

Cet article vous présente quelques problèmes que vous pouvez rencontrer concernant les index dans MySQL. L'index peut être considéré comme un grand cœur de la base de données. Si une base de données n'a pas d'index, alors l'existence de la base de données elle-même n'a que peu d'importance. J'espère que cela aidera tout le monde.

L'index peut être considéré comme un grand cœur dans la base de données. Si une base de données n'a pas d'index, alors la base de données elle-même n'a que peu de signification et n'est pas différente d'un fichier ordinaire. Par conséquent, un bon index est particulièrement important pour le système de base de données. Aujourd'hui, parlons de l'index MySQL Du point de vue des détails et des affaires réelles, nous examinerons les avantages de l'index arborescent B+ dans MySQL, ainsi que les points de connaissances que nous avons. il faut faire attention lors de l’utilisation des index.
Au travail, le moyen le plus direct pour nous de juger si un champ de la table de données doit être indexé est : ce champ apparaîtra-t-il souvent dans nos conditions intermédiaires where ? . D’un point de vue macro, il n’y a aucun problème à penser ainsi, mais dans une perspective à long terme, une réflexion plus détaillée peut parfois être nécessaire. Par exemple, ne devons-nous pas seulement créer un index dans ce domaine ? Un index conjoint sur plusieurs champs est-il préférable ? En prenant une table utilisateur comme exemple, les champs de la table utilisateur peuvent inclure where条件中。从宏观的角度来说,这样思考没有问题,但是从长远的角度来看,有时可能需要更细致的思考,比如我们是不是不仅仅需要在这个字段上建立一个索引?多个字段的联合索引是不是更好?以一张用户表为例,用户表中的字段可能会有用户的姓名、用户的身份证号、用户的家庭地址等等。

现在有个需求需要根据用户的身份证号找到用户的姓名,这时候很显然想到的第一个办法就是在id_cardnom de l'utilisateur
numéro d'identification de l'utilisateur
,「1.
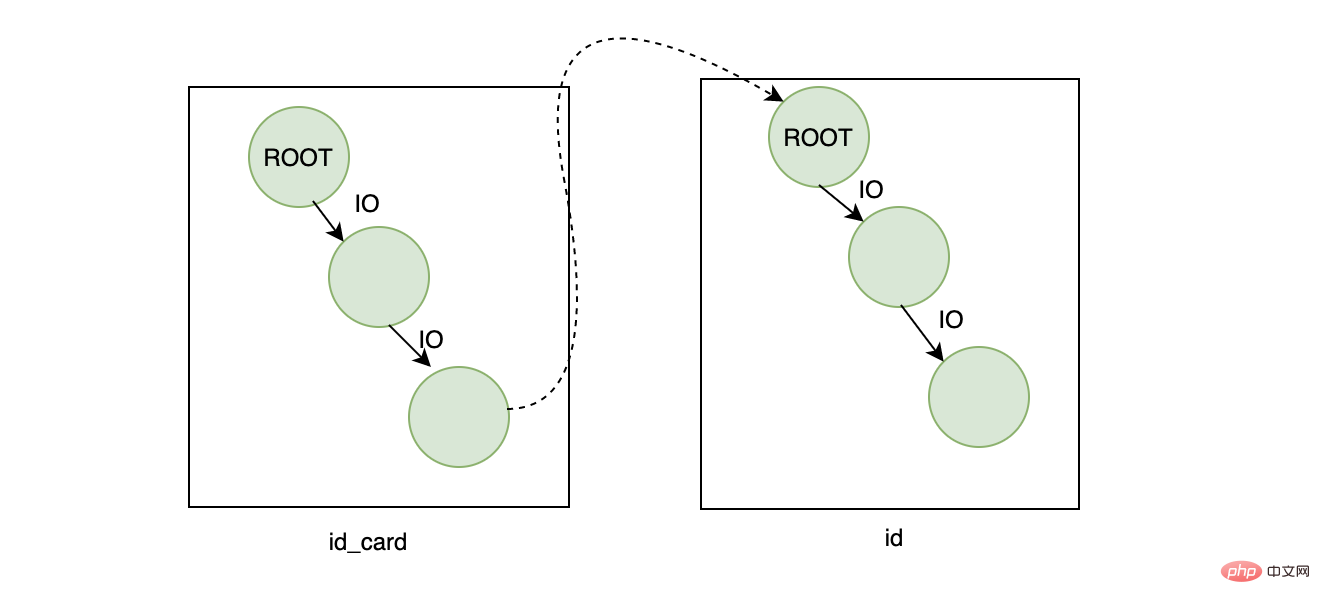 Il est désormais nécessaire de trouver le nom de l'utilisateur en fonction du numéro d'identification de l'utilisateur. À l'heure actuelle, la première façon qui vient à l'esprit est de créer un index sur
Il est désormais nécessaire de trouver le nom de l'utilisateur en fonction du numéro d'identification de l'utilisateur. À l'heure actuelle, la première façon qui vient à l'esprit est de créer un index sur id_card. est un index unique. , car le numéro d'identification est définitivement unique, alors lorsque nous exécutons la requête suivante :
SELECT name FROM user WHERE id_card=xxx
Pass Recherchez l'identifiant sur l'index de la clé primaire et trouvez le nom correspondant
D'un point de vue effet, le résultat ne pose pas de problème, mais d'un point de vue efficacité, il semble que cette requête soit un peu chère car il récupère deux arbres B+, en supposant qu'un arbre La hauteur est de 3, alors la hauteur des deux arbres est de 6, car le nœud racine est dans la mémoire (deux nœuds racine ici), donc le nombre final d'IO à effectuer sur le disque est 4 fois, en fonction du temps d'une E/S de disque aléatoire. Si la consommation de temps moyenne est de 10 ms, cela prendra finalement 40 ms. Ce nombre est moyen, pas rapide.
「2. Le piège de l'index de clé primaire」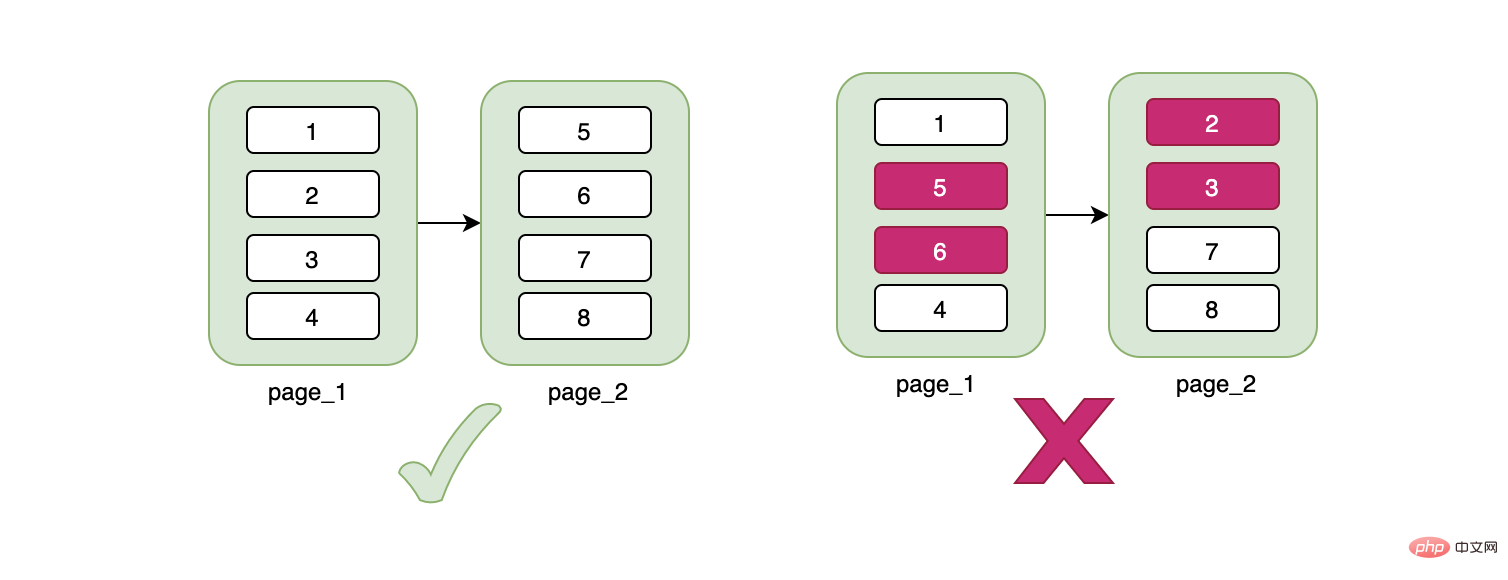
Puisque le problème est le retour de table, qui entraîne une récupération dans les deux arbres, alors le problème principal est de voir s'il peut être récupéré dans un seul arbre. . D'un point de vue commercial, vous avez peut-être trouvé un point d'entrée ici. Le numéro d'identification est unique, notre clé primaire ne peut-elle pas utiliser l'identifiant d'incrémentation automatique par défaut ? La table n'a besoin que d'un seul index, et toutes les données requises, y compris notre nom, peuvent être trouvées via le numéro d'identification. Il semble raisonnable d'y penser simplement tant que vous spécifiez l'ID comme numéro d'identification à chaque fois que vous insérez des données. , tout ira bien, mais avec précaution Il semble y avoir un problème quand j'y pense.
Examinons les caractéristiques des arbres B+. Les données des arbres B+ sont stockées sur des nœuds feuilles, et les données sont gérées en pages. Même si nous avons maintenant une ligne de données, elle occupera une page de données de 16 Ko. Ce n'est que lorsque notre page de données sera pleine qu'elle sera écrite sur une nouvelle page de données. La nouvelle page de données et l'ancienne page de données sont physiquement séparées. pas nécessairement continue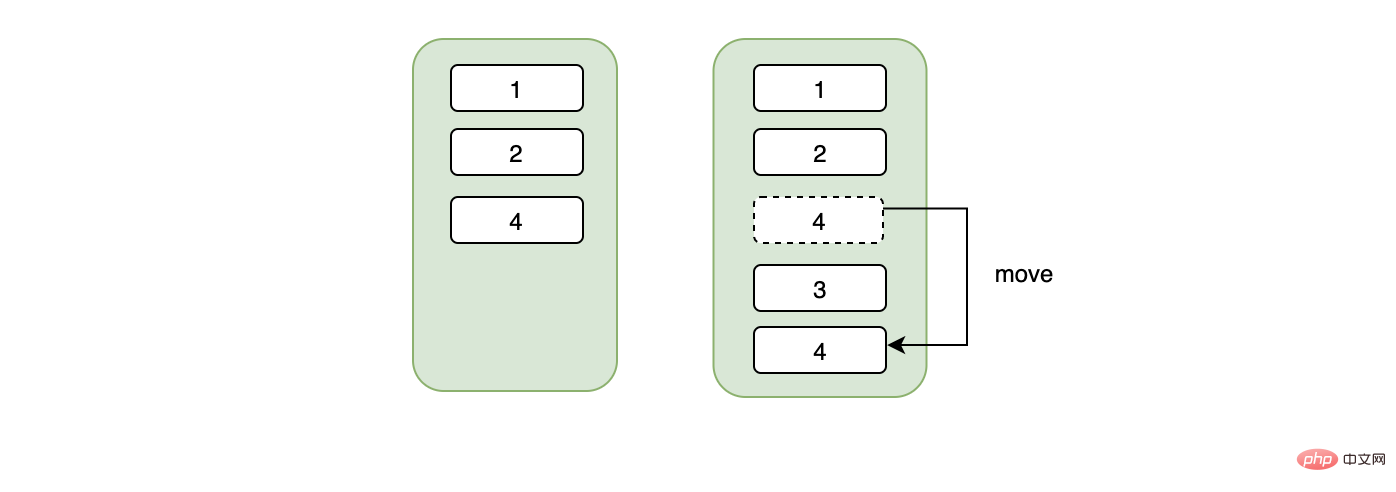 , et une chose est très importante Bien que la page de données soit physiquement discontinue, les données sont logiquement continues
, et une chose est très importante Bien que la page de données soit physiquement discontinue, les données sont logiquement continues
总结来说,不连续的身份证号当主键可能会造成页数据的移动、随机IO、频繁申请新页相关的开销。如果我们用的是自增的主键,那么对于id来说一定是顺序的,不会因为随机IO造成数据移动的问题,在插入方面开销一定是相对较小的。
其实不推荐用身份证号当主键的还有另外一个原因:身份证号作为数字来说太大了,得用bigint来存,正常来说一个学校的学生用int已经足够了,我们知道一页可以存放16K,当一个索引本身占用的空间越大时,会导致一页能存放的数据越少,所以在一定数据量的情况下,使用bigint要比int需要更多的页也就是更多的存储空间。
由上面两条结论可以得出:
所以自然而然地想到了联合索引,创建一个【身份证号+姓名】的联合索引,注意联合索引的顺序,要符合最左原则。这样当我们同样执行以下sql时:
select name from user where id_card=xxx
不需要回表就可以得到我们需要的name字段,然而还是没有解决身份证号本身占用空间过大的问题,这是业务数据本身的问题,如果你要解决它的话,我们可以通过一些转换算法将原本大的数据转换成小的数据,比如crc32:
crc32.ChecksumIEEE([]byte("341124199408203232"))可以将原本需要8个字节存储空间的身份证号用4个字节的crc码替代,因此我们的数据库需要再加个字段crc_id_card,联合索引也从【身份证号+姓名】变成了【crc32(身份证号)+姓名】,联合索引占的空间变小了。但是这种转换也是有代价的:
每次额外的crc,导致需要更多cpu资源
额外的字段,虽然让索引的空间变小了,但是本身也要占用空间
crc会存在冲突的概率,这需要我们查询出来数据后,再根据id_card过滤一下,过滤的成本根据重复数据的数量而定,重复越多,过滤越慢。
关于联合索引存储优化,这里有个小细节,假设现在有两个字段A和B,分别占用8个字节和20个字节,我们在联合索引已经是[A,B]的情况下,还要支持B的单独查询,因此自然而然我们在B上也建立个索引,那么两个索引占用的空间为 8+20+20=48,现在无论我们通过A还是通过B查询都可以用到索引,如果在业务允许的条件下,我们是否可以建立[B,A]和A索引,这样的话,不仅满足单独通过A或者B查询数据用到索引,还可以占用更小的空间:20+8+8=36。
有时候我们需要索引的字段是字符串类型的,并且这个字符串很长,我们希望这个字段加上索引,但是我们又不希望这个索引占用太多的空间,这时可以考虑建立个前缀索引,以这个字段的前一部分字符建立个索引,这样既可以享受索引,又可以节省空间,这里需要注意的是在前缀重复度较高的情况下,前缀索引和普通索引的速度应该是有差距的。
alter table xx add index(name(7));#name前7个字符建立索引 select xx from xx where name="JamesBond"
在说唯一索引之前,我们先了解下普通索引的特点,我们知道对于B+树而言,叶子节点的数据是有序的。
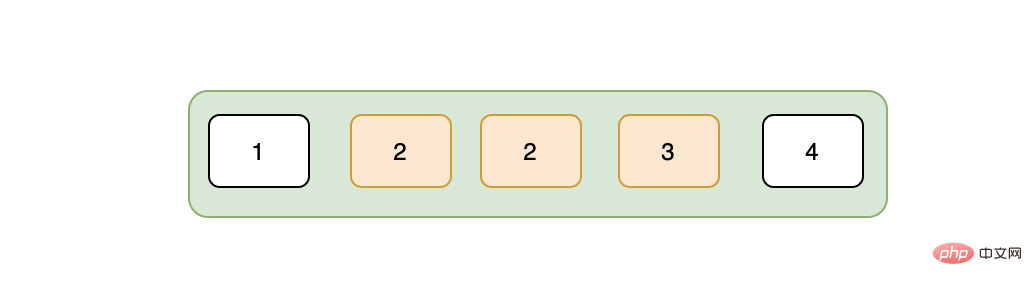
假设现在我们要查询2这条数据,那么在通过索引树找到2的时候,存储引擎并没有停止搜索,因为可能存在多个2,这表现为存储引擎会在叶子节点上接着向后查找,在找到第二个2之后,就停止了吗?答案是否,因为存储引擎并不知道后面还有没有更多的2,所以得接着向后查找,直至找到第一个不是2的数据,也就是3,找到3之后,停止检索,这就是普通索引的检索过程。
唯一索引就不一样了,因为唯一性,不可能存在重复的数据,所以在检索到我们的目标数据之后直接返回,不会像普通索引那样还要向后多查找一次,从这个角度来看,唯一索引是要比普通索引快的,但是当普通索引的数据都在一个页内的话,其实也并不会快多少。在数据的插入方面,唯一索引可能就稍逊色,因为唯一性,每次插入的时候,都需要将判断要插入的数据是否已经存在,而普通索引不需要这个逻辑,并且很重要的一点是唯一索引会用不到change buffer(见下文)。
在工作中,你可能会遇到这样的情况:这个字段我需不需要加索引?。对于这个问题,我们常用的判断手段就是:查询会不会用到这个字段,如果这个字段经常在查询的条件中,我们可能会考虑加个索引。但是如果只根据这个条件判断,你可能会加了一个错误的索引。我们来看个例子:假设有张用户表,大概有100w的数据,用户表中有个性别字段表示男女,男女差不多各占一半,现在我们要统计所有男生的信息,然后我们给性别字段加了索引,并且我们这样写下了sql:
select * from user where sex="男"
如果不出意外的话,InnoDB是不会选择性别这个索引的。如果走性别索引,那么一定是需要回表的,在数据量很大的情况下,回表会造成什么样的后果?我贴一张和上面一样的图想必大家都知道了:
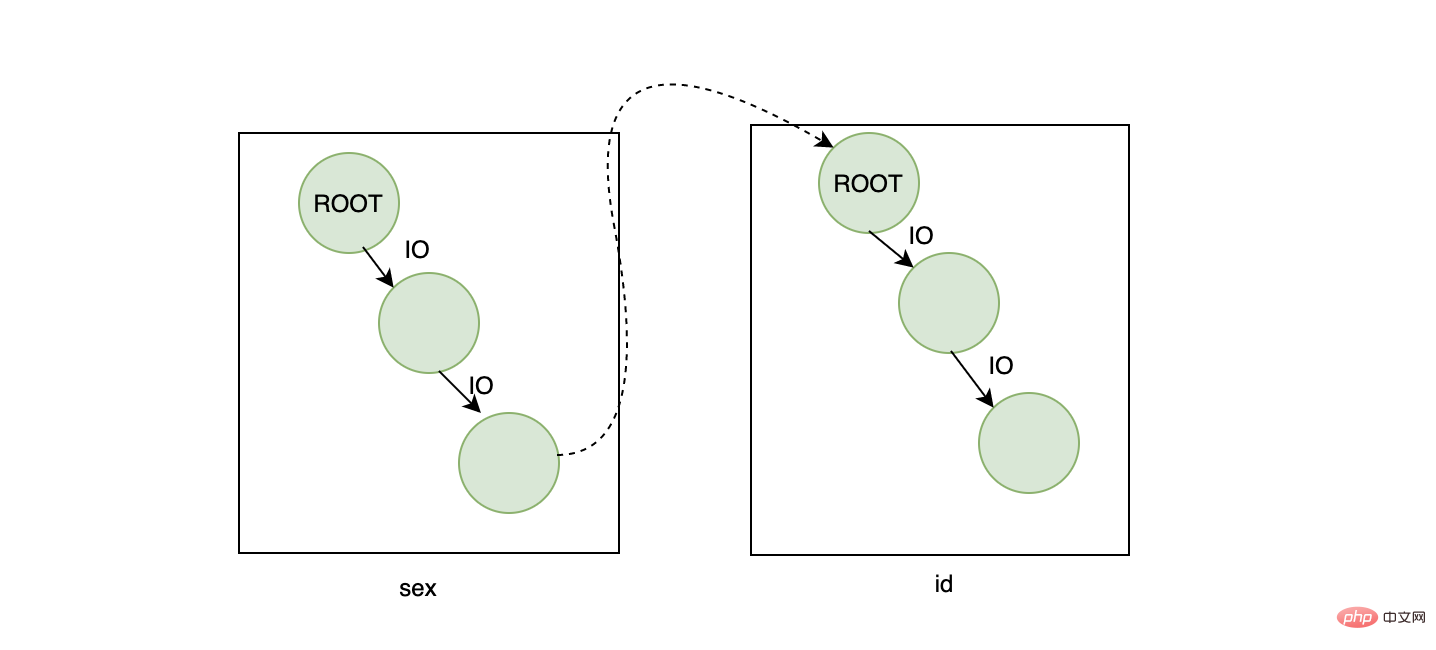
主要就是大量的IO,一条数据需要4次,那么50w的数据呢?结果可想而知。因此针对这种情况,MySQL的优化器大概率走全表扫描,直接扫描主键索引,因为这样性能可能会更高。
某些情况下,因为我们自己使用的不当,导致mysql用不到索引,这一般很容易发生在类型转换方面,也许你会说,mysql不是已经支持隐式转换了吗?比如现在有个整型的user_id索引字段,我们因为查询的时候没注意,写成了:
select xx from user where user_id="1234"
注意这里是字符的1234,当发生这种情况下,MySQL确实足够聪明,会把字符的1234转成数字的1234,然后愉快的使用了user_id索引。 但是如果我们有个字符型的user_id索引字段,还是因为我们查询的时候没注意,写成了:
select xx from user where user_id=1234
这时候就有问题了,会用不到索引,也许你会问,这时MySQL为什么不会转换了,把数字的1234转成字符型的1234不就行了? 这里需要解释下转换的规则了,当出现字符串和数字比较的时候,要记住:MySQL会把字符串转换成数字。也许你又会问:为什么把字符型user_id字段转换成数字就用不到索引了? 这又要说到B+树索引的结构了,我们知道B+树的索引是按照索引的值来分叉和排序的,当我们把索引字段发生类型转换时会发生值的变化,比如原来是A值,如果执行整型转换可能会对应一个B值(int(A)=B),这时这颗索引树就不能用了,因为索引树是按照A来构造的,不是B,所以会用不到索引。
我们知道在更新一条数据的时候,要先判断这条数据的页是否在内存里,如果在的话,直接更新对应的内存页,如果不在的话,只能去磁盘把对应的数据页读到内存中来,然后再更新,这会有什么问题呢?
为了解决这种情况下的速度问题,change buffer出现了,首先不要被buffer这个单词误导,change buffer除了会在公共的buffer pool里之外,也是会持久化到磁盘的。当有了change buffer之后,我们更新的过程中,如果发现对应的数据页不在内存里的话,也不去磁盘读取相应的数据页了,而是把要更新的数据放入到change buffer中,那change buffer的数据何时被同步到磁盘上去?如果此时发生读动作怎么办?首先后台有个线程会定期把change buffer的数据同步到磁盘上去的,如果线程还没来得及同步,但是又发生了读操作,那么也会触发把change buffer的数据merge到磁盘的事件。
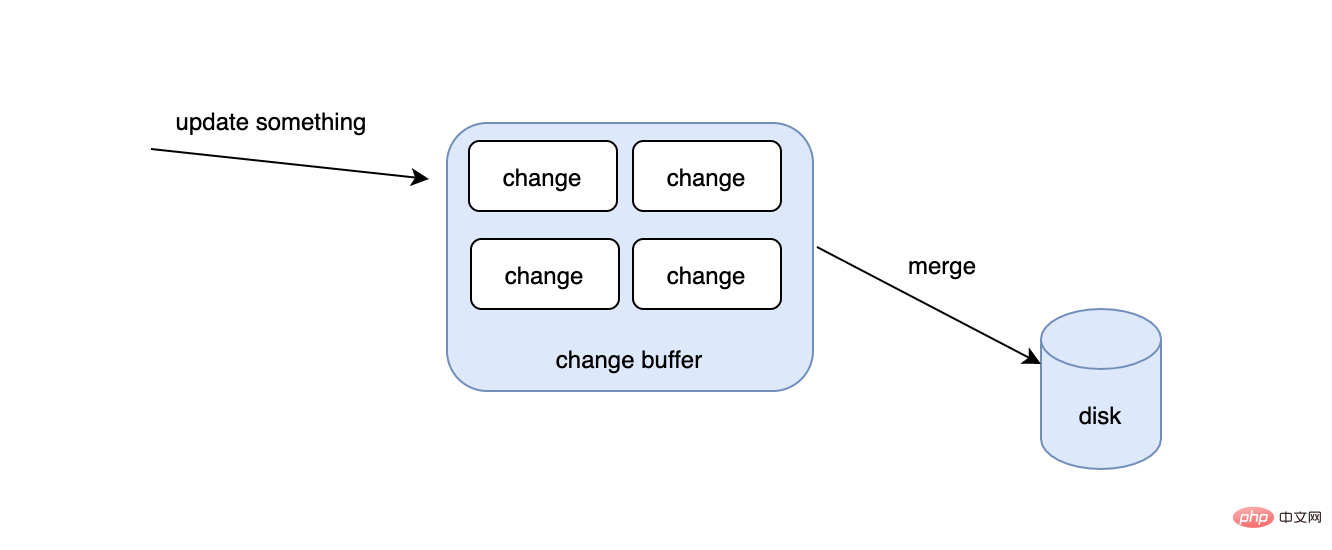
需要注意的是并不是所有的索引都能用到changer buffer,像主键索引和唯一索引就用不到,因为唯一性,所以它们在更新的时候要判断数据存不存在,如果数据页不在内存中,就必须去磁盘上把对应的数据页读到内存里,而普通索引就没关系了,不需要校验唯一性。change buffer越大,理论收益就越大,这是因为首先离散的读IO变少了,其次当一个数据页上发生多次变更,只需merge一次到磁盘上。当然并不是所有的场景都适合changer buffer,如果你的业务是更新之后,需要立马去读,changer buffer会适得其反,因为需要不停地触发merge动作,导致随机IO的次数不会变少,反而增加了维护changer buffer的开销。
前面我们说了联合索引,联合索引要满足最左原则,即在联合索引是[A,B]的情况下,我们可以通过以下的sql用到索引:
select * from table where A="xx" select * from table where A="xx" AND B="xx"
其实联合索引也可以使用最左前缀的原则,即:
select * from table where A like "赵%" AND B="上海市"
但是这里需要注意的是,因为使用了A的一部分,在MySQL5.6之前,上面的sql在检索出所有A是“赵”开头的数据之后,就立马回表(使用的select *),然后再对比B是不是“上海市”这个判断,这里是不是有点懵?为什么B这个判断不直接在联合索引上判断,这样的话回表的次数不就少了吗?造成这个问题的原因还是因为使用了最左前缀的问题,导致索引虽然能使用部分A,但是完全用不到B,看起来是有点“傻”,于是在MySQL5.6之后,就出现了索引下推这个优化(Index Condition Pushdown),有了这个功能以后,虽然使用的是最左前缀,但是也可以在联合索引上搜索出符合A%的同时也过滤非B的数据,大大减少了回表的次数。
在说刷新邻接页之前,我们先说下脏页,我们知道在更新一条数据的时候,得先判断这条数据所在的页是否在内存中,如果不在的话,需要把这个数据页先读到内存中,然后再更新内存中的数据,这时会发现内存中的页有最新的数据,但是磁盘上的页却依然是老数据,那么此时这条数据所在的内存中的页就是脏页,需要刷到磁盘上来保持一致。所以问题来了,何时刷?每次刷多少脏页才合适?如果每次变更就刷,那么性能会很差,如果很久才刷,脏页就会堆积很多,造成内存池中可用的页变少,进而影响正常的功能。所以刷的速度不能太快但要及时,MySQL有个清理线程会定期执行,保证了不会太快,当脏页太多或者redo log已经快满了,也会立刻触发刷盘,保证了及时。
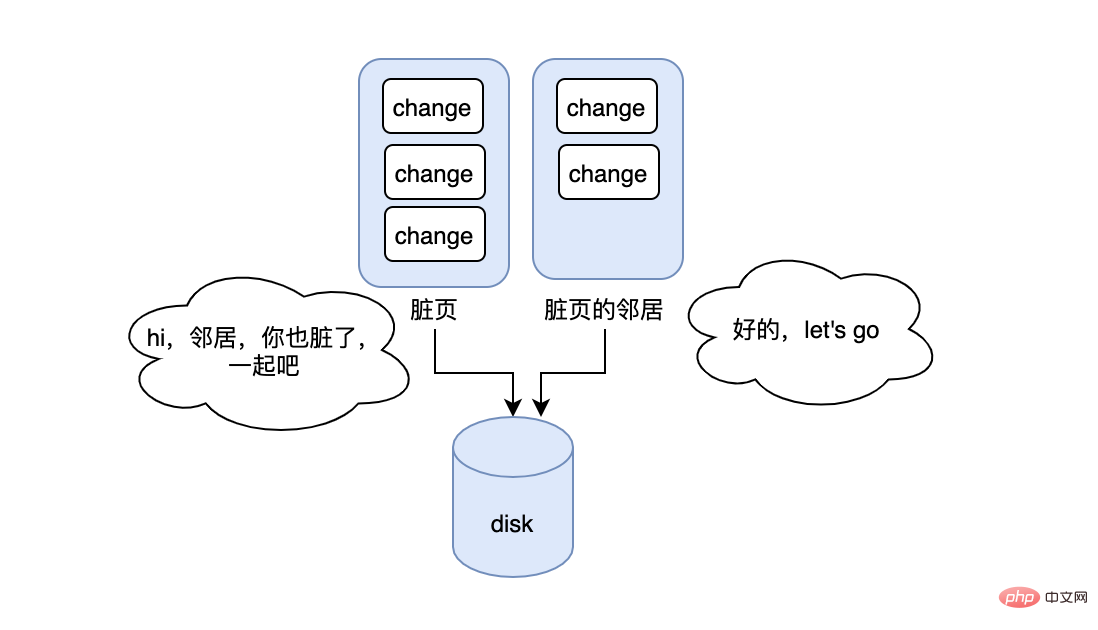
在脏页刷盘的过程中,InnoDB这里有个优化:如果要刷的脏页的邻居页也脏了,那么就顺带一起刷,这样的好处就是可以减少随机IO,在机械磁盘的情况下,优化应该挺大,但是这里可能会有坑,如果当前脏页的邻居脏页在被一起刷入后,邻居页立马因为数据的变更又变脏了,那此时是不是有种多此一举的感觉,并且反而浪费了时间和开销。更糟糕的是如果邻居页的邻居也是脏页...,那么这个连锁反应可能会出现短暂的性能问题。
在实际业务中,我们可能会被告知尽量使用覆盖索引,不要回表,因为回表需要更多IO,耗时更长,但是有时候我们又不得不回表,回表不仅仅会造成过多的IO,更严重的是过多的离散IO。
select * from user where grade between 60 and 70
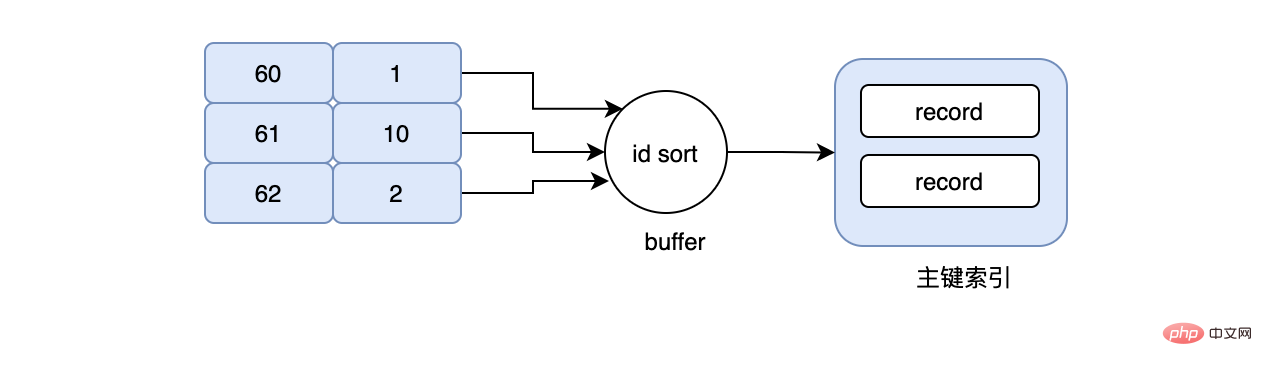
现在要查询成绩在60-70之间的用户信息,于是我们的sql写成上面的那样,当然我们的grade字段是有索引的,按照常理来说,会先在grade索引上找到grade=60这条数据,然后再根据grade=60这条数据对应的id去主键索引上找,最后再次回到grade索引上,不停的重复同样的动作..., 假设现在grade=60对应的id=1,数据是在page_no_1上,grade=61对应的id=10,数据是在page_no_2上,grade=62对应的id=2,数据是在page_no_1上,所以真实的情况就是先在page_no_1上找数据,然后切到page_no_2,最后又切回page_no_1上,但其实id=1和id=2完全可以合并,读一次page_no_1即可,不仅节省了IO,同时避免了随机IO,这就是MRR。当使用MRR之后,辅助索引不会立即去回表,而是将得到的主键id,放在一个buffer中,然后再对其排序,排序后再去顺序读主键索引,大大减少了离散的IO。
推荐学习:mysql视频教程
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié










![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



