
 base de données
tutoriel mysql
Partage très apprécié : idées d'optimisation MySQL adaptées à la production
base de données
tutoriel mysql
Partage très apprécié : idées d'optimisation MySQL adaptées à la production
Partage très apprécié : idées d'optimisation MySQL adaptées à la production

Avant-propos
Le point de départ de la rédaction de cet article est d'enregistrer mon expérience accumulée dans le traitement des données au travail, au fur et à mesure que j'écris, je constate que chaque point dérivera d'autres connaissances de base, comme la nécessité d'optimisation lors de l'optimisation. l'index. Avoir une certaine compréhension des requêtes lentes, Explain et autres fonctions associées. Par exemple, l'introduction d'Elasticsearch nécessite de résoudre la synchronisation des données, d'acquérir les connaissances d'Elasticsearch, etc. En raison de la longueur de l'article, il est impossible d'expliquer chaque point en détail. comme un didacticiel vidéo, je peux seulement résumer quelques points généraux basés sur mes connaissances limitées. Même ainsi, la longueur de l'article est déjà très longue. Si un certain point vous intéresse, veuillez vous rendre sur Baidu/Google pour une connaissance approfondie de certains détails.
L’article est assez long, donc si vous êtes intéressé, vous voudrez peut-être le lire entièrement. J’espère que vous n’avez pas perdu des dizaines de minutes. [Apprentissage recommandé : "Tutoriel vidéo mysql"]
Perspective de réflexion
La technologie des bases de données est jusqu'à présent passée par l'étape de gestion manuelle, l'étape du système de fichiers et l'étape du système de base de données.
Au début, lorsqu'il n'y avait pas de système logiciel, il était possible de gérer une certaine entreprise dans le monde réel grâce à l'étape de gestion manuelle de la comptabilité manuelle et de l'accord verbal. Ce formulaire existe depuis longtemps et est relativement inefficace. solution. . Dans l'étape suivante, avec le développement de la technologie informatique, il y a eu une étape de système de fichiers qui a remplacé la comptabilité manuelle par des tableaux Excel, ce qui a amélioré dans une certaine mesure la productivité. Au stade du système logiciel, qui est un système de base de données avec un fonctionnement simple et une efficacité élevée, la productivité a encore été améliorée, les problèmes spécifiques du monde réel sont résumés en données et les activités du monde réel sont représentées à travers le flux et la modification des données. Dans les systèmes logiciels, le stockage de données est généralement composé d'une base de données relationnelle et de plusieurs bases de données non relationnelles.
La base de données est fortement liée à l'activité du système. Cela nécessite que le chef de produit comprenne le processus de stockage et d'interrogation des données lors de la conception de l'entreprise, il est clair quel impact le changement commercial aura sur la base de données. et si de nouvelles références doivent être référencées. Par exemple, une entreprise conçue par le chef de produit consiste à effectuer une analyse statistique et un résumé des données sur plusieurs tables MySQL avec un volume de plusieurs millions de tables. Si une requête multi-tables MySQL est directement utilisée, des requêtes lentes se produiront certainement et provoqueront le msyql. le service doit baisser. Dans ce cas, la solution est soit de faire un compromis du côté du produit, soit de changer la pile technologique.
Dans l'architecture du système et la solution de base de données, nous devons choisir celle qui est la plus adaptée aux capacités de l'équipe de l'entreprise. Au début du système, une simple optimisation de la base de données avec des capacités de billets de banque sera la solution la plus rentable. Lorsque vous rencontrez la capacité des billets de banque de la base de données MySQL et que vous ne pouvez rien faire, l'introduction des services logiciels clés avec des fonctions de base deviendra la solution la plus rentable. Comment choisir la solution appropriée lorsque vous rencontrez des problèmes est le moment de refléter votre valeur.
Un pauvre garçon tombe amoureux d'une fille riche. La douceur à court terme n'est pas à la hauteur de la véritable inégalité de classe. La fin heureuse n'existe que dans le fantasme du pauvre garçon et dans la série télévisée du professeur Qiong Yao.
Comment améliorer les performances du stockage de données à un coût limité est l'idée centrale de cet article.
Connaissances de base
Je pense que tout le monde entrera souvent en contact avec le contenu suivant dans son travail quotidien. Permettez-moi de le résumer brièvement.
Base de données relationnelle
La base de données relationnelle est une organisation de données composée de tables bidimensionnelles et des connexions entre elles. Elle fournit des fonctions telles que la cohérence des données de transaction et la persistance des données pour le logiciel et constitue le stockage de base du système logiciel. Les services sont les bases de données avec lesquelles nous sommes le plus souvent en contact lors du développement et des entretiens. Pour certains petits projets d'externalisation, un MySQL suffit à répondre à tous les besoins de l'entreprise. C'est quelque chose avec lequel nous sommes souvent en contact, et qui regorge en fait de secrets. Nous discuterons des secrets en détail dans les chapitres suivants.
Avantages :
- Transactions
- Persistance
- Langage SQL relativement courant
Problèmes
- Exigences très élevées en matière d'E/S du disque dur
- La requête d'agrégation d'un grand volume de données est inefficace
- Manque d'index
- Le principe de correspondance de l'index le plus à gauche rend inappropriée la récupération de texte intégral
- Une mauvaise utilisation des transactions peut provoquer un verrouillage congestion
- Niveau Divers problèmes causés par l'expansion sont difficiles à gérer
Base de données non relationnelle - NoSql
En tant que logiciel de stockage de données relationnelles, la base de données MySQL présente des avantages et des inconvénients évidents, donc la quantité de données dans le logiciel Le système est généralement en constante augmentation.Lorsque l'expansion et la complexité de l'entreprise continuent d'augmenter, nous ne pouvons pas espérer résoudre tous les problèmes en améliorant les capacités de la base de données MySQL. Au lieu de cela, nous devons introduire d'autres logiciels de stockage et utiliser divers types de NoSQL pour résoudre le problème continu. expansion du volume de données du système logiciel et de la complexité de l'entreprise. Il n'y a aucun problème de promotion.
La base de données relationnelle est une optimisation de la base de données relationnelle dans différents scénarios. Cela ne signifie pas que tout ira bien si vous introduisez une sorte de NoSQL. Cela signifie que vous devez bien comprendre les types et les difficultés d'application de NoSQL sur le marché et choisir le bon. un logiciel de stockage approprié dans le scénario approprié est la bonne chose à faire.
Type de valeur-clé
En entreprise, le contenu de certaines tables est souvent interrogé, mais la plupart des résultats de la requête sont inchangés, donc des valeurs-clés telles que Memcached et Redis ont émergé. Logiciel de stockage, module de cache. largement utilisé dans les systèmes. Redis a plus de structures de données et de persistance que Memcached, ce qui en fait le NoSQL de type KV le plus largement utilisé.
Type de recherche
Dans le scénario de recherche en texte intégral, l'optimisation des requêtes de l'index arborescent MySQLB+, comme une requête ne peut pas atteindre l'index, est une analyse de table complète dans une table contenant des dizaines de milliers de données. Cela reste supportable, mais des requêtes lentes se produiront lorsque les données sont stockées. Si le code métier n'est pas bien écrit et qu'une requête Like est appelée dans une transaction, un verrou en lecture se produira. ElasticSearch, avec l'index inversé comme noyau, peut parfaitement répondre au scénario de recherche en texte intégral. Dans le même temps, ElasticSearch prend également en charge très bien les données massives, et la documentation et l'écologie sont également très bonnes.
Type de document
Le type de document NoSql fait référence à un type de NoSql qui stocke des données semi-structurées sous forme de documents. Le type de document NoSql stocke généralement les données au format JSON ou XML, le type de document NoSql n'a donc pas de schéma en raison du. Grâce aux caractéristiques de Schema, nous pouvons stocker et lire des données à volonté. Par conséquent, l'émergence de NoSql basé sur des documents résout le problème de l'expansion gênante des structures de tables de bases de données relationnelles. L'auteur n'a jamais utilisé de
formule de colonnes
Pour les entreprises d'une certaine taille, les affaires impliquent souvent une synthèse de données flexible en temps réel. Ce type d'affaires ne peut pas être résolu par des solutions de pré-calcul, même si. Il peut L'entreprise a été écrite à l'aide d'un plan pour calculer et résumer à l'avance, mais à mesure que la quantité de données résumées augmente, l'étape finale d'accumulation des données résumées deviendra progressivement très lente. Le NoSql en colonnes est le produit de ce scénario. est l'une des technologies les plus représentatives de l'ère du big data. La plus courante est HBase, mais l'application de HBase est très lourde et nécessite souvent un ensemble complet d'écosystème Hadoop pour fonctionner. La société de l'auteur utilise AnalyticDB d'Alibaba Cloud. compatible avec les requêtes MySQL. Logiciel de stockage de colonnes pour les instructions. Les puissantes capacités de requête du logiciel de stockage de résumé + colonne sont suffisantes pour prendre en charge divers services de résumé de données flexibles en temps réel.
Cas
En prenant 2021 comme point temporel, la plupart des systèmes commencent avec le plan suivant dans les premières étapes. Ensuite, je ferai lentement quelques ajustements dans ce cas.

Les avantages apportés par les mises à niveau matérielles diminuent avec le temps. Il s'agit de la solution d'optimisation la plus rapide lorsque le temps et le personnel manquent. Les avantages apportés par l'optimisation logicielle sont plus élevés à l'avenir, mais le niveau de personnel technique requis est également plus élevé à l'avenir. Lorsque le temps et le personnel le permettent, il s'agit de la solution d'optimisation la plus rentable. L'optimisation matérielle et logicielle ne s'exclut pas mutuellement. Lorsque cela est nécessaire, les deux peuvent approcher la limite supérieure des performances MYSQL en même temps.
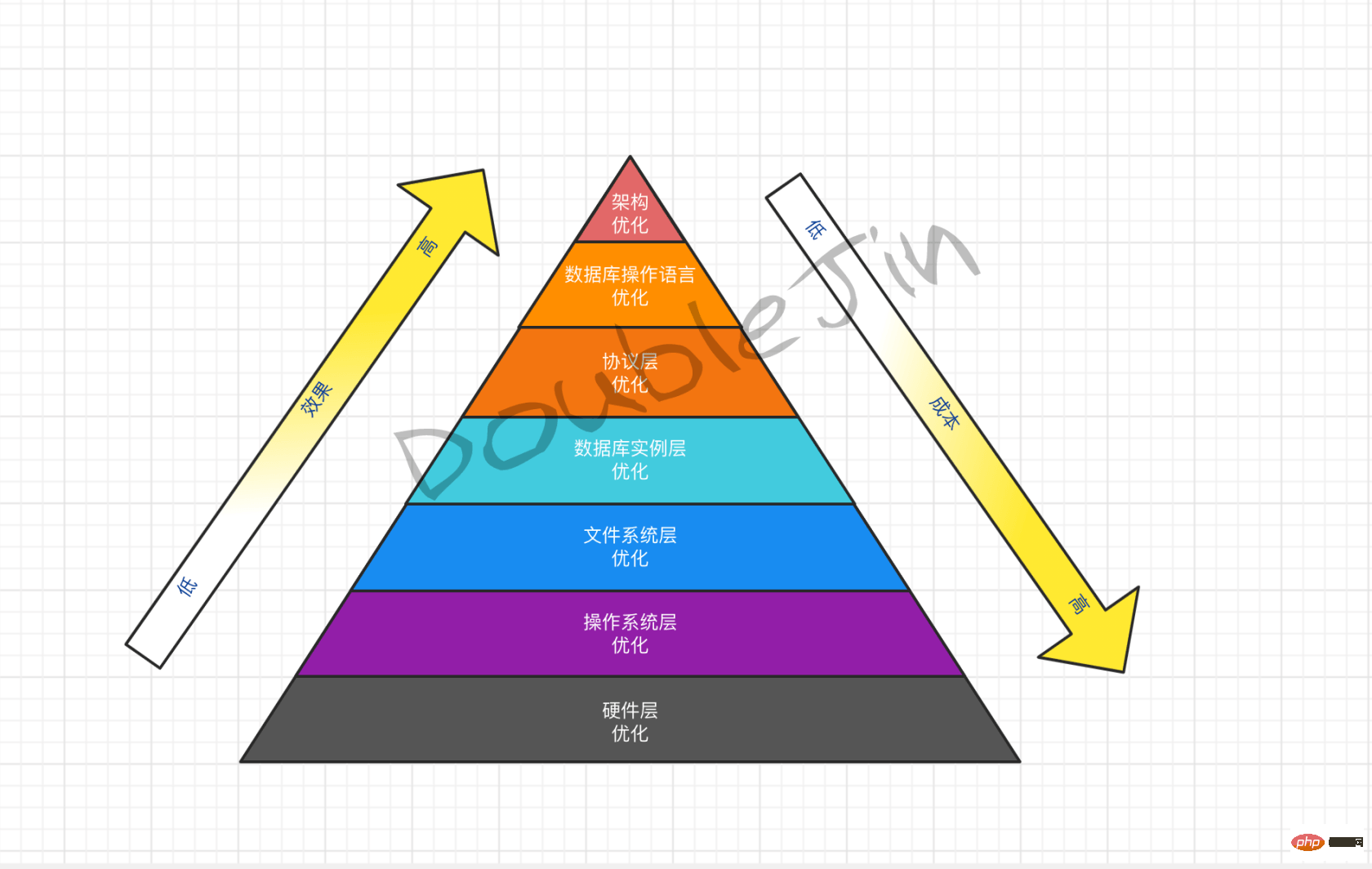
Optimisation matérielle - Capacité financière
-
Phase 1
- Améliorez les E/S du disque, essayez d'utiliser un disque SSD (amélioration qualitative)
- Augmentez la mémoire, augmentez l'espace du cache de requêtes
- Augmentez le nombre de processeurs de cœurs, augmentez les threads d'exécution
-
Phase deux
- Remplacez MySQL auto-construit par le service MySQL du fournisseur de services
- Activez la fonction de séparation de lecture et d'écriture intégrée
-
Phase trois
- Le service MySQL du fournisseur de services est remplacé par une base de données distribuée native du cloud
- Activez la fonction de séparation de lecture et d'écriture intégrée
- Activez la fonction de sous-table intégrée
Optimisation douce - Requête - OLTP
OLTP est principalement utilisé pour l'enregistrement Lorsqu'un certain type d'événement commercial se produit, tel que le comportement de l'utilisateur, lorsque le comportement se produit, le système enregistre quand et où l'utilisateur a fait quoi. ) des données seront ajoutées, supprimées et modifiées dans la base de données. L'opération de traitement de mise à jour nécessite des performances en temps réel élevées, une forte stabilité et garantit une mise à jour réussie des données en temps opportun. Les systèmes d'entreprise courants sont tous OLTP et les bases de données utilisées. sont des bases de données de transactions, telles que MySlq, Oracle, etc. Pour OLTP, l'amélioration de la vitesse des requêtes et la stabilité du service sont au cœur de l'optimisation
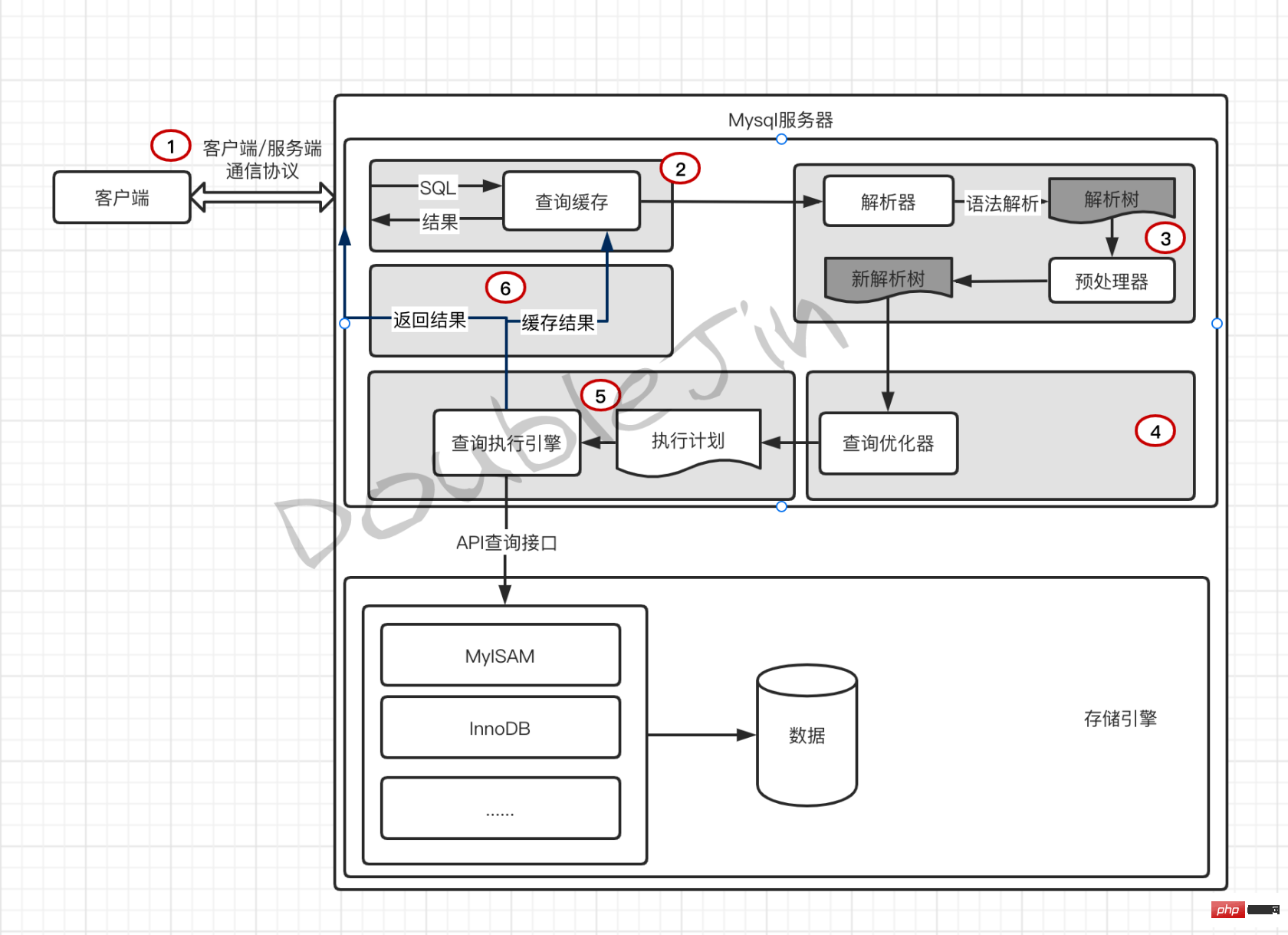
- Requête lente
- Découvrez SQL avec des problèmes d'efficacité grâce aux journaux de requêtes lents
- Direction de dépannage SQL
- Il y a un problème avec la conception de l'index
- Il y a un problème avec l'instruction SQL
- Le mauvais index est sélectionné dans la base de données
- Une seule table est grande
- Expliquez l'analyse détaillée
- Affichez le taux d'exécution SQL
- Affichez l'état d'accès à l'index (points clés)
- optimiseur mysql
- Lorsque l'optimiseur sélectionne un index, il le fera se référer à la cardinalité de l'index
- La cardinalité est automatique MySQL. Ce qui est maintenu et estimé peut ne pas être précis. Si l'index n'atteint pas ou si un mauvais index est utilisé, il y a un problème avec l'optimiseur. Les informations d'index et recalculer la base. L'indexation forcée peut forcer l'utilisation d'index et spécifier de force l'index sur le code d'entreprise
- Index couvert - l'index de succès le plus idéal
- Les index couverts peuvent réduire les retours de requêtes de table
- Si la requête de données utilise plus d'un index, ce n'est pas un index de couverture
-
- count () Fonction
- count (champ non-index) - ne peut pas utiliser l'index de couverture, théoriquement le plus lent
- count (champ d'index) - peut couvrir index, doit encore déterminer si le champ est nul à chaque fois
- count (clé primaire) - comme ci-dessus
- count(*) - MySQL a spécialement optimisé la fonction count(*) pour renvoyer directement l'index Le nombre de données dans l'arborescence, optimal
- ORDER BY
- minimise le tri supplémentaire, spécifiez la condition Where
- La combinaison de l'instruction Where et de l'instruction ORDER BY satisfait le préfixe le plus à gauche
- la couverture d'index la plus efficace (moins de scénarios, le risque de rencontre est peu probable)
- Le champ ORDER doit être indexé et se trouver dans le même index que la condition WHERE et le contenu de sortie
- Requête de pagination
- Trouvez d'abord un moyen d'utiliser la couverture d'index
- Premier découvrez l'identifiant des données requises et revenez au tableau pour obtenir l'ensemble de résultats final
- KEY
store_id_guide_id(store_id,<code> guide_id) EN UTILISANT BTREE- sélectionnez * dans la table où store_id dans (1,2) et guide_id = 3 ;
- Avant MySQL5.6, vous devez utiliser l'index pour interroger store_id dans (1,2), puis ajoutez toutes les tables pour vérifier film_id = 3
- scan d'index libre
store_id_guide_id(store_id,guide_id) USING BTREE - select * from table where store_id in (1,2) and guide_id = 3;
- MySQL5.6之前,需要先拿用索引查询store_id in (1,2),再全部加表验证film_id = 3
- MySQL5.6之后,如果索引中可以判读,直接使用索引过滤
- scan d'index libre
- 松散索引扫描
- KEY
store_id_guide_id(store_id,guide_idKEY - sélectionnez film_id dans la table où guide_id = 3
- Nouvelles fonctionnalités MySQL8.0
- Une analyse d'index lâche peut briser le "principe de la main gauche" et résoudre Le problème de la perte du frère leader
- L'efficacité est inférieure à celle de l'index conjoint
store_id_guide_id( store_id,guide_id) EN UTILISANT BTREE - KEY
- Opération de fonction
- Si vous effectuez des opérations de fonction sur le champ d'index, l'optimiseur abandonnera l'index
- Cette situation peut inclure : fonction time, conversion de chaîne en nombre, conversion d'encodage de caractères
- Optimisez l'utilisation de la logique côté serveur au lieu des fonctions MySQL
- La taille de la table unique est trop grande
- Mise à niveau de MySQL Différents logiciels MySQL peuvent supporter différentes tailles de table unique. . D'après mon expérience actuelle, Alibaba Lorsque la version cloud polardb cluster a une seule table de 200 millions, il n'y a aucun problème pour interroger l'index d'accès (haute priorité)
- Règlement des données - Par exemple, les données du pipeline peuvent être réglées en fonction de. un certain moment pour obtenir la dernière valeur et le transfert du pipeline réglé Accédez à la table de sauvegarde (priorité moyenne)
- Séparation des données chaudes et froides - les données qui ne peuvent pas être réglées sont distinguées en fonction de la fréquence de requête, faible- les données de fréquence sont transférées vers une autre table pour la requête, et l'entrée de la requête est distinguée en termes d'activité (priorité moyenne))
- Division de la table de la base de données distribuée - active la fonction de division de la table de la base de données distribuée avec les commandes et la base de données distribuée Le composant gère l'insertion et la requête après le fractionnement de la table (priorité moyenne)
- Fractionnement de la table d'implémentation du code - selon certaines règles Le fractionnement d'une seule table en plusieurs tables nécessite certaines modifications du framework ORM après le fractionnement dans la plupart des ORM du framework de PHP et GO. L'ORM en JAVA a un support natif. Il est recommandé de l'envisager au début du projet, et plus tard plus la difficulté est grande (faible priorité)
Optimisation logicielle - écriture de suppression de mise à jour
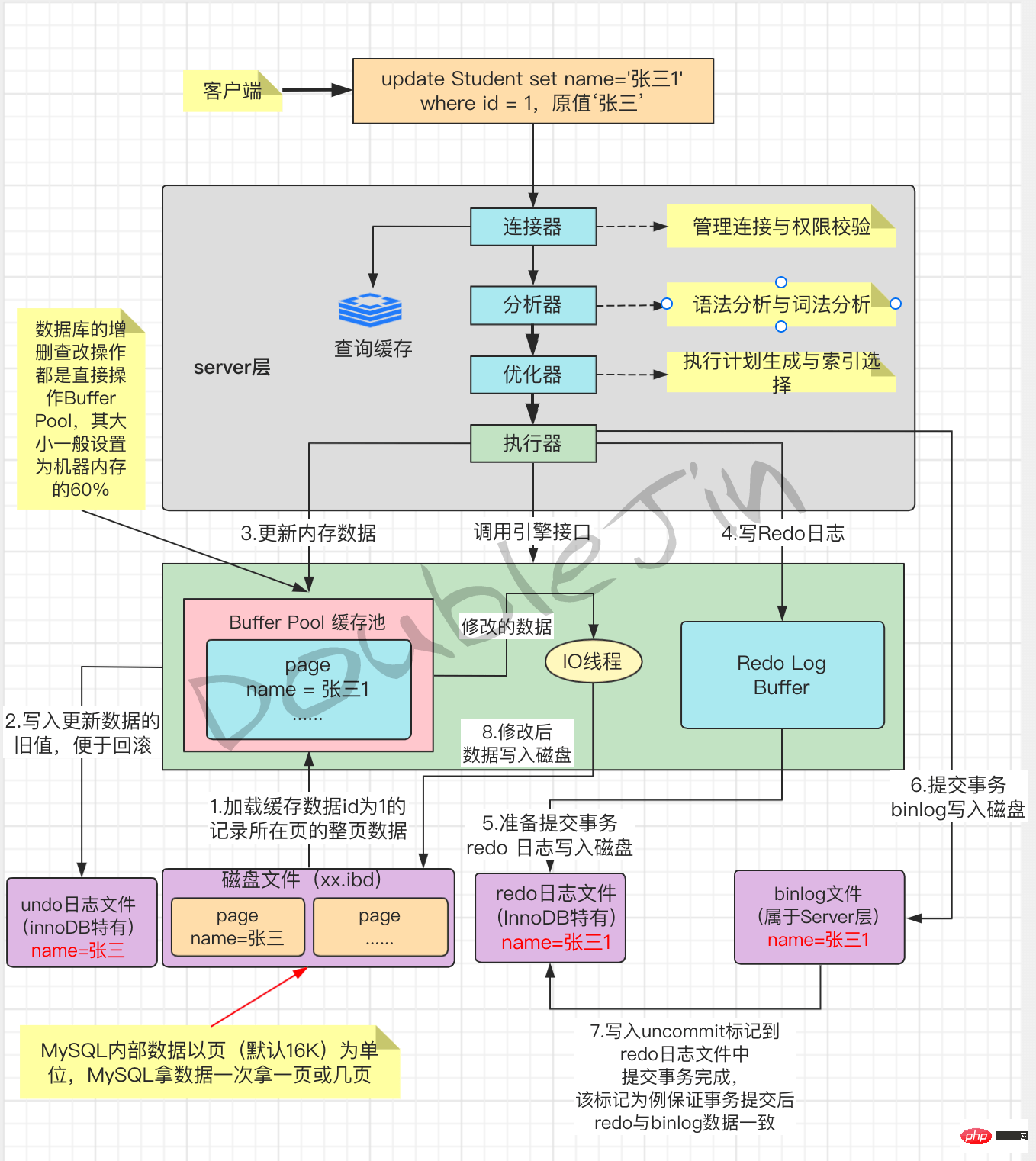
-
Lock
- Selon la granularité, les verrous MySQL peuvent être divisés en verrous globaux, verrous au niveau de la table, verrous de ligne
-
verrou global
- self-google/baidu
-
table- le verrouillage de niveau est divisé en verrouillage de table (verrouillage de données) et verrouillage de métadonnées lignes de données, divisées en verrous partagés et verrous exclusifs
- Self-google/baidu
- Solution à l'impasse
- Configuration des paramètres
- Ajustez le paramètre innodb_lock_wait_timeout
- La valeur par défaut est de 50 secondes, c'est-à-dire que si le verrou n'est pas acquis après 50 secondes d'attente, l'instruction actuelle signalera une erreur
- Si le temps d'attente est trop long, vous pouvez raccourcir ce paramètre de manière appropriée
- Détection active des blocages : innodb_deadlock_detect
- Lorsqu'un blocage est détecté, annulez les transactions moins coûteuses
- Activé par défaut
- Ajustez le paramètre innodb_lock_wait_timeout
- Ne pas ouvrir de transactions lorsque ce n'est pas nécessaire
- Les requêtes doivent être placé autant que possible en dehors des transactions pour réduire le nombre de lignes verrouillées
- Éviter le temps de transaction Trop long, ne pas déclencher de requêtes http dans la transaction
- Vérifier de manière proactive l'état de la transaction
show processlist;SELECT * FROM information_schema.INNODB_TRX; //长事务SELECT * FROM information_schema.INNODB_LOCKs; //查看锁SELECT * FROM information_schema.INNODB_LOCK_waits; //查看阻塞事务
Copier après la connexion
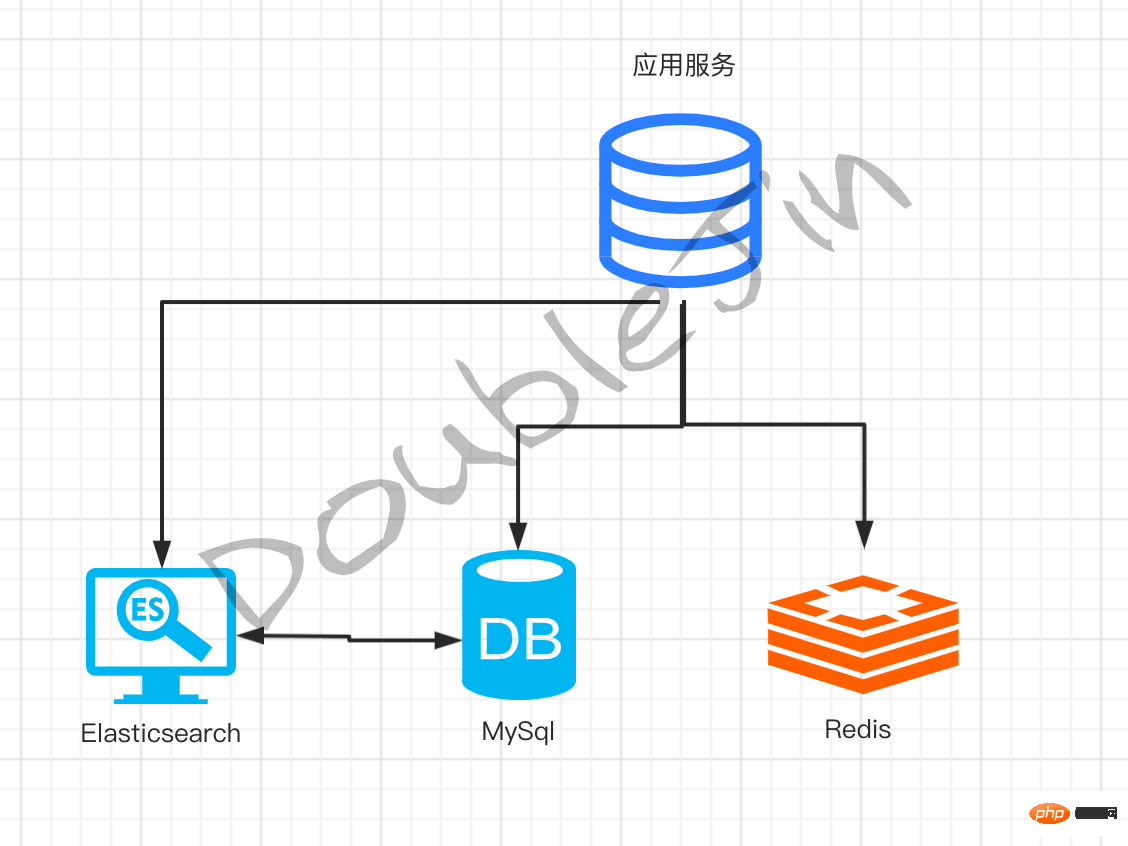
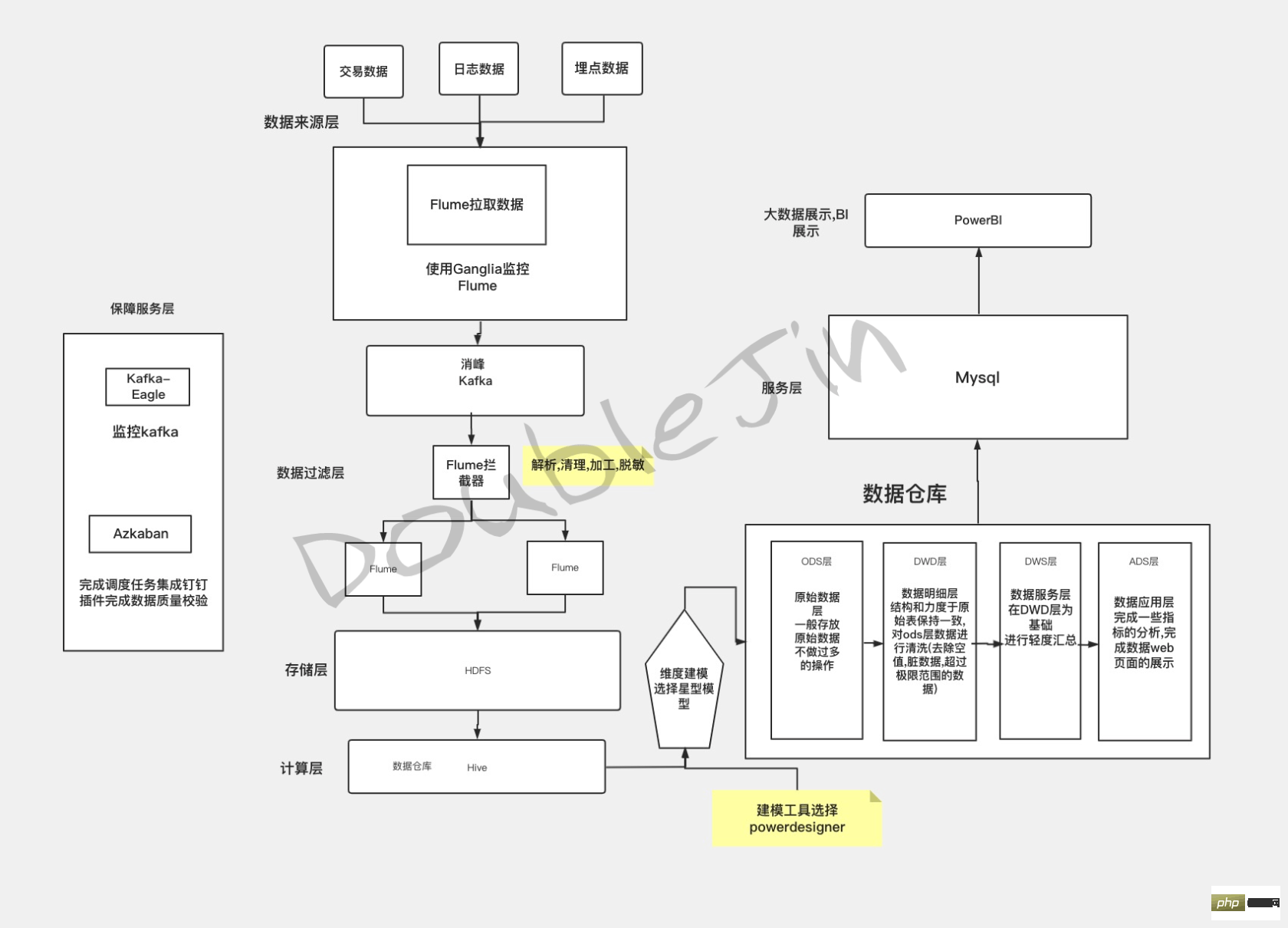
Recherche d'entreprise
- Le le nombre de lignes de recherche est inférieur à 100 000 - MySQL est difficile à transporter recherche en texte intégral, mais la structure des données a une faible flexibilité.
- Synchronisation des données
Lorsque le code métier modifie les données, il est synchronisé avec Elasticsearch en même temps - L'abonnement Canel au journal MySQL déclenche la synchronisation
Elasticsearch-index se compose d'une liste de documents avec les mêmes champs - analogue au champ table
- de mysql Une fois le type défini, il est interdit de le modifier et de nouveaux champs sont autorisés
- La méthode spécifique est google/baidu
- Le document de données de l'utilisateur stocké en es - analogue à la ligne de mysql
- Par métadonnées et composition d'objet Json
- Détails des métadonnées et de l'objet Json self-google/baidu
- self-google/baidu
- Elasticsearch- index inversé (clé)
- self-google/baidu
- Elasticsearch-Aggregation Analysis
- Automatic google/baidu
- Statistical Business-OLAP
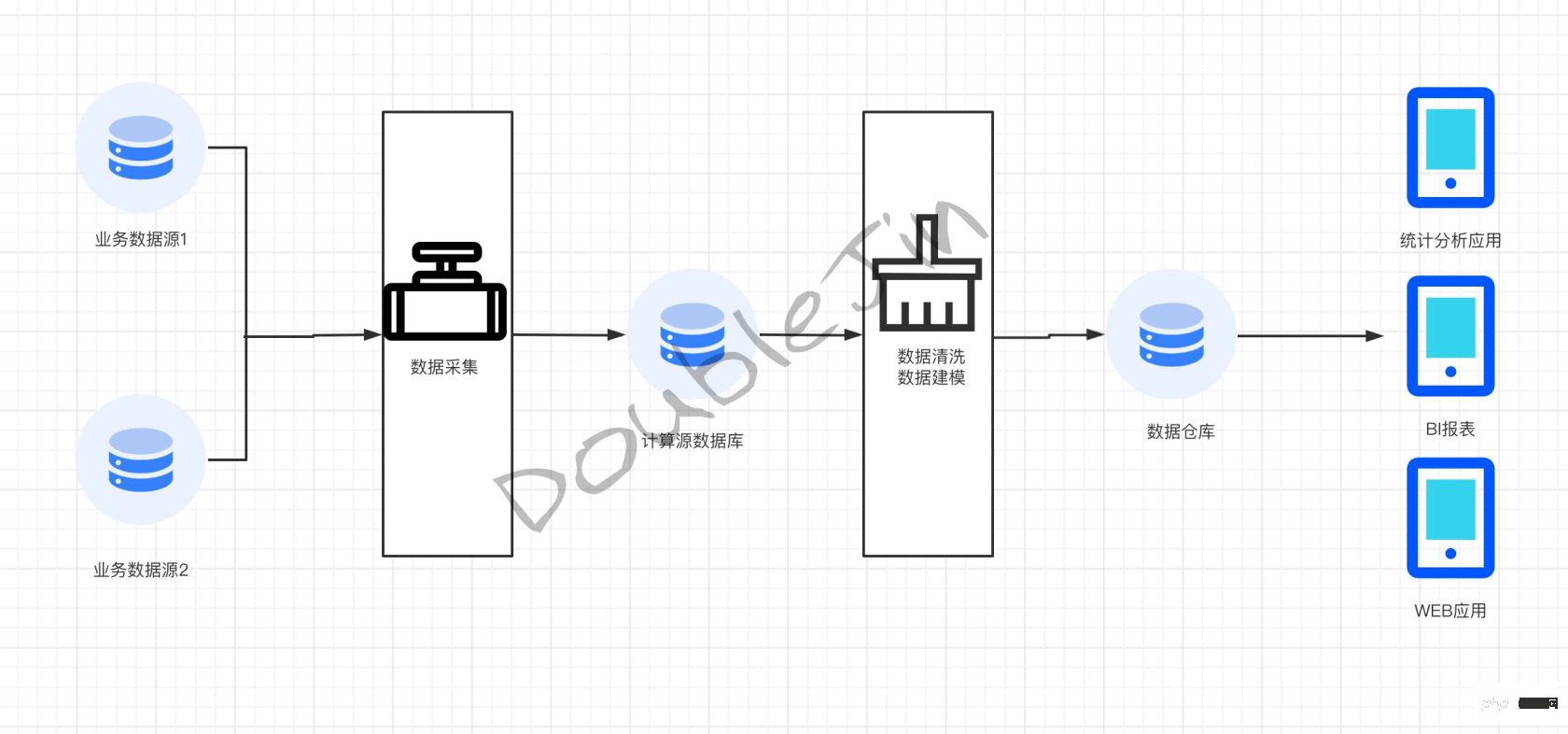
OLAP est utilisé pour l'analyse décisionnelle des données relatives aux scénarios de traitement des transactions OLTP. Il s'agit d'une application dans l'analyse du Big Data. L'idée d'entrepôt de données hors ligne mentionnée ci-dessus n'est pas une pile technologique spécifique. Si votre solution peut refléter l'idée de l'analyse et du traitement OLAP, alors la solution est OLAP. - La construction précoce d'un entrepôt de données fait principalement référence à la modélisation et à la synthèse de bases de données commerciales d'entreprise telles que ERP, CRM, SCM et d'autres données dans le moteur d'entrepôt de données en fonction des exigences de l'analyse décisionnelle. Son application est principalement des rapports, dans le but de. soutenir la prise de décision de la direction et du personnel de l’entreprise (décisions stratégiques à moyen et long terme). À mesure que la technologie informatique évolue vers Internet et la mobilité, les sources de données deviennent de plus en plus abondantes. Les données non structurées apparaissent sur la base de la base de données d'entreprise d'origine, telles que les journaux de sites Web, les données des appareils IoT, les données enfouies dans les applications, etc. C’est plusieurs ordres de grandeur plus grands que les données structurées précédentes.
- Peu importe l'évolution de l'activité à laquelle est confrontée OLAP, elle est indissociable des étapes suivantes : Déterminer le champ d'analyse->Synchroniser les données métier avec la bibliothèque informatique->Modélisation du nettoyage des données->Synchroniser avec l'entrepôt de données-> ;Exposer au monde extérieur
La base de données source de calcul est spécialement utilisée pour le nettoyage des données. Le but est d'éviter d'affecter les performances de la base de données métier lors du nettoyage des données. En nettoyant les données dans la base de données source de calcul en fonction de l'activité et des dimensions, la facilité d'utilisation et la réutilisation des données sont augmentées, et les données détaillées finales en temps réel sont obtenues, qui sont transférées à l'entrepôt de données, et l'entrepôt de données fournit le données d’analyse de décision finale.
Plan DEMO
Plan de productionLe logiciel dans chaque lien peut être remplacé par un logiciel avec la même fonction Si l'équipe est la plus confiante quant au plan de mise en œuvre du logiciel, alors le plan est OLAP.
Résumé
L'optimisation doit être terre-à-terre, avec une accumulation de capacités étape par étape, plusieurs séries d'itérations et ne peut pas être réalisée du jour au lendemain. Effectuez plusieurs séries d'itérations en fonction de vos propres bases, de vos scénarios commerciaux et de vos attentes de développement futur. Le principe de l'itération est d'améliorer d'abord l'efficacité d'un service logiciel unique grâce à une optimisation logicielle et une optimisation matérielle. Lorsque le coût d'optimisation est inférieur aux revenus, en fonction des attentes de développement futur, se référer aux solutions matures du marché et les introduire. selon les besoins en fonction de la solution. Lorsque vous utilisez un nouveau logiciel pour une innovation combinée, veillez à ne pas le copier aveuglément. Ce n'est que grâce à une intégration organique que vous pouvez obtenir les effets de 1+1>2, 2+1>3. un goulot d'étranglement, répétez ce processus.Merci d'avoir lu ceci. Ce qui précède est tout le contenu de l'article. Les points d'optimisation et les solutions proposées dans le contenu ne sont pas nécessairement les solutions optimales. Ce sont les meilleures pratiques en matière de travail personnel. sont invités à en discuter et à les échanger.
 Merci d'avoir lu ceci. Ce qui précède est tout le contenu de l'article. Les points d'optimisation et les solutions proposées dans le contenu ne sont pas nécessairement les solutions optimales. Ce sont les meilleures pratiques en matière de travail personnel. sont invités à en discuter et à les échanger.
Merci d'avoir lu ceci. Ce qui précède est tout le contenu de l'article. Les points d'optimisation et les solutions proposées dans le contenu ne sont pas nécessairement les solutions optimales. Ce sont les meilleures pratiques en matière de travail personnel. sont invités à en discuter et à les échanger. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL est un système de gestion de base de données relationnel open source. 1) Créez une base de données et des tables: utilisez les commandes CreateDatabase et CreateTable. 2) Opérations de base: insérer, mettre à jour, supprimer et sélectionner. 3) Opérations avancées: jointure, sous-requête et traitement des transactions. 4) Compétences de débogage: vérifiez la syntaxe, le type de données et les autorisations. 5) Suggestions d'optimisation: utilisez des index, évitez de sélectionner * et utilisez les transactions.
 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL sont des compétences essentielles pour les développeurs. 1.MySQL est un système de gestion de base de données relationnel open source, et SQL est le langage standard utilisé pour gérer et exploiter des bases de données. 2.MySQL prend en charge plusieurs moteurs de stockage via des fonctions de stockage et de récupération de données efficaces, et SQL termine des opérations de données complexes via des instructions simples. 3. Les exemples d'utilisation comprennent les requêtes de base et les requêtes avancées, telles que le filtrage et le tri par condition. 4. Les erreurs courantes incluent les erreurs de syntaxe et les problèmes de performances, qui peuvent être optimisées en vérifiant les instructions SQL et en utilisant des commandes Explication. 5. Les techniques d'optimisation des performances incluent l'utilisation d'index, d'éviter la numérisation complète de la table, d'optimiser les opérations de jointure et d'améliorer la lisibilité du code.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Comment construire une base de données SQL
Apr 09, 2025 pm 04:24 PM
Comment construire une base de données SQL
Apr 09, 2025 pm 04:24 PM
La construction d'une base de données SQL comprend 10 étapes: sélectionner des SGBD; Installation de SGBD; créer une base de données; créer une table; insérer des données; récupération de données; Mise à jour des données; supprimer des données; gérer les utilisateurs; sauvegarde de la base de données.
