
 base de données
tutoriel mysql
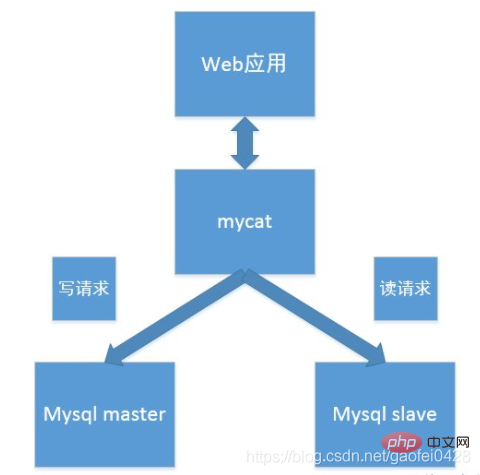
Parlons de l'implémentation par Mycat de la séparation lecture-écriture du cluster Mysql
base de données
tutoriel mysql
Parlons de l'implémentation par Mycat de la séparation lecture-écriture du cluster Mysql
Parlons de l'implémentation par Mycat de la séparation lecture-écriture du cluster Mysql

Cet article vous présente les connaissances pertinentes sur la séparation en lecture et en écriture MySQL, j'espère qu'il vous sera utile.

Aperçu de la séparation lecture-écriture MySQL
MySQL est actuellement la base de données gratuite la plus utilisée au monde. Je pense que tous les ingénieurs impliqués dans l'exploitation et la maintenance du système doivent être entrés en contact avec elle.
Dans un environnement de production réel, un seul MySQL en tant que base de données indépendante est totalement incapable de répondre aux besoins réels, peu importe en termes de sécurité, de haute disponibilité et de haute concurrence.
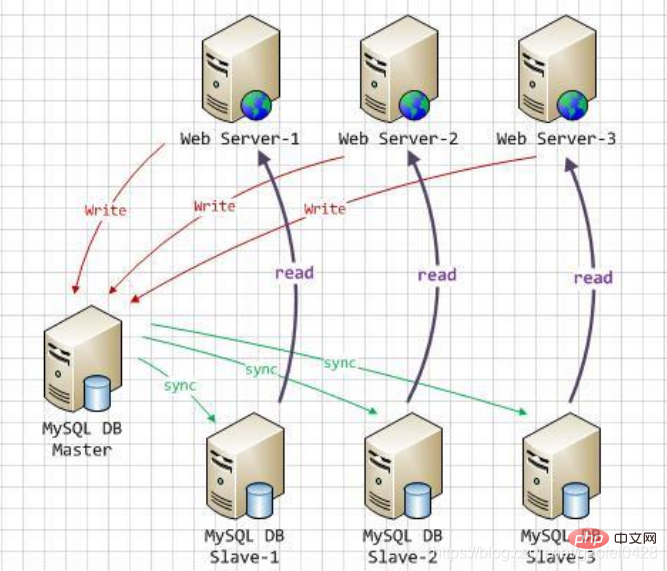
Par conséquent, de manière générale, les données sont synchronisées via Réplication maître-esclave, puis via séparation lecture-écriture (MySQL-Proxy/Amoeba) pour augmenter la charge simultanée de la base de données. Capacité à déployer et mettre en œuvre. "Le principe de fonctionnement de la séparation en lecture et en écriture"
Traitement des opérations de requête SELECT à partir de la base de données
- La réplication de la base de données est utilisée pour synchroniser les modifications provoquées par les opérations transactionnelles avec la base de données esclave du cluster.
-
Pourquoi la séparation en lecture et en écriture
Face à la pression d'accès croissante, les performances d'un serveur unique sont devenues un goulot d'étranglement et la charge doit être partagée - Maître-esclave uniquement Responsable de l'écriture et de la lecture respectives, atténuant considérablement les conflits de verrouillage X (écriture) et de verrouillage S (lecture)
 Le moteur myisam peut être configuré à partir de la base de données pour améliorer les performances des requêtes et économiser la surcharge du système
Le moteur myisam peut être configuré à partir de la base de données pour améliorer les performances des requêtes et économiser la surcharge du système
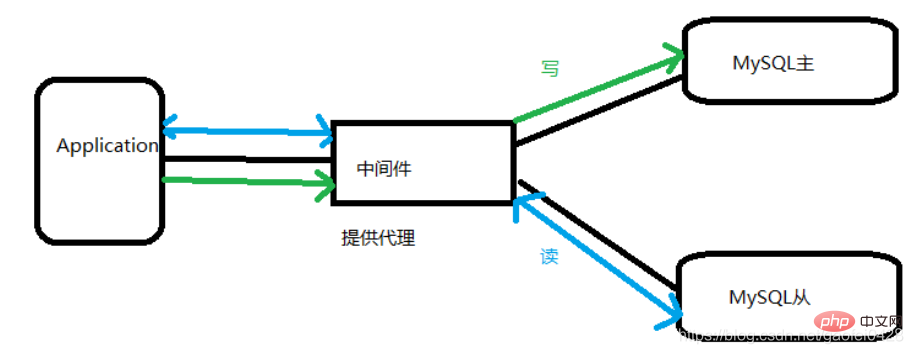
- Moyens d'obtenir une séparation lecture-écriture
Il existe généralement deux façons de l'implémenter
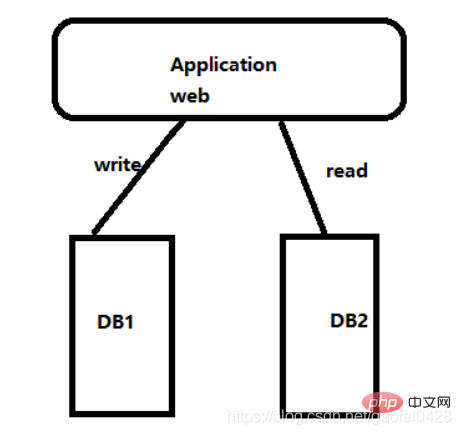
Implémentation de la couche d'application, implémentation du programme de site WebL'implémentation de la couche d'application fait référence à l'intérieur de l'application Et la séparation en lecture et en écriture est réalisée dans le connecteur
Avantages :
La séparation en lecture et en écriture est réalisée à l'intérieur de l'application, et l'installation peut être utilisée- pour réduire une certaine difficulté de déploiement
- La pression d'accès est inférieure à un certain niveau, et les performances sont très bonnes
- Inconvénients :
-
-
Implémentation de la couche middleware :
L'implémentation de la couche middleware fait référence au middleware commun qui implémente la séparation lecture-écriture dans les programmes middleware externes
- Programme logiciel
Cobar :
- Un système distribué relationnel développé par Alibaba B2B , gérant près de 3 000 instances MySQL. Il a résisté au test d'Alibaba. Plus tard, en raison du départ de l'auteur, cobar n'a plus été maintenu. Alibaba a également développé tddl pour remplacer cobar.
- MyCAT :
- Les passionnés de la communauté ont effectué un développement secondaire basé sur Alibaba cobar, résolu certains problèmes que cobar avait à l'époque et lui ont ajouté de nombreuses nouvelles fonctionnalités. Actuellement, la communauté MyCAT est très active et certaines entreprises utilisent déjà MyCAT. D'une manière générale, le niveau de support est supérieur à
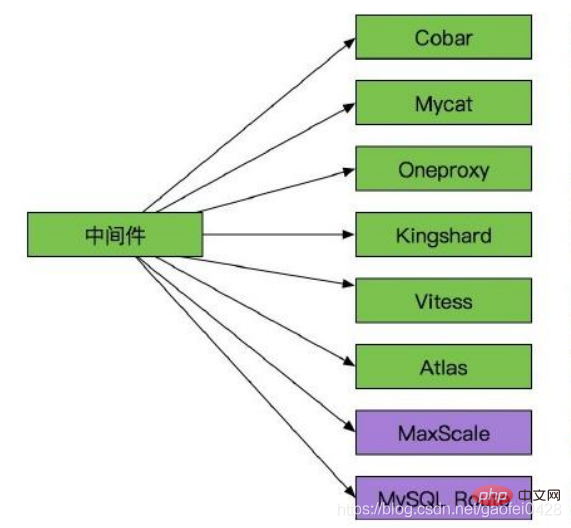
- OneProxy :
- Un grand patron de l'industrie des bases de données, l'ancien chef d'équipe de base de données Alipay, Lou Zong, a développé, sur la base de l'idée officielle du proxy MySQL en utilisant C pour développer, OneProxy est un middleware commercial payant, Lou Zong l'a donné up Certains points de fonctionnalités ont été ajoutés pour se concentrer sur les performances et la stabilité. Quelqu'un l'a testé
- et a déclaré qu'il était très stable dans des conditions de concurrence élevée.
- Vitess :
- Ce middleware est utilisé dans la production Youtube, mais l'architecture est très complexe. Contrairement au middleware précédent, les modifications apportées à l'application utilisant Vitess sont relativement importantes. Pour utiliser l'interface API du langage qu'il fournit, nous pouvons nous inspirer de certaines de ses idées de conception.
- Éclat royal :
Kingshard a été développé par Chen Fei de l'ancienne équipe de développement de middleware 360Atlas dans le langage Go pendant son temps libre. Il y a actuellement environ 3 personnes impliquées dans le développement. À l'heure actuelle, ce n'est pas un produit mature et utilisable et doit le faire. être continuellement amélioré.
Atlas :
L'équipe 360 a réécrit Lua en C basé sur un proxy MySQL. La version originale prend en charge le partitionnement de table, et une version de base de données et de table partitionnée a été publiée. J'ai vu des amis sur Internet dire souvent qu'il se bloque souvent en cas de concurrence élevée. Si vous souhaitez l'utiliser, vous devez le tester à l'avance.
MaxScale et MySQL Route :
Ces deux middlewares sont considérés comme officiels. MaxScale est développé par mariadb (une version maintenue par l'auteur original de MySQL). La version actuelle ne prend pas en charge le partitionnement des bases de données et des tables. MySQL Route est un middleware désormais publié par la société Oracle officielle MySQL.
Avantages :
La conception de l'architecture est plus flexible
Vous pouvez implémenter certains contrôles avancés sur le programme, tels que : le fractionnement horizontal transparent, le basculement et la surveillance. Vous pouvez compter sur des moyens techniques pour vous améliorer. l'impact des performances de MySQL sur le code métier Petit et sûr à la fois
Inconvénients :
Nécessite le soutien d'une certaine équipe de développement et d'exploitation.
Qu'est-ce que MyCAT
Un grand cluster de bases de données entièrement open source pour le développement d'applications d'entreprise
prend en charge les transactions, ACID et une version améliorée de la base de données qui peut remplacer MySQL
Il peut être considéré comme une base de données de cluster MySQL au niveau de l'entreprise, utilisée pour remplacer les clusters Oracle coûteux
Un nouveau serveur SQL qui intègre la technologie de mise en cache mémoire, la technologie NoSQL et le big data HDFS
Combine les bases de données traditionnelles et de nouveaux entrepôts de données distribués Une nouvelle génération de produits de base de données au niveau de l'entreprise
Un nouveau produit middleware de base de données
Installation et configuration du service MyCat
MyCat fournit des packages d'installation compilés, prenant en charge Windows et Linux, Mac, Solaris et autres systèmes à installer et à exécuter
Page d'accueil officielle de téléchargement http://www.mycat.org.cn/

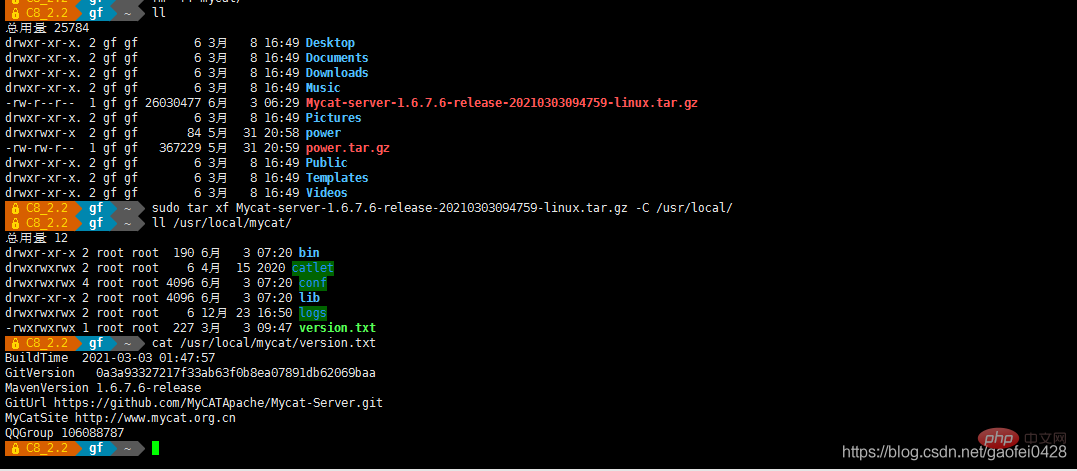
- Architecture expérimentale :
- 192.168. 2.2 Mycat CentOS 8.3.2011
- 192.168.2.3 Serveur principal CentOS 7.6
- 192.168.2.5 Serveur esclave CentOS 7.6
- L'exécution de Mycat nécessite JDK 1.7 ou supérieur

- Téléchargez Mycat
- wget http:/ /dl .mycat.org.cn/1.6.7.6/20210303094759/Mycat-server-1.6.7.6-release-20210303094759-linux.tar.gz
- tar xf Mycat-server-1.6.7.6-release-20210303094759-linux. tar. gz -C /usr/local/
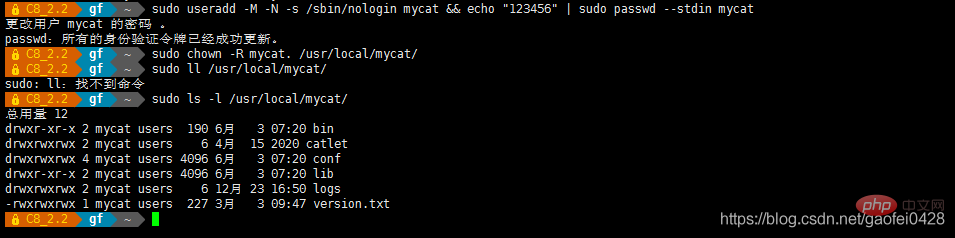
- sudo useradd -M -N -s /sbin/nologin moncat && echo "123456" | sudo passwd --stdin moncat
- sudo chown -R moncat/usr/local/. monchat/

- Répertoire du programme bin, exécuté sous Linux : ./mycat console, first chmod +x *
Remarque : Mycat prend en charge les commandes { console start | restart status | .xml est le fichier de configuration pour l'ajustement des paramètres du serveur Mycat et l'autorisation des utilisateurs. schema.xml est le fichier de configuration pour la définition de la bibliothèque logique, la table et la définition de partitionnement. . Stockez-le dans un fichier séparé, également dans ce répertoire. Si le fichier de configuration est modifié, vous devez redémarrer Mycat pour prendre effet.
Le répertoire lib stocke principalement certains fichiers jar dont dépend mycat.
Le journal est stocké dans logs/mycat.log, un fichier par jour. La configuration du journal est dans conf/log4j.xml Selon vos propres besoins, vous pouvez ajuster le niveau de sortie pour déboguer. sera affiché, pour faciliter le dépannage.
Démarrage du service MyCat et paramètres de démarrage
- Lors du déploiement et du démarrage de MyCAT sous Linux, vous devez d'abord configurer MYCAT_HOME dans la variable d'environnement du système Linux. La méthode de fonctionnement est la suivante : .
- sudo vim /etc/ profile.d/mycat.sh
MYCAT_HOME=/usr/local/mycat PATH=$MYCAT_HOME/bin:$PATH
- Les variables d'environnement prennent effet
- /etc/profile.d. /mycat.sh

- Démarrer le service
- /usr/local/mycat/bin/mycat start
- cat /usr/local/mycat/logs/wrapper.log
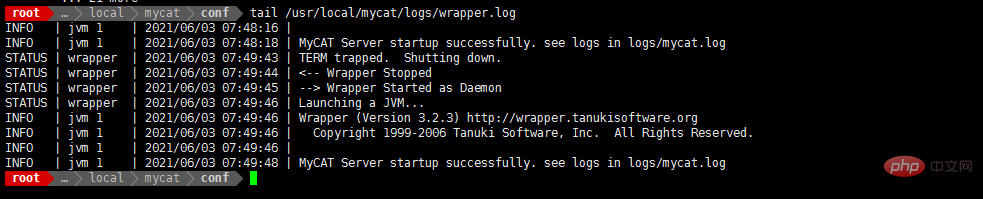

mycat des utilisateurs Les informations de compte et d'autorisation sont configurées dans le fichier conf/server.xml
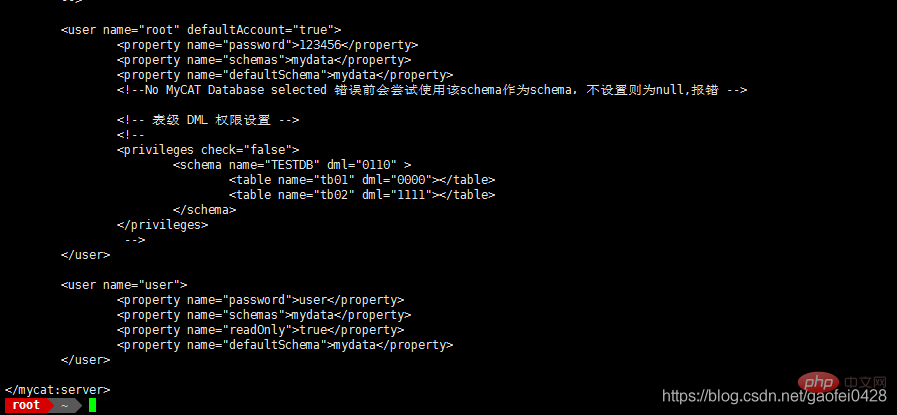
- vim /usr/local/mycat/conf/server.xml
Ce qui est défini voici pour vous connecter à mycat sur 192.168.2.2 Nom d'utilisateur et mot de passe, le nom peut être personnalisé. Le service mysqld ne fonctionne pas sur 192.168.2.2. Le nom de la base de données spécifié dans les schémas est une base de données qui doit exister côté serveur !
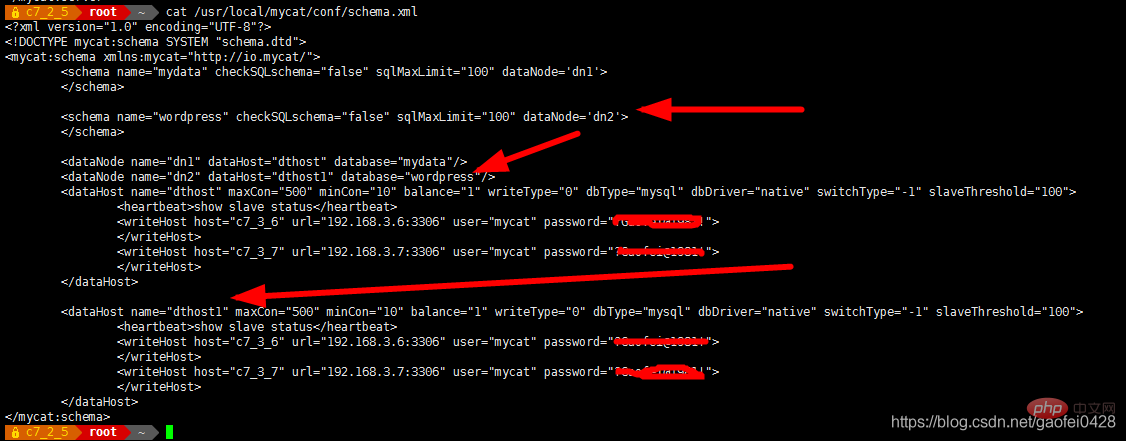
- vim /usr/local/mycat/conf/schema.xml
- < !DOCTYPE mycat:schema SYSTEM "schema.dtd">
-
Faites attention à l'URL ici, une écriture incorrecte entraînera l'échec du démarrage !
< "mesdonnées"/>
balance="1" writeType="0" dbType="mysql" dbDriver="native " switchType= "-1" slaveThreshold="100">
.3:3306" user="mycat " password="123456"> Serveur de lecture
;/writeHost> Forcer toutes les opérations de lecture à s'exécuter sur le serveur de lecture et passer au serveur d'écriture uniquement lorsque les données sont écrites
Notez que l'utilisateur mycat ici doit être autorisé sur la base de données maître-esclave 192.168. 2.3 et 2.5
ACCORDEZ TOUS LES PRIVILÈGES SUR *.* À 'mycat'@'%' IDENTIFIÉ PAR '123456';
ou segment de réseau spécifié
ACCORDEZ TOUS LES PRIVILÈGES SUR *.* À 'mycat '@' 192.168.2.%' IDENTIFIÉ PAR '123456';
flush privilèges;
Si cette erreur est signalée et que le serveur fonctionne normalement, vérifiez d'abord s'il y a une autorisation
ERR OR 1184 (HY000) : Source de données invalide : 0
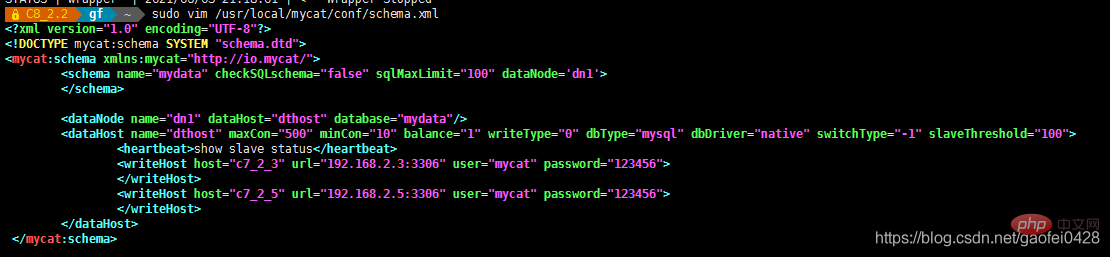

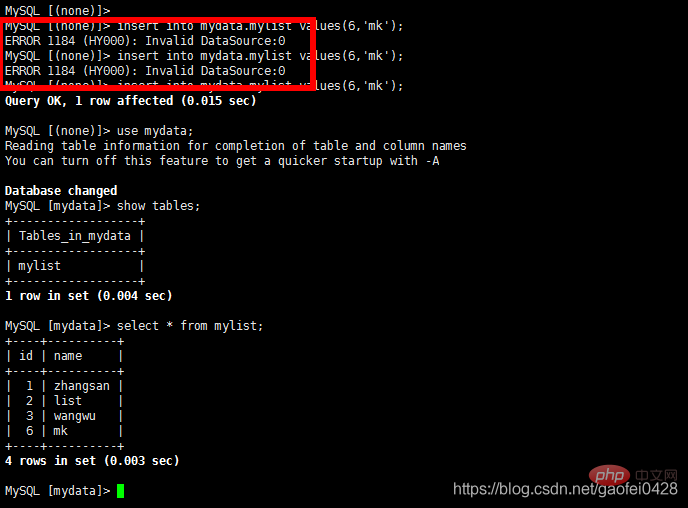
Schéma : Bibliothèque logique, correspondant à la base de données dans MySQL, une bibliothèque logique définit les éléments inclus Tableau .
table : Table, c'est-à-dire une table stockée dans une base de données physique. Différente des bases de données traditionnelles, la table doit ici déclarer le nœud de données logique DataNode qu'elle stocke. Ceci est réalisé grâce à la définition de règles de partitionnement pour la table. Une table peut définir la "childTable" à laquelle elle appartient. Le partitionnement de la table enfant dépend de l'adresse de partitionnement spécifique de la "table parent". En termes simples, il s'agit de toutes les tables enfants appartenant à un certain enregistrement A dans le parent. table Les enregistrements sont tous stockés sur la même partition que A.
Règle de partitionnement : il s'agit d'une définition groupée d'un champ et d'une fonction. En fonction de la valeur de ce champ, le numéro de séquence du fragment stocké (DataNode) est renvoyé. Chaque table peut définir une règle de partitionnement, et la règle de partitionnement peut. être étendu de manière flexible. Des règles de partitionnement basées sur des nombres, des règles de partitionnement de chaînes, etc. sont fournies par défaut.
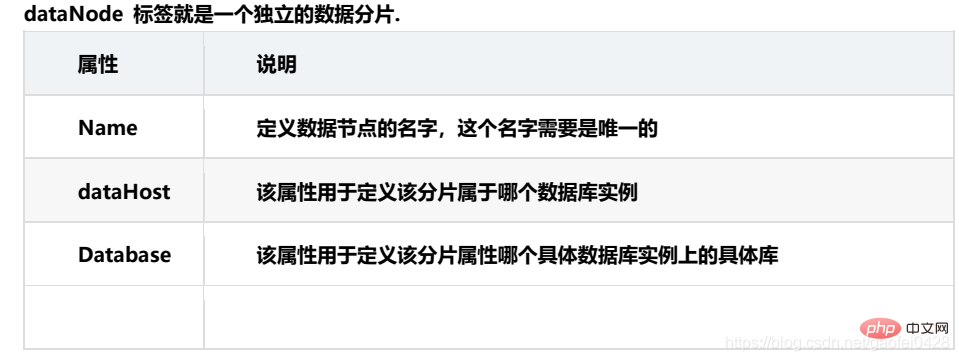
dataNode : Le nœud de données logique de MyCAT est un nœud physique spécifique qui stocke les tables. Il est également appelé nœud de partition. Il est associé à une base de données back-end spécifique via DataSource. De manière générale, pour une haute disponibilité, chaque DataNode. est configuré avec deux DataSources, un maître et un esclave. Lorsque le nœud maître tombe en panne, le système passe automatiquement au nœud esclave.
dataHost : Définissez l'adresse d'accès d'une bibliothèque physique pour la liaison à dataNode.
MyCAT définit actuellement les bibliothèques logiques et les configurations associées via des fichiers de configuration :
Les bibliothèques logiques, les tables, les nœuds de partition et autres contenus sont définis dans MYCAT_HOME/conf/schema.xml
Le partage est défini dans les règles MYCAT_HOME/conf/rule.xml ;
Définissez les variables liées à l'utilisateur et au système, telles que les ports, etc. dans MYCAT_HOME/conf/server.xml.
Remarque :
La balise de schéma est utilisée pour définir la bibliothèque logique dans le nom de l'instance MyCat : elle est suivie du nom de la bibliothèque logique. MyCat peut avoir plusieurs bibliothèques logiques, et chaque bibliothèque logique a sa propre configuration associée. Vous pouvez utiliser des balises de schéma pour diviser ces différentes bibliothèques logiques.
L'attribut checkSQLschema est par défaut false. Le document officiel indique s'il faut supprimer le nom de la base de données devant la table, "select * from db1.testtable". S'il est défini sur true, db1 sera supprimé. Mais si le nom de db1 n'est pas le nom du schéma, il ne sera pas supprimé, il est donc officiellement recommandé de ne pas utiliser cette syntaxe. Également défini sur false par défaut.
sqlMaxLimit Lorsque la valeur est définie sur un certain nombre. Pour chaque instruction SQL exécutée, si aucune instruction de limite n'est ajoutée, MyCat ajoutera automatiquement la valeur correspondante. Par exemple, si vous définissez la valeur sur 100 et exécutez « select * from test_table », l'effet sera « select * from test_table limit 100 ». La balise dataNode définit les nœuds de données dans MyCat, ce que nous appelons habituellement le partage de données.



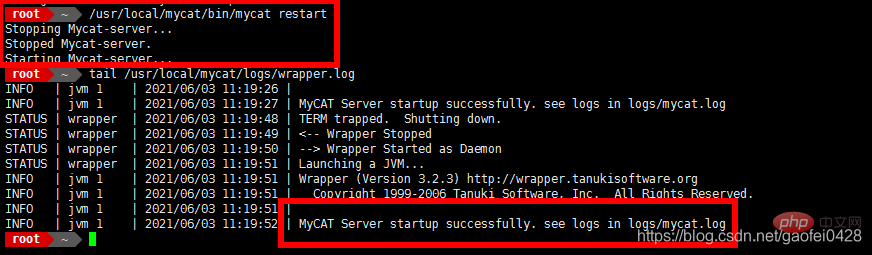
- Redémarrez le service
- /usr/local/mycat/bin/mycat restart
Arrêt du serveur Mycat...
Arrêt du serveur Mycat.
Démarrage du serveur Mycat...
tail /usr/local/ mycat/logs/wrapper.log
Configurer MySQL maître-esclave
- Installez et configurez mariadb sur 2 serveurs respectivement Pour les étapes spécifiques, veuillez vous référer à : https://blog.csdn. net/ gaofei0428/article/details/103829676?spm=1001.2014.3001.5501
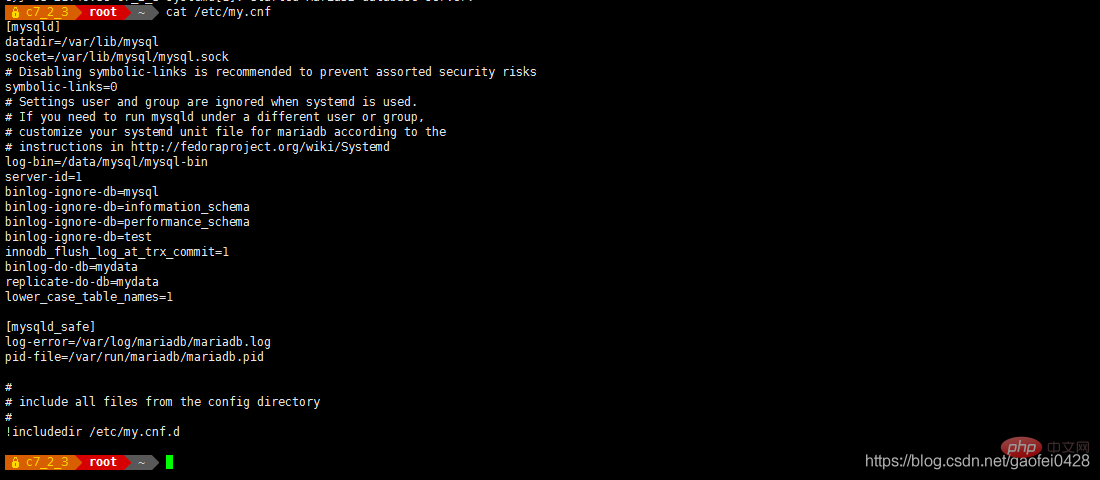
Premier côté base de données principale 192.168.2.3 Edit /etc/my.cnf
- /etc/my.cn f
[ mysqld]
datadir =/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
symbolic-links=0
log-bin=/data/mysql/mysql-bin
server-id =1
binlog-ignore-db=mysql
binlog-ignore-db=information_schema
binlog-ignore-db=performance_schema
binlog-ignore-db=test
innodb_flush_log_at_trx_commit=1
binlog-do-db=mydata
replicate-do- db=mydata - lower_case_table_names=1 Activer la correspondance de casse
- Notez que la base de données qui doit être synchronisée doit exister à l'avance

et puis démarrez-le sans erreur Depuis le serveur 192.168.2.5 Configurer /etc/my.cnf
- vim /etc/my.cnf ock
symbolic-links=0
log-bin=/data/mysql/mysql- bin
server-id=2
relay-log-index=/data/mysql/slave-relay-bin.index
relay-log=/ data/mysql/slave-relay-bin
lower_case_table_names=1
read_only=1 Activez le mode lecture seule pour empêcher l'écriture des données et n'affectera pas la réplication synchrone de l'esclave
lower_case_table_names=1 Activez la correspondance de casse
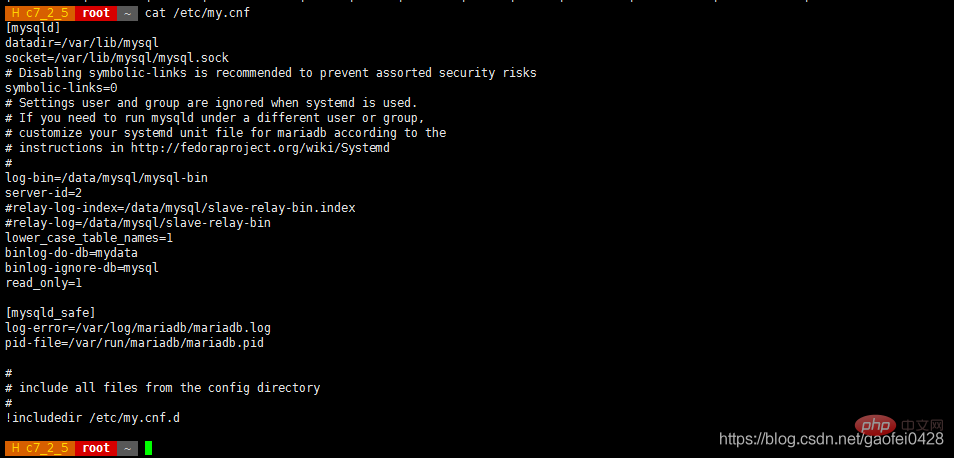
- Après avoir redémarré le service de base de données esclave, effectuez les opérations suivantes
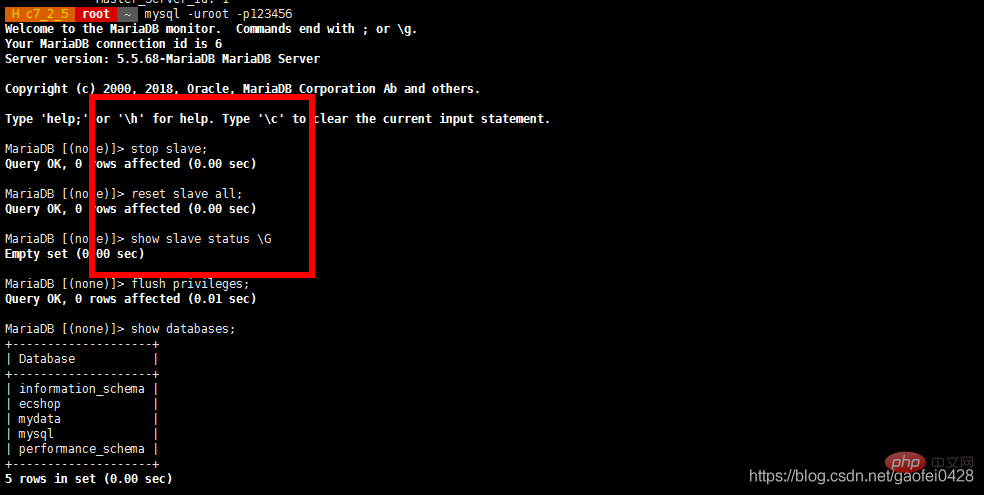
- Arrêtez l'esclave du serveur esclave et créez un utilisateur de base de données esclave mysql -uroot -p123456 -e "stop slave"
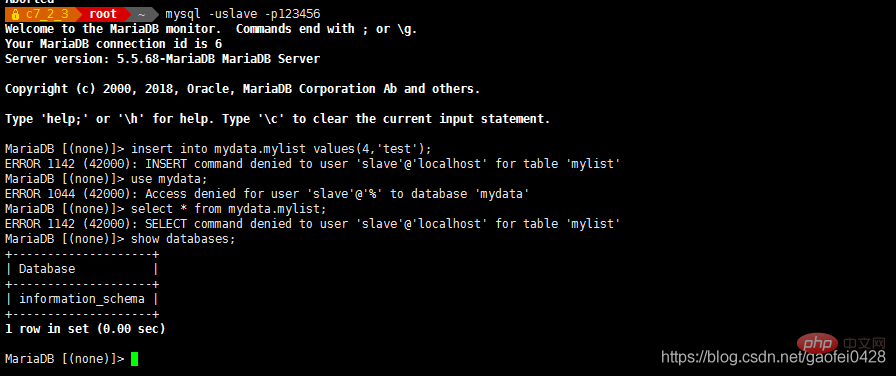
- mysql -uroot -p123456 -e "accorder l'esclave de réplication sur *.* à 'slave'@'%' identifié par '123456'" mysql -uroot -p123456 -e "sélectionnez l'utilisateur, le mot de passe de mysql.user"
-
 mysql -uroot -p123456 -e " changez le maître en master_host='192.168.2.3', master_user='slave',master_password='123456',master_log_file='mysql-bin.000002',master_log_pos=245;"
mysql -uroot -p123456 -e " changez le maître en master_host='192.168.2.3', master_user='slave',master_password='123456',master_log_file='mysql-bin.000002',master_log_pos=245;"
- mysql -uroot -p123456 -e "show slave statut"
-

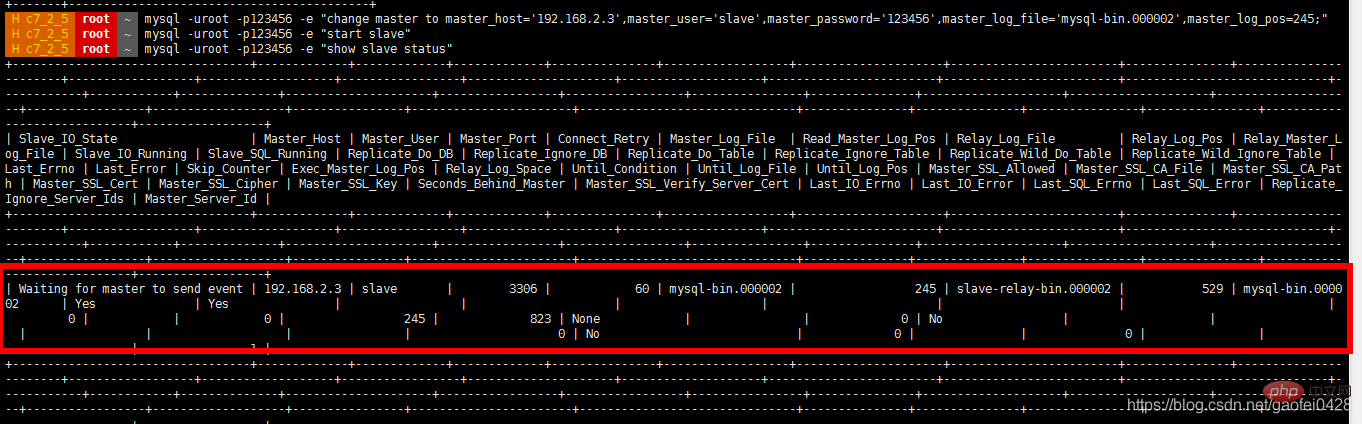
Test
Exportez d'abord la sauvegarde de toutes les bibliothèques du serveur principal 192.168.2.3
mysqldump -uroot -p --all-databases > /tmp/ all_dbs .sql
Puis importer depuis le serveur 192.168.2.5
mysql -uroot -p < Ajoutez 192.168.2.3 sur le réseau principal côté base de données Pour certaines données, observez si la base de données esclave est synchronisée
Vérifiez sur le serveur esclave 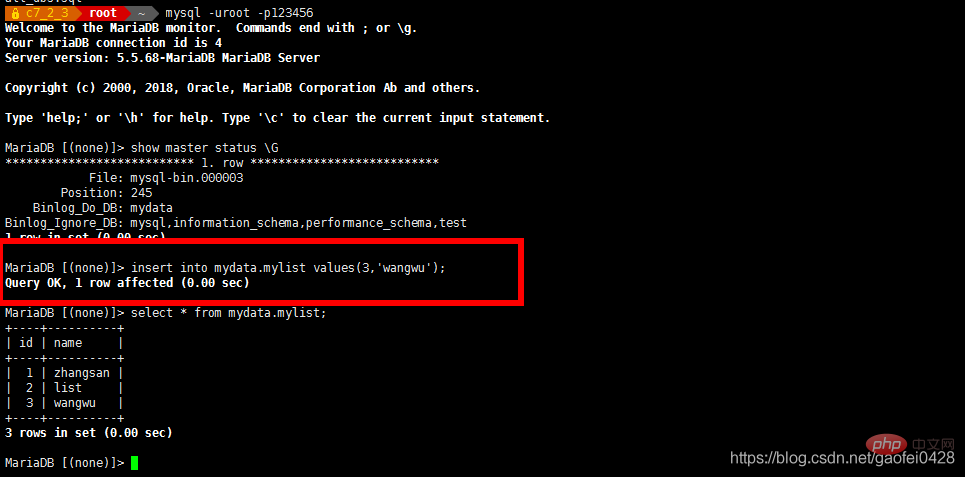
S'il y a une erreur de synchronisation, vous devez arrêter l'esclave sur le serveur esclave et puis changez à nouveau le maître 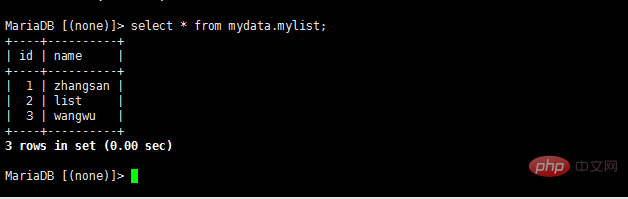
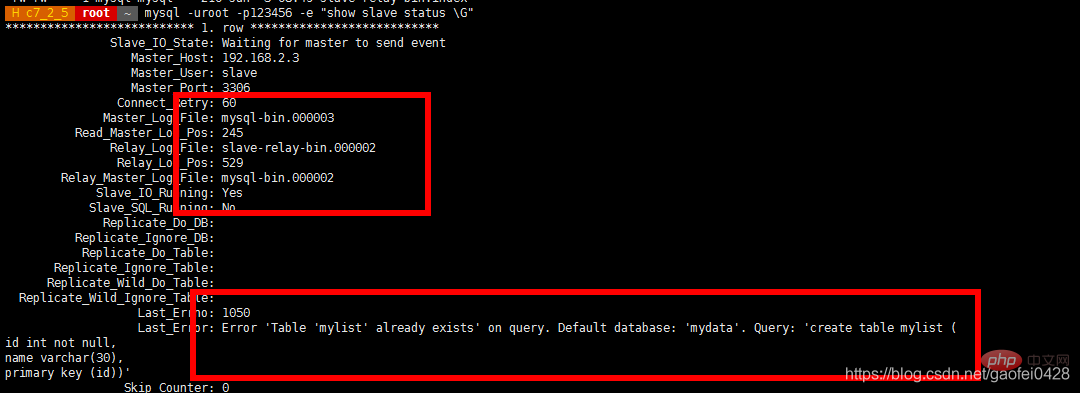

Utilisez le test de connexion de l'utilisateur esclave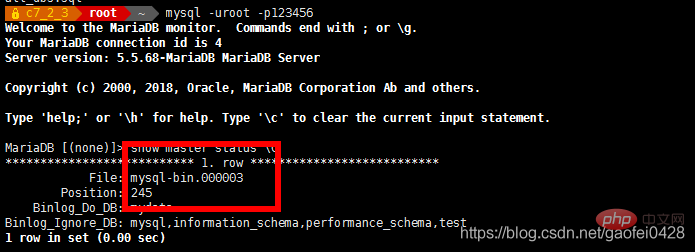
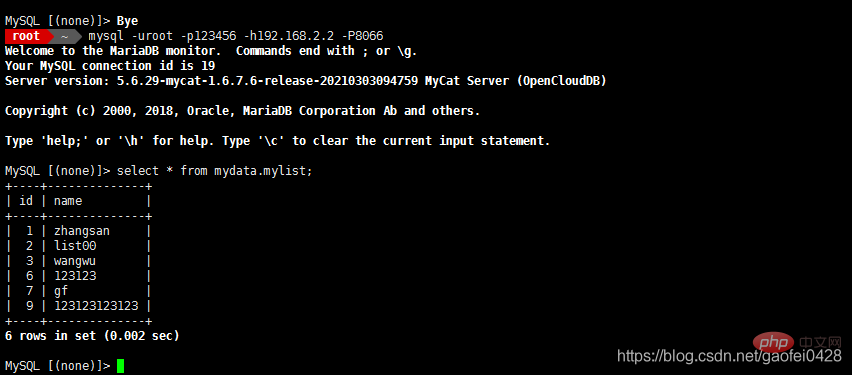
- Retour à serveur mycat 192.168.2.2
Essayez de vous connecter - mysql -uroot - p123456 -h192.168.2.2 -P8066
- 8066 est le numéro de port lorsque mycat est en marche

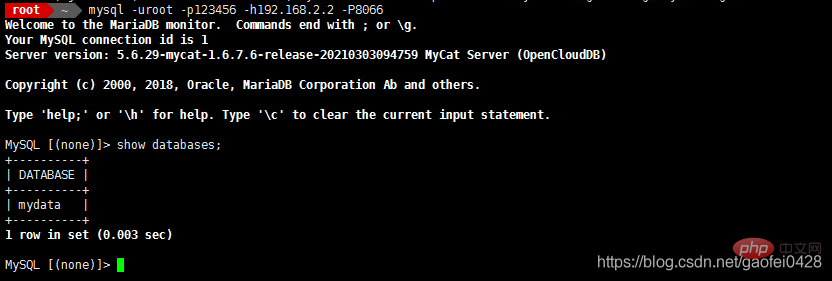 pour tester la séparation en lecture et en écriture
pour tester la séparation en lecture et en écriture
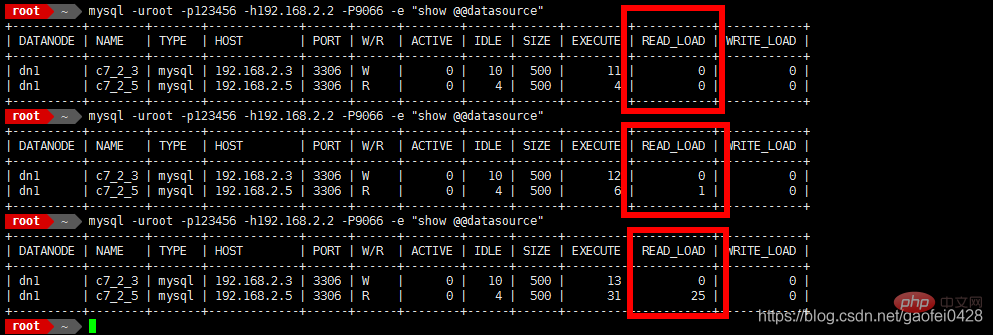
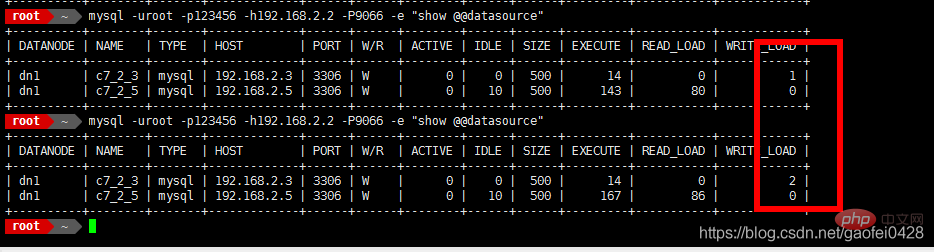
- mysql -uroot -p123456 -h192 .168.2.2 -P9066 -e "show @@datasource"
- 9066 est le port de gestion mycat
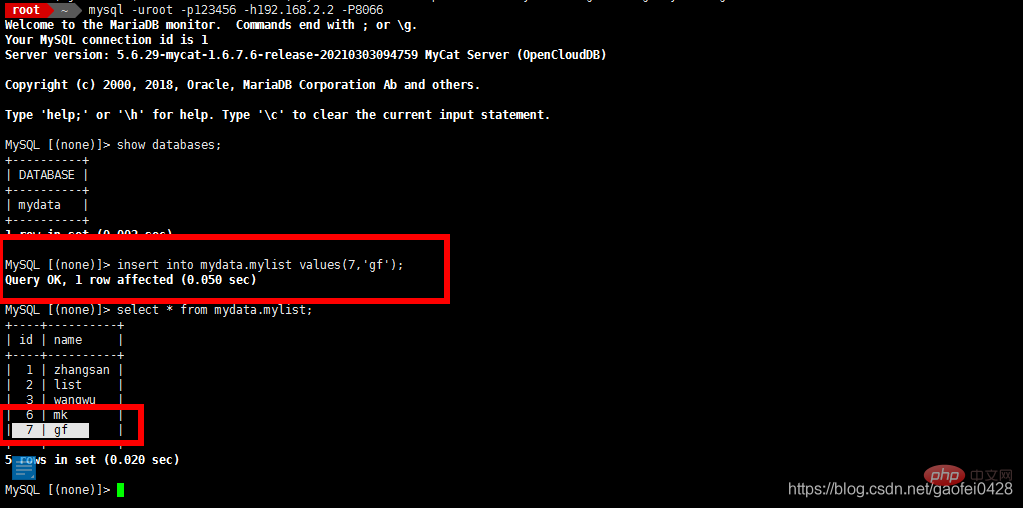
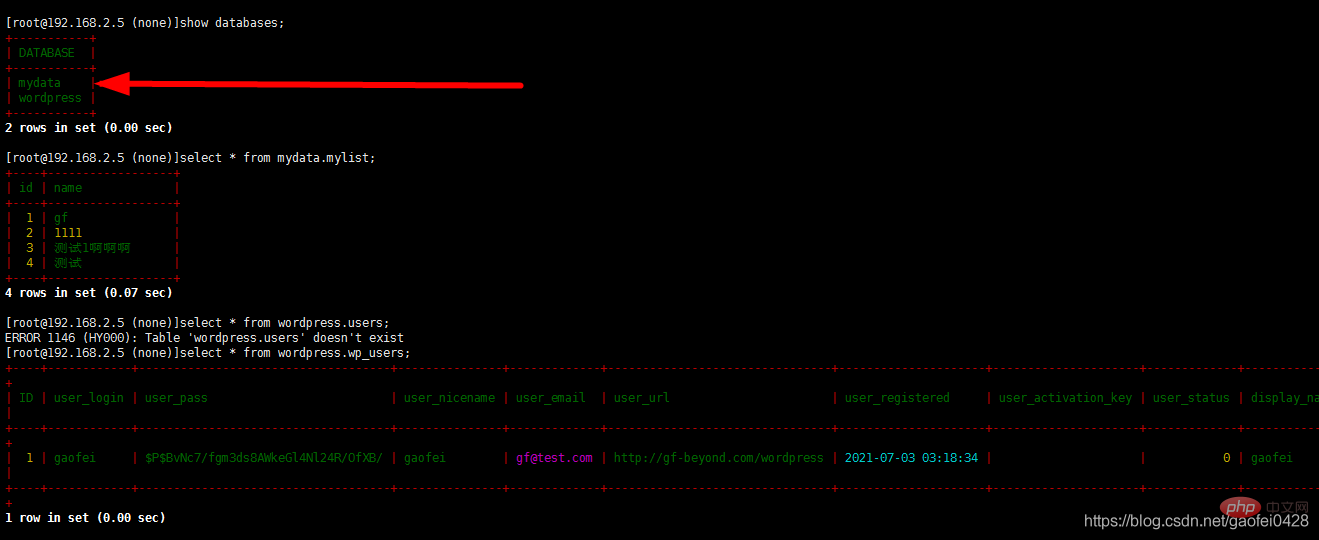
- select * à partir de mydata.mylist;
 Écrire des données ou modifier des données
Écrire des données ou modifier des données
- insérer dans les valeurs de mydata.mylist (10, 'test');

- Simuler une panne , Arrêtez d'abord le serveur esclave 192.168.2.5
Systemctl Stop Mariadb.Service

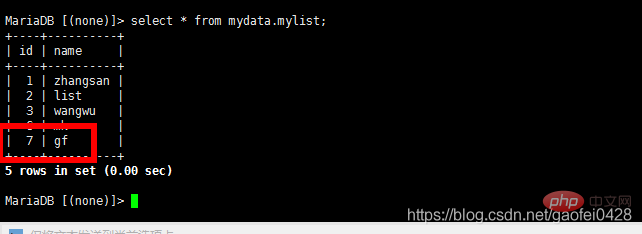
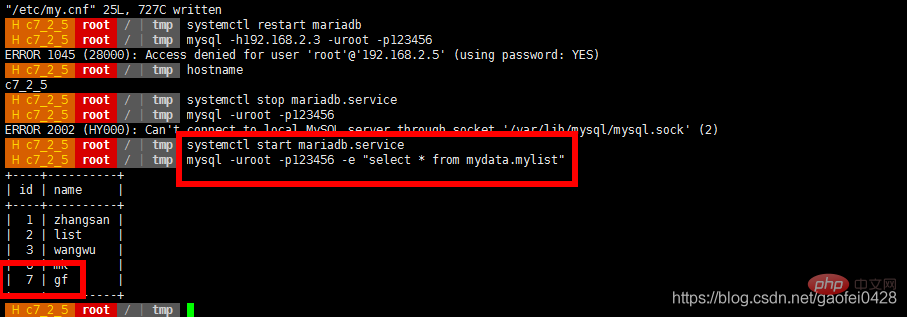
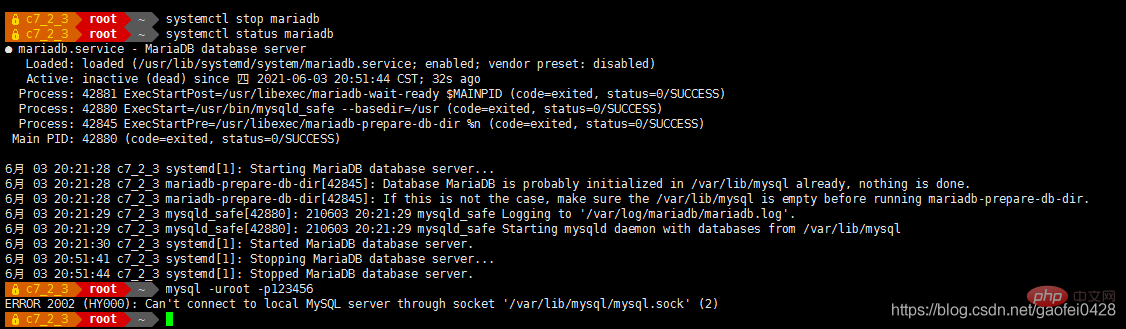
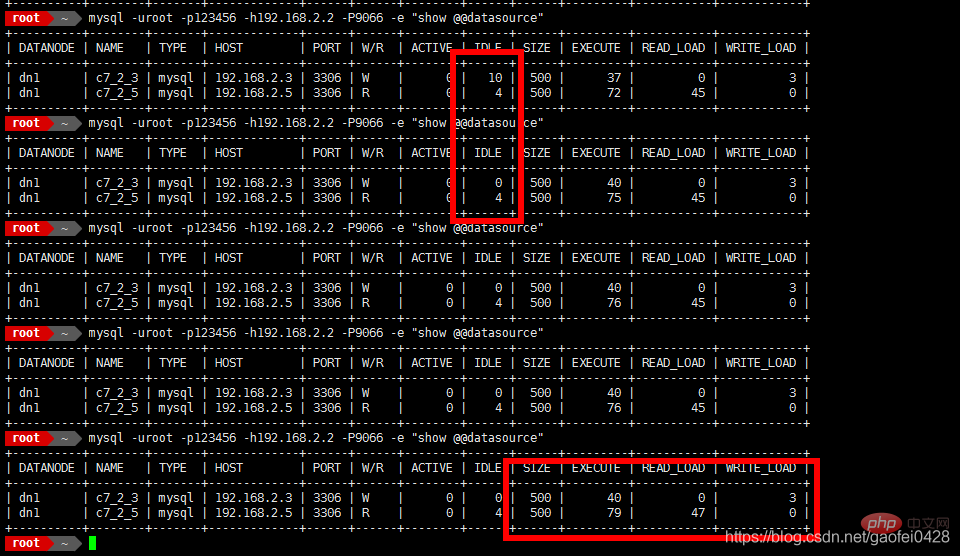
- La requête est normale, j'essaie d'écrire des données
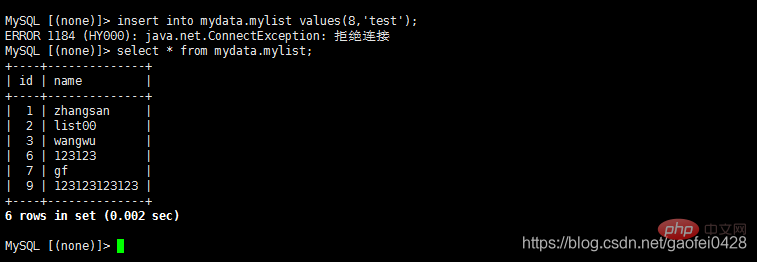
- La requête est normale mais ne peut pas être écrite
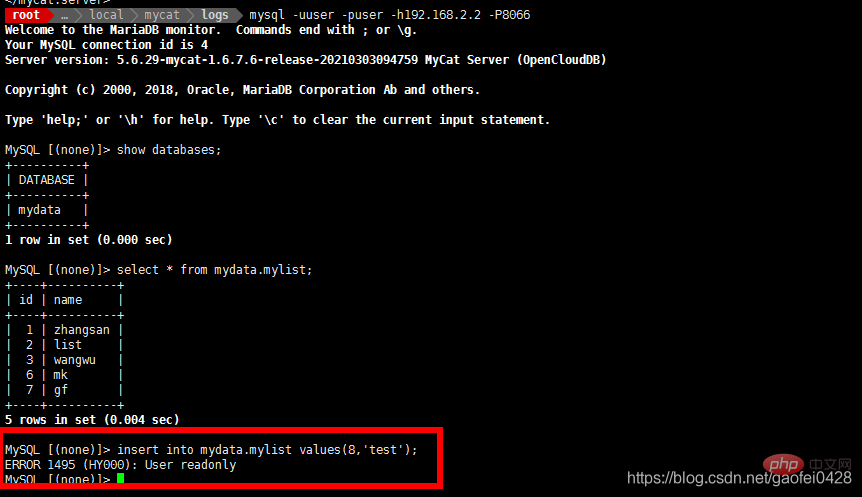
- Ajouter plusieurs bibliothèques
- vim chat /usr/ local/mycat /conf/server.xml
-
vim /usr/local/mycat/conf/schema.xml
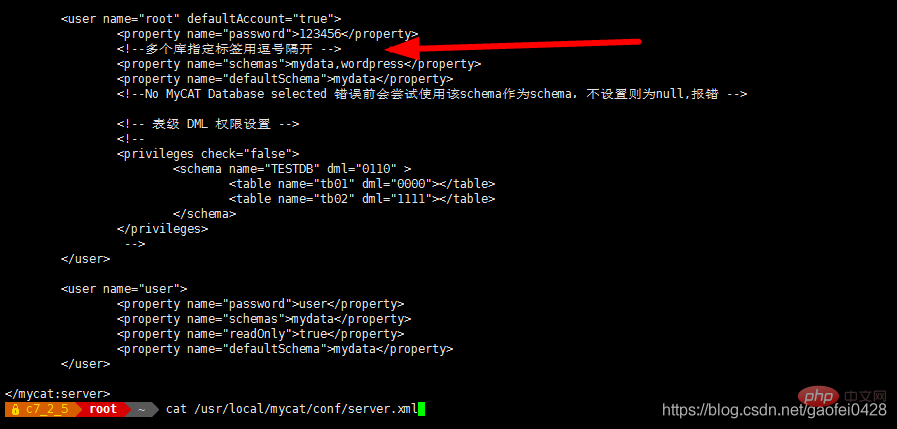 < ;dataNode name="dn2" dataHost="dthost1" database="wordpress"/>
< ;dataNode name="dn2" dataHost="dthost1" database="wordpress"/>- Après avoir ajouté le service de redémarrage
 tail /usr/ local/mycat/logs/wrpper.log
tail /usr/ local/mycat/logs/wrpper.log
 Gestion des erreurs
Gestion des erreurs
 Échec du démarrage : délai d'attente dépassé pour un signal de la JVM.
Échec du démarrage : délai d'attente dépassé pour un signal de la JVM.
- Solution
Ajoutez
wrapper.startup.timeout=300 dans wrapper.conf // timeout 300 secondes
wrapper.ping.timeout=120
Recommandé apprentissage : tutoriel vidéo mysql
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL est un système de gestion de base de données relationnel open source. 1) Créez une base de données et des tables: utilisez les commandes CreateDatabase et CreateTable. 2) Opérations de base: insérer, mettre à jour, supprimer et sélectionner. 3) Opérations avancées: jointure, sous-requête et traitement des transactions. 4) Compétences de débogage: vérifiez la syntaxe, le type de données et les autorisations. 5) Suggestions d'optimisation: utilisez des index, évitez de sélectionner * et utilisez les transactions.
 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL sont des compétences essentielles pour les développeurs. 1.MySQL est un système de gestion de base de données relationnel open source, et SQL est le langage standard utilisé pour gérer et exploiter des bases de données. 2.MySQL prend en charge plusieurs moteurs de stockage via des fonctions de stockage et de récupération de données efficaces, et SQL termine des opérations de données complexes via des instructions simples. 3. Les exemples d'utilisation comprennent les requêtes de base et les requêtes avancées, telles que le filtrage et le tri par condition. 4. Les erreurs courantes incluent les erreurs de syntaxe et les problèmes de performances, qui peuvent être optimisées en vérifiant les instructions SQL et en utilisant des commandes Explication. 5. Les techniques d'optimisation des performances incluent l'utilisation d'index, d'éviter la numérisation complète de la table, d'optimiser les opérations de jointure et d'améliorer la lisibilité du code.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Comment récupérer les données après que SQL supprime les lignes
Apr 09, 2025 pm 12:21 PM
Comment récupérer les données après que SQL supprime les lignes
Apr 09, 2025 pm 12:21 PM
La récupération des lignes supprimées directement de la base de données est généralement impossible à moins qu'il n'y ait un mécanisme de sauvegarde ou de retour en arrière. Point clé: Rollback de la transaction: Exécutez Rollback avant que la transaction ne s'engage à récupérer les données. Sauvegarde: la sauvegarde régulière de la base de données peut être utilisée pour restaurer rapidement les données. Instantané de la base de données: vous pouvez créer une copie en lecture seule de la base de données et restaurer les données après la suppression des données accidentellement. Utilisez la déclaration de suppression avec prudence: vérifiez soigneusement les conditions pour éviter la suppression accidentelle de données. Utilisez la clause WHERE: Spécifiez explicitement les données à supprimer. Utilisez l'environnement de test: testez avant d'effectuer une opération de suppression.
