
 Opération et maintenance
exploitation et maintenance Linux
Comment installer Hadoop sous Linux
Opération et maintenance
exploitation et maintenance Linux
Comment installer Hadoop sous Linux
Comment installer Hadoop sous Linux

Comment installer Hadoop sur Linux : 1. Installez le service ssh ; 2. Utilisez ssh pour vous connecter sans authentification par mot de passe ; 3. Téléchargez le package d'installation Hadoop ; 4. Décompressez le package d'installation Hadoop ; Hadoop.

L'environnement d'exploitation de cet article : système Ubuntu 16.04, Hadoop version 2.7.1, ordinateur Dell G3.
Comment installer Hadoop sur Linux ?
[Big Data] Explication détaillée de l'installation de Hadoop (2.7.1) et de l'exécution de WordCount sous Linux
1. Introduction
Après avoir terminé la configuration de l'environnement de Storm, je souhaite bricoler l'installation de Hadoop, et il existe des tutoriels sur Internet Il y en a beaucoup, mais aucun d'entre eux n'est particulièrement adapté, j'ai donc encore rencontré beaucoup de problèmes lors du processus d'installation, j'ai finalement résolu le problème après avoir constamment vérifié les informations, je me sens bien. venons-en au fait.
L'environnement de configuration de cette machine est le suivant :
Hadoop(2.7.1)
Ubuntu Linux (système 64 bits)
Le processus de configuration est expliqué en détail en plusieurs étapes ci-dessous.
2. Installer le service ssh
Entrez la commande shell et entrez la commande suivante pour vérifier si le service ssh a été installé. Sinon, utilisez la commande suivante pour l'installer :
sudo apt-get. install ssh openssh-serversudo apt-get install ssh openssh-server
安装过程还是比较轻松加愉快的。
三、使用ssh进行无密码验证登录
1.创建ssh-key,这里我们采用rsa方式,使用如下命令:
ssh-keygen -t rsa -P ""
2.出现一个图形,出现的图形就是密码,不用管它
cat ~/.ssh/id_rsa.pub >> authorized_keys(好像是可以省略的)
3.然后即可无密码验证登录了,如下:
ssh localhost
成功截图如下:

四、下载Hadoop安装包
下载Hadoop安装也有两种方式
1.直接上官网进行下载,http://mirrors.hust.edu.cn/apache/hadoop/core/stable/hadoop-2.7.1.tar.gz
2.使用shell进行下载,命令如下:
wget http://mirrors.hust.edu.cn/apache/hadoop/core/stable/hadoop-2.7.1.tar.gz
貌似第二种的方法要快点,经过漫长的等待,终于下载完成。
五、解压缩Hadoop安装包
使用如下命令解压缩Hadoop安装包
tar -zxvf hadoop-2.7.1.tar.gz
解压缩完成后出现hadoop2.7.1的文件夹
六、配置Hadoop中相应的文件
需要配置的文件如下,hadoop-env.sh,core-site.xml,mapred-site.xml.template,hdfs-site.xml,所有的文件均位于hadoop2.7.1/etc/hadoop下面,具体需要的配置如下:
1.core-site.xml 配置如下:
<configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/home/leesf/program/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
其中的hadoop.tmp.dir的路径可以根据自己的习惯进行设置。
2.mapred-site.xml.template配置如下:
<configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> </configuration>
3.hdfs-site.xml配置如下:
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/leesf/program/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/leesf/program/hadoop/tmp/dfs/data</value> </property> </configuration>
其中dfs.namenode.name.dir和dfs.datanode.data.dir的路径可以自由设置,最好在hadoop.tmp.dir的目录下面。
补充,如果运行Hadoop的时候发现找不到jdk,可以直接将jdk的路径放置在hadoop.env.sh里面,具体如下:
export JAVA_HOME="/home/leesf/program/java/jdk1.8.0_60"
七、运行Hadoop
在配置完成后,运行hadoop。
1.初始化HDFS系统
在hadop2.7.1目录下使用如下命令:
bin/hdfs namenode -format
截图如下:

过程需要进行ssh验证,之前已经登录了,所以初始化过程之间键入y即可。
成功的截图如下:

表示已经初始化完成。
2.开启NameNode和DataNode守护进程
使用如下命令开启:
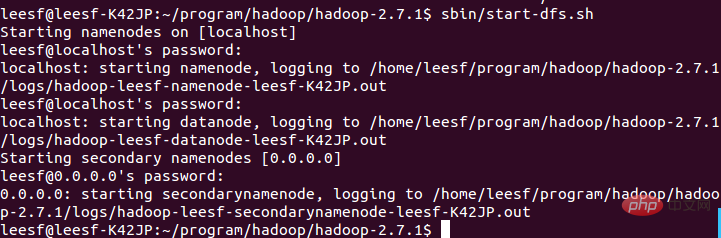
sbin/start-dfs.sh,成功的截图如下:
1. Créez une clé ssh, ici nous utilisons la méthode rsa, utilisez la commande suivante :
ssh-keygen -t rsa -P ""
2. Un graphique apparaîtra. Le graphique qui apparaît est le mot de passe Ne vous inquiétez pas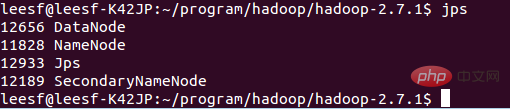
cat ~/.ssh/id_rsa.pub >> 3. Ensuite, vous pouvez vous connecter sans vérification du mot de passe, comme suit : 🎜🎜 ssh localhost🎜🎜 La capture d'écran réussie est la suivante : 🎜🎜  🎜🎜🎜Quatre. Téléchargez le package d'installation Hadoop🎜🎜🎜Il existe deux façons de télécharger l'installation Hadoop. 🎜🎜 1. Accédez directement au site officiel pour télécharger, http://mirrors.hust.edu.cn/apache/hadoop/core/stable/hadoop-2.7.1.tar.gz🎜🎜 2. Utilisez le shell pour télécharger , la commande est la suivante : 🎜🎜
🎜🎜🎜Quatre. Téléchargez le package d'installation Hadoop🎜🎜🎜Il existe deux façons de télécharger l'installation Hadoop. 🎜🎜 1. Accédez directement au site officiel pour télécharger, http://mirrors.hust.edu.cn/apache/hadoop/core/stable/hadoop-2.7.1.tar.gz🎜🎜 2. Utilisez le shell pour télécharger , la commande est la suivante : 🎜🎜 wget http://mirrors .hust.edu.cn/apache/hadoop/core/stable/hadoop-2.7.1.tar.gz🎜🎜 Il semble que la deuxième méthode est plus rapide. Après une longue attente, le téléchargement est enfin terminé. 🎜🎜🎜 5. Décompressez le package d'installation Hadoop 🎜🎜🎜 Utilisez la commande suivante pour décompresser le package d'installation Hadoop 🎜🎜 tar -zxvf hadoop-2.7.1.tar.gz 🎜🎜 Une fois la décompression terminée, le dossier hadoop2.7.1 apparaîtra 🎜🎜 🎜6. Configurez les fichiers correspondants dans Hadoop🎜🎜🎜 Les fichiers qui doivent être configurés sont les suivants, hadoop-env.sh, core-site.xml, mapred-site.xml.template, hdfs-site. .xml, tous les fichiers se trouvent dans hadoop2 .7.1/etc/hadoop, la configuration spécifique requise est la suivante : 🎜🎜 La configuration 1.core-site.xml est la suivante : 🎜rrreee🎜 Le chemin de hadoop.tmp.dir peut être réglé selon vos propres habitudes. 🎜🎜 2.mapred-site.xml.template est configuré comme suit : 🎜rrreee🎜 3.hdfs-site.xml est configuré comme suit : 🎜rrreee🎜 Les chemins de dfs.namenode.name.dir et dfs.datanode.data .dir peut être un paramètre gratuit, de préférence sous le répertoire hadoop.tmp.dir. 🎜🎜 De plus, si vous constatez que jdk est introuvable lors de l'exécution de Hadoop, vous pouvez directement placer le chemin de jdk dans hadoop.env.sh, comme suit : 🎜🎜 Export JAVA_HOME="/home/leesf/program/java/ jdk1.8.0_60"🎜🎜🎜7. Exécutez Hadoop🎜🎜🎜Une fois la configuration terminée, exécutez hadoop. 🎜🎜 1. Initialisez le système HDFS🎜🎜 Utilisez la commande suivante dans le répertoire hadop2.7.1 : 🎜rrreee🎜 La capture d'écran est la suivante :🎜🎜  🎜🎜 Le processus nécessite une vérification ssh. Vous êtes déjà connecté auparavant, alors tapez simplement y entre le processus d'initialisation. 🎜🎜 La capture d'écran réussie est la suivante :🎜🎜 🎜🎜 Indique que l'initialisation est terminée. 🎜🎜 2. Démarrez les démons
🎜🎜 Le processus nécessite une vérification ssh. Vous êtes déjà connecté auparavant, alors tapez simplement y entre le processus d'initialisation. 🎜🎜 La capture d'écran réussie est la suivante :🎜🎜 🎜🎜 Indique que l'initialisation est terminée. 🎜🎜 2. Démarrez les démons NameNode et DataNode 🎜🎜 Utilisez la commande suivante pour démarrer : 🎜🎜 sbin/start-dfs.sh, la capture d'écran réussie est comme suit : 🎜🎜 🎜🎜🎜 3. Afficher les informations sur le processus🎜🎜 Utilisez la commande suivante pour afficher les informations sur le processus🎜🎜 jps, la capture d'écran est la suivante :🎜🎜 🎜🎜🎜 Cela signifie que DataNode et NameNode ont tous deux commencé🎜<p> 4. Afficher l'interface utilisateur Web</p>
<p> Entrez http://localhost:50070 dans le navigateur pour afficher les informations pertinentes. La capture d'écran est la suivante : </p>
<p><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/020/bfb5bc22f461fcb2beb87197aa100a4e-5.png" class="lazy" alt=""></p>
<p> À ce stade, l'environnement hadoop a été configuré. Commençons par utiliser hadoop pour exécuter un exemple WordCount. </p>
<p><strong> 8. Exécutez la démo WordCount </strong></p>
<p> 1. Créez un nouveau fichier localement L'auteur a créé un nouveau document Word dans le répertoire home/leesf. </p>
<p> 2. Créez un nouveau dossier dans HDFS pour télécharger des documents Word locaux. Entrez la commande suivante dans le répertoire hadoop2.7.1 : </p>
<p> bin/hdfs dfs -mkdir /test, ce qui signifie qu'il est créé dans le répertoire racine de hdfs A. test directory</p>
<p> Utilisez la commande suivante pour afficher la structure des répertoires sous le répertoire racine HDFS</p>
<p> bin/hdfs dfs -ls /</p>
<p> La capture d'écran spécifique est la suivante :</p>
<p> <img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/020/2d6b7ed9c222079a563098cea81e4d89-6.png" class="lazy" alt=""></p>
<p> Cela signifie qu'un répertoire de test a été créé sous le répertoire racine de HDFS </p>
<p> 3. Téléchargez les documents Word locaux dans le répertoire de test</p>
<p> Utilisez la commande suivante pour télécharger : </p>
<p> bin/hdfs dfs -put /home/leesf/words /test/</p>
<p> Moi dans dans in in forward dans les documents Words </p>
<p> Utilisez la commande suivante pour le visualiser </p>
<p> bin/ hdfs dfs -ls /test/</p>
<p> La capture d'écran du résultat est la suivante : <img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/020/2d6b7ed9c222079a563098cea81e4d89-7.png" class="lazy" alt=""></p> <p></p>
<p> Cela signifie que le document Word local a été téléchargé dans le répertoire de test. </p>
<p> 4. Exécutez wordcount</p>
<p> Utilisez la commande suivante pour exécuter wordcount :</p>
<p> bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount /test/words /test/out</p>
<p> La capture d'écran est la suivante :<img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/020/2d6b7ed9c222079a563098cea81e4d89-8.png" class="lazy" alt=""></p> <p></p>
<p> Une fois l'opération terminée, un fichier nommé out sera généré dans le répertoire /test Utilisez la commande suivante pour afficher les fichiers dans le répertoire /test</p>
<p> bin/hdfs dfs -. ls /test</p>
<p> La capture d'écran est la suivante :<img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/020/9e4e133c94861b62bd546dbeb0c3b6b4-9.png" class="lazy" alt=""></p> <p> </p>
<p> Indique qu'il existe déjà un répertoire de fichiers nommé Out dans le répertoire de test</p>
<p> Entrez la commande suivante pour afficher les fichiers dans le répertoire out : </p>
<p> bin/hd : fs dfs -ls /test/out, la capture d'écran du résultat est la suivante : <img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/020/9e4e133c94861b62bd546dbeb0c3b6b4-10.png" class="lazy" alt=""></p> <p></p> <p> Indique qu'il a été exécuté avec succès et que le résultat est enregistré dans part-r-00000. </p>
<p> 5. Vérifiez les résultats en cours d'exécution</p>
<p> Utilisez la commande suivante pour vérifier les résultats en cours d'exécution :</p>
<p> bin/hadoop fs -cat /test/out/part-r-00000</p>
<p> La capture d'écran du résultat est la suivante :<img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/020/9e4e133c94861b62bd546dbeb0c3b6b4-11.png" class="lazy" alt=""></p> <p> </p>
<p> À ce stade, le processus en cours est terminé. C'est fait. <strong></strong></p>9. Résumé<p></p>
<p> J'ai rencontré de nombreux problèmes lors de ce processus de configuration hadoop. Les commandes de hadoop1.x et 2.x sont encore très différentes. Lors du processus de configuration, les problèmes ont été résolus un par un et la configuration a été effectuée. réussi., j'ai beaucoup gagné. J'aimerais partager mon expérience dans cette configuration pour la commodité des jardiniers qui souhaitent configurer l'environnement hadoop. Si vous avez des questions pendant le processus de configuration, n'hésitez pas à en discuter. à regarder~<a href="https://www.php.cn/course/list/33.html" target="_blank"></a> Etude recommandée : "</p>tutoriel vidéo Linux🎜"🎜Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Différence entre Centos et Ubuntu
Apr 14, 2025 pm 09:09 PM
Différence entre Centos et Ubuntu
Apr 14, 2025 pm 09:09 PM
Les principales différences entre Centos et Ubuntu sont: l'origine (Centos provient de Red Hat, pour les entreprises; Ubuntu provient de Debian, pour les particuliers), la gestion des packages (Centos utilise Yum, se concentrant sur la stabilité; Ubuntu utilise APT, pour une fréquence de mise à jour élevée), le cycle de support (CentOS fournit 10 ans de soutien, Ubuntu fournit un large soutien de LT tutoriels et documents), utilisations (Centos est biaisé vers les serveurs, Ubuntu convient aux serveurs et aux ordinateurs de bureau), d'autres différences incluent la simplicité de l'installation (Centos est mince)
 Comment installer CentOS
Apr 14, 2025 pm 09:03 PM
Comment installer CentOS
Apr 14, 2025 pm 09:03 PM
Étapes d'installation de CentOS: Téléchargez l'image ISO et Burn Bootable Media; démarrer et sélectionner la source d'installation; sélectionnez la langue et la disposition du clavier; configurer le réseau; partitionner le disque dur; définir l'horloge système; créer l'utilisateur racine; sélectionnez le progiciel; démarrer l'installation; Redémarrez et démarrez à partir du disque dur une fois l'installation terminée.
 Centos arrête la maintenance 2024
Apr 14, 2025 pm 08:39 PM
Centos arrête la maintenance 2024
Apr 14, 2025 pm 08:39 PM
Centos sera fermé en 2024 parce que sa distribution en amont, Rhel 8, a été fermée. Cette fermeture affectera le système CentOS 8, l'empêchant de continuer à recevoir des mises à jour. Les utilisateurs doivent planifier la migration et les options recommandées incluent CentOS Stream, Almalinux et Rocky Linux pour garder le système en sécurité et stable.
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 Le choix de Centos après l'arrêt de l'entretien
Apr 14, 2025 pm 08:51 PM
Le choix de Centos après l'arrêt de l'entretien
Apr 14, 2025 pm 08:51 PM
CentOS a été interrompu, les alternatives comprennent: 1. Rocky Linux (meilleure compatibilité); 2. Almalinux (compatible avec CentOS); 3. Serveur Ubuntu (configuration requise); 4. Red Hat Enterprise Linux (version commerciale, licence payante); 5. Oracle Linux (compatible avec Centos et Rhel). Lors de la migration, les considérations sont: la compatibilité, la disponibilité, le soutien, le coût et le soutien communautaire.
 Que faire après Centos arrête la maintenance
Apr 14, 2025 pm 08:48 PM
Que faire après Centos arrête la maintenance
Apr 14, 2025 pm 08:48 PM
Une fois CentOS arrêté, les utilisateurs peuvent prendre les mesures suivantes pour y faire face: sélectionnez une distribution compatible: comme Almalinux, Rocky Linux et CentOS Stream. Migrez vers les distributions commerciales: telles que Red Hat Enterprise Linux, Oracle Linux. Passez à Centos 9 Stream: Rolling Distribution, fournissant les dernières technologies. Sélectionnez d'autres distributions Linux: comme Ubuntu, Debian. Évaluez d'autres options telles que les conteneurs, les machines virtuelles ou les plates-formes cloud.
 Comment utiliser Docker Desktop
Apr 15, 2025 am 11:45 AM
Comment utiliser Docker Desktop
Apr 15, 2025 am 11:45 AM
Comment utiliser Docker Desktop? Docker Desktop est un outil pour exécuter des conteneurs Docker sur les machines locales. Les étapes à utiliser incluent: 1. Installer Docker Desktop; 2. Démarrer Docker Desktop; 3. Créer une image Docker (à l'aide de DockerFile); 4. Build Docker Image (en utilisant Docker Build); 5. Exécuter Docker Container (à l'aide de Docker Run).
 Quelle configuration de l'ordinateur est requise pour VScode
Apr 15, 2025 pm 09:48 PM
Quelle configuration de l'ordinateur est requise pour VScode
Apr 15, 2025 pm 09:48 PM
Vs Code Système Exigences: Système d'exploitation: Windows 10 et supérieur, MacOS 10.12 et supérieur, processeur de distribution Linux: minimum 1,6 GHz, recommandé 2,0 GHz et au-dessus de la mémoire: minimum 512 Mo, recommandée 4 Go et plus d'espace de stockage: Minimum 250 Mo, recommandée 1 Go et plus d'autres exigences: connexion du réseau stable, xorg / wayland (Linux) recommandé et recommandée et plus
