
 base de données
tutoriel mysql
Maîtriser complètement les principes MySQL et la conception de l'architecture du moteur de stockage InnoDB
base de données
tutoriel mysql
Maîtriser complètement les principes MySQL et la conception de l'architecture du moteur de stockage InnoDB
Maîtriser complètement les principes MySQL et la conception de l'architecture du moteur de stockage InnoDB

Cet article vous apporte des connaissances pertinentes sur la conception de l'architecture du moteur de stockage InnoDB dans le principe MySQL. J'espère qu'il vous sera utile.

Structure des composants InnoDB :
pool de tampons : pool de tampons, données du disque de cache
tampon de journalisation : enregistrer les opérations sur le pool de tampons, écrire sur le disque conformément à la politique pour éviter les temps d'arrêt, mais la transaction a été soumis et perte de données
journal d'annulation : lorsque les données du pool de mémoire tampon sont modifiées, elles peuvent être annulées lorsque la transaction n'est pas soumise. L'ancienne valeur est écrite dans le fichier journal d'annulation pour faciliter l'annulation. temps, les données dans le pool de tampons L'incohérence avec le disque sont des données sales
1. Buffer Pool
Supposons qu'il y ait une instruction de mise à jour :
update users set name = 'lisi' where id = 1
doit être mis à jour dans la base de données, quelles opérations InnoDB effectuera-t-il ?
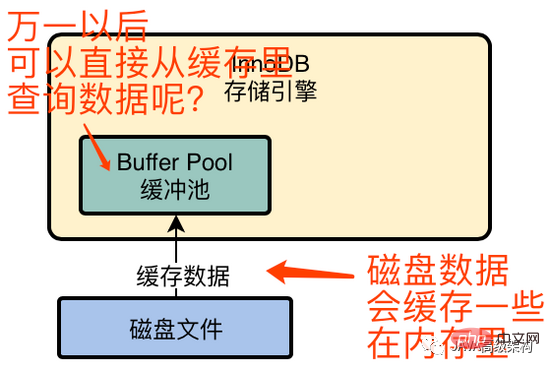
Tout d'abord, InnoDB vérifiera si les données avec l'id = 1 existent dans le pool de tampons. Si elles n'existent pas, elles seront chargées depuis le disque dans le pool de tampons et ajouteront également un verrou exclusif. cette ligne de données pour empêcher plusieurs sql Modifiez également cette ligne de données.
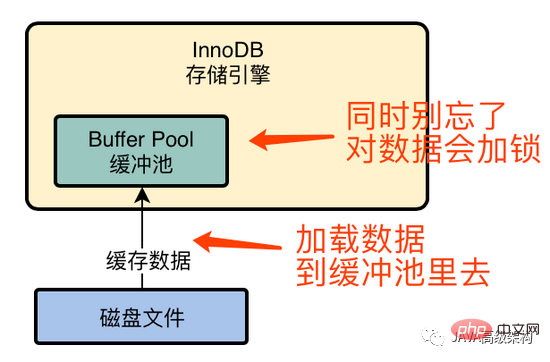
2. Annuler le fichier journal
Supposons que id = 1. La valeur d'origine de ce nom de données est name = 'zhangsan'. Nous voulons maintenant le mettre à jour pour name = 'lisi', alors nous en avons besoin. pour changer l'ancienne valeur en name ='zhangsan' et id=1 sont écrits dans le fichier journal d'annulation.
Pour les étudiants qui connaissent les bases de données, ils comprennent tous le concept de transaction. Avant que la transaction ne soit soumise, toutes les opérations peuvent être annulées, c'est-à-dire que nom = 'lisi' peut être annulé en nom = 'zhangsan', elle sera donc mise à jour. La valeur précédente est écrite dans le fichier journal d'annulation.
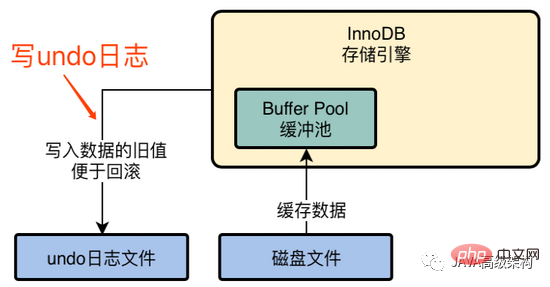
3. Mettre à jour les données du pool de tampons
Une fois le fichier journal d'annulation écrit, commencez à mettre à jour ces données dans la mémoire. Mettre à jour name = 'zhangsan' avec id = 1 vers name = 'lisi'. À ce stade, les données dans la mémoire ont été mises à jour, mais les données sur le disque n'ont pas changé. À ce stade, des données sales incohérentes apparaissent.
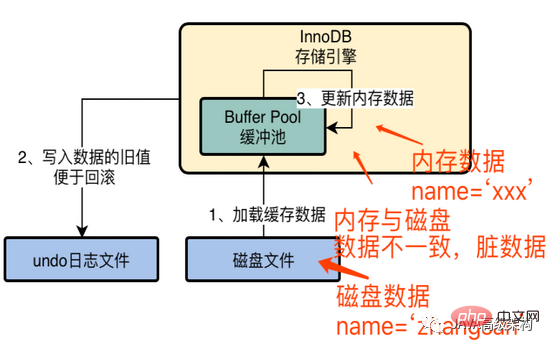
Vous avez peut-être une question à ce moment-là. Si la transaction est soumise mais que le service MySQL est en panne et que les données en mémoire n'ont pas été écrites sur le disque, cela entraînera-t-il une perte de données et une incohérence dans le Données d'exécution SQL ?
4. tampon de journalisation
Dans la structure InnoDB, il existe un tampon de journalisation pour stocker les journaux de rétablissement, par exemple, remplacez id=1, name='zhangsan' par name=. 'lisi' C'est un journal.
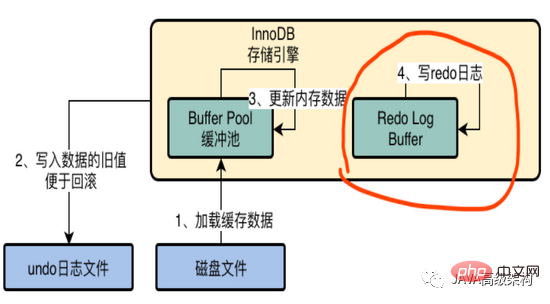
Mais pour le moment, le tampon de journalisation n'existe que dans la mémoire et la récupération des données après un temps d'arrêt de MySQL n'est pas possible.
5. Si la transaction n'est pas soumise, y aura-t-il un impact si la base de données est en panne ?
En fait, cela n'a aucun impact. La transaction n'est pas soumise, ce qui signifie que l'exécution ne réussit pas. Même si MySQL plante ou tombe en panne, les données modifiées dans le pool de tampons et le tampon de journalisation dans la mémoire le seront. perdu, et cela n’affectera pas la cohérence des données. Si la validation de la transaction échoue, les données de la base de données ne changeront pas.
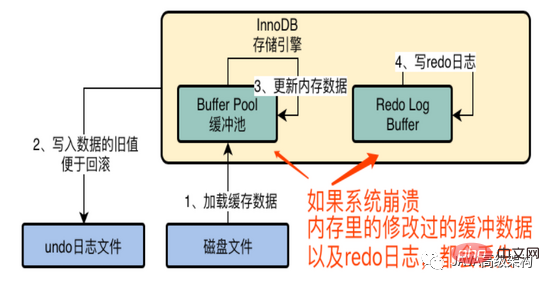
6. Soumettre la transaction, stratégie de configuration du journal redo
Lors de la soumission de la transaction, le journal redo écrira le journal redo du tampon redo log sur le disque selon la stratégie. La politique est configurée via innoDB_flush_log_at_trx_commit.
Le paramètre de innoDB_flush_log_at_trx_commit est 0. Même une fois la transaction validée, le journal redo ne sera pas écrit sur le disque. Après le crash de MySQL, les données en mémoire seront perdues.
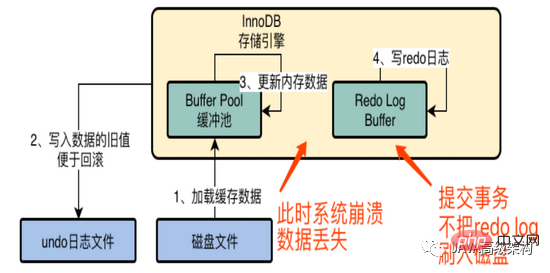
Le paramètre de innoDB_flush_log_at_trx_commit est 1. Une fois la transaction soumise, le journal redo sera vidé de la mémoire vers le disque. Tant que la transaction est soumise avec succès, le journal redo existera définitivement. sur le disque.
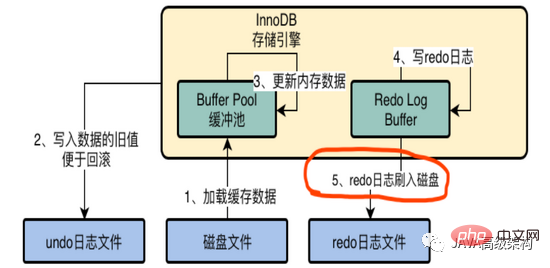
À ce stade, même si les données du pool de mémoire tampon ne sont pas vidées sur le disque, vous pouvez toujours savoir quelles données ont été modifiées à partir du journal redo. Après l'arrêt et le redémarrage de MySQL, les données modifiées peuvent. être restauré à partir du journal de rétablissement.
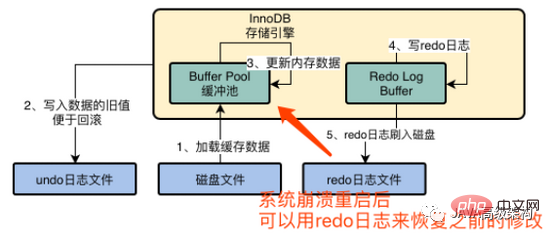
Le paramètre de innoDB_flush_log_at_trx_commit est 2. Une fois la transaction soumise, le journal redo reste uniquement dans le cache du système d'exploitation et n'a pas été vidé sur le disque au cas où le service serait en panne à ce moment-là. Ensuite, les données dans le cache du système d'exploitation seront également perdues. Même si la transaction est soumise avec succès, les données seront perdues.
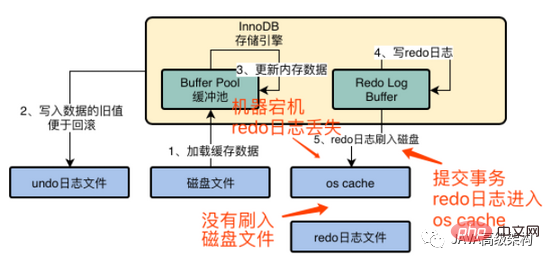
Après avoir lu ceux-ci, je pense que pour assurer la sécurité des données, le paramètre 1 est la meilleure stratégie.
7. La soumission finale de la transaction, binlog
binlog est en fait un fichier journal appartenant au serveur MySQL, et il est mentionné ici car il est étroitement lié au redo log.
1) La différence entre biglog et redo log
redo log : il enregistre un redo log de nature physique partielle, comme "quel enregistrement dans quelle page de données, quelles modifications ont été apportées"
Binlog : Un journal plus logique, tel que : "La ligne de données avec l'id=10 dans la table des utilisateurs a été mise à jour. Quelle est la valeur après la mise à jour ?"
2) Écrivez le binlog sur en même temps lors de la soumission de la transaction
Pendant l'exécution des mises à jour, innoDB interagit constamment avec l'exécuteur, notamment en chargeant des données dans le pool de tampons, en écrivant des fichiers journaux d'annulation, en mettant à jour les données de la mémoire, en écrivant des journaux de rétablissement et en les vidant sur le disque, etc. L'écriture dans binlog est également effectuée par l'exécuteur.
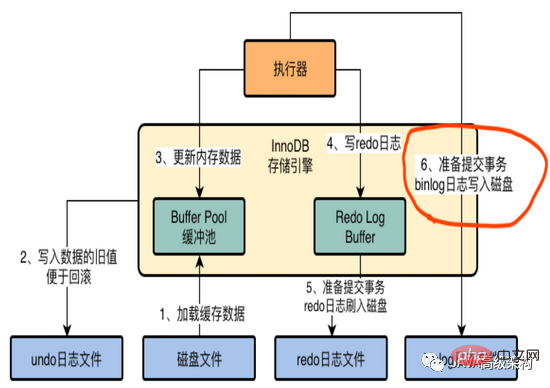
Les étapes 1, 2, 3 et 4 sont ce que vous faites lorsque vous exécutez l'instruction de mise à jour, et les étapes 5 et 6 sont ce que vous faites lorsque vous validez la transaction.
3) Analyse de la stratégie de vidage du journal binlog
Le paramètre sync_binlog contrôle la stratégie de vidage du journal binlog
sync_ La valeur par défaut de binlog est 0. Une fois la transaction soumise, le journal binlog sera stocké dans le cache du système d'exploitation, qui sera provoquer des problèmes après la panne de MySQL. La perte de données dans le cache du système d'exploitation
la valeur de sync_binlog est 1. Une fois la transaction soumise, le journal binlog est vidé directement sur le disque.
4) Soumission complète des transactions basée sur le binlog et le redo log
Une fois le binlog écrit sur le disque, l'emplacement et le nom du fichier journal binlog seront écrits dans le fichier redo log, et en même temps dans le fichier de journalisation, écrivez une marque de validation.
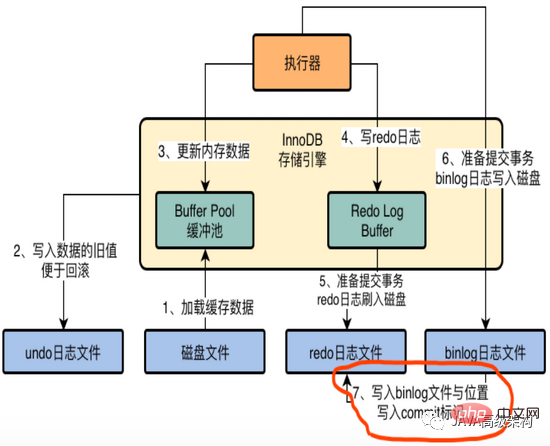
5) Quelle est la signification de la balise commit ? La marque
commit signifie que les journaux redo log et binlog sont cohérents. Si la soumission de la transaction commence à l'étape 5 ou à l'étape 6, que MySQL est en panne et qu'il n'y a aucune marque de validation dans le journal redo, la soumission de la transaction est considérée comme ayant échoué.
signifie que la marque de validation indique que la transaction a finalement été soumise avec succès.
8. Pool de tampons Les données sales sont vidées sur le disque
Les données sales sont vidées sur le disque de manière aléatoire par le thread IO en arrière-plan.
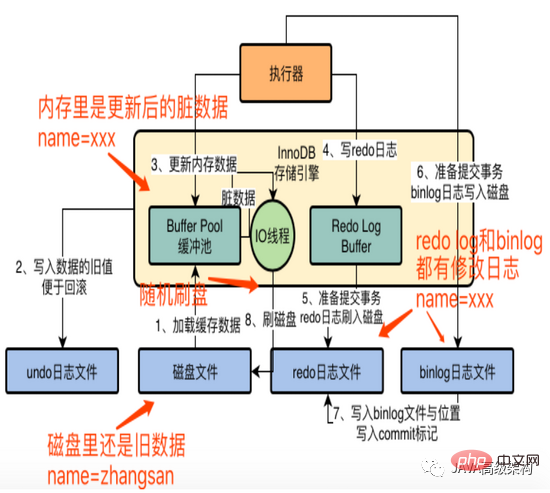
À ce moment-là, j'y ai réfléchi, que dois-je faire si MySQL tombe en panne avant de flasher le disque ? À ce stade, la transaction a été soumise avec succès et il y a une marque de validation dans le journal redo. Même s'il est en panne, après le redémarrage, les données seront mises à jour dans la mémoire selon le fichier redo log, en attendant l'IO. fil pour vider le disque.
9. Résumé
Après avoir exécuté l'analyse via l'instruction de mise à jour, nous avons appris que le moteur de stockage InnoDB comprend un pool de tampons de pool de tampons, un tampon de tampon de journalisation et d'autres données de cache, un défaire, un journal reod et d'autres fichiers journaux, comme ainsi que le fichier journal du serveur MySQL.
Lors de l'exécution de l'instruction de mise à jour, le pool de tampons, l'écriture du fichier journal d'annulation, l'écriture du tampon de journalisation et d'autres opérations seront modifiés ; lorsque la transaction est soumise, le journal redo sera vidé, le journal binaire sera vidé, le fichier binlog sera vidé. le nom et l'emplacement seront écrits, puis entrez la marque de validation, et enfin attendez que le thread IO vide aléatoirement les données sales dans le pool de mémoire tampon.
Apprentissage recommandé : Tutoriel vidéo mysql
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Apache se connecte à une base de données nécessite les étapes suivantes: Installez le pilote de base de données. Configurez le fichier web.xml pour créer un pool de connexion. Créez une source de données JDBC et spécifiez les paramètres de connexion. Utilisez l'API JDBC pour accéder à la base de données à partir du code Java, y compris l'obtention de connexions, la création d'instructions, les paramètres de liaison, l'exécution de requêtes ou de mises à jour et de traitement des résultats.
 Moniteur Disd Droplet avec service d'exportateur Redis
Apr 10, 2025 pm 01:36 PM
Moniteur Disd Droplet avec service d'exportateur Redis
Apr 10, 2025 pm 01:36 PM
La surveillance efficace des bases de données Redis est essentielle pour maintenir des performances optimales, identifier les goulots d'étranglement potentiels et assurer la fiabilité globale du système. Le service Redis Exporter est un utilitaire puissant conçu pour surveiller les bases de données Redis à l'aide de Prometheus. Ce didacticiel vous guidera à travers la configuration et la configuration complètes du service Redis Exportateur, en vous garantissant de créer des solutions de surveillance de manière transparente. En étudiant ce tutoriel, vous réaliserez les paramètres de surveillance entièrement opérationnels
 Comment afficher l'erreur de base de données SQL
Apr 10, 2025 pm 12:09 PM
Comment afficher l'erreur de base de données SQL
Apr 10, 2025 pm 12:09 PM
Les méthodes de visualisation des erreurs de base de données SQL sont: 1. Afficher directement les messages d'erreur; 2. Utilisez des erreurs d'affichage et des commandes d'avertissement Show; 3. Accédez au journal d'erreur; 4. Utiliser les codes d'erreur pour trouver la cause de l'erreur; 5. Vérifiez la connexion de la base de données et la syntaxe de requête; 6. Utilisez des outils de débogage.
