
 base de données
tutoriel mysql
Maîtriser complètement les compétences d'indexation MySQL (partage de résumé)
base de données
tutoriel mysql
Maîtriser complètement les compétences d'indexation MySQL (partage de résumé)
Maîtriser complètement les compétences d'indexation MySQL (partage de résumé)

Cet article vous apporte des connaissances pertinentes sur les index MySQL, y compris la structure logique des instructions d'exécution MySQL et SQL. J'espère qu'il vous sera utile.

1. Architecture logique MySQL à trois niveaux
L'architecture du moteur de stockage de MySQL sépare le traitement des requêtes du stockage/récupération de données. Voici le schéma d'architecture logique de MySQL :

1 La première couche est responsable de la gestion des connexions, de l'authentification des autorisations, de la sécurité, etc.
Chaque connexion client correspond à un thread sur le serveur. Un pool de threads est maintenu sur le serveur pour éviter de créer et de détruire un thread pour chaque connexion. Lorsqu'un client se connecte à un serveur MySQL, le serveur l'authentifie. L'authentification peut être effectuée via un nom d'utilisateur et un mot de passe, ou via un certificat SSL. Une fois l'authentification de connexion réussie, le serveur vérifiera également si le client a le pouvoir d'exécuter une certaine requête.
2. La deuxième couche est chargée d'analyser la requête
compiler SQL et de l'optimiser (comme ajuster l'ordre de lecture de la table, sélectionner les index appropriés, etc.). Pour les instructions SELECT, avant d'analyser la requête, le serveur vérifiera d'abord le cache de requête si le résultat de la requête correspondant peut y être trouvé, le résultat de la requête sera renvoyé directement sans avoir besoin d'analyser la requête, d'optimiser, etc. Les procédures stockées, les déclencheurs, les vues, etc. sont tous implémentés dans cette couche.
3. La troisième couche est le moteur de stockage
Le moteur de stockage est responsable du stockage des données dans MySQL, de l'extraction des données, du démarrage d'une transaction, etc. Le moteur de stockage communique avec la couche supérieure via des API. Ces API masquent les différences entre les différents moteurs de stockage, rendant ces différences transparentes pour le processus de requête de la couche supérieure. Le moteur de stockage n'analysera pas SQL.
2. Comparaison entre InnoDB et MyISAM
1 Structure de stockage
MyISAM : Chaque MyISAM est stocké sous forme de trois fichiers sur le disque. Il s'agit des fichiers de définition de table, des fichiers de données et des fichiers d'index. Le nom du premier fichier commence par le nom de la table et l'extension indique le type de fichier. Les fichiers .frm stockent les définitions de table. L'extension du fichier de données est .MYD (MYData). L'extension du fichier d'index est .MYI (MYIndex).
InnoDB : Toutes les tables sont stockées dans le même fichier de données (ou dans plusieurs fichiers, ou dans des fichiers d'espace table indépendants). La taille de la table InnoDB n'est limitée que par la taille du fichier du système d'exploitation, qui est généralement de 2 Go.
2. Espace de stockage
MyISAM : MyISAM prend en charge trois formats de stockage différents : table statique (par défaut, mais veuillez noter qu'il ne peut pas y avoir d'espaces à la fin des données, elles seront supprimées), table dynamique et compressée. tableau. Une fois la table créée et les données importées, elle ne sera pas modifiée. Vous pouvez utiliser des tables compressées pour réduire considérablement l'utilisation de l'espace disque.
InnoDB : nécessite plus de mémoire et de stockage, il établira son propre pool de tampons dédié dans la mémoire principale pour la mise en cache des données et des index.
3. Portabilité, sauvegarde et récupération
MyISAM : Les données sont stockées sous forme de fichiers, elles sont donc très pratiques pour le transfert de données multiplateforme. Vous pouvez effectuer des opérations sur une table individuellement pendant la sauvegarde et la restauration.
InnoDB : les solutions gratuites incluent la copie de fichiers de données, la sauvegarde du binlog ou l'utilisation de mysqldump, ce qui est relativement pénible lorsque le volume de données atteint des dizaines de gigaoctets.
4. Prise en charge des transactions
MyISAM : L'accent est mis sur les performances. Chaque requête est atomique et ses temps d'exécution sont plus rapides que le type InnoDB, mais elle ne fournit pas de prise en charge des transactions.
InnoDB : fournit une prise en charge des transactions, des clés étrangères et d'autres fonctions de base de données avancées. Tables sécurisées pour les transactions (conformes à l'ACID) avec capacités de transaction (validation), de restauration (rollback) et de récupération après incident.
5. AUTO_INCREMENT
MyISAM : Vous pouvez créer un index commun avec d'autres champs. La colonne de croissance automatique du moteur doit être un index. S'il s'agit d'un index combiné, la colonne de croissance automatique n'a pas besoin d'être la première colonne. Elle peut être triée selon les colonnes précédentes puis incrémentée.
InnoDB : InnoDB doit contenir un index avec uniquement ce champ. La colonne à croissance automatique du moteur doit être un index, et s'il s'agit d'un index composite, elle doit également être la première colonne de l'index composite.
6. Différences de verrouillage de table
MyISAM : seuls les verrous au niveau de la table sont pris en charge. Lorsque les utilisateurs utilisent des tables myisam, les instructions select, update, delete et insert verrouillent automatiquement la table si la table verrouillée répond à la concurrence d'insertion. Dans ce cas, de nouvelles données peuvent être insérées en fin de tableau.
InnoDB : la prise en charge des transactions et des verrous au niveau des lignes est la fonctionnalité la plus importante d'InnoDB. Les verrous de ligne améliorent considérablement les performances des opérations simultanées multi-utilisateurs. Cependant, le verrouillage de ligne d'InnoDB n'est valable que sur la clé primaire de WHERE. Toute clé non primaire WHERE verrouillera la table entière.
7. Index de texte intégral
MyISAM : prend en charge l'index de texte intégral de type FULLTEXT
InnoDB : ne prend pas en charge l'index de texte intégral de type FULLTEXT, mais innodb peut utiliser le plug-in sphinx pour prendre en charge l'indexation de texte intégral , et l'effet est meilleur.
8. Clé primaire de table
MyISAM : permet aux tables sans index ni clés primaires d'exister. Les index sont les adresses où les lignes sont enregistrées.
InnoDB : Si aucune clé primaire ou index unique non vide n'est défini, une clé primaire de 6 octets (invisible pour l'utilisateur) sera automatiquement générée. Les données font partie de l'index primaire, et l'index supplémentaire enregistre la valeur de. l'indice primaire.
9. Le nombre spécifique de lignes dans le tableau
MyISAM : enregistre le nombre total de lignes dans le tableau. Si vous sélectionnez count() dans le tableau ;, la valeur sera supprimée directement.
InnoDB : le nombre total de lignes dans la table n'est pas enregistré. Si vous utilisez select count(*) from table ; il parcourra toute la table, ce qui consomme beaucoup d'argent. myisam et innodb le gèrent de la même manière.
10. Opérations CRUD
MyISAM : Si vous exécutez un grand nombre de SELECT, MyISAM est un meilleur choix.
InnoDB : Si vos données effectuent beaucoup d'INSERT ou de UPDATE, vous devez utiliser une table InnoDB pour des raisons de performances.
11. Clés étrangères
MyISAM : non pris en charge
InnoDB : pris en charge
3. Introduction à l'optimisation SQL
1. Dans quelles circonstances l'optimisation SQL doit-elle être effectuée
Faibles performances, exécution trop longue ? temps, temps d'attente trop long, requête de connexion, échec d'index.
2. Processus d'exécution des instructions SQL
(1) Processus d'écriture
select distinct ... from ... join ... on ... where ... group by ... having ... order by ... limit ...
(2) Processus d'analyse
from ... on ... join ... where ... group by ... having ... select distinct ... order by ... limit ...
3. L'optimisation SQL consiste à optimiser l'index
L'index est équivalent à la table des matières. du livre.
La structure de données de l'index est un arbre B+.
4. Index
1. Avantages de l'index
(1) Améliorer l'efficacité des requêtes (réduire l'utilisation des E/S)
(2) Réduire l'utilisation du processeur
Par exemple, l'ordre des requêtes par âge, en raison du B+. arbre d'index Il est trié par lui-même, donc si l'index est déclenché par des requêtes ultérieures, il n'est pas nécessaire d'effectuer une nouvelle requête.
2. Inconvénients de l'index
(1) L'index lui-même est volumineux et peut être stocké en mémoire ou sur le disque dur, généralement sur le disque dur.
(2) Les index ne sont pas utilisés dans toutes les situations, comme ① une petite quantité de données ② des champs qui changent fréquemment ③ des champs rarement utilisés
(3) Les index réduiront l'efficacité des ajouts, des suppressions et des modifications
3. Classification de l'index
(1) Index à valeur unique
(2) Index unique
(3) Index union
(4) Index de clé primaire
Remarque : La seule différence entre l'index unique et l'index de clé primaire : clé primaire l'index ne peut pas être nul
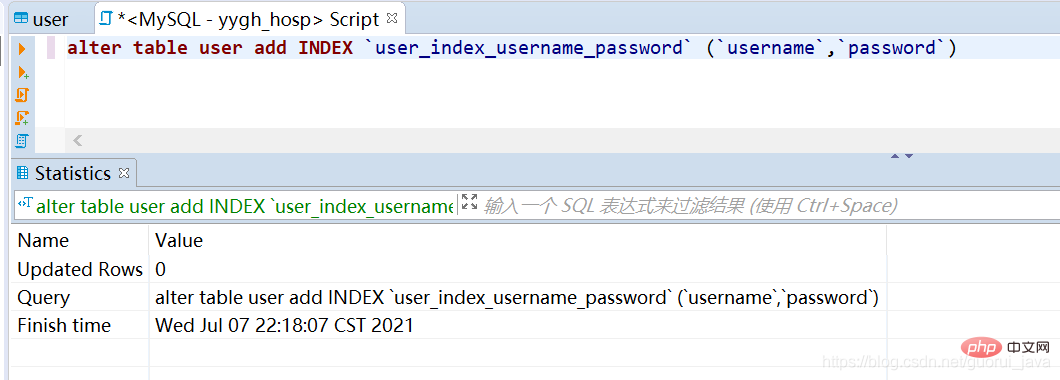
4. Créer un index
alter table user add INDEX `user_index_username_password` (`username`,`password`)
5. Principe de l'index MySQL -> Arbre B+
La structure de données sous-jacente de l'index MySQL est un arbre B+
B+Tree est une optimisation basée sur B-Tree, le rendant plus adapté à la mise en œuvre d'une structure d'index de stockage externe, le moteur de stockage InnoDB utilise B+Tree pour implémenter sa structure d'index.
Chaque nœud du diagramme de structure B-Tree contient non seulement la valeur clé des données, mais également la valeur des données. L'espace de stockage de chaque page est limité. Si les données sont volumineuses, le nombre de clés pouvant être stockées dans chaque nœud (c'est-à-dire une page) sera très faible. Lorsque la quantité de données stockées est importante, cela entraînera également. à B- La profondeur de l'arborescence est plus grande, ce qui augmente le nombre d'E/S disque pendant la requête, affectant ainsi l'efficacité de la requête. Dans B+Tree, tous les nœuds d'enregistrement de données sont stockés sur les nœuds feuilles dans la même couche par ordre de valeur clé. Seules les informations sur les valeurs clés sont stockées sur les nœuds non feuilles. Cela peut augmenter considérablement le nombre de valeurs clés stockées dans chacun. node. , réduisez la hauteur de B+Tree.
B+Tree présente plusieurs différences par rapport à B-Tree :
Les nœuds non-feuilles stockent uniquement les informations sur les valeurs clés.
Il existe un pointeur de lien entre tous les nœuds feuilles.
Les enregistrements de données sont stockés dans des nœuds feuilles.
Optimisez le B-Tree dans la section précédente. Étant donné que les nœuds non-feuilles de B+Tree stockent uniquement les informations sur les valeurs clés, en supposant que chaque bloc de disque puisse stocker 4 valeurs clés et des informations de pointeur, il deviendra la structure de B. +Tree. Comme le montre la figure ci-dessous :
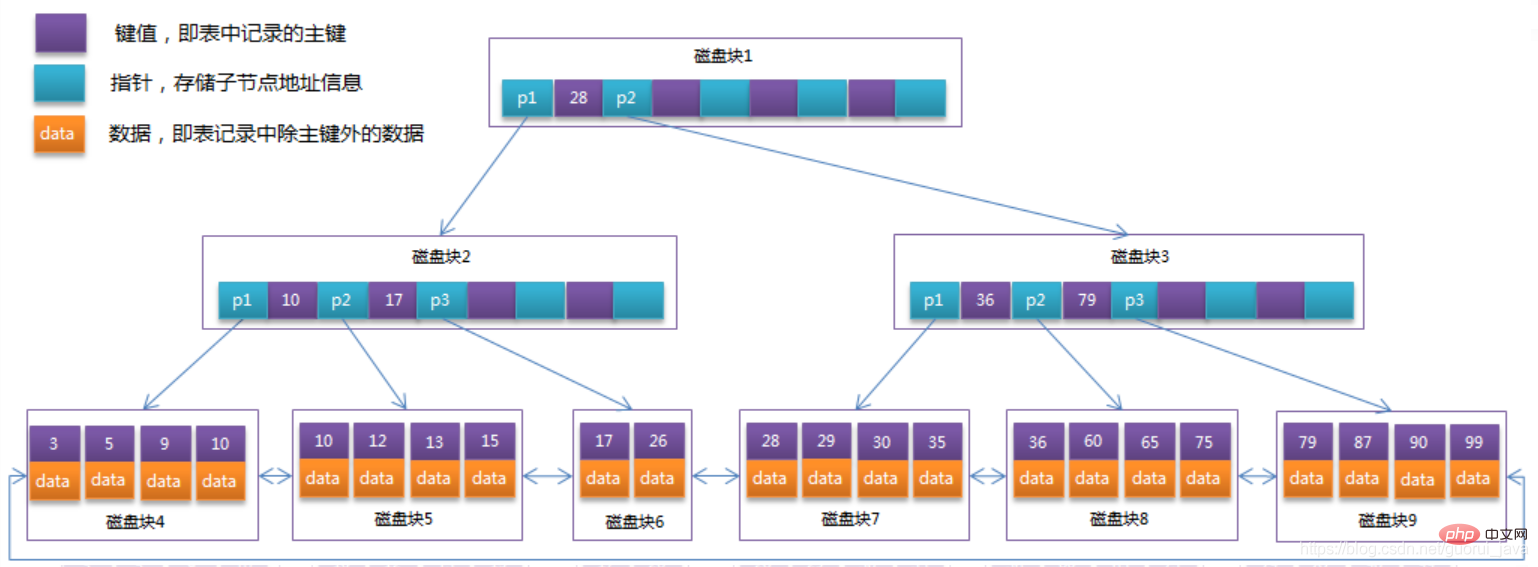
Il y a généralement deux pointeurs de tête sur B+Tree, l'un pointe vers le nœud racine et l'autre vers le nœud feuille avec le plus petit mot-clé, et il existe une sorte de relation entre tous les nœuds feuilles (c'est-à-dire les nœuds de données). Par conséquent, deux opérations de recherche peuvent être effectuées sur B+Tree : l’une est une recherche par plage et une recherche par pagination pour la clé primaire, et l’autre est une recherche aléatoire à partir du nœud racine.
Peut-être qu'il n'y a que 22 enregistrements de données dans l'exemple ci-dessus et que les avantages de B+Tree ne sont pas visibles. Voici un calcul :
La taille de la page dans le moteur de stockage InnoDB est de 16 Ko et le type de clé primaire du. la table générale est la section INT (occupe 4 mots)) ou BIGINT (occupe 8 octets), le type de pointeur est généralement de 4 ou 8 octets, ce qui signifie qu'une page (un nœud dans B+Tree) stocke environ 16 Ko/(8B+8B )=1K valeur clé (car il s'agit d'une estimation, pour faciliter le calcul, la valeur de K ici est 〖10〗^3). En d'autres termes, un index B+Tree d'une profondeur de 3 peut conserver 10^3 * 10^3 * 10^3 = 1 milliard d'enregistrements.
Dans les situations réelles, chaque nœud peut ne pas être entièrement rempli, donc dans la base de données, la hauteur de B+Tree est généralement de 2 à 4 couches. Le moteur de stockage InnoDB de MySQL est conçu de telle sorte que le nœud racine réside en mémoire, ce qui signifie que seules 1 à 3 opérations d'E/S disque sont nécessaires pour trouver l'enregistrement de ligne d'une certaine valeur de clé.
L'index B+Tree dans la base de données peut être divisé en index clusterisé et index secondaire. L'exemple de diagramme B+Tree ci-dessus est implémenté dans la base de données en tant qu'index clusterisé. Les nœuds feuilles du B+Tree de l'index clusterisé stockent les données d'enregistrement de ligne de la table entière. La différence entre un index auxiliaire et un index clusterisé est que les nœuds feuilles de l'index auxiliaire ne contiennent pas toutes les données de l'enregistrement de ligne, mais la clé d'index clusterisé qui stocke les données de ligne correspondantes, c'est-à-dire la clé primaire. Lors de l'interrogation de données via l'index auxiliaire, le moteur de stockage InnoDB parcourra l'index auxiliaire pour trouver la clé primaire, puis trouvera les données complètes de l'enregistrement de ligne dans l'index clusterisé via la clé primaire.
5. Comment déclencher l'index conjoint
1. Créez un index conjoint sur la table utilisateur nom d'utilisateur, mot de passe
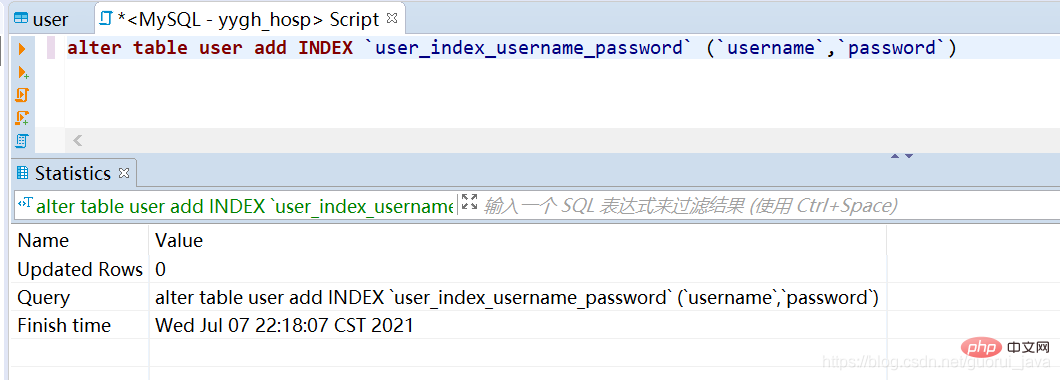
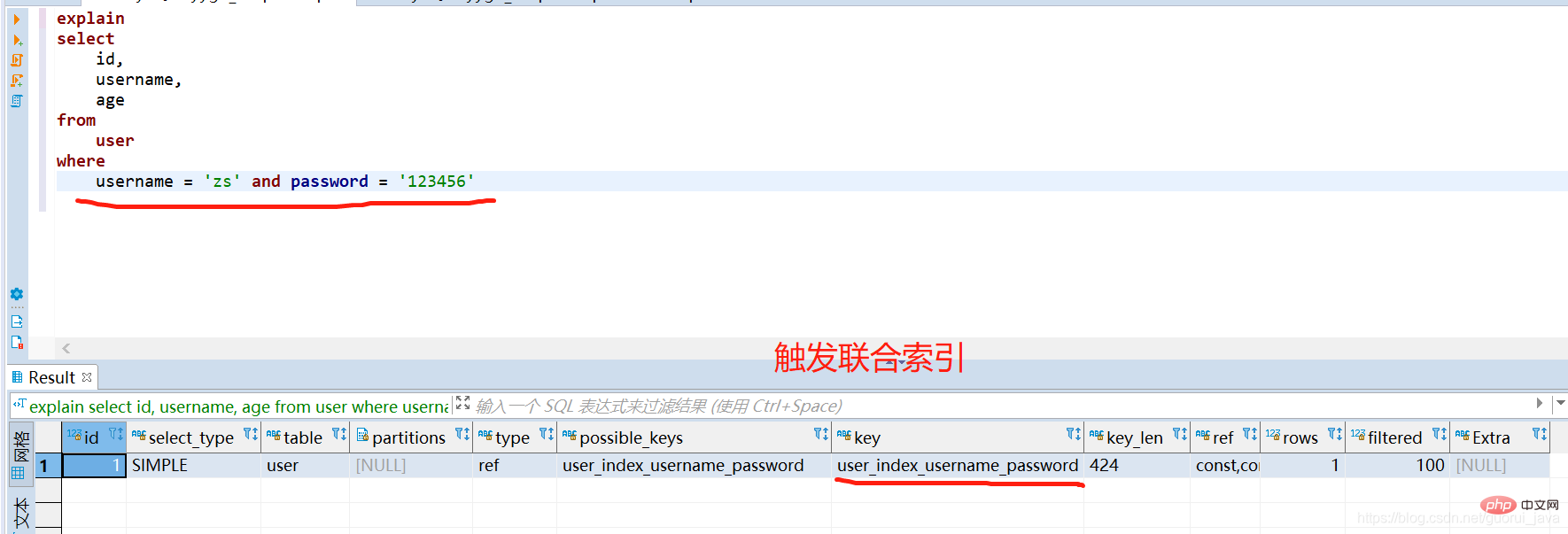
2. Déclenchez l'index conjoint
(1) Utilisez toutes les clés d'index de l'index conjoint. pour déclencher l'index conjoint
(2) En utilisant toutes les touches d'index de l'index conjoint, mais en se connectant avec ou, l'index conjoint ne peut pas être déclenché
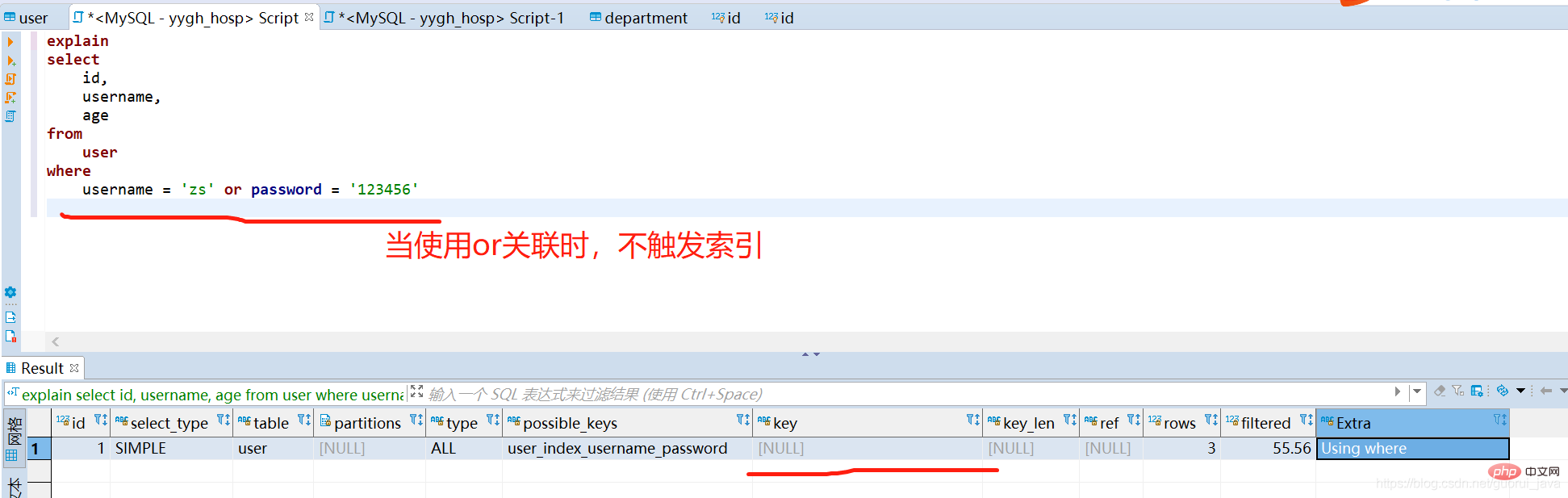
(3) Lorsque le premier champ à gauche de l'index conjoint est utilisé seul, l'index conjoint peut être déclenché

(4) Lors de l'utilisation d'autres champs de l'index conjoint seul, l'index conjoint ne peut pas être déclenché

6. Analyser le plan d'exécution de SQL ---explain
explain peut simuler l'optimisation SQL pour exécuter des instructions SQL.
1. Introduction à l'utilisation d'explication
(1) Table des utilisateurs

(2) Table des départements
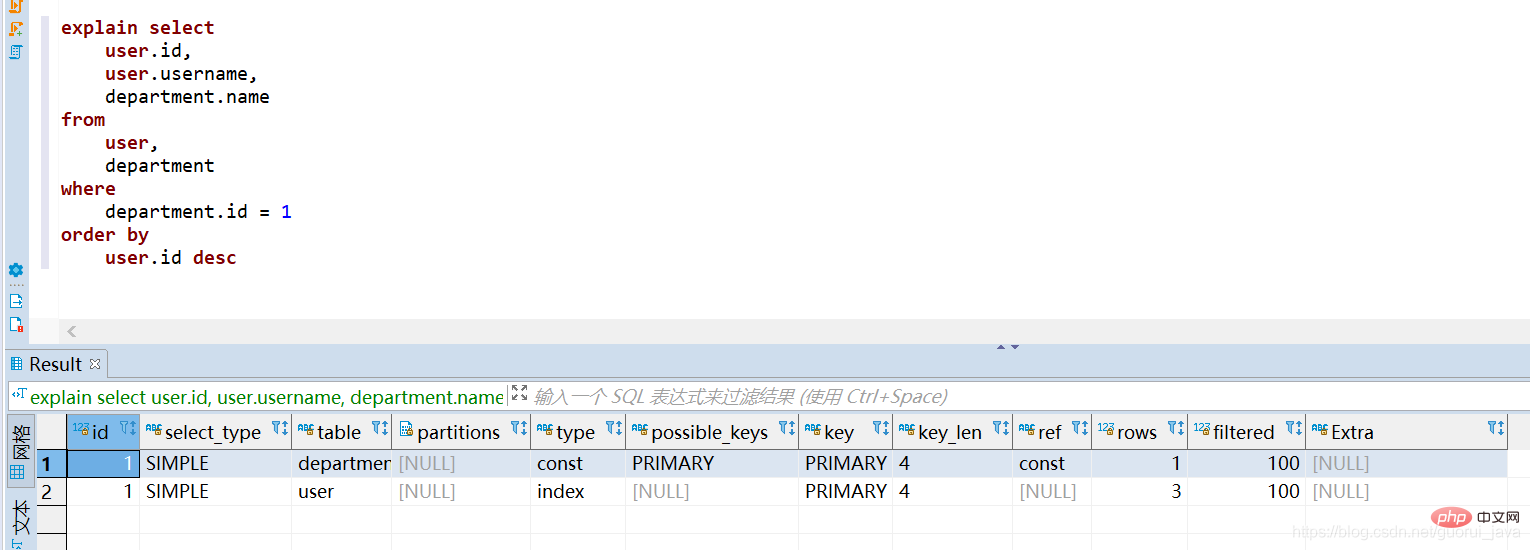
(3) Index non déclenché
(4) Index déclenché
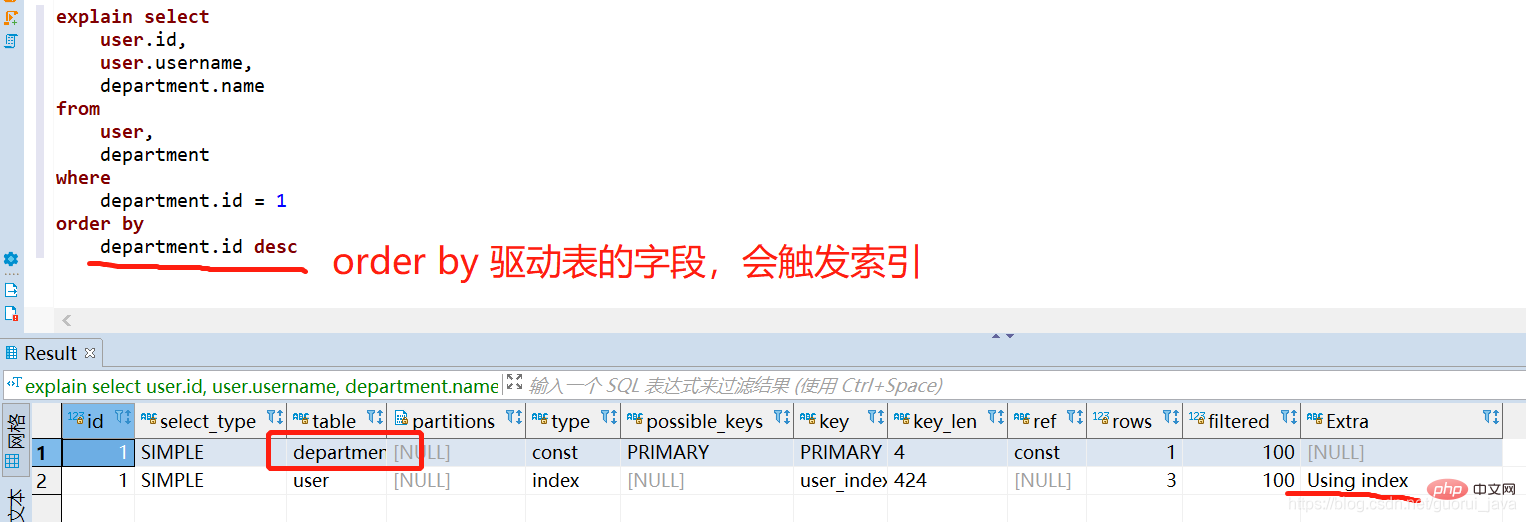
(5) Analyse des résultats Le tableau apparaissant dans la première ligne d'explication est le tableau des pilotes.
Lorsque la condition de jointure est spécifiée, la table avec les quelques lignes qui satisfont à la condition de requête est [Driven Table]
- Lorsque la condition de jointure n'est pas spécifiée, la table avec les quelques lignes est [Driven Table ]
- Le tri direct de la table pilotée déclenchera l'index, tandis que le tri de la table non pilotée ne déclenchera pas l'index.
- PRIMARY : SELECT le plus à l'extérieur
- UNION : la deuxième ou la dernière de l'instruction UNION SELECT
- DEPENDENT UNION : la deuxième instruction SELECT ou les suivantes dans l'UNION, en fonction de la requête externe
- UNION RESULT : le résultat de l'UNION
- SUBQUERY : la première dans la sous-requête SELECT
- DEPENDENT SUBQUERY : Le premier SELECT de la sous-requête, dépend de la requête externe
- DERIVED : SELECT de la table dérivée (sous-requête de la clause FROM)
- (3) table : nom de la table
- const : La table comporte au plus une ligne correspondante, qui sera lue au début de la requête. Puisqu'il n'y a qu'une seule ligne, les valeurs des colonnes de cette ligne peuvent être traitées comme des constantes par le reste de l'optimiseur. const est utilisé lors de la comparaison de toutes les parties d’un index PRIMARY KEY ou UNIQUE avec une valeur constante.
- eq_ref : Pour chaque combinaison de lignes du tableau précédent, lisez une ligne de ce tableau. C'est probablement le meilleur type de jointure, outre les types const. Il est utilisé lorsque toutes les parties d'un index sont utilisées dans la jointure et que l'index est UNIQUE ou PRIMARY KEY. eq_ref peut être utilisé sur des colonnes indexées comparées à l'aide de l'opérateur =. La valeur de comparaison peut être une constante ou une expression qui utilise une colonne du tableau lu avant ce tableau.
- ref : Pour chaque combinaison de lignes du tableau précédent, toutes les lignes avec des valeurs d'index correspondantes seront lues dans ce tableau. Utilisez ref si la jointure utilise uniquement le préfixe le plus à gauche de la clé, ou si la clé n'est pas UNIQUE ou PRIMARY KEY (en d'autres termes, si la jointure ne peut pas sélectionner une seule ligne en fonction de la clé). Ce type de jointure convient si vous utilisez des clés qui correspondent uniquement à un petit nombre de lignes. ref peut être utilisé sur les colonnes indexées à l'aide des opérateurs = ou <=>
- ref_or_null : ce type de jointure est comme ref, mais ajoute MySQL pour rechercher spécifiquement les lignes contenant des valeurs NULL. Ce type d'optimisation de jointure est souvent utilisé pour résoudre des sous-requêtes.
index_merge : Ce type de jointure indique que la méthode d'optimisation de fusion d'index est utilisée. Dans ce cas, la colonne clé contient la liste des index utilisés, et key_len contient l'élément clé le plus long de l'index utilisé.
unique_subquery : Ce type remplace la référence de la sous-requête IN sous la forme suivante : value IN (SELECT Primary_key FROM single_table WHERE some_expr) ; unique_subquery est une fonction de recherche d'index qui peut remplacer complètement la sous-requête et est plus efficace.
index_subquery : ce type de jointure est similaire à unique_subquery. Les sous-requêtes IN peuvent être remplacées, mais uniquement pour les index non uniques dans les sous-requêtes du formulaire : value IN (SELECT key_column FROM single_table WHERE some_expr)
-
range : récupère uniquement une plage donnée de lignes, utilise un index pour sélectionner les lignes. La colonne clé indique quel index a été utilisé. key_len contient l'élément clé le plus long de l'index utilisé. La colonne ref est NULL dans ce type. Lorsque vous utilisez les opérateurs =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN ou IN, vous pouvez utiliser range
lorsque vous comparez des colonnes clés avec des constantes -
index : Ce type de jointure est le même que ALL, sauf que seule l'arborescence d'index est analysée. C'est généralement plus rapide que ALL car les fichiers d'index sont généralement plus petits que les fichiers de données.
all : effectuez une analyse complète du tableau pour chaque combinaison de lignes du tableau précédent. Ce n'est généralement pas bon si la table est la première à ne pas être marquée const, et c'est généralement mauvais dans ce cas. Vous pouvez généralement ajouter plus d'index sans utiliser ALL afin que les lignes puissent être récupérées en fonction de valeurs constantes ou de valeurs de colonne dans le tableau précédent.
(5) possible_keys : La colonne possible_keys indique quel index MySQL peut utiliser pour trouver des lignes dans la table. Notez que cette colonne est complètement indépendante de l'ordre des tableaux affichés dans la sortie EXPLAIN. Cela signifie que certaines clés de possible_keys ne peuvent pas réellement être utilisées dans l'ordre de la table générée.
(6) clé : la colonne clé affiche la clé (index) que MySQL a réellement décidé d'utiliser. Si aucun index n'est sélectionné, la clé est NULL. Pour forcer MySQL à utiliser ou ignorer l'index sur la colonne possible_keys, utilisez FORCE INDEX, USE INDEX ou IGNORE INDEX dans la requête.
(7) key_len : La colonne key_len affiche la longueur de clé que MySQL décide d'utiliser. Si la clé est NULL, la longueur est NULL. Notez qu'en utilisant la valeur key_len, nous pouvons déterminer quelles parties d'un mot-clé en plusieurs parties MySQL utilisera réellement.
(8) ref : La colonne ref indique quelle colonne ou constante est utilisée avec la clé pour sélectionner les lignes du tableau.
(9) lignes : la colonne lignes indique le nombre de lignes que MySQL pense devoir vérifier lors de l'exécution de la requête.
(10)Extra : cette colonne contient des détails sur la façon dont MySQL a résolu la requête.
Distinct : une fois que MySQL a trouvé la première ligne correspondante, il arrête de rechercher d'autres lignes pour la combinaison de lignes actuelle.
N'existe pas : MySQL peut effectuer une optimisation LEFT JOIN sur la requête. Après avoir trouvé une ligne correspondant à la norme LEFT JOIN, il ne vérifiera plus d'autres lignes dans le tableau pour la combinaison de lignes précédente.
plage vérifiée pour chaque enregistrement (carte d'index : #) : MySQL n'a pas trouvé un bon index pouvant être utilisé, mais a constaté que si les valeurs de colonne de la table précédente sont connues, certains index peuvent être utilisés. Pour chaque combinaison de lignes du tableau précédent, MySQL vérifie si les lignes peuvent être récupérées à l'aide des méthodes d'accès range ou index_merge.
Utilisation du tri de fichiers : MySQL nécessite une passe supplémentaire pour comprendre comment récupérer les lignes dans l'ordre trié. Le tri est effectué en parcourant toutes les lignes en fonction du type de jointure et en enregistrant la clé de tri et le pointeur vers la ligne pour toutes les lignes correspondant à la clause WHERE. Les clés sont ensuite triées et les lignes sont récupérées dans l'ordre trié.
Utilisation de l'index : récupérez les informations de colonne d'une table en lisant les lignes réelles en utilisant uniquement les informations de l'arborescence d'index sans autre recherche. Cette stratégie peut être utilisée lorsque la requête utilise uniquement des colonnes faisant partie d'un seul index.
Utilisation de temporaire : afin de résoudre la requête, MySQL doit créer une table temporaire pour accueillir les résultats. Une situation typique est celle où la requête contient des clauses GROUP BY et ORDER BY qui peuvent répertorier les colonnes en fonction de différentes situations.
Utilisation de Where : la clause WHERE est utilisée pour limiter quelle ligne correspond à la table suivante ou est envoyée au client. Sauf si vous demandez ou vérifiez spécifiquement toutes les lignes de la table, la requête peut contenir des erreurs si la valeur Extra n'est pas Using Where et que le type de jointure de la table est ALL ou index.
Using sort_union(...), Using union(...), Using intersect(...) : Ces fonctions illustrent comment fusionner des analyses d'index pour le type de jointure index_merge.
Utilisation de l'index pour le group-by : similaire à la méthode Using index pour accéder à une table, l'utilisation de l'index pour le group-by signifie que MySQL a trouvé un index qui peut être utilisé pour interroger toutes les colonnes des requêtes GROUP BY ou DISTINCT sans recherches supplémentaires. Accès au disque dur à la table réelle. Utilisez également l'index de la manière la plus efficace possible afin que pour chaque groupe, seules quelques entrées d'index soient lues.
En multipliant toutes les valeurs de la colonne des lignes de la sortie EXPLAIN, vous pouvez obtenir un indice sur le déroulement d'une jointure. Cela devrait vous indiquer approximativement combien de lignes MySQL doit vérifier pour exécuter la requête. Ce produit est également utilisé pour déterminer quelle instruction SELECT multi-table exécuter lorsque vous utilisez la variable max_join_size pour limiter une requête.
Apprentissage recommandé : Tutoriel vidéo mysql
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Plusieurs situations d'échec de l'index MySQL
Feb 21, 2024 pm 04:23 PM
Plusieurs situations d'échec de l'index MySQL
Feb 21, 2024 pm 04:23 PM
Situations courantes : 1. Utiliser des fonctions ou des opérations ; 2. Conversion de type implicite ; 3. Utiliser différent de (!= ou <>) ; 4. Utiliser l'opérateur LIKE et commencer par un caractère générique ; Valeur : 7. Faible sélectivité de l'indice ; 8. Principe du préfixe le plus à gauche de l'indice composite ; 9. Décision de l'optimiseur ;
 Dans quelles circonstances l'index MySQL échouera-t-il ?
Aug 09, 2023 pm 03:38 PM
Dans quelles circonstances l'index MySQL échouera-t-il ?
Aug 09, 2023 pm 03:38 PM
Les index MySQL échoueront lors d'une requête sans utilisation de colonnes d'index, de types de données incompatibles, d'une utilisation inappropriée des index de préfixe, de l'utilisation de fonctions ou d'expressions pour les requêtes, d'un ordre incorrect des colonnes d'index, de mises à jour fréquentes des données et d'un trop grand ou trop peu d'index. 1. N'utilisez pas de colonnes d'index pour les requêtes. Afin d'éviter cette situation, vous devez utiliser des colonnes d'index appropriées dans la requête. 2. Les types de données ne correspondent pas. Lors de la conception de la structure de la table, vous devez vous assurer que les colonnes d'index correspondent. types de données de la requête ; 3. , Utilisation inappropriée de l'index de préfixe, vous pouvez utiliser l'index de préfixe.
 Règles de correspondance du préfixe gauche de l'index MySQL
Feb 24, 2024 am 10:42 AM
Règles de correspondance du préfixe gauche de l'index MySQL
Feb 24, 2024 am 10:42 AM
Principe de l'indexation MySQL le plus à gauche et exemples de code Dans MySQL, l'indexation est l'un des moyens importants pour améliorer l'efficacité des requêtes. Parmi eux, le principe de l'index le plus à gauche est un principe important que nous devons suivre lors de l'utilisation des index pour optimiser les requêtes. Cet article présentera le principe du principe le plus à gauche de l'index MySQL et donnera quelques exemples de code spécifiques. 1. Principe du principe de l'index le plus à gauche Le principe de l'index le plus à gauche signifie que dans un index, si la condition de requête est composée de plusieurs colonnes, alors seule la requête basée sur la colonne la plus à gauche de l'index peut satisfaire pleinement les conditions de requête.
 Quelles sont les classifications des index MySQL ?
Apr 22, 2024 pm 07:12 PM
Quelles sont les classifications des index MySQL ?
Apr 22, 2024 pm 07:12 PM
Les index MySQL sont divisés dans les types suivants : 1. Index ordinaire : correspond à la valeur, à la plage ou au préfixe ; 2. Index unique : garantit que la valeur est unique 3. Index de clé primaire : index unique de la colonne de clé primaire ; index clé : pointe vers la clé primaire d'une autre table ; 5. Index en texte intégral : recherche en texte intégral ; 6. Index de hachage : recherche par correspondance égale 7. Index spatial : recherche géospatiale 8. Index composite : recherche basée sur plusieurs ; Colonnes.
 Quand une analyse de table complète pourrait-elle être plus rapide que d'utiliser un index dans MySQL?
Apr 09, 2025 am 12:05 AM
Quand une analyse de table complète pourrait-elle être plus rapide que d'utiliser un index dans MySQL?
Apr 09, 2025 am 12:05 AM
La numérisation complète de la table peut être plus rapide dans MySQL que l'utilisation d'index. Les cas spécifiques comprennent: 1) le volume de données est petit; 2) Lorsque la requête renvoie une grande quantité de données; 3) Lorsque la colonne d'index n'est pas très sélective; 4) Lorsque la requête complexe. En analysant les plans de requête, en optimisant les index, en évitant le sur-index et en maintenant régulièrement des tables, vous pouvez faire les meilleurs choix dans les applications pratiques.
 Expliquez différents types d'index MySQL (B-Tree, hachage, texte intégral, spatial).
Apr 02, 2025 pm 07:05 PM
Expliquez différents types d'index MySQL (B-Tree, hachage, texte intégral, spatial).
Apr 02, 2025 pm 07:05 PM
MySQL prend en charge quatre types d'index: B-Tree, hachage, texte intégral et spatial. 1. L'indice de tree B est adapté à la recherche de valeur égale, à la requête de plage et au tri. 2. L'indice de hachage convient aux recherches de valeur égale, mais ne prend pas en charge la requête et le tri des plages. 3. L'index de texte complet est utilisé pour la recherche en texte intégral et convient pour le traitement de grandes quantités de données de texte. 4. L'indice spatial est utilisé pour la requête de données géospatiaux et convient aux applications SIG.
 Stratégies d'optimisation des performances pour la mise à jour des données et la maintenance des index PHP et MySQL et leur impact sur les performances
Oct 15, 2023 pm 12:15 PM
Stratégies d'optimisation des performances pour la mise à jour des données et la maintenance des index PHP et MySQL et leur impact sur les performances
Oct 15, 2023 pm 12:15 PM
Stratégies d'optimisation des performances pour la mise à jour des données et la maintenance des index PHP et MySQL et leur impact sur les performances Résumé : Dans le développement de PHP et MySQL, les index sont un outil important pour optimiser les performances des requêtes de base de données. Cet article présentera les principes de base et l'utilisation des index, et explorera l'impact des index sur les performances sur la mise à jour et la maintenance des données. Parallèlement, cet article fournit également des stratégies d'optimisation des performances et des exemples de code spécifiques pour aider les développeurs à mieux comprendre et appliquer les index. Principes de base et utilisation des index Dans MySQL, un index est un nombre spécial
 Comment utiliser les index MySQL de manière rationnelle et optimiser les performances des bases de données ? Concevez des protocoles que les étudiants techniques doivent connaître !
Sep 10, 2023 pm 03:16 PM
Comment utiliser les index MySQL de manière rationnelle et optimiser les performances des bases de données ? Concevez des protocoles que les étudiants techniques doivent connaître !
Sep 10, 2023 pm 03:16 PM
Comment utiliser les index MySQL de manière rationnelle et optimiser les performances des bases de données ? Concevez des protocoles que les étudiants techniques doivent connaître ! Introduction : À l'ère d'Internet d'aujourd'hui, la quantité de données continue de croître et l'optimisation des performances des bases de données est devenue un sujet très important. MySQL étant l’une des bases de données relationnelles les plus populaires, l’utilisation rationnelle des index est cruciale pour améliorer les performances des bases de données. Cet article explique comment utiliser les index MySQL de manière rationnelle, optimise les performances de la base de données et fournit quelques règles de conception aux étudiants en technique. 1. Pourquoi utiliser des index ? Un index est une structure de données qui utilise
