
 base de données
tutoriel mysql
Maîtriser complètement le processus d'écriture du journal binaire dans MySql
base de données
tutoriel mysql
Maîtriser complètement le processus d'écriture du journal binaire dans MySql
Maîtriser complètement le processus d'écriture du journal binaire dans MySql

Cet article vous apporte des connaissances pertinentes sur le processus d'écriture du journal binaire dans MySQL, y compris les problèmes liés à "sync_binlog", "binlog_cache_size" et "max_binlog_cache_size". J'espère qu'il sera utile à tout le monde.

Processus d'écriture du journal binaire
Jetons d'abord un coup d'œil à la description du document officiel de la configuration de sync_binlog.
sync_binlog
| Format de ligne de commande | --sync-binlog=# |
| Variables système | sync_bin log |
| portée d'influence | Global |
| Dynamique | Oui |
| L'invite SET_VAR s'applique | Non |
| Type | Entier |
| Par défaut | 1 |
| Valeur minimale | 0 |
| Valeur maximale | 2^32=4294967295 |
Contrôlez la fréquence à laquelle le serveur MySQL synchronise les journaux binaires sur le disque.
sync_binlog=0 : empêche le serveur MySQL de synchroniser les journaux binaires sur le disque. Au lieu de cela, le serveur MySQL s'appuie sur le système d'exploitation pour vider le journal binaire sur le disque de temps en temps, comme il le ferait pour n'importe quel autre fichier. Ce paramètre offre les meilleures performances, mais en cas de panne de courant ou de panne du système d'exploitation, le serveur peut avoir validé des transactions qui n'ont pas encore été vidées.
sync_binlog=1 : Activez la synchronisation du journal binaire sur le disque avant de valider une transaction. Il s'agit du paramètre le plus sûr, mais il peut avoir un impact négatif sur les performances en raison de l'augmentation des écritures sur le disque. En cas de panne de courant ou de panne du système d'exploitation, les transactions perdues dans le journal binaire sont uniquement à l'état préparé. Cela permet une récupération automatique régulière pour annuler les transactions, garantissant ainsi que les transactions ne seront pas perdues dans le journal binaire.
sync_binlog=N, qui est une valeur autre que 0 ou 1 : après la collecte de N groupes de soumission de journaux binaires, le journal binaire sera synchronisé sur le disque. En cas de panne de courant ou de panne du système d'exploitation, le serveur peut avoir validé des transactions qui n'ont pas encore été vidées dans le journal binaire. Ce paramètre peut avoir un impact négatif sur les performances en raison de l'augmentation des écritures sur le disque. Des valeurs plus élevées améliorent les performances mais augmentent le risque de perte de données.
InnoDBPour obtenir la plus grande durabilité et cohérence possible dans une configuration de réplication utilisée avec des transactions, utilisez les paramètres suivants : InnoDB为了在与事务一起使用 的复制设置中获得最大可能的持久性和一致性,请使用以下设置:
- sync_binlog=1.
- innodb_flush_log_at_trx_commit=1.
sync_binlog=1.innodb_flush_log_at_trx_commit=1. >警告
许多操作系统和一些磁盘硬件欺骗了刷新到磁盘操作。他们可能会告诉 mysqld已经发生了刷新,即使它还没有发生。在这种情况下,即使使用推荐的设置也无法保证事务的持久性,在最坏的情况下,断电可能会损坏
InnoDB
-
Avertissement
- De nombreux systèmes d'exploitation et certains matériels de disque trompent l'opération de vidage sur disque. Ils peuvent dire à mysqld qu'une actualisation a eu lieu même si elle ne s'est pas encore produite. Dans ce cas, la durabilité des transactions n'est pas garantie même avec les paramètres recommandés, et dans le pire des cas, une panne de courant peut corrompre les données
InnoDB. L'utilisation d'un cache disque sauvegardé par batterie dans le contrôleur de disque SCSI ou sur le disque lui-même accélère l'actualisation des fichiers et rend les opérations plus sécurisées. Vous pouvez également essayer de désactiver la mise en cache des écritures sur disque dans le cache matériel. Le type de paramètre - Résumé
- sync_binlog est un entier non signé.
Généralement, il n'est pas défini sur 0. 0 dépend du fonctionnement du système et d'une fsync irrégulière. Cela est plus dangereux en cas de panne de courant ou de panne du système - la transaction est soumise mais le journal binaire est manquant.
Il est plus sûr de le définir sur 1, d'obtenir la durabilité et la cohérence maximales possibles, et d'assurer une réplication et une récupération maître-esclave ultérieures. Cependant, cela nuit aux performances et peut être défini lorsque les IOPS requises par l'entreprise ne sont pas élevées.
Le but de définir une valeur supérieure à 1 est d'améliorer les performances. Il ne s'agit pas seulement de valider une transaction par fsync, ce qui équivaut à un vidage par lots, mais en cas de panne de courant ou de panne du système. le journal binaire manquera davantage. Il serait plus sûr si le disque lui-même utilisait un cache disque sauvegardé par batterie. Par conséquent, il peut être défini lorsque les IOPS requises par l'entreprise sont relativement élevées, mais en général, il ne sera pas trop élevé et peut se situer dans la plage [100, 1000].
De plus, à travers la description de sync_binlog=0, nous pouvons aussi à peu près sentir que lorsque la transaction est soumise, même si elle ne se synchronise pas immédiatement, elle a en fait été écrite dans le cache de pages du système de fichiers. mysql est dans la transaction Lors de l'exécution, il y aura également un cache qui mettra en cache le journal binaire généré dans la transaction. binlog_cache_sizeFormat de commande--binlog-cache-size=#Variable systèmebinlog_cache_sizerangeGolbalDynamiqueOuiL'invite SET_VAR s'appliqueNonTypeEntierValeur par défaut32768Valeur minimale4096Valeur maximale ( 64 -bit plate-forme)2^64=18446744073709547520max (plateforme 32 bits)2^32=4294967295| Continuons à examiner la configuration liée au cache du journal binaire lorsque la transaction est en cours d'exécution. | |
|---|---|
La taille de la mémoire tampon destinée à contenir le journal binaire change au cours d'une transaction. La valeur doit être un multiple de 4096.
Lorsque la journalisation binaire est activée sur un serveur (la variable système log_bin est définie sur ON), chaque client se voit attribuer un cache de journal binaire si le serveur prend en charge un moteur de stockage de transactions. Si les données d'une transaction dépassent l'espace dans la mémoire tampon, les données excédentaires sont stockées dans un fichier temporaire. Lorsque le chiffrement des journaux binaires est actif sur le serveur, la mémoire tampon n'est pas chiffrée, mais (à partir de MySQL 8.0.17) tous les fichiers temporaires utilisés pour contenir le cache des journaux binaires sont chiffrés. Une fois chaque transaction validée, le cache du journal binaire est réinitialisé en effaçant la mémoire tampon et en tronquant le fichier temporaire (s'il est utilisé).
Si vous utilisez fréquemment des transactions volumineuses, vous pouvez augmenter cette taille de cache pour de meilleures performances en réduisant ou en éliminant le besoin d'écrire des fichiers temporaires. Binlog_cache_use (variable d'état du service - le nombre de transactions utilisant le cache du journal binaire) et Binlog_cache_disk_use (variable d'état du service - le nombre de transactions utilisant le cache du journal binaire temporaire mais dépassant la valeur binlog_cache_size et utilisant des fichiers temporaires pour stocker les instructions de transaction.) variables d'état peut être utilisé pour ajuster cette taille variable. Voir Section 5.4.4, « Journaux binaires ».
binlog_cache_sizeDéfinit uniquement la taille du cache de transactions ; la taille du cache d'instructions est contrôlée par la variable système binlog_stmt_cache_size. Le type de paramètre
Résumé
- binlog_cache_size est un entier non signé.
- est utilisé pour indiquer la taille utilisée pour mettre en cache le journal binaire lors de chaque transaction. La valeur par défaut est 32 Ko et doit être un multiple de 4096. Si cette valeur est dépassée, le stockage de fichiers temporaires sera utilisé.
- Essayez de ne pas utiliser de transactions importantes dans les affaires. Si la transaction est trop importante, vous devez vous demander si elle est raisonnable. Généralement, il n'est pas nécessaire de modifier binlog_cache_size, 32 Ko suffisent.
- Lorsque binlog_cache_size ne suffit pas, les fichiers temporaires seront utilisés pour le stockage, mais les performances seront inférieures. Nous pouvons définir max_binlog_cache_size=binlog_cache_size afin que les fichiers temporaires ne soient pas utilisés, ce qui sera présenté ci-dessous.
max_binlog_cache_size
| Format de commande | --max-binlog-cache-size=# |
| Système variables | max_binlog_cache_size |
| range | Golbal |
| Dynamique | Oui |
| L'invite SET_VAR s'applique | Non |
| Type | Entier |
| Valeur par défaut | 2^64 =18 446744073709547520 |
| minimum | 4096 |
| maximum | 2^64=18446744073709547520 |
| taille du bloc | 4096 |
Si une transaction nécessite plus de ce nombre d'octets de mémoire, le serveur générera une transaction multi-instructions nécessitant plus de 'max_binlog_cache_size' octets d'erreur de stockage. La valeur minimale est 4096. La valeur maximale possible est de 16EiB (exbioctets). La valeur maximale recommandée est de 4 Go ; ceci est dû au fait que MySQL ne peut actuellement pas gérer les emplacements de journaux binaires supérieurs à 4 Go. La valeur doit être un multiple de 4096.
max_binlog_cache_size définit uniquement la taille du cache de transactions ; la limite supérieure du cache d'instructions est contrôlée par la variable système max_binlog_stmt_cache_size. max_binlog_cache_size仅设置事务缓存的大小;语句缓存的上限由 max_binlog_stmt_cache_size 系统变量控制。
会话的可见性 max_binlog_cache_size
max_binlog_cache_size correspond à la visibilité de la variable système binlog_cache_size ; en d'autres termes, la modification de sa valeur n'affectera que les nouvelles sessions démarrées après la modification de la valeur. Résumé- max_binlog_cache_size est une valeur sûre, généralement définie en fonction de la mémoire pouvant être allouée par le serveur.
- Les transactions sont modifiées dans le cache du journal binaire de chaque transaction lors de leur exécution.
- Une fois la transaction soumise, elle est effectuée selon la configuration. Si sync_binlog=1, le cache sera libéré à chaque fois que fsync est effectué. Si sync_binlog=0, il sera écrit directement dans le cache de pages du fichier système, en s'appuyant sur le système d'exploitation pour vider le journal binaire de temps en temps. Si sync_binlog=N (N>1), cela équivaut à un vidage par lots. Bien entendu, le cache binlog détenu par chaque transaction sera libéré.
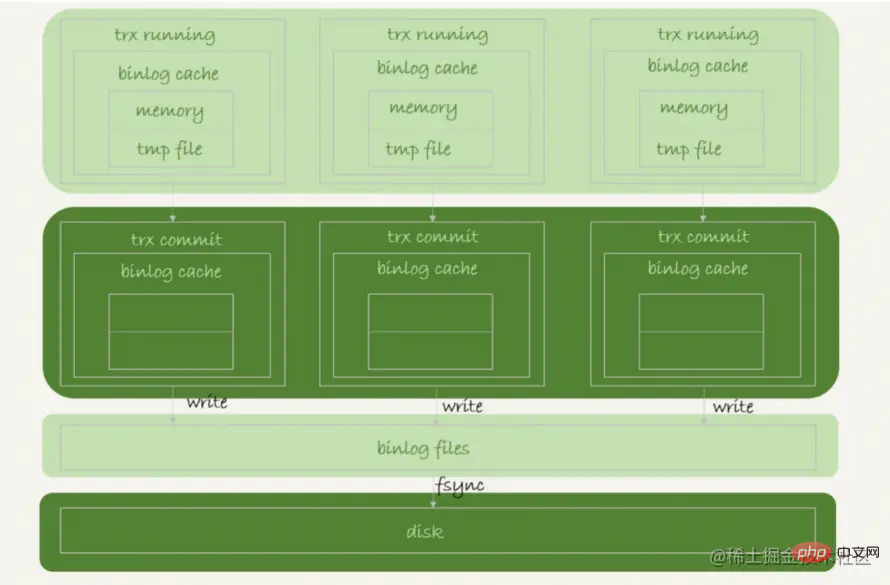
- sync_binlog : Si vous avez besoin d'obtenir une durabilité et une cohérence maximales, définissez-le sur 1. En ce qui concerne les problèmes de performances, vous pouvez ajuster le matériel et d'autres méthodes si le journal binaire peut être perdu ou perdu via d'autres ; méthodes, vous souhaitez le contrôler en fonction de la situation actuelle. Les ressources du serveur sont optimisées et définies dans l'intervalle [100,1000].
- binlog_cahe_size : Comme mentionné précédemment, dans les affaires réelles, il faut prêter attention au contrôle de la granularité des transactions. Dans la plupart des cas, la valeur par défaut de 32 000 est suffisante.
Apprentissage recommandé : Tutoriel vidéo MySQL
🎜Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.
Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL: la facilité de gestion des données pour les débutants
Apr 09, 2025 am 12:07 AM
MySQL: la facilité de gestion des données pour les débutants
Apr 09, 2025 am 12:07 AM
MySQL convient aux débutants car il est simple à installer, puissant et facile à gérer les données. 1. Installation et configuration simples, adaptées à une variété de systèmes d'exploitation. 2. Prise en charge des opérations de base telles que la création de bases de données et de tables, d'insertion, d'interrogation, de mise à jour et de suppression de données. 3. Fournir des fonctions avancées telles que les opérations de jointure et les sous-questionnaires. 4. Les performances peuvent être améliorées par l'indexation, l'optimisation des requêtes et le partitionnement de la table. 5. Prise en charge des mesures de sauvegarde, de récupération et de sécurité pour garantir la sécurité et la cohérence des données.
 MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL est un système de gestion de base de données relationnel open source. 1) Créez une base de données et des tables: utilisez les commandes CreateDatabase et CreateTable. 2) Opérations de base: insérer, mettre à jour, supprimer et sélectionner. 3) Opérations avancées: jointure, sous-requête et traitement des transactions. 4) Compétences de débogage: vérifiez la syntaxe, le type de données et les autorisations. 5) Suggestions d'optimisation: utilisez des index, évitez de sélectionner * et utilisez les transactions.
 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 Comment créer Navicat Premium
Apr 09, 2025 am 07:09 AM
Comment créer Navicat Premium
Apr 09, 2025 am 07:09 AM
Créez une base de données à l'aide de NAVICAT Premium: Connectez-vous au serveur de base de données et entrez les paramètres de connexion. Cliquez avec le bouton droit sur le serveur et sélectionnez Créer une base de données. Entrez le nom de la nouvelle base de données et le jeu de caractères spécifié et la collation. Connectez-vous à la nouvelle base de données et créez le tableau dans le navigateur d'objet. Cliquez avec le bouton droit sur le tableau et sélectionnez Insérer des données pour insérer les données.
 MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL sont des compétences essentielles pour les développeurs. 1.MySQL est un système de gestion de base de données relationnel open source, et SQL est le langage standard utilisé pour gérer et exploiter des bases de données. 2.MySQL prend en charge plusieurs moteurs de stockage via des fonctions de stockage et de récupération de données efficaces, et SQL termine des opérations de données complexes via des instructions simples. 3. Les exemples d'utilisation comprennent les requêtes de base et les requêtes avancées, telles que le filtrage et le tri par condition. 4. Les erreurs courantes incluent les erreurs de syntaxe et les problèmes de performances, qui peuvent être optimisées en vérifiant les instructions SQL et en utilisant des commandes Explication. 5. Les techniques d'optimisation des performances incluent l'utilisation d'index, d'éviter la numérisation complète de la table, d'optimiser les opérations de jointure et d'améliorer la lisibilité du code.
 Comment créer une nouvelle connexion à MySQL dans Navicat
Apr 09, 2025 am 07:21 AM
Comment créer une nouvelle connexion à MySQL dans Navicat
Apr 09, 2025 am 07:21 AM
Vous pouvez créer une nouvelle connexion MySQL dans NAVICAT en suivant les étapes: ouvrez l'application et sélectionnez une nouvelle connexion (CTRL N). Sélectionnez "MySQL" comme type de connexion. Entrez l'adresse Hostname / IP, le port, le nom d'utilisateur et le mot de passe. (Facultatif) Configurer les options avancées. Enregistrez la connexion et entrez le nom de la connexion.
 Comment récupérer les données après que SQL supprime les lignes
Apr 09, 2025 pm 12:21 PM
Comment récupérer les données après que SQL supprime les lignes
Apr 09, 2025 pm 12:21 PM
La récupération des lignes supprimées directement de la base de données est généralement impossible à moins qu'il n'y ait un mécanisme de sauvegarde ou de retour en arrière. Point clé: Rollback de la transaction: Exécutez Rollback avant que la transaction ne s'engage à récupérer les données. Sauvegarde: la sauvegarde régulière de la base de données peut être utilisée pour restaurer rapidement les données. Instantané de la base de données: vous pouvez créer une copie en lecture seule de la base de données et restaurer les données après la suppression des données accidentellement. Utilisez la déclaration de suppression avec prudence: vérifiez soigneusement les conditions pour éviter la suppression accidentelle de données. Utilisez la clause WHERE: Spécifiez explicitement les données à supprimer. Utilisez l'environnement de test: testez avant d'effectuer une opération de suppression.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
