

Dans git, une branche fait référence à être séparée de la ligne principale pour effectuer d'autres opérations. Elle n'affecte pas la ligne principale, et la ligne principale peut continuer à faire son travail. Elle peut être utilisée pour résoudre des besoins temporaires. La branche est terminée, elle peut être fusionnée dans la ligne principale. Lorsque la tâche de la branche est terminée, elle peut être supprimée.

L'environnement d'exploitation de ce tutoriel : système Windows 7, Git version 2.30.0, ordinateur Dell G3.
Qu'est-ce qu'une branche de git
Comme son nom l'indique, une branche est séparée de la ligne principale pour effectuer d'autres opérations sans affecter la ligne principale. est-ce un peu comme un fil de discussion ? La branche finale Une fois la tâche terminée, elle est fusionnée dans la ligne principale et la tâche de branchement est terminée et peut être supprimée. N'est-ce pas très pratique ? La ligne principale continue de faire son travail, et les branches sont utilisées pour résoudre des besoins temporaires. Les deux n'ont rien à voir l'une avec l'autre. La fonction branch de Git est particulièrement puissante. Elle n'a pas besoin de copier toutes les données tant que le pointeur de la branche est recréé pour pointer là où vous devez commencer à créer la branche de la branche (Commit). pointez vers votre dernier objet de validation, et le pointeur de la branche d'origine pointera vers l'emplacement de votre développement d'origine. Lorsque vous développerez sur quelle branche, HEAD pointera vers le dernier objet de validation de cette branche. Ce n'est pas grave si vous ne le comprenez pas clairement. Il existe d'abord un tel concept, et vous le comprendrez progressivement plus tard.
Création et fusion de branches Nous pouvons utiliser la commande git branch pour vérifier le nombre de branches de notre entrepôt git et sur quelle branche nous travaillons actuellement. Celle avec un * devant est l'endroit où nous nous trouvons. actuellement. Nous pouvons créer une branche en commandant git branch name, et le pointeur de cette branche pointe vers le dernier objet de validation, qui pointe vers le même objet que HEAD. Nous pouvons basculer vers la branche de destination via la commande git checkout name Notre branche principale par défaut est master. Lors de la création et du changement de branche, il s'agit en fait simplement de créer un pointeur pour trouver le pointeur, puis de trouver l'objet de validation pointé par le pointeur trouvé, puis de restaurer l'espace de travail vers l'instantané de fichier pointé par l'objet de validation. pour que nous puissions travailler. Lorsqu'il est soumis une fois, le pointeur pointe à nouveau vers le dernier objet soumis, ce qui est très simple.
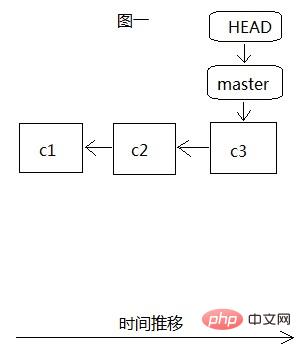
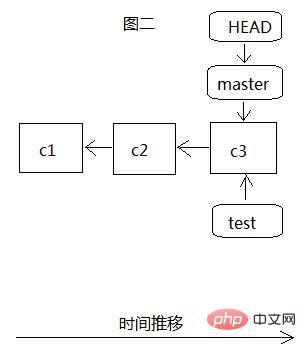 Avant d'établir la branche teset, il n'y avait qu'une seule branche master, comme le montre la figure 1. Tout notre développement se faisait sur cette branche, et HEAD pointait vers l'objet de validation le plus récemment soumis, c3. Il y avait aussi c3. Avant de soumettre c1 et c2 deux fois, nous créons la branche de test via git branch test, comme le montre la figure 2. À ce stade, HEAD pointe toujours vers le dernier c3 soumis par la branche principale lorsque git checkout test passe à. la branche de test, HEAD pointe vers la branche de test. La dernière soumission de c3, à ce moment-là, pointe en fait vers les mêmes données c3 dans .git.
Avant d'établir la branche teset, il n'y avait qu'une seule branche master, comme le montre la figure 1. Tout notre développement se faisait sur cette branche, et HEAD pointait vers l'objet de validation le plus récemment soumis, c3. Il y avait aussi c3. Avant de soumettre c1 et c2 deux fois, nous créons la branche de test via git branch test, comme le montre la figure 2. À ce stade, HEAD pointe toujours vers le dernier c3 soumis par la branche principale lorsque git checkout test passe à. la branche de test, HEAD pointe vers la branche de test. La dernière soumission de c3, à ce moment-là, pointe en fait vers les mêmes données c3 dans .git.
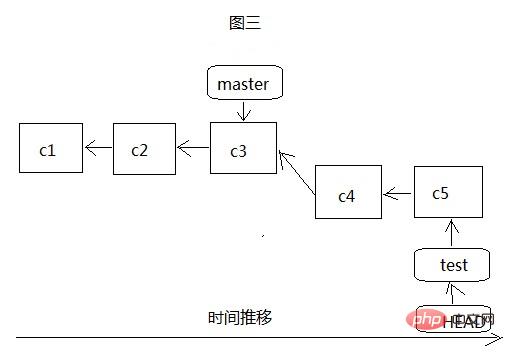 À l'heure actuelle, lorsque nous avons développé plusieurs fois sur la branche test et soumis les deux versions c4 et c5, alors test et HEAD pointent vers la dernière soumission c5 de la branche test, comme le montre la figure 3, et maîtrisez ceci Il n'y a pas encore de changement, et cela pointe toujours vers c3. Si la branche test est fusionnée dans la branche master à ce moment, alors git n'a rien à faire du tout, il suffit de déplacer la branche master vers ce point. à c5. Ce processus est appelé Avance rapide. Si la tâche de test est terminée à ce moment-là, nous pouvons la supprimer via git branch -d test et poursuivre le développement sur la branche principale principale. Si tel est le cas, alors la branche de test sera construite en vain.
À l'heure actuelle, lorsque nous avons développé plusieurs fois sur la branche test et soumis les deux versions c4 et c5, alors test et HEAD pointent vers la dernière soumission c5 de la branche test, comme le montre la figure 3, et maîtrisez ceci Il n'y a pas encore de changement, et cela pointe toujours vers c3. Si la branche test est fusionnée dans la branche master à ce moment, alors git n'a rien à faire du tout, il suffit de déplacer la branche master vers ce point. à c5. Ce processus est appelé Avance rapide. Si la tâche de test est terminée à ce moment-là, nous pouvons la supprimer via git branch -d test et poursuivre le développement sur la branche principale principale. Si tel est le cas, alors la branche de test sera construite en vain.
 Donc si un autre développement est effectué sur la branche master à ce moment et que deux versions c6 et c7 sont soumises, alors les pointeurs master et HEAD à ce moment pointent vers c7, comme le montre la figure 4, vous pouvez voir où Si vous développez sur une branche, alors HEAD pointe vers le commit sur quelle branche. Si vous fusionnez les deux branches à ce moment, ce sera comme suit.
Donc si un autre développement est effectué sur la branche master à ce moment et que deux versions c6 et c7 sont soumises, alors les pointeurs master et HEAD à ce moment pointent vers c7, comme le montre la figure 4, vous pouvez voir où Si vous développez sur une branche, alors HEAD pointe vers le commit sur quelle branche. Si vous fusionnez les deux branches à ce moment, ce sera comme suit.
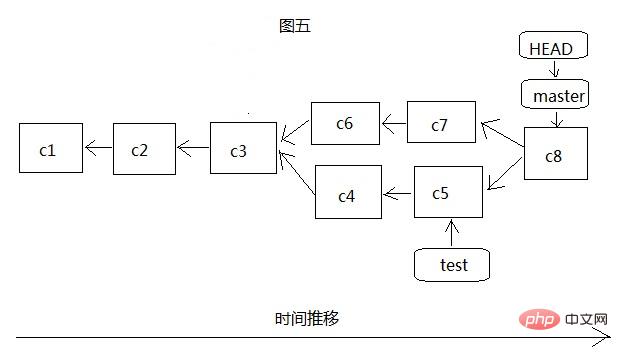
Comme le montre la figure 5, nous passons d'abord à la branche master, puis fusionnons la branche test avec la branche master via git merge test. À ce stade, git ne déplace plus simplement le pointeur, car il y a du développement des deux côtés. , donc git doit gérer à la fois les derniers commits c5 et c7 des branches et l'objet de commit ancêtre commun c3 des deux branches sont utilisés pour effectuer une simple fusion à trois, qui génère un nouvel instantané de fichier et l'enregistre avec le new commit object c8. Vous n'avez pas besoin de prêter trop d'attention à ce processus de fusion. S'il y a un conflit, c'est-à-dire que deux branches ont modifié le même fichier, alors git arrêtera l'opération de fusion, laissez-vous guider. gérer le conflit, puis soumettre (c8), puis fusionner. À l'heure actuelle, master et HEAD pointent vers c8, mais test n'a pas été déplacé. Pour le moment, vous pouvez continuer à développer sur test, puis le fusionner dans master. Si test n'a plus de valeur, vous pouvez le supprimer. .
Branche locale, branche de suivi et branche distante
Il y a trois concepts ici La branche locale est la branche que nous pouvons voir via git branch, c'est-à-dire la branche appartenant à notre propre entrepôt git, nous pouvons tous. utilisez-le. La branche distante est un index des branches de l'entrepôt distant. C'est en fait une branche locale, mais on ne peut pas la déplacer. Il faut interagir avec le serveur central et la déplacer selon le code mis à jour localement par le serveur. la branche distante est celle avec laquelle nous avons interagi pour la dernière fois. La dernière version obtenue par la mise à jour interactive du serveur central est également un pointeur. La branche de suivi est plus difficile à comprendre. C'est aussi une branche locale, mais elle correspond à une branche distante. Si l'une de nos branches locales correspond à une branche distante spécifique, alors il s'agit d'une branche de suivi. Par exemple, notre branche principale d'origine. est une branche de suivi, qui correspond à la branche distante origin/master, où origin est le nom de l'entrepôt distant lorsque l'on effectue des mises à jour (fetch, pull) ou push (push) dans la branche master, sans spécifier de branche. , la valeur par défaut est origin/. La branche master est mise à jour ou soumise à la branche origin/mster.

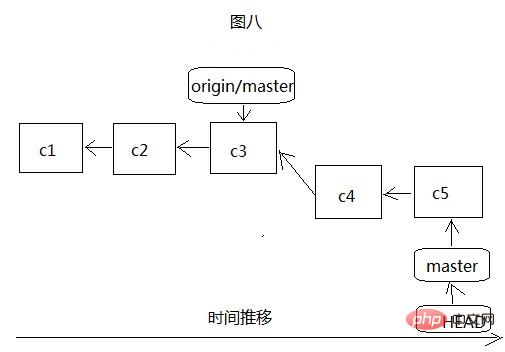
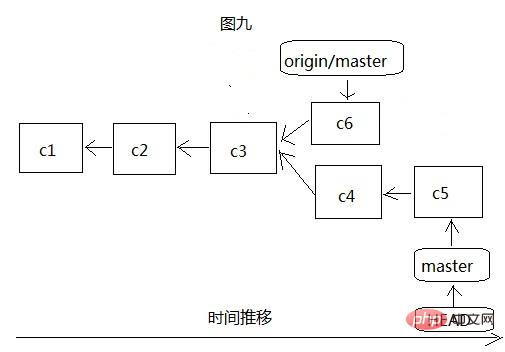
Il est facile de voir sur la Figure 7 et la Figure 8 qu'elle est très similaire à notre création de branche locale, sauf que la branche distante origin/master ne sera déplacée qu'après connexion au serveur et mise à jour du serveur code vers le local, comme le montre la figure 9 ci-dessous :
Il existe deux commandes pour mettre à jour le code à distance vers le local, récupérer et extraire les mises à jour du code à distance vers le local, mais cela n'effectuera pas la mise à jour. Opération de fusion. Vous devez le vérifier vous-même, résoudre les conflits, etc., puis l'exécuter vous-même. Merge fusionne le code mis à jour dans notre propre branche, mais pull combine ces deux opérations en une seule étape, mettant directement à jour le code du serveur et le fusionnant. dans la succursale locale désignée. Bien entendu, si vous rencontrez des conflits, vous devez les résoudre vous-même. Par conséquent, nous utilisons généralement fetch pour implémenter les mises à jour. Même si cela est un peu gênant, cela n'est pas sujet à des problèmes.
Poussez le code local vers l'entrepôt distant, c'est-à-dire le serveur central. Généralement, les données que nous transmettons sont git push origin master:master. Ici, nous spécifions le nom de l'entrepôt distant, le nom de la branche locale et la branche distante. les données de notre branche principale locale Poussez vers la branche principale de l'origine de l'entrepôt distant. Si la branche principale locale est une branche de suivi, elle trouvera la branche correspondante dans l'entrepôt distant pour transmettre les données, sauf indication contraire. Ou nous effectuons directement l'opération git push origin et spécifions uniquement le nom de l'entrepôt distant. Ensuite, git poussera les données en fonction de la branche sur laquelle nous nous trouvons actuellement et de la branche de son entrepôt distant correspondant, à condition que la branche sur laquelle nous nous trouvons actuellement soit. une branche de suivi. Bien sûr, s'il s'agit de git push origin:master, le nom de la branche locale est vide ici. Cette opération consiste à pousser la branche vide vers la branche principale de l'entrepôt distant, et le résultat est de supprimer la branche principale.
Puisque les branches de suivi sont si faciles à utiliser, comment créer des branches de suivi ? Il existe deux manières de supprimer les branches distantes et de créer des branches de suivi. Si vous ne spécifiez pas le nom de la branche de suivi, le nom par défaut. est le nom de la branche de l'entrepôt distant. Idem : git checkout --track origin/test, nous créons donc une branche de suivi nommée test Si vous renommez la branche de suivi : git checkout -b name origin/test, nous créons donc une branche de suivi. branche nommée name La branche de suivi correspond à la branche de test de l'entrepôt distant. La deuxième méthode est qu'une branche locale existe déjà et que vous souhaitez qu'elle corresponde à une branche distante pour devenir une branche de suivi. Il existe également deux commandes que vous pouvez utiliser, git branch --set-upstream test origin/test ou git branch. -f - -track test origin/test Ici, nous laissons notre branche de test locale existante suivre la branche de test distante.
gestion de la succursale git
git est si simple et rapide pour créer des branches et fusionner des branches, nous pouvons donc utiliser les branches de manière folle pendant notre processus de développement, et l'un des principaux gameplays de git est la création de branches. L'utilisation de branches est fortement recommandée, mais pouvons-nous utiliser des branches. sans scrupules ? , comment gérer la création d'autant de branches ? Il ne s'agit pas d'un trop grand nombre de branches mais juste de la bonne quantité. Si trop de branches sont créées, ce sera difficile à gérer. Par conséquent, je recommande une stratégie de gestion de branches, git. -flow, et recommande également un article Venez découvrir cette stratégie : http://nvie.com/posts/a-successful-git-branching-model/ pour rendre votre utilisation de git plus confortable.
Apprentissage recommandé : "Tutoriel Git"
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Construisez votre propre serveur git
Construisez votre propre serveur git
 La différence entre git et svn
La différence entre git et svn
 git annuler le commit soumis
git annuler le commit soumis
 Comment annuler l'erreur de commit git
Comment annuler l'erreur de commit git
 Comment comparer le contenu des fichiers de deux versions dans git
Comment comparer le contenu des fichiers de deux versions dans git
 Que faire si l'icône du bureau de l'ordinateur ne peut pas être ouverte
Que faire si l'icône du bureau de l'ordinateur ne peut pas être ouverte
 L'ordinateur est infecté et ne peut pas être allumé
L'ordinateur est infecté et ne peut pas être allumé
 impossible d'ouvrir la page Web
impossible d'ouvrir la page Web









![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



