
#同样在redis解压的或者安装的目录以管理员身份运行cmdredis-server --service-start
 base de données
Redis
Analyse approfondie de l'entrée en pratique et de la persévérance de Redis (partage de synthèse)
base de données
Redis
Analyse approfondie de l'entrée en pratique et de la persévérance de Redis (partage de synthèse)
Analyse approfondie de l'entrée en pratique et de la persévérance de Redis (partage de synthèse)

Cet article vous apporte des questions sur Redis de l'entrée à la pratique, y compris des didacticiels détaillés sur la prise en main de redis6.0, la persistance de redis, les principes de réplication de redis, la surveillance sentinelle de haute disponibilité de redis et les connaissances sur la construction de clusters. J'espère que cela aidera tout le monde. .

Tutoriel détaillé pour démarrer avec redis6.0, la persistance redis, le principe de réplication redis, la surveillance sentinelle haute disponibilité redis et la construction de clusters.
Intervieweur : Les gars, parlons de votre point de vue sur Redis.
Moi : Ah, qu'en penses-tu ? Asseyez-vous et regardez-le ou allongez-vous et regardez-le. Redis est petit ? bientôt? Mais durable ?
Intervieweur : J'ai dit sérieusement, je soupçonne que vous conduisez, non seulement vous conduisez mais vous faites aussi de la couleur.
Je :. . .
Intervieweur : Allez, allez, allez, mon temps est limité, ne dites pas de bêtises. Revenons au sujet, que savez-vous de Redis.
Me : Léger et de petite taille, très rapide basé sur la mémoire, la persistance RDB et AOF le rendent tout aussi solide et durable.
Intervieweur : Soyez précis.
Moi : Merci de lire le texte.

Texte
Introduction
Redis est un système de mise en cache et de stockage open source, hautes performances, basé sur des paires clé-valeur qui fournit une variété de types de données clé-valeur pour s'adapter aux besoins de mise en cache et de stockage dans différents scénarios. Dans le même temps, les nombreuses fonctions de haut niveau de Redis lui permettent de remplir différents rôles tels que la file d'attente des messages et la file d'attente des tâches. De plus, Redis prend également en charge l'extension de modules externes et peut être utilisé comme base de données principale dans certains scénarios spécifiques.
Étant donné que la vitesse de lecture et d'écriture de la mémoire est beaucoup plus rapide que celle du disque dur, même la réflexion actuelle sur le disque SSD évolue probablement vers le mode de pensée de la mémoire. Peut-être que je suis un amateur, mais pour le stockage à long terme. , j'utilise toujours un disque mécanique. Ainsi, toutes les données de la base de données Redis sont stockées en mémoire, ce qui est assez rapide. Il existe également un certain risque, qui entraînera une perte de données, mais travailler avec la persistance RDB et AOF réduira le risque.
1. Première introduction à Redis
1. Installation sous Linux (série Redhat7)
1.1.Installation
Le package de code source préparé ici n'est pas la dernière version, mais stable et applicable.
Les versions restantes sont disponibles sur le site officiel ou sur la plateforme d'hébergement github. Voici l'adresse de téléchargement du site officiel de Redis.
https://redis.io/download
redis-6.0.8.tar.gz#安装tar -zxvf redis-6.0.8.tar.gz#编译make && make install
1.2, dépannage des erreurs
make[1]: *** [server.o] 错误 1

1.3, solution
1.3.1, installer l'environnement dépendant
yum -y install centos-release-scl yum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils
1.3.2, ajouter des variables d'environnement et prendre effet
scl enable devtoolset-9 bashecho "/opt/rh/devtoolset-9/enable" >> /etc/profile
Relis le fichier de configuration des variables d'environnement
source /etc/profile
Recompiler pour résoudre le problème
#切换到Redis的安装目录,一般源码包安装会放在/usr/local/下面,看个人使用习惯cd /opt/redis-6.0.8/ #编译make && make install
Pour les exercices de commandes de base courants, vous pouvez vous référer au tutoriel novice
https://www.runoob.com/ redis/redis-commands .html
1.4. Démarrage et connexion
Démarrez le serveur redis-server
#启动redis服务nohup /opt/redis-6.0.8/src/redis-server &
Connectez-vous au client redis-cli
#登录redis-cli/opt/redis-6.0.8/src/redis-cli
Vérification du test À l'heure actuelle, redis sous Linux a officiellement démarré avec succès. . Ce qui suit présentera l’utilisation de base.
pingpong

1.5. Définir le mot de passe
Il n'y a pas de paramètre de mot de passe ouvert par défaut et vous devez activer manuellement la configuration des paramètres commentés.
#编辑配置文件vim /opt/redis-6.0.8/redis.conf #原本的被注释掉,复制一行改成你设置的密码即可 #requirepass foobaredrequirepass 123456
2. Installez
2.1 sous Windows. Installez
Redis-x64-3.2.100.zip
2.1.1 Décompressez-le sous Windows ou installez-le directement avec msi.
2.1.2. Définir la commande de service (inscription en tant que service, démarrage automatique)
Installer le service
redis-server --service-install redis.windows-service.conf --loglevel verbose
Désinstaller le service
redis-server --service-uninstall
2.2. Démarrer et arrêter
redis-server redis.windows.conf
2.2.1.
redis-server --service-start
redis-server --service-stop
#同样在redis解压的或者安装的目录以管理员身份运行cmdredis-server --service-start
Copier après la connexion
2.4. Exécutez le test de connexion sous cmd#同样在redis解压的或者安装的目录以管理员身份运行cmdredis-server --service-start
#在redis解压的或者安装的目录以管理员身份运行cmdredis-cli.exe -h 127.0.0.1 -p 6379
#或者直接执行redis-cli
#执行redis-cli
#登录测试ping
Copier après la connexion
5 L'outil de gestion rdm sous Windows est une interface visuelle#在redis解压的或者安装的目录以管理员身份运行cmdredis-cli.exe -h 127.0.0.1 -p 6379 #或者直接执行redis-cli #执行redis-cli #登录测试ping
https://redisdesktop. com/download
Intervieweur : Quels sont les types de données dans redis ?
I : string (type de chaîne), hash (type de hachage), list (type de liste), set (type d'ensemble), zset (type d'ensemble ordonné), stream (type de flux) stream est un nouveau support de fonctionnalité dans redis5.0.
Interviewer : Oh, ce jeune homme a quelque chose. Il connaît beaucoup de choses, même les genres de stream.
Moi : Confus...
3. Avancé 1 PersistanceIntervieweur : Connaissez-vous certaines fonctionnalités avancées de Redis ?
Moi : Je sais un peu.
Interviewer : Pouvez-vous en parler en détail ?
Moi : Je l'ai lu et résumé rapidement devant les chercheurs de cerveau. La mise en cache et la persistance arrivent.
将Redis作为缓存服务器,但缓存被穿透后会对性能照成较大影响,所有缓存同时失效缓存雪崩,从而使服务无法响应。
我们希望Redis能将数据从内存中以某种形式同步到磁盘中,使之重启以后根据磁盘中的记录恢复数据。这一过程就是持久化。
面试官:知道Redis有哪几种常见的持久化方式吗?
我:Redis默认开启的RDB持久化,AOF持久化方式需要手动开启。
Redis支持两种持久化。一种是RDB方式,一种是AOF方式。前者会根据指定的规则“定时”将内存中的数据存储到硬盘上,而后者在每次执行命令后将命令本书记录下来。对于这两种持久化方式,你可以单独使用其中一种,但大多数情况下是将二者紧密结合起来。
此时的面试官一脸期待,炯炯有神的看向了我,请继续。
2、RDB方式
继续介绍,RDB采取的是快照方式,默认设置自定义快照【自动同步】,默认配置如下。

同样可以手动同步
#不推荐在生产环境中使用SAVE
#异步形式BGSAVE
#基于自定义快照FLASHALL
3、AOF方式
当使用Redis存储非临时数据时,一般需要打开AOF持久化来降低进程终止导致数据的丢失。AOF可以将Redis执行的每一条命令追加到硬盘文件中,着这个过程中显然会让Redis的性能打折扣,但大部分情况下这种情况可以接受。这里强调一点,使用读写较快的硬盘可以提高AOF的性能。
默认没有开启,需要手动开启AOF,当你查看redis.conf文件时也会发现appendonly配置的是no
appendonly yes
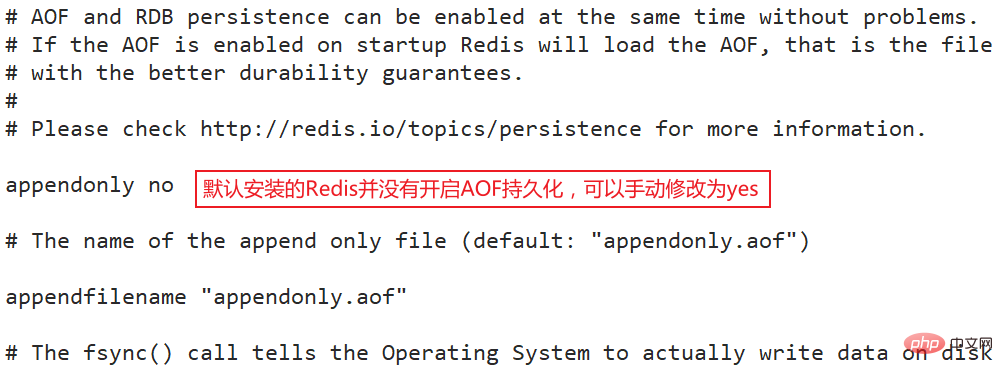
开启AOF持久化后,每次执行一条命令会会更改Redis中的数据的目录,Redis会将该命令写入磁盘中的AOF文件。AOF文件的保存位置和RDB文件的位置相同,都是通过dir参数设置,默认的文件名是appendonly.aof,可以通过appendfilename参数修改。
appendfilename "appendonly.aof

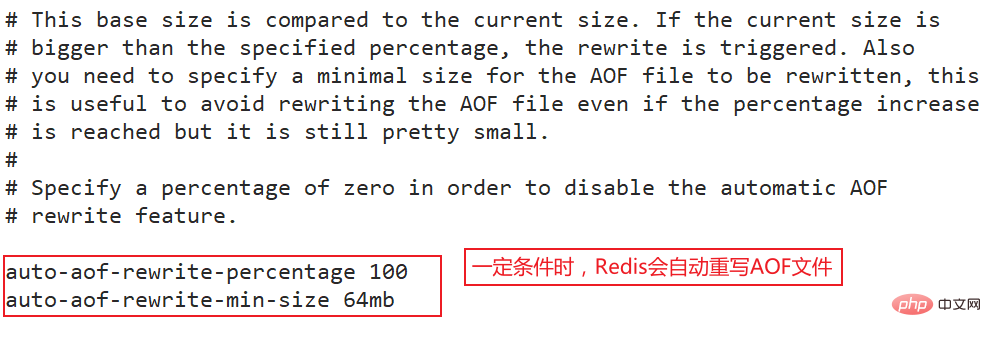
实际上Redis也正是这样做的,每当达到一定的条件时Redis就会自动重写AOF文件,这个条件可以通过redis.conf配置文件中设置:
auto-aof-rewrite-percentage 100auto-aof-rewrite-min-size 64mb
在启动时Redis会逐行执行AOF文件中的命令将硬盘中的数据加载到内存中,加载的速度相比RDB会慢一些。
虽然每次执行更改数据库内容的操作时,AOF都将命令记录在AOF文件中。但事实上,由于操作系统的缓存机制,数据并没与真正写入硬盘,而是进入了操作系统的硬盘缓存。在默认情况下,操作系统每30秒会执行一次同步操作,以便将硬盘缓存中的内容写入硬盘。
在Redis中可以通过appendfsync设置同步的时机:
# appendfsync always #默认设置为everysecappendfsync everysec # appendfsync no
Redis允许同时开启AOF和RDB。这样既保证了数据的安全,又对进行备份等操作比较友好。此时重新启动Redis后,会使用AOF文件来恢复数据。因为AOF方式的持久化,将会丢失数据的概率降至最小化。
4、Redis复制
通过持久化功能,Redis保证了即使服务器重启的情况下也不会丢失(少部分遗失)数据。但是数据库是存储在单台服务器上的,难免不会发生各种突发情况,比如硬盘故障,服务器突然宕机等等,也会导致数据遗失。
为了尽可能的避免故障,通常做法是将数据库复制多个副本以部署在不同的服务器上。这样即使有一台出现故障,其它的服务器依旧可以提供服务。为此,Redis提供了复制(replication)功能。即实现一个数据库中的数据更新后,自动将更新的数据同步到其它数据库上。
此时熟悉MySQL的同学,是不是觉得与MySQL的主从复制很像,以开启二进制日志binlog实现同步复制。
而Redis中使用复制功能更为容易,相比MySQL而言。只需要在从库中启动时加入slaveof 从数据库地址。
#在从库中配置slaveof master_database_ip_addr #测试,加了nohup与&是放入后台,并且输出日志到/root/目录下的nohup.outnohup /opt/redis-6.0.8/src/redis-server --6380 --slaveof 192.168.245.147 6379 &

4.1、原理
复制初始化。这里主要原理是从库启动,会向主库发送SYNC命令。同时主库接收到SYNC命令后会开始在后台保存快照,即RDB持久化的过程,并将快照期间接收的命令缓存起来。当快照完成后,Redis会将快照文件和所有缓存的命令发送给从数据库。从数据库收到后,会载入快照文件并执行收到的缓存命令。
复制同步阶段会贯穿整个主从同步过程,直到主从关系终止为止。在复制的过程中快照起到了至关重要的作用,只要执行复制就会进行快照,即使关闭了RDB方式的持久化,通过删除所有save参数。
4.2、乐观复制
Redis采用了乐观复制(optimistic replication)的复制策略。容忍在一定时间内主从数据库的内容是不同的,但是两者的数据最终是会同步的。具体来讲,Redis在主从数据库之间复制数据的过程本身是异步的,这就意味着,主数据库执行完客户端请求的命令会立即将命令在主数据库的执行结果反馈给客户端,并异步的将数据同步给从库,不会等待从数据库接收到该命令在返回给客户端。
当数据至少同步给指定数量的从库时,才是可写,通过参数指定:
#设置最少限制3min-slaves-to-write 3 #设置允许从数据最长失去连接时间min-slaves-max-lag 10
4.3、增量复制
基于以下三点实现
- 从库会存储主库的运行ID(run id)。每个Redis运行实例均会拥有一个唯一运行ID,每当实例重启后,就会自动生成一个新的运行ID。类似于MySQL的从节点配置的唯一ID去识别。
- 在复制同步阶段,主库一条命令被传送到从库时,会同时把该命令存放到一个积压队列(backlog)中,记录当前积压队列中存放的命令的偏移量范围。
- 从库接收到主库传来的命令时,会记录该命令的偏移量。
4.4、注意
当主数据库崩溃时,情况略微复杂。手动通过从数据库数据库恢复主库数据时,需要严格遵循以下原则:
- 在从数据库中使用
SLAVEOF NO ONE命令将从库提升为主库继续服务。 - 启动之前崩溃的主库,然后使用
SLAVEOF命令将其设置为新的主库的从库。
注意:当开启复制且数据库关闭持久化功能时,一定不要使用supervisor以及类似的进程管理工具令主库崩溃后重启。同样当主库所在的服务器因故障关闭时,也要避免直接重新启动。因为当主库重启后,没有开启持久化功能,数据库中所有数据都被清空。此时从库依然会从主库中接收数据,从而导致所有从库也被清空,导致数据库的持久化开了个寂寞。
手动维护确实很麻烦,好在Redis提供了一种自动化方案:哨兵去实现这一过程,避免手动维护易出错的问题。
5、哨兵(sentinel)
从Redis的复制历中,我们了解到在一个典型的一主多从的Redis系统中,从库在整个系统中起到了冗余备份以及读写分离的作用。当主库遇到异常中断服务后,开发人员手动将从升主时,使系统继续服务。过程相对复杂,不好实现自动化。此时可借助哨兵工具。
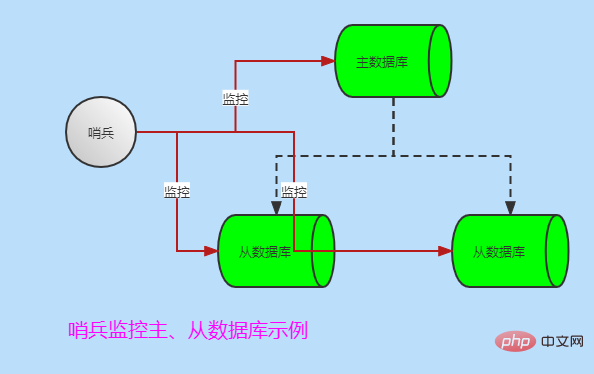
哨兵的作用
- 监控Redis系统运行情况
- 监控主库和从库是否正常运行
- 主库gg思密达,自动将从库升为主库,美滋滋
当然也有多个哨兵监控主从数据库模式,哨兵之间也会互相监控,如下图:

首先需要建立起一主多从的模型,然后开启配置哨兵。
#主库sentinel monitor master 127.0.0.1 6379 1 #建立配置文件,例如sentinel.confredis-sentinel /opt/path/to/sentinel.conf
关于哨兵就介绍这么多,现在大脑中有印象。至少知道有那么回事,可以和美女面试官多掰扯掰扯。
6、集群(cluster)
从Redis3.0开始加入了集群这一特性。
即使使用哨兵,此时的Redis集群的每个数据库依然存有集群中的所有数据,从而导致集群的总数据存储量受限于可用内存最小的数据库节点,继而出现木桶效应。正因为Redis所有数据都是基于内存存储,问题已经很突出,尤其是当Redis作为持久化存储服务时。
有这样一种场景。就扩容来说,在客户端分片后,如果像增加更多的节点,需要对数据库进行手动迁移。迁移的过程中,为了保证数据的一致性,需要将进群暂时下线,相对比较复杂。
此时考虑到Redis很小,啊不口误,是轻量的特点。可以采用预分片(presharding)在一定程度上避免问题的出现。换句话说,就是在部署的初期,提前考虑日后的存储规模,建立足够多的实例。
从上面的理论知识来看,哨兵和集群类似,但哨兵和集群是两个独立的功能。如果要进行水平扩容,集群是不错的选择。
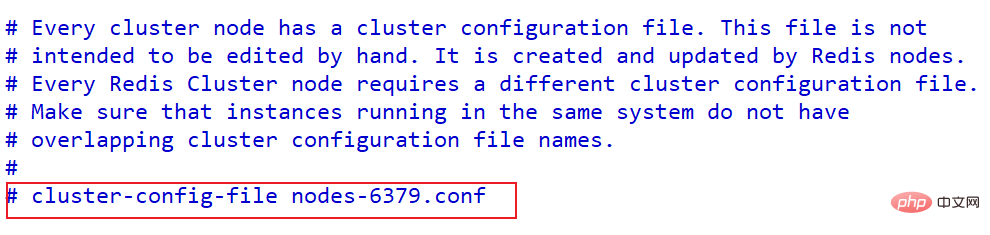
配置集群,开启配置文件redis.conf中的cluster-enabled
cluster-enabled yes

配置集群每个节点配置不同工作目录,或者修改持久化文件
cluster-config-file nodes-6379.conf
集群测试大家可以执行配置,参考其他书籍亦可,实现并不难。只要是知其原理。
四、Redis for Java
示例
package com.jedis;import redis.clients.jedis.Jedis;import redis.clients.jedis.JedisPool;import redis.clients.jedis.JedisPoolConfig;public class Test {
@org.junit.Test
public void demo() {
Jedis jedis = new Jedis("127.0.0.1", 6379);
jedis.set("name", "sky");
String params = jedis.get("jedis");
System.out.println(params);
jedis.close();
}
@org.junit.Test
public void config() {
// 获取连接池的配置对象
JedisPoolConfig config = new JedisPoolConfig();
// 设置最大连接数
config.setMaxTotal(30);
// 设置最大空闲连接数
config.setMaxIdle(10);
// 获取连接池
JedisPool pool = new JedisPool(config, "127.0.0.1", 6379);
// 获得核心对象
Jedis jedis = null;
try {
//通过连接池获取连接
jedis = pool.getResource();
//设置对象
jedis.set("poolname", "pool");
//获取对象
String pools = jedis.get("poolname");
System.out.println("values:"+pools);
} catch (Exception e) {
e.printStackTrace();
}finally{
//释放资源
if(jedis != null){
jedis.close();
}
if(pool != null){
pool.close();
}
}
}}最后放一个制作很粗超的思维导图。
推荐学习:《Redis视频教程》、《2022最新redis面试题大全及答案》
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Le mode Redis Cluster déploie les instances Redis sur plusieurs serveurs grâce à la rupture, à l'amélioration de l'évolutivité et de la disponibilité. Les étapes de construction sont les suivantes: Créez des instances de redis étranges avec différents ports; Créer 3 instances Sentinel, Moniteur Redis Instances et basculement; Configurer les fichiers de configuration Sentinel, ajouter des informations d'instance Redis de surveillance et des paramètres de basculement; Configurer les fichiers de configuration d'instance Redis, activer le mode de cluster et spécifier le chemin du fichier d'informations de cluster; Créer un fichier nœuds.conf, contenant des informations de chaque instance redis; Démarrez le cluster, exécutez la commande CREATE pour créer un cluster et spécifiez le nombre de répliques; Connectez-vous au cluster pour exécuter la commande d'informations de cluster pour vérifier l'état du cluster; faire
 Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données Redis: utilisez la commande flushall pour effacer toutes les valeurs de clé. Utilisez la commande flushdb pour effacer la valeur clé de la base de données actuellement sélectionnée. Utilisez SELECT pour commuter les bases de données, puis utilisez FlushDB pour effacer plusieurs bases de données. Utilisez la commande del pour supprimer une clé spécifique. Utilisez l'outil Redis-CLI pour effacer les données.
 Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Pour lire une file d'attente à partir de Redis, vous devez obtenir le nom de la file d'attente, lire les éléments à l'aide de la commande LPOP et traiter la file d'attente vide. Les étapes spécifiques sont les suivantes: Obtenez le nom de la file d'attente: Nommez-le avec le préfixe de "Fitre:" tel que "Fitre: My-Quyue". Utilisez la commande LPOP: éjectez l'élément de la tête de la file d'attente et renvoyez sa valeur, telle que la file d'attente LPOP: My-Queue. Traitement des files d'attente vides: si la file d'attente est vide, LPOP renvoie NIL et vous pouvez vérifier si la file d'attente existe avant de lire l'élément.
 Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
L'utilisation des opérations Redis pour verrouiller nécessite l'obtention du verrouillage via la commande setnx, puis en utilisant la commande Expire pour définir le temps d'expiration. Les étapes spécifiques sont les suivantes: (1) Utilisez la commande setnx pour essayer de définir une paire de valeurs de clé; (2) Utilisez la commande Expire pour définir le temps d'expiration du verrou; (3) Utilisez la commande del pour supprimer le verrouillage lorsque le verrouillage n'est plus nécessaire.
 Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
L'utilisation de la directive Redis nécessite les étapes suivantes: Ouvrez le client Redis. Entrez la commande (Verbe Key Value). Fournit les paramètres requis (varie de l'instruction à l'instruction). Appuyez sur Entrée pour exécuter la commande. Redis renvoie une réponse indiquant le résultat de l'opération (généralement OK ou -err).
 Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
La meilleure façon de comprendre le code source redis est d'aller étape par étape: familiarisez-vous avec les bases de Redis. Sélectionnez un module ou une fonction spécifique comme point de départ. Commencez par le point d'entrée du module ou de la fonction et affichez le code ligne par ligne. Affichez le code via la chaîne d'appel de fonction. Familiez les structures de données sous-jacentes utilisées par Redis. Identifiez l'algorithme utilisé par Redis.
 Comment utiliser la ligne de commande redis
Apr 10, 2025 pm 10:18 PM
Comment utiliser la ligne de commande redis
Apr 10, 2025 pm 10:18 PM
Utilisez l'outil de ligne de commande redis (Redis-CLI) pour gérer et utiliser Redis via les étapes suivantes: Connectez-vous au serveur, spécifiez l'adresse et le port. Envoyez des commandes au serveur à l'aide du nom et des paramètres de commande. Utilisez la commande d'aide pour afficher les informations d'aide pour une commande spécifique. Utilisez la commande QUIT pour quitter l'outil de ligne de commande.
 Comment configurer le temps d'exécution du script LUA dans Centos Redis
Apr 14, 2025 pm 02:12 PM
Comment configurer le temps d'exécution du script LUA dans Centos Redis
Apr 14, 2025 pm 02:12 PM
Sur CentOS Systems, vous pouvez limiter le temps d'exécution des scripts LUA en modifiant les fichiers de configuration Redis ou en utilisant des commandes Redis pour empêcher les scripts malveillants de consommer trop de ressources. Méthode 1: Modifiez le fichier de configuration Redis et localisez le fichier de configuration Redis: le fichier de configuration redis est généralement situé dans /etc/redis/redis.conf. Edit Fichier de configuration: Ouvrez le fichier de configuration à l'aide d'un éditeur de texte (tel que VI ou NANO): Sudovi / etc / redis / redis.conf Définissez le délai d'exécution du script LUA: Ajouter ou modifier les lignes suivantes dans le fichier de configuration pour définir le temps d'exécution maximal du script LUA (unité: millisecondes)
