Redis集群之前,需要了解集群中Redis实例的内部结构。当某个Redis服务节点通过cluster_enabled配置为yes开启集群模式之后,Redis服务节点不仅会继续使用单机模式下的服务器组件,还会增加custerState、clusterNode、custerLink等结构用于存储集群模式下的特殊数据。 如下三个数据承载对象一定要认真看,尤其是结构中的注释,看完之后集群大体上怎么工作的,心里就有数了,嘿嘿嘿; 2.1 clsuterNodeclsuterNode用于存储节点信息,比如节点的名字、IP地址、端口信息和配置纪元等等,以下代码列出部分非常重要的属性: typedef struct clsuterNode {
// 创建时间
mstime_t ctime;
// 节点名字,由40位随机16进制的字符组成(与sentinel中讲的服务器运行id相同)
char name[REDIS_CLUSTER_NAMELEN];
// 节点标识,可以标识节点的角色和状态
// 角色 -> 主节点或从节点 例如:REDIS_NODE_MASTER(主节点) REDIS_NODE_SLAVE(从节点)
// 状态 -> 在线或下线 例如:REDIS_NODE_PFAIL(疑似下线) REDIS_NODE_FAIL(下线)
int flags;
// 节点配置纪元,用于故障转移,与sentinel中用法类似
// clusterState中的代表集群的配置纪元
unit64_t configEpoch;
// 节点IP地址
char ip[REDIS_IP_STR_LEN];
// 节点端口
int port;
// 连接节点的信息
clusterLink *link;
// 一个2048字节的二进制位数组
// 位数组索引值可能为0或1
// 数组索引i位置值为0,代表节点不负责处理槽i
// 数组索引i位置值为1,代表节点负责处理槽i
unsigned char slots[16384/8];
// 记录当前节点处理槽的数量总和
int numslots;
// 如果当前节点是从节点
// 指向当前从节点的主节点
struct clusterNode *slaveof;
// 如果当前节点是主节点
// 正在复制当前主节点的从节点数量
int numslaves;
// 数组——记录正在复制当前主节点的所有从节点
struct clusterNode **slaves;
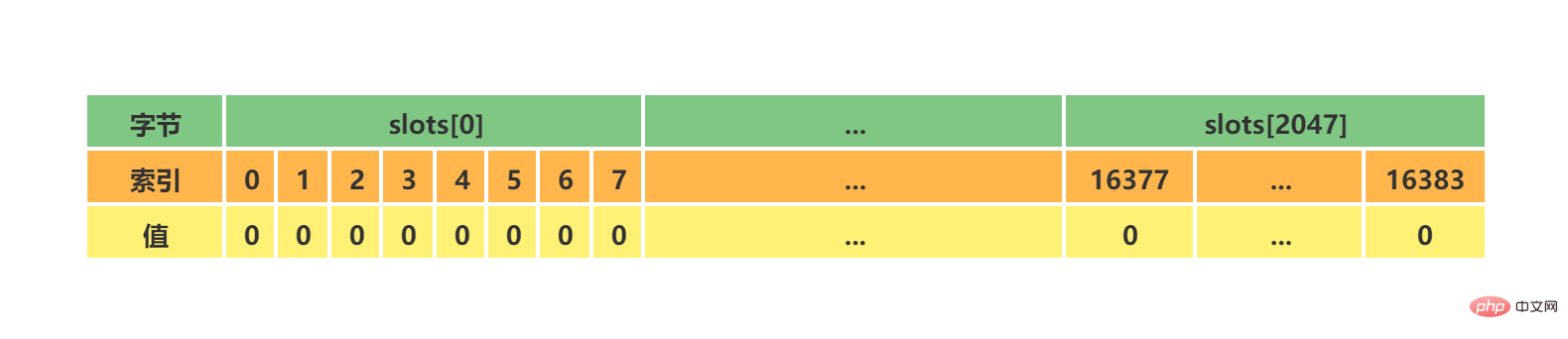
} clsuterNode;Copier après la connexion 上述代码中可能不太好理解的是slots[16384/8],其实可以简单的理解为一个16384大小的数组,数组索引下标处如果为1表示当前槽属于当前clusterNode处理,如果为0表示不属于当前clusterNode处理。clusterNode能够通过slots来识别,当前节点处理负责处理哪些槽。 初始clsuterNode或者未分配槽的集群中的clsuterNode的slots如下所示:
假设集群如上面我给出的资源清单,此时代表Master[0]的clusterNode的slots如下所示:
2.2 clusterLinkclusterLink是clsuterNode中的一个属性,用于存储连接节点所需的相关信息,比如套接字描述符、输入输出缓冲区等待,以下代码列出部分非常重要的属性: typedef struct clusterState {
// 连接创建时间
mstime_t ctime;
// TCP 套接字描述符
int fd;
// 输出缓冲区,需要发送给其他节点的消息缓存在这里
sds sndbuf;
// 输入缓冲区,接收打其他节点的消息缓存在这里
sds rcvbuf;
// 与当前clsuterNode节点代表的节点建立连接的其他节点保存在这里
struct clusterNode *node;
} clusterState;Copier après la connexion 2.3 custerState每个节点都会有一个custerState结构,这个结构中存储了当前集群的全部数据,比如集群状态、集群中的所有节点信息(主节点、从节点)等等,以下代码列出部分非常重要的属性: typedef struct clusterState {
// 当前节点指针,指向一个clusterNode
clusterNode *myself;
// 集群当前配置纪元,用于故障转移,与sentinel中用法类似
unit64_t currentEpoch;
// 集群状态 在线/下线
int state;
// 集群中处理着槽的节点数量总和
int size;
// 集群节点字典,所有clusterNode包括自己
dict *node;
// 集群中所有槽的指派信息
clsuterNode *slots[16384];
// 用于槽的重新分配——记录当前节点正在从其他节点导入的槽
clusterNode *importing_slots_from[16384];
// 用于槽的重新分配——记录当前节点正在迁移至其他节点的槽
clusterNode *migrating_slots_to[16384];
// ...
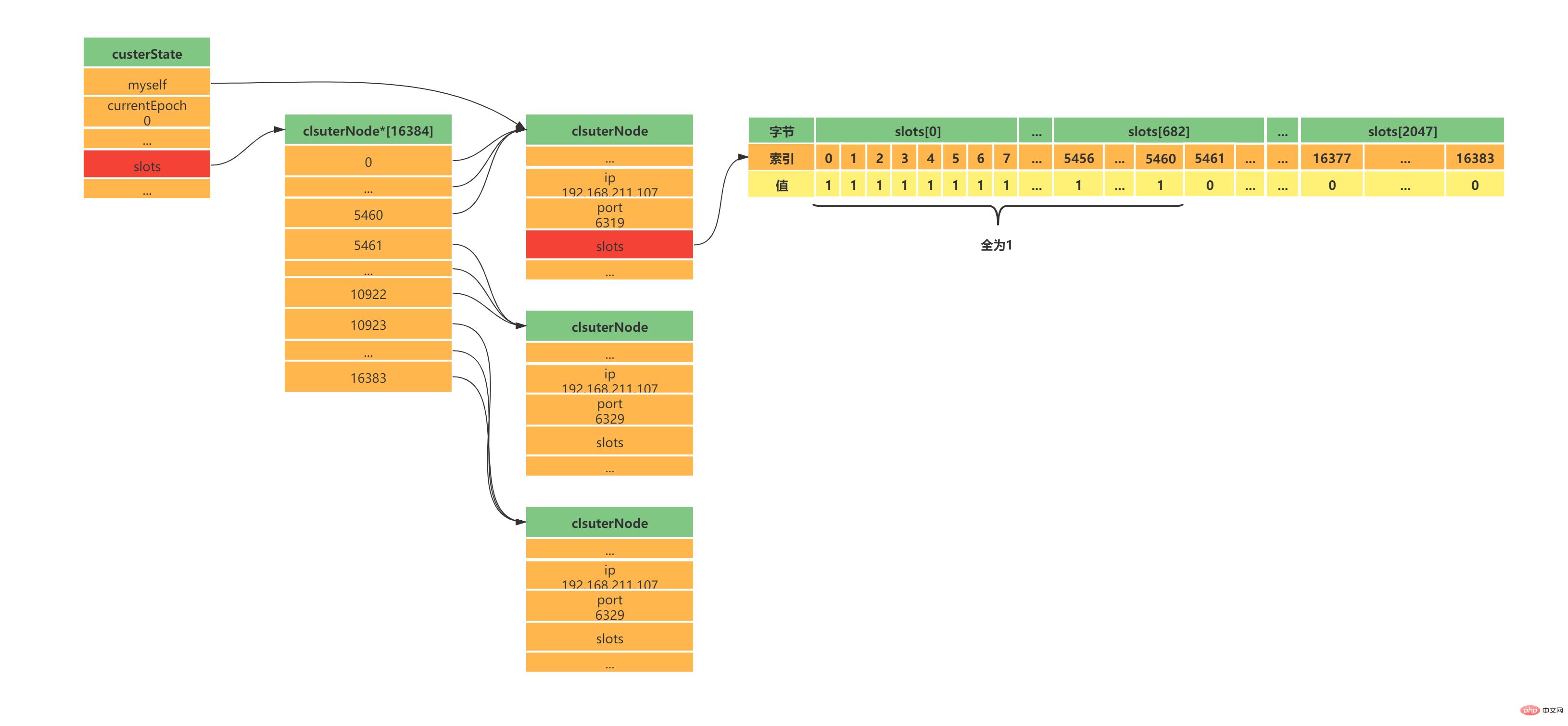
} clusterState;Copier après la connexion 在custerState有三个结构需要认真了解的,第一个是slots数组,clusterState中的slots数组与clsuterNode中的slots数组是不一样的,在clusterNode中slots数组记录的是当前clusterNode所负责的槽,而clusterState中的slots数组记录的是整个集群的每个槽由哪个clsuterNode负责,因此集群正常工作的时候clusterState的slots数组每个索引指向负责该槽的clusterNode,集群槽未分配之前指向null。 如图展示资源清单中的集群clusterState中的slots数组与clsuterNode中的slots数组:
Redis集群中使用两个slots数组的原因是出于性能的考虑:
第二个需要认真了解的结构是node字典,该结构虽然简单,但是node字典中存储了所有的clusterNode,这也是Redis集群中的单个节点获取其他主节点、从节点信息的主要位置,因此我们也需要注意一下。 第三个需要认真了解的结构是importing_slots_from[16384]数组和migrating_slots_to[16384],这两个数组在集群重新分片时需要使用,需要重点了解,后面再说吧,这里说的话顺序不太对。 3. Travail en cluster3.1 Comment attribuer des créneaux ?Le cluster Redis dispose d'un total de 16384 emplacements. Comme le montre la liste des ressources ci-dessus, nous sommes dans un cluster avec trois maîtres et trois esclaves. Chaque nœud maître est responsable de son propre emplacement correspondant. Je l'ai spécifié lors du processus de déploiement des trois maîtres et des trois esclaves ci-dessus. L'emplacement est attribué au nœud maître correspondant, car le cluster Redis lui-même a divisé les emplacements pour nous en interne. Mais si nous voulons attribuer l'emplacement nous-mêmes. , comment devrions-nous l'organiser? Nous pouvons envoyer la commande suivante au nœud pour attribuer un ou plusieurs slots au nœud actuel :
Par exemple, si nous voulons attribuer les slots 0 et 1 au Master[0], nous il faut penser au Maître [0] Le nœud peut envoyer la commande suivante :
Lorsque le nœud se voit attribuer un emplacement, le tableau d'emplacements du clusterNode sera mis à jour et le nœud sera mis à jour les slots dont il est responsable du traitement, qui est le tableau slots. Le message est envoyé aux autres nœuds du cluster. Après avoir reçu le message, les autres nœuds mettront à jour le tableau slots du clusterNode correspondant et le tableau solts du clusterState. 3.2 Comment ADDSLOTS est-il implémenté au sein du cluster Redis ?C'est en fait relativement simple. Lorsque nous envoyons la commande CLUSTER ADDSLOTS à un nœud du cluster Redis, le nœud actuel confirmera d'abord si les emplacements attribués au nœud actuel ne sont pas attribués à d'autres nœuds via le tableau d'emplacements dans clusterState. Si elle a été attribuée, une exception sera levée directement et l'erreur sera renvoyée au client attribué. Si tous les emplacements attribués au nœud actuel ne sont pas attribués à d'autres nœuds, le nœud actuel s'attribue ces emplacements. Il y a trois étapes principales pour l'affectation :
3.3 Il y a tellement de nœuds dans le cluster, comment le client sait-il quel nœud demander ?Avant de comprendre ce problème, vous devez d'abord connaître un point. Comment le cluster Redis calcule-t-il à quel emplacement appartient la clé actuelle ? Selon le site officiel, Redis n'utilise pas réellement d'algorithme de hachage cohérent. Au lieu de cela, chaque clé demandée est vérifiée par CRC16, puis le modulo 16384 est utilisé pour déterminer dans quel emplacement la placer. A ce moment, lorsque le client se connecte pour envoyer une requête à un nœud, le nœud recevant actuellement la commande calculera d'abord l'emplacement i auquel la clé actuelle appartient via un algorithme, après le calcul, le nœud actuel déterminera si le slot i du clusterState est responsable de lui-même. S'il en est responsable, le nœud actuel répondra à la demande du client. pour le nœud actuel, il passera par les étapes suivantes :
CLUSTER 用于槽分配的指令主要有如上这些,ADDSLOTS 和DELSLOTS主要用于槽的快速指派和快速删除,通常我们在集群刚刚建立的时候进行快速分配的时候才使用。CLUSTER SETSLOT slot NODE node也用于直接给指定的节点指派槽。如果集群已经建立我们通常使用最后两个来重分配,其代表的含义如下所示:
上面这两句话是不是感觉不太看的懂,这是官方的描述,不太懂的话我来给你通俗的描述,整个流程大致如下步骤:
3.5 如果客户端访问的key所属的槽正在迁移怎么办?优秀的你总会想到这种并发情况,牛皮呀!大佬们!
这个问题官方也考虑了,还记得我们在聊clusterState结构的时候么?importing_slots_from和migrating_slots_to就是用来处理这个问题的。 typedef struct clusterState {
// ...
// 用于槽的重新分配——记录当前节点正在从其他节点导入的槽
clusterNode *importing_slots_from[16384];
// 用于槽的重新分配——记录当前节点正在迁移至其他节点的槽
clusterNode *migrating_slots_to[16384];
// ...
} clusterState;Copier après la connexion
有了上述两个相互数组,就能判断当前槽是否在迁移了,而且从哪里迁移来,要迁移到哪里去?搞笑不就是这么简单…… 此时,回到问题中,如果客户端请求的key刚好属于正在迁移的槽。那么接收到命令的节点首先会尝试在自己的数据库中查找键key,如果这个槽还没迁移完成,且当前key刚好也还没迁移完成,那就直接响应客户端的请求就行。如果该key已经不在了,此时节点会去查询migrating_slots_to数组对应的索引槽,如果索引处的值不为null,而是指向了某个clusterNode结构,那说明这个key已经被迁移到这个clusterNode了。这个时候节点不会继续在处理指令,而是返回ASKING命令,这个命令也会携带导入槽clusterNode对应的ip和port。客户端在接收到ASKING命令之后就需要将请求转向正确的节点了,不过这里有一点需要注意的地方**(因此我放个表情包在这里,方便读者注意)。**
Comme mentionné précédemment, lorsqu'un nœud constate que l'emplacement actuel n'appartient pas à son propre traitement, il renvoie l'instruction MOVED. Alors, comment gère-t-il l'emplacement en cours de migration ? C'est à cela que sert ce cluster Redis. Lorsque le nœud découvre que l'emplacement est en cours de migration, il renvoie la commande ASKING au client. Le client recevra la commande ASKING, qui contient l'adresse IP du nœud et le port du clusterNode vers lequel l'emplacement est en cours de migration. Ensuite, le client enverra d'abord une commande ASKING au clusterNode migrant. Le but de cette commande doit être d'indiquer au nœud actuel que vous devez faire une exception pour gérer cette demande, car cet emplacement a été migré vers vous et vous ne pouvez pas. rejetez-moi directement (par conséquent, si Redis ne reçoit pas la commande ASKING, il interrogera directement le clusterState du nœud, et l'emplacement en cours de migration n'a pas été mis à jour vers le clusterState, il ne peut donc renvoyer directement MOVED, qui continuera à boucler plusieurs fois...), reçu Le nœud avec la commande ASKING exécutera de force cette requête une fois (une seule fois, et vous devrez renvoyer la commande ASKING à l'avance la prochaine fois). 4. Échec du clusterL'échec du cluster Redis est en fait similaire à celui de Sentinel lorsque le nœud maître tombe en panne ou ne répond pas dans le délai maximum spécifié et qu'un nouveau nœud maître est réélu. les nœuds esclaves. Bien sûr, le principe est que pour chaque nœud maître du cluster Redis, nous avons configuré le nœud esclave à l'avance, sinon cela ne servira à rien... Les étapes générales sont les suivantes :
Ou vous pouvez lire le livre "Redis Design and Implementation" écrit par Huang Jianhong. Ce livre est très bon, et j'ai aussi fait référence à un. beaucoup de contenu. Pour plus de connaissances sur la programmation, veuillez visiter :Vidéos de programmation ! ! |






Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Le mode Redis Cluster déploie les instances Redis sur plusieurs serveurs grâce à la rupture, à l'amélioration de l'évolutivité et de la disponibilité. Les étapes de construction sont les suivantes: Créez des instances de redis étranges avec différents ports; Créer 3 instances Sentinel, Moniteur Redis Instances et basculement; Configurer les fichiers de configuration Sentinel, ajouter des informations d'instance Redis de surveillance et des paramètres de basculement; Configurer les fichiers de configuration d'instance Redis, activer le mode de cluster et spécifier le chemin du fichier d'informations de cluster; Créer un fichier nœuds.conf, contenant des informations de chaque instance redis; Démarrez le cluster, exécutez la commande CREATE pour créer un cluster et spécifiez le nombre de répliques; Connectez-vous au cluster pour exécuter la commande d'informations de cluster pour vérifier l'état du cluster; faire
 Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données Redis: utilisez la commande flushall pour effacer toutes les valeurs de clé. Utilisez la commande flushdb pour effacer la valeur clé de la base de données actuellement sélectionnée. Utilisez SELECT pour commuter les bases de données, puis utilisez FlushDB pour effacer plusieurs bases de données. Utilisez la commande del pour supprimer une clé spécifique. Utilisez l'outil Redis-CLI pour effacer les données.
 Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Pour lire une file d'attente à partir de Redis, vous devez obtenir le nom de la file d'attente, lire les éléments à l'aide de la commande LPOP et traiter la file d'attente vide. Les étapes spécifiques sont les suivantes: Obtenez le nom de la file d'attente: Nommez-le avec le préfixe de "Fitre:" tel que "Fitre: My-Quyue". Utilisez la commande LPOP: éjectez l'élément de la tête de la file d'attente et renvoyez sa valeur, telle que la file d'attente LPOP: My-Queue. Traitement des files d'attente vides: si la file d'attente est vide, LPOP renvoie NIL et vous pouvez vérifier si la file d'attente existe avant de lire l'élément.
 Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
L'utilisation de la directive Redis nécessite les étapes suivantes: Ouvrez le client Redis. Entrez la commande (Verbe Key Value). Fournit les paramètres requis (varie de l'instruction à l'instruction). Appuyez sur Entrée pour exécuter la commande. Redis renvoie une réponse indiquant le résultat de l'opération (généralement OK ou -err).
 Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
L'utilisation des opérations Redis pour verrouiller nécessite l'obtention du verrouillage via la commande setnx, puis en utilisant la commande Expire pour définir le temps d'expiration. Les étapes spécifiques sont les suivantes: (1) Utilisez la commande setnx pour essayer de définir une paire de valeurs de clé; (2) Utilisez la commande Expire pour définir le temps d'expiration du verrou; (3) Utilisez la commande del pour supprimer le verrouillage lorsque le verrouillage n'est plus nécessaire.
 Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
La meilleure façon de comprendre le code source redis est d'aller étape par étape: familiarisez-vous avec les bases de Redis. Sélectionnez un module ou une fonction spécifique comme point de départ. Commencez par le point d'entrée du module ou de la fonction et affichez le code ligne par ligne. Affichez le code via la chaîne d'appel de fonction. Familiez les structures de données sous-jacentes utilisées par Redis. Identifiez l'algorithme utilisé par Redis.
 Comment utiliser la ligne de commande redis
Apr 10, 2025 pm 10:18 PM
Comment utiliser la ligne de commande redis
Apr 10, 2025 pm 10:18 PM
Utilisez l'outil de ligne de commande redis (Redis-CLI) pour gérer et utiliser Redis via les étapes suivantes: Connectez-vous au serveur, spécifiez l'adresse et le port. Envoyez des commandes au serveur à l'aide du nom et des paramètres de commande. Utilisez la commande d'aide pour afficher les informations d'aide pour une commande spécifique. Utilisez la commande QUIT pour quitter l'outil de ligne de commande.
 Comment configurer le temps d'exécution du script LUA dans Centos Redis
Apr 14, 2025 pm 02:12 PM
Comment configurer le temps d'exécution du script LUA dans Centos Redis
Apr 14, 2025 pm 02:12 PM
Sur CentOS Systems, vous pouvez limiter le temps d'exécution des scripts LUA en modifiant les fichiers de configuration Redis ou en utilisant des commandes Redis pour empêcher les scripts malveillants de consommer trop de ressources. Méthode 1: Modifiez le fichier de configuration Redis et localisez le fichier de configuration Redis: le fichier de configuration redis est généralement situé dans /etc/redis/redis.conf. Edit Fichier de configuration: Ouvrez le fichier de configuration à l'aide d'un éditeur de texte (tel que VI ou NANO): Sudovi / etc / redis / redis.conf Définissez le délai d'exécution du script LUA: Ajouter ou modifier les lignes suivantes dans le fichier de configuration pour définir le temps d'exécution maximal du script LUA (unité: millisecondes)
